CC1G_04899
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_04899 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8PFF9 | Functional description | CMGC/SRPK protein kinase |
| Location | Chr_2:3577035..3579573 | Strand | + |
| Gene length (nt) | 2539 | Transcript length (nt) | 2277 |
| CDS length (nt) | 2058 | Protein length (aa) | 685 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Neurospora crassa | NCU09202 |
| Saccharomyces cerevisiae | YMR216C_SKY1 |
| Schizosaccharomyces pombe | dsk1 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7261090 | 71.1 | 0 | 1003 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1448990 | 61.6 | 6.743E-302 | 929 |
| Pleurotus ostreatus PC15 | PleosPC15_2_172231 | 62 | 3.981E-291 | 915 |
| Pleurotus ostreatus PC9 | PleosPC9_1_90889 | 61.9 | 8.639E-297 | 914 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB19263 | 60.3 | 9.157E-291 | 897 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_217668 | 67.9 | 6.837E-289 | 891 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_54166 | 67.8 | 7.124E-289 | 891 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_123672 | 63.4 | 2.43E-285 | 881 |
| Schizophyllum commune H4-8 | Schco3_2645675 | 64.5 | 7.666E-274 | 848 |
| Flammulina velutipes | Flave_chr02AA00254 | 68 | 2.288E-248 | 774 |
| Lentinula edodes B17 | Lened_B_1_1_16948 | 60.5 | 1.012E-217 | 685 |
| Lentinula edodes NBRC 111202 | Lenedo1_1216814 | 60.5 | 1.279E-217 | 685 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_21363 | 60.5 | 1.27E-217 | 685 |
| Auricularia subglabra | Aurde3_1_1278856 | 58.3 | 2.844E-213 | 673 |
| Grifola frondosa | Grifr_OBZ75126 | 46.4 | 2.337E-198 | 629 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 4238 |
