CC1G_10513
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10513 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N192 | Functional description | STE/STE11 protein kinase |
| Location | Chr_1:1451149..1455798 | Strand | - |
| Gene length (nt) | 4650 | Transcript length (nt) | 4356 |
| CDS length (nt) | 4356 | Protein length (aa) | 1451 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB28565 | 48.5 | 0 | 1153 |
| Agrocybe aegerita | Agrae_CAA7258651 | 45.8 | 0 | 1070 |
| Lentinula edodes NBRC 111202 | Lenedo1_1257545 | 40.2 | 1.2E-279 | 900 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_984 | 40.1 | 2.608E-279 | 899 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1390042 | 73.3 | 2.068E-190 | 636 |
| Schizophyllum commune H4-8 | Schco3_2488103 | 75 | 2.345E-189 | 633 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_62685 | 70.9 | 1.552E-186 | 624 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_32645 | 70.9 | 7.524E-186 | 622 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_39415 | 69 | 8.482E-171 | 577 |
| Auricularia subglabra | Aurde3_1_1302452 | 52 | 8.55E-148 | 508 |
| Grifola frondosa | Grifr_OBZ79438 | 68.5 | 2.115E-132 | 460 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1062865 | 83.4 | 3.639E-130 | 453 |
| Pleurotus ostreatus PC9 | PleosPC9_1_85800 | 83.3 | 1.578E-129 | 451 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8950 |
| Description | STE/STE11 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 1165 | 1437 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K11229 |
EggNOG
| COG category | Description |
|---|---|
| T | Ste ste11 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
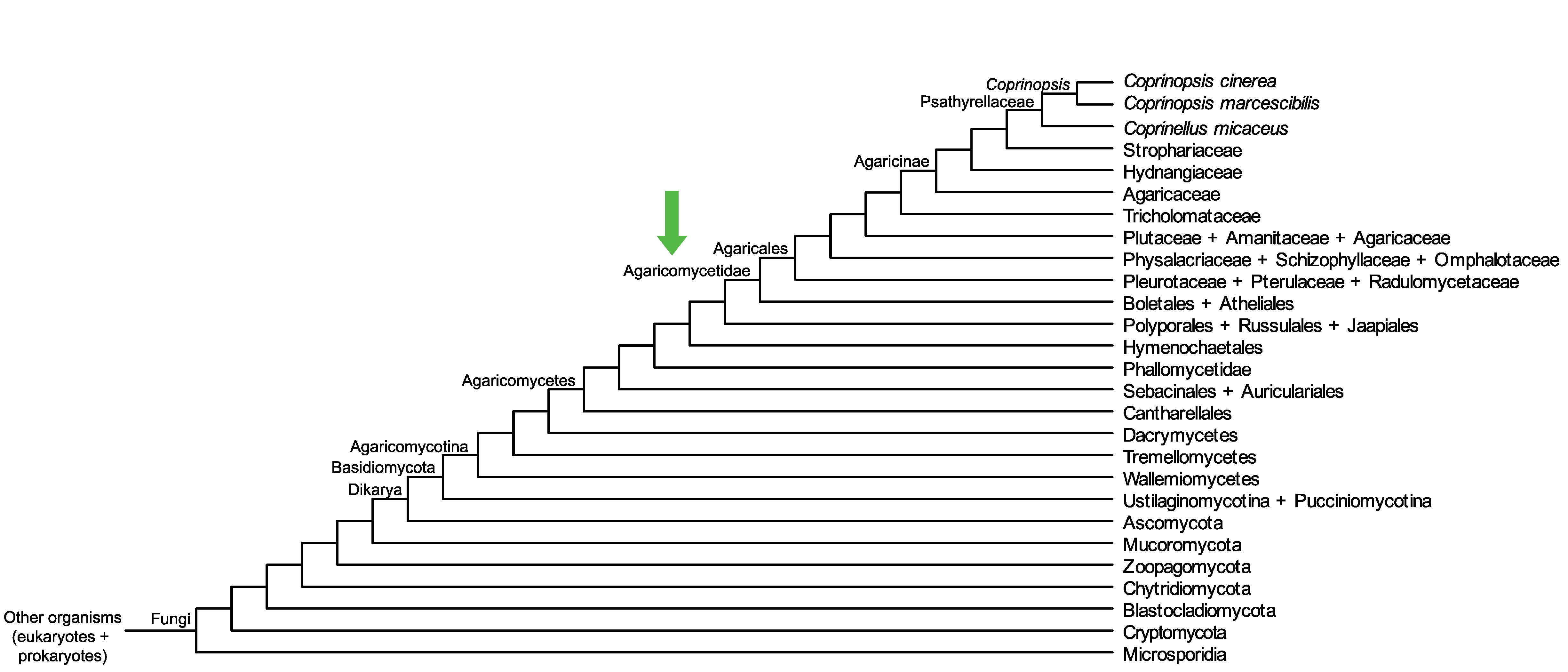
Conservation of CC1G_10513 across fungi.
