CC1G_13258
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_13258 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8PI69 | Functional description | Histidine kinase (EC 2.7.13.3) |
| Location | U362:5600..9084 | Strand | - |
| Gene length (nt) | 3485 | Transcript length (nt) | 2355 |
| CDS length (nt) | 2355 | Protein length (aa) | 784 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Candida albicans | NIK1 |
| Aspergillus nidulans | AN4479_nikA |
| Neurospora crassa | os-1 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7266673 | 79.2 | 0 | 2160 |
| Pleurotus ostreatus PC9 | PleosPC9_1_117202 | 78.8 | 0 | 2130 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB21643 | 93.6 | 0 | 2106 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1050244 | 91.6 | 0 | 2075 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1388585 | 91.4 | 0 | 2070 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_64857 | 91.5 | 0 | 2069 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_228355 | 91.3 | 0 | 2067 |
| Grifola frondosa | Grifr_OBZ72870 | 77.5 | 0 | 2003 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_56143 | 87.5 | 0 | 1969 |
| Schizophyllum commune H4-8 | Schco3_2628525 | 72 | 0 | 1933 |
| Auricularia subglabra | Aurde3_1_1278475 | 57.7 | 0 | 1718 |
| Lentinula edodes NBRC 111202 | Lenedo1_818980 | 91.9 | 0 | 1289 |
| Lentinula edodes B17 | Lened_B_1_1_8551 | 78.5 | 0 | 1275 |
| Flammulina velutipes | Flave_chr09AA01382 | 83.4 | 0 | 1257 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 10957 |
| Description | Histidine kinase (EC 2.7.13.3) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd06225 | HAMP | - | 6 | 50 |
| CDD | cd06225 | HAMP | - | 101 | 143 |
| CDD | cd00082 | HisKA | IPR003661 | 253 | 295 |
