CC1G_15684
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_15684 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RQE5 | Functional description | Other/IKS protein kinase |
| Location | Chr_11:695083..697876 | Strand | - |
| Gene length (nt) | 2794 | Transcript length (nt) | 2124 |
| CDS length (nt) | 2124 | Protein length (aa) | 707 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN1665_stk51 |
| Neurospora crassa | stk-51 |
| Saccharomyces cerevisiae | YJL057C_IKS1 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7268414 | 51.9 | 2.349E-245 | 769 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB27537 | 56.1 | 1.402E-243 | 764 |
| Schizophyllum commune H4-8 | Schco3_2623777 | 49.7 | 4.269E-218 | 690 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1397892 | 61.4 | 2.908E-211 | 670 |
| Pleurotus ostreatus PC9 | PleosPC9_1_89200 | 60.2 | 2.42E-211 | 670 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_74440 | 59.8 | 2.478E-209 | 664 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_45808 | 60 | 2.583E-209 | 664 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_117718 | 48.2 | 5.151E-202 | 643 |
| Flammulina velutipes | Flave_chr11AA00630 | 58.4 | 1.144E-201 | 642 |
| Lentinula edodes NBRC 111202 | Lenedo1_357896 | 52.8 | 9.308E-195 | 622 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_20059 | 52.8 | 9.237E-195 | 622 |
| Lentinula edodes B17 | Lened_B_1_1_6786 | 52.7 | 1.625E-194 | 621 |
| Auricularia subglabra | Aurde3_1_114808 | 44.7 | 5.27E-119 | 401 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1023335 | 61.1 | 5.171E-97 | 335 |
| Grifola frondosa | Grifr_OBZ78055 | 64.4 | 1.11E-74 | 268 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 13235 |
