CC1G_00923
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_00923 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N948 | Functional description | CAMK/CAMKL/GIN4 protein kinase |
| Location | Chr_7:1452004..1454893 | Strand | + |
| Gene length (nt) | 2890 | Transcript length (nt) | 2835 |
| CDS length (nt) | 2835 | Protein length (aa) | 944 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7265113 | 44.9 | 1.924E-218 | 700 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB23720 | 41.2 | 1.83E-195 | 633 |
| Pleurotus ostreatus PC9 | PleosPC9_1_88265 | 39.7 | 2.536E-183 | 597 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1464094 | 39.2 | 1.897E-177 | 580 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_108470 | 38.7 | 4.395E-174 | 570 |
| Grifola frondosa | Grifr_OBZ73948 | 43.6 | 5.075E-171 | 561 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_9481 | 36.7 | 9.742E-158 | 522 |
| Flammulina velutipes | Flave_chr06AA00340 | 36.3 | 6.439E-146 | 487 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1044044 | 65.8 | 1.302E-145 | 486 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_223080 | 66.3 | 2.922E-139 | 467 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_70363 | 66.3 | 3.045E-139 | 467 |
| Auricularia subglabra | Aurde3_1_39749 | 62.1 | 3.258E-135 | 456 |
| Schizophyllum commune H4-8 | Schco3_2535527 | 35.1 | 1.077E-134 | 454 |
| Lentinula edodes NBRC 111202 | Lenedo1_1036975 | 51.6 | 2.576E-108 | 375 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 794 |
| Description | CAMK/CAMKL/GIN4 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd14081 | STKc_BRSK1_2 | - | 24 | 294 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 27 | 294 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K02515 |
| K06668 |
| K18679 |
| K18680 |
EggNOG
| COG category | Description |
|---|---|
| D | Serine/Threonine protein kinases, catalytic domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
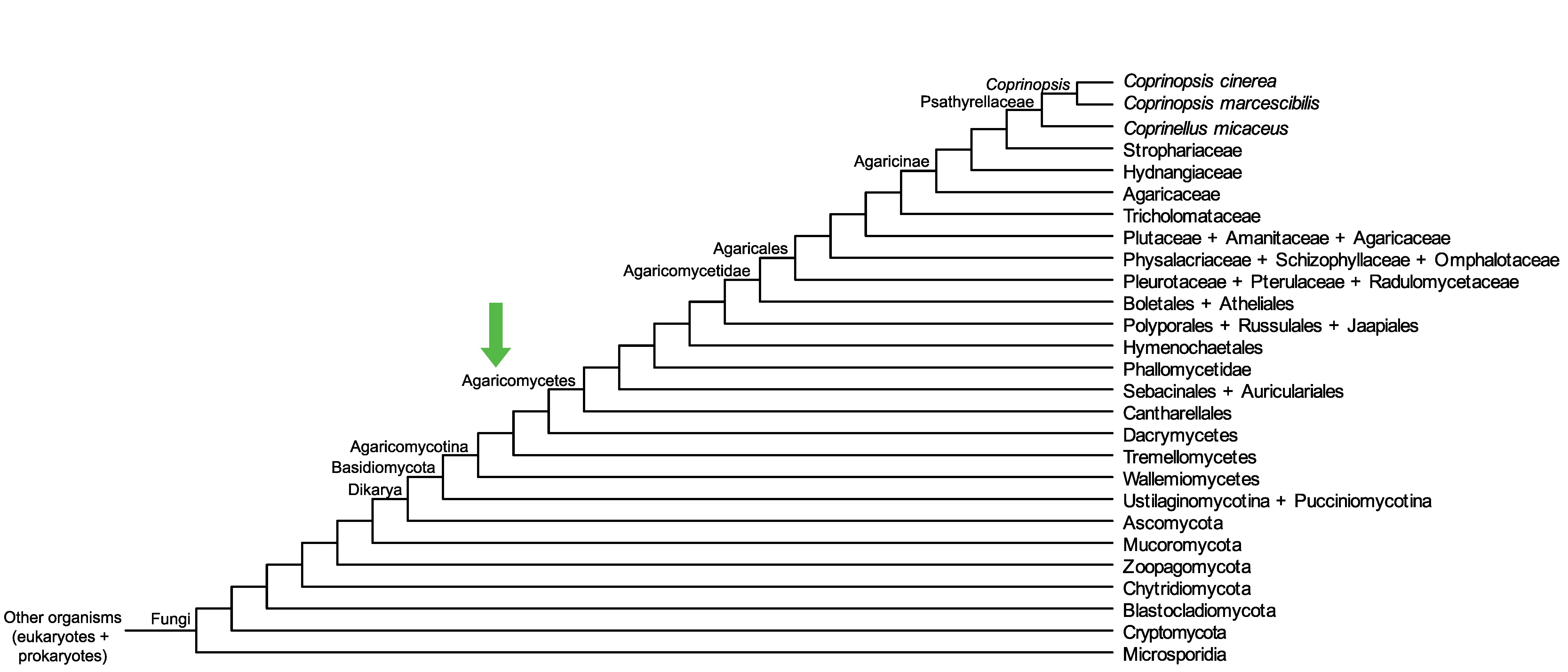
Conservation of CC1G_00923 across fungi.
