CC1G_00840
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_00840 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N8W5 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_7:1199948..1202983 | Strand | - |
| Gene length (nt) | 3036 | Transcript length (nt) | 2663 |
| CDS length (nt) | 2340 | Protein length (aa) | 779 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Schizosaccharomyces pombe | shk1 |
| Aspergillus nidulans | AN2067_ste20 |
| Saccharomyces cerevisiae | YHL007C_STE20 |
| Neurospora crassa | stk-4 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB20838 | 72.7 | 0 | 1121 |
| Pleurotus eryngii ATCC 90797 | Pleery1_135859 | 68.9 | 0 | 1026 |
| Lentinula edodes NBRC 111202 | Lenedo1_1163071 | 68.7 | 0 | 1001 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_21726 | 68.7 | 0 | 1001 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_205902 | 76.2 | 0 | 999 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_118842 | 76.2 | 0 | 999 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_49456 | 65.4 | 2.47E-304 | 996 |
| Flammulina velutipes | Flave_chr06AA00793 | 66.2 | 4.436E-304 | 978 |
| Pleurotus ostreatus PC9 | PleosPC9_1_106676 | 65.6 | 7.273E-304 | 957 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1057192 | 72.2 | 3.074E-291 | 906 |
| Schizophyllum commune H4-8 | Schco3_2699248 | 64.5 | 2.17E-290 | 901 |
| Lentinula edodes B17 | Lened_B_1_1_14028 | 82.2 | 1.683E-229 | 724 |
| Auricularia subglabra | Aurde3_1_1314578 | 68.3 | 1.231E-200 | 641 |
| Grifola frondosa | Grifr_OBZ73737 | 52.8 | 1.213E-155 | 509 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 716 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd01093 | CRIB_PAK_like | IPR033923 | 235 | 280 |
| CDD | cd06614 | STKc_PAK | - | 504 | 757 |
| Pfam | PF00786 | P21-Rho-binding domain | IPR000095 | 236 | 294 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 505 | 756 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR036936 | CRIB domain superfamily |
