CC1G_10369
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10369 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8PEA2 | Functional description | Exo-beta-1,3-glucanase |
| Location | Chr_7:151654..154757 | Strand | - |
| Gene length (nt) | 3104 | Transcript length (nt) | 2238 |
| CDS length (nt) | 2238 | Protein length (aa) | 745 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits | |
|---|---|---|---|---|---|
| No records | |||||
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8836 |
| Description | Exo-beta-1,3-glucanase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 281 | 488 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 126 | 148 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR017853 | Glycoside hydrolase superfamily |
| IPR001547 | Glycoside hydrolase, family 5 |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| K01210 |
EggNOG
| COG category | Description |
|---|---|
| G | Exo-beta-1,3-glucanase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_9 |
Transcription factor
| Group |
|---|
| No records |
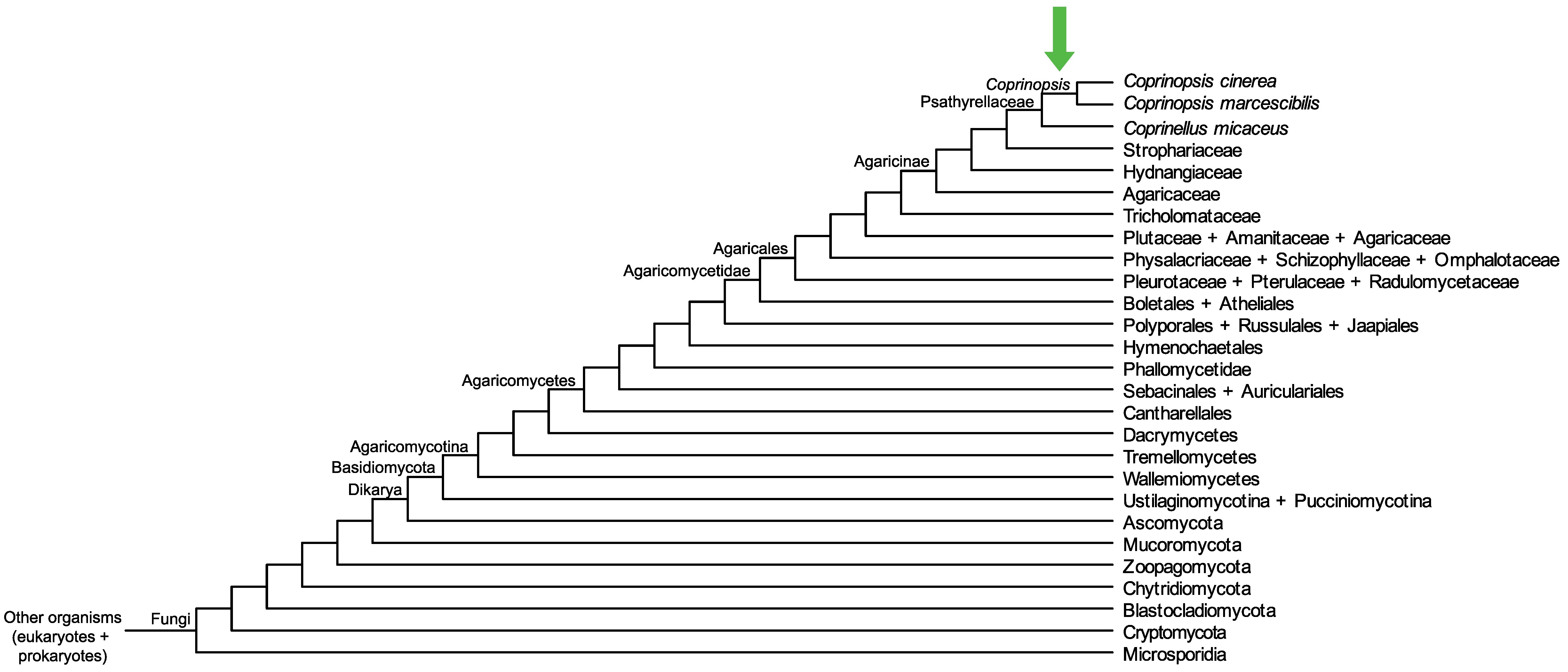
Conservation of CC1G_10369 across fungi.
