CC1G_10437
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10437 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8PDR8 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_7:399955..402398 | Strand | + |
| Gene length (nt) | 2444 | Transcript length (nt) | 2154 |
| CDS length (nt) | 2154 | Protein length (aa) | 717 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7263661 | 30.4 | 7.971E-70 | 251 |
| Schizophyllum commune H4-8 | Schco3_2510924 | 28.7 | 1.483E-59 | 220 |
| Pleurotus ostreatus PC9 | PleosPC9_1_111721 | 23 | 2.366E-21 | 99 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1086791 | 23.6 | 4.9E-21 | 98 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8893 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 227 | 409 |
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 425 | 558 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
| IPR040976 | Fungal-type protein kinase |
| IPR008266 | Tyrosine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | other FunK1 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
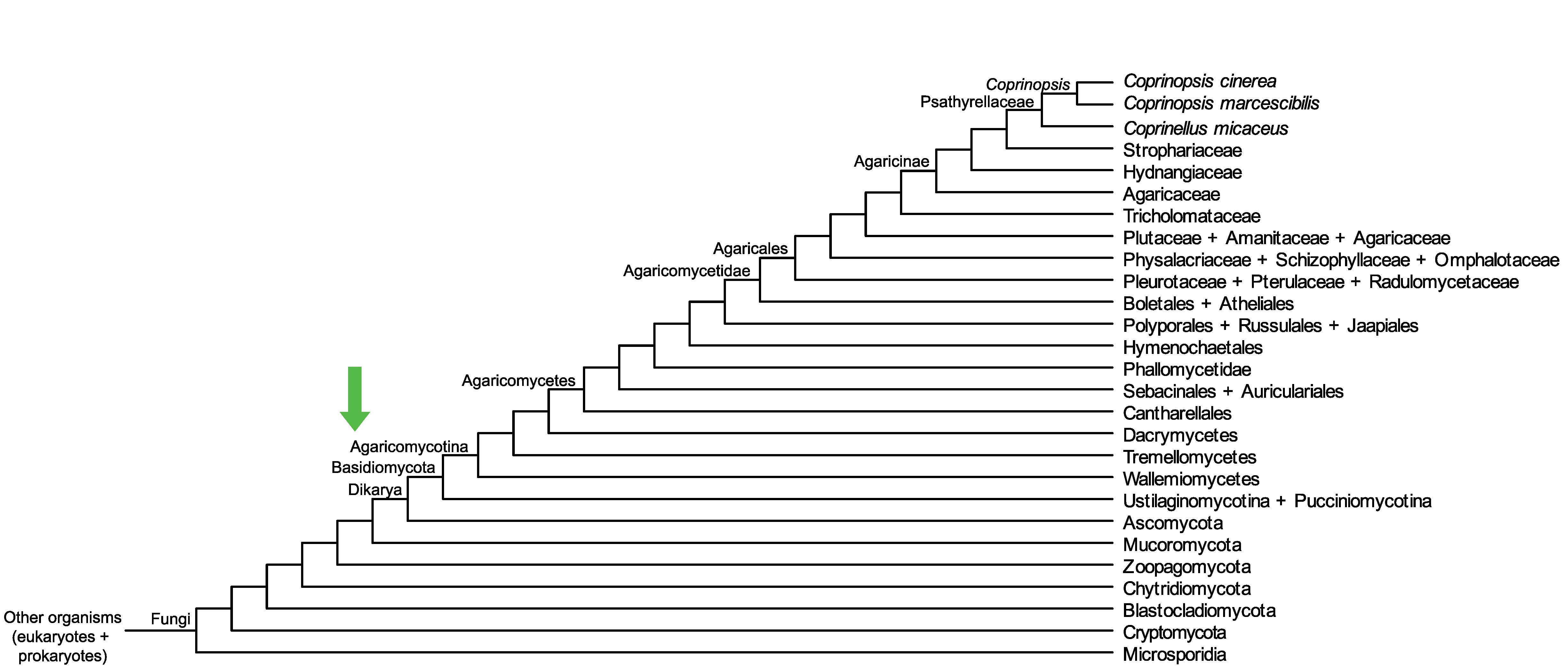
Conservation of CC1G_10437 across fungi.
Arrow shows the origin of gene family containing CC1G_10437.