| Description | CMGC/SRPK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd14136 | STKc_SRPK | - | 31 | 541 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 123 | 203 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 375 | 541 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR017441 | Protein kinase, ATP binding site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K08832 |
EggNOG
| COG category | Description |
|---|---|
| T | CMGC SRPK protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
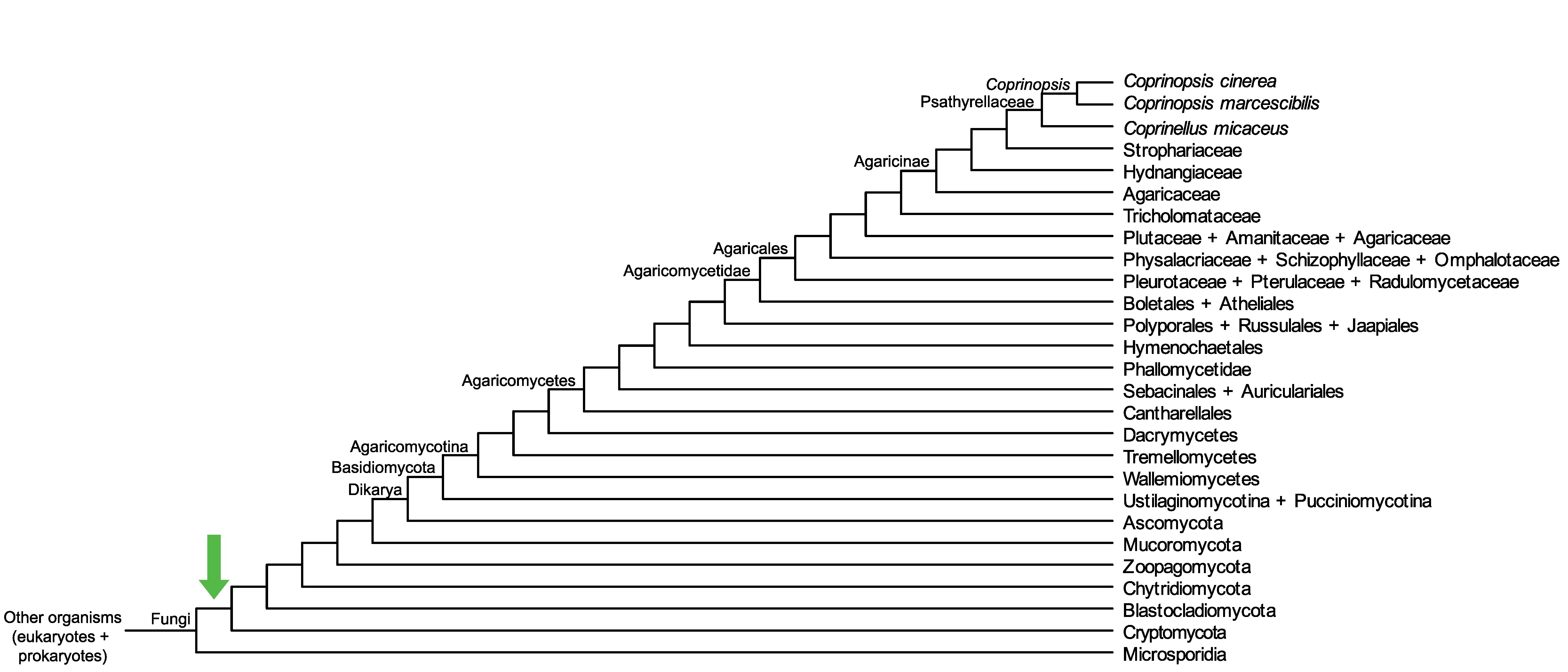
Conservation of CC1G_04899 across fungi.
Arrow shows the origin of gene family containing CC1G_04899.
Protein
| Sequence id | 4238 |
|---|---|
| Sequence |
>4238 MSHGSYSSYSASIMTEDEEDWEDYVKGGYHPVKIGDEFSDGRYVVVRKLGWGHFSTVWLARDTKMNRHVALKIVK SAPRYTETALDEIKLLQRLITSSTPPVAPTPENPNPPPSPSHTHPGKSHVIQFLDHFRHKGPNGTHVCMVFEVLG ENLLGLIKRHQSKGVPMHLVKQIAKQILLGLDYMHRCCGVIHTDLKPENVLICIDDVENVILAELEASSAAASTP PTRLVGVPPSKGRGGNQTPRSESVFITGSQPLPSPSSSFGTSPMLDKWAFGMSRIEGDDNSNGIVEKKGLSTVKR AVSTDLVAEVNNVSLETQASYVGRMPGAPGPSLLTDTKPVPIPGAPSPEPPADGAPRSVMSVDQRSDSSSAIDLS EKITVKIADLGNATWVEHHFTDDIQTRQYRCPEVILGAKWGTSADIWSVACVLFELITGGDYLFDPASGSRYSKD DDHIAQIMELLGELPRSIAFSGKYSSEFFNRKGELRHINKLRYWPLDSVLHDKYLFPKHEADALAAFLLPMLRLH PDRRAKASELIHHNWLEGTVVQGEIDVIKRAEAEEAARKKAKADQQRQASQKHKRDDSKLVQAGGMQLLDEDEAD AMKPIEAGAVVADGEAEGEQKDLKPVQQLQLQHQPPVLNPPPIPHGASGLTRTAPANVAKQVSPPPAANNRQPSA GKKTSKSGRS |
| Length | 685 |
Coding
| Sequence id | CC1G_04899T0 |
|---|---|
| Sequence |
