CC1G_09560
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09560 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P961 | Functional description | Other/FunK1 protein kinase |
| Location | Chr_11:357628..360747 | Strand | + |
| Gene length (nt) | 3120 | Transcript length (nt) | 2724 |
| CDS length (nt) | 2724 | Protein length (aa) | 907 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits | |
|---|---|---|---|---|---|
| No records | |||||
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8173 |
| Description | Other/FunK1 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 175 | 524 |
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 658 | 693 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
| IPR040976 | Fungal-type protein kinase |
GO
| Go id | Term | Ontology |
|---|---|---|
| No records | ||
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| H | other FunK1 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
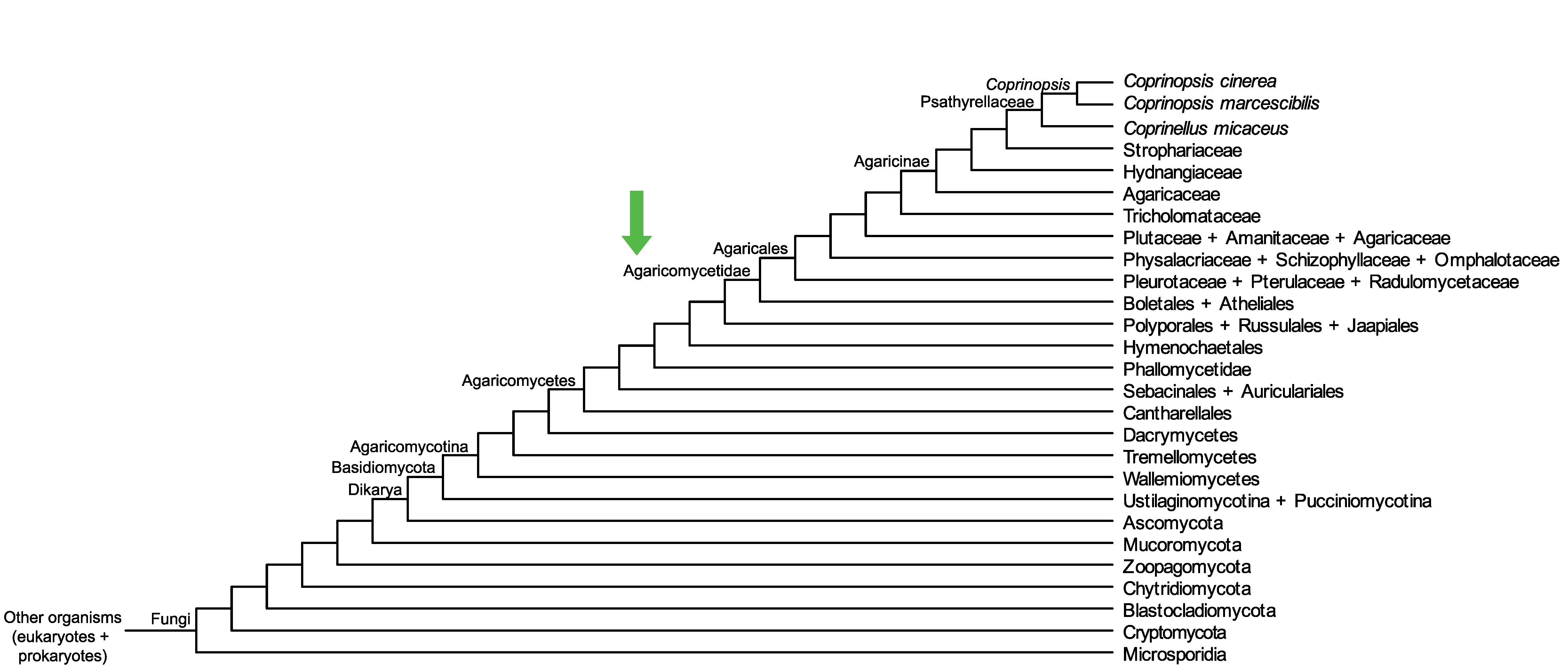
Conservation of CC1G_09560 across fungi.
Arrow shows the origin of gene family containing CC1G_09560.
