CC1G_00654
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_00654 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N3F0 | Functional description | AGC/AGC-Unique protein kinase |
| Location | Chr_1:3485281..3489612 | Strand | - |
| Gene length (nt) | 4332 | Transcript length (nt) | 3948 |
| CDS length (nt) | 3948 | Protein length (aa) | 1315 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Pleurotus ostreatus PC9 | PleosPC9_1_116025 | 56.7 | 0 | 1342 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1063313 | 56.6 | 0 | 1339 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1457021 | 55.6 | 0 | 1332 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB29452 | 56.4 | 0 | 1300 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_7299 | 53.7 | 0 | 1259 |
| Lentinula edodes NBRC 111202 | Lenedo1_1047471 | 53.6 | 0 | 1242 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_104237 | 50.8 | 0 | 1207 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_113649 | 50.4 | 0 | 1206 |
| Flammulina velutipes | Flave_chr07AA01038 | 52.5 | 0 | 1189 |
| Schizophyllum commune H4-8 | Schco3_2644731 | 51.9 | 0 | 1188 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_125581 | 52.6 | 0 | 1169 |
| Grifola frondosa | Grifr_OBZ68429 | 52.2 | 0 | 1133 |
| Auricularia subglabra | Aurde3_1_1313702 | 48.1 | 0 | 1063 |
| Agrocybe aegerita | Agrae_CAA7264913 | 63.3 | 0 | 1034 |
| Lentinula edodes B17 | Lened_B_1_1_10979 | 54.7 | 8.003E-199 | 657 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 561 |
| Description | AGC/AGC-Unique protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd05123 | STKc_AGC | IPR045270 | 451 | 758 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 446 | 758 |
| Pfam | PF00433 | Protein kinase C terminal domain | IPR017892 | 786 | 864 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR045270 | Serine/Threonine Kinase AGC, catalytic domain |
| IPR017892 | Protein kinase, C-terminal |
| IPR000961 | AGC-kinase, C-terminal |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004674 | protein serine/threonine kinase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K13303 |