| CDD | cd16922 | HATPase_EvgS-ArcB-TorS-like | - | 372 | 484 |
| CDD | cd17546 | REC_hyHK_CKI1_RcsC-like | - | 633 | 752 |
| Pfam | PF00672 | HAMP domain | IPR003660 | 2 | 50 |
| Pfam | PF00672 | HAMP domain | IPR003660 | 93 | 143 |
| Pfam | PF00512 | His Kinase A (phospho-acceptor) domain | IPR003661 | 255 | 320 |
| Pfam | PF02518 | Histidine kinase-, DNA gyrase B-, and HSP90-like ATPase | IPR003594 | 367 | 484 |
| Pfam | PF00072 | Response regulator receiver domain | IPR001789 | 633 | 753 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR036890 | Histidine kinase/HSP90-like ATPase superfamily |
| IPR005467 | Histidine kinase domain |
| IPR003660 | HAMP domain |
| IPR004358 | Signal transduction histidine kinase-related protein, C-terminal |
| IPR036097 | Signal transduction histidine kinase, dimerisation/phosphoacceptor domain superfamily |
| IPR003661 | Signal transduction histidine kinase, dimerisation/phosphoacceptor domain |
| IPR001789 | Signal transduction response regulator, receiver domain |
| IPR003594 | Histidine kinase/HSP90-like ATPase |
| IPR011006 | CheY-like superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0007165 | signal transduction | BP |
| GO:0016020 | membrane | CC |
| GO:0016310 | phosphorylation | BP |
| GO:0016772 | transferase activity, transferring phosphorus-containing groups | MF |
| GO:0000155 | phosphorelay sensor kinase activity | MF |
| GO:0000160 | phosphorelay signal transduction system | BP |
KEGG
| KEGG Orthology |
|---|
| K11231 |
| K19691 |
EggNOG
| COG category | Description |
|---|---|
| G | His Kinase A (phosphoacceptor) domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| ungrouped |
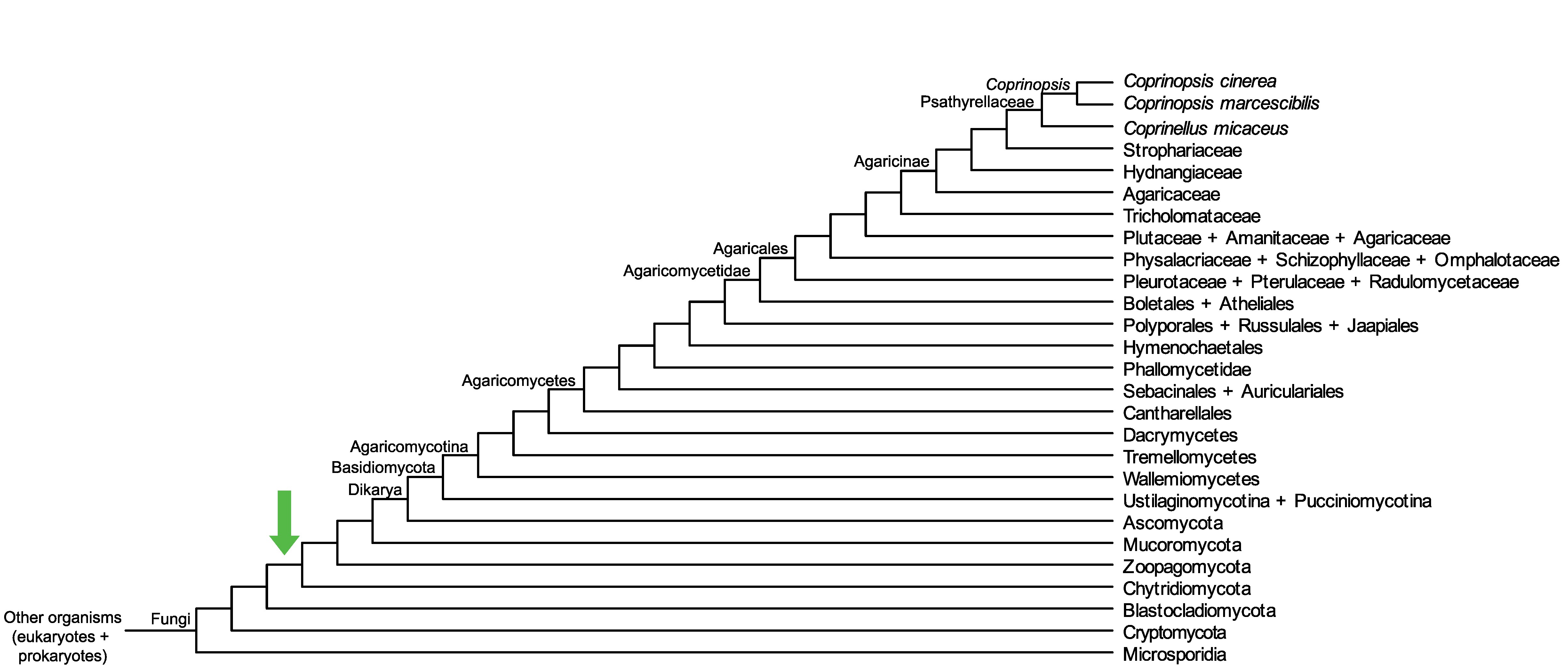
Conservation of CC1G_13258 across fungi.
Arrow shows the origin of gene family containing CC1G_13258.