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR000095 | CRIB domain |
| IPR033923 | p21 activated kinase binding domain |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004674 | protein serine/threonine kinase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K04409 |
EggNOG
| COG category | Description |
|---|---|
| T | P21-Rho-binding domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
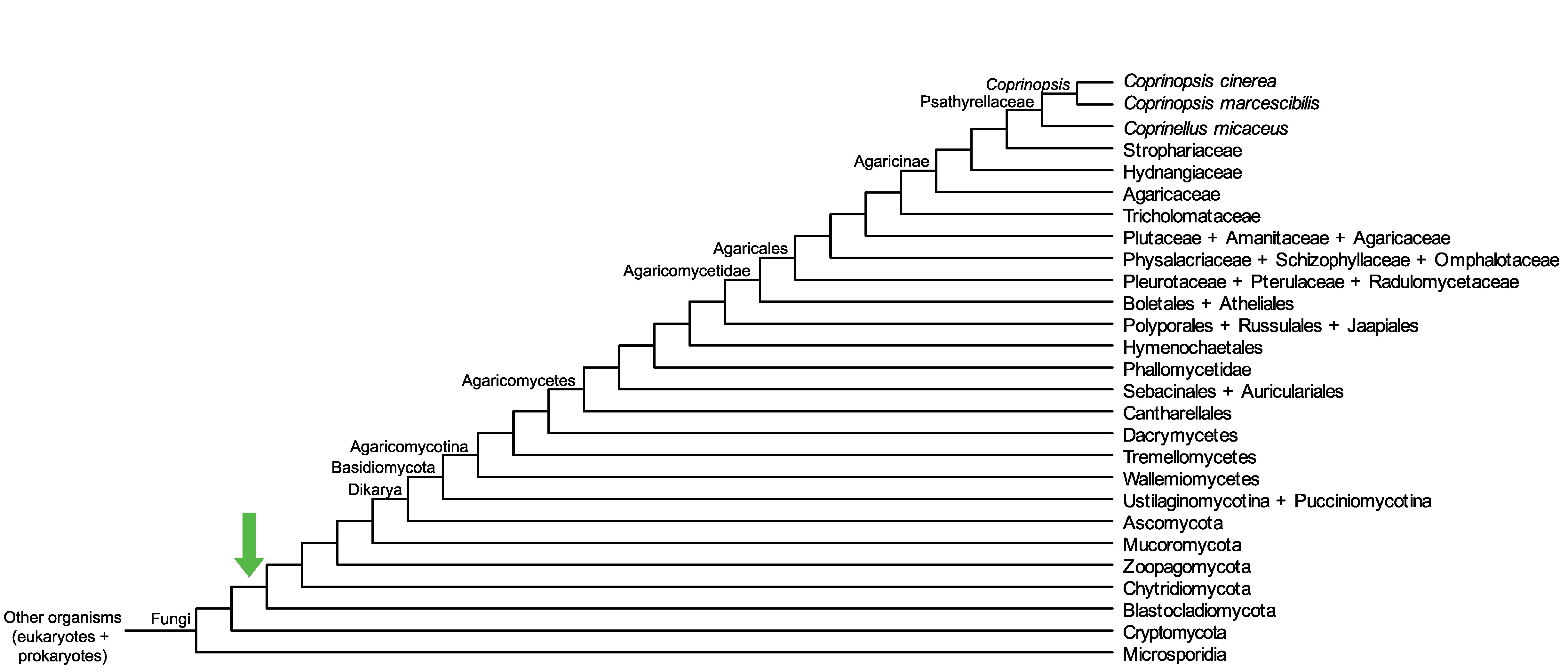
Conservation of CC1G_00840 across fungi.
Arrow shows the origin of gene family containing CC1G_00840.
Protein
| Sequence id | 716 |
|---|---|
| Sequence |
>716 MSSPHTAYNQRPKEPRRQSKITVEYHRPSRESIQEYNALLADANLHAAEAAKYIPSRAPPPPPTNSQRAKTPTDQ QRTRSSLLHKQNPRARNHSLSSQPHHDPFAANVNSQESSFVPPPSPMATHIYNKPPNGTSPPPRPSRANTANLTD IFPTQSQLAARRLSTPSAAPQVHEDGRFYADPNEAMPHNQNMNDYPLPPPPPPSAPLPARVRSGTKSKKGVLGFM SEVFNPTKRPEISTPYDPVHLTHVGFNSSTGEFTGLPKEWQQLLQESGISRHEQEKNPQAVMEIVKFYQEGHGDV WDKLGNVGAPTPEPYALAPENFTNPRSPPPPPKKQPSQASSVHTQHTQSTPTSVGPTSYRPAPTPPTAATPALDR STSQRTPAKPARPADIGRSNTTRDRRSPAPPANNGLAAGSKSYSKPSPGSSQTDLPLKQSAPGPPAHPPRDRADP RAQNHAPSPAASNLAKVAGVATPRRREKKVDKAKDEDIIKRLQQICTDADPTKLYRNLVKIGQGASGGVYTAYQV GTNMSVAIKQMDLDKQPKKDLIINEILVMRSSRHPNIVNYIDSFLYKNDLWVVMEYMEGGSLTDVVTANLMTEGQ IAAVSRETCQGLEHLHRHGVIHRDIKSDNVLLSMVGDIKLTDFGFCAQISEGHAKRTTMVGTPYWMAPEVVTRKE YGPKVDIWSLGIMAIEMIEGEPPYLNQNPLKALYLIATNGTPTIANPENLSPVFTDYLAKTLEVDAEKRPSATEL LQHPFFKLSEPLRTLAPLIKAAREIAKNK |
| Length | 779 |
Coding
| Sequence id | CC1G_00840T0 |
|---|---|
| Sequence |
>CC1G_00840T0 ATGTCCTCGCCTCACACCGCATATAACCAACGTCCCAAAGAGCCCCGACGCCAATCAAAAATCACCGTCGAGTAC CACAGGCCGTCCAGGGAATCAATCCAAGAATACAACGCTCTCCTCGCAGACGCAAATTTGCACGCGGCAGAAGCT GCAAAGTACATCCCCAGCAGGGCTCCTCCACCGCCCCCGACAAATTCACAGCGGGCCAAGACTCCCACAGACCAA CAACGCACTCGCTCTTCCCTCCTTCACAAGCAAAATCCCCGCGCTAGAAACCATTCCCTGTCCTCACAACCCCAC CACGACCCGTTTGCCGCCAACGTAAACTCTCAAGAGTCGTCCTTTGTCCCTCCGCCGTCTCCAATGGCCACACAC ATATATAACAAGCCACCCAACGGCACATCGCCGCCCCCTCGCCCATCAAGAGCAAACACCGCAAATCTCACCGAC