Arrow shows the origin of gene family containing CC1G_00923.
Protein
| Sequence id | 794 |
|---|---|
| Sequence |
>794 MADPPRTPFSFHSTKTVRDPKSIGLWTVGRTIGKGASGRVRIARHAKTGQYAAIKIISKSTLPPMMSQVSLNRLA DVTEHVQLSVEREIVVMKLINHPNIMKLYDVWETSTDLYLVLEYVQGGELFDYLCSKGRLPVHEALLYFQQIISA VDYCHRFNIAHRDLKPENILLDENSNIKIADFGMAAWQSNPDAETLRTSCGSPHYAAPEIINGQPYNGAAADIWS CGIILHALLVGKLPFDDDDCPALLEKILRAKFTMPTDIPASAQNLLGRMLEKDVKKRITMAEIMEHPFFLSQDPP KVDYALPDLESIAQPVPSVSALDPDIFANLRTLWHGTSDAVLIDSLINNERNWQKGIYHLLVDYRSRNPQVYDED EQAVAKLHKERKRRRQQRKPVQNDGDADDIPPRAAPPTPRSASRHNRLGIDLSFDELLPHAKSSSSSLSERNETS RPTHLQPPPMSTQRSSDSTTSEGTSVSSTTATTTTATSSSLLTPFSPLWETLDLPKLTVPNTQDREMQTFFNHIV THLNVLQAKTASSEISTWGASSSLGSAASGGGSESGTIKSGRSGLSASSAAVPNARMTSARKTGVDHEDGFFRPS RHSSPRLDSSLIAPIQQKGKGKEKASLHLPEEGDEDDEDSLGEVEGRQQLGASTVEALRYTETQPLSVRSHSRRA LYPVTPSRTTNKENEDVPLDAYRSNLTRQALANHAKRNLSTPKAITIVEPQPVSQRKHIRQGSRKPPQTPLSALS PLDNRGVGGLSSSSAYAHGYTSPPPHPSSTATPKRTWIDTVFKPKAPNYTLYSRRGVQETRNECRRLLMDLDLLV SIEENERMGVLKCRSIEIQDPFRVHNVPKAIRFRVEGQRAPYNLVQSGITMSLSFYHEKGSFEAFQDIYHSLRAR WDMDKVESVAEGDEDEMEGMTKLASGLSALSTRAIGGRPASQAY |
| Length | 944 |
Coding
| Sequence id | CC1G_00923T0 |
|---|---|
| Sequence |
>CC1G_00923T0 ATGGCTGACCCTCCACGCACACCGTTCTCATTTCATTCAACGAAAACCGTTCGGGACCCCAAGTCGATTGGGCTA TGGACAGTAGGGAGGACGATTGGGAAGGGTGCCTCAGGTCGCGTTAGGATTGCGCGTCATGCAAAGACAGGCCAA TACGCAGCAATCAAAATCATCTCAAAGAGCACCCTTCCGCCCATGATGTCCCAAGTTTCCCTGAACCGCCTGGCA GACGTCACAGAGCATGTTCAGCTCTCTGTAGAGCGAGAGATCGTTGTTATGAAACTCATCAACCACCCCAACATC ATGAAGCTCTACGACGTTTGGGAAACGTCCACGGATCTCTACCTAGTCTTGGAATACGTTCAGGGTGGCGAACTG TTCGACTACCTCTGTTCCAAGGGACGACTGCCGGTCCACGAGGCCCTCTTATACTTCCAGCAAATCATATCCGCA GTCGACTATTGCCATCGTTTTAATATTGCGCATCGGGACTTAAAACCGGAGAACATCCTGCTCGACGAGAACTCG AACATTAAGATTGCGGATTTTGGTATGGCAGCATGGCAGAGCAACCCAGACGCCGAAACACTTCGCACGTCTTGC GGGAGTCCACACTACGCCGCCCCGGAGATCATCAACGGCCAGCCATACAACGGTGCAGCCGCCGATATCTGGTCC TGCGGCATCATCCTTCACGCTCTGTTGGTCGGCAAACTCCCATTCGACGACGACGATTGTCCCGCCCTTCTCGAA AAGATTCTACGCGCCAAGTTCACCATGCCCACGGATATCCCGGCTTCCGCGCAGAACCTATTGGGCCGCATGTTG