Protein
| Sequence id | 10957 |
|---|---|
| Sequence |
>10957 MAMNLTNQVRSIAQVTKAVAGGDLTKKIDVDARGEILELKDTVNGMTASLSVFADEVTRVAREVGTEGRLGGQAR VTNVGGTWKDLTDNVNVMANNLTLQVRTIAVATTAVARGDLTQKITGVSVSGEMLSLVNTINDMIDQLAIFAAEV KKVAREVGTEGKLGVQAEVGNVQGIWQEITLSVNTMAGNLTTQVRGFAQISAAAMDGDFTRFITVEASGEMDSLK TQINQMVFNLRDSIQKNTAAREAAELANRSKSEFLANMSHEIRTPMNGIIGMTELTLDSDLNRSQRESLLLVHSL ARSLLLIIDDILDISKIEAGRMTMEAVTYSLRQTVFGILKTLVVRASQNNLDLTYDVEPDIPDQLIGDSLRLRQV ITNLVGNAIKFTPSKVNRKGQVALSTRLLAMDDQSVTLEFCVTDTGIGIAKDKLNLIFDTFCQADGSTTREYGGT GLGLSISKRLVSLMQGNMWVESEVSKGSKFYFTITSQINHSSMEATLGKMQPFAKRTILFVDTLRDTTGVVNRIK ELNLRPYVIHEVAEVADKEKCPHIDTIVVDSLNVVESLRELEHLRYIPIVLLAPSLPRLNLKWCLDNSLSSQITT PVSAQDLASSLISALESNTVSPVSAPNDVTFDILLAEDNLVNQKLAVKILEKYGHSVEIAENGSLAVDAFKARVA QNKPFDIILMDVSMPFMGGMEATELIRSYEMHKGLTATPIIALTAHAMIGDRERCLQAGMDDHITKPLRRGDLLN AINKLAGANRKEPHHLMRRPPAIAPGPSTFTLAS |
| Length | 784 |
Coding
| Sequence id | CC1G_13258T0 |
|---|---|
| Sequence |
>CC1G_13258T0 ATGGCCATGAACCTCACCAACCAAGTGCGATCTATCGCGCAAGTTACGAAAGCTGTAGCTGGTGGTGATTTGACG AAGAAGATTGATGTTGATGCGAGGGGTGAGATTTTGGAGTTGAAGGACACTGTTAATGGGATGACGGCTAGTTTG AGTGTGTTTGCTGATGAGGTTACGAGGGTGGCGAGGGAAGTCGGAACGGAAGGACGGTTGGGTGGTCAAGCGCGT GTTACGAATGTTGGTGGGACGTGGAAGGATTTGACGGATAATGTCAACGTCATGGCGAACAATTTGACGTTGCAG GTTCGGACTATTGCTGTTGCTACGACCGCCGTAGCCCGTGGTGACCTCACGCAGAAGATCACTGGAGTTTCCGTT TCTGGAGAAATGCTCTCCCTCGTCAATACCATCAACGACATGATTGACCAGTTGGCTATTTTCGCTGCCGAGGTT AAGAAGGTCGCTCGAGAAGTCGGAACGGAAGGAAAGCTTGGCGTTCAAGCTGAAGTTGGGAACGTGCAGGGTATT TGGCAGGAAATTACTCTCTCCGTCAACACCATGGCCGGCAACCTCACAACCCAAGTGCGAGGTTTCGCGCAAATC AGTGCGGCGGCGATGGACGGTGATTTCACGCGATTCATCACTGTTGAAGCGAGTGGTGAGATGGATAGTCTCAAG ACGCAGATTAACCAGATGGTTTTCAATTTGAGGGATAGTATTCAGAAGAATACGGCTGCGAGGGAGGCTGCTGAG TTGGCTAATAGGAGTAAGAGTGAGTTTTTGGCGAATATGAGTCATGAGATTCGGACGCCTATGAACGGTATCATC GGTATGACGGAGCTTACGCTCGATAGTGATCTTAATCGATCGCAACGCGAGAGTTTGCTGCTCGTCCATTCGTTG