CC1G_14422
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_14422 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RM33 | Functional description | Atypical/HisK protein kinase |
| Location | Chr_4:2138069..2144171 | Strand | + |
| Gene length (nt) | 6103 | Transcript length (nt) | 4554 |
| CDS length (nt) | 4554 | Protein length (aa) | 1517 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB26087 | 56.4 | 0 | 1628 |
| Agrocybe aegerita | Agrae_CAA7266924 | 58.4 | 0 | 1598 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_201390 | 52.5 | 0 | 1405 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_59639 | 51.8 | 0 | 1401 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_4034 | 49.5 | 0 | 1384 |
| Lentinula edodes NBRC 111202 | Lenedo1_390962 | 64.1 | 0 | 1342 |
| Pleurotus ostreatus PC9 | PleosPC9_1_116161 | 53.8 | 0 | 1267 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1067353 | 53.5 | 0 | 1266 |
| Grifola frondosa | Grifr_OBZ72215 | 60.8 | 0 | 1216 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_112078 | 45.2 | 0 | 1102 |
| Schizophyllum commune H4-8 | Schco3_2541638 | 43.5 | 0 | 1099 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1434413 | 53.2 | 2.723E-281 | 910 |
| Auricularia subglabra | Aurde3_1_1275710 | 44.7 | 3.803E-265 | 863 |
| Lentinula edodes B17 | Lened_B_1_1_8533 | 50.8 | 1.15E-51 | 201 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 11973 |
| Description | Atypical/HisK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd00082 | HisKA | IPR003661 | 852 | 915 |
| CDD | cd17546 | REC_hyHK_CKI1_RcsC-like | - | 1390 | 1509 |
| Pfam | PF00512 | His Kinase A (phospho-acceptor) domain | IPR003661 | 855 | 917 |
| Pfam | PF02518 | Histidine kinase-, DNA gyrase B-, and HSP90-like ATPase | IPR003594 | 1006 | 1121 |
| Pfam | PF00072 | Response regulator receiver domain | IPR001789 | 1390 | 1509 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR003661 | Signal transduction histidine kinase, dimerisation/phosphoacceptor domain |
| IPR036890 | Histidine kinase/HSP90-like ATPase superfamily |
| IPR001789 | Signal transduction response regulator, receiver domain |
| IPR003594 | Histidine kinase/HSP90-like ATPase |
| IPR005467 | Histidine kinase domain |
| IPR011006 | CheY-like superfamily |
| IPR036097 | Signal transduction histidine kinase, dimerisation/phosphoacceptor domain superfamily |
| IPR004358 | Signal transduction histidine kinase-related protein, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0000155 | phosphorelay sensor kinase activity | MF |
| GO:0007165 | signal transduction | BP |
| GO:0000160 | phosphorelay signal transduction system | BP |
| GO:0016310 | phosphorylation | BP |
| GO:0016772 | transferase activity, transferring phosphorus-containing groups | MF |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| T | Domain present in phytochromes and cGMP-specific phosphodiesterases. |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| ungrouped |
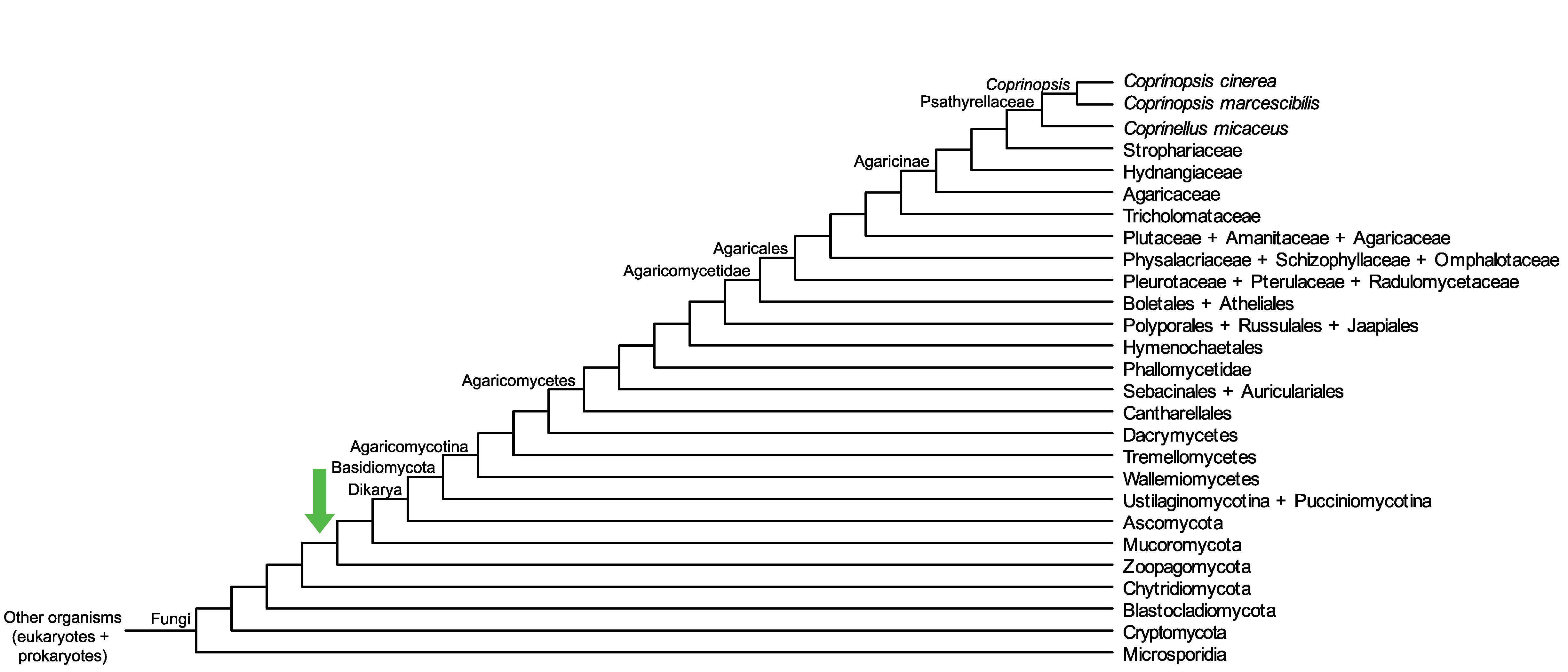
Conservation of CC1G_14422 across fungi.