EggNOG
| COG category | Description |
|---|---|
| T | Agc agc-unique protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
Conservation of CC1G_00654 across fungi.
Arrow shows the origin of gene family containing CC1G_00654.
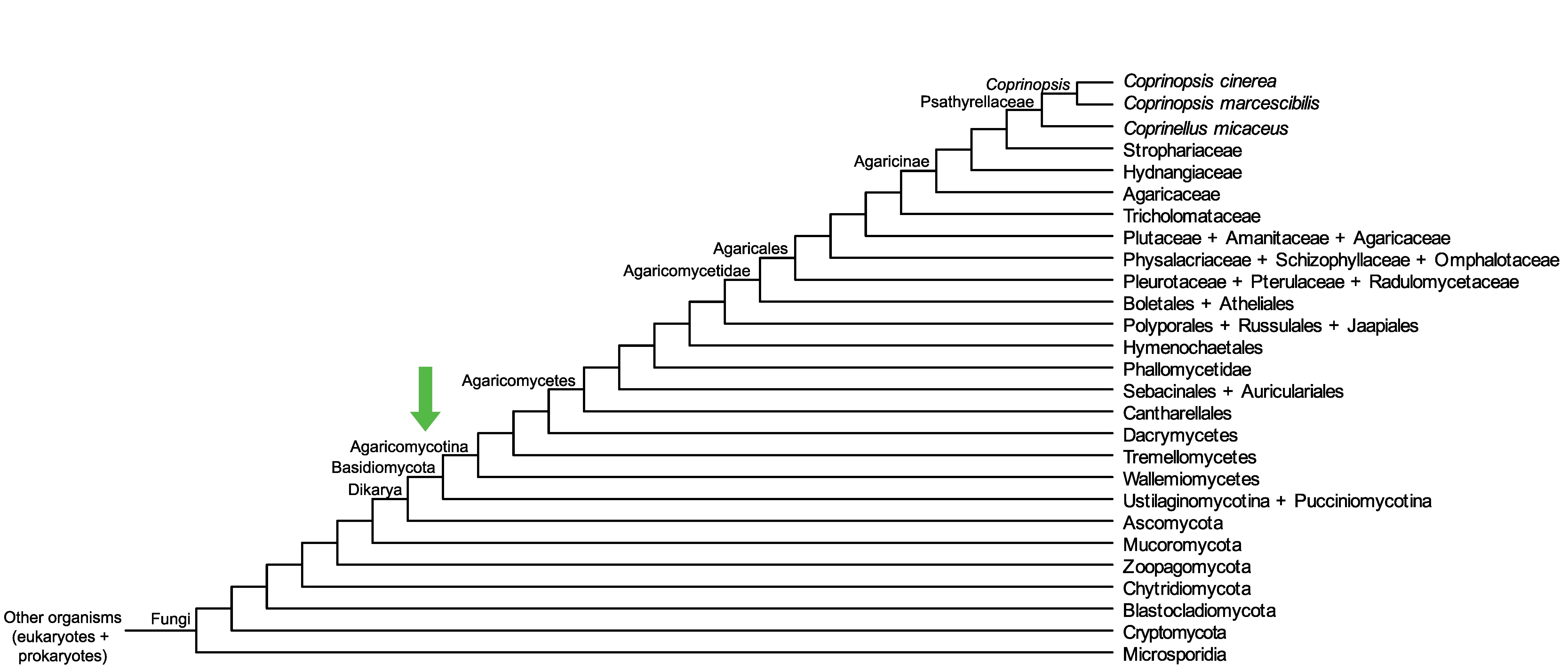
Protein
| Sequence id | 561 |
|---|---|
| Sequence |
>561 MQVVDTNIPANRRQPVRLDGQDGPWSVSVAETPHDSRSYSLYIKTPTHNLTLTRTAIEILELDRKLRDSHPASKI PVLPIDAASLPIPPKRKSNFLNTLSRLASPTSNKNAKSAARRGENATTATAVVASTLPTPPLTSPASESNDPFTQ VENPSEPSPSAASPSATSTAIAAYLTTISNAPELRKDRVWKRFVRVRTDDLESVRVERAIKRVRSDLAAHVGGLA NNRASLIGSVHAEHDKENADRAEASLPTPEDDAVDSAAPSGGNQGGAGQDQKEGDDAPEAHAREATATPADAQAD NPAGASDAAPVQGDQATSSDDQKHLVDGEGRPATGTDESTAAAQGHTADVDQTQAAAPSSSSAATSSTSAAAAAS RLHRSQSCEPDKSHKMARAYAQSTTPSQDGLDGGMSSQIETGDESSFSAAVTRKRKKKKKSSKKVTIEDFEMIRV LGKGCAGKVLLVRHKTGSGLFALKAITKRHVLAHQELQHTLTEQAVLKRMAAESKDPFVVKLWWSFHDKENLFLV MDFHPGGDLATQLARWGRLSRDRTRFYAAEIVEGVEGLHAAGVIYRDLKPENILIAADGHIVLTDFGLSKEFSRP HLSAASSAPMTPSGSRSSDFYSSAPGTPHSVMPPWMKPDKNGEMMYGWPGQPIGNPDVTTTFCGTAEYLAPEVIQ GLPYSYEVDWWSFGTMLYEMLTGMTPFYANNHSDMYVRVLQDELTFPDERVMDQDTKSLIRGLLQKNPDLRIREP RIKKHPYFSMIDWCHVYYKRYIPPYVPPVDRTVAYDTQNFDETFLDMEPVLDEYVDETGQATDTDAEPQTDTDRT DGDTNTTPSQSRSSSVRPASRTANEEEDDSVDVFDGYSFKGRHSILMDDDDEDGDEVDSEEGEDDESMDQDGSSS MMTGETKSEGDTIDEDEVRQQQREEDGATSELEPKTPEARPSALPPVDDAAPPKPAQPQPPQQSPPPPTPPAKTR EPSKVHEPVVPKDSLPSASEEELLANASVAVELEEQLEYQAKEEEAYKRATIIADPNGRPVNGRHTPPPKASGSR AQGRTKRREKSGVPALDKYLSDGGDDEPEMTEPERDEEDEDWDFVEAGDGEDRNGAKGTSLWARGVVDRYKLAVF RKGSTPSQQRSVSGMSKSSQVSEGGTGAESPSPSSRRGRGTGLNFRKHPRQFLRPKAPPSSYTNSTRSFSATASS SLSAAASKSMSMPTGSGLLTPVNTSMFSPSLKSKESAVSMDAKSMSSDYSGNVISPTTPSATNGGPELGSPPAEG EQVEKPLKNKKLKKYKNNAEKVFSLFSSNSPKPPPASATS |
| Length | 1315 |
Coding
| Sequence id | CC1G_00654T0 |
|---|---|
| Sequence |