GCGAGGTCACTGCTTTTGATTATTGATGATATTTTGGATATTTCCAAGATCGAAGCCGGCCGGATGACGATGGAA GCTGTGACCTACTCCCTCCGCCAGACTGTCTTTGGTATCCTCAAGACCCTCGTCGTCCGCGCTTCGCAGAACAAC CTCGACCTCACGTATGACGTCGAGCCTGATATTCCCGACCAGCTCATCGGCGACTCGCTCCGTCTCCGACAGGTT ATCACCAACCTCGTTGGTAATGCTATCAAGTTCACGCCATCCAAGGTGAACAGGAAGGGTCAGGTTGCGTTGAGC ACGCGGTTGTTGGCGATGGATGATCAGAGTGTTACTCTCGAGTTCTGCGTTACGGATACGGGTATTGGTATTGCC AAGGACAAGTTGAACTTGATTTTCGACACGTTCTGTCAAGCTGATGGTTCGACTACTCGTGAATACGGTGGCACT GGTCTCGGTCTCTCCATCTCCAAGCGTCTCGTCTCGCTCATGCAAGGCAACATGTGGGTCGAGTCGGAAGTGTCC AAGGGATCCAAGTTTTACTTCACCATCACGTCGCAAATCAACCACTCGTCTATGGAGGCTACGCTCGGCAAGATG CAGCCTTTCGCCAAACGCACGATCTTGTTCGTGGATACGCTGAGGGATACGACTGGAGTGGTAAATAGGATTAAG GAGTTGAATTTGAGGCCGTATGTTATTCATGAGGTTGCGGAGGTGGCGGATAAGGAGAAGTGTCCGCATATTGAT ACGATTGTTGTTGATTCGTTGAATGTGGTTGAATCACTTCGCGAACTCGAACACCTGCGGTACATTCCTATCGTC CTCCTTGCCCCCTCCCTCCCACGTCTCAACCTCAAATGGTGCCTCGACAACTCGCTCTCCTCGCAAATCACGACA CCGGTATCGGCCCAAGACCTCGCGTCTTCACTCATCTCCGCCCTCGAGAGTAACACTGTTTCGCCTGTCTCTGCG CCGAACGATGTGACGTTTGATATACTCCTGGCGGAGGATAACTTGGTTAACCAGAAGCTGGCGGTGAAGATTTTG GAAAAATATGGGCATAGTGTTGAGATTGCGGAGAATGGAAGTTTGGCGGTTGATGCGTTCAAGGCGAGGGTTGCG CAGAATAAGCCGTTTGATATTATCCTCATGGACGTGTCTATGCCTTTCATGGGTGGTATGGAAGCTACGGAGTTG ATTCGGTCGTATGAGATGCATAAGGGGTTGACGGCTACTCCTATCATTGCTTTGACTGCTCATGCCATGATTGGT GATCGTGAACGGTGCTTGCAGGCTGGTATGGACGATCATATCACCAAACCTCTCCGACGAGGCGACCTCCTCAAC GCCATCAACAAGCTCGCCGGCGCGAACCGCAAAGAACCGCACCACCTCATGCGCCGCCCGCCTGCTATCGCTCCT GGACCTTCAACGTTTACTCTCGCCTCG |
| Length | 2355 |
Transcript
| Sequence id | CC1G_13258T0 |
|---|---|
| Sequence |
>CC1G_13258T0 ATGGCCATGAACCTCACCAACCAAGTGCGATCTATCGCGCAAGTTACGAAAGCTGTAGCTGGTGGTGATTTGACG AAGAAGATTGATGTTGATGCGAGGGGTGAGATTTTGGAGTTGAAGGACACTGTTAATGGGATGACGGCTAGTTTG AGTGTGTTTGCTGATGAGGTTACGAGGGTGGCGAGGGAAGTCGGAACGGAAGGACGGTTGGGTGGTCAAGCGCGT GTTACGAATGTTGGTGGGACGTGGAAGGATTTGACGGATAATGTCAACGTCATGGCGAACAATTTGACGTTGCAG GTTCGGACTATTGCTGTTGCTACGACCGCCGTAGCCCGTGGTGACCTCACGCAGAAGATCACTGGAGTTTCCGTT