CC1G_03033
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_03033 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NS59 | Functional description | Other/TTK protein kinase |
| Location | Chr_8:1605368..1608766 | Strand | - |
| Gene length (nt) | 3399 | Transcript length (nt) | 3018 |
| CDS length (nt) | 3018 | Protein length (aa) | 1005 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7261490 | 57.5 | 0 | 1051 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB17945 | 50.7 | 1.891E-278 | 878 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_23002 | 47.1 | 1.067E-238 | 762 |
| Lentinula edodes B17 | Lened_B_1_1_8718 | 53.2 | 1.31E-205 | 665 |
| Flammulina velutipes | Flave_chr05AA00444 | 42.7 | 1.804E-202 | 656 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_59067 | 61.6 | 3.446E-186 | 608 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_224326 | 61.6 | 7.239E-186 | 607 |
| Schizophyllum commune H4-8 | Schco3_2615147 | 51 | 5.319E-167 | 552 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_127850 | 62.7 | 2.049E-166 | 550 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1481621 | 70.4 | 3.804E-150 | 502 |
| Lentinula edodes NBRC 111202 | Lenedo1_1050818 | 70.2 | 1.831E-148 | 497 |
| Pleurotus ostreatus PC15 | PleosPC15_2_32199 | 73.5 | 8.969E-139 | 468 |
| Auricularia subglabra | Aurde3_1_1213330 | 33.2 | 3.946E-133 | 452 |
| Pleurotus ostreatus PC9 | PleosPC9_1_87255 | 72.7 | 2.167E-125 | 428 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 2623 |
| Description | Other/TTK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd14131 | PKc_Mps1 | IPR027084 | 640 | 936 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 642 | 936 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR027084 | Protein kinase Mps1 family, catalytic domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR017441 | Protein kinase, ATP binding site |
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K08866 |
EggNOG
| COG category | Description |
|---|---|
| D | Belongs to the protein kinase superfamily |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
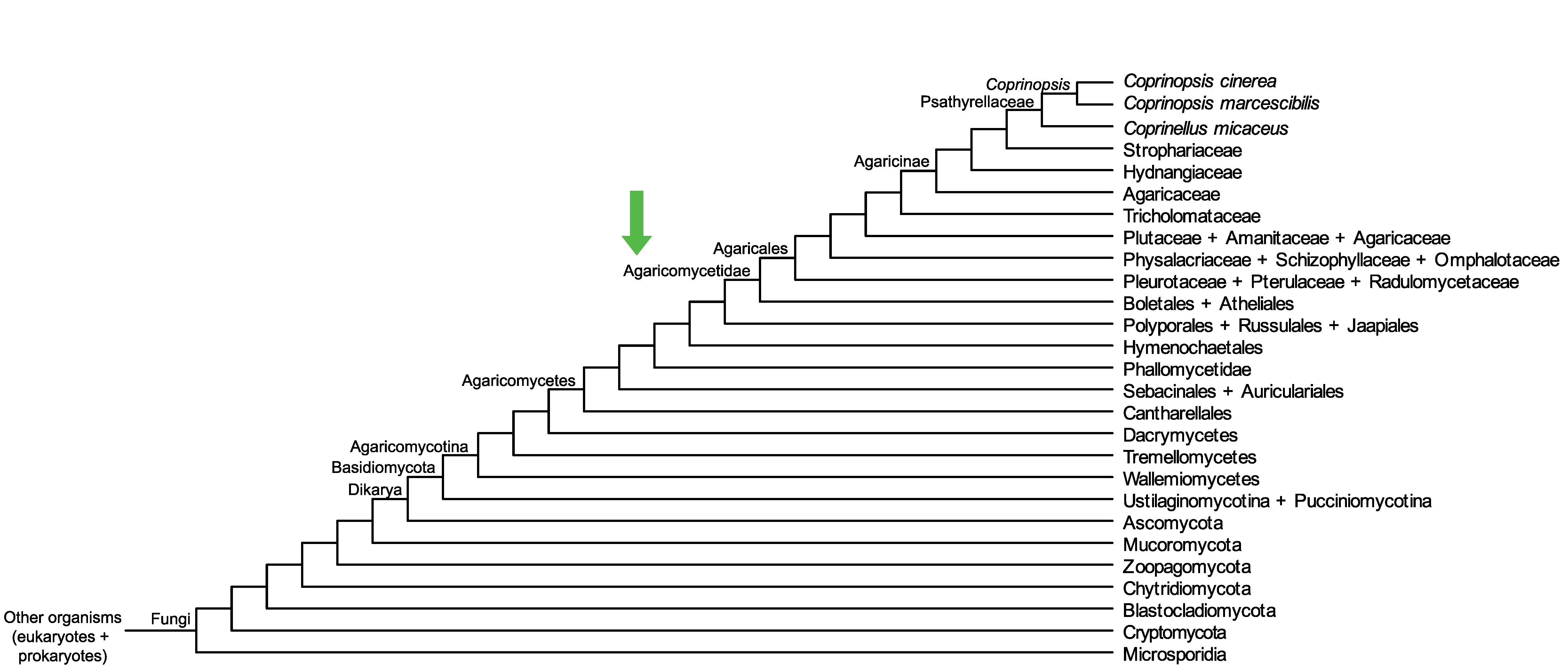
Conservation of CC1G_03033 across fungi.