Protein
| Sequence id | 8173 |
|---|---|
| Sequence |
>8173 MTVSTAATVAKDVEKAVKEDLEHNVRVCELQEFVNRLFPVNRDKLANIVAKLKRSHLLSESGWTGLPEQPGGAEI HYYKPYTEILEAITSAALRCGSEDEDHVPSIWLDRYESPPQSNVENASKLRPDLNNLIFDPSIDTKKQLADCLEE ACGAEASSSDDARASKRAKTQGESKSAQSLVVSWLRTRGVAEIKAKYEQVGKTAVQLGTYLRQMLREQHDRRFVF GFIFFHRSLSIWYCDRSGLLGADRVINIDRNPELFIQVMASFASMGAERLGFDPNMKMVVPGCAPAFSYALPFHR IPKQRHRLHWQIKIDGVIYQTVEILSVARSEIMCGRATLVWRAVRLDELESSEPELVIIKQSWRLHMPGGLSELE VYQLLGDFGGRAATCSGEDVPGSHTADHLRRGLESKASTLDDSQTTEVHDLPPDEHLLHKAQPRVGKGAAKYMPR VQHRMIIRLNGLPIKMFGGVCELFGVVIDVLKDYEYAYYEKGICHRDISMGNIVIECVKRLGRLIDFDHAKTLPG YTPKQVSSLQNEFAEHMAELHRFREWNELPRLSDNLVLLLLYLAKTDASKVSLVDWNNPKIAANQVQSLSDHVTA GLQLENIEGEIKISHILPSLGDDVGASASTIGVLLKKLISVLQPYLPPNFTERRQIHTFVTGTVPFMAHDLNIRD VVHTARHDMESILWILVYLGITRDGVGGASRPQPQTMDGLLYEAASLRYWLFESTGGEMTHFETKKAFLDSSPTG LDQYVFRYFHEDLRLLKVVIIKWTDILRRARGGDLLCKFYTPMAFRQAAEEVKAGIHRAMDNLDAGDLSDEDLRL IQSALERHNATVETQKLHMDNLLRAGIELVRSATAEHARDEEEENDTTTPTNERPKIFDMSPCGKLDERTAGRTP NFQQGGR |
| Length | 907 |
Coding
| Sequence id | CC1G_09560T0 |
|---|---|
| Sequence |
>CC1G_09560T0 ATGACCGTGTCCACTGCTGCAACGGTAGCCAAGGATGTAGAGAAAGCCGTCAAGGAAGACCTTGAACACAACGTC CGCGTTTGCGAGCTTCAGGAGTTCGTGAACCGACTTTTCCCCGTCAACCGCGACAAGCTCGCCAACATTGTCGCC AAGCTCAAGCGGTCCCACTTGCTCTCGGAATCAGGCTGGACCGGCCTTCCCGAACAGCCAGGCGGGGCAGAGATC CACTACTACAAGCCCTATACCGAGATTCTTGAAGCCATAACGAGTGCGGCGCTGCGTTGCGGTTCAGAGGACGAG GACCACGTGCCAAGTATCTGGCTAGATCGCTATGAGTCTCCACCACAGTCTAATGTCGAGAACGCCAGCAAGTTG CGCCCAGATTTGAATAATCTGATTTTTGACCCCAGTATCGACACGAAGAAGCAACTCGCCGATTGTCTGGAGGAG GCATGTGGGGCAGAAGCGAGTAGCAGCGATGATGCCAGGGCATCGAAGCGTGCCAAAACACAAGGAGAATCCAAG TCTGCGCAGTCCTTGGTTGTCTCATGGCTCAGAACTCGCGGTGTCGCCGAAATCAAGGCGAAATATGAGCAAGTT GGGAAGACAGCGGTTCAGCTGGGAACCTACCTTCGGCAGATGCTGCGAGAGCAGCACGATCGCCGTTTTGTTTTC GGTTTCATCTTCTTCCACCGTTCACTGTCAATCTGGTACTGTGACCGCTCAGGTCTCCTTGGAGCCGACCGGGTT ATCAACATCGACAGGAATCCGGAACTTTTCATCCAGGTTATGGCCAGCTTTGCATCGATGGGCGCGGAGCGTCTG GGATTCGATCCAAATATGAAGATGGTCGTGCCTGGCTGTGCCCCTGCCTTCAGCTATGCTCTGCCCTTCCACCGG