Arrow shows the origin of gene family containing CC1G_10369.
Protein
| Sequence id | 8836 |
|---|---|
| Sequence |
>8836 MGASFLRVVPGGCTQPPDRKHGDPSRGSLTPRLHVHPWRHSPDLNPRPDSTCVPWIPDPAKSHALKPTYSITSST INTQDHSKRGSLNLESHMWATCNDDKPLYSSDSGPSLSSGKRSARCGRITLVIIGVASVILLGVFLPLHFGVLRS LHHGNTVPLSRGNETNSQPTTHTLLRGGDGSEVTTADGTKFTYRNPFGGFWISDPEDPFNLDAQPNEWTPPLNRS WRWGQDRIFGVNLGGLFVLEPFITPGVFEARPGYVDEYTLSEMMRDGVNGTQGFQDLEEHYKTFITEKDIAEIAG AGLNWLRVPLGFWAVEVYENEPFLERTSWTYFLRIVEWARKYGLRIYLDLHAVPGGQNGMNHSGRVHRISFLAGN MGLANAQRTLYYLRVLTEFISQPQYSSVIPVLGILNEPLSEELGMEALSSFYLEAYTMIRNITGYGEGNGPYIAI GDGLRSPLDWEGLLPNADRVIMDAHPYVAFDRSHDTSPLTDLAEDGEFGGIWPRTACQRWGPLINSTKMALGVTI GGEFSGALNDCGRYIREVGVTSDHPQCPLYDDWENWTDELKAGLQNFILASMDAIGDFFFWTWKIGPSIEGKITA PFWSYKLGLEQGWIPRDPRTSFGKCARLGISSAPFDGTYKPWQTGDFESQPTIPAEYLANNAWPPGTLTRADMPV ALLPTYATTGSVITLPVPTYSGTPASATENLRGWYNDADTRGGVTPIGGCKYPDPYVVKFDVLPTARCGE |
| Length | 745 |
Coding
| Sequence id | CC1G_10369T0 |
|---|---|
| Sequence |
>CC1G_10369T0 ATGGGCGCCTCATTTTTGCGGGTTGTTCCGGGGGGTTGCACACAGCCGCCAGATAGAAAACACGGAGATCCTTCG CGTGGATCTCTTACTCCCCGACTCCATGTGCACCCCTGGCGACACTCGCCGGATCTTAATCCTCGACCGGACAGT ACTTGCGTTCCCTGGATCCCTGATCCCGCAAAATCGCATGCACTAAAGCCTACCTACTCGATAACCAGCTCCACC ATCAACACGCAAGATCATTCAAAACGGGGTTCCTTGAACCTTGAATCCCACATGTGGGCTACTTGTAACGACGAT AAGCCTCTTTACAGCAGCGACAGCGGGCCATCTCTGAGCTCGGGGAAAAGGAGTGCACGGTGCGGGAGAATCACC CTCGTCATCATTGGTGTGGCTTCTGTGATTCTCCTAGGGGTCTTTTTGCCTCTTCATTTTGGAGTCCTTCGATCT TTACACCACGGAAATACAGTCCCACTTTCCCGAGGCAACGAAACAAACAGCCAACCGACTACTCACACATTGCTG CGGGGAGGCGACGGCTCGGAAGTGACCACGGCGGACGGAACCAAATTTACTTATCGCAATCCATTCGGCGGATTC TGGATCTCTGACCCTGAAGACCCCTTTAATCTCGACGCACAGCCGAATGAATGGACCCCACCCCTCAACAGGTCC TGGCGCTGGGGTCAGGATCGAATCTTCGGAGTCAATCTTGGTGGATTGTTCGTCCTCGAGCCGTTCATTACTCCA GGTGTGTTCGAAGCTCGACCAGGATATGTGGACGAGTACACCCTGTCGGAGATGATGCGCGACGGGGTCAATGGC