Arrow shows the origin of gene family containing CC1G_10513.
Protein
| Sequence id | 8950 |
|---|---|
| Sequence |
>8950 MSEDVRNGKIHGRKYFVANRGSDSENDSDDDNDKPPIFNSYHYSAPYHSKPPPTDPYDHHPPALRTDLGSSYVQD HNHRPSLSSPSSLSSHAADESTPPPPTPGVSLPLASPPTIPAKPVHPLHEALPINDRHYPDVHQTSARGGTVTNM LTNLRNWRHGSTPRTPVEASAARRPRTSPSVSTPDSAVSSNSNLPNPDKILICVTTEADPERLNIVDVSGAKDAT SIRESILSKVPYSFSAVSSSILTRHQTNLLDGLNRYSIYLTEIGASVIGDPLNDERLLDLVQRQGDSRGTLKFFV SRSTKEQIPPPPQQMPPPFPFPYVEQPTHPAILPLRPRRRPRSRQGSVSSVSSEQPAELGYDADLDNPDDSRKSS RQQNHSSRSHLTGPGISPPSPGPLRRPPNGPLPIAPLGPPSASHSNYPHPPSPISQGHVSKPPTPPTFFHDRPHL PSASRSTYIDKYGQVLPAPPPPPPLSSPRRGDFLDEPNSSLSPLAHIRSGSDAGAEREQLLIASEQAEAASQQRR RRDASLTRLRAEPSRDNLSLLSRNRKPTPTDPNDWTFINPPDTNIPVTEPLRSGEPIWPTKTLASSRGHRSQMFA RVPKQPPQSLPSSSTESRSSSSRSASKPIYLPKAVHSKPPDSYPKGTSSTVPLKSLGKGKSMDNLRQFSYNSSKA PTIKPPHPQLPSRPPVVREPVYLAAGSFGVPKSYEPPRAIRPLPVQGSHYPQSPDANSRSGFPSYGKPSPYMPTP LSTNLTSPNRDMYGRDHPPRPLSASDNHTTSPTYSQRSNQSPSYGGTMSPSRSYGIGGPRTLLHHSGHSDRSSDV PSGPETSNSTPPRTPISPVSCKSSPAGKMPLVIEPSSPASDSGNATYISNVSSVDSEKTIREDDKTQLAALLNNM NALMSSDRLPVSASETSMAVNDLSSSDESDYEGSGGTWIKPYQDRPPSARPELTKLRTDLPSTPDPADKVREERP NPSASQSQGYQNGGPSSQYQLPPPQRFPPGNQQHRDHRVSGFADGDDDWAPRPPPEDVYDRLEEFFPEHDLDKLV IEANSGGNSPTNPEPTTAIPTPVSANATVIMPQHPHRRHKKSIRIVAQEQKRKMNDQTSRVDPAPYGQNAMLRKR NTKMWGSKLEEVTTMQVRTSSTIPESPSSAGSPPTFKWVRGELIGKGTYGRVYLALNATTGEMIAVKQVELPQTP SDRNDSRQNTVVQALKLESETLKDLDHPHIVQYLGFEETPANLSIFLEYVPGGSIGSCLHKHGKFSENVTKSFTG QILSGLEYLHSKGILHRDLKADNILVEMTGICKISDFGISKRTDDLHGGAFTAMQGTVFWMAPEVINTQKKGYNF KIDIWSVGCVVLEMWGGRRPWTGQEMVTVMFKLYEAKLPPPVPDDVVLSELGDDFRRKCFAIFMTDGACSNPDER PPAAELRLHPYLELPPGWTFTSFTSD |
| Length | 1451 |
Coding
| Sequence id | CC1G_10513T0 |
|---|---|
| Sequence |
>CC1G_10513T0 ATGTCGGAGGACGTCAGAAATGGCAAGATACACGGCCGCAAGTACTTCGTCGCAAACCGGGGCTCCGACTCTGAA AACGACAGCGACGACGACAATGACAAGCCTCCGATCTTCAACTCTTACCACTATTCGGCTCCTTATCACTCAAAG CCTCCTCCAACCGACCCCTACGACCACCATCCACCAGCTTTGAGAACAGATCTGGGTTCCAGCTACGTGCAGGAT CATAACCACAGGCCATCCCTGTCGTCCCCGTCCAGCCTGAGTTCACATGCGGCCGATGAGTCCACCCCACCGCCC CCAACCCCAGGCGTTTCCCTGCCACTTGCTTCACCGCCGACCATTCCAGCCAAACCCGTCCACCCACTTCACGAA GCCCTTCCCATCAACGATCGACACTATCCCGATGTTCACCAGACCTCTGCTCGCGGCGGGACCGTTACAAACATG TTGACAAACCTCCGCAACTGGCGGCACGGGAGCACTCCCCGAACGCCCGTCGAAGCCAGTGCTGCCCGTAGACCG