ATCTTCCCGACCCAGTCCCAGCTCGCAGCTCGTCGTTTGTCCACTCCCTCCGCCGCTCCCCAGGTCCACGAGGAT GGCCGCTTTTACGCAGATCCAAACGAGGCAATGCCCCACAATCAGAACATGAACGATTACCCACTACCGCCTCCC CCGCCCCCAAGTGCTCCCCTGCCAGCGAGAGTACGCAGCGGCACCAAATCCAAGAAGGGGGTCCTCGGTTTCATG TCTGAAGTTTTCAATCCAACGAAACGTCCGGAAATCAGCACGCCTTACGATCCCGTCCATCTCACCCACGTCGGG TTCAACTCATCGACAGGAGAATTCACTGGCTTGCCCAAAGAATGGCAGCAATTGTTGCAGGAGAGCGGCATCTCA CGCCACGAGCAGGAGAAGAATCCTCAGGCAGTCATGGAGATCGTCAAGTTCTATCAGGAAGGCCACGGCGATGTG TGGGACAAGCTGGGTAACGTTGGAGCACCAACACCTGAACCCTATGCTCTAGCCCCAGAGAACTTTACCAACCCT CGATCCCCGCCTCCCCCGCCGAAGAAGCAGCCTTCGCAGGCTTCCTCGGTTCATACCCAACATACCCAATCAACC CCGACCTCAGTGGGACCAACATCTTATCGCCCAGCACCAACGCCTCCAACTGCAGCAACCCCTGCGCTTGATCGT TCCACCTCTCAACGGACGCCAGCGAAACCGGCACGTCCGGCTGATATTGGTCGCTCGAATACCACCCGCGATCGT CGATCTCCTGCTCCCCCAGCTAATAACGGTCTCGCGGCTGGATCCAAATCCTATTCGAAGCCATCACCTGGTTCA TCCCAGACAGACCTTCCTCTCAAGCAGTCCGCCCCTGGTCCCCCAGCTCATCCTCCCAGAGATCGCGCGGATCCC CGGGCCCAGAACCATGCTCCCAGCCCTGCCGCTTCCAACCTTGCCAAGGTCGCCGGCGTTGCTACTCCGCGCAGA AGAGAGAAGAAGGTCGACAAGGCGAAGGATGAAGATATCATCAAGCGGCTGCAGCAAATCTGTACTGATGCTGAT CCTACAAAACTCTACAGAAATCTCGTCAAGATTGGTCAAGGTGCTTCTGGAGGTGTATACACTGCCTATCAAGTG GGCACCAATATGTCCGTGGCTATCAAACAGATGGACTTGGACAAGCAGCCCAAGAAGGACCTTATTATCAACGAA ATTCTCGTCATGCGTTCCTCCCGTCATCCCAACATCGTCAACTACATCGACTCATTCCTGTACAAGAATGATCTC TGGGTCGTGATGGAGTACATGGAGGGCGGTTCCCTGACGGACGTCGTTACCGCCAACCTAATGACGGAAGGCCAA ATCGCCGCCGTCTCGCGCGAGACTTGTCAAGGTCTTGAGCACCTCCATCGACACGGTGTCATCCACCGTGATATC AAGAGCGACAACGTCTTGCTGAGCATGGTCGGTGATATTAAATTGACTGATTTCGGTTTCTGTGCACAAATTTCC GAGGGTCATGCCAAGCGAACAACGATGGTTGGTACGCCATATTGGATGGCACCCGAAGTGGTTACGCGCAAAGAG TACGGACCGAAGGTGGACATTTGGAGTTTGGGTATCATGGCTATTGAGATGATCGAAGGTGAACCGCCATATCTC AACCAGAACCCGCTCAAGGCCCTCTACTTGATTGCCACCAACGGCACGCCGACAATTGCCAACCCTGAAAATCTA TCGCCCGTCTTCACGGACTACTTGGCCAAGACCCTCGAGGTTGATGCTGAGAAACGGCCCTCGGCGACGGAACTG CTTCAGCATCCGTTCTTTAAACTGTCGGAACCTCTTCGAACGCTTGCTCCTCTAATCAAGGCTGCAAGGGAAATC GCGAAGAACAAG |
| Length | 2340 |
Transcript
| Sequence id | CC1G_00840T0 |
