CC1G_06600
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_06600 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N2W5 | Functional description | Other/NAK protein kinase |
| Location | Chr_1:2916478..2920591 | Strand | - |
| Gene length (nt) | 4114 | Transcript length (nt) | 3744 |
| CDS length (nt) | 3744 | Protein length (aa) | 1247 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7264818 | 45.6 | 1.68E-304 | 1020 |
| Lentinula edodes NBRC 111202 | Lenedo1_1164473 | 47.7 | 4.567E-304 | 972 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_483 | 47.6 | 2.194E-304 | 970 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB29204 | 44.7 | 2.339E-294 | 938 |
| Pleurotus ostreatus PC9 | PleosPC9_1_53073 | 43.4 | 2.857E-285 | 911 |
| Pleurotus ostreatus PC15 | PleosPC15_2_166468 | 43.1 | 7.21E-283 | 904 |
| Schizophyllum commune H4-8 | Schco3_2744124 | 43.6 | 2.643E-278 | 891 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1485541 | 42.9 | 2.63E-276 | 885 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_113930 | 42.6 | 6.615E-268 | 860 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_124351 | 42.9 | 1.597E-266 | 856 |
| Flammulina velutipes | Flave_chr08AA00430 | 41.9 | 4.426E-265 | 852 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_148486 | 39.6 | 3.058E-257 | 829 |
| Grifola frondosa | Grifr_OBZ79644 | 40 | 1.544E-255 | 824 |
| Lentinula edodes B17 | Lened_B_1_1_16156 | 65.3 | 4.283E-209 | 687 |
| Auricularia subglabra | Aurde3_1_1410795 | 34.9 | 1.539E-186 | 621 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 5680 |
| Description | Other/NAK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 113 | 244 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K08286 |
| K08853 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
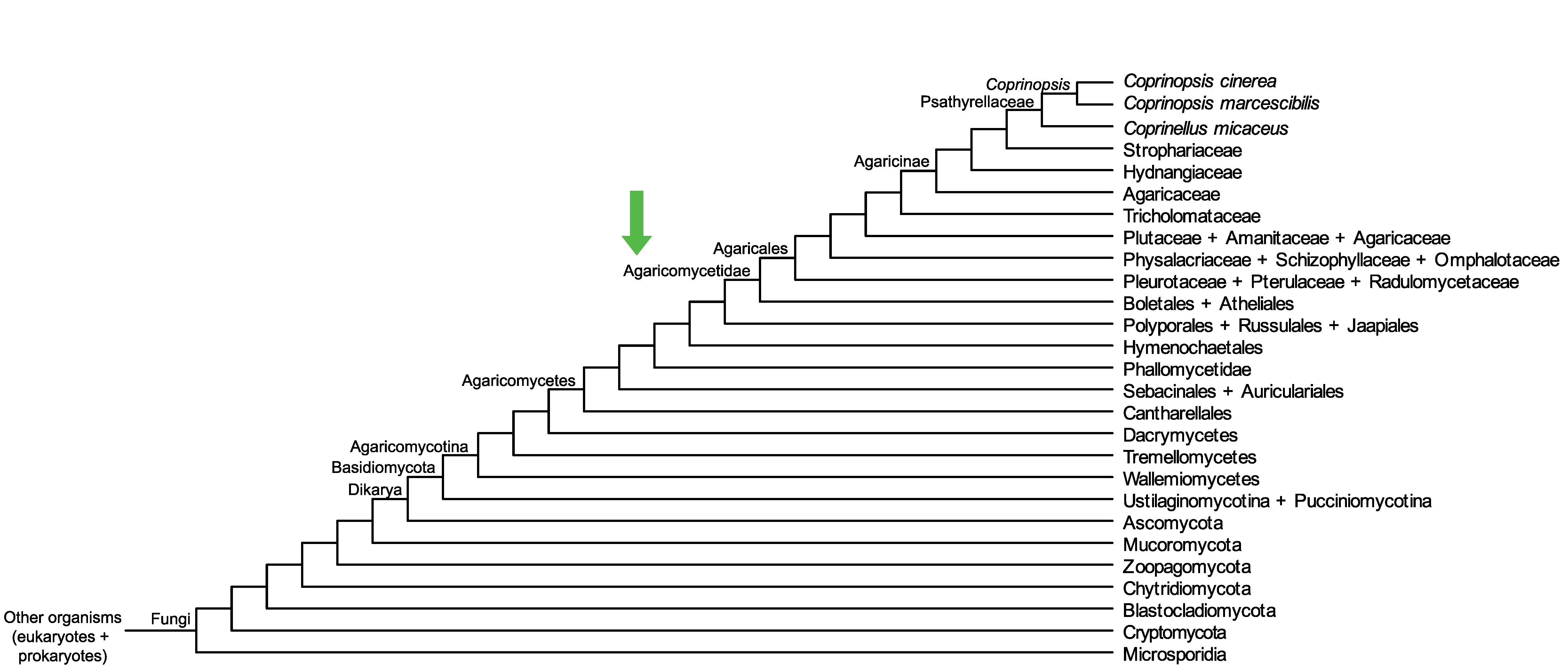
Conservation of CC1G_06600 across fungi.