>CC1G_00654T0 ATGCAAGTTGTAGATACCAACATACCCGCCAACCGCAGGCAACCAGTCCGTCTAGATGGCCAAGATGGCCCCTGG AGCGTCAGCGTCGCAGAAACACCCCACGATTCCCGCTCCTACAGTCTTTACATAAAGACGCCGACGCACAACCTC ACGCTCACCCGCACTGCCATCGAGATTCTTGAGCTGGACCGAAAACTCCGCGACTCCCATCCTGCCTCCAAGATC CCAGTCCTGCCCATCGACGCCGCATCGCTCCCCATCCCTCCCAAACGCAAGTCAAACTTTTTGAACACTCTTTCT CGTCTTGCGTCCCCGACCTCGAACAAGAATGCCAAATCGGCAGCTCGTCGAGGTGAAAACGCGACGACGGCGACT GCGGTTGTCGCGTCCACACTCCCCACCCCGCCTCTAACCAGCCCCGCAAGCGAGAGCAACGATCCCTTCACTCAG GTCGAGAACCCCAGCGAGCCAAGCCCATCAGCTGCCTCCCCCTCGGCTACCAGCACCGCGATCGCAGCCTATCTC ACCACCATCTCCAACGCTCCAGAGTTGCGCAAGGATCGTGTGTGGAAGCGTTTTGTTCGGGTCCGGACGGATGAT CTAGAGAGTGTCCGTGTTGAAAGGGCCATTAAACGTGTTCGCTCTGATCTAGCGGCACATGTCGGTGGTCTTGCC AATAACCGTGCTAGTCTCATTGGGAGTGTGCACGCCGAGCATGACAAAGAAAACGCTGATCGAGCAGAGGCTTCG CTGCCCACTCCTGAGGATGACGCTGTGGATTCAGCTGCGCCATCCGGAGGCAATCAGGGTGGTGCTGGGCAAGAC CAGAAGGAGGGGGACGATGCTCCAGAAGCCCATGCCCGAGAGGCTACTGCTACTCCTGCTGATGCTCAGGCGGAC AACCCTGCAGGAGCGTCAGATGCCGCGCCCGTTCAGGGTGATCAGGCGACCTCGTCTGATGATCAAAAGCACCTT GTCGATGGAGAGGGCCGACCCGCCACCGGAACAGATGAGTCTACCGCTGCTGCACAAGGGCACACTGCCGATGTC GACCAAACTCAAGCTGCTGCTCCTTCCTCTTCGTCTGCTGCGACATCTTCCACTTCTGCAGCTGCTGCAGCTTCC CGTCTCCACCGTTCCCAGTCGTGCGAGCCTGACAAGTCTCACAAGATGGCTAGGGCCTACGCACAGTCCACGACC CCGAGCCAGGACGGCCTCGATGGTGGGATGTCATCACAGATCGAGACCGGCGACGAATCGTCCTTCTCCGCAGCC GTCACCCGCAAACGCAAGAAGAAGAAGAAGTCGTCAAAGAAAGTTACCATAGAAGACTTTGAGATGATTCGTGTG CTTGGGAAGGGTTGTGCTGGTAAAGTGTTGCTTGTTCGACACAAGACTGGCTCGGGCCTGTTCGCTCTCAAGGCT ATCACGAAACGACACGTTTTGGCGCATCAAGAGCTGCAGCATACGTTGACGGAACAGGCTGTTCTAAAACGGATG GCCGCGGAGTCGAAAGATCCCTTTGTCGTCAAGCTGTGGTGGAGTTTCCATGATAAAGAGAACCTCTTCTTGGTT ATGGACTTCCACCCCGGAGGTGATCTTGCGACCCAACTGGCTCGTTGGGGCCGACTCAGCAGGGACCGAACCCGT TTCTACGCCGCTGAAATCGTCGAAGGTGTCGAAGGCCTCCACGCCGCCGGTGTCATCTACCGCGACCTCAAGCCC GAAAACATCCTCATCGCCGCGGACGGGCACATCGTTCTCACTGATTTCGGTCTCTCCAAGGAGTTCTCCCGTCCC CACTTGTCCGCTGCTTCTTCAGCTCCGATGACTCCGAGTGGAAGTCGTTCGAGCGATTTCTATTCGAGTGCGCCC GGGACCCCACATAGTGTGATGCCTCCGTGGATGAAGCCTGATAAGAATGGCGAAATGATGTACGGGTGGCCAGGT CAGCCGATTGGGAATCCGGATGTGACCACTACGTTCTGTGGGACGGCCGAGTACCTTGCGCCTGAGGTTATCCAA GGCTTGCCGTATTCGTACGAGGTGGATTGGTGGAGTTTTGGAACCATGTTGTATGAGATGTTGACTGGCATGACT CCATTCTATGCCAACAACCATTCCGACATGTATGTGAGGGTGTTGCAGGACGAGTTGACATTCCCGGATGAGAGG GTTATGGATCAGGATACCAAGAGCTTGATTCGTGGTCTCTTGCAAAAGAATCCCGACCTCCGAATTCGTGAACCT