CC1G_05089
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_05089 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NGA5 | Functional description | Exo-beta-1,3-glucanase |
| Location | Chr_2:1825171..1827974 | Strand | + |
| Gene length (nt) | 2804 | Transcript length (nt) | 2430 |
| CDS length (nt) | 2430 | Protein length (aa) | 809 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | exgD |
| Aspergillus niger | exgD |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7267896 | 66.1 | 0 | 1122 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB21561 | 64 | 0 | 1095 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_63154 | 60.6 | 0 | 1047 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_33887 | 60.6 | 0 | 1044 |
| Pleurotus ostreatus PC15 | PleosPC15_2_60667 | 59 | 4.95E-304 | 985 |
| Pleurotus ostreatus PC9 | PleosPC9_1_114096 | 59 | 4.845E-304 | 985 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1479769 | 58.9 | 6.331E-304 | 982 |
| Flammulina velutipes | Flave_chr09AA00203 | 57.1 | 1.171E-299 | 929 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_2760 | 52.6 | 2.109E-283 | 882 |
| Lentinula edodes B17 | Lened_B_1_1_3627 | 52.4 | 8.938E-282 | 877 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_109089 | 53 | 7.019E-277 | 863 |
| Lentinula edodes NBRC 111202 | Lenedo1_1058758 | 56 | 1.705E-266 | 833 |
| Schizophyllum commune H4-8 | Schco3_2481161 | 61.1 | 1.084E-243 | 767 |
| Auricularia subglabra | Aurde3_1_1273308 | 47.5 | 1.065E-227 | 721 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 4388 |
| Description | Exo-beta-1,3-glucanase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 327 | 486 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 156 | 178 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR017853 | Glycoside hydrolase superfamily |