AGAACGTCGCCCTCCGTTTCGACCCCGGATTCCGCAGTGTCCTCGAATTCGAACCTTCCAAATCCTGACAAGATC CTAATCTGTGTGACCACCGAAGCCGATCCAGAAAGGTTGAATATTGTCGATGTCAGTGGGGCAAAGGATGCCACC TCTATCAGAGAATCCATCCTTTCAAAGGTACCGTATTCTTTCTCAGCAGTGTCTTCCTCAATCCTTACGCGGCAC CAGACAAACCTTCTCGATGGCCTCAACCGCTATTCCATCTATTTGACGGAGATAGGGGCTTCCGTGATTGGGGAT CCTCTAAATGACGAGCGGTTGTTGGATTTGGTTCAACGACAAGGTGATTCGAGAGGCACCCTCAAATTCTTTGTT TCGCGGTCAACGAAGGAGCAAATACCTCCACCACCTCAACAAATGCCCCCACCCTTCCCCTTCCCATACGTGGAA CAGCCCACTCACCCTGCAATTCTCCCCCTTCGCCCCCGACGCCGCCCAAGGTCTCGACAAGGGAGCGTGTCGTCG GTTTCAAGCGAGCAACCGGCTGAGCTGGGGTACGATGCGGACCTCGACAATCCCGACGACTCTCGTAAAAGCTCA AGGCAGCAAAACCATTCAAGTCGTTCCCATCTCACGGGCCCCGGCATCTCCCCACCTTCCCCGGGGCCACTCCGG CGACCTCCAAATGGACCTTTGCCAATAGCACCTTTGGGGCCACCTTCAGCATCCCACAGTAATTATCCTCACCCT CCTTCGCCCATATCCCAAGGCCATGTGTCCAAACCTCCGACACCGCCTACATTCTTCCATGACCGCCCTCATCTT CCTTCAGCTTCTCGATCGACTTACATCGATAAATACGGTCAGGTATTGCCCGCTCCCCCTCCTCCGCCTCCGTTG AGCTCCCCACGGCGAGGGGACTTCTTGGATGAACCCAATTCATCACTGTCACCCCTGGCACATATACGTTCTGGC TCAGACGCTGGGGCCGAGCGCGAACAGCTGCTCATTGCCTCAGAACAAGCTGAGGCCGCCAGTCAGCAGCGCCGA AGGAGAGATGCTTCCTTAACCCGTCTCAGAGCGGAGCCATCCAGGGACAATCTCAGTTTGCTGTCTCGAAATCGC AAGCCTACGCCGACGGATCCTAATGACTGGACTTTTATCAACCCACCAGACACAAACATTCCCGTCACAGAGCCA CTTCGTTCTGGTGAACCCATTTGGCCGACCAAAACGTTGGCTTCATCTCGTGGTCACCGCTCCCAAATGTTTGCC AGAGTACCTAAGCAGCCACCTCAGTCTCTCCCCTCATCCAGCACAGAATCCAGGTCATCGTCATCTCGGTCTGCA AGCAAACCGATATACTTGCCGAAAGCTGTCCACTCTAAACCTCCTGATTCTTACCCTAAGGGAACTTCGTCTACA GTGCCGTTGAAATCCCTTGGGAAAGGGAAAAGTATGGACAACCTGCGGCAGTTTTCTTACAACAGTAGCAAGGCC CCGACCATCAAGCCTCCACACCCTCAATTGCCCTCTCGCCCTCCTGTAGTCCGTGAGCCCGTTTACTTGGCAGCG GGTTCTTTTGGGGTACCAAAGTCGTACGAACCCCCTCGTGCCATCCGGCCTTTGCCAGTGCAAGGCTCACATTAT CCACAATCTCCGGATGCCAACAGTCGATCTGGGTTCCCGTCTTACGGCAAACCCTCGCCTTATATGCCCACCCCT TTGTCGACCAACCTCACGTCACCTAACCGTGATATGTATGGCCGTGATCATCCTCCTCGCCCGCTCTCGGCATCT GACAATCATACTACATCACCCACATATTCTCAGCGAAGCAACCAATCTCCGTCATACGGGGGTACGATGTCTCCA AGCCGCTCTTATGGAATCGGTGGACCTCGAACCCTGCTGCACCATAGCGGACATTCTGACAGGTCTTCAGACGTT CCAAGCGGACCTGAAACTTCCAATTCCACCCCTCCACGGACGCCTATCAGTCCAGTCAGCTGCAAGTCCAGTCCT GCTGGAAAGATGCCTCTCGTCATTGAACCTTCATCGCCCGCGTCGGACAGCGGTAACGCTACGTACATCTCGAAT GTTAGCAGTGTCGATTCGGAGAAGACAATCCGAGAGGACGACAAGACGCAGTTGGCAGCGTTGTTGAATAACATG