Arrow shows the origin of gene family containing CC1G_06600.
Protein
| Sequence id | 5680 |
|---|---|
| Sequence |
>5680 MATQQAYQTAGGFAHVYLVRTPTPVYNTTHHVLKRIAVANEAMLSEVKREVDVMRVLKGHPNIVHLIDAAWHRLP NGTFEVFILMEYCPGGGIIDMMNRRLRERLTEAEILQIFVDSSPTSYKLCDFGSASTVQRPPTNTQEIRALEADL GRHTTMQYRAPEMIDLYSKRPIDEKSDVWALGVLLYKLCYYTTPFEEHGSLAILNVQYRIPPYPQYSNQMNMLIA SMLREHGSQRPTVFELLRHVHHLRGTKSPFTYNIPVPQPVVPRHHQIPPKPAPSPIPGPQHHTGSRQVANGLRSA PVVTSGSPPKGQGVQAREKVLEAIAPMRRGRPVQPKEGSSSRQPSPQKHAPPKPVLPVQPIQPAKPAVKESNWLD KEEASLKTANAQAEARERANALFDEAWRVSSATATKESDSKASSGFENDFADKLWRAPNPNMSLSPAKVSPKPTS HGHSASAVIKPLSHTGSDALRNGRGKDAFEGLGLITSIGKPAPTLAEARKLRTGLAIMSSQPNQYGSTKPAELSV KPTTDGGSTHPTPSPRPSYLGPTTGHFQSTSRSTTPNPEPWRGSAPAPSSAHASKDGTPIESRFPSLEELDAQFS ATSLYPASAQANDRFASRSTPTVAPSLPPRPSANVPKEDPERPSRFNAPPSAPPTLDSLEKKYEATSVRNDWKSS PSTRSAVESRTESSPAKLPSGSATMRFAMEELKSTQSSSGTSQSTKLSSNRPPSPSKHSRTAPAPDWLTGDGDVT ENTIEKATTGPVVRDTPAKRASVILKNDFKIQEPVTAQYDTTPVIRPEKSLHPEESPTVARFTKNFPAIDTASAN ELLIQNEPLTDNWSPIVASKPPPQLPRRPSKKELEAAESASSADDDEGPEDLGGLTSPPKKMGSLRASRHKGRQS SVHELVDLWGGKGPAKDRPRDEPSSPLKAASAEKPVTRPKPRPTSLLPPQRTPSFSMRSVSGGARISPIQRVPSP QPSPSLPEKSPPLHSPPITTSPSSGTGRSRPQSMFIFPSKSTDALPSPSQPTGMGPPPEEGTQRPARRQTSISNM VQRYEAIGGKVIAPQQAAPSPVTRKPSLNLNKSSVPPNQVETGRIKVLPVPDKVPAIAPKDEFRPAWISGEAART RTTSTGPLKASLDIPRTTVKPQRVSPIERKPTGSPKKNLVGLPSITTTTNAVVFPKRRPTLPSEDVLSPPASNSD DRSVSPERPYQGVGKLIDQWQRKSEESEGFHGRPPIKRAGLVQGNRG |
| Length | 1247 |
Coding
| Sequence id | CC1G_06600T0 |
|---|---|
| Sequence |
>CC1G_06600T0 ATGGCAACCCAGCAGGCATATCAGACCGCAGGTGGCTTCGCTCACGTTTATCTCGTACGGACGCCGACACCGGTC TACAACACGACTCACCATGTCCTCAAACGAATCGCCGTTGCCAACGAAGCCATGCTCAGCGAGGTCAAGAGGGAA GTAGACGTTATGCGGGTACTCAAAGGCCATCCCAACATCGTTCACCTCATCGATGCAGCATGGCACCGCTTGCCT AACGGCACATTTGAGGTTTTCATCTTAATGGAATATTGTCCAGGTGGTGGAATCATCGACATGATGAACCGGCGA CTGCGGGAGCGACTCACAGAAGCTGAGATTTTGCAAATATTCGTCGACTCTTCTCCGACTTCGTACAAGCTTTGC GATTTCGGTTCCGCTAGCACGGTCCAAAGACCCCCGACGAATACGCAGGAAATCAGAGCACTGGAAGCTGACCTC