>CC1G_04899T0 ATGTCTCACGGTTCCTATTCTTCATACTCTGCCTCCATCATGACTGAAGACGAAGAAGATTGGGAGGACTATGTC AAGGGAGGCTACCACCCAGTCAAGATTGGCGACGAGTTTTCCGATGGACGCTACGTCGTCGTCAGAAAGCTCGGT TGGGGTCACTTTTCCACTGTCTGGCTCGCCAGAGACACAAAGATGAATCGCCATGTTGCCCTCAAAATCGTGAAA TCAGCCCCGCGATATACAGAGACCGCCCTGGACGAAATCAAGCTCCTGCAGCGTCTGATCACGTCCTCGACTCCA CCCGTCGCGCCCACCCCAGAGAATCCAAATCCACCCCCGTCTCCCTCTCATACCCACCCCGGGAAATCGCACGTC ATTCAATTCCTGGATCACTTCCGACACAAGGGGCCCAATGGAACCCACGTCTGCATGGTTTTCGAGGTTCTGGGC GAGAACCTCCTTGGTCTCATTAAACGACACCAGAGCAAGGGCGTTCCGATGCATCTCGTTAAGCAAATCGCGAAA CAAATCCTCCTCGGTCTCGACTACATGCATCGCTGTTGCGGCGTCATCCACACAGATCTTAAGCCCGAGAACGTC CTCATCTGCATCGACGACGTCGAAAACGTCATCTTAGCCGAGCTTGAAGCCTCTTCTGCAGCAGCCAGCACGCCA CCCACGAGGCTAGTCGGTGTTCCTCCTTCGAAAGGACGTGGAGGCAACCAAACTCCAAGATCCGAATCCGTTTTC ATCACCGGCTCACAGCCCCTTCCCTCGCCTTCCTCATCCTTTGGCACGAGCCCAATGCTAGACAAATGGGCATTT GGTATGAGCAGGATTGAGGGAGACGACAACAGCAATGGCATCGTGGAGAAGAAGGGCCTGTCAACGGTGAAACGG GCTGTCTCGACGGATTTGGTCGCTGAAGTCAACAACGTCTCACTAGAAACCCAGGCTAGCTACGTTGGACGCATG CCTGGCGCGCCCGGACCTTCCCTGCTCACCGACACCAAACCTGTTCCTATTCCTGGCGCCCCATCCCCCGAACCT CCAGCAGACGGGGCCCCTCGCTCTGTGATGTCGGTCGATCAACGATCCGACTCTTCCAGTGCCATCGACTTGTCA GAGAAGATCACTGTTAAGATCGCGGATTTGGGAAATGCCACGTGGGTTGAGCATCACTTCACCGACGATATCCAA ACTCGACAATACCGCTGTCCCGAAGTCATCCTAGGCGCCAAGTGGGGCACTAGTGCAGATATTTGGAGTGTAGCT TGCGTGCTCTTCGAATTGATCACTGGCGGTGATTATCTATTTGATCCCGCCTCTGGTTCGAGGTACAGCAAGGAT GACGACCACATCGCTCAGATCATGGAGCTGCTCGGCGAGCTACCAAGGAGTATAGCCTTTTCCGGCAAATACTCT TCCGAATTCTTCAACCGGAAAGGTGAGCTACGGCACATCAACAAACTACGATATTGGCCTCTCGACTCTGTGCTG CACGACAAGTACCTGTTCCCTAAACACGAAGCCGACGCACTCGCGGCATTCCTCCTCCCGATGCTCCGCCTCCAC CCCGATCGACGCGCCAAAGCCTCCGAGTTGATCCACCACAACTGGCTCGAGGGTACCGTCGTACAAGGCGAGATC GACGTGATTAAGAGGGCTGAAGCGGAGGAAGCAGCGCGGAAGAAGGCGAAGGCCGATCAGCAGCGCCAGGCGTCG CAGAAACACAAGCGGGACGATTCAAAACTCGTCCAGGCGGGAGGGATGCAGCTGTTGGACGAGGACGAGGCGGAT GCGATGAAGCCTATCGAAGCTGGGGCTGTGGTGGCTGATGGAGAGGCCGAGGGTGAACAGAAGGATTTGAAACCG GTGCAGCAGTTGCAGTTGCAGCATCAGCCGCCAGTGTTGAACCCTCCTCCGATCCCGCATGGCGCGTCGGGGCTG ACGAGGACTGCGCCTGCGAATGTTGCGAAACAGGTTTCCCCTCCTCCTGCCGCGAATAATCGTCAGCCATCTGCT GGTAAGAAGACGTCCAAATCCGGCCGGAGT |
