CC1G_00304
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_00304 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NXH3 | Functional description | STE/STE20/YSK protein kinase |
| Location | Chr_5:1560456..1562721 | Strand | + |
| Gene length (nt) | 2266 | Transcript length (nt) | 1974 |
| CDS length (nt) | 1974 | Protein length (aa) | 657 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7259762 | 76.1 | 0 | 1039 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1453572 | 73.8 | 0 | 1007 |
| Pleurotus ostreatus PC9 | PleosPC9_1_49007 | 73.9 | 0 | 1004 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB22823 | 72.4 | 0 | 1001 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1092749 | 73.9 | 4.941E-304 | 991 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_219768 | 73.2 | 1.481E-304 | 981 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_73338 | 72.6 | 8.295E-304 | 976 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_14262 | 73.8 | 6.263E-304 | 968 |
| Lentinula edodes NBRC 111202 | Lenedo1_1034727 | 73.8 | 1.4E-304 | 967 |
| Lentinula edodes B17 | Lened_B_1_1_10206 | 73.9 | 1.717E-304 | 952 |
| Schizophyllum commune H4-8 | Schco3_2621466 | 72.5 | 8.459E-304 | 936 |
| Flammulina velutipes | Flave_chr11AA00599 | 69.5 | 9.754E-301 | 924 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_41754 | 66.1 | 2.749E-288 | 888 |
| Grifola frondosa | Grifr_OBZ76590 | 65.9 | 9.165E-274 | 846 |
| Auricularia subglabra | Aurde3_1_1272538 | 61.3 | 3.909E-272 | 842 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 252 |
| Description | STE/STE20/YSK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd06609 | STKc_MST3_like | - | 36 | 306 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 38 | 286 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K08286 |
| K08838 |
| K21618 |
EggNOG
| COG category | Description |
|---|---|
| T | Serine/Threonine protein kinases, catalytic domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
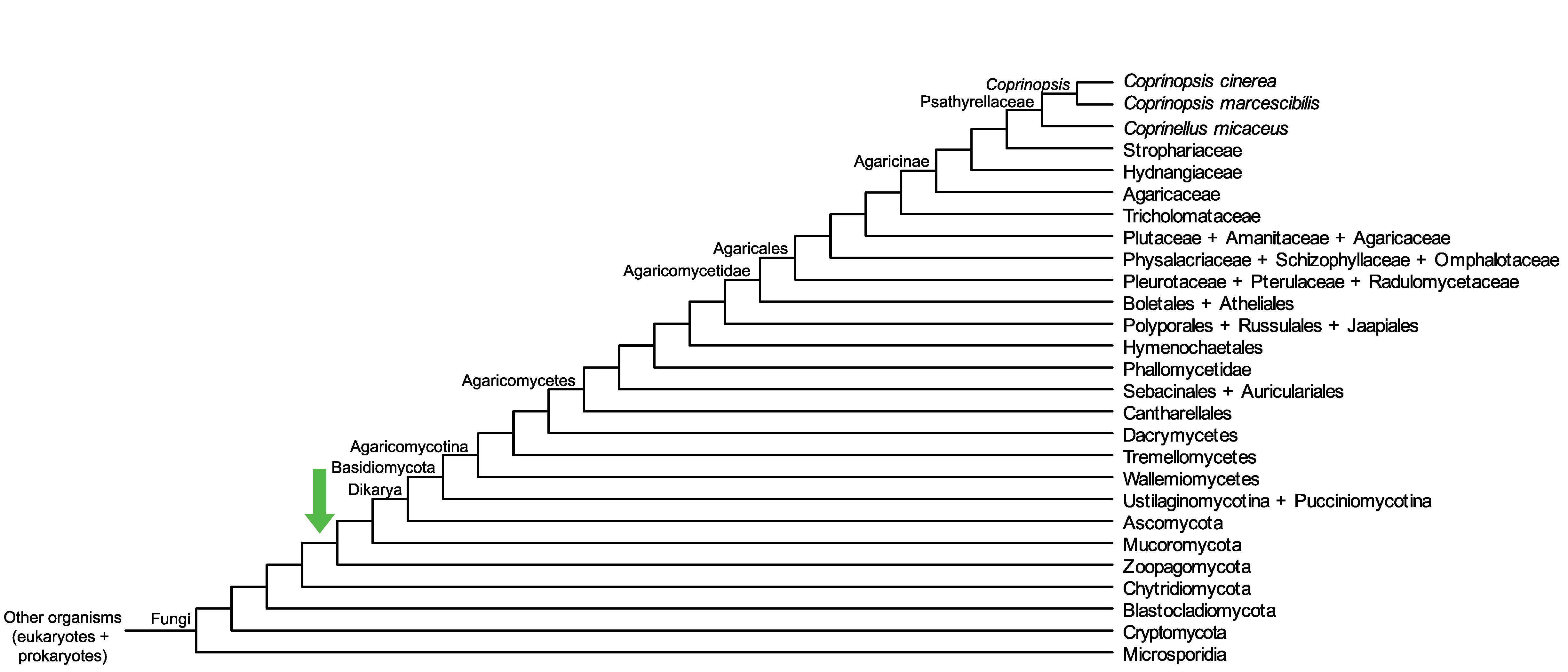
Conservation of CC1G_00304 across fungi.