TCTGGAGAAATGCTCTCCCTCGTCAATACCATCAACGACATGATTGACCAGTTGGCTATTTTCGCTGCCGAGGTT AAGAAGGTCGCTCGAGAAGTCGGAACGGAAGGAAAGCTTGGCGTTCAAGCTGAAGTTGGGAACGTGCAGGGTATT TGGCAGGAAATTACTCTCTCCGTCAACACCATGGCCGGCAACCTCACAACCCAAGTGCGAGGTTTCGCGCAAATC AGTGCGGCGGCGATGGACGGTGATTTCACGCGATTCATCACTGTTGAAGCGAGTGGTGAGATGGATAGTCTCAAG ACGCAGATTAACCAGATGGTTTTCAATTTGAGGGATAGTATTCAGAAGAATACGGCTGCGAGGGAGGCTGCTGAG TTGGCTAATAGGAGTAAGAGTGAGTTTTTGGCGAATATGAGTCATGAGATTCGGACGCCTATGAACGGTATCATC GGTATGACGGAGCTTACGCTCGATAGTGATCTTAATCGATCGCAACGCGAGAGTTTGCTGCTCGTCCATTCGTTG GCGAGGTCACTGCTTTTGATTATTGATGATATTTTGGATATTTCCAAGATCGAAGCCGGCCGGATGACGATGGAA GCTGTGACCTACTCCCTCCGCCAGACTGTCTTTGGTATCCTCAAGACCCTCGTCGTCCGCGCTTCGCAGAACAAC CTCGACCTCACGTATGACGTCGAGCCTGATATTCCCGACCAGCTCATCGGCGACTCGCTCCGTCTCCGACAGGTT ATCACCAACCTCGTTGGTAATGCTATCAAGTTCACGCCATCCAAGGTGAACAGGAAGGGTCAGGTTGCGTTGAGC ACGCGGTTGTTGGCGATGGATGATCAGAGTGTTACTCTCGAGTTCTGCGTTACGGATACGGGTATTGGTATTGCC AAGGACAAGTTGAACTTGATTTTCGACACGTTCTGTCAAGCTGATGGTTCGACTACTCGTGAATACGGTGGCACT GGTCTCGGTCTCTCCATCTCCAAGCGTCTCGTCTCGCTCATGCAAGGCAACATGTGGGTCGAGTCGGAAGTGTCC AAGGGATCCAAGTTTTACTTCACCATCACGTCGCAAATCAACCACTCGTCTATGGAGGCTACGCTCGGCAAGATG CAGCCTTTCGCCAAACGCACGATCTTGTTCGTGGATACGCTGAGGGATACGACTGGAGTGGTAAATAGGATTAAG GAGTTGAATTTGAGGCCGTATGTTATTCATGAGGTTGCGGAGGTGGCGGATAAGGAGAAGTGTCCGCATATTGAT ACGATTGTTGTTGATTCGTTGAATGTGGTTGAATCACTTCGCGAACTCGAACACCTGCGGTACATTCCTATCGTC CTCCTTGCCCCCTCCCTCCCACGTCTCAACCTCAAATGGTGCCTCGACAACTCGCTCTCCTCGCAAATCACGACA CCGGTATCGGCCCAAGACCTCGCGTCTTCACTCATCTCCGCCCTCGAGAGTAACACTGTTTCGCCTGTCTCTGCG CCGAACGATGTGACGTTTGATATACTCCTGGCGGAGGATAACTTGGTTAACCAGAAGCTGGCGGTGAAGATTTTG GAAAAATATGGGCATAGTGTTGAGATTGCGGAGAATGGAAGTTTGGCGGTTGATGCGTTCAAGGCGAGGGTTGCG CAGAATAAGCCGTTTGATATTATCCTCATGGACGTGTCTATGCCTTTCATGGGTGGTATGGAAGCTACGGAGTTG ATTCGGTCGTATGAGATGCATAAGGGGTTGACGGCTACTCCTATCATTGCTTTGACTGCTCATGCCATGATTGGT GATCGTGAACGGTGCTTGCAGGCTGGTATGGACGATCATATCACCAAACCTCTCCGACGAGGCGACCTCCTCAAC GCCATCAACAAGCTCGCCGGCGCGAACCGCAAAGAACCGCACCACCTCATGCGCCGCCCGCCTGCTATCGCTCCT GGACCTTCAACGTTTACTCTCGCCTCGTAA |