AGGATCAAGAAACACCCCTATTTCTCCATGATCGACTGGTGTCACGTCTACTACAAGCGGTACATTCCTCCATAT GTCCCTCCTGTCGACCGCACGGTTGCATACGACACCCAAAACTTCGATGAAACCTTCCTCGACATGGAACCTGTT TTGGACGAATACGTCGACGAGACTGGCCAAGCCACCGACACTGATGCCGAGCCTCAGACCGATACCGACCGGACT GACGGTGATACCAACACCACGCCTTCTCAATCGCGCAGTTCTTCCGTCCGTCCTGCTTCTCGAACGGCAAACGAG GAAGAAGACGACAGTGTGGACGTGTTCGATGGGTACTCGTTCAAGGGTCGACACTCGATACTTATGGACGATGAC GACGAGGACGGTGACGAGGTTGACAGTGAAGAGGGTGAGGATGACGAGAGTATGGATCAGGATGGCAGCTCTTCG ATGATGACTGGGGAGACCAAGTCGGAGGGCGATACGATTGATGAGGATGAGGTTCGTCAGCAACAACGTGAGGAG GATGGTGCTACTTCAGAGTTGGAGCCCAAGACGCCTGAAGCAAGGCCTTCGGCTTTGCCTCCTGTCGACGACGCC GCACCACCAAAACCAGCGCAGCCTCAACCACCACAGCAAAGTCCACCGCCACCAACTCCGCCCGCCAAAACACGC GAACCTTCAAAGGTACACGAGCCTGTCGTCCCCAAGGATTCGTTGCCGAGCGCTTCCGAGGAAGAGCTGTTGGCC AATGCCAGTGTCGCTGTCGAGCTCGAAGAGCAACTCGAGTACCAGGCCAAGGAAGAAGAGGCGTACAAGCGAGCT ACCATCATCGCCGATCCGAATGGACGACCTGTCAATGGACGACACACACCACCTCCCAAAGCAAGTGGCAGCCGT GCTCAAGGACGTACCAAACGACGCGAGAAATCTGGTGTTCCGGCATTGGACAAGTATCTGTCTGATGGTGGTGAT GATGAGCCTGAGATGACTGAGCCTGAGCGGGATGAAGAAGATGAGGACTGGGATTTTGTCGAGGCTGGGGATGGG GAAGACAGGAACGGCGCCAAGGGAACGAGTTTGTGGGCTCGTGGTGTGGTGGATCGGTACAAACTCGCGGTGTTC CGCAAGGGGTCGACACCAAGTCAGCAGCGTTCGGTCTCCGGGATGTCAAAATCGTCTCAGGTATCGGAGGGTGGT ACTGGAGCCGAGTCCCCTTCTCCTTCTAGCCGCCGTGGTCGAGGCACCGGCTTGAACTTCCGCAAACATCCCCGC CAATTCCTCCGTCCCAAAGCCCCACCATCGAGTTATACGAATTCGACGAGGTCGTTCTCTGCGACTGCTTCGAGT TCGCTTTCCGCTGCTGCTTCAAAATCGATGTCGATGCCTACTGGAAGTGGATTGTTGACCCCCGTGAACACGTCC ATGTTCTCGCCCTCCCTCAAGTCGAAGGAATCGGCAGTCTCGATGGACGCGAAGAGCATGTCATCGGATTACTCT GGGAACGTGATCTCGCCGACTACGCCATCCGCGACGAATGGTGGTCCTGAGCTTGGGTCGCCGCCAGCAGAGGGT GAGCAAGTGGAGAAGCCGCTCAAGAACAAGAAGTTGAAGAAGTACAAGAACAACGCGGAGAAGGTGTTTTCGTTG TTTTCTTCGAATTCGCCTAAACCTCCCCCCGCGTCGGCTACGTCG |
| Length | 3948 |
Transcript
| Sequence id | CC1G_00654T0 |
|---|---|
| Sequence |