Arrow shows the origin of gene family containing CC1G_00304.
Protein
| Sequence id | 252 |
|---|---|
| Sequence |
>252 MTLTWSSTRSPPPSPKVEQRTRPRDPCPIPSSNPASQYTLLEKLGTGSFGVVYKAIHNETKQIVAIKQIDLEDSD DDISEIQQEIASLAQCDSEYVTKYYGSFVVHYKLWIVMEYLAGGSCLDLLKAGPFSEAHIAVICRELLLGLDYLH AEGTIHRDIKAANVLLSSSGKVKLADFGVAAQLTNTLRHTFVGTPFWMAPEVIRQAGYDSKADMWSLGITAIEMA KGEPPLAEYHPMRVLFLIPKAKPPTLEGPFSAAFKDFVTLCLTKDPKLRPSANELLQHRFIRGAKKTSYLTELIE RYQEWRMRSPHKGQNNAATIRNTATWDMNDTIRSDWNFDTVKSMGAMGTFRGSVKDLGMPTGMILEADESDDGET SIDTGAATKGSDPLLSNSQAAHSTVMIKNPPPHLAESDDIADDDIPNGAPPAYSGSVRSARRASYAERSSTDGPG TVLNEADLGTGVDTIRPVKKVDAAGSLRLSTGYLGSIRKEGSGSSYSTHKRSASEGARAGRAMVDEVVLPVLQRA IRDDMDAREIESLSMLQRGFEELKEANSELAYNVILDILQGINDNNAIKRHVQTSRGLFPHKRITRKSEMTSKGL VVTEETEEVSGLPESSNGVPPAQAEAETPRRSPIAELLYMRWLEGLRLKWPSIMTGS |
| Length | 657 |
Coding
| Sequence id | CC1G_00304T0 |
|---|---|
| Sequence |
>CC1G_00304T0 ATGACACTAACTTGGTCTTCGACCCGCTCGCCGCCCCCCTCTCCCAAGGTGGAGCAACGGACCCGACCCAGGGAT CCCTGCCCAATCCCGAGCAGCAACCCCGCAAGCCAGTATACGCTACTGGAGAAGCTTGGGACAGGAAGTTTTGGT GTCGTGTACAAGGCCATACACAACGAGACCAAGCAAATTGTTGCAATCAAGCAGATAGATCTTGAAGACTCGGAC GACGACATTTCTGAAATACAGCAAGAAATTGCCAGCCTTGCCCAATGCGACTCTGAATACGTGACCAAGTACTAT GGGTCCTTCGTGGTGCACTACAAACTCTGGATCGTGATGGAGTACCTCGCAGGTGGCTCGTGTCTTGACCTTCTT AAAGCCGGGCCGTTTTCTGAAGCACACATCGCTGTCATTTGCCGCGAGCTTCTTTTGGGACTCGACTACCTCCAC GCTGAAGGAACCATTCACCGGGACATCAAGGCTGCGAATGTGCTTCTCTCCTCGTCGGGCAAAGTCAAGCTGGCC GATTTTGGCGTTGCAGCTCAGCTCACCAACACCCTACGACACACATTTGTCGGCACCCCCTTCTGGATGGCACCT GAAGTTATTCGACAGGCCGGATACGATTCCAAAGCGGACATGTGGAGCCTTGGAATTACAGCGATTGAGATGGCT AAAGGCGAGCCTCCATTAGCCGAGTATCACCCGATGCGGGTTCTTTTTCTCATCCCAAAAGCGAAGCCACCGACT CTTGAAGGACCGTTCTCAGCGGCATTCAAGGATTTCGTGACCCTATGCTTGACTAAAGACCCCAAACTCCGCCCA TCTGCCAACGAGCTGCTTCAACATAGATTCATTCGTGGCGCAAAGAAGACATCTTATTTGACAGAGTTGATCGAG CGGTACCAGGAATGGCGCATGCGGAGCCCTCACAAAGGCCAGAATAATGCTGCTACGATCAGGAATACCGCCACA