CC1G_09382
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09382 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NB22 | Functional description | Other/FunK1 protein kinase |
| Location | Chr_9:320169..321974 | Strand | + |
| Gene length (nt) | 1806 | Transcript length (nt) | 1671 |
| CDS length (nt) | 1671 | Protein length (aa) | 556 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_9261 | 27 | 4.958E-41 | 165 |
| Lentinula edodes NBRC 111202 | Lenedo1_1236159 | 28.7 | 1.01E-40 | 164 |
| Schizophyllum commune H4-8 | Schco3_2505559 | 24.4 | 1.908E-39 | 160 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8024 |
| Description | Other/FunK1 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 106 | 270 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR040976 | Fungal-type protein kinase |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | other FunK1 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
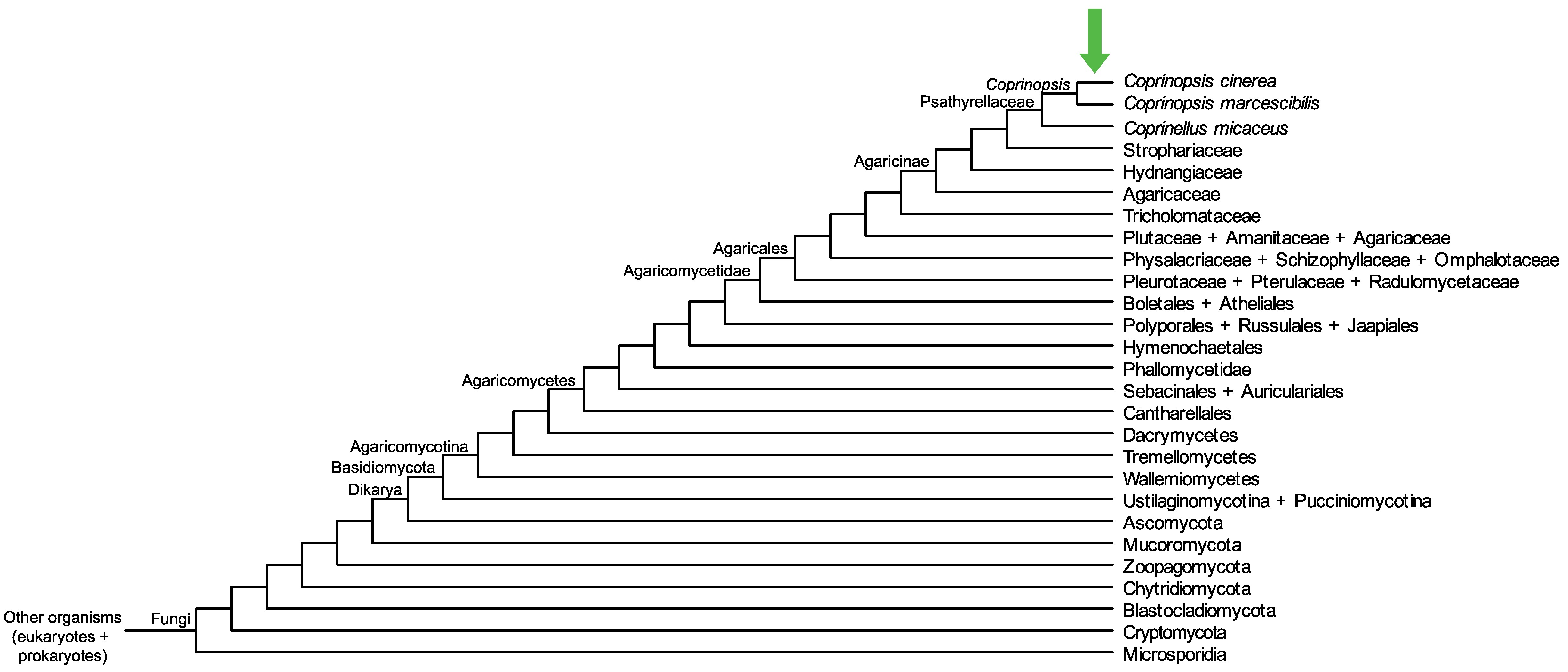
Conservation of CC1G_09382 across fungi.
Arrow shows the origin of gene family containing CC1G_09382.