Arrow shows the origin of gene family containing CC1G_03033.
Protein
| Sequence id | 2623 |
|---|---|
| Sequence |
>2623 MSTSPSISPPRTPNDNRPTASTSNSPSSDDSSIIDDLSFDYVYDDNGNVVRLSRKSNSTSPPTDQESLPDSALDN DSPAGSPLNRQSLSRSESAQSILQGTSAAATDPKPARPFQRVASTPSYLLPTAAATSRAAVTRGGPRRIIEDSHN RERQEPIVRSRQTFDYATRDSYAHQEEKENILAEMDERPQLVNRRNSPPLIARSTASRFSSARISYSTIGGSLNG RPLADVPVQRTARQPPTGLTRPGRLMKSSLTSLKYSTSNQDRLSDVVESSDYEHKQQGLPEPNPYAPPASDTEPE DEPLEPSAIPLRSSLNPRQRKELNINAQAASLAQSGSNRPRRSASLSDALYPHDDYQLQVAAPPTHGHSRPGTSL GLNAESGPRRVYPEERERQELEAHKKLRREHEDDRQSPSPTHGHPQHQRLVANGHRRRDSDTLRGLAPPNSAGTV GSPTVMDMPNGRPSPTGHRFPHGRSSPAATVRGRQSPQTVKGRVSPPATKGRVSPANAGNRLGVSRDAGKHRRSP TAPEPPTTSGQIGGHEQPPGSKTWGGSEREDEFDPASSGEKDREKERERQLEAQRERRERREQQQQQQPPPQPPP QQLQPYAQVPQAIAQPAAPAPQPPIPAPNQLNRHIVVNKKAYARIDIIGKGGSSRVFRVLNHANELYAIKRVSLD KTDAETMSGYMNEIALLKRLEGNSRIIRLIDSEVKPGPGGSKGHLLLVMECGEIDLAKLLQEQMKEPLNMVWVSY YWQQMLQAVHVIHEEKIVHSDLKPANFVLVKGQLKLIDFGIANAIANDTTNIQRDHQIGTVNYMSPEAIELPDGM RRLKVGRPSDVWSLGIILYQMVYGHPPFQHLSVYQKMKAIPDLSHVIEYPEYTVPSIPAKTSSNGTVEPPKRLEH LKRRVRADVIRGIKSCLCRNPKERATIPELLEQPWLGLTGNEPEPVRPRIEDMLGEKETLINPYYMAQLMQYCVK LAREDKPMDAETLQKDAEVRELVVPMLADN |
| Length | 1005 |
Coding
| Sequence id | CC1G_03033T0 |
|---|---|
| Sequence |
>CC1G_03033T0 ATGTCCACTTCGCCCTCAATTTCCCCGCCTCGCACACCAAACGACAACCGGCCTACCGCTTCAACCTCAAACTCC CCAAGTTCAGATGATTCTTCAATAATTGACGACCTTTCTTTCGACTATGTCTACGACGACAATGGCAACGTCGTC CGTCTGTCCAGAAAATCAAACTCGACATCTCCCCCAACCGACCAAGAAAGTTTGCCAGATTCAGCCCTCGACAAC GACAGTCCTGCAGGCTCACCTCTCAACCGCCAATCACTATCTCGCTCGGAAAGCGCCCAGTCAATACTTCAGGGT ACATCCGCAGCGGCTACCGACCCAAAACCTGCAAGACCCTTTCAACGCGTCGCGTCAACCCCATCGTATCTTCTT CCAACAGCTGCAGCGACCAGTCGAGCAGCTGTAACGCGCGGAGGTCCTCGCCGTATTATTGAAGACAGTCATAAT CGGGAACGACAGGAGCCAATCGTCCGATCGAGGCAAACTTTTGACTATGCCACGCGCGATTCATACGCGCACCAA GAGGAGAAAGAGAATATCCTCGCTGAGATGGACGAAAGGCCTCAACTCGTCAACAGACGGAATTCCCCTCCACTT