| Description | Other/IKS protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 156 | 259 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 358 | 552 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| J | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
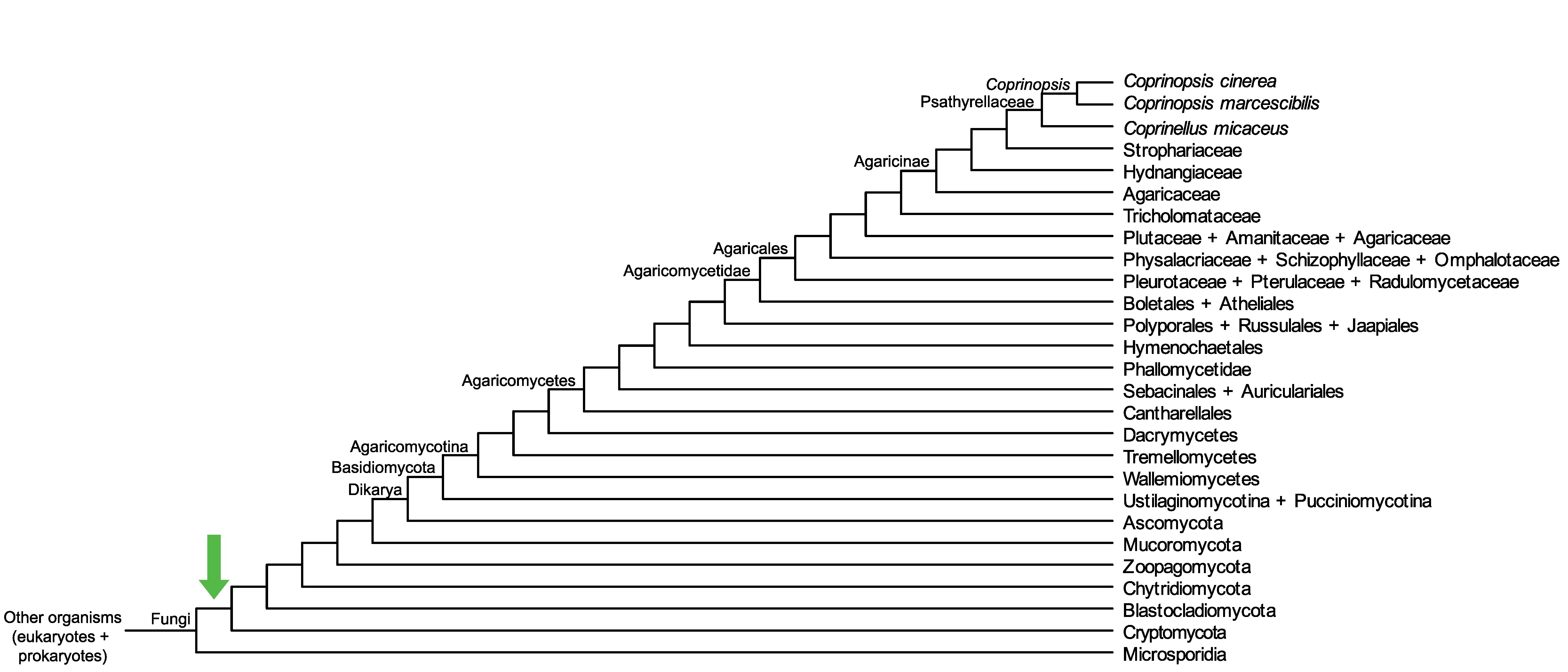
Conservation of CC1G_15684 across fungi.
Arrow shows the origin of gene family containing CC1G_15684.
Protein
| Sequence id | 13235 |
|---|---|
| Sequence |
>13235 MSNPSSPTRTTVALVSTTSESEWQPILHASNQVVLYNPHSHALTISRPANLAASSSSLIATRRPRPCPYCKQDLP PGFHAQPNDVDDEAEVLDSLHDDDPAYHSRVPNYFQLLAVSNETTSRPSSPPIGLTSEDPASRSTTFQAEQMAEG YFKRFFQEEYKLGMGANGSVYLCQHMLDGNPLGHFAVKKIAVGESHSYLLKILREVRLLERLHHPNIVTYHHSWL ETCQFSSFGPRIPTLHVLMQWAEGGSLDDFIDIRQGKKPSHPHIHPVPNHNASSRFDFDHNPSPLNLDESTPQIS PSTSTEPEVIHSRSARIRAFRAFQKASPEERERLVREGYGASEDRRNRRNKQWAPVHLLSADEVKSLFQDVVEGL GFLHSKSILHLDLKPGNVLLTWDDGKMIPRAMLSDFGTSRDMISSGRIPRSGNTGTLEYASPESLPSPETGLLQQ IDSKSDMWSLGMILHKMLFFKLPYRYASEGDANGEPTSLGQGQENEKMKRLEAEVLSYPGFKATSGLVTSFEARR LPKAFLVLLERLLDKSPAGRPSCDRVVTAVREGKAKLDPLSEVPRRRSGSNSPDALVPVNRKRPSTEATIEETQD ATVHPAVSSEDKRRLLGLPPPSEILGPDENEKKSFINRLRSNWNYGRLIVRRNPVWKAIGKAMRSRNGRIGLRIV RSCILVSKILSIPRVRRLSTMWLRSSPGTVGS |
| Length | 707 |
Coding
| Sequence id | CC1G_15684T0 |
|---|---|
| Sequence |
>CC1G_15684T0 ATGAGCAACCCTTCTTCACCGACTCGCACAACCGTGGCACTGGTATCGACGACTTCAGAGTCTGAATGGCAACCA ATTCTTCATGCTTCGAACCAGGTCGTTCTGTACAACCCCCACTCACATGCCCTCACGATCAGCCGCCCTGCGAAC CTTGCGGCCTCGTCGTCGTCACTGATAGCGACAAGGAGACCACGACCATGTCCTTACTGCAAGCAGGATCTTCCA CCGGGGTTCCACGCCCAACCGAACGACGTCGATGATGAGGCTGAGGTCTTGGATTCATTGCACGACGATGACCCT GCATACCACTCTAGGGTGCCAAACTACTTTCAGCTGCTGGCCGTATCGAATGAGACGACCTCTAGGCCCTCGAGC CCACCTATTGGACTTACCTCGGAAGATCCAGCCAGCCGCTCGACCACGTTCCAGGCTGAACAAATGGCAGAAGGC