AACGCGCTTATGTCTAGTGATCGCCTACCGGTGTCAGCGAGCGAGACTTCGATGGCTGTTAACGATTTGTCGTCC TCAGACGAATCGGATTATGAAGGTAGCGGTGGTACCTGGATCAAACCCTACCAGGACCGTCCTCCATCAGCCCGT CCAGAACTTACCAAGCTGCGAACCGACCTCCCATCGACACCAGACCCGGCAGACAAAGTTCGAGAGGAACGGCCA AATCCTTCCGCATCACAATCGCAAGGCTACCAGAACGGCGGACCCTCGTCCCAATACCAGCTCCCTCCACCACAG AGGTTCCCTCCGGGCAATCAGCAACATAGGGACCATCGCGTTAGTGGGTTTGCTGACGGCGATGACGACTGGGCC CCTCGACCTCCGCCCGAAGATGTTTACGACCGTCTAGAAGAGTTCTTCCCCGAACATGATCTCGACAAGCTAGTC ATCGAAGCAAATTCTGGTGGCAATTCGCCCACGAATCCAGAGCCGACGACTGCGATCCCTACTCCAGTGTCTGCC AATGCTACCGTAATAATGCCACAGCATCCTCATAGGCGACACAAGAAGAGTATTCGCATTGTTGCTCAAGAGCAG AAGAGGAAGATGAATGACCAAACGTCCCGGGTGGATCCAGCGCCGTATGGTCAGAACGCGATGCTGAGGAAGAGG AATACGAAGATGTGGGGTAGCAAGTTGGAAGAAGTGACCACGATGCAAGTGAGGACATCGTCTACGATTCCCGAA TCACCGTCCAGTGCAGGCTCGCCTCCCACATTCAAGTGGGTACGAGGAGAGTTGATTGGCAAAGGCACCTACGGT CGGGTGTATCTTGCCCTCAACGCGACCACGGGAGAGATGATCGCAGTCAAGCAAGTGGAGCTTCCACAAACGCCG AGTGATCGAAATGATTCGCGTCAGAATACAGTTGTGCAGGCGTTGAAGTTGGAAAGTGAGACGCTGAAAGATTTA GACCATCCCCATATTGTCCAGTATTTGGGCTTCGAGGAGACACCGGCGAACTTGAGCATCTTTCTGGAATATGTG CCTGGTGGCTCTATTGGAAGTTGCCTTCATAAACATGGCAAATTCTCAGAGAACGTTACGAAGTCTTTCACTGGT CAAATTCTGAGCGGGCTCGAGTATTTGCATTCTAAAGGGATTCTTCACCGAGATCTCAAGGCAGACAACATACTT GTGGAAATGACAGGAATATGCAAAATATCTGATTTCGGTATCTCGAAACGAACGGACGATCTGCATGGAGGTGCC TTTACTGCTATGCAGGGAACCGTATTTTGGATGGCTCCAGAGGTAATTAATACGCAGAAGAAGGGCTACAATTTC AAGATCGATATCTGGAGTGTCGGTTGTGTAGTGCTGGAAATGTGGGGTGGGCGAAGACCTTGGACTGGACAGGAG ATGGTAACGGTCATGTTCAAGCTGTACGAGGCCAAGCTACCGCCTCCCGTTCCTGACGATGTTGTGTTGTCTGAG TTGGGAGATGATTTCAGGCGGAAGTGTTTCGCTATCTTCATGACTGATGGCGCTTGCAGCAATCCCGATGAACGA CCACCCGCGGCAGAGCTTCGCCTTCACCCATACCTCGAGCTTCCACCGGGCTGGACTTTTACTTCGTTTACCTCC GAT |
| Length | 4356 |
Transcript
| Sequence id | CC1G_10513T0 |
|---|---|
| Sequence |
>CC1G_10513T0 ATGTCGGAGGACGTCAGAAATGGCAAGATACACGGCCGCAAGTACTTCGTCGCAAACCGGGGCTCCGACTCTGAA AACGACAGCGACGACGACAATGACAAGCCTCCGATCTTCAACTCTTACCACTATTCGGCTCCTTATCACTCAAAG CCTCCTCCAACCGACCCCTACGACCACCATCCACCAGCTTTGAGAACAGATCTGGGTTCCAGCTACGTGCAGGAT CATAACCACAGGCCATCCCTGTCGTCCCCGTCCAGCCTGAGTTCACATGCGGCCGATGAGTCCACCCCACCGCCC CCAACCCCAGGCGTTTCCCTGCCACTTGCTTCACCGCCGACCATTCCAGCCAAACCCGTCCACCCACTTCACGAA