ATCGCCCGCTCCACAGCTTCACGGTTCTCCTCGGCACGGATATCGTACTCGACTATCGGTGGAAGTCTCAATGGT CGCCCTTTAGCTGACGTCCCCGTTCAGCGGACCGCACGGCAGCCACCGACCGGTCTAACGCGACCTGGTCGCCTC ATGAAATCGTCGTTGACCTCGCTCAAATACAGCACGTCCAACCAAGACCGCTTGAGCGACGTGGTCGAGAGTTCC GATTATGAGCACAAGCAACAAGGCCTACCCGAACCAAATCCCTACGCGCCGCCTGCTTCCGATACGGAGCCGGAG GACGAGCCTCTGGAACCTTCCGCCATTCCCCTTCGCTCTTCGCTCAACCCACGGCAACGCAAAGAACTCAACATC AATGCCCAAGCTGCAAGCCTGGCTCAATCTGGCAGCAACCGTCCAAGGAGATCAGCTAGTCTCAGTGATGCACTA TACCCCCACGACGACTACCAACTCCAAGTGGCCGCTCCACCTACACACGGACATTCCCGCCCAGGGACCAGCCTT GGTTTGAACGCCGAATCAGGTCCAAGGCGCGTCTATCCTGAGGAGAGAGAACGACAGGAATTAGAGGCCCACAAG AAACTCCGCAGAGAACACGAGGACGATCGACAATCACCCTCACCAACACACGGCCATCCCCAACATCAAAGGCTT GTCGCCAATGGCCATCGTAGACGCGACTCGGATACGCTTCGTGGTTTGGCTCCTCCCAATTCTGCAGGCACTGTT GGATCCCCTACCGTGATGGATATGCCCAATGGTCGACCATCGCCCACGGGGCATCGTTTCCCCCATGGGCGCTCG TCTCCAGCAGCAACCGTTCGTGGAAGACAGTCTCCCCAAACAGTCAAAGGACGCGTCTCTCCGCCAGCCACCAAA GGTCGCGTGTCCCCCGCCAATGCCGGTAATCGCCTAGGTGTCAGTAGGGATGCGGGAAAGCATCGTCGCAGCCCG ACCGCCCCCGAACCTCCAACGACGAGTGGCCAAATCGGTGGCCATGAACAACCGCCTGGTTCCAAGACATGGGGT GGCAGTGAGCGCGAGGACGAGTTTGATCCTGCCAGCTCCGGGGAGAAGGATCGGGAAAAGGAGCGGGAACGGCAA TTGGAAGCCCAACGGGAGAGGAGGGAGCGCAGGGAACAACAGCAGCAGCAGCAACCACCCCCTCAACCTCCACCA CAACAACTCCAACCCTACGCACAAGTGCCTCAGGCTATTGCCCAGCCCGCTGCACCTGCACCACAACCACCGATA CCGGCTCCCAATCAGCTCAACCGTCACATTGTGGTCAACAAAAAGGCTTACGCTCGCATTGACATCATTGGCAAG GGAGGGTCGTCACGCGTATTCCGGGTTTTGAACCACGCCAACGAACTATACGCGATTAAACGCGTCTCTCTGGAC AAGACGGATGCTGAGACGATGAGTGGCTACATGAACGAAATCGCACTTCTCAAGCGACTCGAAGGCAATAGCCGT ATCATTCGGTTGATCGACAGCGAAGTCAAACCTGGTCCTGGGGGAAGCAAGGGGCATCTACTGTTGGTGATGGAG TGCGGCGAGATCGATTTGGCCAAGCTTCTCCAGGAACAGATGAAGGAGCCATTGAACATGGTTTGGGTTTCGTAC TACTGGCAACAGATGCTGCAAGCCGTCCATGTCATTCACGAAGAGAAGATTGTTCATTCCGACTTGAAGCCTGCA AACTTTGTGTTGGTCAAAGGCCAGCTCAAGTTGATTGACTTTGGTATCGCGAACGCGATTGCGAATGACACTACC