GAGAAGGATGTCAAGAAGAGGATCACCATGGCCGAGATCATGGAACATCCTTTTTTCCTGTCCCAGGACCCGCCA AAGGTCGACTATGCGCTCCCAGACCTCGAAAGCATCGCTCAACCTGTCCCAAGCGTCTCAGCCCTCGATCCAGAC ATATTTGCCAACCTCCGTACCCTCTGGCACGGAACGAGCGACGCCGTCCTCATTGACAGCCTCATTAACAACGAG CGAAACTGGCAAAAGGGCATCTACCACCTACTCGTTGACTATCGATCCCGCAATCCGCAGGTGTACGACGAAGAC GAGCAAGCCGTTGCGAAACTTCACAAGGAACGGAAACGTCGACGACAGCAACGTAAGCCTGTACAGAATGACGGG GATGCCGATGACATCCCTCCTCGTGCAGCTCCTCCCACACCTCGCAGCGCTTCCCGACACAACCGGCTTGGAATC GACCTCTCCTTCGATGAACTACTACCCCATGCCAAGTCTTCATCATCGTCCCTATCAGAACGAAATGAAACATCC CGTCCGACTCATCTCCAACCCCCTCCAATGTCTACCCAACGCAGCTCAGACTCTACCACTTCTGAAGGAACATCT GTCAGTAGCACAACGGCCACCACCACCACCGCAACCAGCTCATCCCTCCTCACCCCTTTCTCTCCGCTCTGGGAA ACCCTAGATCTACCCAAACTTACGGTTCCCAACACACAAGACCGCGAGATGCAAACCTTTTTCAATCACATCGTG ACGCATCTCAATGTTCTCCAAGCCAAGACGGCTTCTTCAGAGATCAGCACATGGGGTGCCTCGTCTTCTTTGGGT TCGGCGGCTTCAGGTGGAGGTAGTGAGAGTGGCACGATCAAGAGTGGGAGGAGTGGTTTAAGCGCTTCGAGTGCA GCCGTGCCTAACGCGAGGATGACGTCGGCTAGGAAGACGGGAGTGGATCACGAAGACGGGTTCTTTCGACCATCC CGACATTCTTCGCCGAGATTGGATTCATCTCTCATTGCTCCTATCCAGCAGAAAGGTAAAGGGAAGGAGAAGGCG AGCTTGCATTTGCCGGAGGAAGGCGACGAAGATGATGAGGATTCACTTGGCGAGGTTGAAGGACGACAGCAGTTG GGAGCTTCTACCGTGGAAGCGCTTCGGTACACCGAGACACAACCGCTCAGCGTGCGAAGCCATTCCCGACGGGCT CTGTACCCTGTGACGCCCAGCCGCACCACCAACAAGGAGAACGAAGATGTCCCATTAGATGCCTACCGAAGTAAT CTGACGAGGCAGGCTCTCGCCAACCACGCAAAGCGGAACCTTTCTACACCCAAAGCGATTACGATCGTCGAACCT CAACCAGTCTCCCAACGCAAACACATCAGGCAAGGGAGTCGCAAACCCCCTCAAACACCATTGTCTGCTCTGTCA CCTCTAGACAACAGAGGGGTGGGAGGTCTGTCATCAAGCAGCGCTTACGCCCACGGTTACACTTCCCCACCTCCA CATCCCTCTTCCACCGCGACTCCCAAACGCACCTGGATCGACACAGTCTTTAAACCGAAAGCACCCAACTACACG CTCTACTCCCGTCGTGGCGTGCAAGAAACGCGCAATGAATGCCGCAGGCTGCTCATGGACCTCGACCTTCTCGTC TCCATCGAGGAGAACGAGCGGATGGGCGTCCTGAAATGCCGCTCGATTGAAATTCAGGACCCTTTCCGGGTACAC AACGTGCCCAAAGCTATCCGGTTCCGAGTAGAAGGTCAGAGGGCACCTTACAATCTGGTGCAGTCGGGGATCACA ATGTCGTTGTCCTTCTATCATGAGAAGGGGTCCTTTGAGGCGTTTCAGGATATCTATCACTCGTTAAGGGCGAGA TGGGATATGGACAAGGTTGAGTCGGTGGCGGAAGGAGATGAAGATGAGATGGAGGGGATGACGAAGCTAGCGAGT GGTTTGTCTGCACTTTCGACGAGGGCCATTGGGGGACGGCCTGCGAGTCAGGCGTAT |