GCCCTTCCCATCAACGATCGACACTATCCCGATGTTCACCAGACCTCTGCTCGCGGCGGGACCGTTACAAACATG TTGACAAACCTCCGCAACTGGCGGCACGGGAGCACTCCCCGAACGCCCGTCGAAGCCAGTGCTGCCCGTAGACCG AGAACGTCGCCCTCCGTTTCGACCCCGGATTCCGCAGTGTCCTCGAATTCGAACCTTCCAAATCCTGACAAGATC CTAATCTGTGTGACCACCGAAGCCGATCCAGAAAGGTTGAATATTGTCGATGTCAGTGGGGCAAAGGATGCCACC TCTATCAGAGAATCCATCCTTTCAAAGGTACCGTATTCTTTCTCAGCAGTGTCTTCCTCAATCCTTACGCGGCAC CAGACAAACCTTCTCGATGGCCTCAACCGCTATTCCATCTATTTGACGGAGATAGGGGCTTCCGTGATTGGGGAT CCTCTAAATGACGAGCGGTTGTTGGATTTGGTTCAACGACAAGGTGATTCGAGAGGCACCCTCAAATTCTTTGTT TCGCGGTCAACGAAGGAGCAAATACCTCCACCACCTCAACAAATGCCCCCACCCTTCCCCTTCCCATACGTGGAA CAGCCCACTCACCCTGCAATTCTCCCCCTTCGCCCCCGACGCCGCCCAAGGTCTCGACAAGGGAGCGTGTCGTCG GTTTCAAGCGAGCAACCGGCTGAGCTGGGGTACGATGCGGACCTCGACAATCCCGACGACTCTCGTAAAAGCTCA AGGCAGCAAAACCATTCAAGTCGTTCCCATCTCACGGGCCCCGGCATCTCCCCACCTTCCCCGGGGCCACTCCGG CGACCTCCAAATGGACCTTTGCCAATAGCACCTTTGGGGCCACCTTCAGCATCCCACAGTAATTATCCTCACCCT CCTTCGCCCATATCCCAAGGCCATGTGTCCAAACCTCCGACACCGCCTACATTCTTCCATGACCGCCCTCATCTT CCTTCAGCTTCTCGATCGACTTACATCGATAAATACGGTCAGGTATTGCCCGCTCCCCCTCCTCCGCCTCCGTTG AGCTCCCCACGGCGAGGGGACTTCTTGGATGAACCCAATTCATCACTGTCACCCCTGGCACATATACGTTCTGGC TCAGACGCTGGGGCCGAGCGCGAACAGCTGCTCATTGCCTCAGAACAAGCTGAGGCCGCCAGTCAGCAGCGCCGA AGGAGAGATGCTTCCTTAACCCGTCTCAGAGCGGAGCCATCCAGGGACAATCTCAGTTTGCTGTCTCGAAATCGC AAGCCTACGCCGACGGATCCTAATGACTGGACTTTTATCAACCCACCAGACACAAACATTCCCGTCACAGAGCCA CTTCGTTCTGGTGAACCCATTTGGCCGACCAAAACGTTGGCTTCATCTCGTGGTCACCGCTCCCAAATGTTTGCC AGAGTACCTAAGCAGCCACCTCAGTCTCTCCCCTCATCCAGCACAGAATCCAGGTCATCGTCATCTCGGTCTGCA AGCAAACCGATATACTTGCCGAAAGCTGTCCACTCTAAACCTCCTGATTCTTACCCTAAGGGAACTTCGTCTACA GTGCCGTTGAAATCCCTTGGGAAAGGGAAAAGTATGGACAACCTGCGGCAGTTTTCTTACAACAGTAGCAAGGCC CCGACCATCAAGCCTCCACACCCTCAATTGCCCTCTCGCCCTCCTGTAGTCCGTGAGCCCGTTTACTTGGCAGCG GGTTCTTTTGGGGTACCAAAGTCGTACGAACCCCCTCGTGCCATCCGGCCTTTGCCAGTGCAAGGCTCACATTAT CCACAATCTCCGGATGCCAACAGTCGATCTGGGTTCCCGTCTTACGGCAAACCCTCGCCTTATATGCCCACCCCT TTGTCGACCAACCTCACGTCACCTAACCGTGATATGTATGGCCGTGATCATCCTCCTCGCCCGCTCTCGGCATCT GACAATCATACTACATCACCCACATATTCTCAGCGAAGCAACCAATCTCCGTCATACGGGGGTACGATGTCTCCA AGCCGCTCTTATGGAATCGGTGGACCTCGAACCCTGCTGCACCATAGCGGACATTCTGACAGGTCTTCAGACGTT CCAAGCGGACCTGAAACTTCCAATTCCACCCCTCCACGGACGCCTATCAGTCCAGTCAGCTGCAAGTCCAGTCCT GCTGGAAAGATGCCTCTCGTCATTGAACCTTCATCGCCCGCGTCGGACAGCGGTAACGCTACGTACATCTCGAAT