AATATTCAACGTGACCACCAGATCGGTACGGTCAACTACATGAGTCCCGAAGCTATAGAGCTTCCAGACGGTATG CGTCGACTGAAGGTCGGCCGTCCGTCTGACGTTTGGTCGTTGGGTATCATCTTGTACCAGATGGTGTACGGACAC CCACCCTTCCAACATCTTTCCGTGTATCAGAAGATGAAGGCTATTCCCGACCTCAGCCATGTCATCGAATATCCC GAATACACAGTCCCATCGATCCCAGCCAAGACCAGCAGCAATGGAACCGTGGAACCTCCCAAACGACTGGAGCAC CTCAAGCGACGCGTGCGAGCAGACGTGATCAGGGGCATCAAGAGTTGTCTTTGCCGCAACCCCAAGGAGCGCGCG ACGATCCCCGAGTTGTTGGAGCAGCCTTGGCTGGGTTTGACCGGTAATGAACCTGAACCTGTGCGTCCCAGGATT GAAGATATGCTAGGCGAAAAGGAGACTTTGATCAATCCATACTACATGGCTCAGCTCATGCAGTATTGTGTCAAG CTCGCCCGGGAAGACAAGCCAATGGACGCCGAAACTTTGCAGAAGGATGCCGAGGTTCGTGAACTCGTTGTGCCA ATGCTAGCCGACAAC |
| Length | 3018 |
Transcript
| Sequence id | CC1G_03033T0 |
|---|---|
| Sequence |
>CC1G_03033T0 ATGTCCACTTCGCCCTCAATTTCCCCGCCTCGCACACCAAACGACAACCGGCCTACCGCTTCAACCTCAAACTCC CCAAGTTCAGATGATTCTTCAATAATTGACGACCTTTCTTTCGACTATGTCTACGACGACAATGGCAACGTCGTC CGTCTGTCCAGAAAATCAAACTCGACATCTCCCCCAACCGACCAAGAAAGTTTGCCAGATTCAGCCCTCGACAAC GACAGTCCTGCAGGCTCACCTCTCAACCGCCAATCACTATCTCGCTCGGAAAGCGCCCAGTCAATACTTCAGGGT ACATCCGCAGCGGCTACCGACCCAAAACCTGCAAGACCCTTTCAACGCGTCGCGTCAACCCCATCGTATCTTCTT CCAACAGCTGCAGCGACCAGTCGAGCAGCTGTAACGCGCGGAGGTCCTCGCCGTATTATTGAAGACAGTCATAAT CGGGAACGACAGGAGCCAATCGTCCGATCGAGGCAAACTTTTGACTATGCCACGCGCGATTCATACGCGCACCAA GAGGAGAAAGAGAATATCCTCGCTGAGATGGACGAAAGGCCTCAACTCGTCAACAGACGGAATTCCCCTCCACTT ATCGCCCGCTCCACAGCTTCACGGTTCTCCTCGGCACGGATATCGTACTCGACTATCGGTGGAAGTCTCAATGGT CGCCCTTTAGCTGACGTCCCCGTTCAGCGGACCGCACGGCAGCCACCGACCGGTCTAACGCGACCTGGTCGCCTC ATGAAATCGTCGTTGACCTCGCTCAAATACAGCACGTCCAACCAAGACCGCTTGAGCGACGTGGTCGAGAGTTCC GATTATGAGCACAAGCAACAAGGCCTACCCGAACCAAATCCCTACGCGCCGCCTGCTTCCGATACGGAGCCGGAG GACGAGCCTCTGGAACCTTCCGCCATTCCCCTTCGCTCTTCGCTCAACCCACGGCAACGCAAAGAACTCAACATC AATGCCCAAGCTGCAAGCCTGGCTCAATCTGGCAGCAACCGTCCAAGGAGATCAGCTAGTCTCAGTGATGCACTA TACCCCCACGACGACTACCAACTCCAAGTGGCCGCTCCACCTACACACGGACATTCCCGCCCAGGGACCAGCCTT