CC1G_01540
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_01540 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NHZ1 | Functional description | Pyranose dehydrogenase |
| Location | Chr_10:221401..223682 | Strand | + |
| Gene length (nt) | 2282 | Transcript length (nt) | 1767 |
| CDS length (nt) | 1767 | Protein length (aa) | 588 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits | |
|---|---|---|---|---|---|
| No records | |||||
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1328 |
| Description | Pyranose dehydrogenase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00732 | GMC oxidoreductase | IPR000172 | 34 | 351 |
| Pfam | PF05199 | GMC oxidoreductase | IPR007867 | 441 | 579 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 19 | 0.8834 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR012132 | Glucose-methanol-choline oxidoreductase |
| IPR036188 | FAD/NAD(P)-binding domain superfamily |
| IPR000172 | Glucose-methanol-choline oxidoreductase, N-terminal |
| IPR007867 | Glucose-methanol-choline oxidoreductase, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0050660 | flavin adenine dinucleotide binding | MF |
| GO:0016614 | oxidoreductase activity, acting on CH-OH group of donors | MF |
KEGG
| KEGG Orthology |
|---|
| K00108 |
| K20154 |
EggNOG
| COG category | Description |
|---|---|
| E | Aryl-alcohol oxidase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| AA | AA3 | AA3_2 |
Transcription factor
| Group |
|---|
| No records |
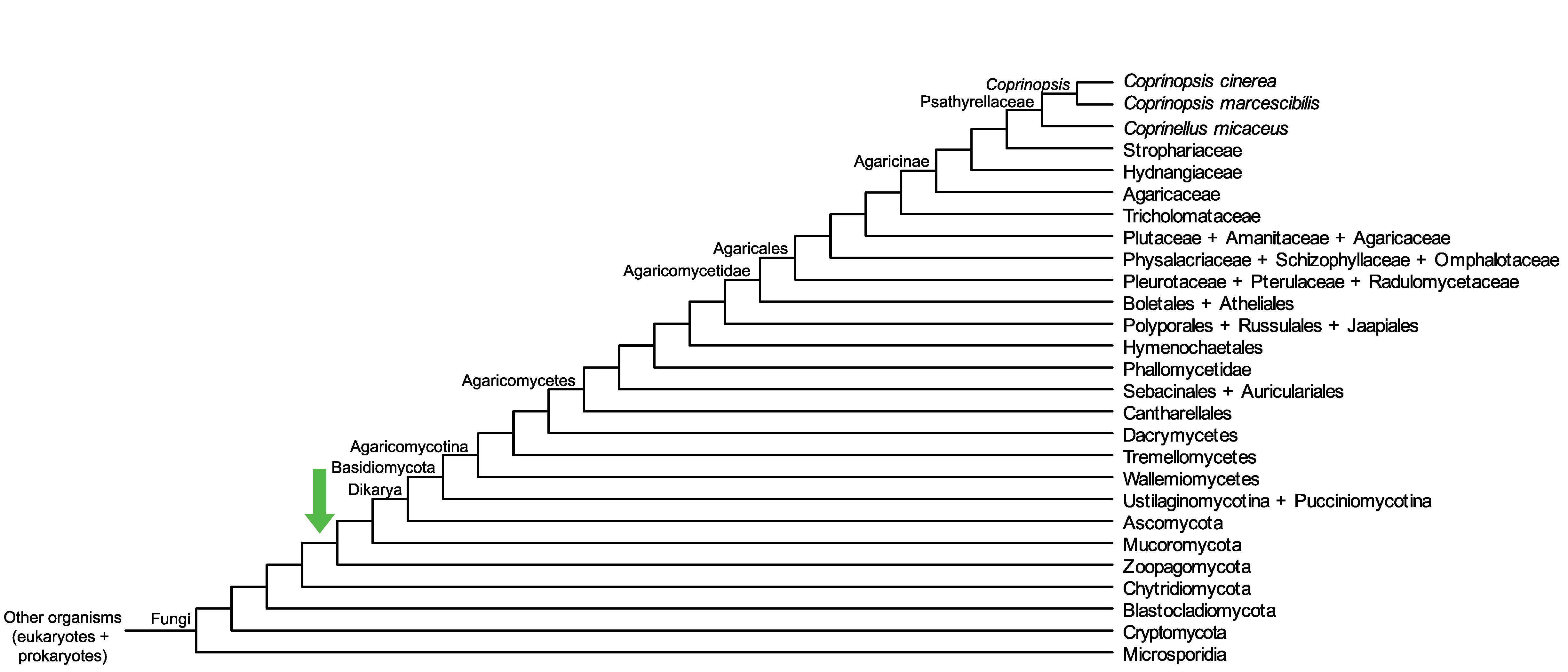
Conservation of CC1G_01540 across fungi.
