CC1G_02249
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_02249 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N7J2 | Functional description | BZIP domain-containing protein |
| Location | Chr_3:2913270..2915593 | Strand | - |
| Gene length (nt) | 2324 | Transcript length (nt) | 1943 |
| CDS length (nt) | 1743 | Protein length (aa) | 580 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Pleurotus eryngii ATCC 90797 | Pleery1_474294 | 43.3 | 4.546E-70 | 241 |
| Agrocybe aegerita | Agrae_CAA7260628 | 48.3 | 1.522E-63 | 222 |
| Pleurotus ostreatus PC9 | PleosPC9_1_103976 | 45.5 | 2.852E-62 | 218 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1089374 | 45.3 | 8.05E-58 | 205 |
| Schizophyllum commune H4-8 | Schco3_2506997 | 40.5 | 1.126E-56 | 202 |
| Lentinula edodes NBRC 111202 | Lenedo1_111604 | 40.5 | 2.176E-56 | 201 |
| Lentinula edodes B17 | Lened_B_1_1_9320 | 40.7 | 3.775E-56 | 200 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_4826 | 40.7 | 4.734E-56 | 200 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_196071 | 43.5 | 7.74E-56 | 199 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_116286 | 43.5 | 1.768E-55 | 198 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_115825 | 40.9 | 5.35E-52 | 188 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB16729 | 44.8 | 6.858E-52 | 188 |
| Grifola frondosa | Grifr_OBZ70851 | 44.3 | 1.224E-50 | 184 |
| Auricularia subglabra | Aurde3_1_120387 | 42.5 | 6.68E-40 | 153 |
| Flammulina velutipes | Flave_chr07AA00193 | 38.3 | 7.886E-26 | 110 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1940 |
| Description | BZIP domain-containing protein |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd14812 | bZIP_u3 | - | 48 | 91 |
| Pfam | PF00170 | bZIP transcription factor | IPR004827 | 46 | 88 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 477 | 499 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR004827 | Basic-leucine zipper domain |