TACTTTAAGCGTTTCTTCCAGGAGGAATATAAGCTTGGGATGGGTGCTAATGGATCTGTATACCTGTGCCAGCAT ATGCTCGACGGGAACCCGCTTGGGCATTTCGCTGTAAAGAAGATTGCAGTAGGGGAATCGCATTCCTACCTACTC AAGATCCTCCGTGAAGTGAGGTTACTTGAACGGTTACACCATCCAAATATCGTCACATACCACCACTCGTGGCTA GAGACATGCCAGTTCTCTTCGTTTGGACCACGGATACCAACGCTCCACGTCCTCATGCAATGGGCCGAAGGGGGA AGTCTCGACGACTTCATTGACATCCGACAGGGAAAGAAGCCCTCCCATCCACATATCCACCCGGTCCCAAACCAC AACGCTTCGAGCCGCTTCGATTTCGACCACAACCCTTCGCCGCTCAACCTTGACGAGAGTACTCCTCAAATTTCG CCATCGACGTCCACAGAACCAGAGGTCATTCACAGTCGGTCGGCCCGAATAAGAGCTTTCAGGGCCTTCCAAAAG GCGTCACCCGAGGAAAGGGAACGCCTGGTACGCGAAGGATACGGTGCTTCGGAAGATAGGCGAAACCGGCGGAAT AAACAATGGGCTCCAGTTCACTTGCTCAGTGCGGACGAGGTGAAGAGTCTGTTCCAAGATGTTGTCGAGGGGCTG GGATTTCTGCATTCGAAATCCATCCTCCACCTGGATCTCAAACCTGGAAACGTTCTGTTAACCTGGGACGACGGC AAGATGATCCCTCGAGCCATGTTGTCAGACTTTGGCACCTCTCGCGACATGATCAGCTCTGGTCGGATCCCTCGG TCTGGAAATACGGGAACTCTAGAATACGCTTCTCCCGAGTCCCTACCCTCCCCAGAAACAGGCCTATTGCAGCAG ATCGACTCCAAGTCGGATATGTGGAGCTTGGGTATGATACTGCACAAGATGCTTTTCTTCAAGTTGCCCTATCGA TATGCATCAGAAGGCGATGCCAACGGTGAGCCCACTAGTCTGGGCCAAGGGCAGGAAAACGAGAAGATGAAGAGG TTGGAAGCGGAAGTTCTATCTTACCCTGGATTCAAGGCGACCTCTGGGCTCGTGACCAGTTTCGAAGCACGTCGG CTGCCCAAGGCGTTTTTGGTTCTCCTGGAACGTTTGCTCGACAAATCACCTGCTGGTCGCCCATCTTGTGATCGT GTGGTAACGGCCGTTCGTGAAGGAAAGGCGAAGCTCGACCCGTTGAGCGAAGTACCCAGACGACGTAGCGGTTCC AACAGCCCAGACGCCCTTGTACCCGTCAACCGCAAGCGACCGTCCACAGAGGCTACCATCGAGGAGACGCAGGAT GCGACTGTGCATCCTGCAGTATCTTCAGAGGACAAACGACGGCTGTTGGGTTTACCGCCTCCATCAGAAATTCTA GGCCCCGACGAAAACGAAAAGAAAAGTTTCATTAACCGCCTGCGATCAAACTGGAACTACGGGCGTCTAATCGTG AGACGCAATCCAGTGTGGAAGGCAATAGGAAAAGCAATGAGGAGCCGAAACGGACGAATTGGGCTGCGCATTGTC CGAAGCTGCATCTTGGTTTCAAAGATTTTGAGCATACCTCGCGTGCGGCGATTGTCGACAATGTGGTTGAGGTCG AGCCCTGGCACCGTGGGCTCC |
| Length | 2124 |