>CC1G_00654T0 ATGCAAGTTGTAGATACCAACATACCCGCCAACCGCAGGCAACCAGTCCGTCTAGATGGCCAAGATGGCCCCTGG AGCGTCAGCGTCGCAGAAACACCCCACGATTCCCGCTCCTACAGTCTTTACATAAAGACGCCGACGCACAACCTC ACGCTCACCCGCACTGCCATCGAGATTCTTGAGCTGGACCGAAAACTCCGCGACTCCCATCCTGCCTCCAAGATC CCAGTCCTGCCCATCGACGCCGCATCGCTCCCCATCCCTCCCAAACGCAAGTCAAACTTTTTGAACACTCTTTCT CGTCTTGCGTCCCCGACCTCGAACAAGAATGCCAAATCGGCAGCTCGTCGAGGTGAAAACGCGACGACGGCGACT GCGGTTGTCGCGTCCACACTCCCCACCCCGCCTCTAACCAGCCCCGCAAGCGAGAGCAACGATCCCTTCACTCAG GTCGAGAACCCCAGCGAGCCAAGCCCATCAGCTGCCTCCCCCTCGGCTACCAGCACCGCGATCGCAGCCTATCTC ACCACCATCTCCAACGCTCCAGAGTTGCGCAAGGATCGTGTGTGGAAGCGTTTTGTTCGGGTCCGGACGGATGAT CTAGAGAGTGTCCGTGTTGAAAGGGCCATTAAACGTGTTCGCTCTGATCTAGCGGCACATGTCGGTGGTCTTGCC AATAACCGTGCTAGTCTCATTGGGAGTGTGCACGCCGAGCATGACAAAGAAAACGCTGATCGAGCAGAGGCTTCG CTGCCCACTCCTGAGGATGACGCTGTGGATTCAGCTGCGCCATCCGGAGGCAATCAGGGTGGTGCTGGGCAAGAC CAGAAGGAGGGGGACGATGCTCCAGAAGCCCATGCCCGAGAGGCTACTGCTACTCCTGCTGATGCTCAGGCGGAC AACCCTGCAGGAGCGTCAGATGCCGCGCCCGTTCAGGGTGATCAGGCGACCTCGTCTGATGATCAAAAGCACCTT GTCGATGGAGAGGGCCGACCCGCCACCGGAACAGATGAGTCTACCGCTGCTGCACAAGGGCACACTGCCGATGTC GACCAAACTCAAGCTGCTGCTCCTTCCTCTTCGTCTGCTGCGACATCTTCCACTTCTGCAGCTGCTGCAGCTTCC CGTCTCCACCGTTCCCAGTCGTGCGAGCCTGACAAGTCTCACAAGATGGCTAGGGCCTACGCACAGTCCACGACC CCGAGCCAGGACGGCCTCGATGGTGGGATGTCATCACAGATCGAGACCGGCGACGAATCGTCCTTCTCCGCAGCC GTCACCCGCAAACGCAAGAAGAAGAAGAAGTCGTCAAAGAAAGTTACCATAGAAGACTTTGAGATGATTCGTGTG CTTGGGAAGGGTTGTGCTGGTAAAGTGTTGCTTGTTCGACACAAGACTGGCTCGGGCCTGTTCGCTCTCAAGGCT ATCACGAAACGACACGTTTTGGCGCATCAAGAGCTGCAGCATACGTTGACGGAACAGGCTGTTCTAAAACGGATG GCCGCGGAGTCGAAAGATCCCTTTGTCGTCAAGCTGTGGTGGAGTTTCCATGATAAAGAGAACCTCTTCTTGGTT ATGGACTTCCACCCCGGAGGTGATCTTGCGACCCAACTGGCTCGTTGGGGCCGACTCAGCAGGGACCGAACCCGT TTCTACGCCGCTGAAATCGTCGAAGGTGTCGAAGGCCTCCACGCCGCCGGTGTCATCTACCGCGACCTCAAGCCC GAAAACATCCTCATCGCCGCGGACGGGCACATCGTTCTCACTGATTTCGGTCTCTCCAAGGAGTTCTCCCGTCCC CACTTGTCCGCTGCTTCTTCAGCTCCGATGACTCCGAGTGGAAGTCGTTCGAGCGATTTCTATTCGAGTGCGCCC GGGACCCCACATAGTGTGATGCCTCCGTGGATGAAGCCTGATAAGAATGGCGAAATGATGTACGGGTGGCCAGGT CAGCCGATTGGGAATCCGGATGTGACCACTACGTTCTGTGGGACGGCCGAGTACCTTGCGCCTGAGGTTATCCAA GGCTTGCCGTATTCGTACGAGGTGGATTGGTGGAGTTTTGGAACCATGTTGTATGAGATGTTGACTGGCATGACT CCATTCTATGCCAACAACCATTCCGACATGTATGTGAGGGTGTTGCAGGACGAGTTGACATTCCCGGATGAGAGG GTTATGGATCAGGATACCAAGAGCTTGATTCGTGGTCTCTTGCAAAAGAATCCCGACCTCCGAATTCGTGAACCT