GTTAGCAGTGTCGATTCGGAGAAGACAATCCGAGAGGACGACAAGACGCAGTTGGCAGCGTTGTTGAATAACATG AACGCGCTTATGTCTAGTGATCGCCTACCGGTGTCAGCGAGCGAGACTTCGATGGCTGTTAACGATTTGTCGTCC TCAGACGAATCGGATTATGAAGGTAGCGGTGGTACCTGGATCAAACCCTACCAGGACCGTCCTCCATCAGCCCGT CCAGAACTTACCAAGCTGCGAACCGACCTCCCATCGACACCAGACCCGGCAGACAAAGTTCGAGAGGAACGGCCA AATCCTTCCGCATCACAATCGCAAGGCTACCAGAACGGCGGACCCTCGTCCCAATACCAGCTCCCTCCACCACAG AGGTTCCCTCCGGGCAATCAGCAACATAGGGACCATCGCGTTAGTGGGTTTGCTGACGGCGATGACGACTGGGCC CCTCGACCTCCGCCCGAAGATGTTTACGACCGTCTAGAAGAGTTCTTCCCCGAACATGATCTCGACAAGCTAGTC ATCGAAGCAAATTCTGGTGGCAATTCGCCCACGAATCCAGAGCCGACGACTGCGATCCCTACTCCAGTGTCTGCC AATGCTACCGTAATAATGCCACAGCATCCTCATAGGCGACACAAGAAGAGTATTCGCATTGTTGCTCAAGAGCAG AAGAGGAAGATGAATGACCAAACGTCCCGGGTGGATCCAGCGCCGTATGGTCAGAACGCGATGCTGAGGAAGAGG AATACGAAGATGTGGGGTAGCAAGTTGGAAGAAGTGACCACGATGCAAGTGAGGACATCGTCTACGATTCCCGAA TCACCGTCCAGTGCAGGCTCGCCTCCCACATTCAAGTGGGTACGAGGAGAGTTGATTGGCAAAGGCACCTACGGT CGGGTGTATCTTGCCCTCAACGCGACCACGGGAGAGATGATCGCAGTCAAGCAAGTGGAGCTTCCACAAACGCCG AGTGATCGAAATGATTCGCGTCAGAATACAGTTGTGCAGGCGTTGAAGTTGGAAAGTGAGACGCTGAAAGATTTA GACCATCCCCATATTGTCCAGTATTTGGGCTTCGAGGAGACACCGGCGAACTTGAGCATCTTTCTGGAATATGTG CCTGGTGGCTCTATTGGAAGTTGCCTTCATAAACATGGCAAATTCTCAGAGAACGTTACGAAGTCTTTCACTGGT CAAATTCTGAGCGGGCTCGAGTATTTGCATTCTAAAGGGATTCTTCACCGAGATCTCAAGGCAGACAACATACTT GTGGAAATGACAGGAATATGCAAAATATCTGATTTCGGTATCTCGAAACGAACGGACGATCTGCATGGAGGTGCC TTTACTGCTATGCAGGGAACCGTATTTTGGATGGCTCCAGAGGTAATTAATACGCAGAAGAAGGGCTACAATTTC AAGATCGATATCTGGAGTGTCGGTTGTGTAGTGCTGGAAATGTGGGGTGGGCGAAGACCTTGGACTGGACAGGAG ATGGTAACGGTCATGTTCAAGCTGTACGAGGCCAAGCTACCGCCTCCCGTTCCTGACGATGTTGTGTTGTCTGAG TTGGGAGATGATTTCAGGCGGAAGTGTTTCGCTATCTTCATGACTGATGGCGCTTGCAGCAATCCCGATGAACGA CCACCCGCGGCAGAGCTTCGCCTTCACCCATACCTCGAGCTTCCACCGGGCTGGACTTTTACTTCGTTTACCTCC GATTAG |
| Length | 4356 |
Gene
| Sequence id | CC1G_10513T0 |
|---|---|
| Sequence |
>CC1G_10513T0 ATGTCGGAGGACGTCAGAAATGGCAAGATACACGGCCGCAAGTACTTCGTCGCAAACCGGGGCTCCGACTCTGAA AACGACAGCGACGACGACAATGACAAGCCTCCGATCTTCAACTCTTACCACTATTCGGCTCCTTATCACTCAAAG CCTCCTCCAACCGACCCCTACGACCACCATCCACCAGCTTTGAGAACAGATCTGGGTTCCAGCTACGTGCAGGAT CATAACCACAGGCCATCCCTGTCGTCCCCGTCCAGCCTGAGTTCACATGCGGCCGATGAGTCCACCCCACCGCCC