Arrow shows the origin of gene family containing CC1G_01540.
Protein
| Sequence id | 1328 |
|---|---|
| Sequence |
>1328 MSKLRALRFALLTAVSVHAAVHQGLDELDAEQDFDFIVVGGGIGGSVVASRLSENPDFNVLLVEAGPDNDGVLDI AVPGYTDRINSTYDWRFRTEPQIGLNNRTFSYDRGHVLGGSSSVNSMIYTRGAAEDYDRWAEVTGDSGWTWDALF PLIKRHEKFVPPPGGRNVTGQYNPDVHGYEGNSLVSLPWSEPTEFDKLCLKNAEAQKDEFPFNIDQNSGSPVGLT YGIVAWMQSTIGNGERSSAATAYLGNDVRARPNLSILLNTYATRAIPVAHSGEGLDIRTIELAPRRGAGSSVTLT ARKELILTAGAFGTPHILLNSGIGDREELADVGVETIHHLPDVGKDLHDHVFASVMWTNRIPAPRPVSPAQALAE WQANRTGPLTEAAGAGHQVLWSRIPSDSPIFEEHDDPASGVNAPHIETFLAPSANFLMSGVVLLTPYSRGTIKLR SNDPFDPPRIDLALLTHPFDVLALKEGIRNTRRFFSGPVWEGYSLSTFTPNPDTVPADEYERYLRGAAGTFGHAV GTASMSAKGSDKGVLDPDLLVKGVSGLRVVDASAIPFVPAAHSQAAVYILAERAVDLIREAWN |
| Length | 588 |
Coding
| Sequence id | CC1G_01540T0 |
|---|---|
| Sequence |
>CC1G_01540T0 ATGTCGAAACTGAGAGCTCTACGCTTCGCCCTTTTGACCGCTGTATCTGTTCATGCAGCAGTCCATCAAGGACTC GACGAATTAGATGCAGAGCAGGACTTCGATTTCATCGTCGTAGGCGGTGGAATTGGCGGTTCTGTCGTCGCGAGT CGCTTGAGCGAAAATCCGGATTTCAATGTTCTCCTTGTGGAGGCGGGGCCTGATAACGATGGTGTCCTCGATATT GCCGTTCCAGGGTACACAGACCGAATTAACAGTACCTACGATTGGAGATTTAGGACGGAGCCGCAAATTGGTTTA AACAATCGCACTTTCTCCTACGACAGGGGACATGTCCTTGGAGGAAGTAGCTCTGTTAACAGCATGATTTACACC AGAGGTGCCGCCGAGGACTATGATCGGTGGGCAGAGGTCACCGGTGATAGCGGATGGACTTGGGACGCGTTGTTC CCCTTGATTAAACGGCACGAGAAGTTTGTCCCTCCGCCTGGAGGTCGCAACGTGACAGGACAGTACAACCCAGAC GTACATGGATACGAAGGAAACTCCTTGGTCAGCCTCCCATGGAGTGAGCCTACCGAGTTCGACAAACTTTGCTTG AAGAACGCAGAGGCTCAGAAGGATGAGTTCCCCTTCAACATTGATCAGAACTCCGGCTCCCCAGTTGGTCTCACT TATGGAATCGTAGCGTGGATGCAGTCGACTATTGGCAACGGCGAAAGAAGCAGCGCGGCGACCGCTTACCTCGGC AACGACGTCAGAGCGAGGCCTAACCTCTCTATTCTCCTTAACACGTACGCAACACGGGCCATTCCTGTCGCACAC TCGGGTGAAGGGCTAGACATACGAACAATCGAGTTAGCCCCGAGACGTGGAGCAGGATCCTCGGTAACCCTGACA