Arrow shows the origin of gene family containing CC1G_14422.
Protein
| Sequence id | 11973 |
|---|---|
| Sequence |
>11973 MQAHCEPSVLNPVGKLHTNGLFVLNTAIANNRYQTSDSTGIDPRSLTQSINAAKRHTVSLPTSPYQEGSSRSYAE GTPLGQANGLATFSNEALLPRTSSSDDLEVPSDSNLLSTHGRSLSGDTECDWATFITAYANGRWDPHKPPNRPHP CHGYDSETGYMKKLEPVQLSTSLQVTASDFDQDRDGTSKLRDGRDKVSISLQAMQDQAGSIIASSTNGRKFHNLK MDFPLKLPVSGRSRISFPPSTSTASIGSNSSMASTAASNSDLQTTVATMRWAAARVDISPLALPSPEHELTDPMR GVITPVPGSHPPDDDEPHDQVITPGGSRRSRLSSFWEGTIDVDPKAFKMGSIPRKHSRLSLGGNSADGRVTPDSV QTNKQDIPDKVPKKTEHSPATQLSILAAQPPPATAPIPDKKTSSRSVEDSDYFGNFQQSPKPITAPILVEPVREV HSTSSNPAAADSGSRTVPALPRRICLTRQTSSPLPISLAPPEARIPGGRVPSDSANPNAKGRAVKEEQMFSELGY LAPPNPPDELERRRALYKFNIWYTGPDLNFDRIAHLAKLVFNTKGVIVSLIDGNEQGDEPMIVLDTHLDWRFARN PLVINSPRIRFYAGAPLRTQDGYNIGTLALIDDVSREDFSPRQRHTLKEFAAIAMREMELWRDKIQLRIRDRIQS SMEEFTRECLEIDSEVHPKVDKASIVIGTSMDRVYDRAAKLVQRTLDVEGVIVMDVTHCEVLETMGDEGNVSVTL HHGTPGSEMEKRPLSREDYQSLNNFFAAYPEGKISEGILPPSFRPYMPTHIRYALLVPIFNIDKRPFALLCAYNT NLHSKRFKGMSVIILSAVLKRRMILADKAKSLFISNISHELRTPLHGILAAAELLSDSPLNHSQMSFIQTVQACG TSLVETVNHVLDFTKLSGNVKAGGVENVIVPITNDMMQLIEEAIDGSWIGYKARTANLVDSGIGSVYSPPSDETT DQGHQPSQPHVETVIDIGYRREGWLLKYEKGGIRRVLMNLFGNSLKFTTDGYVHVRLRLLPRLPDDPPNKVRLEL AIEDTGKGISQNFLKNQLFHPFSQENPLQTGTGLGLAIVNSIVSSENVGGKVDVRSEEGQGTEIKVFFPAEIPED DPRLADAAQDMEHFRADKNSPLPKISMLGFESQHKGIQLLYRVLRTYITEWWGLDIVDDSQDSDIVVLNEDLGPI RSAIERNDIRRPFVILWVTRGNPTVLAAATEYERIGGFCRILYKPTGPSKLRGVLKLCMHSIKINRYYRDSAPMT AVRKNTVSGFAEDKDVSHGGVLRRNSDENSTYASKSLSRPPMSPRSATIHPSVSSLRHQLLLSALPEKDRGQEGE VGSPVSDGTGLRPMVSIGPGGSVLKSSVQPTDIRGRKLRVLVIEDNNILRNLLAKWLIKKGYDFEEAVDGQAGVT AFQEHGPFDVALIDLSMPVLDGVAATKEIRRIESSKAGGDDSYPSVKILALTGMSSLEDKRRAFEAGVDGYLVKP VAFKTLDEMFHKLGISS |
| Length | 1517 |
Coding
| Sequence id | CC1G_14422T0 |
|---|---|
| Sequence |
>CC1G_14422T0 ATGCAAGCACACTGCGAACCCTCAGTACTCAACCCGGTAGGGAAGCTTCATACGAATGGGCTGTTCGTTCTGAAT ACAGCCATCGCCAACAATCGCTACCAGACCAGCGACAGCACTGGGATCGACCCGAGGTCATTGACGCAGAGCATA AATGCCGCCAAACGCCATACCGTCTCGCTTCCGACCTCCCCATATCAGGAGGGCTCATCACGATCGTACGCCGAA GGCACTCCCCTCGGGCAGGCCAACGGCCTAGCCACCTTCAGTAATGAGGCTCTGCTTCCGCGAACGTCGAGCTCC GATGATCTCGAAGTGCCTTCGGATAGCAATCTACTTTCCACACATGGACGGTCATTATCTGGAGACACAGAGTGC GACTGGGCGACCTTTATCACGGCTTATGCCAATGGGCGATGGGACCCTCACAAGCCGCCGAACCGGCCTCACCCG TGTCATGGCTACGATTCCGAGACTGGGTACATGAAGAAGTTGGAGCCAGTGCAACTGTCTACCTCGCTACAAGTC ACCGCGTCGGATTTCGACCAGGACCGCGATGGAACTTCCAAGTTGCGAGACGGGCGAGACAAGGTTTCAATCTCT CTGCAGGCTATGCAGGACCAGGCCGGTTCAATCATCGCATCATCTACGAACGGACGCAAGTTCCACAATCTAAAA ATGGATTTCCCTCTCAAGCTCCCTGTTTCTGGGAGGTCACGGATCTCTTTTCCTCCTTCGACGTCTACTGCATCC