CCAACCCCAGGCGTTTCCCTGCCACTTGCTTCACCGCCGACCATTCCAGCCAAACCCGTCCACCCACTTCACGAA GCCCTTCCCATCAACGATCGACACTATCCCGATGTTCACCAGACCTCTGCTCGCGGCGGGACCGTTACAAACATG TTGACAAACCTCCGCAACTGGCGGCACGGGAGCACTCCCCGAACGCCCGTCGAAGCCAGTGCTGCCCGTAGACCG AGAACGGTGAGCTTTTAACCATTCCTTACGTTTTTGACATTGCTCATGTGCCACGATAGTCGCCCTCCGTTTCGA CCCCGGATTCCGCAGTGTCCTCGAATTCGAACCTTCCAAATCCTGACAAGATCCTAATCTGTGTGACCACCGAAG CCGATCCAGAAAGGTTGAATATTGTCGATGTCAGTGGGGCAAAGGATGCCACCTCTATCAGAGAATCCATCCTTT CAAAGGTACCGTATTCTTTCTCAGCAGTGTCTTCCTCAATCCTTACGCGGCACCAGACAAACCTTCTCGATGGCC TCAACCGCTATTCCATCTATTTGACGGAGATAGGGGCTTCCGTGATTGGGGATCCTCTAAATGACGAGCGGTTGT TGGATTTGGTTCAACGACAAGGTGATTCGAGAGGCACCCTCAAATTCTTTGTTTCGCGGTCAACGAAGGAGCAAA TACCTCCACCACCTCAACAAATGCCCCCACCCTTCCCCTTCCCATACGTGGAACAGCCCACTCACCCTGCAATTC TCCCCCTTCGCCCCCGACGCCGCCCAAGGTCTCGACAAGGGAGCGTGTCGTCGGTTTCAAGCGAGCAACCGGCTG AGCTGGGGTACGATGCGGACCTCGACAATCCCGACGACTCTCGTAAAAGCTCAAGGCAGCAAAACCATTCAAGTC GTTCCCATCTCACGGGCCCCGGCATCTCCCCACCTTCCCCGGGGCCACTCCGGCGACCTCCAAATGGACCTTTGC CAATAGCACCTTTGGGGCCACCTTCAGCATCCCACAGTAATTATCCTCACCCTCCTTCGCCCATATCCCAAGGCC ATGTGTCCAAACCTCCGACACCGCCTACATTCTTCCATGACCGCCCTCATCTTCCTTCAGCTTCTCGATCGACTT ACATCGATAAATACGGTCAGGTATTGCCCGCTCCCCCTCCTCCGCCTCCGTTGAGCTCCCCACGGCGAGGGGACT TCTTGGATGAACCCAATTCATCACTGTCACCCCTGGCACATATACGTTCTGGCTCAGACGCTGGGGCCGAGCGCG AACAGCTGCTCATTGCCTCAGAACAAGCTGAGGCCGCCAGTCAGCAGCGCCGAAGGAGAGATGCTTCCTTAACCC GTCTCAGAGCGGAGCCATCCAGGGACAATCTCAGTTTGCTGTCTCGAAATCGCAAGCCTACGCCGACGGATCCTA ATGACTGGACTTTTATCAACCCACCAGACACAAACATTCCCGTCACAGAGCCACTTCGTTCTGGTGAACCCATTT GGCCGACCAAAACGTTGGCTTCATCTCGTGGTCACCGCTCCCAAATGTTTGCCAGAGTACCTAAGCAGCCACCTC AGTCTCTCCCCTCATCCAGCACAGAATCCAGGTCATCGTCATCTCGGTCTGCAAGCAAACCGATATACTTGCCGA AAGCTGTCCACTCTAAACCTCCTGATTCTTACCCTAAGGGAACTTCGTCTACAGTGCCGTTGAAATCCCTTGGGA AAGGGAAAAGTATGGACAACCTGCGGCAGTTTTCTTACAACAGTAGCAAGGCCCCGACCATCAAGCCTCCACACC CTCAATTGCCCTCTCGCCCTCCTGTAGTCCGTGAGCCCGTTTACTTGGCAGCGGGTTCTTTTGGGGTACCAAAGT CGTACGAACCCCCTCGTGCCATCCGGCCTTTGCCAGTGCAAGGCTCACATTATCCACAATCTCCGGATGCCAACA GTCGATCTGGGTTCCCGTCTTACGGCAAACCCTCGCCTTATATGCCCACCCCTTTGTCGACCAACCTCACGTCAC CTAACCGTGATATGTATGGCCGTGATCATCCTCCTCGCCCGCTCTCGGCATCTGACAATCATACTACATCACCCA CATATTCTCAGCGAAGCAACCAATCTCCGTCATACGGGGGTACGATGTCTCCAAGCCGCTCTTATGGAATCGGTG