CC1G_09916
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09916 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NN03 | Functional description | AGC/Akt protein kinase |
| Location | Chr_12:1213716..1215851 | Strand | + |
| Gene length (nt) | 2136 | Transcript length (nt) | 1702 |
| CDS length (nt) | 1671 | Protein length (aa) | 556 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Neurospora crassa | stk-50 |
| Schizosaccharomyces pombe | gad8 |
| Saccharomyces cerevisiae | YMR104C_YPK2 |
| Aspergillus nidulans | AN5973_pkcB |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB26846 | 91.1 | 0 | 1028 |
| Agrocybe aegerita | Agrae_CAA7270851 | 89.3 | 0 | 1015 |
| Schizophyllum commune H4-8 | Schco3_2643711 | 88 | 0 | 998 |
| Lentinula edodes NBRC 111202 | Lenedo1_1258776 | 88.9 | 0 | 997 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_195357 | 88.1 | 0 | 996 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_116625 | 88.1 | 0 | 996 |
| Lentinula edodes B17 | Lened_B_1_1_5835 | 88.7 | 0 | 995 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_6024 | 88.7 | 0 | 995 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1449888 | 88.1 | 0 | 987 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1059520 | 88.1 | 0 | 987 |
| Pleurotus ostreatus PC9 | PleosPC9_1_88836 | 88.1 | 0 | 987 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_107907 | 82.2 | 2.817E-291 | 925 |
| Auricularia subglabra | Aurde3_1_1251965 | 79.2 | 2.296E-276 | 848 |
| Grifola frondosa | Grifr_OBZ78439 | 77.4 | 9.996E-262 | 805 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8461 |
| Description | AGC/Akt protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd11651 | YPK1_N_like | - | 43 | 202 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 209 | 477 |