| Length | 2835 |
Transcript
| Sequence id | CC1G_00923T0 |
|---|---|
| Sequence |
>CC1G_00923T0 ATGGCTGACCCTCCACGCACACCGTTCTCATTTCATTCAACGAAAACCGTTCGGGACCCCAAGTCGATTGGGCTA TGGACAGTAGGGAGGACGATTGGGAAGGGTGCCTCAGGTCGCGTTAGGATTGCGCGTCATGCAAAGACAGGCCAA TACGCAGCAATCAAAATCATCTCAAAGAGCACCCTTCCGCCCATGATGTCCCAAGTTTCCCTGAACCGCCTGGCA GACGTCACAGAGCATGTTCAGCTCTCTGTAGAGCGAGAGATCGTTGTTATGAAACTCATCAACCACCCCAACATC ATGAAGCTCTACGACGTTTGGGAAACGTCCACGGATCTCTACCTAGTCTTGGAATACGTTCAGGGTGGCGAACTG TTCGACTACCTCTGTTCCAAGGGACGACTGCCGGTCCACGAGGCCCTCTTATACTTCCAGCAAATCATATCCGCA GTCGACTATTGCCATCGTTTTAATATTGCGCATCGGGACTTAAAACCGGAGAACATCCTGCTCGACGAGAACTCG AACATTAAGATTGCGGATTTTGGTATGGCAGCATGGCAGAGCAACCCAGACGCCGAAACACTTCGCACGTCTTGC GGGAGTCCACACTACGCCGCCCCGGAGATCATCAACGGCCAGCCATACAACGGTGCAGCCGCCGATATCTGGTCC TGCGGCATCATCCTTCACGCTCTGTTGGTCGGCAAACTCCCATTCGACGACGACGATTGTCCCGCCCTTCTCGAA AAGATTCTACGCGCCAAGTTCACCATGCCCACGGATATCCCGGCTTCCGCGCAGAACCTATTGGGCCGCATGTTG GAGAAGGATGTCAAGAAGAGGATCACCATGGCCGAGATCATGGAACATCCTTTTTTCCTGTCCCAGGACCCGCCA AAGGTCGACTATGCGCTCCCAGACCTCGAAAGCATCGCTCAACCTGTCCCAAGCGTCTCAGCCCTCGATCCAGAC ATATTTGCCAACCTCCGTACCCTCTGGCACGGAACGAGCGACGCCGTCCTCATTGACAGCCTCATTAACAACGAG CGAAACTGGCAAAAGGGCATCTACCACCTACTCGTTGACTATCGATCCCGCAATCCGCAGGTGTACGACGAAGAC GAGCAAGCCGTTGCGAAACTTCACAAGGAACGGAAACGTCGACGACAGCAACGTAAGCCTGTACAGAATGACGGG GATGCCGATGACATCCCTCCTCGTGCAGCTCCTCCCACACCTCGCAGCGCTTCCCGACACAACCGGCTTGGAATC GACCTCTCCTTCGATGAACTACTACCCCATGCCAAGTCTTCATCATCGTCCCTATCAGAACGAAATGAAACATCC CGTCCGACTCATCTCCAACCCCCTCCAATGTCTACCCAACGCAGCTCAGACTCTACCACTTCTGAAGGAACATCT GTCAGTAGCACAACGGCCACCACCACCACCGCAACCAGCTCATCCCTCCTCACCCCTTTCTCTCCGCTCTGGGAA ACCCTAGATCTACCCAAACTTACGGTTCCCAACACACAAGACCGCGAGATGCAAACCTTTTTCAATCACATCGTG ACGCATCTCAATGTTCTCCAAGCCAAGACGGCTTCTTCAGAGATCAGCACATGGGGTGCCTCGTCTTCTTTGGGT TCGGCGGCTTCAGGTGGAGGTAGTGAGAGTGGCACGATCAAGAGTGGGAGGAGTGGTTTAAGCGCTTCGAGTGCA GCCGTGCCTAACGCGAGGATGACGTCGGCTAGGAAGACGGGAGTGGATCACGAAGACGGGTTCTTTCGACCATCC CGACATTCTTCGCCGAGATTGGATTCATCTCTCATTGCTCCTATCCAGCAGAAAGGTAAAGGGAAGGAGAAGGCG