GCACGCAAAGAGCTCATTCTCACAGCTGGTGCCTTCGGTACTCCTCACATCCTGCTTAACTCGGGTATCGGTGAC CGCGAAGAGCTCGCGGACGTCGGTGTTGAAACAATCCACCATCTACCTGATGTCGGGAAAGACCTGCATGACCAC GTCTTTGCATCTGTGATGTGGACAAATCGTATTCCAGCTCCACGACCGGTTTCTCCCGCCCAGGCACTTGCGGAA TGGCAAGCGAACAGGACGGGTCCTCTCACCGAGGCTGCCGGGGCTGGTCACCAGGTCCTCTGGTCACGCATTCCA TCAGACTCACCCATTTTCGAAGAGCATGACGATCCAGCCTCCGGTGTTAACGCACCCCATATCGAGACTTTCCTC GCGCCTTCTGCCAATTTCCTCATGAGTGGAGTGGTTCTCTTGACCCCATACTCACGAGGGACCATCAAGCTAAGG TCGAACGATCCTTTCGATCCTCCCCGCATCGACCTCGCACTGTTGACCCACCCATTCGACGTGCTCGCGCTGAAG GAAGGTATCCGGAACACCCGTCGATTCTTCAGTGGTCCCGTTTGGGAGGGCTACAGTCTCAGTACATTCACTCCC AATCCTGACACGGTTCCTGCCGATGAGTATGAGAGGTATCTCCGGGGTGCTGCAGGAACATTCGGGCACGCAGTT GGCACAGCGTCCATGTCTGCGAAGGGCTCGGACAAGGGTGTACTGGATCCTGACCTTCTTGTCAAAGGTGTCTCT GGACTGCGTGTGGTCGACGCTTCTGCGATCCCCTTTGTACCAGCGGCGCACAGCCAGGCTGCCGTTTACATTCTA GCTGAGCGAGCAGTAGATCTTATTCGGGAGGCTTGGAAC |
| Length | 1767 |
Transcript
| Sequence id | CC1G_01540T0 |
|---|---|
| Sequence |
>CC1G_01540T0 ATGTCGAAACTGAGAGCTCTACGCTTCGCCCTTTTGACCGCTGTATCTGTTCATGCAGCAGTCCATCAAGGACTC GACGAATTAGATGCAGAGCAGGACTTCGATTTCATCGTCGTAGGCGGTGGAATTGGCGGTTCTGTCGTCGCGAGT CGCTTGAGCGAAAATCCGGATTTCAATGTTCTCCTTGTGGAGGCGGGGCCTGATAACGATGGTGTCCTCGATATT GCCGTTCCAGGGTACACAGACCGAATTAACAGTACCTACGATTGGAGATTTAGGACGGAGCCGCAAATTGGTTTA AACAATCGCACTTTCTCCTACGACAGGGGACATGTCCTTGGAGGAAGTAGCTCTGTTAACAGCATGATTTACACC AGAGGTGCCGCCGAGGACTATGATCGGTGGGCAGAGGTCACCGGTGATAGCGGATGGACTTGGGACGCGTTGTTC CCCTTGATTAAACGGCACGAGAAGTTTGTCCCTCCGCCTGGAGGTCGCAACGTGACAGGACAGTACAACCCAGAC GTACATGGATACGAAGGAAACTCCTTGGTCAGCCTCCCATGGAGTGAGCCTACCGAGTTCGACAAACTTTGCTTG AAGAACGCAGAGGCTCAGAAGGATGAGTTCCCCTTCAACATTGATCAGAACTCCGGCTCCCCAGTTGGTCTCACT TATGGAATCGTAGCGTGGATGCAGTCGACTATTGGCAACGGCGAAAGAAGCAGCGCGGCGACCGCTTACCTCGGC