TGGGATATGAATGATACCATTCGGAGCGACTGGAATTTCGACACTGTGAAGTCGATGGGGGCCATGGGTACTTTC AGGGGCTCGGTTAAGGACCTTGGGATGCCTACGGGGATGATCCTTGAAGCCGACGAGAGCGACGATGGAGAGACC TCGATTGATACAGGTGCAGCAACCAAGGGAAGCGATCCGCTTCTCTCAAATTCACAAGCCGCACATTCGACTGTG ATGATCAAGAACCCTCCGCCGCATCTTGCGGAATCAGACGACATTGCAGACGATGATATCCCAAACGGTGCCCCT CCTGCCTATTCCGGTTCGGTTCGCAGTGCCAGACGCGCCTCTTACGCAGAGAGATCCTCCACAGATGGTCCAGGA ACGGTTTTAAATGAGGCAGATCTTGGTACTGGAGTGGATACTATCCGACCCGTCAAGAAAGTCGATGCAGCTGGC TCTCTGCGCCTGTCCACTGGTTATCTCGGTAGCATACGCAAGGAGGGTAGCGGCTCATCCTACTCGACTCACAAA CGGTCGGCAAGTGAAGGTGCCAGGGCCGGTAGGGCAATGGTAGACGAGGTTGTATTGCCTGTCCTACAAAGAGCT ATTCGGGATGACATGGACGCACGCGAAATCGAGTCTCTCAGCATGCTTCAGCGAGGCTTCGAAGAACTCAAGGAA GCCAACTCGGAACTGGCGTACAACGTCATTCTGGACATCCTCCAGGGCATCAATGATAACAACGCCATTAAACGA CATGTCCAGACATCCCGCGGGCTGTTCCCACACAAACGCATTACTCGCAAGAGTGAGATGACGTCCAAGGGTCTC GTCGTCACAGAAGAGACGGAGGAGGTATCCGGACTTCCGGAGTCGTCGAACGGTGTTCCTCCTGCGCAGGCTGAA GCTGAAACCCCGCGACGGTCCCCCATAGCTGAACTCCTCTACATGCGCTGGCTGGAAGGACTGAGATTGAAGTGG CCTAGTATCATGACCGGCAGC |
| Length | 1974 |
Transcript
| Sequence id | CC1G_00304T0 |
|---|---|
| Sequence |
>CC1G_00304T0 ATGACACTAACTTGGTCTTCGACCCGCTCGCCGCCCCCCTCTCCCAAGGTGGAGCAACGGACCCGACCCAGGGAT CCCTGCCCAATCCCGAGCAGCAACCCCGCAAGCCAGTATACGCTACTGGAGAAGCTTGGGACAGGAAGTTTTGGT GTCGTGTACAAGGCCATACACAACGAGACCAAGCAAATTGTTGCAATCAAGCAGATAGATCTTGAAGACTCGGAC GACGACATTTCTGAAATACAGCAAGAAATTGCCAGCCTTGCCCAATGCGACTCTGAATACGTGACCAAGTACTAT GGGTCCTTCGTGGTGCACTACAAACTCTGGATCGTGATGGAGTACCTCGCAGGTGGCTCGTGTCTTGACCTTCTT AAAGCCGGGCCGTTTTCTGAAGCACACATCGCTGTCATTTGCCGCGAGCTTCTTTTGGGACTCGACTACCTCCAC GCTGAAGGAACCATTCACCGGGACATCAAGGCTGCGAATGTGCTTCTCTCCTCGTCGGGCAAAGTCAAGCTGGCC GATTTTGGCGTTGCAGCTCAGCTCACCAACACCCTACGACACACATTTGTCGGCACCCCCTTCTGGATGGCACCT GAAGTTATTCGACAGGCCGGATACGATTCCAAAGCGGACATGTGGAGCCTTGGAATTACAGCGATTGAGATGGCT