Protein
| Sequence id | 8893 |
|---|---|
| Sequence |
>8893 MPNRMSTPEPGFSARKQTRTEEPRTPPRSVPTVQATATTVSVTPFKSKSSRSIALVKMTVDEQKEIIRIELEGNR VEAEFDFWSQVYSDESVSDEATVENYLQTTALYCCTSKRWTGIPANVAEEIKLYPPGTAIFQDIIQHFGHGERRQ VWNMYHFRSKKKAKDDDNYVELSKTKTAMCHCEPHGAAACTTPDFVITGSDQYTPRLTHDVECPLYDDTRWLADG KLDKNMSSDLGAMTTQFGVYARQIFNVQPNRTFVRILAFSEKHIRLFHFDRSGVKYTPLLDYHKNPVAFVRTVLS LLSEHSNHSGFDPSITYSIEGDGDGKHKVGYIKLNKTKYKMRQLAPSFKTWDLSGRGTTCWIVVGKVDGKMEVLL IKDSWISVGRQPEYRYLEDAAAVPGIAKLVEWEDSVETAALRHEQEGAMPNNFHNRVKRKIVQLYYGPQITRFLT RLEPLKALHDTVGTHESLEDHDILHRDISTSNILLNRNPSCDRDGVIIDLDMAIRPSSVKGASADCRTGTPETQS INILDSSRMGVPTLRHSYLDDLESFFWVFCIIVTGYDSKGKRAEPTPACIQGWRNADPEHAANAKRAFLFAPPLA PVDPTWGKHVQRLFWDLRRFFMGMTSLVSDIAAGRSEMTMEELFSKRVEHYRTVRGYIKKAIDAIEAETPPEKRP AQDVSLEEPEPKRRRSERQRSKQAAAGAQAGTSTPTTAADSP |
| Length | 717 |
Coding
| Sequence id | CC1G_10437T0 |
|---|---|
| Sequence |
>CC1G_10437T0 ATGCCCAACCGAATGTCCACCCCAGAACCTGGTTTCTCTGCCCGGAAACAAACTCGAACCGAAGAGCCTCGTACG CCGCCGCGCTCCGTACCAACAGTTCAGGCCACGGCCACGACTGTCTCGGTTACTCCCTTCAAATCCAAGTCGTCT CGCAGTATTGCCCTAGTAAAGATGACCGTGGACGAACAGAAGGAGATTATTCGAATTGAGCTCGAAGGAAACAGA GTCGAAGCAGAGTTCGATTTCTGGAGCCAAGTCTACTCGGACGAGTCGGTTTCAGACGAAGCGACTGTCGAGAAC TATCTCCAAACAACCGCACTGTACTGCTGTACTTCCAAGCGGTGGACTGGGATTCCCGCAAACGTGGCCGAGGAG ATAAAGCTCTACCCACCAGGCACGGCAATCTTTCAGGATATTATCCAGCACTTCGGCCATGGTGAGCGCCGCCAG GTTTGGAACATGTATCATTTCAGGTCGAAGAAAAAGGCCAAGGACGATGACAACTATGTTGAGCTGAGCAAGACC AAGACCGCGATGTGCCATTGCGAGCCCCATGGAGCCGCTGCCTGTACCACACCCGACTTCGTTATCACCGGAAGC GACCAGTACACTCCCCGCCTCACGCACGATGTAGAATGCCCCTTGTACGACGACACGCGGTGGCTGGCCGACGGG AAGCTGGACAAAAATATGTCAAGCGACCTGGGCGCAATGACCACTCAGTTTGGCGTTTATGCAAGGCAAATCTTT AACGTTCAACCAAACCGAACCTTTGTCCGGATCTTGGCGTTCAGCGAGAAGCACATCCGACTGTTCCATTTCGAC CGGAGCGGCGTGAAGTACACCCCTCTGCTCGACTATCACAAGAACCCAGTAGCCTTTGTCCGCACCGTCCTCAGC CTTCTTTCCGAACATTCCAACCACTCCGGGTTCGATCCAAGCATCACCTACAGCATCGAGGGTGATGGGGACGGC AAGCACAAAGTGGGGTATATCAAGCTCAACAAAACCAAGTACAAGATGCGACAGCTGGCACCGTCGTTCAAGACT