ATTGGAAGCAATTCCTCCATGGCGAGCACGGCGGCCTCCAACTCGGATTTGCAGACGACCGTGGCCACAATGCGA TGGGCTGCGGCCAGAGTGGACATCTCGCCTCTGGCCCTTCCATCTCCCGAGCACGAGCTAACAGATCCCATGCGC GGTGTCATCACTCCTGTACCTGGTTCCCACCCTCCCGACGACGACGAACCTCATGACCAAGTCATAACGCCTGGT GGAAGCCGACGATCAAGGTTATCCAGCTTTTGGGAAGGTACGATAGATGTCGATCCTAAGGCCTTCAAGATGGGG TCTATTCCACGGAAACATTCGCGCTTGAGCCTGGGTGGCAACAGCGCAGATGGTAGGGTCACTCCAGATAGTGTG CAGACGAACAAACAGGATATACCAGATAAAGTTCCAAAGAAAACCGAACACTCACCCGCTACTCAACTTTCCATA CTCGCTGCTCAACCACCGCCTGCCACTGCACCAATTCCGGACAAGAAAACTTCCAGTCGATCGGTAGAAGACTCT GACTACTTTGGAAATTTTCAACAATCTCCCAAACCTATTACCGCCCCGATCCTGGTGGAACCCGTACGAGAGGTG CATTCGACTTCCTCCAACCCCGCTGCGGCGGACAGTGGATCTAGGACAGTCCCAGCGCTTCCTCGCCGCATTTGC CTCACCAGGCAAACATCCTCTCCTCTTCCGATTTCCCTGGCACCACCCGAAGCTCGTATCCCTGGAGGAAGGGTA CCATCAGACTCGGCAAATCCAAATGCCAAAGGAAGAGCTGTCAAGGAGGAACAGATGTTCTCGGAACTCGGATAC CTTGCTCCTCCAAATCCTCCAGATGAGCTTGAGCGCCGGCGAGCCTTGTATAAATTCAACATATGGTACACCGGG CCCGACCTCAACTTTGACCGAATAGCCCATCTCGCCAAGCTGGTTTTCAATACGAAGGGTGTCATCGTATCGCTC ATCGATGGCAACGAGCAAGGAGATGAGCCTATGATCGTTCTAGACACCCATCTCGATTGGAGATTTGCCAGGAAT CCATTGGTGATAAATTCCCCACGTATTCGCTTCTATGCCGGAGCCCCCTTGCGCACCCAAGATGGCTACAACATT GGCACGCTTGCCCTCATCGACGACGTCTCTCGAGAAGACTTCTCCCCCCGTCAAAGACATACTCTCAAGGAATTC GCTGCAATTGCTATGCGGGAAATGGAACTTTGGCGAGACAAAATTCAGTTGAGAATACGGGATCGAATACAAAGC TCTATGGAGGAGTTCACTCGAGAATGCTTAGAAATCGATTCCGAAGTACATCCCAAAGTCGACAAAGCTTCCATC GTGATCGGTACTTCCATGGACCGTGTTTACGACCGCGCAGCGAAGCTTGTCCAGAGAACGCTTGACGTAGAGGGA GTGATTGTCATGGATGTAACGCACTGCGAAGTTTTGGAGACTATGGGTGACGAAGGAAATGTGTCTGTGACCTTG CACCATGGCACTCCAGGGAGTGAAATGGAGAAGCGCCCGTTGTCGAGAGAAGATTACCAGAGCCTGAATAATTTC TTCGCAGCCTACCCAGAGGGCAAAATTTCTGAAGGAATTCTTCCTCCTTCTTTCAGGCCCTACATGCCCACTCAT ATCCGATATGCACTACTTGTACCGATATTCAATATAGACAAGCGCCCATTTGCCCTGCTATGCGCATATAATACT AATCTTCATTCAAAACGATTTAAGGGCATGAGTGTGATCATTCTGTCCGCTGTCCTCAAGAGACGCATGATTCTA GCCGACAAAGCGAAGAGCCTATTCATTTCAAATATTTCTCACGAGCTACGAACACCCTTGCATGGGATCCTTGCC GCTGCAGAGTTACTCAGTGACAGCCCCTTGAATCACTCACAGATGTCCTTCATCCAGACCGTCCAAGCTTGTGGC ACTTCTTTAGTTGAAACAGTCAATCATGTCCTAGACTTCACAAAGCTCAGCGGCAACGTCAAAGCCGGCGGAGTG GAGAATGTCATCGTCCCCATCACAAACGACATGATGCAACTCATAGAAGAGGCAATTGACGGAAGTTGGATCGGC TATAAAGCCAGGACGGCCAATCTGGTGGATTCGGGCATCGGCAGTGTCTACTCACCTCCAAGTGACGAAACCACC GACCAGGGCCACCAACCGTCGCAACCACATGTCGAGACGGTTATAGACATTGGGTATCGAAGAGAGGGATGGCTG CTGAAGTACGAGAAGGGTGGAATTCGCCGTGTGCTGATGAATCTCTTCGGAAACAGCCTCAAATTCACCACGGAT GGGTATGTTCACGTCAGGCTGCGGTTACTCCCTCGCTTGCCAGACGACCCGCCAAACAAAGTGAGGTTAGAGCTT