ACCCAGGGATTCCAAGATCTCGAGGAGCATTACAAGACTTTTATCACCGAGAAAGACATCGCTGAGATTGCCGGT GCAGGGCTGAATTGGCTGCGCGTTCCCTTAGGATTTTGGGCTGTCGAGGTATACGAGAACGAACCATTCCTGGAA CGGACTTCTTGGACATATTTCCTACGCATCGTCGAATGGGCAAGAAAGTACGGTTTAAGGATTTACCTCGACCTT CATGCTGTACCTGGTGGTCAAAACGGAATGAATCACTCCGGACGCGTTCACCGGATCAGTTTCCTTGCTGGAAAC ATGGGTCTCGCCAATGCGCAGCGGACCCTCTATTACTTGCGTGTCTTAACCGAATTCATATCCCAGCCTCAGTAC TCGTCTGTCATTCCTGTTCTCGGAATCCTCAATGAGCCACTGTCGGAGGAACTTGGAATGGAGGCGCTGTCTAGC TTTTATCTTGAGGCGTACACGATGATCCGCAACATCACTGGGTACGGCGAAGGAAACGGGCCGTACATTGCTATC GGTGACGGGCTGCGCTCGCCATTGGATTGGGAAGGCCTCCTTCCCAACGCAGATCGTGTTATCATGGATGCGCAT CCATATGTCGCATTCGACCGTAGCCATGACACGTCTCCCCTTACCGATCTCGCTGAAGATGGCGAATTTGGTGGG ATCTGGCCAAGGACCGCTTGTCAGCGATGGGGACCCCTCATCAACTCTACAAAAATGGCTCTGGGCGTCACCATT GGCGGAGAGTTCTCAGGAGCTCTAAACGATTGTGGCCGGTACATTCGCGAAGTTGGTGTCACGTCGGATCACCCC CAATGCCCATTGTATGACGACTGGGAGAACTGGACCGATGAACTCAAGGCGGGACTGCAAAACTTCATCTTGGCG AGTATGGACGCAATCGGTGATTTCTTCTTTTGGACATGGAAGATAGGACCTTCGATCGAAGGGAAGATCACCGCC CCATTTTGGTCGTACAAGCTCGGTTTAGAACAGGGATGGATTCCTCGGGACCCACGCACCTCGTTTGGAAAATGT GCTAGGCTCGGTATCAGCAGCGCGCCGTTCGATGGCACCTACAAGCCCTGGCAGACTGGAGATTTTGAGTCACAG CCGACCATTCCCGCTGAATATCTCGCGAACAACGCTTGGCCGCCTGGGACCCTTACTCGTGCCGATATGCCCGTT GCTTTGCTGCCTACGTATGCTACCACCGGTTCGGTCATCACTCTCCCTGTTCCGACGTACTCTGGTACGCCTGCC TCTGCTACTGAGAACTTGAGGGGATGGTATAACGATGCTGATACTCGAGGGGGAGTGACTCCCATTGGCGGTTGC AAGTACCCTGATCCCTATGTGGTTAAATTCGATGTTCTACCTACGGCTCGGTGCGGAGAA |
| Length | 2238 |
Transcript
| Sequence id | CC1G_10369T0 |
|---|---|
| Sequence |