AGCTTGCATTTGCCGGAGGAAGGCGACGAAGATGATGAGGATTCACTTGGCGAGGTTGAAGGACGACAGCAGTTG GGAGCTTCTACCGTGGAAGCGCTTCGGTACACCGAGACACAACCGCTCAGCGTGCGAAGCCATTCCCGACGGGCT CTGTACCCTGTGACGCCCAGCCGCACCACCAACAAGGAGAACGAAGATGTCCCATTAGATGCCTACCGAAGTAAT CTGACGAGGCAGGCTCTCGCCAACCACGCAAAGCGGAACCTTTCTACACCCAAAGCGATTACGATCGTCGAACCT CAACCAGTCTCCCAACGCAAACACATCAGGCAAGGGAGTCGCAAACCCCCTCAAACACCATTGTCTGCTCTGTCA CCTCTAGACAACAGAGGGGTGGGAGGTCTGTCATCAAGCAGCGCTTACGCCCACGGTTACACTTCCCCACCTCCA CATCCCTCTTCCACCGCGACTCCCAAACGCACCTGGATCGACACAGTCTTTAAACCGAAAGCACCCAACTACACG CTCTACTCCCGTCGTGGCGTGCAAGAAACGCGCAATGAATGCCGCAGGCTGCTCATGGACCTCGACCTTCTCGTC TCCATCGAGGAGAACGAGCGGATGGGCGTCCTGAAATGCCGCTCGATTGAAATTCAGGACCCTTTCCGGGTACAC AACGTGCCCAAAGCTATCCGGTTCCGAGTAGAAGGTCAGAGGGCACCTTACAATCTGGTGCAGTCGGGGATCACA ATGTCGTTGTCCTTCTATCATGAGAAGGGGTCCTTTGAGGCGTTTCAGGATATCTATCACTCGTTAAGGGCGAGA TGGGATATGGACAAGGTTGAGTCGGTGGCGGAAGGAGATGAAGATGAGATGGAGGGGATGACGAAGCTAGCGAGT GGTTTGTCTGCACTTTCGACGAGGGCCATTGGGGGACGGCCTGCGAGTCAGGCGTATTGA |
| Length | 2835 |
Gene
| Sequence id | CC1G_00923T0 |
|---|---|
| Sequence |
>CC1G_00923T0 ATGGCTGACCCTCCACGCACACCGTTCTCATTTCATTCAACGAAAACCGTTCGGGACCCCAAGTCGATTGGGCTA TGGACAGTAGGGAGGACGATTGGGAAGGGTGCCTCAGGTAAGACACCCAGGTTTTATAGGCTTAATACAGTAGAA ATGAACGCAACTTCTAGGTCGCGTTAGGATTGCGCGTCATGCAAAGACAGGCCAATACGCAGCAATCAAAATCAT CTCAAAGAGCACCCTTCCGCCCATGATGTCCCAAGTTTCCCTGAACCGCCTGGCAGACGTCACAGAGCATGTTCA GCTCTCTGTAGAGCGAGAGATCGTTGTTATGAAACTCATCAACCACCCCAACATCATGAAGCTCTACGACGTTTG GGAAACGTCCACGGATCTCTACCTAGTCTTGGAATACGTTCAGGGTGGCGAACTGTTCGACTACCTCTGTTCCAA GGGACGACTGCCGGTCCACGAGGCCCTCTTATACTTCCAGCAAATCATATCCGCAGTCGACTATTGCCATCGTTT TAATATTGCGCATCGGGACTTAAAACCGGAGAACATCCTGCTCGACGAGAACTCGAACATTAAGATTGCGGATTT TGGTATGGCAGCATGGCAGAGCAACCCAGACGCCGAAACACTTCGCACGTCTTGCGGGAGTCCACACTACGCCGC CCCGGAGATCATCAACGGCCAGCCATACAACGGTGCAGCCGCCGATATCTGGTCCTGCGGCATCATCCTTCACGC TCTGTTGGTCGGCAAACTCCCATTCGACGACGACGATTGTCCCGCCCTTCTCGAAAAGATTCTACGCGCCAAGTT CACCATGCCCACGGATATCCCGGCTTCCGCGCAGAACCTATTGGGCCGCATGTTGGAGAAGGATGTCAAGAAGAG