AGGATCAAGAAACACCCCTATTTCTCCATGATCGACTGGTGTCACGTCTACTACAAGCGGTACATTCCTCCATAT GTCCCTCCTGTCGACCGCACGGTTGCATACGACACCCAAAACTTCGATGAAACCTTCCTCGACATGGAACCTGTT TTGGACGAATACGTCGACGAGACTGGCCAAGCCACCGACACTGATGCCGAGCCTCAGACCGATACCGACCGGACT GACGGTGATACCAACACCACGCCTTCTCAATCGCGCAGTTCTTCCGTCCGTCCTGCTTCTCGAACGGCAAACGAG GAAGAAGACGACAGTGTGGACGTGTTCGATGGGTACTCGTTCAAGGGTCGACACTCGATACTTATGGACGATGAC GACGAGGACGGTGACGAGGTTGACAGTGAAGAGGGTGAGGATGACGAGAGTATGGATCAGGATGGCAGCTCTTCG ATGATGACTGGGGAGACCAAGTCGGAGGGCGATACGATTGATGAGGATGAGGTTCGTCAGCAACAACGTGAGGAG GATGGTGCTACTTCAGAGTTGGAGCCCAAGACGCCTGAAGCAAGGCCTTCGGCTTTGCCTCCTGTCGACGACGCC GCACCACCAAAACCAGCGCAGCCTCAACCACCACAGCAAAGTCCACCGCCACCAACTCCGCCCGCCAAAACACGC GAACCTTCAAAGGTACACGAGCCTGTCGTCCCCAAGGATTCGTTGCCGAGCGCTTCCGAGGAAGAGCTGTTGGCC AATGCCAGTGTCGCTGTCGAGCTCGAAGAGCAACTCGAGTACCAGGCCAAGGAAGAAGAGGCGTACAAGCGAGCT ACCATCATCGCCGATCCGAATGGACGACCTGTCAATGGACGACACACACCACCTCCCAAAGCAAGTGGCAGCCGT GCTCAAGGACGTACCAAACGACGCGAGAAATCTGGTGTTCCGGCATTGGACAAGTATCTGTCTGATGGTGGTGAT GATGAGCCTGAGATGACTGAGCCTGAGCGGGATGAAGAAGATGAGGACTGGGATTTTGTCGAGGCTGGGGATGGG GAAGACAGGAACGGCGCCAAGGGAACGAGTTTGTGGGCTCGTGGTGTGGTGGATCGGTACAAACTCGCGGTGTTC CGCAAGGGGTCGACACCAAGTCAGCAGCGTTCGGTCTCCGGGATGTCAAAATCGTCTCAGGTATCGGAGGGTGGT ACTGGAGCCGAGTCCCCTTCTCCTTCTAGCCGCCGTGGTCGAGGCACCGGCTTGAACTTCCGCAAACATCCCCGC CAATTCCTCCGTCCCAAAGCCCCACCATCGAGTTATACGAATTCGACGAGGTCGTTCTCTGCGACTGCTTCGAGT TCGCTTTCCGCTGCTGCTTCAAAATCGATGTCGATGCCTACTGGAAGTGGATTGTTGACCCCCGTGAACACGTCC ATGTTCTCGCCCTCCCTCAAGTCGAAGGAATCGGCAGTCTCGATGGACGCGAAGAGCATGTCATCGGATTACTCT GGGAACGTGATCTCGCCGACTACGCCATCCGCGACGAATGGTGGTCCTGAGCTTGGGTCGCCGCCAGCAGAGGGT GAGCAAGTGGAGAAGCCGCTCAAGAACAAGAAGTTGAAGAAGTACAAGAACAACGCGGAGAAGGTGTTTTCGTTG TTTTCTTCGAATTCGCCTAAACCTCCCCCCGCGTCGGCTACGTCGTAA |
| Length | 3948 |
Gene
| Sequence id | CC1G_00654T0 |
|---|---|
| Sequence |