AAAGGCGAGCCTCCATTAGCCGAGTATCACCCGATGCGGGTTCTTTTTCTCATCCCAAAAGCGAAGCCACCGACT CTTGAAGGACCGTTCTCAGCGGCATTCAAGGATTTCGTGACCCTATGCTTGACTAAAGACCCCAAACTCCGCCCA TCTGCCAACGAGCTGCTTCAACATAGATTCATTCGTGGCGCAAAGAAGACATCTTATTTGACAGAGTTGATCGAG CGGTACCAGGAATGGCGCATGCGGAGCCCTCACAAAGGCCAGAATAATGCTGCTACGATCAGGAATACCGCCACA TGGGATATGAATGATACCATTCGGAGCGACTGGAATTTCGACACTGTGAAGTCGATGGGGGCCATGGGTACTTTC AGGGGCTCGGTTAAGGACCTTGGGATGCCTACGGGGATGATCCTTGAAGCCGACGAGAGCGACGATGGAGAGACC TCGATTGATACAGGTGCAGCAACCAAGGGAAGCGATCCGCTTCTCTCAAATTCACAAGCCGCACATTCGACTGTG ATGATCAAGAACCCTCCGCCGCATCTTGCGGAATCAGACGACATTGCAGACGATGATATCCCAAACGGTGCCCCT CCTGCCTATTCCGGTTCGGTTCGCAGTGCCAGACGCGCCTCTTACGCAGAGAGATCCTCCACAGATGGTCCAGGA ACGGTTTTAAATGAGGCAGATCTTGGTACTGGAGTGGATACTATCCGACCCGTCAAGAAAGTCGATGCAGCTGGC TCTCTGCGCCTGTCCACTGGTTATCTCGGTAGCATACGCAAGGAGGGTAGCGGCTCATCCTACTCGACTCACAAA CGGTCGGCAAGTGAAGGTGCCAGGGCCGGTAGGGCAATGGTAGACGAGGTTGTATTGCCTGTCCTACAAAGAGCT ATTCGGGATGACATGGACGCACGCGAAATCGAGTCTCTCAGCATGCTTCAGCGAGGCTTCGAAGAACTCAAGGAA GCCAACTCGGAACTGGCGTACAACGTCATTCTGGACATCCTCCAGGGCATCAATGATAACAACGCCATTAAACGA CATGTCCAGACATCCCGCGGGCTGTTCCCACACAAACGCATTACTCGCAAGAGTGAGATGACGTCCAAGGGTCTC GTCGTCACAGAAGAGACGGAGGAGGTATCCGGACTTCCGGAGTCGTCGAACGGTGTTCCTCCTGCGCAGGCTGAA GCTGAAACCCCGCGACGGTCCCCCATAGCTGAACTCCTCTACATGCGCTGGCTGGAAGGACTGAGATTGAAGTGG CCTAGTATCATGACCGGCAGCTAG |
| Length | 1974 |
Gene
| Sequence id | CC1G_00304T0 |
|---|---|
| Sequence |
>CC1G_00304T0 ATGACACTAACTTGGGTATGTTTCGTAAACAGACAAAGTCTTCGACCCGCTCGCCGCCCCCCTCTCCCAAGGTGG AGCAACGGACCCGACCCAGGGATCCCTGCCCAATCCCGAGCAGCAACCCCGCAAGCCAGTATACGCTACTGGAGA AGCTTGGGACAGGAAGTTTTGGTGTCGTGTACAAGGCCATACACAACGAGACCAAGCAAATTGTTGCAATCAAGC AGATAGGTGCGCCCTCCTCGTTGTCTTGGCTCCGCACGGTACTAATCCAATATGGTAGATCTTGAAGACTCGGAC GACGACATTTCTGAAATACAGCAAGAAATTGCCAGCCTTGCCCAATGCGACTCTGAATACGTGACCAAGTACTAT GGGTCCTTCGTGGTGCACTACAAACTCTGGATCGTGATGGAGTACCTCGCAGGTGGCTCGTGTCTTGACCTTCTT