| IPR001547 | Glycoside hydrolase, family 5 |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| K01210 |
EggNOG
| COG category | Description |
|---|---|
| G | Glycoside hydrolase family 5 protein |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_9 |
Transcription factor
| Group |
|---|
| No records |
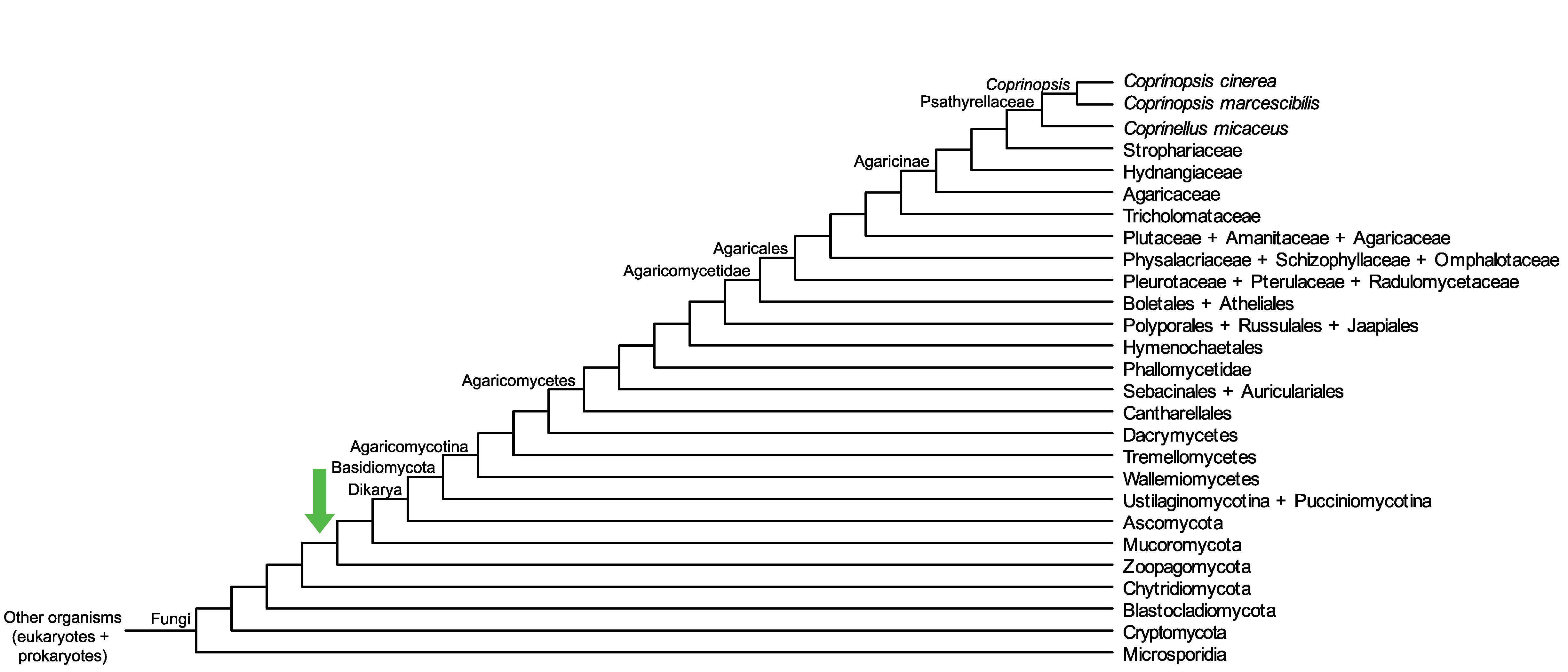
Conservation of CC1G_05089 across fungi.
Arrow shows the origin of gene family containing CC1G_05089.
Protein
| Sequence id | 4388 |
|---|---|
| Sequence |
>4388 MANNPQNPSGNVVYDPLPLTGDDVPSNALYNAPPSPDPRLTSFNTPQMGHSDLPRDDTFIPPGAAQPRFMGQYDE ASARNSFTSSQPSLRQSEYGSVYHLNDAQGSSAQFNNYRDEPNYTDNVPMSPVGHSRGMLHEKNTAYTAPRQKSK RKVMIIGAIVAAILILAAIAIPLYFAVIKPKTSKDNSKSDSNHDKPDSTASPSGKPGSGASRAVVTGGDGSTITM EDGTTFVYRNPFGGYWYYDPNDPFNNGAKAQSWTPALNETFRYGIDKIRGVNVGGWLLTEPFMQVDSPALYEKYL DDPAGPAIDEWDLSLRMRADTAGGGIDQMEEHYKTFITERDFAEIAGAGLNYVRVPIGYWAVETRGDEPYLSQVS WTYFLKAVKWARKYGLRINLDLHGVPGSQNGWNHSGRFGTIGFLHGPMGYANAQRTLDIIRVLAEFISQPQYKDV VTMFGIMNEPLGDPMGQDALSRFYMESYNIIRRAGGGTGEGNGVWISLHDGFFGRAPWEGFLPNADRVTLDTHPY LCFGEQSAAPMSSYAQTPCTTWGHLVNNSMANFGLTNAGEFSNAVTDCGLFLNGVNLGTRYEGDYTPGSWPRIGD CSEWTDYTRYSDQMKSDIRQFALASMDALQHYFFWTWRIGETLRSGRVETPAWSYQLGLREGWMPTDPRDADGVC GNSSPWTPPLQPWQTGGAGAGDIPPSVTEALAWPPPEIRNGGPIESLPRYTQTGALPTLTGMAITAGPSETITRT VDIGNGWNNPADTVGFAVEIPGCTYLDPWVTPAAAPPSPLCAAARREAAQEPAVTLPPS |
| Length | 809 |
Coding
| Sequence id | CC1G_05089T0 |
|---|---|
| Sequence |
>CC1G_05089T0 ATGGCCAACAACCCGCAGAATCCATCAGGAAACGTAGTGTACGACCCACTCCCCTTGACTGGGGATGACGTGCCC TCGAATGCGCTCTACAATGCCCCGCCATCGCCAGATCCGCGTCTGACATCGTTCAATACCCCTCAGATGGGCCAC TCAGACCTGCCTCGCGATGACACCTTCATCCCCCCGGGAGCAGCCCAACCACGTTTCATGGGTCAATATGATGAA GCTTCTGCCCGCAACTCATTTACTTCTTCCCAACCTAGTCTGCGCCAGTCAGAGTATGGTTCAGTTTACCACCTC AACGACGCCCAAGGCTCCTCGGCCCAATTCAACAATTACCGTGACGAACCCAACTACACCGACAACGTCCCCATG TCTCCCGTCGGTCATTCACGCGGTATGCTCCACGAAAAGAACACAGCCTACACCGCTCCCCGGCAGAAGTCGAAA