GGAAGGCATACGACGATGCAATACAGAGCTCCTGAAATGATCGACCTGTACTCAAAACGTCCAATCGACGAGAAG AGTGATGTGTGGGCATTGGGAGTCTTGCTGTACAAGCTCTGCTACTACACAACCCCCTTCGAGGAGCATGGGTCA TTAGCCATCCTGAACGTGCAGTACCGCATCCCCCCGTATCCTCAATATTCAAATCAAATGAACATGCTTATCGCC TCGATGCTTCGAGAGCATGGATCCCAGCGACCGACCGTGTTCGAACTTCTGAGACACGTACATCATCTTCGCGGA ACCAAATCACCATTCACGTACAACATACCTGTTCCTCAGCCTGTGGTTCCGCGACATCACCAAATCCCCCCGAAA CCTGCACCATCGCCTATACCAGGACCCCAACACCACACCGGTTCTCGCCAAGTTGCGAATGGCCTCCGATCGGCA CCCGTCGTAACATCAGGGTCCCCGCCAAAAGGTCAGGGAGTGCAAGCCAGGGAGAAGGTGTTGGAGGCGATCGCT CCTATGCGCCGAGGCAGACCGGTACAGCCAAAAGAAGGTTCATCTTCCAGGCAGCCTAGTCCACAGAAGCACGCG CCACCTAAGCCTGTCCTGCCTGTCCAGCCAATTCAGCCAGCGAAACCTGCTGTCAAAGAATCAAATTGGCTTGAC AAGGAGGAAGCATCTCTGAAGACTGCGAACGCTCAAGCGGAAGCACGCGAGAGAGCTAATGCGCTCTTTGACGAA GCATGGCGTGTGTCTAGCGCTACAGCCACCAAAGAATCAGATTCTAAAGCATCGTCGGGTTTCGAGAACGACTTT GCGGACAAGTTGTGGCGTGCCCCCAATCCAAATATGAGCCTATCTCCCGCGAAAGTCAGCCCCAAACCCACCTCG CATGGCCACTCGGCAAGCGCTGTCATCAAGCCGCTTTCGCATACAGGAAGCGACGCGCTGCGTAATGGACGGGGT AAGGACGCATTCGAGGGATTGGGCCTCATCACTTCCATCGGTAAACCCGCACCTACTCTTGCCGAAGCGCGAAAA CTTCGAACAGGCTTAGCCATCATGAGTTCGCAACCGAATCAGTATGGCAGTACCAAGCCTGCTGAGTTGTCGGTC AAACCTACTACGGACGGGGGGTCGACGCATCCAACTCCATCGCCTCGCCCTTCGTATCTTGGCCCCACGACAGGC CACTTCCAATCGACTTCTAGGAGCACCACTCCAAATCCAGAACCTTGGCGGGGATCTGCACCTGCTCCCAGCTCG GCCCATGCCAGCAAGGACGGGACGCCAATCGAGTCACGGTTCCCTTCATTGGAAGAGCTAGATGCTCAGTTCTCG GCCACTTCATTGTACCCAGCGTCTGCGCAGGCTAACGACCGATTCGCCAGCCGATCAACGCCTACCGTTGCGCCT TCGCTACCCCCTCGCCCGAGTGCAAATGTGCCCAAGGAAGATCCTGAACGTCCTTCTCGTTTCAACGCTCCGCCG TCCGCTCCTCCGACTTTGGATTCTCTGGAGAAGAAATATGAAGCGACCTCTGTCAGGAACGACTGGAAGTCATCA CCATCGACACGCAGTGCGGTTGAGAGCAGGACGGAATCCTCGCCAGCTAAGCTCCCAAGCGGTTCGGCGACAATG AGGTTCGCTATGGAGGAATTGAAGTCTACCCAGTCATCTTCGGGCACGTCGCAATCTACCAAATTGTCGTCGAAC CGACCACCCTCTCCCTCGAAGCATTCACGAACCGCACCTGCGCCTGATTGGCTCACTGGAGACGGCGATGTTACC GAAAACACCATTGAGAAGGCCACCACTGGACCTGTTGTTCGCGATACGCCAGCCAAGAGAGCTTCCGTCATCTTG