AACGACGTCAGAGCGAGGCCTAACCTCTCTATTCTCCTTAACACGTACGCAACACGGGCCATTCCTGTCGCACAC TCGGGTGAAGGGCTAGACATACGAACAATCGAGTTAGCCCCGAGACGTGGAGCAGGATCCTCGGTAACCCTGACA GCACGCAAAGAGCTCATTCTCACAGCTGGTGCCTTCGGTACTCCTCACATCCTGCTTAACTCGGGTATCGGTGAC CGCGAAGAGCTCGCGGACGTCGGTGTTGAAACAATCCACCATCTACCTGATGTCGGGAAAGACCTGCATGACCAC GTCTTTGCATCTGTGATGTGGACAAATCGTATTCCAGCTCCACGACCGGTTTCTCCCGCCCAGGCACTTGCGGAA TGGCAAGCGAACAGGACGGGTCCTCTCACCGAGGCTGCCGGGGCTGGTCACCAGGTCCTCTGGTCACGCATTCCA TCAGACTCACCCATTTTCGAAGAGCATGACGATCCAGCCTCCGGTGTTAACGCACCCCATATCGAGACTTTCCTC GCGCCTTCTGCCAATTTCCTCATGAGTGGAGTGGTTCTCTTGACCCCATACTCACGAGGGACCATCAAGCTAAGG TCGAACGATCCTTTCGATCCTCCCCGCATCGACCTCGCACTGTTGACCCACCCATTCGACGTGCTCGCGCTGAAG GAAGGTATCCGGAACACCCGTCGATTCTTCAGTGGTCCCGTTTGGGAGGGCTACAGTCTCAGTACATTCACTCCC AATCCTGACACGGTTCCTGCCGATGAGTATGAGAGGTATCTCCGGGGTGCTGCAGGAACATTCGGGCACGCAGTT GGCACAGCGTCCATGTCTGCGAAGGGCTCGGACAAGGGTGTACTGGATCCTGACCTTCTTGTCAAAGGTGTCTCT GGACTGCGTGTGGTCGACGCTTCTGCGATCCCCTTTGTACCAGCGGCGCACAGCCAGGCTGCCGTTTACATTCTA GCTGAGCGAGCAGTAGATCTTATTCGGGAGGCTTGGAACTGA |
| Length | 1767 |
Gene
| Sequence id | CC1G_01540T0 |
|---|---|
| Sequence |
>CC1G_01540T0 ATGTCGAAACTGAGAGCTCTACGCTTCGCCCTTTTGACCGCTGTATCTGTTCATGCAGCAGTCCATCAAGGACTC GACGAATTAGATGCAGAGCAGGACTTCGATTTCATCGTCGTAGGCGGTAAGTTGCATCTTCACCTTTAAAGGTAG CTACTTACATCATAGCTCAGGTGGAATTGGCGGTTCTGTCGTCGCGAGTCGCTTGAGCGAAAATCCGGATTTCAA TGTTCTCCTTGTGGAGGCGGGGCCTGAGTACGTCCACCAACACCCCAGCACCCTCTGAGAGCCTGACCACTATTT TCAGTAACGATGGTGTCCTCGATATTGCCGTTCCAGGGTACACAGACCGAATTAACAGTACCTACGATTGGAGAT TTAGGACGGAGCCGCAAATTGGTTTAAACAATCGCACTTTCTCCTACGACAGGGGACATGTCCTTGGAGGAAGTA GCTCTGTTAGTAAGTCATTTCGTTCCAATCTTGCCAATCTCTTAGTCACAGTCTGTAGACAGCATGATTTACACC AGAGGTGCCGCCGAGGACTATGATCGGTGGGCAGAGGTCACCGGTGATAGCGGATGGACTTGGGACGCGTTGTTC