>CC1G_00654T0 ATGCAAGTTGTAGATACCAACATACCCGCCAACCGCAGGCAACCAGTCCGTCTAGATGGCCAAGATGGCCCCTGG AGCGTCAGCGTCGCAGAAACACCCCACGATTCCCGCTCCTACAGTCTTTACATAAAGAGTGAGTCGTCTTTATTC CGCACCCCACTCTGTATACATCGTCGAGCGTGTGCTTTGTCATTTCAACCCATTCTGAATTTGTTTTCTGATTCT AATACGTTATCCTGACAGCGCCGACGCACAACCTCACGCTCACCCGCACTGCCATCGAGATTCTTGAGCTGGACC GAAAACTCCGCGACTCCCATCCTGCCTCCAAGATCCCAGTCCTGCCCATCGACGCCGCATCGCTCCCCATCCCTC CCAAACGCAAGTCAAACTTTTTGAACACTCTTTCTCGTCTTGCGTCCCCGACCTCGAACAAGAATGCCAAATCGG CAGCTCGTCGAGGTGAAAACGCGACGACGGCGACTGCGGTTGTCGCGTCCACACTCCCCACCCCGCCTCTAACCA GCCCCGCAAGCGAGAGCAACGATCCCTTCACTCAGGTCGAGAACCCCAGCGAGCCAAGCCCATCAGCTGCCTCCC CCTCGGCTACCAGCACCGCGATCGCAGCCTATCTCACCACCATCTCCAACGCTCCAGAGTTGCGCAAGGATCGTG TGTGGAAGCGTTTTGTTCGGGTCCGGACGGATGATCTAGAGAGTGTCCGTGTTGAAAGGGCCATTAAACGTGTTC GCTCTGATCTAGCGGCACATGTCGGTGGTCTTGCCAATAACCGTGCTAGTCTCATTGGGAGTGTGCACGCCGAGC ATGACAAAGAAAACGCTGATCGAGCAGAGGCTTCGCTGCCCACTCCTGAGGATGACGCTGTGGATTCAGCTGCGC CATCCGGAGGCAATCAGGGTGGTGCTGGGCAAGACCAGAAGGAGGGGGACGATGCTCCAGAAGCCCATGCCCGAG AGGCTACTGCTACTCCTGCTGATGCTCAGGCGGACAACCCTGCAGGAGCGTCAGATGCCGCGCCCGTTCAGGGTG ATCAGGCGACCTCGTCTGATGATCAAAAGCACCTTGTCGATGGAGAGGGCCGACCCGCCACCGGAACAGATGAGT CTACCGCTGCTGCACAAGGGCACACTGCCGATGTCGACCAAACTCAAGCTGCTGCTCCTTCCTCTTCGTCTGCTG CGACATCTTCCACTTCTGCAGCTGCTGCAGCTTCCCGTCTCCACCGTTCCCAGTCGTGCGAGCCTGACAAGTCTC ACAAGATGGCTAGGGCCTACGCACAGTCCACGACCCCGAGCCAGGACGGCCTCGATGGTGGGATGTCATCACAGA TCGAGACCGGCGACGAATCGTCCTTCTCCGCAGCCGTCACCCGCAAACGCAAGAAGAAGAAGAAGTCGTCAAAGA AAGTTACCATAGAAGACTTTGAGATGATTCGTGTGCTTGGGAAGGGTTGTGCTGGTAAAGTGTTGCTTGTTCGAC ACAAGACTGGCTCGGGCCTGTTCGCTCTCAAGGCTATCACGAAACGACACGTTTTGGCGCATCAAGAGCTGCAGC ATACGTTGACGGAACAGGCTGTTCTAAAACGGATGGCCGCGGAGTCGAAAGATCCCTTTGTCGTCAAGCTGTGGT GGAGTTTCCATGATAAAGAGAACCTCTTCTTGGTTATGGTATGCATTATGTTCTCCAGTTGACTCGTTTATTTAT GTTTTTTTAGGACTTCCACCCCGGAGGTGATCTTGCGACCCAACTGGCTCGTTGGGGCCGACTCAGCAGGGACCG AACCCGTTTCTACGCCGCTGAAATCGTCGAAGGTGTCGAAGGCCTCCACGCCGCCGGTGTCATCTACCGCGACCT CAAGCCCGAAAACATCCTCATCGCCGCGGACGGGCACATCGTTCTCACTGATTTCGGTCTCTCCAAGGAGTTCTC CCGTCCCCACTTGTCCGCTGCTTCTTCAGCTCCGATGACTCCGAGTGGAAGTCGTTCGAGCGATTTCTATTCGAG TGCGCCCGGGACCCCACATAGTGTGATGCCTCCGTGGATGAAGCCTGATAAGAATGGCGAAATGATGTACGGGTG GCCAGGTCAGCCGATTGGGAATCCGGATGTGACCACTACGTTCTGTGGGACGGCCGAGTACCTTGCGCCTGAGGT TATCCAAGGCTTGCCGTATTCGTACGAGGTGGATTGGTGGAGTTTTGGAACCATGTTGTATGAGATGTTGACTGG CATGGTGAGTGTCCTTTTCCTGTGGCTGTTTGTGGGCGAGCGCTGATAACCCGGGTCTGCAGACTCCATTCTATG