GCCATCGAAGATACAGGGAAGGGTATCAGTCAGAACTTCCTCAAGAATCAACTCTTTCACCCGTTCTCGCAGGAG AATCCTCTCCAAACAGGCACCGGCCTCGGATTGGCGATAGTTAACAGTATCGTGTCTTCCGAGAATGTCGGAGGA AAGGTGGACGTCCGAAGTGAAGAGGGTCAAGGAACCGAGATCAAGGTCTTCTTCCCTGCAGAAATCCCAGAGGAC GACCCCAGGTTGGCTGATGCGGCACAAGACATGGAACACTTCCGGGCGGACAAGAACAGCCCGTTACCCAAGATA TCCATGCTAGGCTTCGAGTCTCAGCACAAAGGCATCCAACTCTTGTACAGAGTGCTTCGGACGTACATAACAGAG TGGTGGGGCCTTGACATAGTGGATGACTCTCAGGACAGTGACATCGTCGTCCTCAACGAGGACCTTGGGCCAATT CGTTCCGCCATCGAGCGCAACGACATACGTCGCCCGTTCGTGATTTTATGGGTCACACGCGGGAACCCTACTGTT CTGGCAGCCGCCACAGAATACGAACGGATAGGCGGATTCTGCCGCATCCTCTACAAGCCCACTGGCCCATCGAAA CTACGGGGGGTCCTCAAACTCTGCATGCACTCCATCAAGATCAATCGGTATTATCGCGACTCGGCACCCATGACA GCTGTACGGAAGAACACGGTATCGGGGTTTGCAGAGGACAAGGATGTATCGCATGGAGGGGTGTTGAGAAGGAAC TCGGATGAAAACTCGACTTACGCCAGCAAGTCGCTTAGTCGACCCCCAATGTCCCCGCGGTCAGCGACCATTCAT CCCTCCGTTTCCTCACTTCGGCATCAACTGTTATTATCCGCGCTTCCGGAGAAGGATCGTGGACAGGAAGGGGAA GTTGGTTCACCTGTCTCTGATGGAACAGGTCTTCGTCCGATGGTTTCTATCGGCCCTGGGGGCTCAGTCCTGAAG TCATCCGTCCAGCCGACAGACATCCGAGGCCGGAAGCTCAGGGTTTTAGTCATCGAGGACAACAACATTCTGAGG AACCTCCTGGCCAAATGGCTGATCAAGAAAGGGTATGATTTCGAAGAAGCTGTGGATGGGCAGGCAGGCGTGACG GCGTTCCAGGAACATGGTCCATTCGATGTTGCGTTGATTGACCTGTCAATGCCAGTCCTCGACGGCGTCGCGGCT ACCAAAGAGATCCGTCGTATAGAGTCCAGTAAAGCAGGGGGAGACGACAGCTACCCCTCAGTCAAGATACTTGCC CTTACTGGAATGTCTTCATTAGAAGATAAGCGGCGAGCGTTTGAAGCAGGAGTGGACGGATACCTTGTCAAACCG GTGGCCTTTAAGACCCTGGACGAGATGTTCCACAAGCTCGGGATCTCTTCA |
| Length | 4554 |
Transcript
| Sequence id | CC1G_14422T0 |
|---|---|
| Sequence |
>CC1G_14422T0 ATGCAAGCACACTGCGAACCCTCAGTACTCAACCCGGTAGGGAAGCTTCATACGAATGGGCTGTTCGTTCTGAAT ACAGCCATCGCCAACAATCGCTACCAGACCAGCGACAGCACTGGGATCGACCCGAGGTCATTGACGCAGAGCATA AATGCCGCCAAACGCCATACCGTCTCGCTTCCGACCTCCCCATATCAGGAGGGCTCATCACGATCGTACGCCGAA GGCACTCCCCTCGGGCAGGCCAACGGCCTAGCCACCTTCAGTAATGAGGCTCTGCTTCCGCGAACGTCGAGCTCC GATGATCTCGAAGTGCCTTCGGATAGCAATCTACTTTCCACACATGGACGGTCATTATCTGGAGACACAGAGTGC GACTGGGCGACCTTTATCACGGCTTATGCCAATGGGCGATGGGACCCTCACAAGCCGCCGAACCGGCCTCACCCG TGTCATGGCTACGATTCCGAGACTGGGTACATGAAGAAGTTGGAGCCAGTGCAACTGTCTACCTCGCTACAAGTC ACCGCGTCGGATTTCGACCAGGACCGCGATGGAACTTCCAAGTTGCGAGACGGGCGAGACAAGGTTTCAATCTCT CTGCAGGCTATGCAGGACCAGGCCGGTTCAATCATCGCATCATCTACGAACGGACGCAAGTTCCACAATCTAAAA ATGGATTTCCCTCTCAAGCTCCCTGTTTCTGGGAGGTCACGGATCTCTTTTCCTCCTTCGACGTCTACTGCATCC ATTGGAAGCAATTCCTCCATGGCGAGCACGGCGGCCTCCAACTCGGATTTGCAGACGACCGTGGCCACAATGCGA TGGGCTGCGGCCAGAGTGGACATCTCGCCTCTGGCCCTTCCATCTCCCGAGCACGAGCTAACAGATCCCATGCGC GGTGTCATCACTCCTGTACCTGGTTCCCACCCTCCCGACGACGACGAACCTCATGACCAAGTCATAACGCCTGGT