| Length | 2355 |
Gene
| Sequence id | CC1G_13258T0 |
|---|---|
| Sequence |
>CC1G_13258T0 ATGGCCATGAACCTCACCAACCAAGTGCGATCTATCGCGCAAGTTACGAAAGCTGTAGCTGGTGGTGATTTGACG AAGAAGATTGATGTTGATGCGAGGGGTGAGATTTTGGAGTTGAAGGACACTGTTAATGGGATGACGGCTAGTTTG AGTGTGTTTGCTGATGAGGTTACGAGGTGCGTATCGCCGCCTGATTGGCGTGCCACCAATTAAGGAACAATACTG ACGGATGATTGCTTACAGGGTGGCGAGGGAAGTCGGAACGGAAGGACGGTTGGGTGGTCAAGCGCGTGTTACGAA TGTTGGTGGGACGTGGAAGGATTTGACGGATAATGTCAACGTCATGGCGAACAATTTGACGTTGCAGGTTCGGAC TATTGCTGTTGCTACGGTGCGTGAATATTGGTTTGTTGAGGTGGTGGGTTTTCTGACGGTTGACTGTGCTCTCCC GGCTCGCGTCAATCCACGTCGCATTAATGCACTCGCTCTCGCCAACACTCATCATATTAATACACTCGCTCCCGC TCGTTCGCACCGCACAGACCGCCGTAGCCCGTGGTGACCTCACGCAGAAGATCACTGGAGTTTCCGTTTCTGGAG AAATGCTCTCCCTCGTCAATACCATCAACGACATGATTGACCAGTTGGCTATTTTCGCTGCCGAGGTTAAGAAGG TGCGTTCTACTTTTATTATGGGAGGGGAGAGTAGGAGAAAGGAGGGCTAACTGGGTTCGGTGTAGGTCGCTCGAG AAGTCGGAACGGAAGGAAAGCTTGGCGTTCAAGCTGAAGTTGGGAACGTGCAGGGTATTTGGCAGGAAATTACGT GCGTCCCTTCTCCTTCCCTCTATCCTCCCCATCGTAGCTGACGCTGGTTCTGCTGCTCACAGTCTCTCCGTCAAC ACCATGGCCGGCAACCTCACAACCCAAGTGCGAGGTTTCGCGCAAATCAGTGCGGCGGCGATGGACGGTGATTTC ACGCGATTCATCACTGTTGAAGCGAGTGGTGAGATGGATAGTCTCAAGACGCAGATTAACCAGATGGTTTTCAAT TTGAGGGATAGTATTCAGAAGAATACGGCTGCGAGGGAGGCTGCTGAGTTGGCTAATAGGAGTAAGAGTGAGTTT TTGGCGAATATGAGTCATGAGATTCGGTGAGTGGCCTATTCTTATTCTCTCTTCGCTCTTTTCTTTTTCTAGTAG GATGAGAGCTGATGTGTTTTAATCCTTGGGATATAGGACGCCTATGAACGGTATCATCGGTATGACGGAGCTTAC GCTCGATAGTGATCTTAATCGATCGCAACGCGAGAGTTTGCTGCTCGTCCATTCGTTGGCGAGGTCACTGCTTTT GATTATTGATGATATTTTGGATATTTCCAAGAGTGCGTATTTCCTTTTTGGTTTGCGTGGGCTGGGGTTGGTTAT TGACCCTTGATTACTGTCTACAGTCGAAGCCGGCCGGATGACGATGGAAGCTGTGACCTACTCCCTCCGCCAGAC TGTCTTTGGTATCCTCAAGACCCTCGTCGTCCGCGCTTCGCAGAACAACCTCGACCTCACGTATGACGTCGAGCC TGATATTCCCGACCAGCTCATCGGCGACTCGCTCCGTCTCCGACAGGTTATCACCAACCTCGTTGGTAATGCTAT