AAAAATGACTTCAAGATCCAAGAACCTGTCACTGCGCAGTACGATACAACGCCAGTGATACGCCCAGAAAAGTCC CTTCATCCAGAAGAATCACCCACTGTCGCACGGTTCACGAAGAATTTCCCTGCCATTGACACTGCGTCTGCGAAT GAGCTCTTGATCCAGAACGAGCCGTTGACGGATAATTGGAGCCCAATTGTTGCGAGCAAACCTCCGCCCCAACTT CCCCGCAGGCCGTCCAAAAAGGAACTCGAAGCCGCAGAGTCTGCTTCGAGTGCTGACGATGATGAGGGGCCGGAG GACCTTGGTGGTTTGACCAGCCCGCCCAAGAAGATGGGCAGTCTACGAGCTTCGCGACACAAGGGGCGGCAAAGC TCTGTACATGAGCTTGTTGATCTGTGGGGAGGCAAAGGGCCTGCTAAAGACAGACCTCGCGATGAACCTTCTTCG CCATTGAAGGCGGCATCTGCGGAGAAACCTGTTACTAGACCAAAGCCTCGACCAACATCCTTACTGCCGCCTCAG CGTACTCCTTCGTTCAGCATGCGATCTGTCAGTGGTGGTGCAAGGATATCACCCATCCAGCGAGTTCCTTCACCG CAGCCGTCGCCCAGCCTTCCGGAAAAGTCGCCACCGCTCCACTCCCCTCCCATTACCACGTCTCCCTCCAGCGGT ACCGGTCGATCCCGCCCTCAGTCTATGTTCATCTTTCCTTCCAAATCCACCGATGCATTACCGAGCCCATCTCAA CCTACGGGGATGGGACCTCCGCCTGAGGAAGGCACGCAGCGCCCAGCCCGTCGCCAAACGTCGATATCGAACATG GTGCAACGATATGAGGCCATTGGCGGTAAAGTGATTGCCCCTCAGCAAGCCGCTCCATCACCCGTTACTCGTAAA CCGAGTCTTAACCTCAATAAGAGCTCTGTGCCCCCCAATCAAGTCGAAACTGGGCGTATCAAGGTCTTACCTGTG CCTGACAAGGTACCTGCGATTGCACCGAAGGACGAATTCAGACCTGCTTGGATATCCGGGGAGGCGGCTCGAACA CGCACAACCTCGACTGGTCCTCTGAAAGCCAGTCTGGACATCCCTCGCACGACGGTCAAACCCCAGCGGGTGTCA CCTATCGAACGTAAGCCAACCGGGTCACCCAAGAAGAACCTCGTTGGTCTGCCTTCGATTACCACAACCACGAAT GCTGTCGTTTTCCCGAAGCGCAGACCGACGTTGCCGTCGGAAGATGTCCTGTCACCTCCTGCTTCGAACAGCGAT GATCGATCAGTATCTCCTGAAAGGCCATATCAAGGTGTAGGGAAGCTCATTGATCAATGGCAGCGCAAATCCGAA GAGAGCGAGGGCTTCCATGGCAGGCCGCCTATAAAACGAGCCGGCCTCGTTCAAGGCAATCGTGGA |
| Length | 3744 |
Transcript
| Sequence id | CC1G_06600T0 |
|---|---|
| Sequence |
>CC1G_06600T0 ATGGCAACCCAGCAGGCATATCAGACCGCAGGTGGCTTCGCTCACGTTTATCTCGTACGGACGCCGACACCGGTC TACAACACGACTCACCATGTCCTCAAACGAATCGCCGTTGCCAACGAAGCCATGCTCAGCGAGGTCAAGAGGGAA GTAGACGTTATGCGGGTACTCAAAGGCCATCCCAACATCGTTCACCTCATCGATGCAGCATGGCACCGCTTGCCT AACGGCACATTTGAGGTTTTCATCTTAATGGAATATTGTCCAGGTGGTGGAATCATCGACATGATGAACCGGCGA CTGCGGGAGCGACTCACAGAAGCTGAGATTTTGCAAATATTCGTCGACTCTTCTCCGACTTCGTACAAGCTTTGC