GGAAGCCGACGATCAAGGTTATCCAGCTTTTGGGAAGGTACGATAGATGTCGATCCTAAGGCCTTCAAGATGGGG TCTATTCCACGGAAACATTCGCGCTTGAGCCTGGGTGGCAACAGCGCAGATGGTAGGGTCACTCCAGATAGTGTG CAGACGAACAAACAGGATATACCAGATAAAGTTCCAAAGAAAACCGAACACTCACCCGCTACTCAACTTTCCATA CTCGCTGCTCAACCACCGCCTGCCACTGCACCAATTCCGGACAAGAAAACTTCCAGTCGATCGGTAGAAGACTCT GACTACTTTGGAAATTTTCAACAATCTCCCAAACCTATTACCGCCCCGATCCTGGTGGAACCCGTACGAGAGGTG CATTCGACTTCCTCCAACCCCGCTGCGGCGGACAGTGGATCTAGGACAGTCCCAGCGCTTCCTCGCCGCATTTGC CTCACCAGGCAAACATCCTCTCCTCTTCCGATTTCCCTGGCACCACCCGAAGCTCGTATCCCTGGAGGAAGGGTA CCATCAGACTCGGCAAATCCAAATGCCAAAGGAAGAGCTGTCAAGGAGGAACAGATGTTCTCGGAACTCGGATAC CTTGCTCCTCCAAATCCTCCAGATGAGCTTGAGCGCCGGCGAGCCTTGTATAAATTCAACATATGGTACACCGGG CCCGACCTCAACTTTGACCGAATAGCCCATCTCGCCAAGCTGGTTTTCAATACGAAGGGTGTCATCGTATCGCTC ATCGATGGCAACGAGCAAGGAGATGAGCCTATGATCGTTCTAGACACCCATCTCGATTGGAGATTTGCCAGGAAT CCATTGGTGATAAATTCCCCACGTATTCGCTTCTATGCCGGAGCCCCCTTGCGCACCCAAGATGGCTACAACATT GGCACGCTTGCCCTCATCGACGACGTCTCTCGAGAAGACTTCTCCCCCCGTCAAAGACATACTCTCAAGGAATTC GCTGCAATTGCTATGCGGGAAATGGAACTTTGGCGAGACAAAATTCAGTTGAGAATACGGGATCGAATACAAAGC TCTATGGAGGAGTTCACTCGAGAATGCTTAGAAATCGATTCCGAAGTACATCCCAAAGTCGACAAAGCTTCCATC GTGATCGGTACTTCCATGGACCGTGTTTACGACCGCGCAGCGAAGCTTGTCCAGAGAACGCTTGACGTAGAGGGA GTGATTGTCATGGATGTAACGCACTGCGAAGTTTTGGAGACTATGGGTGACGAAGGAAATGTGTCTGTGACCTTG CACCATGGCACTCCAGGGAGTGAAATGGAGAAGCGCCCGTTGTCGAGAGAAGATTACCAGAGCCTGAATAATTTC TTCGCAGCCTACCCAGAGGGCAAAATTTCTGAAGGAATTCTTCCTCCTTCTTTCAGGCCCTACATGCCCACTCAT ATCCGATATGCACTACTTGTACCGATATTCAATATAGACAAGCGCCCATTTGCCCTGCTATGCGCATATAATACT AATCTTCATTCAAAACGATTTAAGGGCATGAGTGTGATCATTCTGTCCGCTGTCCTCAAGAGACGCATGATTCTA GCCGACAAAGCGAAGAGCCTATTCATTTCAAATATTTCTCACGAGCTACGAACACCCTTGCATGGGATCCTTGCC GCTGCAGAGTTACTCAGTGACAGCCCCTTGAATCACTCACAGATGTCCTTCATCCAGACCGTCCAAGCTTGTGGC ACTTCTTTAGTTGAAACAGTCAATCATGTCCTAGACTTCACAAAGCTCAGCGGCAACGTCAAAGCCGGCGGAGTG GAGAATGTCATCGTCCCCATCACAAACGACATGATGCAACTCATAGAAGAGGCAATTGACGGAAGTTGGATCGGC TATAAAGCCAGGACGGCCAATCTGGTGGATTCGGGCATCGGCAGTGTCTACTCACCTCCAAGTGACGAAACCACC GACCAGGGCCACCAACCGTCGCAACCACATGTCGAGACGGTTATAGACATTGGGTATCGAAGAGAGGGATGGCTG CTGAAGTACGAGAAGGGTGGAATTCGCCGTGTGCTGATGAATCTCTTCGGAAACAGCCTCAAATTCACCACGGAT GGGTATGTTCACGTCAGGCTGCGGTTACTCCCTCGCTTGCCAGACGACCCGCCAAACAAAGTGAGGTTAGAGCTT GCCATCGAAGATACAGGGAAGGGTATCAGTCAGAACTTCCTCAAGAATCAACTCTTTCACCCGTTCTCGCAGGAG AATCCTCTCCAAACAGGCACCGGCCTCGGATTGGCGATAGTTAACAGTATCGTGTCTTCCGAGAATGTCGGAGGA AAGGTGGACGTCCGAAGTGAAGAGGGTCAAGGAACCGAGATCAAGGTCTTCTTCCCTGCAGAAATCCCAGAGGAC GACCCCAGGTTGGCTGATGCGGCACAAGACATGGAACACTTCCGGGCGGACAAGAACAGCCCGTTACCCAAGATA