CopciAB_483540
Coprinopsis cinerea A43mutB43mut pab1-1 #326
General data
| Systematic name | CopciAB_483540 | Strain | Coprinopsis cinerea Okayama 7 |
|---|---|---|---|
| Standard name | - | Synonyms | 483540 |
| Uniprot id | Functional description | other FunK1 protein kinase | |
| Location | scaffold_8:2371094..2376044 | Strand | - |
| Gene length (nt) | 4951 | Transcript length (nt) | 3567 |
| CDS length (nt) | 3567 | Protein length (aa) | 1188 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| 0 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Carbon metabolism | Transcriptional changes along alternative morphogenetic paths of C. cinerea | Xie et al. 2020 | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Complex carbon sources 1 (long incubation) | Expression profiling on diverse complex carbon sources. | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Coprinopsis challenged with bacteria | Transcriptional response to Bacillus subtilis and Escherichia coli. | Kombrink et al. 2018 | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Early development 1 | Time series expression profiling of basidiospore and oidium germination | Hegedus et al. | QuantSeq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Early development 2 | Time series expression profiling of mycelial growth, light induction and fruiting body initiation. | Hegedus et al. | QuantSeq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fruiting body development | RNA-Seq analysis of fruiting body development | Krizsan et al. 2019 | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Nitrogen sources (12h incubation) | Expression profiling on diverse nitrogen sources. | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Plant biomass (12h incubation) | Expression profiling on diverse plant biomasses as carbon sources. | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Simple and complex carbon and nitrogen sources | Expression profiling on diverse complex carbon and nitrogen sources. | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Simple and complex carbon sources (12h incubation) | Expression profiling on diverse complex carbon sources. | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Starvation induced by water agar transfer | Expression profiling on starvation induced by transfer to water agar | Hegedus et al. | QuantSeq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Straw time series | Time series expression profiling on straw as a carbon source | Hegedus et al. | RNA-Seq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Stress conditions 1 | Expression profiling under various stress conditions | Hegedus et al. | QuantSeq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Stress conditions 2 | Expression profiling under various stress conditions | Hegedus et al. | QuantSeq | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | CopciAB_483540.T0 |
| Description | other FunK1 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 589 | 760 |
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 837 | 974 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR040976 | Fungal-type protein kinase |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | other FunK1 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
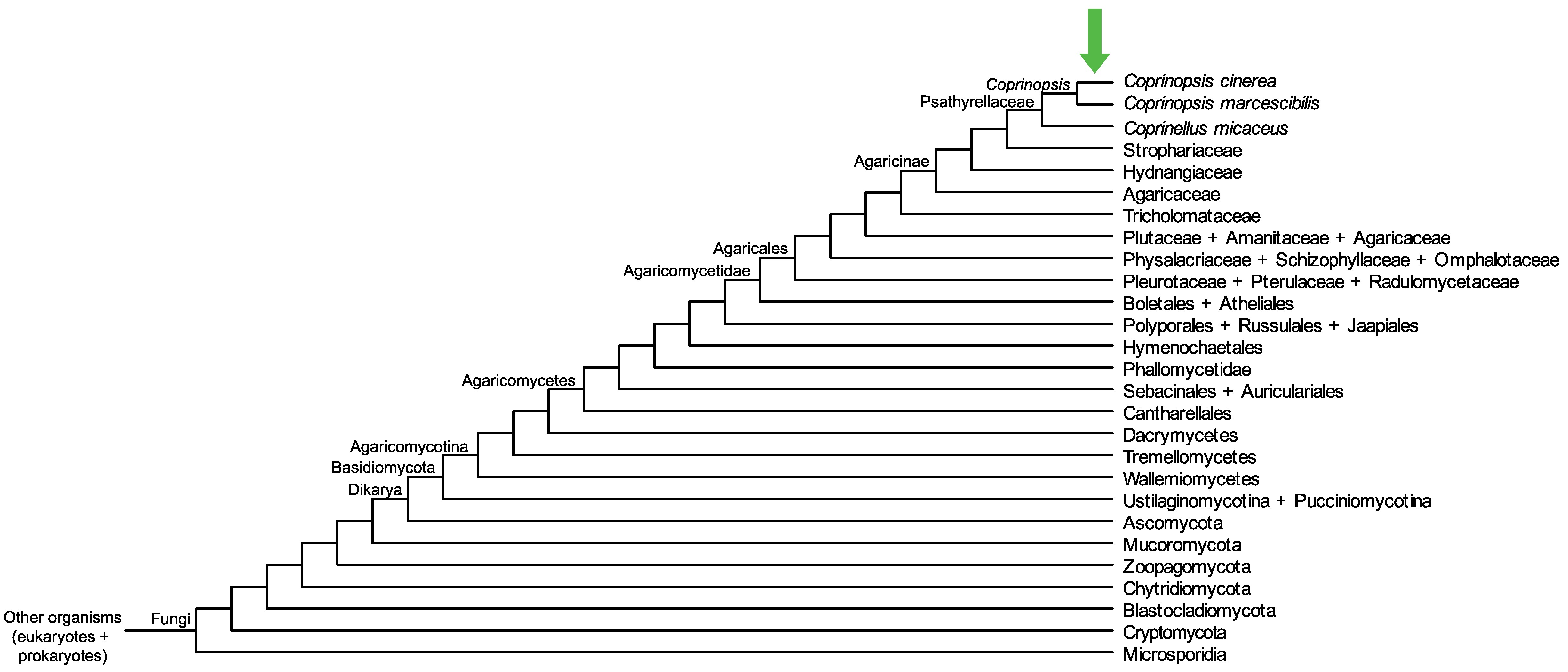
Conservation of CopciAB_483540 across fungi.