|---|---|
| Sequence |
>CC1G_00840T0 ATGTCCTCGCCTCACACCGCATATAACCAACGTCCCAAAGAGCCCCGACGCCAATCAAAAATCACCGTCGAGTAC CACAGGCCGTCCAGGGAATCAATCCAAGAATACAACGCTCTCCTCGCAGACGCAAATTTGCACGCGGCAGAAGCT GCAAAGTACATCCCCAGCAGGGCTCCTCCACCGCCCCCGACAAATTCACAGCGGGCCAAGACTCCCACAGACCAA CAACGCACTCGCTCTTCCCTCCTTCACAAGCAAAATCCCCGCGCTAGAAACCATTCCCTGTCCTCACAACCCCAC CACGACCCGTTTGCCGCCAACGTAAACTCTCAAGAGTCGTCCTTTGTCCCTCCGCCGTCTCCAATGGCCACACAC ATATATAACAAGCCACCCAACGGCACATCGCCGCCCCCTCGCCCATCAAGAGCAAACACCGCAAATCTCACCGAC ATCTTCCCGACCCAGTCCCAGCTCGCAGCTCGTCGTTTGTCCACTCCCTCCGCCGCTCCCCAGGTCCACGAGGAT GGCCGCTTTTACGCAGATCCAAACGAGGCAATGCCCCACAATCAGAACATGAACGATTACCCACTACCGCCTCCC CCGCCCCCAAGTGCTCCCCTGCCAGCGAGAGTACGCAGCGGCACCAAATCCAAGAAGGGGGTCCTCGGTTTCATG TCTGAAGTTTTCAATCCAACGAAACGTCCGGAAATCAGCACGCCTTACGATCCCGTCCATCTCACCCACGTCGGG TTCAACTCATCGACAGGAGAATTCACTGGCTTGCCCAAAGAATGGCAGCAATTGTTGCAGGAGAGCGGCATCTCA CGCCACGAGCAGGAGAAGAATCCTCAGGCAGTCATGGAGATCGTCAAGTTCTATCAGGAAGGCCACGGCGATGTG TGGGACAAGCTGGGTAACGTTGGAGCACCAACACCTGAACCCTATGCTCTAGCCCCAGAGAACTTTACCAACCCT CGATCCCCGCCTCCCCCGCCGAAGAAGCAGCCTTCGCAGGCTTCCTCGGTTCATACCCAACATACCCAATCAACC CCGACCTCAGTGGGACCAACATCTTATCGCCCAGCACCAACGCCTCCAACTGCAGCAACCCCTGCGCTTGATCGT TCCACCTCTCAACGGACGCCAGCGAAACCGGCACGTCCGGCTGATATTGGTCGCTCGAATACCACCCGCGATCGT CGATCTCCTGCTCCCCCAGCTAATAACGGTCTCGCGGCTGGATCCAAATCCTATTCGAAGCCATCACCTGGTTCA TCCCAGACAGACCTTCCTCTCAAGCAGTCCGCCCCTGGTCCCCCAGCTCATCCTCCCAGAGATCGCGCGGATCCC CGGGCCCAGAACCATGCTCCCAGCCCTGCCGCTTCCAACCTTGCCAAGGTCGCCGGCGTTGCTACTCCGCGCAGA AGAGAGAAGAAGGTCGACAAGGCGAAGGATGAAGATATCATCAAGCGGCTGCAGCAAATCTGTACTGATGCTGAT CCTACAAAACTCTACAGAAATCTCGTCAAGATTGGTCAAGGTGCTTCTGGAGGTGTATACACTGCCTATCAAGTG GGCACCAATATGTCCGTGGCTATCAAACAGATGGACTTGGACAAGCAGCCCAAGAAGGACCTTATTATCAACGAA ATTCTCGTCATGCGTTCCTCCCGTCATCCCAACATCGTCAACTACATCGACTCATTCCTGTACAAGAATGATCTC TGGGTCGTGATGGAGTACATGGAGGGCGGTTCCCTGACGGACGTCGTTACCGCCAACCTAATGACGGAAGGCCAA ATCGCCGCCGTCTCGCGCGAGACTTGTCAAGGTCTTGAGCACCTCCATCGACACGGTGTCATCCACCGTGATATC