| Length | 2058 |
Transcript
| Sequence id | CC1G_04899T0 |
|---|---|
| Sequence |
>CC1G_04899T0 CGACGAGCTCGCCCGGTTCCACACCTTTTCGCACCTCTCGCCACCGGGGCCCACGGCGACCACACGACTAACGGC AACCAGCTGCGGATTTGGTCTCCAATTGGGTGGCTAAACTAGGCAACCAGGGCTTATCTTTGACCGCCTCCAGAT ACTCGACCCTTATCTCGGGAAGCCACAGGACAGCAACAGATTACGGATTGGTTAGAATTATCATAAACGATGTCT CACGGTTCCTATTCTTCATACTCTGCCTCCATCATGACTGAAGACGAAGAAGATTGGGAGGACTATGTCAAGGGA GGCTACCACCCAGTCAAGATTGGCGACGAGTTTTCCGATGGACGCTACGTCGTCGTCAGAAAGCTCGGTTGGGGT CACTTTTCCACTGTCTGGCTCGCCAGAGACACAAAGATGAATCGCCATGTTGCCCTCAAAATCGTGAAATCAGCC CCGCGATATACAGAGACCGCCCTGGACGAAATCAAGCTCCTGCAGCGTCTGATCACGTCCTCGACTCCACCCGTC GCGCCCACCCCAGAGAATCCAAATCCACCCCCGTCTCCCTCTCATACCCACCCCGGGAAATCGCACGTCATTCAA TTCCTGGATCACTTCCGACACAAGGGGCCCAATGGAACCCACGTCTGCATGGTTTTCGAGGTTCTGGGCGAGAAC CTCCTTGGTCTCATTAAACGACACCAGAGCAAGGGCGTTCCGATGCATCTCGTTAAGCAAATCGCGAAACAAATC CTCCTCGGTCTCGACTACATGCATCGCTGTTGCGGCGTCATCCACACAGATCTTAAGCCCGAGAACGTCCTCATC TGCATCGACGACGTCGAAAACGTCATCTTAGCCGAGCTTGAAGCCTCTTCTGCAGCAGCCAGCACGCCACCCACG AGGCTAGTCGGTGTTCCTCCTTCGAAAGGACGTGGAGGCAACCAAACTCCAAGATCCGAATCCGTTTTCATCACC GGCTCACAGCCCCTTCCCTCGCCTTCCTCATCCTTTGGCACGAGCCCAATGCTAGACAAATGGGCATTTGGTATG AGCAGGATTGAGGGAGACGACAACAGCAATGGCATCGTGGAGAAGAAGGGCCTGTCAACGGTGAAACGGGCTGTC TCGACGGATTTGGTCGCTGAAGTCAACAACGTCTCACTAGAAACCCAGGCTAGCTACGTTGGACGCATGCCTGGC GCGCCCGGACCTTCCCTGCTCACCGACACCAAACCTGTTCCTATTCCTGGCGCCCCATCCCCCGAACCTCCAGCA GACGGGGCCCCTCGCTCTGTGATGTCGGTCGATCAACGATCCGACTCTTCCAGTGCCATCGACTTGTCAGAGAAG ATCACTGTTAAGATCGCGGATTTGGGAAATGCCACGTGGGTTGAGCATCACTTCACCGACGATATCCAAACTCGA CAATACCGCTGTCCCGAAGTCATCCTAGGCGCCAAGTGGGGCACTAGTGCAGATATTTGGAGTGTAGCTTGCGTG