GATTTCGGTTCCGCTAGCACGGTCCAAAGACCCCCGACGAATACGCAGGAAATCAGAGCACTGGAAGCTGACCTC GGAAGGCATACGACGATGCAATACAGAGCTCCTGAAATGATCGACCTGTACTCAAAACGTCCAATCGACGAGAAG AGTGATGTGTGGGCATTGGGAGTCTTGCTGTACAAGCTCTGCTACTACACAACCCCCTTCGAGGAGCATGGGTCA TTAGCCATCCTGAACGTGCAGTACCGCATCCCCCCGTATCCTCAATATTCAAATCAAATGAACATGCTTATCGCC TCGATGCTTCGAGAGCATGGATCCCAGCGACCGACCGTGTTCGAACTTCTGAGACACGTACATCATCTTCGCGGA ACCAAATCACCATTCACGTACAACATACCTGTTCCTCAGCCTGTGGTTCCGCGACATCACCAAATCCCCCCGAAA CCTGCACCATCGCCTATACCAGGACCCCAACACCACACCGGTTCTCGCCAAGTTGCGAATGGCCTCCGATCGGCA CCCGTCGTAACATCAGGGTCCCCGCCAAAAGGTCAGGGAGTGCAAGCCAGGGAGAAGGTGTTGGAGGCGATCGCT CCTATGCGCCGAGGCAGACCGGTACAGCCAAAAGAAGGTTCATCTTCCAGGCAGCCTAGTCCACAGAAGCACGCG CCACCTAAGCCTGTCCTGCCTGTCCAGCCAATTCAGCCAGCGAAACCTGCTGTCAAAGAATCAAATTGGCTTGAC AAGGAGGAAGCATCTCTGAAGACTGCGAACGCTCAAGCGGAAGCACGCGAGAGAGCTAATGCGCTCTTTGACGAA GCATGGCGTGTGTCTAGCGCTACAGCCACCAAAGAATCAGATTCTAAAGCATCGTCGGGTTTCGAGAACGACTTT GCGGACAAGTTGTGGCGTGCCCCCAATCCAAATATGAGCCTATCTCCCGCGAAAGTCAGCCCCAAACCCACCTCG CATGGCCACTCGGCAAGCGCTGTCATCAAGCCGCTTTCGCATACAGGAAGCGACGCGCTGCGTAATGGACGGGGT AAGGACGCATTCGAGGGATTGGGCCTCATCACTTCCATCGGTAAACCCGCACCTACTCTTGCCGAAGCGCGAAAA CTTCGAACAGGCTTAGCCATCATGAGTTCGCAACCGAATCAGTATGGCAGTACCAAGCCTGCTGAGTTGTCGGTC AAACCTACTACGGACGGGGGGTCGACGCATCCAACTCCATCGCCTCGCCCTTCGTATCTTGGCCCCACGACAGGC CACTTCCAATCGACTTCTAGGAGCACCACTCCAAATCCAGAACCTTGGCGGGGATCTGCACCTGCTCCCAGCTCG GCCCATGCCAGCAAGGACGGGACGCCAATCGAGTCACGGTTCCCTTCATTGGAAGAGCTAGATGCTCAGTTCTCG GCCACTTCATTGTACCCAGCGTCTGCGCAGGCTAACGACCGATTCGCCAGCCGATCAACGCCTACCGTTGCGCCT TCGCTACCCCCTCGCCCGAGTGCAAATGTGCCCAAGGAAGATCCTGAACGTCCTTCTCGTTTCAACGCTCCGCCG TCCGCTCCTCCGACTTTGGATTCTCTGGAGAAGAAATATGAAGCGACCTCTGTCAGGAACGACTGGAAGTCATCA CCATCGACACGCAGTGCGGTTGAGAGCAGGACGGAATCCTCGCCAGCTAAGCTCCCAAGCGGTTCGGCGACAATG AGGTTCGCTATGGAGGAATTGAAGTCTACCCAGTCATCTTCGGGCACGTCGCAATCTACCAAATTGTCGTCGAAC CGACCACCCTCTCCCTCGAAGCATTCACGAACCGCACCTGCGCCTGATTGGCTCACTGGAGACGGCGATGTTACC