Arrow shows the origin of gene family containing CopciAB_483540.
Protein
| Sequence id | CopciAB_483540.T0 |
|---|---|
| Sequence |
>CopciAB_483540.T0 MNLAGGPPPNHPMDLYIQEQMSRVASASHELLILSKNPVYQALLQERDDLKRAIQEAHFEIEMRRIATLEEQLSS VASSSSAPASGPSSSISSPILLSHNHLEDTKPSIITPLAHGLTNEEFKKLPWLSEDSWQRYKKAHRGDPDFDRYM FLTDIHGNRVSEEYQKIINNTATRIWIDMFNDGTDPQSWDKDAGASTNDFFHSLMAQRHVEFTLSEVPWKAREFA IQKYPDFTQHKRIQLMKSGKRLRSDAPFPEPKPKKAKRSKGKAPAAAIGSEQPTDVNTNTNPPTPNADTGPNATA STSLSITPNVDAGTAATHNVGDGTAHPISAATSGSNTPNPDTNSNPAAGGSKPEADPSITIEHGTTPDDDVLAAY PAAGGSKPEADPSVTIEHGTTPDDDVLAALGEFDDLNDTPIPAAKDVIPLIPPPPVDPNAPWVPDPHSTTARGLF LVDYASKNPNAKLQDADKAWRKLDTDSKAVWTSESETKTKEKKERQKAEKAAASAASKPPPKSKKKGGKKARGRA AAAPSSSLEHADVLGARIDLFCDALGRATDCEITDYSLREEHNIRENAQGCLTSNLEDPLHPTEVVVPMTVIAED GNYTSSEEAKAKLLSRATEIMNEDARRRFCFGVTCPLSSSPTPFDMTEQPDLLLRLFVALFTAPPHQLGYDPLVT LLPDRNYVYHIPSDSSTTPLYFKTVHPIWDVKPTCLAGRRTRIWEVEQVLSPSDPTRVPGTPNRALKDVFLNSDT RTESDIQEELFADIAKFGRHKNWRSRPLLKDFAQTDLEGLAEALEGDLFKQYFSRIVAKQVGEGDVPALVIPTTP PPKRRFLFLYEHVCTALNNIPTLGEAVDILKSTLIPLRLMFCAGWVHRDVSPGNILAYRESPTSTWTVKLSDLEH AKRFPDPLSSGGDQTTGTPYFIAYEVLDGRHLFPTGIDLARIDPSQLAPPYPIVPVLHSYQHDLESIWWILLWLT TMRVNQNLPRRFGRLYFQHSVDQQYARARALLLMDTLSYKPDMKESLPPALRTSSFYNRLDMLRHNLYTVYLNRN KEGKFSDMDTYSWIISEGMRNFFDGVDGSRQQWGNIELMVDTQPRSLGVGAIGCGLVEAPSPSNQPTTDNVIKTR NRDELDEDNRVPKRMRPIRARETAMFTQRSGATTRSMTRNTGPMTRSMTRRLREAEQQGRSSR |
| Length | 1188 |
Coding
| Sequence id | CopciAB_483540.T0 |
|---|---|
| Sequence |
>CopciAB_483540.T0 ATGAACCTTGCTGGCGGCCCCCCACCTAACCATCCCATGGATCTCTATATCCAGGAGCAGATGTCTAGAGTGGCT AGCGCTAGCCACGAGCTCCTTATTTTATCGAAGAATCCTGTATATCAAGCACTCCTCCAGGAGCGTGACGACTTG AAGCGCGCCATTCAAGAGGCTCATTTCGAGATAGAGATGAGAAGAATTGCCACACTCGAGGAGCAACTCAGCAGT GTTGCCTCCTCGTCATCTGCCCCTGCATCAGGACCATCGTCGTCCATCTCGTCGCCCATCCTACTCTCCCACAAC CATCTTGAGGACACAAAACCCTCCATCATCACTCCCCTCGCCCACGGCCTAACCAATGAAGAGTTCAAGAAGCTT CCATGGTTATCCGAGGACTCCTGGCAGCGGTATAAGAAGGCACATCGCGGTGACCCTGACTTTGATCGCTATATG TTCCTAACTGACATTCACGGCAATCGCGTCTCGGAGGAGTACCAGAAAATCATCAATAATACGGCGACAAGAATT