Transcript
| Sequence id | CC1G_15684T0 |
|---|---|
| Sequence |
>CC1G_15684T0 ATGAGCAACCCTTCTTCACCGACTCGCACAACCGTGGCACTGGTATCGACGACTTCAGAGTCTGAATGGCAACCA ATTCTTCATGCTTCGAACCAGGTCGTTCTGTACAACCCCCACTCACATGCCCTCACGATCAGCCGCCCTGCGAAC CTTGCGGCCTCGTCGTCGTCACTGATAGCGACAAGGAGACCACGACCATGTCCTTACTGCAAGCAGGATCTTCCA CCGGGGTTCCACGCCCAACCGAACGACGTCGATGATGAGGCTGAGGTCTTGGATTCATTGCACGACGATGACCCT GCATACCACTCTAGGGTGCCAAACTACTTTCAGCTGCTGGCCGTATCGAATGAGACGACCTCTAGGCCCTCGAGC CCACCTATTGGACTTACCTCGGAAGATCCAGCCAGCCGCTCGACCACGTTCCAGGCTGAACAAATGGCAGAAGGC TACTTTAAGCGTTTCTTCCAGGAGGAATATAAGCTTGGGATGGGTGCTAATGGATCTGTATACCTGTGCCAGCAT ATGCTCGACGGGAACCCGCTTGGGCATTTCGCTGTAAAGAAGATTGCAGTAGGGGAATCGCATTCCTACCTACTC AAGATCCTCCGTGAAGTGAGGTTACTTGAACGGTTACACCATCCAAATATCGTCACATACCACCACTCGTGGCTA GAGACATGCCAGTTCTCTTCGTTTGGACCACGGATACCAACGCTCCACGTCCTCATGCAATGGGCCGAAGGGGGA AGTCTCGACGACTTCATTGACATCCGACAGGGAAAGAAGCCCTCCCATCCACATATCCACCCGGTCCCAAACCAC AACGCTTCGAGCCGCTTCGATTTCGACCACAACCCTTCGCCGCTCAACCTTGACGAGAGTACTCCTCAAATTTCG CCATCGACGTCCACAGAACCAGAGGTCATTCACAGTCGGTCGGCCCGAATAAGAGCTTTCAGGGCCTTCCAAAAG GCGTCACCCGAGGAAAGGGAACGCCTGGTACGCGAAGGATACGGTGCTTCGGAAGATAGGCGAAACCGGCGGAAT AAACAATGGGCTCCAGTTCACTTGCTCAGTGCGGACGAGGTGAAGAGTCTGTTCCAAGATGTTGTCGAGGGGCTG GGATTTCTGCATTCGAAATCCATCCTCCACCTGGATCTCAAACCTGGAAACGTTCTGTTAACCTGGGACGACGGC AAGATGATCCCTCGAGCCATGTTGTCAGACTTTGGCACCTCTCGCGACATGATCAGCTCTGGTCGGATCCCTCGG TCTGGAAATACGGGAACTCTAGAATACGCTTCTCCCGAGTCCCTACCCTCCCCAGAAACAGGCCTATTGCAGCAG ATCGACTCCAAGTCGGATATGTGGAGCTTGGGTATGATACTGCACAAGATGCTTTTCTTCAAGTTGCCCTATCGA TATGCATCAGAAGGCGATGCCAACGGTGAGCCCACTAGTCTGGGCCAAGGGCAGGAAAACGAGAAGATGAAGAGG TTGGAAGCGGAAGTTCTATCTTACCCTGGATTCAAGGCGACCTCTGGGCTCGTGACCAGTTTCGAAGCACGTCGG CTGCCCAAGGCGTTTTTGGTTCTCCTGGAACGTTTGCTCGACAAATCACCTGCTGGTCGCCCATCTTGTGATCGT