| IPR046347 | Basic-leucine zipper domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0003700 | DNA-binding transcription factor activity | MF |
| GO:0006355 | regulation of transcription, DNA-templated | BP |
KEGG
| KEGG Orthology |
|---|
| K09027 |
| K16230 |
EggNOG
| COG category | Description |
|---|---|
| K | bZIP transcription factor |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| leucine zipper |
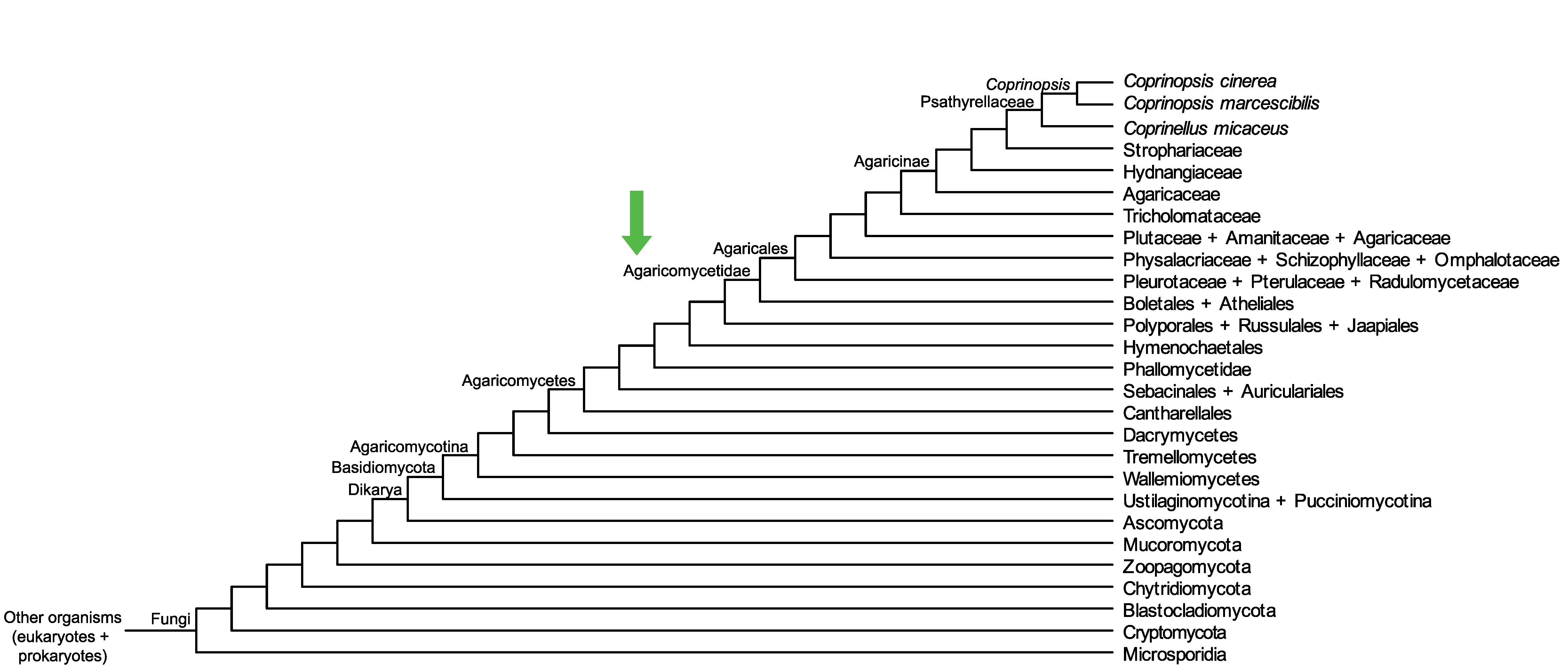
Conservation of CC1G_02249 across fungi.
Arrow shows the origin of gene family containing CC1G_02249.
Protein
| Sequence id | 1940 |
|---|---|
| Sequence |
>1940 MSFVSAHSPSPSCDSPSPSPSTSSHALPDAGQPPRKRSRSEMTSEERKEARAHRNRIAAQNSRDRRKAQFSWLER RVAELEEENRRLRAGLPVPPVPAPPPPAGLHIPVLSNIAPAMMPAPQPIPVLSPEDAIRASRDLERERENEELKE RIKTLERGWDAVVKALAAQGLPTGLSTTPAAPTTASTHSTQPLNPVPVSTTPSTSTTPSSPPTTSPTTTTKPPIS SATHFSTGFPSPAPSHASDFDFEAPVSAPSPLALSTPHQQQRDDVTARHSARVATLEPRSTALQRAVSSSHAAKV FIEVSDDATADDDAKMEDLFREIVVDDSTSSATGESSGRPVQEAASAAPSVTSTTTEVGKTETQGQGESLGKRKR EEDEESSGATKKLAFDGLELGIGANAGLDFGFDWSNTASSTTTAPLTPDEMQQMLNQIDTTNAMMQFPNDLGLDM TLDLGIWSNTATAELQSFSFISFSLSFSSFPLIISISLFMSLFLSVSLFDDSVFLHFLPWFSSYRPFCAVDRSVD CGTPDDLTTSDPDYSASLVTTIGHLSPSSSPAGLKPTGRIAEGGPRRDEMKEMAE |
| Length | 580 |
Coding
| Sequence id | CC1G_02249T0 |
|---|---|
| Sequence |
>CC1G_02249T0 ATGTCCTTTGTTTCCGCCCACTCCCCATCGCCATCGTGCGATTCACCCTCACCGTCGCCATCGACCTCATCACAC GCCTTGCCAGACGCTGGACAGCCGCCCAGGAAGCGGTCCAGGTCTGAGATGACCTCTGAAGAACGCAAGGAAGCA CGAGCGCACAGAAATCGAATCGCCGCTCAGAACAGCCGCGACCGACGGAAGGCTCAATTCTCATGGCTCGAGCGC CGTGTCGCCGAGCTCGAGGAGGAGAACCGCCGGCTACGAGCTGGCCTTCCTGTCCCCCCTGTACCAGCACCACCA CCACCCGCAGGCCTTCATATCCCCGTTCTCTCCAACATCGCCCCCGCCATGATGCCCGCACCACAACCAATCCCT GTCCTCAGTCCCGAGGACGCAATCCGGGCCAGTCGGGATTTGGAGCGAGAACGGGAGAACGAAGAGCTCAAGGAA CGCATCAAGACCTTGGAACGCGGCTGGGACGCAGTTGTCAAGGCTCTGGCAGCCCAGGGCTTGCCCACAGGCCTT