CGAAAGGTCATGATCATTGGGGCTATCGTTGCTGCCATCCTCATCCTAGCTGCCATCGCCATACCGCTCTACTTC GCCGTTATTAAACCAAAAACAAGCAAAGACAACAGCAAGTCCGATAGCAATCATGATAAACCGGACTCGACGGCT TCACCTAGCGGAAAGCCAGGCAGCGGTGCTTCGCGGGCTGTCGTCACAGGCGGTGATGGTAGCACCATCACAATG GAGGACGGAACGACGTTCGTCTATCGTAATCCATTCGGCGGCTACTGGTACTACGATCCCAACGATCCTTTCAAC AATGGCGCAAAGGCCCAGTCTTGGACCCCTGCACTGAACGAAACCTTCCGCTATGGAATCGACAAAATCCGAGGG GTTAATGTCGGTGGTTGGCTTTTGACCGAACCGTTCATGCAAGTAGACTCTCCAGCCCTGTATGAAAAGTACCTG GATGACCCAGCAGGTCCCGCCATCGACGAGTGGGACTTAAGCCTCCGTATGCGAGCTGATACTGCTGGTGGAGGG ATTGACCAGATGGAGGAGCATTACAAGACCTTTATCACTGAAAGGGACTTTGCCGAAATCGCCGGTGCTGGACTC AACTATGTCCGCGTCCCAATCGGCTATTGGGCCGTCGAAACTCGTGGAGACGAACCCTATCTGTCTCAGGTCTCT TGGACGTACTTTTTGAAGGCCGTGAAGTGGGCAAGGAAATACGGACTCAGAATCAATCTCGACCTTCACGGGGTC CCTGGAAGCCAGAACGGATGGAACCATTCGGGCCGCTTTGGCACTATTGGCTTTCTTCACGGTCCTATGGGTTAT GCAAATGCCCAGCGTACCTTGGATATCATTCGTGTCCTCGCCGAGTTCATTTCTCAACCCCAGTATAAAGATGTT GTCACCATGTTCGGGATTATGAACGAGCCCCTTGGCGATCCCATGGGCCAGGATGCTCTTTCACGATTCTACATG GAAAGTTACAATATCATCCGCCGGGCTGGAGGTGGAACCGGTGAAGGAAACGGCGTTTGGATCTCTCTACACGAT GGTTTCTTCGGCCGTGCCCCTTGGGAAGGCTTCCTTCCCAACGCTGACCGAGTGACCTTAGACACTCACCCATAC CTCTGTTTCGGTGAACAGTCTGCTGCACCGATGTCGTCCTACGCTCAAACACCTTGTACAACCTGGGGCCATCTC GTCAACAACTCGATGGCCAACTTCGGGTTGACCAATGCTGGTGAATTCAGCAATGCTGTTACTGACTGTGGGCTA TTCCTGAATGGAGTCAACCTTGGTACTCGGTACGAAGGTGATTACACCCCGGGTAGCTGGCCTCGCATCGGCGAT TGCTCCGAATGGACCGATTACACTCGTTACAGTGATCAGATGAAGAGCGACATTCGACAGTTCGCACTCGCGTCC ATGGATGCCCTTCAGCACTACTTCTTCTGGACATGGAGGATTGGCGAGACACTTCGCAGCGGACGGGTCGAGACG CCAGCATGGTCTTATCAGCTGGGACTGCGCGAAGGCTGGATGCCTACTGACCCTCGTGATGCCGACGGCGTTTGT GGCAACAGCTCGCCTTGGACCCCGCCCCTTCAACCATGGCAAACGGGCGGTGCAGGTGCGGGGGATATTCCTCCT TCTGTGACGGAAGCTCTTGCCTGGCCCCCCCCAGAAATTCGCAACGGTGGTCCCATTGAATCACTTCCCCGATAC ACGCAGACTGGGGCCCTCCCGACACTGACAGGAATGGCCATCACTGCCGGACCCAGCGAGACCATCACCAGAACC GTCGACATCGGCAATGGTTGGAATAACCCGGCAGATACCGTTGGTTTCGCCGTTGAAATTCCAGGCTGCACCTAC CTCGACCCTTGGGTAACTCCTGCTGCCGCTCCCCCTTCCCCTTTGTGCGCAGCAGCCCGCCGTGAGGCAGCGCAG GAGCCTGCCGTCACTCTCCCTCCCTCG |