GGTTTGAACGCCGAATCAGGTCCAAGGCGCGTCTATCCTGAGGAGAGAGAACGACAGGAATTAGAGGCCCACAAG AAACTCCGCAGAGAACACGAGGACGATCGACAATCACCCTCACCAACACACGGCCATCCCCAACATCAAAGGCTT GTCGCCAATGGCCATCGTAGACGCGACTCGGATACGCTTCGTGGTTTGGCTCCTCCCAATTCTGCAGGCACTGTT GGATCCCCTACCGTGATGGATATGCCCAATGGTCGACCATCGCCCACGGGGCATCGTTTCCCCCATGGGCGCTCG TCTCCAGCAGCAACCGTTCGTGGAAGACAGTCTCCCCAAACAGTCAAAGGACGCGTCTCTCCGCCAGCCACCAAA GGTCGCGTGTCCCCCGCCAATGCCGGTAATCGCCTAGGTGTCAGTAGGGATGCGGGAAAGCATCGTCGCAGCCCG ACCGCCCCCGAACCTCCAACGACGAGTGGCCAAATCGGTGGCCATGAACAACCGCCTGGTTCCAAGACATGGGGT GGCAGTGAGCGCGAGGACGAGTTTGATCCTGCCAGCTCCGGGGAGAAGGATCGGGAAAAGGAGCGGGAACGGCAA TTGGAAGCCCAACGGGAGAGGAGGGAGCGCAGGGAACAACAGCAGCAGCAGCAACCACCCCCTCAACCTCCACCA CAACAACTCCAACCCTACGCACAAGTGCCTCAGGCTATTGCCCAGCCCGCTGCACCTGCACCACAACCACCGATA CCGGCTCCCAATCAGCTCAACCGTCACATTGTGGTCAACAAAAAGGCTTACGCTCGCATTGACATCATTGGCAAG GGAGGGTCGTCACGCGTATTCCGGGTTTTGAACCACGCCAACGAACTATACGCGATTAAACGCGTCTCTCTGGAC AAGACGGATGCTGAGACGATGAGTGGCTACATGAACGAAATCGCACTTCTCAAGCGACTCGAAGGCAATAGCCGT ATCATTCGGTTGATCGACAGCGAAGTCAAACCTGGTCCTGGGGGAAGCAAGGGGCATCTACTGTTGGTGATGGAG TGCGGCGAGATCGATTTGGCCAAGCTTCTCCAGGAACAGATGAAGGAGCCATTGAACATGGTTTGGGTTTCGTAC TACTGGCAACAGATGCTGCAAGCCGTCCATGTCATTCACGAAGAGAAGATTGTTCATTCCGACTTGAAGCCTGCA AACTTTGTGTTGGTCAAAGGCCAGCTCAAGTTGATTGACTTTGGTATCGCGAACGCGATTGCGAATGACACTACC AATATTCAACGTGACCACCAGATCGGTACGGTCAACTACATGAGTCCCGAAGCTATAGAGCTTCCAGACGGTATG CGTCGACTGAAGGTCGGCCGTCCGTCTGACGTTTGGTCGTTGGGTATCATCTTGTACCAGATGGTGTACGGACAC CCACCCTTCCAACATCTTTCCGTGTATCAGAAGATGAAGGCTATTCCCGACCTCAGCCATGTCATCGAATATCCC GAATACACAGTCCCATCGATCCCAGCCAAGACCAGCAGCAATGGAACCGTGGAACCTCCCAAACGACTGGAGCAC CTCAAGCGACGCGTGCGAGCAGACGTGATCAGGGGCATCAAGAGTTGTCTTTGCCGCAACCCCAAGGAGCGCGCG ACGATCCCCGAGTTGTTGGAGCAGCCTTGGCTGGGTTTGACCGGTAATGAACCTGAACCTGTGCGTCCCAGGATT GAAGATATGCTAGGCGAAAAGGAGACTTTGATCAATCCATACTACATGGCTCAGCTCATGCAGTATTGTGTCAAG CTCGCCCGGGAAGACAAGCCAATGGACGCCGAAACTTTGCAGAAGGATGCCGAGGTTCGTGAACTCGTTGTGCCA ATGCTAGCCGACAACTGA |