| Pfam | PF00433 | Protein kinase C terminal domain | IPR017892 | 499 | 540 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR017892 | Protein kinase, C-terminal |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR017441 | Protein kinase, ATP binding site |
| IPR000961 | AGC-kinase, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004674 | protein serine/threonine kinase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K13303 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein kinase C terminal domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
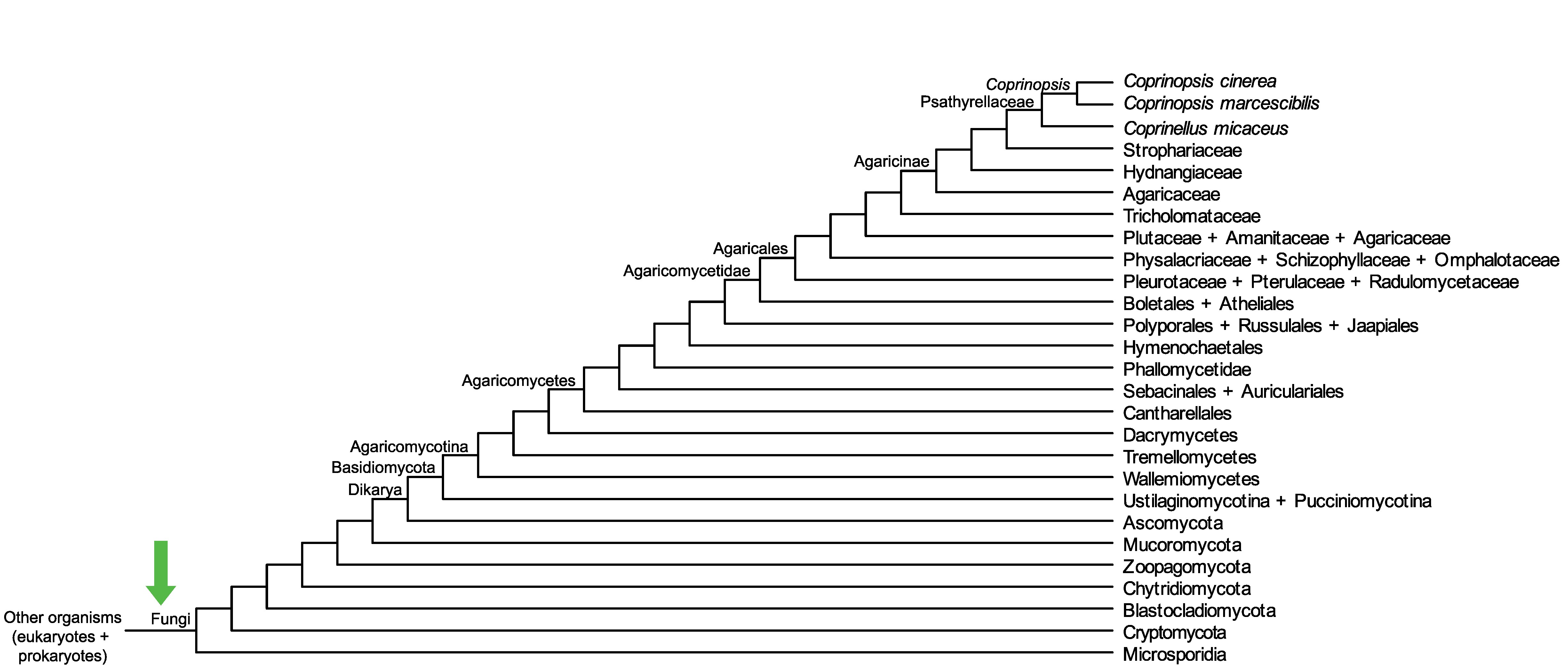
Conservation of CC1G_09916 across fungi.
Arrow shows the origin of gene family containing CC1G_09916.
Protein
| Sequence id | 8461 |
|---|---|
| Sequence |
>8461 MSWKLGVKKSKDTKENGVISRSVTPIPSRPTTPRMSTDGDQFRSGMLTIRIFSGRGLSLAPGVPLPDVIQQALKS APPPRKSTSNRDSIQRKRYWWLPYVVLEFDKNEILIDALGGDLSNPVWNYRADFDVSRTSNISVSSYLRTTAAQG PDDMGNDLLIARVDLTPSLDSQHASDQWYSATAGSGSFHLKIDFKPSRNESLTIDHFDLLKVIGKGSFGKVMQVR KKDTQRIYALKTIRKAHIAQRPGEITHILAERTVLALVNNPFIVPLKFSFQNPDKLYLVMSFVNGGELFYHLQRE GKFDQDRSRFYAAELLCALEHLHGFNVVYRLLDLTRRRDLKPENILLDYTGHIALCDFGLCKLNMSETEKTNTFC GTPEYIAPELLESHGYTKTVDWWTLGVLLYEMMPADQHQTGLPPFYDENVNTMYQRILSDPLQFPPDISPEARSV MTGLLQRNPAHRLGANGGEEIKRHPFFAKYIDWNLLMAKKIQPPFKPSVESVLDVANFDPDFTNEEAQDSVVTDS ALSETVQDQFRGFTYNPANEHLSESVSYPVL |
| Length | 556 |
Coding
| Sequence id | CC1G_09916T0 |
|---|---|
| Sequence |
>CC1G_09916T0 ATGTCCTGGAAATTGGGCGTCAAAAAGTCGAAAGACACCAAGGAGAACGGGGTTATCTCCAGATCTGTTACACCG ATTCCTTCTCGCCCAACAACACCACGAATGTCCACCGATGGCGACCAATTTCGCTCTGGAATGTTGACAATCCGC ATCTTTTCAGGACGTGGATTGTCTCTGGCGCCCGGCGTGCCCCTTCCAGACGTCATTCAACAGGCTCTCAAATCC GCCCCGCCACCGAGAAAGTCGACCAGCAACCGTGATTCGATACAACGCAAGCGTTATTGGTGGTTGCCATATGTT GTCCTCGAGTTCGACAAGAACGAGATTCTAATTGATGCGTTGGGTGGTGACCTGTCCAATCCCGTGTGGAATTAT