TGGATCGATATGTTTAATGACGGTACAGACCCCCAGTCCTGGGACAAGGATGCTGGTGCATCCACCAACGATTTT TTCCATTCATTGATGGCTCAGCGACATGTTGAGTTCACGTTGTCGGAGGTTCCGTGGAAGGCACGCGAGTTCGCT ATCCAAAAGTACCCCGACTTTACGCAGCATAAGCGGATCCAGTTGATGAAATCGGGGAAACGCCTGCGTTCTGAC GCCCCCTTCCCAGAGCCGAAACCGAAGAAGGCAAAAAGGTCCAAGGGAAAGGCTCCCGCAGCTGCGATTGGTTCC GAACAGCCCACCGACGTCAATACCAACACCAATCCACCTACCCCTAATGCCGACACTGGTCCAAACGCCACTGCT TCTACCAGCCTTTCCATCACTCCCAACGTCGATGCCGGAACTGCTGCTACCCACAATGTCGGTGATGGAACTGCT CATCCAATTTCCGCTGCCACAAGTGGTTCCAATACCCCCAACCCCGACACCAACAGCAATCCTGCTGCCGGTGGC TCGAAGCCCGAAGCGGACCCCTCCATCACCATTGAACATGGTACCACTCCCGACGACGATGTTCTGGCGGCATAT CCTGCTGCCGGTGGCTCGAAGCCCGAAGCGGACCCCTCCGTCACCATTGAACATGGTACCACTCCCGACGACGAT GTTCTGGCGGCATTGGGCGAGTTTGATGACCTGAATGATACACCTATCCCGGCGGCTAAAGACGTCATACCACTT ATTCCCCCTCCCCCCGTTGATCCCAACGCACCCTGGGTCCCCGATCCTCATTCTACCACTGCAAGGGGACTTTTC CTTGTCGATTATGCAAGCAAGAACCCAAACGCGAAGCTCCAAGATGCCGATAAAGCCTGGCGCAAACTAGACACT GATAGTAAAGCGGTTTGGACATCGGAAAGCGAGACGAAGACCAAGGAGAAGAAGGAACGTCAAAAGGCCGAGAAG GCGGCTGCCTCTGCTGCATCAAAACCTCCTCCCAAGTCGAAAAAGAAGGGTGGCAAGAAGGCGCGAGGAAGAGCC GCCGCTGCCCCCTCGTCGTCCCTTGAGCACGCTGACGTTCTTGGAGCCAGAATCGACCTTTTCTGTGATGCCCTC GGGAGGGCCACAGACTGCGAGATCACCGACTACTCCCTCAGAGAAGAGCATAACATCCGAGAGAATGCTCAAGGA TGCCTAACCTCGAACCTGGAGGACCCATTACACCCCACCGAAGTTGTGGTTCCGATGACAGTCATCGCAGAGGAT GGTAATTATACATCATCTGAAGAGGCAAAGGCAAAACTACTGTCCCGTGCCACTGAAATCATGAATGAAGACGCT CGTCGAAGGTTTTGTTTCGGGGTCACTTGTCCATTGTCGTCAAGTCCCACGCCTTTTGACATGACCGAGCAACCA GACCTCTTGCTTCGCCTGTTCGTCGCTCTGTTCACAGCCCCGCCACACCAGCTAGGATACGACCCTCTGGTTACC CTGCTCCCCGATCGCAACTACGTCTATCATATTCCATCTGATAGTTCTACAACCCCGCTCTACTTTAAAACGGTC CATCCGATCTGGGACGTCAAACCGACCTGCCTTGCTGGACGCCGCACGCGTATTTGGGAAGTCGAGCAGGTCCTC TCACCGTCTGATCCGACTCGAGTTCCGGGCACACCTAACCGGGCTTTGAAGGACGTCTTCCTGAATTCGGACACG AGGACCGAATCCGACATCCAGGAAGAACTGTTCGCTGATATCGCGAAGTTTGGCCGGCACAAGAACTGGCGTTCT CGACCTCTGCTGAAGGATTTCGCCCAAACCGACCTGGAAGGGCTGGCGGAGGCATTGGAAGGGGACCTATTTAAG CAATACTTTTCGCGCATAGTCGCGAAGCAGGTCGGGGAAGGCGATGTGCCTGCCCTGGTCATTCCAACCACGCCT