TCAACAACTCCCGCCGCACCCACCACCGCCTCGACTCACTCGACCCAACCACTTAACCCCGTCCCTGTTTCGACG ACTCCCTCTACTTCCACAACGCCCTCTTCACCCCCGACAACCTCCCCAACCACCACTACCAAACCTCCCATTTCC TCCGCCACACACTTCTCTACCGGTTTCCCTTCTCCTGCGCCCTCCCATGCCTCCGACTTCGACTTTGAAGCACCC GTCTCCGCACCATCACCATTGGCGTTGTCCACTCCCCACCAACAGCAGCGTGATGACGTTACCGCTCGCCACTCA GCACGGGTGGCGACCCTCGAGCCTCGCTCGACGGCCCTGCAGCGGGCGGTCTCGTCCTCTCACGCGGCCAAAGTC TTCATCGAGGTCTCCGATGATGCAACAGCAGATGATGATGCAAAGATGGAAGACTTGTTCAGGGAGATTGTTGTT GATGACTCAACGTCGTCAGCGACGGGCGAATCTAGCGGCCGACCAGTACAAGAGGCAGCTTCTGCTGCTCCGTCG GTCACTTCCACCACCACGGAAGTAGGGAAGACAGAGACCCAGGGACAAGGAGAGAGTTTGGGTAAGAGGAAGAGG GAAGAAGACGAAGAATCATCGGGAGCGACGAAGAAGCTCGCCTTTGACGGATTGGAATTGGGAATTGGAGCGAAC GCCGGACTGGACTTTGGTTTCGACTGGTCGAATACCGCATCATCAACCACCACTGCGCCTCTCACTCCCGACGAG ATGCAGCAGATGCTCAACCAGATCGACACCACCAACGCCATGATGCAGTTTCCCAACGACTTGGGCCTCGACATG ACCTTGGATCTCGGTATCTGGTCCAACACTGCGACCGCTGAGCTCCAGTCGTTTTCGTTCATTTCGTTTTCTTTG TCATTTTCATCATTTCCTCTCATCATCAGCATCTCTCTATTTATGTCTCTCTTCCTCTCTGTTTCTCTTTTTGAC GATAGTGTCTTCCTGCATTTTCTACCGTGGTTTTCTTCCTATCGCCCCTTCTGCGCAGTCGACCGATCCGTCGAC TGTGGCACGCCCGACGACCTTACCACCTCTGACCCCGACTACTCGGCCTCGCTAGTCACGACTATCGGTCACCTC TCGCCGTCGAGTTCACCAGCTGGTCTCAAACCGACAGGACGCATTGCGGAGGGAGGGCCTAGGCGAGATGAGATG AAGGAAATGGCGGAA |
| Length | 1743 |
Transcript
| Sequence id | CC1G_02249T0 |
|---|---|
| Sequence |
>CC1G_02249T0 CGTAGTCCGTCCTGCCATTGCGCAGTATCCGCTTCTCCCTTATTTCCTTCCACACCGCCGCCTCAGGGCTTTCCT TTCCTTCGACCCTTACCAAGTCTCTAAATAATACATTCGACTTGGATCCAATTCGAATTTAACTATTCGGATTAC AACAACAACACAAACATCACTGTATTATTTTTTTCACAACGAGAACCACAATGTCCTTTGTTTCCGCCCACTCCC CATCGCCATCGTGCGATTCACCCTCACCGTCGCCATCGACCTCATCACACGCCTTGCCAGACGCTGGACAGCCGC CCAGGAAGCGGTCCAGGTCTGAGATGACCTCTGAAGAACGCAAGGAAGCACGAGCGCACAGAAATCGAATCGCCG CTCAGAACAGCCGCGACCGACGGAAGGCTCAATTCTCATGGCTCGAGCGCCGTGTCGCCGAGCTCGAGGAGGAGA ACCGCCGGCTACGAGCTGGCCTTCCTGTCCCCCCTGTACCAGCACCACCACCACCCGCAGGCCTTCATATCCCCG TTCTCTCCAACATCGCCCCCGCCATGATGCCCGCACCACAACCAATCCCTGTCCTCAGTCCCGAGGACGCAATCC