TCCATGCTAGGCTTCGAGTCTCAGCACAAAGGCATCCAACTCTTGTACAGAGTGCTTCGGACGTACATAACAGAG TGGTGGGGCCTTGACATAGTGGATGACTCTCAGGACAGTGACATCGTCGTCCTCAACGAGGACCTTGGGCCAATT CGTTCCGCCATCGAGCGCAACGACATACGTCGCCCGTTCGTGATTTTATGGGTCACACGCGGGAACCCTACTGTT CTGGCAGCCGCCACAGAATACGAACGGATAGGCGGATTCTGCCGCATCCTCTACAAGCCCACTGGCCCATCGAAA CTACGGGGGGTCCTCAAACTCTGCATGCACTCCATCAAGATCAATCGGTATTATCGCGACTCGGCACCCATGACA GCTGTACGGAAGAACACGGTATCGGGGTTTGCAGAGGACAAGGATGTATCGCATGGAGGGGTGTTGAGAAGGAAC TCGGATGAAAACTCGACTTACGCCAGCAAGTCGCTTAGTCGACCCCCAATGTCCCCGCGGTCAGCGACCATTCAT CCCTCCGTTTCCTCACTTCGGCATCAACTGTTATTATCCGCGCTTCCGGAGAAGGATCGTGGACAGGAAGGGGAA GTTGGTTCACCTGTCTCTGATGGAACAGGTCTTCGTCCGATGGTTTCTATCGGCCCTGGGGGCTCAGTCCTGAAG TCATCCGTCCAGCCGACAGACATCCGAGGCCGGAAGCTCAGGGTTTTAGTCATCGAGGACAACAACATTCTGAGG AACCTCCTGGCCAAATGGCTGATCAAGAAAGGGTATGATTTCGAAGAAGCTGTGGATGGGCAGGCAGGCGTGACG GCGTTCCAGGAACATGGTCCATTCGATGTTGCGTTGATTGACCTGTCAATGCCAGTCCTCGACGGCGTCGCGGCT ACCAAAGAGATCCGTCGTATAGAGTCCAGTAAAGCAGGGGGAGACGACAGCTACCCCTCAGTCAAGATACTTGCC CTTACTGGAATGTCTTCATTAGAAGATAAGCGGCGAGCGTTTGAAGCAGGAGTGGACGGATACCTTGTCAAACCG GTGGCCTTTAAGACCCTGGACGAGATGTTCCACAAGCTCGGGATCTCTTCATAG |
| Length | 4554 |
Gene
| Sequence id | CC1G_14422T0 |
|---|---|
| Sequence |
>CC1G_14422T0 ATGCAAGCACACTGCGAACCCTCAGTACTCAACCCGGTAGGGAAGCTTCATACGAATGGGCTGTTCGTTCTGAAT ACAGCCATCGCCAACAATCGCTACCAGACCAGCGACAGCACTGGGATCGACCCGAGGTCATTGACGCAGAGCATA AATGCCGCCAAACGTGCGTGTAAGACCGTATCAGGGTGCCTGCGACCCGAACACAGAAAAGGACAAATTCTGACG TCGTGGATCTCTGTAGGCCATACCGTCTCGCTTCCGACCTCCCCATATCAGGAGGGCTCATCACGATCGTACGCC GAAGGCACTCCCCTCGGGCAGGCCAACGGCCTAGCCACCTTCAGTAATGAGGCTCTGCTTCCGCGAACGTCGAGC TCCGGTACGTTTTTGTAAGGAAATGTTCTCAATGTATGTCTAACATGTCGTCCAGATGATCTCGAAGTGCCTTCG GATAGCAATCTACTTTCCACACATGGACGGTCATTATCTGGAGACACAGAGTGCGACTGGGCGACCTTTATCACG GCTTATGCCAATGGGCGATGGGACCCTCACAAGCCGCCGAACCGGCCTCACCCGTGTCATGGCTACGATTCCGAG ACTGGGTACATGAAGAAGTTGGAGCCAGTGCAACTGTCTACCTCGCTACAAGTCACCGCGTCGGATTTCGACCAG GACCGCGATGGAACTTCCAAGTTGCGAGACGGGCGAGACAAGGTTTCAATCTCTCTGCAGGCTATGCAGGACCAG GCCGGTTCAATCATCGCATCATCTACGAACGGACGCAAGTTCCACAATCTAAAAATGGATTTCCCTCTCAAGCTC CCTGTTTCTGGGAGGTCACGGATCTCTTTTCCTCCTTCGACGTCTACTGCATCCATTGGAAGCAATTCCTCCATG GCGAGCACGGCGGCCTCCAACTCGGATTTGCAGACGACCGTGGCCACAATGCGATGGGCTGCGGCCAGAGTGGAC ATCTCGCCTCTGGCCCTTCCATCTCCCGAGCACGAGCTAACAGATCCCATGCGCGGTGTCATCACTCCTGTACCT GGTTCCCACCCTCCCGACGACGACGAACCTCATGACCAAGTCATAACGCCTGGTGGAAGCCGACGATCAAGGTTA TCCAGCTTTTGGGAAGGTACGATAGATGTCGATCCTAAGGCCTTCAAGATGGGGTCTATTCCACGGAAACATTCG