CGTGCAGATTTCGATGTATCCCGAACATCCAATATTTCTGTCTCTTCGTATCTTCGTACCACCGCCGCTCAGGGG CCAGACGACATGGGGAATGATCTCCTCATTGCCCGCGTTGATCTAACGCCGAGCCTTGACAGCCAGCATGCCTCA GATCAATGGTACTCGGCAACCGCTGGCTCGGGTTCCTTCCACCTTAAGATCGATTTCAAGCCTAGTCGCAACGAG TCGCTCACCATCGACCATTTCGATCTCTTGAAGGTTATCGGCAAGGGAAGCTTTGGAAAGGTCATGCAAGTGCGA AAGAAGGACACCCAACGGATATACGCCCTCAAGACGATTCGAAAAGCCCACATCGCCCAGCGGCCAGGCGAGATC ACCCATATTCTCGCCGAGCGAACTGTCCTCGCTCTCGTCAACAACCCATTCATTGTCCCCCTCAAATTCTCATTC CAGAATCCCGACAAGCTTTACTTGGTCATGTCATTCGTTAACGGGGGAGAGCTGTTCTACCATCTTCAGCGGGAG GGTAAATTTGACCAGGATCGAAGTCGGTTCTACGCTGCCGAGCTCCTATGTGCTCTGGAGCACTTGCATGGCTTC AATGTCGTCTACCGATTGCTTGATCTCACCCGACGCAGGGATCTGAAACCCGAGAACATCCTGTTGGATTACACC GGCCATATCGCTCTATGTGACTTCGGTCTCTGCAAACTCAACATGTCCGAAACAGAGAAAACAAACACCTTCTGT GGGACCCCTGAGTACATCGCTCCTGAACTGCTGGAAAGCCACGGGTATACGAAAACAGTCGATTGGTGGACACTC GGTGTGTTGCTCTACGAGATGATGCCCGCTGACCAACATCAGACCGGCCTCCCACCATTCTACGATGAGAACGTC AACACTATGTACCAACGAATCCTCTCCGATCCCCTTCAATTCCCTCCTGATATTTCACCGGAAGCGCGAAGCGTG ATGACTGGGCTGTTGCAGAGAAATCCTGCTCACCGATTGGGTGCCAATGGAGGTGAAGAGATCAAGCGACATCCC TTCTTTGCCAAATATATCGACTGGAATCTTTTGATGGCCAAGAAGATCCAGCCACCGTTCAAGCCAAGCGTTGAA TCTGTGCTCGATGTGGCCAACTTTGATCCTGATTTCACTAACGAAGAGGCACAAGACTCGGTCGTCACTGACTCA GCACTATCGGAAACAGTCCAGGATCAATTCAGAGGCTTCACTTACAACCCAGCCAACGAGCATCTCAGCGAGAGC GTTAGCTACCCTGTTCTG |
| Length | 1671 |
Transcript
| Sequence id | CC1G_09916T0 |
|---|---|
| Sequence |
>CC1G_09916T0 CGCCGATACCCGTAACCATCGTTTTTCAACAATGTCCTGGAAATTGGGCGTCAAAAAGTCGAAAGACACCAAGGA GAACGGGGTTATCTCCAGATCTGTTACACCGATTCCTTCTCGCCCAACAACACCACGAATGTCCACCGATGGCGA CCAATTTCGCTCTGGAATGTTGACAATCCGCATCTTTTCAGGACGTGGATTGTCTCTGGCGCCCGGCGTGCCCCT TCCAGACGTCATTCAACAGGCTCTCAAATCCGCCCCGCCACCGAGAAAGTCGACCAGCAACCGTGATTCGATACA ACGCAAGCGTTATTGGTGGTTGCCATATGTTGTCCTCGAGTTCGACAAGAACGAGATTCTAATTGATGCGTTGGG