GGGCCAGTCGGGATTTGGAGCGAGAACGGGAGAACGAAGAGCTCAAGGAACGCATCAAGACCTTGGAACGCGGCT GGGACGCAGTTGTCAAGGCTCTGGCAGCCCAGGGCTTGCCCACAGGCCTTTCAACAACTCCCGCCGCACCCACCA CCGCCTCGACTCACTCGACCCAACCACTTAACCCCGTCCCTGTTTCGACGACTCCCTCTACTTCCACAACGCCCT CTTCACCCCCGACAACCTCCCCAACCACCACTACCAAACCTCCCATTTCCTCCGCCACACACTTCTCTACCGGTT TCCCTTCTCCTGCGCCCTCCCATGCCTCCGACTTCGACTTTGAAGCACCCGTCTCCGCACCATCACCATTGGCGT TGTCCACTCCCCACCAACAGCAGCGTGATGACGTTACCGCTCGCCACTCAGCACGGGTGGCGACCCTCGAGCCTC GCTCGACGGCCCTGCAGCGGGCGGTCTCGTCCTCTCACGCGGCCAAAGTCTTCATCGAGGTCTCCGATGATGCAA CAGCAGATGATGATGCAAAGATGGAAGACTTGTTCAGGGAGATTGTTGTTGATGACTCAACGTCGTCAGCGACGG GCGAATCTAGCGGCCGACCAGTACAAGAGGCAGCTTCTGCTGCTCCGTCGGTCACTTCCACCACCACGGAAGTAG GGAAGACAGAGACCCAGGGACAAGGAGAGAGTTTGGGTAAGAGGAAGAGGGAAGAAGACGAAGAATCATCGGGAG CGACGAAGAAGCTCGCCTTTGACGGATTGGAATTGGGAATTGGAGCGAACGCCGGACTGGACTTTGGTTTCGACT GGTCGAATACCGCATCATCAACCACCACTGCGCCTCTCACTCCCGACGAGATGCAGCAGATGCTCAACCAGATCG ACACCACCAACGCCATGATGCAGTTTCCCAACGACTTGGGCCTCGACATGACCTTGGATCTCGGTATCTGGTCCA ACACTGCGACCGCTGAGCTCCAGTCGTTTTCGTTCATTTCGTTTTCTTTGTCATTTTCATCATTTCCTCTCATCA TCAGCATCTCTCTATTTATGTCTCTCTTCCTCTCTGTTTCTCTTTTTGACGATAGTGTCTTCCTGCATTTTCTAC CGTGGTTTTCTTCCTATCGCCCCTTCTGCGCAGTCGACCGATCCGTCGACTGTGGCACGCCCGACGACCTTACCA CCTCTGACCCCGACTACTCGGCCTCGCTAGTCACGACTATCGGTCACCTCTCGCCGTCGAGTTCACCAGCTGGTC TCAAACCGACAGGACGCATTGCGGAGGGAGGGCCTAGGCGAGATGAGATGAAGGAAATGGCGGAATGA |
| Length | 1943 |
Gene
| Sequence id | CC1G_02249T0 |
|---|---|
| Sequence |
>CC1G_02249T0 CGTAGTCCGTCCTGCCATTGCGCAGTATCCGCTTCTCCCTTATTTCCTTCCACACCGCCGCCTCAGGGCTTTCCT TTCCTTCGACCCTTACCAAGTCTCTAAATAATACATTCGACTTGGATCCAATTCGAATTTAACTATTCGGATTAC AACAACAACACAAACATCACTGTATTGTGAGTAATTTCGGAGACATTTGTCTAGATTTTAGCGAATATTGACAAC GACGTCGTGCAGATTTTTTTCACAACGAGAACCACAATGTCCTTTGTTTCCGCCCACTCCCCATCGCCATCGTGC GATTCACCCTCACCGTCGCCATCGACCTCATCACACGCCTTGCCAGACGCTGGACAGCCGCCCAGGAAGCGGTCC AGGTCTGAGATGACCTCTGAAGAACGCAAGGAAGCACGAGCGCACAGAAATCGAATCGCCGCTCAGAACAGCCGC