CTCTTCGAATTGATCACTGGCGGTGATTATCTATTTGATCCCGCCTCTGGTTCGAGGTACAGCAAGGATGACGAC CACATCGCTCAGATCATGGAGCTGCTCGGCGAGCTACCAAGGAGTATAGCCTTTTCCGGCAAATACTCTTCCGAA TTCTTCAACCGGAAAGGTGAGCTACGGCACATCAACAAACTACGATATTGGCCTCTCGACTCTGTGCTGCACGAC AAGTACCTGTTCCCTAAACACGAAGCCGACGCACTCGCGGCATTCCTCCTCCCGATGCTCCGCCTCCACCCCGAT CGACGCGCCAAAGCCTCCGAGTTGATCCACCACAACTGGCTCGAGGGTACCGTCGTACAAGGCGAGATCGACGTG ATTAAGAGGGCTGAAGCGGAGGAAGCAGCGCGGAAGAAGGCGAAGGCCGATCAGCAGCGCCAGGCGTCGCAGAAA CACAAGCGGGACGATTCAAAACTCGTCCAGGCGGGAGGGATGCAGCTGTTGGACGAGGACGAGGCGGATGCGATG AAGCCTATCGAAGCTGGGGCTGTGGTGGCTGATGGAGAGGCCGAGGGTGAACAGAAGGATTTGAAACCGGTGCAG CAGTTGCAGTTGCAGCATCAGCCGCCAGTGTTGAACCCTCCTCCGATCCCGCATGGCGCGTCGGGGCTGACGAGG ACTGCGCCTGCGAATGTTGCGAAACAGGTTTCCCCTCCTCCTGCCGCGAATAATCGTCAGCCATCTGCTGGTAAG AAGACGTCCAAATCCGGCCGGAGTTAA |
| Length | 2277 |
Gene
| Sequence id | CC1G_04899T0 |
|---|---|
| Sequence |
>CC1G_04899T0 CGACGAGCTCGCCCGGTTCCACACCTTTTCGCACCTCTCGCCACCGGGGCCCACGGCGACCACACGACTAACGGC AACCAGCTGCGGATTTGGTCTCCAATTGGGTGGCTAAACTAGGCAACCAGGGCTTATCTTTGACCGCCTCCAGAT ACTCGACCCTTATCTCGGGAAGCCACAGGACAGCAACAGATTACGGATTGGTTAGAATTATCATAAACGATGTCT CACGGTTCCTATTCTTCATACTCTGCCTCCATCATGACTGAAGACGAAGAAGATTGGGAGGACTATGTCAAGGGA GGCTACCACCCAGTCAAGATTGGCGACGAGTTTTCCGATGGACGCTACGTCGTCGTCAGAAAGCTCGGTTGGGGT CACTTTTCCACTGTCTGGCTCGCCAGAGACACAAAGTGAGTTTCACGAGACCACAAGGTTGACCCACATTCTCTG ACATTCCCGGGTGGCTAGGATGAATCGCCATGTTGCCCTCAAAATCGTGAAATCAGCCCCGCGATATACAGAGAC CGCCCTGGACGAAATCAAGCTCCTGCAGCGTCTGATCACGTCCTCGACTCCACCCGTCGCGCCCACCCCAGAGAA TCCAAATCCACCCCCGTCTCCCTCTCATACCCACCCCGGGAAATCGCACGTCATTCAATTCCTGGATCACTTCCG ACACAAGGGGCCCAATGGAACCCACGTCTGCATGGTTTTCGAGGTTCTGGGCGAGAACCTCCTTGGTCTCATTAA ACGACACCAGAGCAAGGGCGTTCCGATGCATCTCGTTAAGCAAATCGCGAAACAAATCCTCCTCGGTCTCGACTA