CGCTTGAGCCTGGGTGGCAACAGCGCAGATGGTAGGGTCACTCCAGATAGTGTGCAGACGAACAAACAGGATATA CCAGATAAAGTTCCAAAGAAAACCGAACACTCACCCGCTACTCAACTTTCCATACTCGCTGCTCAACCACCGCCT GCCACTGCACCAATTCCGGACAAGAAAACTTCCAGTCGATCGGTAGAAGACTCTGACTACTTTGGAAATTTTCAA CAATCTCCCAAACCTATTACCGCCCCGATCCTGGTGGAACCCGTACGAGAGGTGCATTCGACTTCCTCCAACCCC GCTGCGGCGGACAGTGGATCTAGGACAGTCCCAGCGCTTCCTCGCCGCATTTGCCTCACCAGGCAAACATCCTCT CCTCTTCCGATTTCCCTGGCACCACCCGAAGCTCGTATCCCTGGAGGAAGGGTACCATCAGACTCGGCAAATCCA AATGCCAAAGGAAGAGCTGTCAAGGAGGAACAGATGTTCTCGGAACTCGGATACCTTGCTCCTCCAAATCCTCCA GATGAGCTTGAGCGCCGGCGAGCCTTGTATAAGTGCGTTGCCACGTAAAAGTCGTCTGCATGACCACTGAAGTTT TTCAGATTCAACATATGGTACACCGGGCCCGACCTCAACTTTGACCGAATAGCCCATCTCGCCAAGCTGGTTTTC AATACGAAGGGTGTCATCGTATCGCTCATCGATGGCAACGAGCAGTCAGTCTAGTTCCTGCGCATTTAGTTATCT CAGTTAGCTCACACGGTGCATTCTAGGTGGTTCAAATCAGAATGTGAATGTCTCTTCCTTTCTTGCGCGCTTGCT TGTTCTAATTTACTTACCCTTTTTTTCCCCCTTCCTATGGGGTTTCAATTTTAACTGGTGGCTCGATTTTGACAC AAGGGGGGCTCAAGTCACCAAGCTGTCCCAGGACACATTCACTGTGTGGCCATGCCATCCTTCAACAGTTGAGTA TGGTCTCCATCCTTTCGTCCCTCCCACGTGTGGACGTTCTCGAGTTGGATTGCACTCGGGTTTATCTTCCGAGGG TGCCACTCGCTCGAAACTTCGCGCTTGAGGCAAACGACTAACTTAATTGAGCAGAGGAGATGAGCCTATGATCGT TCTAGACACCCATCTCGATTGGAGATTTGCCAGGAATGTGAGTAGTAAAGAGTCTTTTTTTCCCTTCTCCGACCC GAGAATATTTCCCTATAGTTCTCTCTGTATTCTCAGCACGTTCCTAATGCATGCATTTCTAGCCATTGGTGATAA ATTCCCCACGTATTCGCTTCTATGCCGGAGCCCCCTTGCGCACCCAAGATGGCTACAACATTGGCACGTGCGTTA AAACGAGGTTCTTCAGAAGATGGTGACGGACTCAGATACGCCATTTCCCACTAGGCTTGCCCTCATCGACGACGT CTCTCGAGAAGACTTCTCCCCCCGTCAAAGACATACTCTCAAGGAATTCGCTGTAGGTATATTTGTCGCATGTTT CCCTGACAAGCACTGACATGCCATGGCAGGCAATTGCTATGCGGGAAATGGAACTTTGGCGAGACAAAGTCAGTG TTTCGTGAAATTCGAGTTCCAAGGCTAATTTGGCCTTTAGATTCAGTTGAGAATACGGGATCGAATACAAAGCTC TGTAAGTCTTGGTTGACTTGGAATGAAACAGAAACTCAATCCATTCTATCTAAATTTCGACAGATGGAGGAGTTC ACTCGAGAATGCTTAGAAATCGATTCCGAAGTACATCCCAAAGTCGACAAAGCTTCCATCGTGATCGGTACTTCC ATGGACCGTGTTTACGACCGCGCAGCGAAGCTTGTCCAGAGAACGCTTGACGTAGAGGGAGTGATTGTCATGGAT GTAACGCACTGCGAAGTTTTGGAGACTATGGGTGACGAAGGAAATGTGTCTGTGACCTTGCACCATGGCACTCCA GGGAGTGAAATGGAGAAGCGCCCGTTGTCGAGAGAAGATTACCAGAGCCTGAATAATTTCTTCGCAGCCTACCCA GAGGGCAAAATTTCTGAAGGAATTCTTCCTCCTTCTTTCAGGCCCTACATGCCCACTCATATCCGATATGCACTA CGTTTGTCCTCCTCGCCTTTCCATCGCCACGCAGCTGACCCTTTCTGGACAGTTGTACCGATATTCAATATAGAC AAGCGCCCATTTGCCCTGCTATGCGCATATAATACTAATCTTCATTCAAAACGATTTGTGAGTTCTCTTCCCTCT TTATCTCCTTTCATGCACTGACTTCTGCTTAGTTAGAAGGGCATGAGTTATCATACCTGCGAGCTATTGGCAAGA CCTTTTCCCGTTTCGTCAATCCATTTCGACTGATTTATTTCAGGTGTGATCATTCTGTCCGCTGTCCTCAAGAGA CGCATGATTCTAGCCGACAAAGCGAAGAGCCTATTCATTTCAAAGTGCGTTACTTCAGCAACAATGTTCACGATA