| Length | 3018 |
Gene
| Sequence id | CC1G_03033T0 |
|---|---|
| Sequence |
>CC1G_03033T0 ATGTCCACTTCGCCCTCAATTTCCCCGCCTCGCACACCAAACGACAACCGGCCTACCGCTTCAACCTCAAACTCC CCAAGTTCAGATGATTCTTCAATAATTGACGACCTTTCTTTCGACTATGTCTACGACGACAATGGCAACGTCGTC CGTCTGTCCAGAAAATCAAACTCGACATCTCCCCCAACCGACCAAGAAAGTTTGCCAGATTCAGCCCTCGACAAC GACAGTCCTGCAGGCTCACCTCTCAACCGCCAATCACTATCTCGCTCGGAAAGCGCCCAGTCAATACTTCAGGGT ACATCCGCAGCGGCTACCGACCCAAAACCTGCAAGACCCTTTCAACGCGTCGCGTCAACCCCATCGTATCTTCTT CCAACAGCTGCAGCGACCAGTCGAGCAGCTGTAACGCGCGGAGGTCCTCGCCGTATTATTGAAGACAGTCATAAT CGGGAACGACAGGAGCCAATCGTCCGATCGAGGCAAACTTTTGACTATGCCACGCGCGATTCATACGCGCACCAA GAGGAGAAAGAGAATATCCTCGCTGAGATGGACGAAAGGCCTCAACTCGTCAACAGACGGAATTCCCCTCCACTT ATCGCCCGCTCCACAGCTTCACGGTTCTCCTCGGCACGGATATCGTACTCGACTATCGGTGGAAGTCTCAATGGT CGCCCTTTAGCTGACGTCCCCGTTCAGCGGACCGCACGGCAGCCACCGACCGGTCTAACGCGACCTGGTCGCCTC ATGAAATCGTCGTTGACCTCGCTCAAATACAGCACGTCCAACCAAGACCGCTTGAGCGACGTGGTCGAGAGTTCC GATTATGAGCACAAGCAACAAGGCCTACCCGAACCAAATCCCTACGCGCCGCCTGCTTCCGATACGGAGCCGGAG GACGAGCCTCTGGAACCTTCCGCCATTCCCCTTCGCTCTTCGCTCAACCCACGGCAACGCAAAGAACTCAACATC AATGCCCAAGCTGCAAGCCTGGCTCAATCTGGCAGCAACCGTCCAAGGAGATCAGCTAGTCTCAGTGATGCACTA TGTATGTTGTTCACGCTTCTGTTCAACCGTGATATTTGTTGACCTTTCCTTTAGACCCCCACGACGACTACCAAC TCCAAGTGGCCGCTCCACCTACACACGGACATTCCCGCCCAGGGACCAGCCTTGGTACGTGACCGTCCAGCTTCT TTGTGTAAGCACGCTTATTCCTTTGTGACAGGTTTGAACGCCGAATCAGGTCCAAGGCGCGTCTATCCTGAGGAG AGAGAACGACAGGAATTAGAGGCCCACAAGAGTATGTGCAGTTCAACTTCTCACGCGTGTCTCTTGTACTTACAG CACCTTTCACATTTCAGAACTCCGCAGAGAACACGAGGACGATCGACAATCACCCTCACCAACACACGGCCATCC CCAACATCAAAGGCTTGTCGCCAATGGCCATCGTAGACGCGACTCGGATACGCTTCGTGGTTTGGCTCCTCCCAA TTCTGCAGGCACTGTTGGATCCCCTACCGTGATGGATATGCCCAATGGTCGACCATCGCCCACGGGGCATCGTTT