GACCGACGGAAGGCTCAATTCTCATGGCTCGAGCGCCGTGTCGCCGAGCTCGAGGAGGAGAACCGCCGGCTACGA GCTGGCCTTCCTGTCCCCCCTGTACCAGCACCACCACCACCCGCAGGCCTTCATATCCCCGTTCTCTCCAACATC GCCCCCGCCATGATGCCCGCACCACAACCAATCCCTGTCCTCAGTCCCGAGGACGCAATCCGGGCCAGTCGGGAT TTGGAGCGAGAACGGGAGAACGAAGAGCTCAAGGAACGCATCAAGACCTTGGAACGCGGCTGGGACGCAGTTGTC AAGGCTCTGGCAGCCCAGGGCTTGCCCACAGGCCTTTCAACAACTCCCGCCGCACCCACCACCGCCTCGACTCAC TCGACCCAACCACTTAACCCCGTCCCTGTTTCGACGACTCCCTCTACTTCCACAACGCCCTCTTCACCCCCGACA ACCTCCCCAACCACCACTACCAAACCTCCCATTTCCTCCGCCACACACTTCTCTACCGGTTTCCCTTCTCCTGCG CCCTCCCATGCCTCCGACTTCGACTTTGAAGCACCCGTCTCCGCACCATCACCATTGGCGTTGTCCACTCCCCAC CAACAGCAGCGTGATGACGTTACCGCTCGCCACTCAGCACGGGTGGCGACCCTCGAGCCTCGCTCGACGGCCCTG CAGCGGGCGGTCTCGTCCTCTCACGCGGCCAAAGTGTCGGCGTGTACCCTTCGCCATCTACCAGCTTCATCGAGG TCTCCGATGATGCAACAGCAGATGATGATGCAAAGATGGAAGACTTGTTCAGGGAGATTGTTGTTGATGACTCAA CGTCGTCAGCGACGGGCGAATCTAGCGGCCGACCAGTACAAGAGGCAGCTTCTGCTGCTCCGTCGGTCACTTCCA CCACCACGGAAGTAGGGAAGACAGAGACCCAGGGACAAGGAGAGAGTTTGGGTAAGAGGAAGAGGGAAGAAGACG AAGAATCATCGGGAGCGACGAAGAAGCTCGCCTTTGACGGATTGGAATTGGGAATTGGAGCGAACGCCGGACTGG ACTTTGGTTTCGACTGGTCGAATACCGCATCATCAACCACCACTGCGCCTCTCACTCCCGACGAGATGCAGCAGA TGCTCAACCAGATCGACACCACCAACGCCATGATGCAGTTTCCCAACGACTTGGGCCTCGACATGACCTTGGATC TCGGTATCTGGTCCAACACTGCGACCGCTGGTGTTTTCTAAACCCGGCGCCAGTGTTGTCTGTCTTCCTTGTCTC GCATCACCGGATTCGACTCGTTGTTACCCCACTTCGCAAACGAGTGCGCCTAGTTCTGCGTACTTGAAGGTTTGG GAACAGCCTCACTGAGTCTCCGAAGCGTTGTTTCGTCCCACGTGGACCCCGTGACCCATTAGTCTGGACATTCGC CCAACATGGTGTCGCCCCTGATACCACCTCCCAAAATTGTACAACAGTATCCATTTCGTCTTTCTCATTGGGTTG GCTTTCTTCATCTACATCTAGAGCTCCAGTCGTTTTCGTTCATTTCGTTTTCTTTGTCATTTTCATCATTTCCTC TCATCATCAGCATCTCTCTATTTATGTCTCTCTTCCTCTCTGTTTCTCTTTTTGACGATAGTGTCTTCCTGCATT TTCTACCGTGGTTTTCTTCCTATCGCCCCTTCTGCGCAGTCGACCGATCCGTCGACTGTGGCACGCCCGACGACC TTACCACCTCTGACCCCGACTACTCGGCCTCGCTAGTCACGACTATCGGTCACCTCTCGCCGTCGAGTTCACCAG CTGGTCTCAAACCGACAGGACGCATTGCGGAGGGAGGGCCTAGGCGAGATGAGATGAAGGAAATGGCGGAATGA |
| Length | 2324 |