GAAAACACCATTGAGAAGGCCACCACTGGACCTGTTGTTCGCGATACGCCAGCCAAGAGAGCTTCCGTCATCTTG AAAAATGACTTCAAGATCCAAGAACCTGTCACTGCGCAGTACGATACAACGCCAGTGATACGCCCAGAAAAGTCC CTTCATCCAGAAGAATCACCCACTGTCGCACGGTTCACGAAGAATTTCCCTGCCATTGACACTGCGTCTGCGAAT GAGCTCTTGATCCAGAACGAGCCGTTGACGGATAATTGGAGCCCAATTGTTGCGAGCAAACCTCCGCCCCAACTT CCCCGCAGGCCGTCCAAAAAGGAACTCGAAGCCGCAGAGTCTGCTTCGAGTGCTGACGATGATGAGGGGCCGGAG GACCTTGGTGGTTTGACCAGCCCGCCCAAGAAGATGGGCAGTCTACGAGCTTCGCGACACAAGGGGCGGCAAAGC TCTGTACATGAGCTTGTTGATCTGTGGGGAGGCAAAGGGCCTGCTAAAGACAGACCTCGCGATGAACCTTCTTCG CCATTGAAGGCGGCATCTGCGGAGAAACCTGTTACTAGACCAAAGCCTCGACCAACATCCTTACTGCCGCCTCAG CGTACTCCTTCGTTCAGCATGCGATCTGTCAGTGGTGGTGCAAGGATATCACCCATCCAGCGAGTTCCTTCACCG CAGCCGTCGCCCAGCCTTCCGGAAAAGTCGCCACCGCTCCACTCCCCTCCCATTACCACGTCTCCCTCCAGCGGT ACCGGTCGATCCCGCCCTCAGTCTATGTTCATCTTTCCTTCCAAATCCACCGATGCATTACCGAGCCCATCTCAA CCTACGGGGATGGGACCTCCGCCTGAGGAAGGCACGCAGCGCCCAGCCCGTCGCCAAACGTCGATATCGAACATG GTGCAACGATATGAGGCCATTGGCGGTAAAGTGATTGCCCCTCAGCAAGCCGCTCCATCACCCGTTACTCGTAAA CCGAGTCTTAACCTCAATAAGAGCTCTGTGCCCCCCAATCAAGTCGAAACTGGGCGTATCAAGGTCTTACCTGTG CCTGACAAGGTACCTGCGATTGCACCGAAGGACGAATTCAGACCTGCTTGGATATCCGGGGAGGCGGCTCGAACA CGCACAACCTCGACTGGTCCTCTGAAAGCCAGTCTGGACATCCCTCGCACGACGGTCAAACCCCAGCGGGTGTCA CCTATCGAACGTAAGCCAACCGGGTCACCCAAGAAGAACCTCGTTGGTCTGCCTTCGATTACCACAACCACGAAT GCTGTCGTTTTCCCGAAGCGCAGACCGACGTTGCCGTCGGAAGATGTCCTGTCACCTCCTGCTTCGAACAGCGAT GATCGATCAGTATCTCCTGAAAGGCCATATCAAGGTGTAGGGAAGCTCATTGATCAATGGCAGCGCAAATCCGAA GAGAGCGAGGGCTTCCATGGCAGGCCGCCTATAAAACGAGCCGGCCTCGTTCAAGGCAATCGTGGATAG |
| Length | 3744 |
Gene
| Sequence id | CC1G_06600T0 |
|---|---|
| Sequence |
>CC1G_06600T0 ATGGCAACCCAGCAGGCATATCAGGTATATGCCCAGCAGAACAAGGGGACACTGGTGCCAGGGCAGACCATCTCC GTGAACAAGTATACTGTGCAGGTCGAGCGGTATTTATCGCAGGGTATGTCCAGCTCAAGTACGGGAGAATCAGTG AATGAACACAGACCGCAGGTGGCTTCGCTCACGTTTATCTCGTACGGACGCCGACACCGGTCTACAACACGACTC ACCATGTCCTCAAACGAATCGCCGTTGCCAACGAAGCCATGCTCAGCGAGGTCAAGAGGGAAGTAGACGTTATGG TGCGTCGAGCGTTCCTTTGCCTTGCTGTCGCTAATGTTTGCCTGTAGCGGGTACTCAAAGGCCATCCCAACATCG