AAAGCCGGGCCGTTTTCTGAAGCACACATCGCTGTCATTTGCCGCGAGCTTCTTTTGGGACTCGACTACCTCCAC GCTGAAGGAACCATTCACCGGGACATCAAGGCTGCGAATGTGCTTCTCTCCTCGTCGGGCAAAGTCAAGCTGGCC GATTTTGGCGTTGCAGCTCAGCTCACCAACACCCTACGACACACATTTGTCGGCACCCCCTTCTGGATGGCACCT GAAGTTATTCGACAGGCCGGATACGATTCCAAAGCGGACATGTGGAGCCTTGGAATTACAGCGATTGAGATGGCT AAAGGCGAGCCTCCATTAGCCGAGTATCACCCGATGCGGGTTCTTTTTCTCATCCCAAAAGCGAAGCCACCGACT CTTGAAGGACCGTTCTCAGCGGCATTCAAGGATTTCGTGACCCTATGCTTGACTAAAGACCCCAAACTCGTTCGT AATTCTAATCTACCCTGTTTGAAATACATTACTAACTCCTTATTGTGTTCAATTAGCGCCCATCTGCCAACGAGC TGCTTCAACATAGATTCATTCGTGGCGCAAAGAAGACATCTTATTTGACAGAGTTGATCGAGCGGTACCAGGAAT GGCGCATGCGGAGCCCTCACAAAGGCCAGAATAATGCTGCTACGATCAGGAATACCGCCACATGGGATATGAATG ATACCATTCGGAGCGACTGGAATTTCGACACTGTGAAGTCGATGGGGGCCATGGGTACTTTCAGGGGCTCGGTTA AGGACCTTGGGATGCCTACGGGGATGATCCTTGAAGCCGACGAGAGCGACGATGGAGAGACCTCGATTGATACAG GTGCAGCAACCAAGGGAAGCGATCCGCTTCTCTCAAATTCACAAGCCGCACATTCGACTGTGATGATCAAGAACC CTCCGCCGCATCTTGCGGAATCAGACGACATTGCAGACGATGATATCCCAAACGGTATGCATCTAACGTCTGGCT CGGTGTTAACTTTACTGACCATCCTCTTTAGGTGCCCCTCCTGCCTATTCCGGTTCGGTTCGCAGTGCCAGACGC GCCTCTTACGCAGAGAGATCCTCCACAGATGGTCCAGGAACGGTTTTAAATGAGGCAGATCTTGGTACTGGAGTG GATACTATCCGACCCGTCAAGAAAGTCGATGCAGCTGGCTCTCTGCGCCTGTCCACTGGTTATCTCGGTAGCATA CGCAAGGAGGGTAGCGGCTCATCCTACTCGACTCACAAACGGTCGGCAAGTGAAGGTGCCAGGGCCGGTAGGGCA ATGGTAGACGAGGTTGTATTGCCTGTCCTACAAAGAGTAAGTGCCTTGCGGCTACGCCGTCATGAGATTTGCTCA AGTGTTTTTCAGGCTATTCGGGATGACATGGACGCACGCGAAATCGAGTCTCTCAGCATGCTTCAGCGAGGCTTC GAAGAACTCAAGGAAGCCAACTCGGAACTGGCGTACAACGTCATTCTGGACATCCTCCAGGGCATCAATGAGTGA GTAAATCAACCACTCTCATGGAACGCCAGTCCCTAACTATGTTTTCAGTAACAACGCCATTAAACGACATGTCCA GACATCCCGCGGGCTGTTCCCACACAAACGCATTACTCGCAAGAGTGAGATGACGTCCAAGGGTCTCGTCGTCAC AGAAGAGACGGAGGAGGTATCCGGACTTCCGGAGTCGTCGAACGGTGTTCCTCCTGCGCAGGCTGAAGCTGAAAC CCCGCGACGGTCCCCCATAGCTGAACTCCTCTACATGCGCTGGCTGGAAGGACTGAGATTGAAGTGGCCTAGTAT CATGACCGGCAGCTAG |
| Length | 2266 |