CCCCCATGGGCGCTCGTCTCCAGCAGCAACCGTTCGTGGAAGACAGTCTCCCCAAACAGTCAAAGGACGCGTCTC TCCGCCAGCCACCAAAGGTCGCGTGTCCCCCGCCAATGCCGGTAATCGCCTAGGTGTCAGTAGGGATGCGGGAAA GCATCGTCGCAGCCCGACCGCCCCCGAACCTCCAACGACGAGTGGCCAAATCGGTGGCCATGAACAACCGCCTGG TTCCAAGACATGGGGTGGCAGTGAGCGCGAGGACGAGTTTGATCCTGCCAGCTCCGGGGAGAAGGATCGGGAAAA GGAGCGGGAACGGCAATTGGAAGCCCAACGGGAGAGGAGGGAGCGCAGGGAACAACAGCAGCAGCAGCAACCACC CCCTCAACCTCCACCACAACAACTCCAACCCTACGCACAAGTGCCTCAGGCTATTGCCCAGCCCGCTGCACCTGC ACCACAACCACCGATACCGGCTCCCAATCAGCTCAACCGTCACATTGTGGTATGTCTACACAATCTAGTCTTCAA TTTTCCGCGCTAATTTAATTCTTAGGTCAACAAAAAGGCTTACGCTCGCATTGACATCATTGGCAAGGGAGGGTC GTCACGCGTATTCCGGGTTTTGAACCACGCCAACGAACTATACGCGATTAAACGCGTCTCTCTGGACAAGACGGA TGCTGAGACGATGAGTGGCTACATGAACGAAATCGCACTTCTCAAGCGACTCGAAGGCAATAGCCGTATCATTCG GTTGATCGACAGCGAAGTCAAACCTGGTCCTGGGGGAAGCAAGGGGCATCTACTGTTGGTGATGGAGTGCGGCGA GATCGATTTGGCCAAGCTTCTCCAGGAACAGATGAAGGAGCCATTGAACATGGTTTGGGTTTCGTACTACTGGCA ACAGGTACGTGTCAATCGTTCGGATGAAAAGTACATTGTCTGATACCTGTGGGCATTAGATGCTGCAAGCCGTCC ATGTCATTCACGAAGAGAAGATTGTTCATTCCGACTTGAAGCCTGCAAACTTTGTGTTGGTCAAAGGCCAGCTCA AGTTGATTGACTTTGGTATCGCGAACGCGATTGCGAATGACACTACCAATATTCAACGTGACCACCAGGTGTGTT ATACTAGTGTTGGTTCATTGCGGCATATACTGACGTTACTTGTAGATCGGTACGGTCAACTACATGAGTCCCGAA GCTATAGAGCTTCCAGACGGTATGCGTCGACTGAAGGTCGGCCGTCCGTCTGACGTTTGGTCGTTGGGTATCATC TTGTACCAGATGGTGTACGGACACCCACCCTTCCAACATCTTTCCGTGTATCAGAAGATGAAGGCTATTCCCGAC CTCAGCCATGTCATCGAATATCCCGAATACACAGTCCCATCGATCCCAGCCAAGACCAGCAGCAATGGAACCGTG GAACCTCCCAAACGACTGGAGCACCTCAAGCGACGCGTGCGAGCAGACGTGATCAGGGGCATCAAGAGTTGTCTT TGCCGCAACCCCAAGGAGCGCGCGACGATCCCCGAGTTGTTGGAGCAGCCTTGGCTGGGTTTGACCGGTAATGAA CCTGAACGTGAGATACCTTTTGATTCCGCTGAGTGAGAGTGGTACTAAATGAATTTCTCTCCAGCTGTGCGTCCC AGGATTGAAGATATGCTAGGCGAAAAGGAGACTTTGATCAATCCATACTACATGGCTCAGCTCATGCAGTATTGT GTCAAGCTCGCCCGGGAAGACAAGCCAATGGACGCCGAAACTTTGCAGAAGGATGCCGAGGTTCGTGAACTCGTT GTGCCAATGCTAGCCGACAACTGA |
| Length | 3399 |