GTGGTAACGGCCGTTCGTGAAGGAAAGGCGAAGCTCGACCCGTTGAGCGAAGTACCCAGACGACGTAGCGGTTCC AACAGCCCAGACGCCCTTGTACCCGTCAACCGCAAGCGACCGTCCACAGAGGCTACCATCGAGGAGACGCAGGAT GCGACTGTGCATCCTGCAGTATCTTCAGAGGACAAACGACGGCTGTTGGGTTTACCGCCTCCATCAGAAATTCTA GGCCCCGACGAAAACGAAAAGAAAAGTTTCATTAACCGCCTGCGATCAAACTGGAACTACGGGCGTCTAATCGTG AGACGCAATCCAGTGTGGAAGGCAATAGGAAAAGCAATGAGGAGCCGAAACGGACGAATTGGGCTGCGCATTGTC CGAAGCTGCATCTTGGTTTCAAAGATTTTGAGCATACCTCGCGTGCGGCGATTGTCGACAATGTGGTTGAGGTCG AGCCCTGGCACCGTGGGCTCCTAA |
| Length | 2124 |
Gene
| Sequence id | CC1G_15684T0 |
|---|---|
| Sequence |
>CC1G_15684T0 ATGAGCAACCCTTCTTCACCGACTCGCACAACCGTGGCACTGGTATCGACGACTTCAGAGTCTGAATGGCAACCA ATTCTTCATGCTTCGAACCAGGTCGTTCTGTACAACCCCCACTCACATGCCCTCACGATCAGCCGCCCTGCGAAC CTTGCGGCCTCGTCGTCGTCACTGATAGCGACAAGGAGACCACGACCATGTCCTTACTGCAAGCAGGATCTTCCA CCGGGGTTCCACGCCCAACCGAACGACGTCGATGATGAGGCTGAGGTCTTGGATTCATTGCACGACGATGACCCT GCATACCACTCTAGGGTGCCAAACTACTTTCAGCTGCTGGCCGTATCGAATGAGACGACCTCTAGGCCCTCGAGC CCACCTATTGGACTTACCTCGGAAGATCCAGCCAGCCGCTCGACCACGTTCCAGGCTGAACAAATGGCAGAAGGC TACTTTAAGCGTTTCTTCCAGGAGGAATATAAGCTTGGGATGGGTGCTAATGGATCTGTATACCTGTGCCAGGTA AACCACACTTGAGGGGTGTCTAAACCATTGCTAACGAGCCCCGTAGCATATGCTCGACGGGAACCCGCTTGGGCA TTTCGCTGTAAAGAAGATTGCAGTAGGGGAATCGCATTCCTACCTACTCAAGATCCTCCGTGAAGTTTGTCCCAA TTGCCTGGACTAAGCTAGTGTTTAACCCTTTCCTTTAACAGGTGAGGTTACTTGAACGGTTACACCATCCAAATA TCGTCACATACCAGTCAGTATTGTTATTTCTTGTCACCGAAGCTTCGACTTAACTATCTCTCAGCCACTCGTGGC TAGAGACATGCCAGTTCTCTTCGTTTGGACCACGGATACCAACGCTCCAGTATGTAGCAAAGTCAATGTGCTTTC TCCTTCGTCTCATTGGTAATTTCCAGCGTCCTCATGCAATGGGCCGAAGGGGGAAGGTAAGACTTGTTCCATCTC AACTGCCCCATCCACTAACCCAGGATAGTCTCGACGACTTCATTGACATCCGACAGGGAAAGAAGCCCTCCCATC CACATATCCACCCGGTCCCAAACCACAACGCTTCGAGCCGCTTCGATTTCGACCACAACCCTTCGCCGCTCAACC