CCGCCGAAGCGCCGTTTTCTCTTCCTGTACGAGCATGTTTGCACGGCACTGAACAACATCCCTACACTTGGTGAA GCGGTCGACATCCTCAAATCGACTCTCATCCCTTTGCGTCTGATGTTCTGCGCGGGCTGGGTTCATCGAGACGTC AGTCCGGGCAATATCCTAGCGTATCGAGAATCGCCTACCTCAACATGGACAGTCAAATTATCGGACCTCGAGCAT GCGAAACGGTTCCCTGACCCTTTATCCAGTGGAGGTGATCAAACCACGGGAACCCCTTATTTTATCGCGTACGAA GTCCTTGACGGACGACACCTCTTCCCCACGGGGATTGACCTTGCTCGCATTGACCCCAGCCAACTAGCCCCCCCT TATCCCATCGTACCTGTCCTTCACAGCTACCAGCACGACTTGGAGTCGATCTGGTGGATACTTCTCTGGCTTACG ACCATGCGGGTCAATCAAAACCTGCCGAGACGGTTCGGGCGACTGTACTTCCAGCACAGCGTCGATCAGCAGTAC GCCCGAGCGAGGGCCCTTCTACTCATGGACACGCTCTCATACAAGCCCGACATGAAGGAATCCCTCCCTCCAGCC TTACGAACTTCGTCGTTCTACAATCGCCTGGACATGCTACGCCACAACCTCTACACTGTATACCTAAACCGCAAC AAGGAGGGGAAATTCAGTGACATGGATACTTACTCGTGGATCATCAGTGAGGGAATGCGCAACTTCTTCGATGGT GTCGACGGCTCTAGGCAACAGTGGGGTAATATTGAGCTTATGGTCGACACTCAGCCACGAAGCTTGGGCGTCGGA GCCATCGGCTGCGGCCTCGTAGAAGCGCCCTCGCCCTCCAACCAACCAACCACGGACAATGTGATAAAGACGCGT AACCGTGATGAGTTGGATGAAGACAACCGAGTGCCCAAGAGAATGAGGCCTATTCGAGCGCGGGAGACAGCCATG TTCACGCAGAGGAGTGGAGCGACGACAAGATCGATGACAAGGAATACTGGGCCAATGACGAGATCTATGACCAGA CGTCTTCGTGAGGCTGAGCAACAGGGACGAAGTAGCCGATAG |
| Length | 3567 |
Transcript
| Sequence id | CopciAB_483540.T0 |
|---|---|
| Sequence |
>CopciAB_483540.T0 ATGAACCTTGCTGGCGGCCCCCCACCTAACCATCCCATGGATCTCTATATCCAGGAGCAGATGTCTAGAGTGGCT AGCGCTAGCCACGAGCTCCTTATTTTATCGAAGAATCCTGTATATCAAGCACTCCTCCAGGAGCGTGACGACTTG AAGCGCGCCATTCAAGAGGCTCATTTCGAGATAGAGATGAGAAGAATTGCCACACTCGAGGAGCAACTCAGCAGT GTTGCCTCCTCGTCATCTGCCCCTGCATCAGGACCATCGTCGTCCATCTCGTCGCCCATCCTACTCTCCCACAAC CATCTTGAGGACACAAAACCCTCCATCATCACTCCCCTCGCCCACGGCCTAACCAATGAAGAGTTCAAGAAGCTT CCATGGTTATCCGAGGACTCCTGGCAGCGGTATAAGAAGGCACATCGCGGTGACCCTGACTTTGATCGCTATATG TTCCTAACTGACATTCACGGCAATCGCGTCTCGGAGGAGTACCAGAAAATCATCAATAATACGGCGACAAGAATT TGGATCGATATGTTTAATGACGGTACAGACCCCCAGTCCTGGGACAAGGATGCTGGTGCATCCACCAACGATTTT TTCCATTCATTGATGGCTCAGCGACATGTTGAGTTCACGTTGTCGGAGGTTCCGTGGAAGGCACGCGAGTTCGCT ATCCAAAAGTACCCCGACTTTACGCAGCATAAGCGGATCCAGTTGATGAAATCGGGGAAACGCCTGCGTTCTGAC