GATCACCATGGCCGAGATCATGGAACATCCTTTTTTCCTGTCCCAGGACCCGCCAAAGGTCGACTATGCGCTCCC AGACCTCGAAAGCATCGCTCAACCTGTCCCAAGCGTCTCAGCCCTCGATCCAGACATATTTGCCAACCTCCGTAC CCTCTGGCACGGAACGAGCGACGCCGTCCTCATTGACAGCCTCATTAACAACGAGCGAAACTGGCAAAAGGGCAT CTACCACCTACTCGTTGACTATCGATCCCGCAATCCGCAGGTGTACGACGAAGACGAGCAAGCCGTTGCGAAACT TCACAAGGAACGGAAACGTCGACGACAGCAACGTAAGCCTGTACAGAATGACGGGGATGCCGATGACATCCCTCC TCGTGCAGCTCCTCCCACACCTCGCAGCGCTTCCCGACACAACCGGCTTGGAATCGACCTCTCCTTCGATGAACT ACTACCCCATGCCAAGTCTTCATCATCGTCCCTATCAGAACGAAATGAAACATCCCGTCCGACTCATCTCCAACC CCCTCCAATGTCTACCCAACGCAGCTCAGACTCTACCACTTCTGAAGGAACATCTGTCAGTAGCACAACGGCCAC CACCACCACCGCAACCAGCTCATCCCTCCTCACCCCTTTCTCTCCGCTCTGGGAAACCCTAGATCTACCCAAACT TACGGTTCCCAACACACAAGACCGCGAGATGCAAACCTTTTTCAATCACATCGTGACGCATCTCAATGTTCTCCA AGCCAAGACGGCTTCTTCAGAGATCAGCACATGGGGTGCCTCGTCTTCTTTGGGTTCGGCGGCTTCAGGTGGAGG TAGTGAGAGTGGCACGATCAAGAGTGGGAGGAGTGGTTTAAGCGCTTCGAGTGCAGCCGTGCCTAACGCGAGGAT GACGTCGGCTAGGAAGACGGGAGTGGATCACGAAGACGGGTTCTTTCGACCATCCCGACATTCTTCGCCGAGATT GGATTCATCTCTCATTGCTCCTATCCAGCAGAAAGGTAAAGGGAAGGAGAAGGCGAGCTTGCATTTGCCGGAGGA AGGCGACGAAGATGATGAGGATTCACTTGGCGAGGTTGAAGGACGACAGCAGTTGGGAGCTTCTACCGTGGAAGC GCTTCGGTACACCGAGACACAACCGCTCAGCGTGCGAAGCCATTCCCGACGGGCTCTGTACCCTGTGACGCCCAG CCGCACCACCAACAAGGAGAACGAAGATGTCCCATTAGATGCCTACCGAAGTAATCTGACGAGGCAGGCTCTCGC CAACCACGCAAAGCGGAACCTTTCTACACCCAAAGCGATTACGATCGTCGAACCTCAACCAGTCTCCCAACGCAA ACACATCAGGCAAGGGAGTCGCAAACCCCCTCAAACACCATTGTCTGCTCTGTCACCTCTAGACAACAGAGGGGT GGGAGGTCTGTCATCAAGCAGCGCTTACGCCCACGGTTACACTTCCCCACCTCCACATCCCTCTTCCACCGCGAC TCCCAAACGCACCTGGATCGACACAGTCTTTAAACCGAAAGCACCCAACTACACGCTCTACTCCCGTCGTGGCGT GCAAGAAACGCGCAATGAATGCCGCAGGCTGCTCATGGACCTCGACCTTCTCGTCTCCATCGAGGAGAACGAGCG GATGGGCGTCCTGAAATGCCGCTCGATTGAAATTCAGGACCCTTTCCGGGTACACAACGTGCCCAAAGCTATCCG GTTCCGAGTAGAAGGTCAGAGGGCACCTTACAATCTGGTGCAGTCGGGGATCACAATGTCGTTGTCCTTCTATCA TGAGAAGGGGTCCTTTGAGGCGTTTCAGGATATCTATCACTCGTTAAGGGCGAGATGGGATATGGACAAGGTTGA GTCGGTGGCGGAAGGAGATGAAGATGAGATGGAGGGGATGACGAAGCTAGCGAGTGGTTTGTCTGCACTTTCGAC GAGGGCCATTGGGGGACGGCCTGCGAGTCAGGCGTATTGA |
| Length | 2890 |