CATGCATCGCTGTTGCGGCGTCATCCACACAGGTGCGAAAATCTCGTGCCACTGGGTCTTAATGCCACTCACAGA GAACCTTCTAGATCTTAAGCCCGAGAACGTCCTCATCTGCATCGACGACGTCGAAAACGTCATCTTAGCCGAGCT TGAAGCCTCTTCTGCAGCAGCCAGCACGCCACCCACGAGGCTAGTCGGTGTTCCTCCTTCGAAAGGACGTGGAGG CAACCAAACTCCAAGATCCGAATCCGTTTTCATCACCGGCTCACAGCCCCTTCCCTCGCCTTCCTCATCCTTTGG CACGAGCCCAATGCTAGACAAATGGGCATTTGGTATGAGCAGGATTGAGGGAGACGACAACAGCAATGGCATCGT GGAGAAGAAGGGCCTGTCAACGGTGAAACGGGCTGTCTCGACGGATTTGGTCGCTGAAGTCAACAACGTCTCACT AGAAACCCAGGCTAGCTACGTTGGACGCATGCCTGGCGCGCCCGGACCTTCCCTGCTCACCGACACCAAACCTGT TCCTATTCCTGGCGCCCCATCCCCCGAACCTCCAGCAGACGGGGCCCCTCGCTCTGTGATGTCGGTCGATCAACG ATCCGACTCTTCCAGTGCCATCGACTTGTCAGAGAAGATCACTGTTAAGATCGCGGATTTGGGAAATGGTATGCC TCTTCTTTTAGTTGCCTCAACATGTTTTTGAGCGATTTTTAGCCACGTGGGTTGAGCATCACTTCACCGACGATA TCCAAACTCGACAATACCGCTGTCCCGAAGTCATCCTAGGCGCCAAGTGGGGCACTAGTGCAGATATTTGGAGTG TAGCTTGCGTGGTACGTTTTTTGGTTATCTGAGATCGCCTCGAGTGTGCTGACTCTTCTTTAGCTCTTCGAATTG ATCACTGGCGGTGATTATCTATTTGATCCCGCCTCTGGTTCGAGGTACAGCAAGGATGACGACCACATCGCTCAG ATCATGGAGCTGCTCGGCGAGCTACCAAGGAGTATAGCCTTTTCCGGCAAATACTCTTCCGAATTCTTCAACCGG AAAGGTATGTCGCACCAACTCCTATTCATTCTTCAGGTTCTAATGCGACGCAGGTGAGCTACGGCACATCAACAA ACTACGATATTGGCCTCTCGACTCTGTGCTGCACGACAAGTACCTGTTCCCTAAACACGAAGCCGACGCACTCGC GGCATTCCTCCTCCCGATGCTCCGCCTCCACCCCGATCGACGCGCCAAAGCCTCCGAGTTGATCCACCACAACTG GCTCGAGGGTACCGTCGTACAAGGCGAGATCGACGTGATTAAGAGGGCTGAAGCGGAGGAAGCAGCGCGGAAGAA GGCGAAGGCCGATCAGCAGCGCCAGGCGTCGCAGAAACACAAGCGGGACGATTCAAAACTCGTCCAGGCGGGAGG GATGCAGCTGTTGGACGAGGACGAGGCGGATGCGATGAAGCCTATCGAAGCTGGGGCTGTGGTGGCTGATGGAGA GGCCGAGGGTGAACAGAAGGATTTGAAACCGGTGCAGCAGTTGCAGTTGCAGCATCAGCCGCCAGTGTTGAACCC TCCTCCGATCCCGCATGGCGCGTCGGGGCTGACGAGGACTGCGCCTGCGAATGTTGCGAAACAGGTTTCCCCTCC TCCTGCCGCGAATAATCGTCAGCCATCTGCTGGTAAGAAGACGTCCAAATCCGGCCGGAGTTAA |
| Length | 2539 |