ATCCCCAAGCAACGACATAGGCTCCACTGGCAAATCAAGATCGATGGCGTGATTTACCAAACCGTCGAGATCTTG AGCGTGGCTCGGTCTGAAATCATGTGTGGCCGAGCAACACTTGTATGGCGGGCGGTGCGACTTGATGAGCTCGAA TCTTCTGAGCCGGAATTGGTTATCATCAAGCAATCGTGGCGACTGCACATGCCAGGTGGTCTCAGTGAGCTCGAA GTCTACCAGCTGCTTGGCGATTTTGGAGGGCGTGCGGCGACTTGCAGCGGGGAGGATGTCCCAGGCTCCCACACT GCGGACCACCTTCGTCGTGGACTCGAATCCAAGGCATCCACGCTGGACGATTCACAAACGACAGAAGTGCACGAC CTCCCTCCTGATGAACATTTGCTCCACAAGGCGCAACCTCGAGTTGGCAAAGGGGCGGCCAAGTACATGCCTCGT GTCCAGCATCGTATGATCATTCGGCTGAATGGCCTTCCGATCAAGATGTTTGGTGGCGTTTGCGAGCTATTTGGG GTGGTCATCGACGTGCTCAAAGATTACGAATATGCCTACTATGAAAAGGGTATATGTCATCGAGACATCAGCATG GGGAACATTGTCATCGAATGCGTAAAGCGCTTGGGGAGGCTCATTGACTTTGACCACGCTAAGACCCTTCCTGGC TACACTCCCAAACAAGTTTCGTCCCTCCAGAACGAATTTGCTGAGCACATGGCGGAGCTTCACCGATTTCGTGAA TGGAATGAGCTTCCTCGTCTGTCTGACAACCTTGTGTTGTTGCTCCTATACCTGGCCAAAACAGATGCCTCCAAG GTCTCACTGGTTGATTGGAACAACCCCAAGATCGCCGCCAACCAGGTCCAAAGTCTTTCAGACCACGTGACTGCG GGCCTTCAGCTCGAGAACATAGAGGGCGAAATCAAGATATCCCATATACTCCCGTCCTTGGGTGACGATGTAGGT GCTTCTGCGTCTACTATCGGCGTGCTTCTAAAAAAGCTTATCTCTGTCCTCCAGCCATACCTCCCTCCCAATTTC ACTGAGAGACGACAGATCCATACGTTTGTCACGGGCACGGTACCGTTCATGGCCCATGACCTCAATATCAGGGAC GTCGTACACACCGCCAGACACGACATGGAGTCGATCCTGTGGATTCTGGTTTACCTGGGCATTACACGGGATGGC GTGGGGGGAGCCAGTCGCCCTCAGCCTCAAACAATGGATGGTCTGCTGTATGAGGCGGCATCCCTGCGCTACTGG CTTTTCGAGTCGACGGGCGGGGAAATGACCCACTTTGAAACAAAAAAGGCCTTTCTTGACTCATCGCCTACCGGA CTCGACCAGTATGTCTTCCGCTACTTCCACGAAGACCTGCGGCTTTTGAAGGTCGTTATCATCAAGTGGACGGAC ATTTTACGCCGCGCTCGCGGAGGCGATTTACTCTGCAAATTTTACACCCCAATGGCCTTCCGTCAAGCTGCGGAG GAGGTGAAGGCCGGCATCCACCGCGCGATGGACAATCTCGATGCTGGTGACCTCAGCGACGAGGATCTCCGACTC ATTCAAAGCGCCCTTGAGCGTCACAATGCGACCGTCGAAACTCAGAAGCTCCATATGGACAACCTCCTCCGAGCT GGCATTGAGCTCGTGCGGAGCGCAACTGCTGAACATGCGCGGGACGAAGAGGAAGAGAACGACACCACGACCCCA ACGAATGAGCGCCCAAAGATCTTCGACATGAGCCCTTGCGGAAAGCTCGACGAGCGTACTGCTGGGAGGACGCCT AACTTCCAACAGGGTGGTCGT |
| Length | 2724 |
Transcript
| Sequence id | CC1G_09560T0 |
|---|---|
| Sequence |