GCCCCCTTCCCAGAGCCGAAACCGAAGAAGGCAAAAAGGTCCAAGGGAAAGGCTCCCGCAGCTGCGATTGGTTCC GAACAGCCCACCGACGTCAATACCAACACCAATCCACCTACCCCTAATGCCGACACTGGTCCAAACGCCACTGCT TCTACCAGCCTTTCCATCACTCCCAACGTCGATGCCGGAACTGCTGCTACCCACAATGTCGGTGATGGAACTGCT CATCCAATTTCCGCTGCCACAAGTGGTTCCAATACCCCCAACCCCGACACCAACAGCAATCCTGCTGCCGGTGGC TCGAAGCCCGAAGCGGACCCCTCCATCACCATTGAACATGGTACCACTCCCGACGACGATGTTCTGGCGGCATAT CCTGCTGCCGGTGGCTCGAAGCCCGAAGCGGACCCCTCCGTCACCATTGAACATGGTACCACTCCCGACGACGAT GTTCTGGCGGCATTGGGCGAGTTTGATGACCTGAATGATACACCTATCCCGGCGGCTAAAGACGTCATACCACTT ATTCCCCCTCCCCCCGTTGATCCCAACGCACCCTGGGTCCCCGATCCTCATTCTACCACTGCAAGGGGACTTTTC CTTGTCGATTATGCAAGCAAGAACCCAAACGCGAAGCTCCAAGATGCCGATAAAGCCTGGCGCAAACTAGACACT GATAGTAAAGCGGTTTGGACATCGGAAAGCGAGACGAAGACCAAGGAGAAGAAGGAACGTCAAAAGGCCGAGAAG GCGGCTGCCTCTGCTGCATCAAAACCTCCTCCCAAGTCGAAAAAGAAGGGTGGCAAGAAGGCGCGAGGAAGAGCC GCCGCTGCCCCCTCGTCGTCCCTTGAGCACGCTGACGTTCTTGGAGCCAGAATCGACCTTTTCTGTGATGCCCTC GGGAGGGCCACAGACTGCGAGATCACCGACTACTCCCTCAGAGAAGAGCATAACATCCGAGAGAATGCTCAAGGA TGCCTAACCTCGAACCTGGAGGACCCATTACACCCCACCGAAGTTGTGGTTCCGATGACAGTCATCGCAGAGGAT GGTAATTATACATCATCTGAAGAGGCAAAGGCAAAACTACTGTCCCGTGCCACTGAAATCATGAATGAAGACGCT CGTCGAAGGTTTTGTTTCGGGGTCACTTGTCCATTGTCGTCAAGTCCCACGCCTTTTGACATGACCGAGCAACCA GACCTCTTGCTTCGCCTGTTCGTCGCTCTGTTCACAGCCCCGCCACACCAGCTAGGATACGACCCTCTGGTTACC CTGCTCCCCGATCGCAACTACGTCTATCATATTCCATCTGATAGTTCTACAACCCCGCTCTACTTTAAAACGGTC CATCCGATCTGGGACGTCAAACCGACCTGCCTTGCTGGACGCCGCACGCGTATTTGGGAAGTCGAGCAGGTCCTC TCACCGTCTGATCCGACTCGAGTTCCGGGCACACCTAACCGGGCTTTGAAGGACGTCTTCCTGAATTCGGACACG AGGACCGAATCCGACATCCAGGAAGAACTGTTCGCTGATATCGCGAAGTTTGGCCGGCACAAGAACTGGCGTTCT CGACCTCTGCTGAAGGATTTCGCCCAAACCGACCTGGAAGGGCTGGCGGAGGCATTGGAAGGGGACCTATTTAAG CAATACTTTTCGCGCATAGTCGCGAAGCAGGTCGGGGAAGGCGATGTGCCTGCCCTGGTCATTCCAACCACGCCT CCGCCGAAGCGCCGTTTTCTCTTCCTGTACGAGCATGTTTGCACGGCACTGAACAACATCCCTACACTTGGTGAA GCGGTCGACATCCTCAAATCGACTCTCATCCCTTTGCGTCTGATGTTCTGCGCGGGCTGGGTTCATCGAGACGTC AGTCCGGGCAATATCCTAGCGTATCGAGAATCGCCTACCTCAACATGGACAGTCAAATTATCGGACCTCGAGCAT GCGAAACGGTTCCCTGACCCTTTATCCAGTGGAGGTGATCAAACCACGGGAACCCCTTATTTTATCGCGTACGAA