TGGGACCTCAGTGGCCGTGGTACCACCTGCTGGATTGTCGTGGGGAAAGTCGACGGCAAGATGGAAGTGCTGCTG ATCAAGGACAGCTGGATTTCGGTGGGGAGGCAGCCGGAGTATCGCTATCTCGAAGATGCCGCTGCCGTCCCTGGC ATCGCCAAGCTTGTGGAATGGGAAGATTCTGTCGAAACGGCTGCTTTACGCCATGAGCAAGAAGGGGCGATGCCC AACAATTTCCACAATCGAGTCAAACGAAAGATCGTTCAACTGTACTACGGACCCCAAATCACCCGGTTTCTTACT CGCTTGGAACCCTTGAAAGCGCTTCACGATACCGTTGGAACGCATGAAAGCCTCGAAGACCACGACATCTTGCAT CGGGATATCAGCACTAGCAACATCCTCCTCAATAGGAACCCAAGTTGCGATCGAGATGGCGTTATAATCGACCTC GACATGGCTATAAGGCCATCATCTGTGAAGGGGGCGTCCGCCGATTGTAGAACTGGAACTCCCGAAACACAGTCC ATAAATATACTGGATAGTTCAAGGATGGGTGTGCCGACGCTCCGTCACTCCTACCTGGACGACTTGGAATCTTTT TTCTGGGTCTTCTGCATAATTGTCACTGGCTACGACAGCAAGGGAAAGCGGGCCGAACCTACTCCTGCGTGTATC CAAGGCTGGAGGAACGCAGATCCTGAGCATGCTGCTAACGCCAAAAGGGCCTTTCTCTTTGCACCCCCCTTAGCT CCCGTCGATCCCACCTGGGGAAAACACGTTCAGCGGCTGTTCTGGGATCTCCGCAGGTTCTTCATGGGTATGACC TCACTCGTTTCTGATATTGCCGCTGGGCGATCGGAAATGACGATGGAGGAGCTCTTCAGCAAGCGCGTCGAACAT TATAGGACTGTCCGCGGCTACATCAAGAAAGCTATCGACGCCATCGAAGCGGAAACCCCTCCGGAAAAGCGACCA GCTCAAGACGTCTCACTGGAGGAACCTGAGCCCAAGCGTCGTCGCTCTGAGCGTCAGCGCTCCAAGCAGGCGGCA GCAGGGGCCCAGGCCGGTACCTCCACACCGACGACCGCCGCTGATTCTCCT |
| Length | 2154 |
Transcript
| Sequence id | CC1G_10437T0 |
|---|---|
| Sequence |
>CC1G_10437T0 ATGCCCAACCGAATGTCCACCCCAGAACCTGGTTTCTCTGCCCGGAAACAAACTCGAACCGAAGAGCCTCGTACG CCGCCGCGCTCCGTACCAACAGTTCAGGCCACGGCCACGACTGTCTCGGTTACTCCCTTCAAATCCAAGTCGTCT CGCAGTATTGCCCTAGTAAAGATGACCGTGGACGAACAGAAGGAGATTATTCGAATTGAGCTCGAAGGAAACAGA GTCGAAGCAGAGTTCGATTTCTGGAGCCAAGTCTACTCGGACGAGTCGGTTTCAGACGAAGCGACTGTCGAGAAC TATCTCCAAACAACCGCACTGTACTGCTGTACTTCCAAGCGGTGGACTGGGATTCCCGCAAACGTGGCCGAGGAG ATAAAGCTCTACCCACCAGGCACGGCAATCTTTCAGGATATTATCCAGCACTTCGGCCATGGTGAGCGCCGCCAG GTTTGGAACATGTATCATTTCAGGTCGAAGAAAAAGGCCAAGGACGATGACAACTATGTTGAGCTGAGCAAGACC AAGACCGCGATGTGCCATTGCGAGCCCCATGGAGCCGCTGCCTGTACCACACCCGACTTCGTTATCACCGGAAGC GACCAGTACACTCCCCGCCTCACGCACGATGTAGAATGCCCCTTGTACGACGACACGCGGTGGCTGGCCGACGGG AAGCTGGACAAAAATATGTCAAGCGACCTGGGCGCAATGACCACTCAGTTTGGCGTTTATGCAAGGCAAATCTTT AACGTTCAACCAAACCGAACCTTTGTCCGGATCTTGGCGTTCAGCGAGAAGCACATCCGACTGTTCCATTTCGAC