Protein
| Sequence id | 8024 |
|---|---|
| Sequence |
>8024 MTEMQIQHRLFADVRAFRDSDWQKSPAVKDYGEEELNLLADALDGDRFKRFFCCILDKYVGKPSRSLCPKGSIET NVFPEYKAFKSHNSGEFLPSIRTGQSTAKPKTLKKAEDANLTRAFDPRRQCRFIMESVCTPLSQVETLGEAVDII KVLMTGLRIMFCAGWIHRDISPGNILAWRASESEPWQAKLSDLEYSKKLPYTGPASRDPKTGTPYFMPCEVLKGA YFLPRSTVNYRDDNESGAKPAWDKENSVTPNYQHDLESIWWILLWKSTARAWEDAPIERDIYVFQKRVTDMYTNA RAACFRVPLGDEAKIMSHVPPRLELFVGQHLDFLRSSLYYEYESRAKEDRDNIGSYSWVMSKPFTRFFARVEESR EEWGSLKLVVDKQVRKMEDLELVSHTDTDEPSTPAGETIGVSEEGEATNIEHNERAQGSEQDVADPDIEESTSRP MKPSGKKRKATDVEEDKVVDGRGTAAIHRAEEDGDVDDKAQSRRTSKRLRSARADTQEKLADTHIGRVTRSMTKA TTATTQGGSAANTDSVKQNHGLSKQKKNTRR |
| Length | 556 |
Coding
| Sequence id | CC1G_09382T0 |
|---|---|
| Sequence |
>CC1G_09382T0 ATGACTGAGATGCAAATTCAGCACAGACTGTTTGCGGATGTCAGGGCCTTTCGTGACTCGGATTGGCAGAAGAGT CCTGCGGTGAAGGACTACGGCGAAGAGGAATTAAATCTCCTGGCCGATGCGCTGGACGGTGACAGGTTTAAGAGG TTCTTTTGCTGCATCCTGGACAAGTATGTCGGAAAGCCCTCTCGTTCGCTTTGCCCTAAGGGGTCAATCGAAACG AATGTGTTTCCTGAATACAAAGCGTTCAAGAGCCACAACAGTGGCGAGTTCCTCCCTTCAATTCGTACAGGCCAG AGCACGGCAAAGCCAAAGACATTGAAGAAAGCGGAAGATGCCAACCTCACCCGCGCCTTTGATCCTCGAAGACAG TGTCGCTTCATTATGGAATCGGTATGCACCCCTCTCAGCCAAGTTGAGACTTTGGGCGAGGCTGTTGATATTATA AAGGTGCTTATGACCGGTCTCCGTATTATGTTCTGCGCGGGCTGGATTCACAGAGACATTAGTCCAGGCAACATC CTTGCTTGGCGCGCGTCAGAAAGCGAGCCATGGCAAGCCAAGCTCTCCGATCTCGAGTATTCGAAGAAACTCCCT TACACTGGGCCAGCTAGCCGGGACCCTAAGACTGGAACACCGTATTTCATGCCCTGTGAGGTTCTAAAAGGGGCA TATTTCCTTCCCCGTTCCACCGTCAACTATAGGGATGACAACGAGTCAGGGGCGAAACCAGCCTGGGATAAGGAA AACAGTGTTACCCCAAATTACCAACACGACTTGGAGTCCATCTGGTGGATTCTTCTGTGGAAGTCCACGGCAAGG GCCTGGGAAGACGCTCCAATTGAGCGAGACATCTATGTCTTCCAGAAGAGGGTAACAGACATGTACACAAATGCT CGGGCGGCTTGTTTTCGGGTTCCACTTGGCGATGAGGCTAAAATTATGAGCCACGTCCCCCCGCGACTGGAATTG TTTGTCGGGCAGCACCTAGATTTTTTACGATCTAGCCTGTACTATGAGTACGAATCTCGCGCCAAAGAGGACAGA GACAATATCGGGTCTTACTCTTGGGTTATGAGTAAGCCGTTCACAAGATTTTTCGCCAGAGTTGAAGAGTCGCGG GAGGAGTGGGGGAGTCTCAAATTAGTGGTGGACAAACAGGTCAGGAAGATGGAGGACTTGGAGTTAGTCAGCCAT ACGGATACTGACGAGCCCAGCACACCTGCGGGGGAAACCATTGGAGTTTCTGAGGAAGGAGAAGCTACAAACATA GAACACAATGAGAGAGCTCAAGGTAGCGAGCAAGATGTCGCTGATCCAGATATCGAGGAATCAACCAGCCGACCA