TGGTGACCTGTCCAATCCCGTGTGGAATTATCGTGCAGATTTCGATGTATCCCGAACATCCAATATTTCTGTCTC TTCGTATCTTCGTACCACCGCCGCTCAGGGGCCAGACGACATGGGGAATGATCTCCTCATTGCCCGCGTTGATCT AACGCCGAGCCTTGACAGCCAGCATGCCTCAGATCAATGGTACTCGGCAACCGCTGGCTCGGGTTCCTTCCACCT TAAGATCGATTTCAAGCCTAGTCGCAACGAGTCGCTCACCATCGACCATTTCGATCTCTTGAAGGTTATCGGCAA GGGAAGCTTTGGAAAGGTCATGCAAGTGCGAAAGAAGGACACCCAACGGATATACGCCCTCAAGACGATTCGAAA AGCCCACATCGCCCAGCGGCCAGGCGAGATCACCCATATTCTCGCCGAGCGAACTGTCCTCGCTCTCGTCAACAA CCCATTCATTGTCCCCCTCAAATTCTCATTCCAGAATCCCGACAAGCTTTACTTGGTCATGTCATTCGTTAACGG GGGAGAGCTGTTCTACCATCTTCAGCGGGAGGGTAAATTTGACCAGGATCGAAGTCGGTTCTACGCTGCCGAGCT CCTATGTGCTCTGGAGCACTTGCATGGCTTCAATGTCGTCTACCGATTGCTTGATCTCACCCGACGCAGGGATCT GAAACCCGAGAACATCCTGTTGGATTACACCGGCCATATCGCTCTATGTGACTTCGGTCTCTGCAAACTCAACAT GTCCGAAACAGAGAAAACAAACACCTTCTGTGGGACCCCTGAGTACATCGCTCCTGAACTGCTGGAAAGCCACGG GTATACGAAAACAGTCGATTGGTGGACACTCGGTGTGTTGCTCTACGAGATGATGCCCGCTGACCAACATCAGAC CGGCCTCCCACCATTCTACGATGAGAACGTCAACACTATGTACCAACGAATCCTCTCCGATCCCCTTCAATTCCC TCCTGATATTTCACCGGAAGCGCGAAGCGTGATGACTGGGCTGTTGCAGAGAAATCCTGCTCACCGATTGGGTGC CAATGGAGGTGAAGAGATCAAGCGACATCCCTTCTTTGCCAAATATATCGACTGGAATCTTTTGATGGCCAAGAA GATCCAGCCACCGTTCAAGCCAAGCGTTGAATCTGTGCTCGATGTGGCCAACTTTGATCCTGATTTCACTAACGA AGAGGCACAAGACTCGGTCGTCACTGACTCAGCACTATCGGAAACAGTCCAGGATCAATTCAGAGGCTTCACTTA CAACCCAGCCAACGAGCATCTCAGCGAGAGCGTTAGCTACCCTGTTCTGTAA |
| Length | 1702 |
Gene
| Sequence id | CC1G_09916T0 |
|---|---|
| Sequence |
>CC1G_09916T0 CGCCGATACCCGTAACCATCGTTTTTCAACAATGTCCTGGAAATTGGGCGTCAAAAGTGCGTTTCTTGTCGGTGT CGAGTGCGTTGTGCTCACCGTTGTTGACGTCGTCGAGCAGAGTCGAAAGACACCAAGGAGAACGGGGTTATCTCC AGATCTGTTACACCGATTCCTTCTCGCCCAACAACACCACGAATGTCCACCGATGGCGACCAATTTCGCTCTGGA ATGTTGACAATCCGCATCTTTTCAGGTGAGCACCGTAGCGGACTGCTGTGTGTGCTTCAGCGCCAATTCTGCTTG CAGGACGTGGATTGTCTCTGGCGCCCGGCGTGCCCCTTCCAGACGTCATTCAACAGGCTCTCAAATCCGCCCCGC