CGGAGCGGCGTGAAGTACACCCCTCTGCTCGACTATCACAAGAACCCAGTAGCCTTTGTCCGCACCGTCCTCAGC CTTCTTTCCGAACATTCCAACCACTCCGGGTTCGATCCAAGCATCACCTACAGCATCGAGGGTGATGGGGACGGC AAGCACAAAGTGGGGTATATCAAGCTCAACAAAACCAAGTACAAGATGCGACAGCTGGCACCGTCGTTCAAGACT TGGGACCTCAGTGGCCGTGGTACCACCTGCTGGATTGTCGTGGGGAAAGTCGACGGCAAGATGGAAGTGCTGCTG ATCAAGGACAGCTGGATTTCGGTGGGGAGGCAGCCGGAGTATCGCTATCTCGAAGATGCCGCTGCCGTCCCTGGC ATCGCCAAGCTTGTGGAATGGGAAGATTCTGTCGAAACGGCTGCTTTACGCCATGAGCAAGAAGGGGCGATGCCC AACAATTTCCACAATCGAGTCAAACGAAAGATCGTTCAACTGTACTACGGACCCCAAATCACCCGGTTTCTTACT CGCTTGGAACCCTTGAAAGCGCTTCACGATACCGTTGGAACGCATGAAAGCCTCGAAGACCACGACATCTTGCAT CGGGATATCAGCACTAGCAACATCCTCCTCAATAGGAACCCAAGTTGCGATCGAGATGGCGTTATAATCGACCTC GACATGGCTATAAGGCCATCATCTGTGAAGGGGGCGTCCGCCGATTGTAGAACTGGAACTCCCGAAACACAGTCC ATAAATATACTGGATAGTTCAAGGATGGGTGTGCCGACGCTCCGTCACTCCTACCTGGACGACTTGGAATCTTTT TTCTGGGTCTTCTGCATAATTGTCACTGGCTACGACAGCAAGGGAAAGCGGGCCGAACCTACTCCTGCGTGTATC CAAGGCTGGAGGAACGCAGATCCTGAGCATGCTGCTAACGCCAAAAGGGCCTTTCTCTTTGCACCCCCCTTAGCT CCCGTCGATCCCACCTGGGGAAAACACGTTCAGCGGCTGTTCTGGGATCTCCGCAGGTTCTTCATGGGTATGACC TCACTCGTTTCTGATATTGCCGCTGGGCGATCGGAAATGACGATGGAGGAGCTCTTCAGCAAGCGCGTCGAACAT TATAGGACTGTCCGCGGCTACATCAAGAAAGCTATCGACGCCATCGAAGCGGAAACCCCTCCGGAAAAGCGACCA GCTCAAGACGTCTCACTGGAGGAACCTGAGCCCAAGCGTCGTCGCTCTGAGCGTCAGCGCTCCAAGCAGGCGGCA GCAGGGGCCCAGGCCGGTACCTCCACACCGACGACCGCCGCTGATTCTCCTTAG |
| Length | 2154 |
Gene
| Sequence id | CC1G_10437T0 |
|---|---|
| Sequence |
>CC1G_10437T0 ATGCCCAACCGAATGTCCACCCCAGAACCTGGTTTCTCTGCCCGGAAACAAACTCGAACCGAAGGTAGGAATATC ACTCTAGATTTTCGTTCATTACTGAACTGGTCACAGAGCCTCGTACGCCGCCGCGCTCCGTACCAACAGTTCAGG CCACGGCCACGACTGTCTCGGTTACTCCCTTCAAATCCAAGTCGTCTCGCAGTATTGCCCTAGTAAAGATGACCG TGGACGAACAGAAGGAGATTATTCGAATTGAGCTCGAAGGAAACAGAGTCGAAGCAGAGTTCGATTTCTGGAGCC AAGTCTACTCGGACGAGTCGGTTTCAGACGAAGCGACTGTCGAGAACTATCTCCAAACAACCGCACTGTACTGCT GTACTTCCAAGCGGTGGACTGGGATTCCCGCAAACGTGGCCGAGGAGATAAAGCTCTACCCACCAGGCACGGCAA TCTTTCAGGATATTATCCAGCACTTCGGCCATGGTGAGCGCCGCCAGGTTTGGAACATGTATCATTTCAGGTCGA