ATGAAGCCATCGGGAAAGAAGAGAAAGGCTACCGACGTAGAAGAAGACAAGGTCGTTGATGGTCGCGGGACTGCA GCAATTCACAGGGCCGAGGAAGATGGTGATGTTGACGACAAAGCGCAGTCGAGGCGTACGTCGAAGAGGCTCCGC TCGGCACGGGCAGACACACAAGAGAAACTGGCGGATACGCACATTGGAAGGGTGACTAGGTCGATGACCAAGGCC ACGACAGCGACCACGCAAGGAGGCAGTGCCGCCAACACCGATAGCGTCAAACAAAACCACGGACTTTCGAAACAG AAGAAGAATACGCGCCGC |
| Length | 1671 |
Transcript
| Sequence id | CC1G_09382T0 |
|---|---|
| Sequence |
>CC1G_09382T0 ATGACTGAGATGCAAATTCAGCACAGACTGTTTGCGGATGTCAGGGCCTTTCGTGACTCGGATTGGCAGAAGAGT CCTGCGGTGAAGGACTACGGCGAAGAGGAATTAAATCTCCTGGCCGATGCGCTGGACGGTGACAGGTTTAAGAGG TTCTTTTGCTGCATCCTGGACAAGTATGTCGGAAAGCCCTCTCGTTCGCTTTGCCCTAAGGGGTCAATCGAAACG AATGTGTTTCCTGAATACAAAGCGTTCAAGAGCCACAACAGTGGCGAGTTCCTCCCTTCAATTCGTACAGGCCAG AGCACGGCAAAGCCAAAGACATTGAAGAAAGCGGAAGATGCCAACCTCACCCGCGCCTTTGATCCTCGAAGACAG TGTCGCTTCATTATGGAATCGGTATGCACCCCTCTCAGCCAAGTTGAGACTTTGGGCGAGGCTGTTGATATTATA AAGGTGCTTATGACCGGTCTCCGTATTATGTTCTGCGCGGGCTGGATTCACAGAGACATTAGTCCAGGCAACATC CTTGCTTGGCGCGCGTCAGAAAGCGAGCCATGGCAAGCCAAGCTCTCCGATCTCGAGTATTCGAAGAAACTCCCT TACACTGGGCCAGCTAGCCGGGACCCTAAGACTGGAACACCGTATTTCATGCCCTGTGAGGTTCTAAAAGGGGCA TATTTCCTTCCCCGTTCCACCGTCAACTATAGGGATGACAACGAGTCAGGGGCGAAACCAGCCTGGGATAAGGAA AACAGTGTTACCCCAAATTACCAACACGACTTGGAGTCCATCTGGTGGATTCTTCTGTGGAAGTCCACGGCAAGG GCCTGGGAAGACGCTCCAATTGAGCGAGACATCTATGTCTTCCAGAAGAGGGTAACAGACATGTACACAAATGCT CGGGCGGCTTGTTTTCGGGTTCCACTTGGCGATGAGGCTAAAATTATGAGCCACGTCCCCCCGCGACTGGAATTG TTTGTCGGGCAGCACCTAGATTTTTTACGATCTAGCCTGTACTATGAGTACGAATCTCGCGCCAAAGAGGACAGA GACAATATCGGGTCTTACTCTTGGGTTATGAGTAAGCCGTTCACAAGATTTTTCGCCAGAGTTGAAGAGTCGCGG GAGGAGTGGGGGAGTCTCAAATTAGTGGTGGACAAACAGGTCAGGAAGATGGAGGACTTGGAGTTAGTCAGCCAT ACGGATACTGACGAGCCCAGCACACCTGCGGGGGAAACCATTGGAGTTTCTGAGGAAGGAGAAGCTACAAACATA GAACACAATGAGAGAGCTCAAGGTAGCGAGCAAGATGTCGCTGATCCAGATATCGAGGAATCAACCAGCCGACCA ATGAAGCCATCGGGAAAGAAGAGAAAGGCTACCGACGTAGAAGAAGACAAGGTCGTTGATGGTCGCGGGACTGCA GCAATTCACAGGGCCGAGGAAGATGGTGATGTTGACGACAAAGCGCAGTCGAGGCGTACGTCGAAGAGGCTCCGC TCGGCACGGGCAGACACACAAGAGAAACTGGCGGATACGCACATTGGAAGGGTGACTAGGTCGATGACCAAGGCC ACGACAGCGACCACGCAAGGAGGCAGTGCCGCCAACACCGATAGCGTCAAACAAAACCACGGACTTTCGAAACAG AAGAAGAATACGCGCCGCTAA |