TTCACCTCATCGATGCAGCATGGCACCGCTTGCCTAACGGCACATTTGAGGTTTTCATCTTAATGGAATATTGTC CAGGTGGGGTGGAGTGCATCATGCTATACAATCCAGCTCAATCGCGCGTTAGGTGGTGGAATCATCGACATGATG AACCGGCGACTGCGGGAGCGACTCACAGAAGCTGAGATTTTGCAAATATTCGTCGACGTATGTGAAGGCGTGGCA TTCATGCACAACTCCCGGCCACCGCTATTACATCGGGATCTAAAAGTCGAGAATATCCTCCAGTCTTCTCCGACT TCGTACAAGCTTTGCGATTTCGGTTCCGCTAGCACGGTCCAAAGACCCCCGACGAATACGCAGGAAATCAGAGCA CTGGAAGCTGACCTCGGAAGGCATACGACGATGCAATACAGAGCTCCTGAAATGATCGACCTGTACTCAAAACGT CCAATCGACGAGAAGAGTGATGTGTGGGCATTGGGAGTCTTGCTGTACAAGCTCTGCTACTACACAACCCCCTTC GAGGAGCATGGGTCATTAGCCATCCTGAACGTGCAGTACCGCATCCCCCCGTATCCTCAATATTCAAATCAAATG AACATGCTTATCGGTAAGTGGTAGGCACCTTGTATACGAATGCTAACTAAACGATTATGTTCGGACAGCCTCGAT GCTTCGAGAGCATGGATCCCAGCGACCGACCGTGTTCGAACTTCTGAGACACGTACATCATCTTCGCGGAACCAA ATCACCATTCACGTACAACATACCTGTTCCTCAGCCTGTGGTTCCGCGACATCACCAAATCCCCCCGAAACCTGC ACCATCGCCTATACCAGGACCCCAACACCACACCGGTTCTCGCCAAGTTGCGAATGGCCTCCGATCGGCACCCGT CGTAACATCAGGGTCCCCGCCAAAAGGTCAGGGAGTGCAAGCCAGGGAGAAGGTGTTGGAGGCGATCGCTCCTAT GCGCCGAGGCAGACCGGTACAGCCAAAAGAAGGTTCATCTTCCAGGCAGCCTAGTCCACAGAAGCACGCGCCACC TAAGCCTGTCCTGCCTGTCCAGCCAATTCAGCCAGCGAAACCTGCTGTCAAAGAATCAAATTGGCTTGACAAGGA GGAAGCATCTCTGAAGACTGCGAACGCTCAAGCGGAAGCACGCGAGAGAGCTAATGCGCTCTTTGACGAAGCATG GCGTGTGTCTAGCGCTACAGCCACCAAAGAATCAGATTCTAAAGCATCGTCGGGTTTCGAGAACGACTTTGCGGA CAAGTTGTGGCGTGCCCCCAATCCAAATATGAGCCTATCTCCCGCGAAAGTCAGCCCCAAACCCACCTCGCATGG CCACTCGGCAAGCGCTGTCATCAAGCCGCTTTCGCATACAGGAAGCGACGCGCTGCGTAATGGACGGGGTAAGGA CGCATTCGAGGGATTGGGCCTCATCACTTCCATCGGTAAACCCGCACCTACTCTTGCCGAAGCGCGAAAACTTCG AACAGGCTTAGCCATCATGAGTTCGCAACCGAATCAGTATGGCAGTACCAAGCCTGCTGAGTTGTCGGTCAAACC TACTACGGACGGGGGGTCGACGCATCCAACTCCATCGCCTCGCCCTTCGTATCTTGGCCCCACGACAGGCCACTT CCAATCGACTTCTAGGAGCACCACTCCAAATCCAGAACCTTGGCGGGGATCTGCACCTGCTCCCAGCTCGGCCCA TGCCAGCAAGGACGGGACGCCAATCGAGTCACGGTTCCCTTCATTGGAAGAGCTAGATGCTCAGTTCTCGGCCAC TTCATTGTACCCAGCGTCTGCGCAGGCTAACGACCGATTCGCCAGCCGATCAACGCCTACCGTTGCGCCTTCGCT