TTGACGAGAGTACTCCTCAAATTTCGCCATCGACGTCCACAGAACCAGAGGTCATTCACAGTCGGTCGGCCCGAA TAAGAGCTTTCAGGGCCTTCCAAAAGGCGTCACCCGAGGAAAGGGAACGCCTGGTACGCGAAGGATACGGTGCTT CGGAAGATAGGCGAAACCGGCGGAATAAACAATGGGCTCCAGTTCACTTGCTCAGTGCGGACGAGGTGAAGAGTC TGTTCCAAGATGTTGTCGAGGGGCTGGGATTTCTGGTGGGTCCACTCCCGTTGGCGTTCGGGTAGACTGCTAAAC TTGAGTGATAGCATTCGAAATCCATCCTCCACCTGGATCTCAAACCTGGAAACGTTCTGTTAACCTGGGACGACG GCAAGATGATGTAGGTTTCATAGCACCAAACCATACTCCATGGCTAATATCCCTTGGTTCACTAGCCCTCGAGCC ATGTTGTCAGACTTTGGCACCTCTCGCGACATGATCAGCTCTGGTCGGATCCCTCGGTCTGGAAATACGGGAACG TAAGTAGCCACTTTCAAAGTAGGTTTGCGGATCTGACCTTGGATGATTCCATAGTCTAGAATACGCTTCTCCCGA GTCCCTACCCTCCCCAGAAACAGGCCTATTGCAGCAGATCGACTCCAAGTCGGATATGTGGAGCTTGGGTATGAT ACTGCACAAGATGCTTTTCTTCAAGTTGCCCTATCGGTGGGTACCTCCTTGTGCGCATACCACTACCTCACTTAT GGATGGCCTCTAGATATGCATCAGAAGGCGATGCCAACGGTGAGCCCACTAGTCTGGGCCAAGGGCAGGAAAACG AGAAGATGAAGAGGTTGGAAGCGGAAGTTCTATCTTACCCTGGGTATGCTAGGTGCCACTTACTTTCCGCTTTCT TCTCACCCTTCGCCAGATTCAAGGCGACCTCTGGGCTCGTGACCAGTTTCGAAGCACGTCGGCTGCCCAAGGCGT TTTTGGTTCTCCTGGAACGTTTGCTCGACAAATCACCTGCTGGTCGCCCATCTTGTGATCGTGTGGTAACGGCCG TTCGTGAAGGAAAGGTATCGTAACCTGTATCATTCAATTCAGTTCTCATCTGACCTAGGCGAAGCTCGACCCGTT GAGCGAAGTACCCAGACGACGTAGCGGTTCCAACAGCCCAGACGCCCTTGTACCCGTCAACCGCAAGCGACCGTC CACAGAGGCTACCATCGAGGAGACGCAGGATGCGACTGTGCATCCTGCAGTATCTTCAGAGGACAAACGACGGCT GTTGGGTTTACCGCCTCCATCAGAAATTCTAGGCCCCGACGAAAACGAAAAGAAAAGTTTCATTAACCGCCTGCG ATCAAACTGGAACTACGGGCGTCTAATCGTGAGACGCAATCCAGTGTGGAAGGCAATAGGAAAAGCAATGAGGAG CCGAAACGGACGAATTGGGCTGCGCATTGTCCGAAGCTGCATCTTGGTTTCAAAGGTGTGTTAGGAACCGTTACC CATCGTATTCAATGTTGTTGATCCGTTATTTCCCACCAGATTTTGAGCATACCTCGCGTATGCCCCGACCTGCAC ATGCACCCCCGTCAAGCCGTGCTAACGGTGCTGATAGGTGCGGCGATTGTCGACAATGTGGTTGAGGTCGAGCCC TGGCACCGTGGGCTCCTAA |
| Length | 2794 |