GTCCTTGACGGACGACACCTCTTCCCCACGGGGATTGACCTTGCTCGCATTGACCCCAGCCAACTAGCCCCCCCT TATCCCATCGTACCTGTCCTTCACAGCTACCAGCACGACTTGGAGTCGATCTGGTGGATACTTCTCTGGCTTACG ACCATGCGGGTCAATCAAAACCTGCCGAGACGGTTCGGGCGACTGTACTTCCAGCACAGCGTCGATCAGCAGTAC GCCCGAGCGAGGGCCCTTCTACTCATGGACACGCTCTCATACAAGCCCGACATGAAGGAATCCCTCCCTCCAGCC TTACGAACTTCGTCGTTCTACAATCGCCTGGACATGCTACGCCACAACCTCTACACTGTATACCTAAACCGCAAC AAGGAGGGGAAATTCAGTGACATGGATACTTACTCGTGGATCATCAGTGAGGGAATGCGCAACTTCTTCGATGGT GTCGACGGCTCTAGGCAACAGTGGGGTAATATTGAGCTTATGGTCGACACTCAGCCACGAAGCTTGGGCGTCGGA GCCATCGGCTGCGGCCTCGTAGAAGCGCCCTCGCCCTCCAACCAACCAACCACGGACAATGTGATAAAGACGCGT AACCGTGATGAGTTGGATGAAGACAACCGAGTGCCCAAGAGAATGAGGCCTATTCGAGCGCGGGAGACAGCCATG TTCACGCAGAGGAGTGGAGCGACGACAAGATCGATGACAAGGAATACTGGGCCAATGACGAGATCTATGACCAGA CGTCTTCGTGAGGCTGAGCAACAGGGACGAAGTAGCCGATAG |
| Length | 3567 |
Gene
| Sequence id | CopciAB_483540.T0 |
|---|---|
| Sequence |
>CopciAB_483540.T0 ATGAACCTTGCTGGCGGCCCCCCACCTAACCATCCCATGGTACGTCAATCACCCTCATGATACATTTTCTCTCAT CAATAACTGACGCACAATAGGATCTCTATATCCAGGAGCAGATGTCTAGAGTGGCTAGCGCTAGCCACGAGCTCC TTATTTTATCGAAGAATCCTGTATATCAAGCACTCCTCCAGGAGCGTGACGACTTGAAGCGCGCCATTCAAGAGG CTCATTTCGAGATAGAGATGAGAAGGTTGGTCCCTCAGTTGGCATGGTACCTCCTATGCTTATGTTCCGCAGCAA TAGAATTGCCACACTCGAGGAGCAACTCAGCAGTGTTGCCTCCTCGTCATCTGCCCCTGCATCAGGACCATCGTC GTCCATCTCGTCGCCCATCCTACTCTCCCACAACCATCTTGAGGACACAAAACCCTCCATCATCACTCCCCTCGC CCACGGCCTAACCAATGAAGAGTTCAAGAAGCTTCCATGGTTATCCGAGGACTCCTGGCAGCGGTATAAGAAGGC ACATCGCGGTGACCCTGACTTTGATCGCTATATGTTCCTAACTGACATTCACGGCAATCGCGTCTCGGAGGAGTA CCAGAAAATCATCAATAATACGGCGACAAGAATTTGGATCGATATGTTTAATGACGGTACAGACCCCCAGTCCTG GGACAAGGATGCTGGTGCATCCACCAACGATTTTTTCCATTCATTGATGGCTCAGCGACATGTTGAGTTCACGTT GTCGGAGGTTCCGTGGAAGGCACGCGAGTTCGCTATCCAAAAGTACCCCGACTTTACGCAGCATAAGCGGATCCA GTTGATGAAATCGGGGAAACGTAAGTATTCATTTCCTTTTCTGAATTCCTCGTTTTGGTGTAACTGACTATCTTC CTCTCTAGGCCTGCGTTCTGACGCCCCCTTCCCAGAGCCGAAACCGAAGAAGGCAAAAAGGTCCAAGGGAAAGGC TCCCGCAGGTGCGTACTCACTCTGTTATGAGTTTCCATGAACACCGAGACCTGAGACTACGTTGCTGTAGCTGCG