>CC1G_09560T0 ATGACCGTGTCCACTGCTGCAACGGTAGCCAAGGATGTAGAGAAAGCCGTCAAGGAAGACCTTGAACACAACGTC CGCGTTTGCGAGCTTCAGGAGTTCGTGAACCGACTTTTCCCCGTCAACCGCGACAAGCTCGCCAACATTGTCGCC AAGCTCAAGCGGTCCCACTTGCTCTCGGAATCAGGCTGGACCGGCCTTCCCGAACAGCCAGGCGGGGCAGAGATC CACTACTACAAGCCCTATACCGAGATTCTTGAAGCCATAACGAGTGCGGCGCTGCGTTGCGGTTCAGAGGACGAG GACCACGTGCCAAGTATCTGGCTAGATCGCTATGAGTCTCCACCACAGTCTAATGTCGAGAACGCCAGCAAGTTG CGCCCAGATTTGAATAATCTGATTTTTGACCCCAGTATCGACACGAAGAAGCAACTCGCCGATTGTCTGGAGGAG GCATGTGGGGCAGAAGCGAGTAGCAGCGATGATGCCAGGGCATCGAAGCGTGCCAAAACACAAGGAGAATCCAAG TCTGCGCAGTCCTTGGTTGTCTCATGGCTCAGAACTCGCGGTGTCGCCGAAATCAAGGCGAAATATGAGCAAGTT GGGAAGACAGCGGTTCAGCTGGGAACCTACCTTCGGCAGATGCTGCGAGAGCAGCACGATCGCCGTTTTGTTTTC GGTTTCATCTTCTTCCACCGTTCACTGTCAATCTGGTACTGTGACCGCTCAGGTCTCCTTGGAGCCGACCGGGTT ATCAACATCGACAGGAATCCGGAACTTTTCATCCAGGTTATGGCCAGCTTTGCATCGATGGGCGCGGAGCGTCTG GGATTCGATCCAAATATGAAGATGGTCGTGCCTGGCTGTGCCCCTGCCTTCAGCTATGCTCTGCCCTTCCACCGG ATCCCCAAGCAACGACATAGGCTCCACTGGCAAATCAAGATCGATGGCGTGATTTACCAAACCGTCGAGATCTTG AGCGTGGCTCGGTCTGAAATCATGTGTGGCCGAGCAACACTTGTATGGCGGGCGGTGCGACTTGATGAGCTCGAA TCTTCTGAGCCGGAATTGGTTATCATCAAGCAATCGTGGCGACTGCACATGCCAGGTGGTCTCAGTGAGCTCGAA GTCTACCAGCTGCTTGGCGATTTTGGAGGGCGTGCGGCGACTTGCAGCGGGGAGGATGTCCCAGGCTCCCACACT GCGGACCACCTTCGTCGTGGACTCGAATCCAAGGCATCCACGCTGGACGATTCACAAACGACAGAAGTGCACGAC CTCCCTCCTGATGAACATTTGCTCCACAAGGCGCAACCTCGAGTTGGCAAAGGGGCGGCCAAGTACATGCCTCGT GTCCAGCATCGTATGATCATTCGGCTGAATGGCCTTCCGATCAAGATGTTTGGTGGCGTTTGCGAGCTATTTGGG GTGGTCATCGACGTGCTCAAAGATTACGAATATGCCTACTATGAAAAGGGTATATGTCATCGAGACATCAGCATG GGGAACATTGTCATCGAATGCGTAAAGCGCTTGGGGAGGCTCATTGACTTTGACCACGCTAAGACCCTTCCTGGC TACACTCCCAAACAAGTTTCGTCCCTCCAGAACGAATTTGCTGAGCACATGGCGGAGCTTCACCGATTTCGTGAA TGGAATGAGCTTCCTCGTCTGTCTGACAACCTTGTGTTGTTGCTCCTATACCTGGCCAAAACAGATGCCTCCAAG GTCTCACTGGTTGATTGGAACAACCCCAAGATCGCCGCCAACCAGGTCCAAAGTCTTTCAGACCACGTGACTGCG GGCCTTCAGCTCGAGAACATAGAGGGCGAAATCAAGATATCCCATATACTCCCGTCCTTGGGTGACGATGTAGGT GCTTCTGCGTCTACTATCGGCGTGCTTCTAAAAAAGCTTATCTCTGTCCTCCAGCCATACCTCCCTCCCAATTTC ACTGAGAGACGACAGATCCATACGTTTGTCACGGGCACGGTACCGTTCATGGCCCATGACCTCAATATCAGGGAC