>CC1G_10369T0 ATGGGCGCCTCATTTTTGCGGGTTGTTCCGGGGGGTTGCACACAGCCGCCAGATAGAAAACACGGAGATCCTTCG CGTGGATCTCTTACTCCCCGACTCCATGTGCACCCCTGGCGACACTCGCCGGATCTTAATCCTCGACCGGACAGT ACTTGCGTTCCCTGGATCCCTGATCCCGCAAAATCGCATGCACTAAAGCCTACCTACTCGATAACCAGCTCCACC ATCAACACGCAAGATCATTCAAAACGGGGTTCCTTGAACCTTGAATCCCACATGTGGGCTACTTGTAACGACGAT AAGCCTCTTTACAGCAGCGACAGCGGGCCATCTCTGAGCTCGGGGAAAAGGAGTGCACGGTGCGGGAGAATCACC CTCGTCATCATTGGTGTGGCTTCTGTGATTCTCCTAGGGGTCTTTTTGCCTCTTCATTTTGGAGTCCTTCGATCT TTACACCACGGAAATACAGTCCCACTTTCCCGAGGCAACGAAACAAACAGCCAACCGACTACTCACACATTGCTG CGGGGAGGCGACGGCTCGGAAGTGACCACGGCGGACGGAACCAAATTTACTTATCGCAATCCATTCGGCGGATTC TGGATCTCTGACCCTGAAGACCCCTTTAATCTCGACGCACAGCCGAATGAATGGACCCCACCCCTCAACAGGTCC TGGCGCTGGGGTCAGGATCGAATCTTCGGAGTCAATCTTGGTGGATTGTTCGTCCTCGAGCCGTTCATTACTCCA GGTGTGTTCGAAGCTCGACCAGGATATGTGGACGAGTACACCCTGTCGGAGATGATGCGCGACGGGGTCAATGGC ACCCAGGGATTCCAAGATCTCGAGGAGCATTACAAGACTTTTATCACCGAGAAAGACATCGCTGAGATTGCCGGT GCAGGGCTGAATTGGCTGCGCGTTCCCTTAGGATTTTGGGCTGTCGAGGTATACGAGAACGAACCATTCCTGGAA CGGACTTCTTGGACATATTTCCTACGCATCGTCGAATGGGCAAGAAAGTACGGTTTAAGGATTTACCTCGACCTT CATGCTGTACCTGGTGGTCAAAACGGAATGAATCACTCCGGACGCGTTCACCGGATCAGTTTCCTTGCTGGAAAC ATGGGTCTCGCCAATGCGCAGCGGACCCTCTATTACTTGCGTGTCTTAACCGAATTCATATCCCAGCCTCAGTAC TCGTCTGTCATTCCTGTTCTCGGAATCCTCAATGAGCCACTGTCGGAGGAACTTGGAATGGAGGCGCTGTCTAGC TTTTATCTTGAGGCGTACACGATGATCCGCAACATCACTGGGTACGGCGAAGGAAACGGGCCGTACATTGCTATC GGTGACGGGCTGCGCTCGCCATTGGATTGGGAAGGCCTCCTTCCCAACGCAGATCGTGTTATCATGGATGCGCAT CCATATGTCGCATTCGACCGTAGCCATGACACGTCTCCCCTTACCGATCTCGCTGAAGATGGCGAATTTGGTGGG ATCTGGCCAAGGACCGCTTGTCAGCGATGGGGACCCCTCATCAACTCTACAAAAATGGCTCTGGGCGTCACCATT GGCGGAGAGTTCTCAGGAGCTCTAAACGATTGTGGCCGGTACATTCGCGAAGTTGGTGTCACGTCGGATCACCCC CAATGCCCATTGTATGACGACTGGGAGAACTGGACCGATGAACTCAAGGCGGGACTGCAAAACTTCATCTTGGCG AGTATGGACGCAATCGGTGATTTCTTCTTTTGGACATGGAAGATAGGACCTTCGATCGAAGGGAAGATCACCGCC CCATTTTGGTCGTACAAGCTCGGTTTAGAACAGGGATGGATTCCTCGGGACCCACGCACCTCGTTTGGAAAATGT GCTAGGCTCGGTATCAGCAGCGCGCCGTTCGATGGCACCTACAAGCCCTGGCAGACTGGAGATTTTGAGTCACAG