ATTGGTTCCGAACAGCCCACCGACGTCAATACCAACACCAATCCACCTACCCCTAATGCCGACACTGGTCCAAAC GCCACTGCTTCTACCAGCCTTTCCATCACTCCCAACGTCGATGCCGGAACTGCTGCTACCCACAATGTCGGTGAT GGAACTGCTCATCCAATTTCCGCTGCCACAAGTGGTTCCAATACCCCCAACCCCGACACCAACAGCAATCCTGCT GCCGGTGGCTCGAAGCCCGAAGCGGACCCCTCCATCACCATTGAACATGGTACCACTCCCGACGACGATGTTCTG GCGGCATATCCTGCTGCCGGTGGCTCGAAGCCCGAAGCGGACCCCTCCGTCACCATTGAACATGGTACCACTCCC GACGACGATGTTCTGGCGGCATTGGGCGAGGTAAGGGATCTAGTGAATTGCTGCTGTCGGTAACCGTGACTAATC CATTGCTCTGGGCCACAGTTTGATGACCTGTATGTCCTTTCTTATCTCGCTGATTACGCCACCCATGCTAAAGGG TCTTCAGGAATGATACACCTATCCCGGCGGCTAAAGACGTCATACCACTTATTCCCCCTCCCCCCGTTGATCCCA ACGCACCCTGGGTCCCCGATCCTCATTCTACCACTGCAAGGTATGTTCGCACGTCTAGCTTTCAATGTGGGTGTT GCTAACTATCTTGTATTCATATCCTCTAGGGGACTTTTCCTTGTCGATTATGCAAGCAAGAACCCAAACGCGAAG CTCCAAGATGCCGATAAAGCCTGGCGCAAACTAGACACTGATAGTAAAGCGGTATGCTGTTTCTAGTTCCATTGA GGTGGTATTCTCATCCCTTTGGGTCTTCTCAACAGGTTTGGACATCGGAAAGCGAGACGAAGACCAAGGAGAAGA AGGAACGTCAAAAGGCCGAGAAGGCGGCTGCCTCTGCTGCATCAAAACCTCCTCCCAAGTCGAAAAAGAAGGGTG GCAAGAAGGCGCGAGGAAGAGCCGCCGCTGCCCCCTCGTCGTCCCTTGGTATGTTTTCTGGAATCCACCCTCGAC TTAGCGCTATTTCTGACTTGCAGATTTTAGGTGGAGGGGTGGCTGCCTCCTGAACAGCTCGGACGATTTCTGAAT GCGCGTACCTGGTCATAATATGTGGTCTGTCTGATGGTTTCTGAAGTAGTCTGAATGTATCGTAAATAGCTCTTC TGAAATTATCACACCATGTCAGACCAATTCTGAAGTGATTCTGAACTGTTCTCGGATAGTTTCTGACGATATCTG ATTTAATTCTGAGAGAATCTTAAGTTTTCCGACGAGACGGCGCGAAGTGGTCAGACAATATCTGATTCTTTCTGA ACACTTCTGCTCCATACTCTGACTCGTTCTGAAGCTCATCTGAAAATGGACGTATTTTCTGATTCTGCCTGAATC CATCGGTATTTTGAGAATCCTGATGTTTTCTGATTATCTCAGGCGCATTCCGTCAACGTCTGACAAATTCTTTAT GGGTTTTAACTGGGATTGAGCTCGCGCCCGTCGGCGTGACTTAGCGTGATCTAACATTGCTCAGGCCAGAGCACG CTGACGTTCTTGGGTCAGTCCATGGCGGGCAAGAGCTAACCCTAATGTGGGCTGCCTGGCCAGAGCCAGAATCGA CCTTTTCTGTGATGCCCTCGGGAGGGCCACAGACTGCGAGATCACCGACTACTCCCTCAGAGAAGAGCATAACAT CCGAGAGAATGCTCAAGGATGCCTAACCTCGAACCTGGAGGACCCATTACACCCCACCGAAGTTGTGGTTCCGAT GACAGTCATCGCAGAGGATGGTAATTATACATCATCTGAAGAGGTGCGTGTTTTCGCTGTCCTTGCTTGGGACTA CTTATTAGAAACTGACATCCATTAGGCAAAGGCAAAACTACTGTCCCGTGCCACTGAAATCATGAATGAAGACGC