GTCGTACACACCGCCAGACACGACATGGAGTCGATCCTGTGGATTCTGGTTTACCTGGGCATTACACGGGATGGC GTGGGGGGAGCCAGTCGCCCTCAGCCTCAAACAATGGATGGTCTGCTGTATGAGGCGGCATCCCTGCGCTACTGG CTTTTCGAGTCGACGGGCGGGGAAATGACCCACTTTGAAACAAAAAAGGCCTTTCTTGACTCATCGCCTACCGGA CTCGACCAGTATGTCTTCCGCTACTTCCACGAAGACCTGCGGCTTTTGAAGGTCGTTATCATCAAGTGGACGGAC ATTTTACGCCGCGCTCGCGGAGGCGATTTACTCTGCAAATTTTACACCCCAATGGCCTTCCGTCAAGCTGCGGAG GAGGTGAAGGCCGGCATCCACCGCGCGATGGACAATCTCGATGCTGGTGACCTCAGCGACGAGGATCTCCGACTC ATTCAAAGCGCCCTTGAGCGTCACAATGCGACCGTCGAAACTCAGAAGCTCCATATGGACAACCTCCTCCGAGCT GGCATTGAGCTCGTGCGGAGCGCAACTGCTGAACATGCGCGGGACGAAGAGGAAGAGAACGACACCACGACCCCA ACGAATGAGCGCCCAAAGATCTTCGACATGAGCCCTTGCGGAAAGCTCGACGAGCGTACTGCTGGGAGGACGCCT AACTTCCAACAGGGTGGTCGTTAA |
| Length | 2724 |
Gene
| Sequence id | CC1G_09560T0 |
|---|---|
| Sequence |
>CC1G_09560T0 ATGACCGTGTCCACTGCTGCAACGGTAGCCAAGGATGTAGAGAAAGCCGTCAAGGAAGACCTTGAACACAACGTC CGCGTTTGCGAGCTTCAGGAGTTCGTGAACCGACTTTTCCCCGTCAACCGCGACAAGCTCGCCAACATTGTCGCC AAGCTCAAGCGGTCCCACTTGCTCTCGGAATCAGGCTGGACCGGCCTTCCCGAACAGCCAGGCGGGGCAGAGATC CACTACTACAAGCCCTATACCGAGATTCTTGAAGCCATAACGAGTGCGGCGCTGCGTTGCGGTTCAGAGGACGAG GACCACGTGCCAAGTATCTGGCTAGATCGCTATGAGTCTCCACCACAGTCTAATGTCGAGAACGCCAGCAAGTTG CGCCCAGATTTGAATAATCTGATTTTTGACCCCAGTATCGACACGAAGAAGCAACTCGCCGATTGTCTGGAGGTC AGTAGTAGGCTTCTCTTCCTTTGGGCAGAGTCTGACGAAAACGTTCAGGAGGCATGTGGGGCAGAAGCGAGTAGC AGCGATGATGCCAGGGCATCGAAGCGTGCCAAAACACAAGGAGAATCCAAGGTGAATCAATCGCCCTTTTACATC TCGATTGACGAGCGCCTCTTTCTAACCCGTTCTCGTTGACGAAGTCTGCGCAGTCCTTGGTTGTCTCATGGCTCA GAACTCGCGGTGTCGCCGAAATCAAGGCGAAATATGAGCAAGTTGGGAAGACAGCGGTTCAGCTGGGAACCTACC TTCGGCAGATGCTGCGAGAGCAGCACGATCGCCGTTTTGTTTTCGGTTTCATCTTCTTCCACCGTTCACTGTCAA TCTGGTACTGTGACCGCTCAGGTCTCCTTGGAGCCGACCGGGTTATCAACATCGACAGGGTATGTGCGCCAGAAT GGTTCACTGCGGCTGTCAACTGGGATCTCACCGATTTACTCTAGAATCCGGAACTTTTCATCCAGGTTATGGCCA GCTTTGCATCGATGGGCGCGGAGCGTCTGGGATTCGATCCAAATATGAAGATGGTCGTGCCTGGCTGTGCCCCTG CCTTCAGCTATGCTCTGCCCTTCCACCGGATCCCCAAGCAACGACATAGGCTCCACTGGCAAATCAAGATCGATG GCGTGATTTACCAAACCGTCGAGATCTTGAGCGTGGCTCGGTCTGAAATCATGTGTGGCCGAGCAACACTTGTAT