CCGACCATTCCCGCTGAATATCTCGCGAACAACGCTTGGCCGCCTGGGACCCTTACTCGTGCCGATATGCCCGTT GCTTTGCTGCCTACGTATGCTACCACCGGTTCGGTCATCACTCTCCCTGTTCCGACGTACTCTGGTACGCCTGCC TCTGCTACTGAGAACTTGAGGGGATGGTATAACGATGCTGATACTCGAGGGGGAGTGACTCCCATTGGCGGTTGC AAGTACCCTGATCCCTATGTGGTTAAATTCGATGTTCTACCTACGGCTCGGTGCGGAGAATAG |
| Length | 2238 |
Gene
| Sequence id | CC1G_10369T0 |
|---|---|
| Sequence |
>CC1G_10369T0 ATGGGCGCCTCATTTTTGCGGGTTGTTCCGGGGGGTTGCACGTGAGTTCCTCCCACGGTGGATGGTTCTTTCCGA ACTTTTTAACTTCGCTTTCTCTTCCAAACCCATTCCAGGAGACTTCGACGAATGTAGGGCAGTGAGCTCTCTGGA TCGACTTACGCCTCAATGAGTGGAAGTAGCACCAAACTCTGGATTGCCATGTCATTTCCGAAGGAGCTCCTCTGG CTGACACCTTGCCAATACCGTGGCGGTTAACCTCACGACTTGTTCTGTGTTCCAGACAGCCGCCAGATAGAAAAC ACGGAGATCCTTCGCGTGGATCTCTTACTCCCCGACTCCATGTGCACCCCTGGCGACGTCTGTTGACAATACTGG CTCTGCGATTGCTGACCTCCCCGGCACGATATCTGGCACCAACGCTATGGCGATTAACATTCCTGCTCCTACCCG ACTTCTAACCCTGAGCGCTCGAGCTCCATCATCACCACCAGACTCGCCGGATCTTAATCCTCGACCGGACAGTAC TTGCGTTCCCTGGATCCCTGATCCCGCAAAATCGCATGCACTAAAGCCTACCTACTCGATAACCAGCTCCACCAT CAACACGCAAGATCATTCAAAACGGGGTTCCTTGAACCTTGAATCCCACATGTGGGCTACTTGTAACGACGATAA GCCTCTTTACAGCAGCGACAGCGGGCCATCTCTGAGCTCGGGGAAAAGGAGTGCACGGTGCGGGAGAATCACCCT CGTCATCATTGGTGTGGCTTCTGTGATTCTCCTAGGGGTCTTTTTGCCTCTTCATTTTGGAGTCCTTCGATCTTT ACACCACGGAAATACAGTCCCACTTTCCCGAGGCAACGAAACAAACAGCCAACCGACTACTCACACATTGCTGGT GCGTCTTCACTTCACGCGATTCGCTTGTCTTGACCGGTATCTCATAGCGGGGAGGCGACGGCTCGGAAGTGACCA CGGCGGACGGAACCAAATTTACTTATCGCAATCCATTCGGCGGATTCTGTATGTACTCCTTCGTCCCTCTTCTCT GGTGCCACACTGACGTCTTGGATCCAGGGATCTCTGACCCTGAAGACCCCTTTAATCTCGACGCACAGCCGAATG AATGGACCCCACCCCTCAACAGGTCCTGGCGCTGGGGTCAGGATCGAATCTTCGGAGTCAATCTTGGTGGATTGT TCGTCCTCGAGCCGTTCATTACTCCAGGTGTGTTCGAAGCTCGACCAGGATATGTGGACGAGTACACCCTGTCGG AGATGATGCGCGACGGGGTCAATGGCACCCAGGGATTCCAAGATCTCGAGGAGCATTACAAGACTTTTATCGTAA