| Length | 1671 |
Gene
| Sequence id | CC1G_09382T0 |
|---|---|
| Sequence |
>CC1G_09382T0 ATGACTGAGATGCAAATTCAGCACAGACTGTTTGCGGATGTCAGGGCCTTTCGTGACTCGGATTGGCAGAAGAGT CCTGCGGTGAAGGACTACGGCGAAGAGGAATTAAATCTCCTGGCCGATGCGCTGGACGGTGACAGGTTTAAGAGG TTCTTTTGCTGCATCCTGGACAAGTATGTCGGAAAGCCCTCTCGTTCGCTTTGCCCTAAGGGGTCAATCGAAACG AATGTGTTTCCTGAATACAAAGCGTTCAAGAGCCACAACAGTGGCGAGTTCCTCCCTTCAATTCGTACAGGCCAG AGCACGGCAAAGCCAAAGACATTGAAGAAAGCGGAAGATGCCAACCTCACCCGCGCCTTTGATCCTCGAAGACAG TGTCGCTTCATTATGGAATCGGTATGCACCCCTCTCAGCCAAGTTGAGACTTTGGGCGAGGCTGTTGATATTATA AAGGTGCTTATGACCGGTGAGTGGCATCAACATTCACTAAAACCAACAACAATTCATGCTAACGATCTCGTTCCT CATTAACCAATCCAACCAGGTCTCCGTATTATGTTCTGCGCGGGCTGGATTCACAGAGACATTAGTCCAGGCAAC ATCCTTGCTTGGCGCGCGTCAGAAAGCGAGCCATGGCAAGCCAAGCTCTCCGATCTCGAGTATTCGAAGAAACTC CCTTACACTGGGCCAGCTAGCCGGGACCCTAAGACTGTAAGTGACATCGTGTACATTTTATTCTAAATGACTCTG ACACTGGCCATGGGACAGGGAACACCGTATTTCATGCCCTGTGAGGTTCTAAAAGGGGCATATTTCCTTCCCCGT TCCACCGTCAACTATAGGGATGACAACGAGTCAGGGGCGAAACCAGCCTGGGATAAGGAAAACAGTGTTACCCCA AATTACCAACACGACTTGGAGTCCATCTGGTGGATTCTTCTGTGGAAGTCCACGGCAAGGGCCTGGGAAGACGCT CCAATTGAGCGAGACATCTATGTCTTCCAGAAGAGGGTAACAGACATGTACACAAATGCTCGGGCGGCTTGTTTT CGGGTTCCACTTGGCGATGAGGCTAAAATTATGAGCCACGTCCCCCCGCGACTGGAATTGTTTGTCGGGCAGCAC CTAGATTTTTTACGATCTAGCCTGTACTATGAGTACGAATCTCGCGCCAAAGAGGACAGAGACAATATCGGGTCT TACTCTTGGGTTATGAGTAAGCCGTTCACAAGATTTTTCGCCAGAGTTGAAGAGTCGCGGGAGGAGTGGGGGAGT CTCAAATTAGTGGTGGACAAACAGGTCAGGAAGATGGAGGACTTGGAGTTAGTCAGCCATACGGATACTGACGAG CCCAGCACACCTGCGGGGGAAACCATTGGAGTTTCTGAGGAAGGAGAAGCTACAAACATAGAACACAATGAGAGA GCTCAAGGTAGCGAGCAAGATGTCGCTGATCCAGATATCGAGGAATCAACCAGCCGACCAATGAAGCCATCGGGA AAGAAGAGAAAGGCTACCGACGTAGAAGAAGACAAGGTCGTTGATGGTCGCGGGACTGCAGCAATTCACAGGGCC GAGGAAGATGGTGATGTTGACGACAAAGCGCAGTCGAGGCGTACGTCGAAGAGGCTCCGCTCGGCACGGGCAGAC ACACAAGAGAAACTGGCGGATACGCACATTGGAAGGGTGACTAGGTCGATGACCAAGGCCACGACAGCGACCACG CAAGGAGGCAGTGCCGCCAACACCGATAGCGTCAAACAAAACCACGGACTTTCGAAACAGAAGAAGAATACGCGC CGCTAA |
| Length | 1806 |