CACCGAGAAAGTCGACCAGCAACCGTGATTCGATACAACGCAAGCGTTATTGGTGGTTGCCATATGTTGTCCTCG AGTTCGACAAGAACGAGATTCTAATTGATGCGTTGGGTGGTGACCTGTCCAATCCCGTGTGGAATTATCGTGCAG ATTTGTGAGTATTCAGACCACTTTTATGCCTCACAATTGACTCATACACCGTCCAGCGATGTATCCCGAACATCC AATATTTCTGTCTCTTCGTATCTTCGTACCACCGCCGCTCAGGGGCCAGACGACATGGGGAATGATCTCCTCATT GCCCGCGTTGATCTAACGCCGAGCCTTGACAGCCAGGTATTACATCGTCAACCACGACCACCAACTTCACGCACT AAACATTACCCCTCTAGCATGCCTCAGATCAATGGTACTCGGCAACCGCTGGCTCGGGTTCCTTCCACCTTAAGA TCGATTTCAAGCCTAGTCGCAACGAGTCGCTCACCATCGACCATTTCGATCTCTTGAAGGTTATCGGCAAGGGAA GCTTTGGAAAGGTCATGCAAGTGCGAAAGAAGGACACCCAACGGATATACGCCCTCAAGACGATTCGAAAAGCCC ACATCGCCCAGCGGCCAGGCGAGATCACCCATATTCTCGCCGAGCGAACTGTCCTCGCTCTCGTCAACAACCCAT TCATTGTCCCCCTCAAATTCTCATTCCAGAATCCCGACAAGCTTTACTTGGTCATGTCATTCGGTATAGCCCAAT ACTTCCATCCGCGGATTGATGTTCTGACGAAGGTTTCTAGTTAACGGGGGAGAGCTGTTCTACCATCTTCAGCGG GAGGGTAAATTTGACCAGGATCGAAGTCGGTTCTACGCTGCCGAGCTCCTATGTGCTCTGGAGCACTTGCATGGC TTCAATGTCGTCTACCGGTAAGTGCTTCCTGTCCTCTCAGATTGCTTGATCTCACCCGACGCAGGGATCTGAAAC CCGAGAACATCCTGTTGGATTACACCGGCCATATCGCTCTATGTGACTTCGGTCTCTGCAAACTCAACATGTCCG AAACAGAGAAAACAAACAGTATGTCTATCAACGATCTACCAGTACTCACACTCATCCACGCATAGCCTTCTGTGG GACCCCTGAGTACATCGCTCCTGAACTGCTGGAAAGCCACGGGTATACGAAAACAGTCGATTGGTGGACACTCGG TGTGTTGCTCTACGAGATGATGGTGAGAATTTTCCCGCTCTTCCTCCCTTATCTGCAAGCCCGCTGACCAACATC AGACCGGCCTCCCACCATTCTACGATGAGAACGTCAACACTATGTACCAACGAATCCTCTCCGATCCCCTTCAAT TCCCTCCTGATATTTCACCGGAAGCGCGAAGCGTGATGACTGGGCTGTTGCAGAGAAATCCTGCTCACCGATTGG GTGCCAATGGAGGTGAAGAGATCAAGCGACATCCCTTCTTTGCCAAATATATCGACTGGAATCTTTTGATGGCCA AGAAGATCCAGCCACCGTTCAAGCCAAGCGTTGTGAGTTTCCTCTGTCAGCTTTATCATGTTGAATATTCCTGAT CCACGTTTGCAGGAATCTGTGCTCGATGTGGCCAACTTTGATCCTGATTTCACTAACGAAGAGGCACAAGACTCG GTCGTCACTGACTCAGCACTATCGGAAACAGTCCAGGATCAATTCAGAGGCTTCACTTACAACCCAGCCAACGAG CATCTCAGCGAGAGCGTTAGCTACCCTGTTCTGTAA |
| Length | 2136 |