AGAAAAAGGCCAAGGACGATGACAACTATGTTGAGCTGAGCAAGACCAAGACCGCGATGTGCCATTGCGAGCCCC ATGGAGCCGCTGCCTGTACCACACCCGACTTCGTTATCACCGGAAGCGACCAGTACACTCCCCGCCTCACGCACG ATGTAGAATGCCCCTTGTACGACGACACGCGGTGGCTGGCCGACGGGAAGCTGGACAAAAATATGTCAAGCGACC TGGGCGCAATGACCACTCAGTTTGGCGTTTATGCAAGGTACGAATATTACCTATGGATCCTTACGTTGACACTGG CGCTGATATCTCCCTGTCAGGCAAATCTTTAACGTTCAACCAAACCGAACCTTTGTCCGGATCTTGGCGTTCAGC GAGAAGCACATCCGACTGTTCCATTTCGACCGGAGCGGCGTGAAGTACACCCCTCTGCTCGACTATCACAAGAAC CCAGTAGCCTTTGTCCGCACCGTCCTCAGCCTTCTTTCCGAACATTCCAACCACTCCGGGTTCGATCCAAGCATC ACCTACAGCATCGAGGGTGATGGGGACGGCAAGCACAAAGTGGGGTATATCAAGCTCAACAAAACCAAGTACAAG ATGCGACAGCTGGCACCGTCGTTCAAGACTTGGGACCTCAGTGGCCGTGGTACCACCTGCTGGATTGTCGTGGGG AAAGTCGACGGCAAGATGGAAGTGCTGCTGATCAAGGACAGCTGGATTTCGGTGGGGAGGCAGCCGGAGTATCGC TATCTCGAAGATGCCGCTGCCGTCCCTGGCATCGCCAAGCTTGTGGAATGGGAAGATTCTGTCGAAACGGCTGCT TTACGCCATGAGCAAGAAGGGGCGATGCCCAACAATTTCCACAATCGAGTCAAACGAAAGATCGTTCAACTGTAC TACGGACCCCAAATCACCCGGTTTCTTACTCGCTTGGAACCCTTGAAAGCGCTTCACGATACCGTTGGAAGTACG TTTTATTTTGAAGCACATCATGTTTATCAAATCGCTAATTCAGCTCGCCCTCCAGCGCATGAAAGCCTCGAAGAC CACGACATCTTGCATCGGGATATCAGCACTAGCAACATCCTCCTCAATAGGAACCCAAGTTGCGATCGAGATGGC GTTATAATCGACCTCGACATGGCTATAAGGCCATCATCTGTGAAGGGGGCGTCCGCCGATTGTAGAACTGTAAGT CCCCTGGTGTTTTTTTATTATTCTTATTTTTTATTTTATTTTTTATTTTTTTATTATTCTTTTTCTATTATTATT ATTTTCATGCATCCGACGTCGCGATCCTGATAAGCTGCTTGCAGGGAACTCCCGAAACACAGTCCATAAATATAC TGGATAGTTCAAGGATGGGTGTGCCGACGCTCCGTCACTCCTACCTGGACGACTTGGAATCTTTTTTCTGGGTCT TCTGCATAATTGTCACTGGCTACGACAGCAAGGGAAAGCGGGCCGAACCTACTCCTGCGTGTATCCAAGGCTGGA GGAACGCAGATCCTGAGCATGCTGCTAACGCCAAAAGGGCCTTTCTCTTTGCACCCCCCTTAGCTCCCGTCGATC CCACCTGGGGAAAACACGTTCAGCGGCTGTTCTGGGATCTCCGCAGGTTCTTCATGGGTATGACCTCACTCGTTT CTGATATTGCCGCTGGGCGATCGGAAATGACGATGGAGGAGCTCTTCAGCAAGCGCGTCGAACATTATAGGACTG TCCGCGGCTACATCAAGAAAGCTATCGACGCCATCGAAGCGGAAACCCCTCCGGAAAAGCGACCAGCTCAAGACG TCTCACTGGAGGAACCTGAGCCCAAGCGTCGTCGCTCTGAGCGTCAGCGCTCCAAGCAGGCGGCAGCAGGGGCCC AGGCCGGTACCTCCACACCGACGACCGCCGCTGATTCTCCTTAG |
| Length | 2444 |