| Length | 2430 |
Transcript
| Sequence id | CC1G_05089T0 |
|---|---|
| Sequence |
>CC1G_05089T0 ATGGCCAACAACCCGCAGAATCCATCAGGAAACGTAGTGTACGACCCACTCCCCTTGACTGGGGATGACGTGCCC TCGAATGCGCTCTACAATGCCCCGCCATCGCCAGATCCGCGTCTGACATCGTTCAATACCCCTCAGATGGGCCAC TCAGACCTGCCTCGCGATGACACCTTCATCCCCCCGGGAGCAGCCCAACCACGTTTCATGGGTCAATATGATGAA GCTTCTGCCCGCAACTCATTTACTTCTTCCCAACCTAGTCTGCGCCAGTCAGAGTATGGTTCAGTTTACCACCTC AACGACGCCCAAGGCTCCTCGGCCCAATTCAACAATTACCGTGACGAACCCAACTACACCGACAACGTCCCCATG TCTCCCGTCGGTCATTCACGCGGTATGCTCCACGAAAAGAACACAGCCTACACCGCTCCCCGGCAGAAGTCGAAA CGAAAGGTCATGATCATTGGGGCTATCGTTGCTGCCATCCTCATCCTAGCTGCCATCGCCATACCGCTCTACTTC GCCGTTATTAAACCAAAAACAAGCAAAGACAACAGCAAGTCCGATAGCAATCATGATAAACCGGACTCGACGGCT TCACCTAGCGGAAAGCCAGGCAGCGGTGCTTCGCGGGCTGTCGTCACAGGCGGTGATGGTAGCACCATCACAATG GAGGACGGAACGACGTTCGTCTATCGTAATCCATTCGGCGGCTACTGGTACTACGATCCCAACGATCCTTTCAAC AATGGCGCAAAGGCCCAGTCTTGGACCCCTGCACTGAACGAAACCTTCCGCTATGGAATCGACAAAATCCGAGGG GTTAATGTCGGTGGTTGGCTTTTGACCGAACCGTTCATGCAAGTAGACTCTCCAGCCCTGTATGAAAAGTACCTG GATGACCCAGCAGGTCCCGCCATCGACGAGTGGGACTTAAGCCTCCGTATGCGAGCTGATACTGCTGGTGGAGGG ATTGACCAGATGGAGGAGCATTACAAGACCTTTATCACTGAAAGGGACTTTGCCGAAATCGCCGGTGCTGGACTC AACTATGTCCGCGTCCCAATCGGCTATTGGGCCGTCGAAACTCGTGGAGACGAACCCTATCTGTCTCAGGTCTCT TGGACGTACTTTTTGAAGGCCGTGAAGTGGGCAAGGAAATACGGACTCAGAATCAATCTCGACCTTCACGGGGTC CCTGGAAGCCAGAACGGATGGAACCATTCGGGCCGCTTTGGCACTATTGGCTTTCTTCACGGTCCTATGGGTTAT GCAAATGCCCAGCGTACCTTGGATATCATTCGTGTCCTCGCCGAGTTCATTTCTCAACCCCAGTATAAAGATGTT GTCACCATGTTCGGGATTATGAACGAGCCCCTTGGCGATCCCATGGGCCAGGATGCTCTTTCACGATTCTACATG GAAAGTTACAATATCATCCGCCGGGCTGGAGGTGGAACCGGTGAAGGAAACGGCGTTTGGATCTCTCTACACGAT GGTTTCTTCGGCCGTGCCCCTTGGGAAGGCTTCCTTCCCAACGCTGACCGAGTGACCTTAGACACTCACCCATAC CTCTGTTTCGGTGAACAGTCTGCTGCACCGATGTCGTCCTACGCTCAAACACCTTGTACAACCTGGGGCCATCTC