CAAGTTCACGCCATCCAAGGTTCGTCGTCGTGATCTCTCGTACTTTGGAGTTGGAGGCTGATGGGTTTTGTGATG TAGGTGAACAGGAAGGGTCAGGTTGCGTTGAGCACGCGGTTGTTGGCGATGGATGATCAGAGTGTTACTCTCGAG TTCTGCGTTACGGATACGGGTATTGGTATTGCCAAGGACAAGTTGAACTTGATTTTCGACACGTTCTGTCAAGCT GATGGTTCGACTACTCGTGTATGTTTCTCTTTTATCTTCTCGTTCGTTCGTTGCTCACGCACGCGTTTAGGAATA CGGTGGCACTGGTCTCGGTCTCTCCATCTCCAAGCGTCTCGTCTCGCTCATGCAAGGCAACATGTGGGTCGAGTC GGAAGTGTCCAAGGGATCCAAGTTTTACTTCACCATCACGTCGCAAATCAACCACTCGTCTATGGAGGCTACGCT CGGCAAGATGCAGCCTTTCGCCAAACGCACGATCTTGTTCGTGGATACGCTGAGGGATACGACTGGAGTGGTAAA TAGGATTAAGGAGTTGAATTTGAGGCCGTATGTTATTCATGAGGTTGCGGAGGTGGCGGATAAGGAGAAGTGTCC GCATATTGATACGATTGTTGTTGATTCGTTGAATGTGGTGCGTAGTCGCTTTTCGTTCTTTGTCGGGTGGTATCG AGGGGCTGATGGCGTCTCGGTTGGTTTTGATAGGTTGAATCACTTCGCGAACTCGAACACCTGCGGTACATTCCT ATCGTCCTCCTTGCCCCCTCCCTCCCACGTCTCAACCTCAAATGGTGCCTCGACAACTCGCTCTCCTCGCAAATC ACGACACCGGTATCGGCCCAAGACCTCGCGTCTTCACTCATCTCCGCCCTCGAGAGTAACACTGTTTCGCCTGTC TCTGCGCCGAACGATGTGACGTTTGATATACTCCTGGCGGAGGATAACTTGGTTAACCAGAAGCTGGCGGTGAAG ATTTTGGAAAAATATGGGCATAGTGTTGAGATTGCGGAGAATGGAAGTTTGGCGGTTGATGCGTTCAAGGCGAGG GTTGCGCAGAATAAGCCGTTTGATATTATCCTCGTGAGTTTCACTCTATCGTTGGTTTTTTTCACCTGTGATTGG ATGCTAATGAGGTGGGGTTTGTAGATGGACGTGTCTATGCCTTTCATGGGTGGTATGGAAGCTACGGAGTTGATT CGGTCGTATGAGATGCATAAGGGGTTGACGGCTACTCCTATCATTGCTTTGACTGCTCATGCCAGTATGTCTATC TTTTGTGTTTGGTGATTCGGGGTGCTAATCTGCGATCGTAGTGATTGGTGATCGTGAACGGTGCTTGCAGGCTGG TATGGACGATCATATCACCAGTAGGTCTTCTCCTTTCGCGTTATGATTCTCATCGTGCTGACGCCTGGGTGCTTA GAACCTCTCCGACGAGGCGACCTCCTCAACGCCATCAACAAGCTCGCCGGCGCGAACCGCAAAGAACCGCACCAC CTCATGCGCCGCCCGCCTGCTATCGCTCCTGGACCTTCGTACGCATAGATCTTCTTCACGATACCCCCCGTCCTT TTTTTTCCCATCCTGTGGATATGTTTTGCCGACGCGGTTTTTCTTTTGAGCAGACTGAGGTCGTTTGTGGTCTCG CCGATTGCGGACCGGTTTGGGCAGATATGATGGGTGGGAGGTCTTGGAGGTGCCGGTCTGTGATTGCAATGGCGA GTCTCGAATGGAGCGAGCGACCTTGGACATCTCCTAATGCATGCCCCGACCCCGTTATGAGATACCCCCGATGAT GACATTCCCCCAGAACGTTTACTCTCGCCTCGTAA |
| Length | 3485 |