CCAACAACCATTCCGACATGTATGTGAGGGTGTTGCAGGACGAGTTGACATTCCCGGATGAGAGGGTTATGGATC AGGATACCAAGAGCTTGATTCGTGGTGTAAGTCTCGATCCTTGACTCTGCGCGAGGCTTGTTCTAAATTATCCTC CATATAGCTCTTGCAAAAGAATCCCGACCTCCGAATTCGTGAACCTAGGATCAAGAAACACCCCTATTTCTCCAT GATGTGGGTTTTGAGCGTCCTCCAAGCAAGATGTGTACTGACGAATATGGTTTCCCAACAGCGACTGGTGTCACG TCTACTACAAGCGGTACATTCGTAAGTTCTTTCATTTCACCTCCTTTCGTTCCAATCTGACAATGATGGAATGTA GCTCCATATGTCCCTCCTGTCGACCGCACGGTTGCATACGACACCCAAAACTTCGATGAAACCTTCCTCGACATG GAACCTGTTTTGGACGAATACGTCGACGAGACTGGCCAAGCCACCGACACTGATGCCGAGCCTCAGACCGATACC GACCGGACTGACGGTGATACCAACACCACGCCTTCTCAATCGCGCAGTTCTTCCGTCCGTCCTGCTTCTCGAACG GCAAACGAGGAAGAAGACGACAGTGTGGACGTGTTCGATGGGTACTCGTTCAAGGGTCGACACTCGATACTTATG GACGATGACGACGAGGACGGTGACGAGGTTGACAGTGAAGAGGGTGAGGATGACGAGAGTATGGATCAGGATGGC AGCTCTTCGATGATGACTGGGGAGACCAAGTCGGAGGGCGATACGATTGATGAGGATGAGGTTCGTCAGCAACAA CGTGAGGAGGATGGTGCTACTTCAGAGTTGGAGCCCAAGACGCCTGAAGCAAGGCCTTCGGCTTTGCCTCCTGTC GACGACGCCGCACCACCAAAACCAGCGCAGCCTCAACCACCACAGCAAAGTCCACCGCCACCAACTCCGCCCGCC AAAACACGCGAACCTTCAAAGGTACACGAGCCTGTCGTCCCCAAGGATTCGTTGCCGAGCGCTTCCGAGGAAGAG CTGTTGGCCAATGCCAGTGTCGCTGTCGAGCTCGAAGAGCAACTCGAGTACCAGGCCAAGGAAGAAGAGGCGTAC AAGCGAGCTACCATCATCGCCGATCCGAATGGACGACCTGTCAATGGACGACACACACCACCTCCCAAAGCAAGT GGCAGCCGTGCTCAAGGACGTACCAAACGACGCGAGAAATCTGGTGTTCCGGCATTGGACAAGTATCTGTCTGAT GGTGGTGATGATGAGCCTGAGATGACTGAGCCTGAGCGGGATGAAGAAGATGAGGACTGGGATTTTGTCGAGGCT GGGGATGGGGAAGACAGGAACGGCGCCAAGGGAACGAGTTTGTGGGCTCGTGGTGTGGTGGATCGGTACAAACTC GCGGTGTTCCGCAAGGGGTCGACACCAAGTCAGCAGCGTTCGGTCTCCGGGATGTCAAAATCGTCTCAGGTATCG GAGGGTGGTACTGGAGCCGAGTCCCCTTCTCCTTCTAGCCGCCGTGGTCGAGGCACCGGCTTGAACTTCCGCAAA CATCCCCGCCAATTCCTCCGTCCCAAAGCCCCACCATCGAGTTATACGAATTCGACGAGGTCGTTCTCTGCGACT GCTTCGAGTTCGCTTTCCGCTGCTGCTTCAAAATCGATGTCGATGCCTACTGGAAGTGGATTGTTGACCCCCGTG AACACGTCCATGTTCTCGCCCTCCCTCAAGTCGAAGGAATCGGCAGTCTCGATGGACGCGAAGAGCATGTCATCG GATTACTCTGGGAACGTGATCTCGCCGACTACGCCATCCGCGACGAATGGTGGTCCTGAGCTTGGGTCGCCGCCA GCAGAGGGTGAGCAAGTGGAGAAGCCGCTCAAGAACAAGAAGTTGAAGAAGTACAAGAACAACGCGGAGAAGGTG TTTTCGTTGTTTTCTTCGAATTCGCCTAAACCTCCCCCCGCGTCGGCTACGTCGTAA |
| Length | 4332 |