GACCTCGAACCCTGCTGCACCATAGCGGACATTCTGACAGGTCTTCAGACGTTCCAAGCGGACCTGAAACTTCCA ATTCCACCCCTCCACGGACGCCTATCAGTCCAGTCAGCTGCAAGTCCAGTCCTGCTGGAAAGATGCCTCTCGTCA TTGAACCTTCATCGCCCGCGTCGGACAGCGGTAACGCTACGTACATCTCGAATGTTAGCAGTGTCGATTCGGAGA AGACAATCCGAGAGGACGACAAGACGCAGTTGGCAGCGTTGTTGAATAACATGAACGCGCTTATGTCTAGTGATC GCCTACCGGTGTCAGCGAGCGAGACTTCGATGGCTGTTAACGATTTGTCGTCCTCAGACGAATCGGATTATGAAG GTAGCGGTGGTACCTGGATCAAACCCTACCAGGACCGTCCTCCATCAGCCCGTCCAGAACTTACCAAGCTGCGAA CCGACCTCCCATCGACACCAGACCCGGCAGACAAAGTTCGAGAGGAACGGCCAAATCCTTCCGCATCACAATCGC AAGGCTACCAGAACGGCGGACCCTCGTCCCAATACCAGCTCCCTCCACCACAGAGGTTCCCTCCGGGCAATCAGC AACATAGGGACCATCGCGTTAGTGGGTTTGCTGACGGCGATGACGACTGGGCCCCTCGACCTCCGCCCGAAGATG TTTACGACCGTCTAGAAGAGTTCTTCCCCGAACATGATCTCGACAAGCTAGTCATCGAAGCAAATTCTGGTGGCA ATTCGCCCACGAATCCAGAGCCGACGACTGCGATCCCTACTCCAGTGTCTGCCAATGCTACCGTAATAATGCCAC AGCATCCTCATAGGCGACACAAGAAGAGTATTCGCATTGTTGCTCAAGAGCAGAAGAGGAAGATGAATGACCAAA CGTCCCGGGTGGATCCAGCGCCGTATGGTCAGAACGCGATGCTGAGGAAGAGGAATACGAAGATGTGGGGTAGCA AGTTGGAAGAAGTGACCACGATGCAAGTGAGGACATCGTCTACGATTCCCGAATCACCGTCCAGTGCAGGCTCGC CTCGTAAGTCTCATGCAGAATTTACCCCAAATGGGCCTAACCGTTCCCTTTTTAGCCACATTCAAGTGGGTACGA GGAGAGTTGATTGGCAAAGGCACCTACGGTCGGGTGTATCTTGCCCTCAACGCGACCACGGGAGAGATGATCGCA GTCAAGCAAGTGGAGCTTCCACAAACGCCGAGTGATCGAAATGATTCGCGTCAGAATACAGTTGTGCAGGCGTTG AAGTTGGAAAGTGAGACGCTGAAAGATTTAGACCATCCCCATATTGTCCAGTATTTGGGCTTCGAGGAGACACCG GCGAACTTGAGCATGTAAGATATTTCCTTGGAACACCTCTTTCGTCACGTCGCTCATCGCCTTTTCCTTTCAAGC TTTCTGGAATATGTGCCTGGTGGCTCTATTGGAAGTTGCCTTCATAAACATGGCAAATTCTCAGAGAACGTTACG AAGTCTTTCACTGGTCAAATTCTGAGCGGGCTCGAGTATTTGCATTCTAAAGGGATTCTTCACCGAGTACGTTTT CGATCCGTATTCTCGATCATTGGCGTTTGACACTCCCCCTAGGATCTCAAGGCAGACAACATACTTGTGGAAATG ACAGGAATATGCAAAATATCTGATTTCGGTATCTCGAAACGAACGGACGATCTGCATGGAGGTGCCTTTACTGCT ATGCAGGGAACCGTATTTTGGATGGCTCCAGAGGTAATTAATACGCAGAAGAAGGGCTACAATTTCAAGATCGAT ATCTGGAGTGTCGGTTGTGTAGTGCTGGAAATGTGGGGTGGGCGAAGACCTTGGACTGGACAGGAGATGGTAACG GTCATGTTCAAGGTATGCGATCGAGGTGACCGAATTGAATCGATTCTGACGTTGCTGTACAGCTGTACGAGGCCA AGCTACCGCCTCCCGTTCCTGACGATGTTGTGTTGTCTGAGTTGGGAGATGATTTCAGGCGGAAGTGTTTCGCTA TGTAAGGGCTCTCTTTTCTCCCTGTTTAGCTTCATGACTGATGGCGCTTGCAGCAATCCCGATGAACGACCACCC GCGGCAGAGCTTCGCCTTCACCCATACCTCGAGCTTCCACCGGGCTGGACTTTTACTTCGTTTACCTCCGATTAG |
| Length | 4650 |