GGCGGGCGGTGCGACTTGATGAGCTCGAATCTTCTGAGCCGGTAAGATCAACATTCCCGTTCACGACTTTTTTCT TCAGCTGACGGGCTCCATCAGGAATTGGTTATCATCAAGCAATCGTGGCGACTGCACATGCCAGGTGGTCTCAGT GAGCTCGAAGTCTACCAGCTGCTTGGCGATTTTGGAGGGCGTGCGGCGACTTGCAGCGGGGAGGATGTCCCAGGC TCCCACACTGCGGACCACCTTCGTCGTGGACTCGAATCCAAGGCATCCACGCTGGACGATTCACAAACGACAGAA GTGCACGACCTCCCTCCTGATGAACATTTGCTCCACAAGGCGCAACCTCGAGTTGGCAAAGGGGCGGCCAAGTAC ATGCCTCGTGTCCAGCATCGTATGATCATTCGGCTGAATGGCCTTCCGATCAAGATGTTTGGTGGCGTTTGCGAG CTATTTGGGGTGGTCATCGACGTGCTCAAAGGTATGTAACATGTCATGGATTGTGAGGTGTCTTGCGTCTTGACA TTGTTGGGGACAGATTACGAATATGCCTACTATGAAAAGGGTATATGTCATCGAGACATCAGCATGGGGAACATT GTCATCGAATGCGTAAAGCGCTTGGGGAGGCTCATTGACTTTGACCACGCTAAGACCCTTCCTGGCTACACTCCC AAACAAGTTTCGTCCCTCCAGAACGAATTTGCTGAGCACATGGCGGAGCTTCACCGATTTCGTGAATGGAATGAG CTTCCTCGTCTGTCTGACAACCTTGTGTTGTTGCTCCTATACCTGGCCAAAACAGATGCCTCCAAGGTCTCACTG GTTGATTGGAACAACCCCAAGATCGCCGCCAACCAGGTCCAAAGTCTTTCAGACCACGTGACTGCGGGCCTTCAG GTATGTCAATCGCTTGTGATTAACGTCCGGGTTCCTGACCCTTGTCCCTCCAGCTCGAGAACATAGAGGGCGAAA TCAAGATATCCCATATACTCCCGTCCTTGGGTGACGATGTAGGTGCTTCTGCGTCTACTATCGGCGTGCTTCTAA AAAAGCTTATCTCTGTCCTCCAGCCATACCTCCCTCCCAATTTCACTGAGAGACGACAGATCCATACGTTTGTCA CGGTATGCAATTACTTTGGTTATGTCAGCCTCTGAGCTGACACCGGACTTTCAGGGCACGGTACCGTTCATGGCC CATGACCTCAATATCAGGGACGTCGTACACACCGCCAGACACGACATGGAGTCGATCCTGTGGATTCTGGTTTAC CTGGGCATTACACGGGATGGCGTGGGGGGAGCCAGTCGCCCTCAGCCTCAAACAATGGATGGTCTGCTGTATGAG GCGGCATCCCTGCGCTACTGGCTTTTCGAGTCGACGGGCGGGGAAATGACCCACTTTGAAACAAAAAAGGCCTTT CTTGACTCATCGCCTACCGGACTCGACCAGTATGTCTTCCGCTACTTCCACGAAGACCTGCGGCTTTTGAAGGTC GTTATCATCAAGTGGACGGACATTTTACGCCGCGCTCGCGGAGGCGATTTACTCTGCAAATTTTACACCCCAATG GCCTTCCGTCAAGCTGCGGAGGAGGTGAAGGCCGGCATCCACCGCGCGATGGACAATCTCGATGCTGGTGACCTC AGCGACGAGGATCTCCGACTCATTCAAAGCGCCCTTGAGCGTCACAATGCGACCGTCGAAACTCAGAAGCTCCAT ATGGACAACCTCCTCCGAGCTGGCATTGAGCTCGTGCGGAGCGCAACTGCTGAACATGCGCGGGACGAAGAGGAA GAGAACGACACCACGACCCCAACGAATGAGCGCCCAAAGATCTTCGACATGAGCCCTTGCGGAAAGCTCGACGAG CGTACTGCTGGGAGGACGCCTAACTTCCAACAGGGTGGTCGTTAA |
| Length | 3120 |