ACCCCCTCGCCCGAGTGCAAATGTGCCCAAGGAAGATCCTGAACGTCCTTCTCGTTTCAACGCTCCGCCGTCCGC TCCTCCGACTTTGGATTCTCTGGAGAAGAAATATGAAGCGACCTCTGTCAGGAACGACTGGAAGTCATCACCATC GACACGCAGTGCGGTTGAGAGCAGGACGGAATCCTCGCCAGCTAAGCTCCCAAGCGGTTCGGCGACAATGAGGTT CGCTATGGAGGAATTGAAGTCTACCCAGTCATCTTCGGGCACGTCGCAATCTACCAAATTGTCGTCGAACCGACC ACCCTCTCCCTCGAAGCATTCACGAACCGCACCTGCGCCTGATTGGCTCACTGGAGACGGCGATGTTACCGAAAA CACCATTGAGAAGGCCACCACTGGACCTGTTGTTCGCGATACGCCAGCCAAGAGAGCTTCCGTCATCTTGAAAAA TGACTTCAAGATCCAAGAACCTGTCACTGCGCAGTACGATACAACGCCAGTGATACGCCCAGAAAAGTCCCTTCA TCCAGAAGAATCACCCACTGTCGCACGGTTCACGAAGAATTTCCCTGCCATTGACACTGCGTCTGCGAATGAGCT CTTGATCCAGAACGAGCCGTTGACGGATAATTGGAGCCCAATTGTTGCGAGCAAACCTCCGCCCCAACTTCCCCG CAGGCCGTCCAAAAAGGAACTCGAAGCCGCAGAGTCTGCTTCGAGTGCTGACGATGATGAGGGGCCGGAGGACCT TGGTGGTTTGACCAGCCCGCCCAAGAAGATGGGCAGTCTACGAGCTTCGCGACACAAGGGGCGGCAAAGCTCTGT ACATGAGCTTGTTGATCTGTGGGGAGGCAAAGGGCCTGCTAAAGACAGACCTCGCGATGAACCTTCTTCGCCATT GAAGGCGGCATCTGCGGAGAAACCTGTTACTAGACCAAAGCCTCGACCAACATCCTTACTGCCGCCTCAGCGTAC TCCTTCGTTCAGCATGCGATCTGTCAGTGGTGGTGCAAGGATATCACCCATCCAGCGAGTTCCTTCACCGCAGCC GTCGCCCAGCCTTCCGGAAAAGTCGCCACCGCTCCACTCCCCTCCCATTACCACGTCTCCCTCCAGCGGTACCGG TCGATCCCGCCCTCAGTCTATGTTCATCTTTCCTTCCAAATCCACCGATGCATTACCGAGCCCATCTCAACCTAC GGGGATGGGACCTCCGCCTGAGGAAGGCACGCAGCGCCCAGCCCGTCGCCAAACGTCGATATCGAACATGGTGCA ACGATATGAGGCCATTGGCGGTAAAGTGATTGCCCCTCAGCAAGCCGCTCCATCACCCGTTACTCGTAAACCGAG TCTTAACCTCAATAAGAGCTCTGTGCCCCCCAATCAAGTCGAAACTGGGCGTATCAAGGTCTTACCTGTGCCTGA CAAGGTACCTGCGATTGCACCGAAGGACGAATTCAGACCTGCTTGGATATCCGGGGAGGCGGCTCGAACACGCAC AACCTCGACTGGTCCTCTGAAAGCCAGTCTGGACATCCCTCGCACGACGGTCAAACCCCAGCGGGTGTCACCTAT CGAACGTAAGCCAACCGGGTCACCCAAGAAGAACCTCGTTGGTCTGCCTTCGATTACCACAACCACGAATGCTGT CGTTTTCCCGAAGCGCAGACCGACGTTGCCGTCGGAAGATGTCCTGTCACCTCCTGCTTCGAACAGCGATGATCG ATCAGTATCTCCTGAAAGGCCATATCAAGGTGTAGGGAAGCTCATTGATCAATGGCAGCGCAAATCCGAAGAGAG CGAGGGCTTCCATGGCAGGCCGCCTATAAAACGAGCCGGCCTCGTTCAAGGCAATCGTGGATAG |
| Length | 4114 |