TCGTCGAAGGTTTTGTTTCGGGGTATGTAGCTTCTCCTCGAAATTAAGATCCATCGACTGATTCAGTTCCAGGTC ACTTGTGAACGGTCTGAAGTCACTCTGTGGCGCTTTTCCAGGTCCATTGTCGTCAAGTCCCACGCCTTTTGACAT GACCGAGGTGCGCTTCCCATTTTGCGCGCGTTTTCGAGATTTGGACTGATATACCTCGCACTTCAGCAACCAGAC CTCTTGCTTCGCCTGTTCGTCGCTCTGTTCACAGCCCCGCCACACCAGCTAGGATACGACCCTCTGGTTACCCTG CTCCCCGATCGCAACTACGTCTATCATATTCCATCTGATAGTTCTACAACCCCGCTCTACTTTAAAACGGTCCAT CCGATCTGGGACGTCAAACCGACCTGCCTTGCTGGACGCCGCACGCGTATTTGGGAAGTCGAGCAGGTCCTCTCA CCGTCTGATCCGACTCGAGTTCCGGGCACACCTAACCGGGCTTTGAAGGACGTCTTCCTGAATTCGGACACGAGG ACCGAATCCGACATCCAGGAAGAACTGTTCGCTGATATCGCGAAGTTTGGCCGGCACAAGAACTGGCGTTCTCGA CCTCTGCTGAAGGATTTCGCCCAAACCGACCTGGAAGGGCTGGCGGAGGCATTGGAAGGGGACCTATTTAAGCAA TACTTTTCGCGCATAGTCGCGAAGCAGGTCGGGGAAGGCGATGTGCCTGCCCTGGTCATTCCAACCACGCCTCCG CCGAAGCGCCGTTTTCTCTTCCTGTACGAGCATGTTTGCACGGCACTGAACAACATCCCTACACTTGGTGAAGCG GTCGACATCCTCAAATCGACTCTCATCCGTACGCCATCTGTTGTTCATCTTCCCCTTACCCGTGGTCCTAATGCC ATTTCCTTAGCTTTGCGTCTGATGTTCTGCGCGGGCTGGGTTCATCGAGACGTCAGTCCGGGCAATATCCTAGCG TATCGAGAATCGCCTACCTCAACATGGACAGTCAAATTATCGGACCTCGAGCATGCGAAACGGTTCCCTGACCCT TTATCCAGTGGAGGTGATCAAACCACGGTAAGCCACCATTTTCAGCGTCGTCGAACTCATGACTGATTTTTGATG ATCTCAGGGAACCCCTTATTTTATCGCGTACGAAGTCCTTGACGGACGACACCTCTTCCCCACGGGGATTGACCT TGCTCGCATTGACCCCAGCCAACTAGCCCCCCCTTATCCCATCGTACCTGTCCTTCACAGCTACCAGCACGACTT GGAGTCGATCTGGTGGATACTTCTCTGGCTTACGACCATGCGGGTCAATCAAAACCTGCCGAGACGGTTCGGGCG ACTGTACTTCCAGCACAGCGTCGATCAGCAGTACGCCCGAGCGAGGGCCCTTCTACTCATGGACACGCTCTCATA CAAGCCCGACATGAAGGAATCCCTCCCTCCAGCCTTACGAACTTCGTCGTTCTACAATCGCCTGGACATGCTACG CCACAACCTCTACACTGTATACCTAAACCGCAACAAGGAGGGGAAATTCAGTGACATGGATACTTACTCGTGGAT CATCAGTGAGGGAATGCGCAACTTCTTCGATGGTGTCGACGGCTCTAGGCAACAGTGGGGTAATATTGAGCTTAT GGTCGACACTCAGCCACGAAGCTTGGGCGTCGGAGCCATCGGCTGCGGCCTCGTAGAAGCGCCCTCGCCCTCCAA CCAACCAACCACGGACAATGTGATAAAGACGCGTAACCGTGATGAGTTGGATGAAGACAACCGAGTGCCCAAGAG AATGAGGCCTATTCGAGCGCGGGAGACAGCCATGTTCACGCAGAGGAGTGGAGCGACGACAAGATCGATGACAAG GAATACTGGGCCAATGACGAGATCTATGACCAGACGTCTTCGTGAGGCTGAGCAACAGGGACGAAGTAGCCGATA G |
| Length | 4951 |