AAGAGCGACAACGTCTTGCTGAGCATGGTCGGTGATATTAAATTGACTGATTTCGGTTTCTGTGCACAAATTTCC GAGGGTCATGCCAAGCGAACAACGATGGTTGGTACGCCATATTGGATGGCACCCGAAGTGGTTACGCGCAAAGAG TACGGACCGAAGGTGGACATTTGGAGTTTGGGTATCATGGCTATTGAGATGATCGAAGGTGAACCGCCATATCTC AACCAGAACCCGCTCAAGGCCCTCTACTTGATTGCCACCAACGGCACGCCGACAATTGCCAACCCTGAAAATCTA TCGCCCGTCTTCACGGACTACTTGGCCAAGACCCTCGAGGTTGATGCTGAGAAACGGCCCTCGGCGACGGAACTG CTTCAGCATCCGTTCTTTAAACTGTCGGAACCTCTTCGAACGCTTGCTCCTCTAATCAAGGCTGCAAGGGAAATC GCGAAGAACAAGTAAAGGACAATTTTCTCTGTGGACAGCACCTTCCATTTTTCTCTCTTTCTTCTTCTCTTTTTT CTCTTCTCTCATTAAATCTGTGTTTGTTCGCGATCGATGATATATCCCCCTCCTCTCCAATTCCCGGTCCGAGTC TCATAGTCCGCATCTAATACCTGGTTGTGAAAACCATTTCTTTTGGTATCTTCTTATGCATTGATGGTTCTCGGT CAACTATATCTCCCTTTCTTCACCCTTCCTATTACCTCCCACTTCAATCTCCTTCGTCGACCAAGATCGTCTGTT TCACCTTACATATATGCCCTTCGTCCTTTCTTTCGGTC |
| Length | 2663 |
Gene
| Sequence id | CC1G_00840T0 |
|---|---|
| Sequence |
>CC1G_00840T0 ATGTCCTCGCCTCACACCGCATATAACCAACGTCCCAAAGAGCCCCGACGCCAATCAAAAATCACCGTCGAGTAC CACAGGCCGTCCAGGGAATCAATCCAAGAATACAACGCTCTCCTCGCAGACGCAAATTTGCACGCGGCAGAAGCT GCAAAGTACATCCCCAGCAGGGCTCCTCCACCGCCCCCGACAAATTCACAGCGGGCCAAGACTCCCACAGACCAA CAACGCACTCGCTCTTCCCTCCTTCACAAGCAAAATCCCCGCGCTAGAAACCATTCCCTGTCCTCACAACCCCAC CACGACCCGTTTGCCGCCAACGTAAACTCTCAAGAGTCGTCCTTTGTCCCTCCGCCGTCTCCAATGGCCACACAC ATATATAACAAGCCACCCAACGGCACATCGCCGCCCCCTCGCCCATCAAGAGCAAACACCGCAAATCTCACCGAC ATCTTCCCGACCCAGTCCCAGCTCGCAGCTCGTCGTTTGTCCACTCCCTCCGCCGCTCCCCAGGTCCACGAGGAT GGCCGCTTTTACGCAGATCCAAACGAGGCAATGCCCCACAATCAGAACATGAACGATTACCCACTACCGCCTCCC CCGCCCCCAAGTGCTCCCCTGCCAGCGAGAGTACGCAGCGGCACCAAATCCAAGAAGGGGGTCCTCGGTTTCATG TCTGAAGTTTTCAATCCAACGAAACGTCCGGAAATCAGCACGCCTTACGATCCCGTCCATCTCACCCACGTCGGG TTCAACTCATCGACAGGAGAATTCACTGGCTTGCCCAAAGAATGGCAGCAATTGTTGCAGGAGAGCGGCATCTCA CGCCACGAGCAGGAGAAGAATCCTCAGGCAGTCATGGAGATCGTCAAGTTCTATCAGGAAGGCCACGGCGATGTG TGGGACAAGCTGGGTAACGTTGGAGCACCAACACCTGAACCCTATGCTCTAGCCCCAGAGAACTTTACCAACCCT GTCAGTCCCATTTCCGTAACTATATGCCACATGATAATTAACATCTATTGTTTCGCAGCGATCCCCGCCTCCCCC GCCGAAGAAGCAGCCTTCGCAGGCTTCCTCGGTTCATACCCAACATACCCAATCAACCCCGACCTCAGTGGGACC