CCCTTGATTAAACGGGTGAGTAGCCCATGCATCCGTACTATTTCTCCTCCTTCACTCATAGTCGATTGTAGCACG AGAAGTTTGTCCCTCCGCCTGGAGGTCGCAACGTGACAGGACAGTACAACCCAGACGTACATGGATACGAAGGAA ACTCCTTGGTCAGCCTCCCATGGAGTGAGCCTACCGAGTTCGACAAACTTTGCTTGAAGAACGCAGAGGCTCAGA AGGATGAGTTCCCCTTCAACATTGATCAGAACTCCGGCTCCCCAGTTGGTCTCAGTATGTCTACCGAATTTTCGT ATGCTTCCTTTCAGTAGCTTATGGAATCGTAGCGTGGATGCAGTCGACTATTGGCAACGGCGAAAGAAGCAGCGC GGCGACCGCTTACCTCGGCAACGACGTCAGAGCGAGGCCTAACCTCTCTATTCTCCTTAACACGTACGCAACACG GGCCATTCCTGTCGCACACTCGGGTGAAGGGCTAGACATACGAACAATCGAGTTAGCCCCGAGACGTGGAGGTAC GGTTATTGCGTTTCATCATTATGTACCTCTGTTGACTGGCTTCGTGTAGCAGGATCCTCGGTAACCCTGACAGCA CGCAAAGAGCTCATTCTCACAGCTGGTGCCTTCGGTACTCCTCACATCCTGCTTAACTCGGGTATCGGTGACCGC GAAGAGCTCGCGGACGTCGGTGTTGAAACAATCCACCATCTACCTGATGTCGGGAAAGACCTGCATGACCACGTC TTTGCATCTGTGATGTGGACAAATCGTATTCCAGCTCCACGACCGTCAGTTCTATCGACTGCTGTTGTATAGGGT TCAGAGACTTAGGTCATTTATAGGGTTTCTCCCGCCCAGGCACTTGCGGAATGGCAAGCGAACAGGACGGGTCCT CTCACCGAGGCTGCCGGGGCTGGTCACCAGGTCCTCTGGTCACGCATTCCATCAGACTCACCCATTTTCGAAGAG CATGACGATCCAGCCTCCGGTGTTAACGCACCCCATATCGAGACTTTCCTCGCGGTAAGCGTCCATCTTTGCCTT TTCAAAGACCTGGACTAAAGTTGGCACAAGCCTTCTGCCAATTTCCTCATGAGTGGAGTGGTTCTCTTGACCCCA TACTCACGTACGTCGATCTGTCACCACCCTCCCATACTATACTCACTCACTCGGTCTGACATCGTCTACAGGAGG GACCATCAAGCTAAGGTCGAACGATCCTTTCGATCCTCCCCGCATCGACCTCGCACTGTTGACCCACCCATTCGA CGTGCTCGCGCTGAAGGAAGGTATCCGGAACACCCGTCGATTCTTCAGTGGTCCCGTTTGGGAGGGCTACAGTCT CAGTACATTCACTCCCAATCCTGACACGGTTCCTGCCGATGAGTATGAGAGGTATCTCCGGGGTGCTGCAGGAAC ATTCGGGCACGCAGTTGGCACAGCGTCCATGTCTGCGAAGGGCTCGGACAAGGGTGTACTGGATCCTGACCTTCT TGTCAAAGGTGTCTCTGGACTGCGTGTGGTCGACGCTTCTGCGATCGTAAGTACTCAAATGATCATCCTCGACCC TCGTCCTGACTCGTCCCTAGCCCTTTGTACCAGCGGCGCACAGCCAGGCTGCCGTTTACATTCTAGCTGAGCGAG CAGTAGATCTTATTCGGGAGGCTTGGAACTGA |
| Length | 2282 |