TTGCTGACTGCAAAGTAGTATTTCTCACGAGCTACGAACACCCTTGCATGGGGTCAGTACTGCCGCTTTACTGTC CGAAACGCGTCCACTGACGACGCGCTGAGCAGATCCTTGCCGCTGCAGAGTTACTCAGTGACAGCCCCTTGAATC ACTCACAGATGTCCTTCATCCAGACCGTCCAAGCTTGTGGCACTTCTTTAGTTGAAACAGTCAATCATGTCCTAG ACTTCACAAAGCTCAGCGGCAACGTCAAAGCCGGCGGAGTGGAGAATGTCATCGTCCCCATCACGTCAGTGACTT CGTACGTTCCTGGAGGAGCTTTATTCACAATTCCAGTAGAAACGACATGATGCAACTCATAGAAGAGGCAATTGA CGGAAGTTGGATCGGCTATAAAGCCAGGACGGCCAATCTGGTGGATTCGGGCATCGGCAGTGTCTACTCACCTCC AAGTGACGAAACCACCGACCAGGGCCACCAACCGTCGCAACCACATGTCGAGACGGTTATAGACATTGGGTATCG AAGAGAGGTATGGCCGATGTGTTGCATGTTCCGTGCCATGTTATTAATGCTTTTGTCCACAGGGATGGCTGCTGA AGTACGAGAAGGGTGGAATTCGCCGTGTGCTGATGAATCTCTTCGGAAACAGCCTCAAATTCACCACGGATGGGT ATGTTCACGTCAGGCTGCGGTTACTCCCTCGCTTGCCAGACGACCCGCCAAACAAAGTGAGGTTAGAGCTTGCCA TCGAAGATACAGGGAAGGGTATCAGTCAGAACTTCCTCAAGGTGAGCTTGCTGATCTAGCGATCGGAATCGCACT ACTTACTGTCCACTCAGAATCAACTCTTTCACCCGTTCTCGCAGGAGAATCCTCTCCAAACAGGCACCGGCCTCG GATTGGCGATAGTTAACAGTATCGTGTCTTCCGAGAATGTCGGAGGAAAGGTGGACGTCCGAAGTGAAGAGGGTC AAGGAACCGAGATCAAGGTCTTCTTCCCTGCAGAAATCCCAGAGGACGACCCCAGGTTGGCTGATGCGGCACAAG ACATGGAACACTTCCGGGCGGACAAGAACAGCCCGTTACCCAAGATATCCATGCTAGGCTTCGAGTCTCAGCACA AAGGCATCCAACTCTTGTACAGAGTGCTTCGGACGTACATAACAGAGTGGTGGGGCCTTGACATAGTGGATGACT CTCAGGACAGTGACATCGTCGTCCTCAACGAGGACCTTGGGCCAATTCGTTCCGCCATCGAGCGCAACGACATAC GTCGCCCGTTCGTGATTTTATGGGTCACACGCGGGAACCCTACTGTTCTGGCAGCCGCCACAGAATACGAACGGA TAGGCGGATTCTGCCGCATCCTCTACAAGCCCACTGGCCCATCGAAACTACGGGGGGTCCTCAAACTCTGCATGC ACTCCATCAAGATCAATCGGTATTATCGCGACTCGGCACCCATGACAGCTGTACGGAAGAACACGGTATCGGGGT TTGCAGAGGACAAGGATGTATCGCATGGAGGGGTGTTGAGAAGGAACTCGGATGAAAACTCGACTTACGCCAGCA AGTCGCTTAGTCGACCCCCAATGTCCCCGCGGTCAGCGACCATTCATCCCTCCGTTTCCTCACTTCGGCATCAAC TGTTATTATCCGCGCTTCCGGAGAAGGATCGTGGACAGGAAGGGGAAGTTGGTTCACCTGTCTCTGATGGAACAG GTCTTCGTCCGATGGTTTCTATCGGCCCTGGGGGCTCAGTCCTGAAGTCATCCGTCCAGCCGACAGACATCCGAG GCCGGAAGCTCAGGGTTTTAGTCATCGAGGACAACAACATTCTGAGGAACCTCCTGTAAGTTCTACTCTAAATCA CAATGGTGGGACTCCTTGAGAGCTGACACGTATGTCTTTCTTCCAGGGCCAAATGGCTGATCAAGAAAGGGTATG ATTTCGAAGAAGCTGTGGATGGGCAGGCAGGCGTGACGGCGTTCCAGGAACATGGTCCATTCGAGTGCGTCGTCA CCGGTTTCTGCAGTGGGCACTGTTTCTGACGTTCTCGATTCATAGTGTTGCGTTGATTGACCTGTCAATGCCAGT CCTCGACGGTGCGTCCATATGCGTATCCTTTTTAACGGCGCGCTAATGACGCGGTATAGGCGTCGCGGCTACCAA AGAGATCCGTCGTATAGAGTCCAGTAAAGCAGGGGGAGACGACAGCTACCCCTCAGTCAAGATACTTGCCCTTAC TGGAATGTCTTCATTAGAAGATAAGCGGCGAGCGTTTGAAGCAGGAGTGGACGGATAGTGCGTTCGTTTCGTTAT TCTTAGTTCTGCTGCTGACGGTCTTGGAACTCATAGCCTTGTCAAACCGGTGGCCTTTAAGACCCTGGACGAGAT GTTCCACAAGCTCGGGATCTCTTCATAG |
| Length | 6103 |