AACATCTTATCGCCCAGCACCAACGCCTCCAACTGCAGCAACCCCTGCGCTTGATCGTTCCACCTCTCAACGGAC GCCAGCGAAACCGGCACGTCCGGCTGATATTGGTCGCTCGAATACCACCCGCGATCGTCGATCTCCTGCTCCCCC AGCTAATAACGGTCTCGCGGCTGGATCCAAATCCTATTCGAAGCCATCACCTGGTTCATCCCAGACAGACCTTCC TCTCAAGCAGTCCGCCCCTGGTCCCCCAGCTCATCCTCCCAGAGATCGCGCGGATCCCCGGGCCCAGAACCATGC TCCCAGCCCTGCCGCTTCCAACCTTGCCAAGGTCGCCGGCGTTGCTACTCCGCGCAGAAGAGAGAAGAAGGTCGA CAAGGCGAAGGATGAAGATATCATCAAGCGGCTGCAGCAAATCTGTACTGATGCTGATCCTACAAAACTCTACAG AAATCTCGTCAAGATTGGTCAAGGGTGAGGATCATCGATATGCTATGCTTAATCCAAGTCTTCTGAACTCGCAAA CAATAGTGCTTCTGGAGGTGTATACACTGCCTATCAAGTGGGCACCAATATGTCCGTGGCTATCAAACAGATGGA CTTGGACAAGCAGCCCAAGAAGGACCTTATTATCAACGAAATTCTCGTCATGCGTTCCTCCCGTCATCCCAACAT CGTCAACTACATCGACTCATTCCTGTACAAGAATGATCTCTGGGTCGTGATGGAGTACATGGAGGGCGGTTCCCT GACGGACGTCGTTACCGCCAACCTAATGACGGAAGGCCAAATCGCCGCCGTCTCGCGCGAGACTTGTCAAGGTCT TGAGCACCTCCATCGACACGGTGTCATCCACCGTGATATCAAGAGCGACAACGTCTTGCTGAGCATGGTCGGTGA TATTAAATTGAGTAAGTGTGTCTACACCCGTGATGATCCTTGTTTTCTGACCATTGGATATTTTTTGCTTCGCCT CGTCTTCTTCGGCATTTGCCTGGACCACCCTTTCTAGCTGATTTCGGTTTCTGTGCACAAATTTCCGAGGGTCAT GCCAAGCGAACAACGATGGTTGGTACGCCATATTGGATGGCACCCGAAGTGGTTACGCGCAAAGAGTACGGACCG AAGGTGGACATTTGGAGTTTGGGTATCATGGCTATTGGTGAGTGTTGTCAATCTAATTTTCCGATCTCCCCGTGT TTTGGCTGACCAGGGTTTGTTGGGTGAACAGAGATGATCGAAGGTGAACCGCCATATCTCAACCAGAACCCGCTC AAGGCCCTCTACTTGATTGCCACCAACGGCACGCCGACAATTGCCAACCCTGAAAATCTATCGCCCGTCTTCACG GACTACTTGGCCAAGACCCTCGAGGTTGATGCTGAGAAACGGCCCTCGGCGACGGAACTGCTTCAGGTGCGCATT TTTTTCATTAACTTTGGTCCACATGGCCAAGGATTGCACTGCCACGACGTTGGATACTGATGATTGATTGGATTT TTAGCATCCGTTCTTTAAACTGTCGGAACCTCTTCGAACGCTTGCTCCTCTAATCAAGGCTGCAAGGGAAATCGC GAAGAACAAGTAAAGGACAATTTTCTCTGTGGACAGCACCTTCCATTTTTCTCTCTTTCTTCTTCTCTTTTTTCT CTTCTCTCATTAAATCTGTGTTTGTTCGCGATCGATGATATATCCCCCTCCTCTCCAATTCCCGGTCCGAGTCTC ATAGTCCGCATCTAATACCTGGTTGTGAAAACCATTTCTTTTGGTATCTTCTTATGCATTGATGGTTCTCGGTCA ACTATATCTCCCTTTCTTCACCCTTCCTATTACCTCCCACTTCAATCTCCTTCGTCGACCAAGATCGTCTGTTTC ACCTTACATATATGCCCTTCGTCCTTTCTTTCGGTC |
| Length | 3036 |