GTCAACAACTCGATGGCCAACTTCGGGTTGACCAATGCTGGTGAATTCAGCAATGCTGTTACTGACTGTGGGCTA TTCCTGAATGGAGTCAACCTTGGTACTCGGTACGAAGGTGATTACACCCCGGGTAGCTGGCCTCGCATCGGCGAT TGCTCCGAATGGACCGATTACACTCGTTACAGTGATCAGATGAAGAGCGACATTCGACAGTTCGCACTCGCGTCC ATGGATGCCCTTCAGCACTACTTCTTCTGGACATGGAGGATTGGCGAGACACTTCGCAGCGGACGGGTCGAGACG CCAGCATGGTCTTATCAGCTGGGACTGCGCGAAGGCTGGATGCCTACTGACCCTCGTGATGCCGACGGCGTTTGT GGCAACAGCTCGCCTTGGACCCCGCCCCTTCAACCATGGCAAACGGGCGGTGCAGGTGCGGGGGATATTCCTCCT TCTGTGACGGAAGCTCTTGCCTGGCCCCCCCCAGAAATTCGCAACGGTGGTCCCATTGAATCACTTCCCCGATAC ACGCAGACTGGGGCCCTCCCGACACTGACAGGAATGGCCATCACTGCCGGACCCAGCGAGACCATCACCAGAACC GTCGACATCGGCAATGGTTGGAATAACCCGGCAGATACCGTTGGTTTCGCCGTTGAAATTCCAGGCTGCACCTAC CTCGACCCTTGGGTAACTCCTGCTGCCGCTCCCCCTTCCCCTTTGTGCGCAGCAGCCCGCCGTGAGGCAGCGCAG GAGCCTGCCGTCACTCTCCCTCCCTCGTAA |
| Length | 2430 |
Gene
| Sequence id | CC1G_05089T0 |
|---|---|
| Sequence |
>CC1G_05089T0 ATGGCCAACAACCCGCAGAATCCATCAGGAAACGTAGTGTACGACCCACTCCCCTTGACTGGGGATGACGTGCCC TCGAATGCGCTCTACAATGCCCCGCCATCGCCAGATCCGCGTCTGACATCGTTCAATACCCCTCAGATGGGCCAC TCAGACCTGCCTCGCGATGACACCTTCATCCCCCCGGGAGCAGCCCAACCACGTTTCATGGGTCAATATGATGAA GCTTCTGCCCGCAACTCATTTACTTCTTCCCAACCTAGTCTGCGCCAGTCAGAGTATGGTTCAGTTTACCACCTC AACGACGCCCAAGGCTCCTCGGCCCAATTCAACAATTACCGTGACGAACCCAACTACACCGACAACGTCCCCATG TCTCCCGTCGGTCATTCACGCGGTATGCTCCACGAAAAGAACACAGCCTACACCGCTCCCCGGCAGAAGTCGAAA CGAAAGGTCATGATCATTGGGGCTATCGTTGCTGCCATCCTCATCCTAGCTGCCATCGCCATACCGCTCTACTTC GCCGTTATTAAACCAAAAACAAGCAAAGACAACAGCAAGTCCGATAGCAATCATGATAAACCGGACTCGACGGCT TCACCTAGCGGAAAGCCAGGCAGCGGTGCTTCGCGGGCTGTCGTCACAGGCGGTGATGGTAGCACCATCACAATG GAGGACGGAACGACGTTCGTCTATCGTAATCCATTCGGCGGCTACTGGTACTACGATCCCAACGATCCTTTCAAC AATGGCGCAAAGGCCCAGTCTTGGACCCCTGCACTGAACGAAACCTTCCGCTATGGAATCGACAAAATCCGAGGG TGTGTATTCACCTAGTTCATTTCAAGAGGGTCTCTAAATATCACAAACAGGGTTAATGTCGGTGGTTGGCTTTTG ACCGAACCGGTAAGTCCACAGCCCTCGTCGCGTTGTCCATGTCAGTCTTCTAATGCCAATTTTAGTTCATGCAAG