GTTCTTAATTCCCATAGCACTTGGCCATGGCTGATAGAGCTGTGGGTAGACCGAGAAAGACATCGCTGAGATTGC CGGTGCAGGGCTGAATTGGCTGCGCGTTCCCTTAGGATTTTGGGCTGTCGAGGTATACGAGAACGAACCATTCCT GGAACGGACTTCTTGGACGTGAGTATGATCACTTTCTCTTTTCAAATGACTGACTCACCGCCTTTCTCCCAAGAT ATTTCCTACGCATCGTCGAATGGGCAAGAAAGTACGGTTTAAGGATTTACCTCGACCTTCATGCTGTACCTGGTG GTCAAAACGGTATGTGACAATGTTGTACGACGCCTGTGATCGAAGACTTTAACACGTGCTCTTTAGGAATGAATC ACTCCGGACGGTAGGATTCATTTACGATGTTAGTCTATCAATCCCAAACGCTTCCTGAATTTTCGACAGCGTTCA CCGGATCAGTTTCCTTGCTGGAAACATGGGTCTCGCCAATGCGCAGCGGACCCTCTATTACTTGCGTGTCTTAAC CGAATTCATATCCCAGCCTCAGTACTCGTCTGTCATTCCTGTTCTCGGAATCCTCAATGAGCCACTGTCGGAGGA ACTTGGAATGGAGGCGCTGTCTAGCTTTTATCTTGAGGCGTACACGATGATCCGCAACATCACTGGGTACGGCGA AGGAAACGGGCCGGTGAGTATATCCGGTTCTGCTGCTTAACGTCCCAATTAATACTTATCTGTAGTACATTGCTA TCGGTGACGGGCTGCGCTCGCCATTGGATTGGGAAGGCCTCCTTCCCAACGCAGATCGTGTTATCATGGATGCGC ATCCATATGTCGCATTCGACCGTAGCCATGACACGTCTCCCCTTACCGATCTCGCTGAAGATGGCGAATTTGGTG GGATCTGGCCAAGGACCGCTTGTCAGCGATGGGGACCCCTCATCAACTCTACGTACGTCAGGGCTCAGAAGGTAT CGCTGTTTCGCCGGTCTGATTTCATCAGTAGAAAAATGGCTCTGGGCGTCACCATTGGCGGAGAGTTCTCAGGAG CTCTAAACGATTGTGGCCGGTACATTCGCGAAGTTGGTGTCACGTCGGATCACCCCCAATGCCCATTGTATGACG ACTGGGAGAACTGGACCGATGAACTCAAGGCGGGACTGCAAAACTTCATCTTGGCGAGTATGGACGCAATCGGTG ATTTCTTCTTTTGGACATGGAAGGTCAGGCTCTGTCTAGTCGCCCCTTAAACCTTTTAATATTGACTTATTGCTG TGTTATAGATAGGACCTTCGATCGAAGGGAAGATCACCGCCCCATTTTGGTCGTACAAGCTCGGTTTAGAACAGG GATGGATTCCTCGGGACCCACGCACCTCGTTTGGAAAATGTGCTAGGCTCGGTATCAGCAGCGCGCCGTTCGATG GCACCTACAAGCCCTGGCAGACTGGAGATTTTGAGTCACAGCCGACCATTCCCGCTGAATATCTCGCGAACAACG CTTGGCCGCCTGGGACCCTTACTCGTGCCGATATGCCCGTTGCTTTGCTGCCTACGTATGCTACCACCGGTTCGG TCATCACTCTCCCTGTTCCGACGTACTCTGGTACGCCTGCCTCTGCTACTGAGAACTTGAGGGGATGGTATAACG ATGCTGATACTCGAGGGGGAGTGACTCCCATTGGCGGTTGCAAGTACCCTGATCCCTATGTGGTTAAATTCGATG TTCTACCTACGGCTCGGTGCGGAGAATAG |
| Length | 3104 |