TAGAGTACCTTATCTTCGCAAACGCGGCGCCTAATTCTCCTTTCCAGCTCTCCAGCCCTGTATGAAAAGTACCTG GATGACCCAGCAGGTCCCGCCATCGACGAGTGGGACTTAAGCCTCCGTATGCGAGCTGATACTGCTGGTGGAGGG ATTGACCAGATGGAGGAGCATTACAAGACCTTTATCGTGAGGCCATCATCTGGTACACCCTACTGATAACTTTGC TAACGAAACATTCACTCAGACTGAAAGGGACTTTGCCGAAATCGCCGGTGCTGGACTCAACTATGTCCGCGTCCC AATCGGCTATTGGGCCGTCGAAACTCGTGGAGACGAACCCTATCTGTCTCAGGTCTCTTGGACGTGAGGTCGCAA TGGTCTCTCTTCCATCAAGCTGCTCATTCTGTTTCAATTAGGTACTTTTTGAAGGCCGTGAAGTGGGCAAGGAAA TACGGACTCAGAATCAATCTCGACCTTCACGGGGTCCCTGGAAGCCAGAACGGATGGAACCATTCGGGCCGCTTT GGCACTATTGGCTTTCTTCACGGTCCTATGGGTTATGCAAATGCCCAGCGTACCTTGGATATCATTCGTGTCCTC GCCGAGTTCATTTCTCAACCCCAGTATAAAGATGTTGTCACCATGTTCGGGATTATGAACGAGCCCCTTGGCGAT CCCATGGGCCAGGATGCTCTTTCACGATTGTGAGGTCATTTTTCCCTTCCATAGTCGGTGGTCTGACAGTGTCCC TCTCTCCTAGCTACATGGAAAGTTACAATATCATCCGCCGGGCTGGAGGTGGAACCGGTGAAGGAAACGGCGTTT GGATCTCTCTACACGATGGTTTCTTCGGCCGTGCCCCTTGGGAAGGCTTCCTTCCCAACGCTGACCGAGTGACCT TAGACACTCACCCATACCTCTGTTTCGGTGAACAGTCTGCTGCACCGATGTCGTCCTACGCTCAAACACCTTGTA CAACCTGGGGCCATCTCGTCAACAACTCGATGGCCAACTTCGGGTTGACCAATGCTGGTGAATTCAGCAATGCTG TTACTGACTGTGGGCTATTCCTGAATGGAGTCAACCTTGGTACTCGGTACGAAGGTGATTACACCCCGGGTAGCT GGCCTCGCATCGGCGATTGCTCCGAATGGACCGATTACACTCGTTACAGTGATCAGATGAAGAGCGACATTCGAC AGTTCGCACTCGCGTCCATGGATGCCCTTCAGGTCAGTTAAATCAGCATCAATCAGTGATACCAGGAAAGTTGAC CAAAAGACATACAGCACTACTTCTTCTGGACATGGAGGATTGGCGAGACACTTCGCAGCGGACGGGTCGAGACGC CAGCATGGTCTTATCAGCTGGGACTGCGCGAAGGCTGGATGCCTACTGACCCTCGTGATGCCGACGGCGTTTGTG GCAACAGCTCGCCTTGGACCCCGCCCCTTCAACCATGGCAAACGGGCGGTGCAGGTGCGGGGGATATTCCTCCTT CTGTGACGGAAGCTCTTGCCTGGCCCCCCCCAGAAATTCGCAACGGTGGTCCCATTGAATCACTTCCCCGATACA CGCAGACTGGGGCCCTCCCGACACTGACAGGAATGGCCATCACTGCCGGACCCAGCGAGACCATCACCAGAACCG TCGACATCGGCAATGGTTGGAATAACCCGGCAGATACCGTTGGTTTCGCCGTTGAAATTCCAGGCTGCACCTACC TCGACCCTTGGGTAACTCCTGCTGCCGCTCCCCCTTCCCCTTTGTGCGCAGCAGCCCGCCGTGAGGCAGCGCAGG AGCCTGCCGTCACTCTCCCTCCCTCGTAA |
| Length | 2804 |