CC1G_01353
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_01353 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NYJ2 | Functional description | Other/Haspin protein kinase |
| Location | Chr_5:2244786..2247499 | Strand | - |
| Gene length (nt) | 2714 | Transcript length (nt) | 2508 |
| CDS length (nt) | 2508 | Protein length (aa) | 835 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7260064 | 53.9 | 9.27E-270 | 844 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB19923 | 52.4 | 8.171E-263 | 824 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1055497 | 47.9 | 2.656E-221 | 703 |
| Pleurotus ostreatus PC9 | PleosPC9_1_47322 | 47.8 | 5.736E-221 | 702 |
| Schizophyllum commune H4-8 | Schco3_2623257 | 46 | 2.444E-215 | 686 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1442943 | 46.2 | 2.329E-214 | 683 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_188624 | 44.3 | 2.11E-211 | 674 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_119933 | 43.8 | 5.198E-210 | 670 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_18801 | 45.9 | 1.082E-202 | 649 |
| Lentinula edodes NBRC 111202 | Lenedo1_1097137 | 45.8 | 1.166E-201 | 646 |
| Lentinula edodes B17 | Lened_B_1_1_11470 | 45.3 | 2.839E-196 | 630 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_64662 | 43.7 | 1.945E-192 | 619 |
| Flammulina velutipes | Flave_chr11AA00876 | 42.7 | 3.929E-181 | 586 |
| Grifola frondosa | Grifr_OBZ76602 | 44.2 | 3.192E-157 | 516 |
| Auricularia subglabra | Aurde3_1_1237497 | 51 | 9.08E-75 | 271 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1167 |
| Description | Other/Haspin protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF12330 | Haspin like kinase domain | - | 453 | 736 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
| IPR024604 | Serine/threonine-protein kinase haspin, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| No records | ||
KEGG
| KEGG Orthology |
|---|
| K16315 |
EggNOG
| COG category | Description |
|---|---|
| D | Domain of unknown function |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
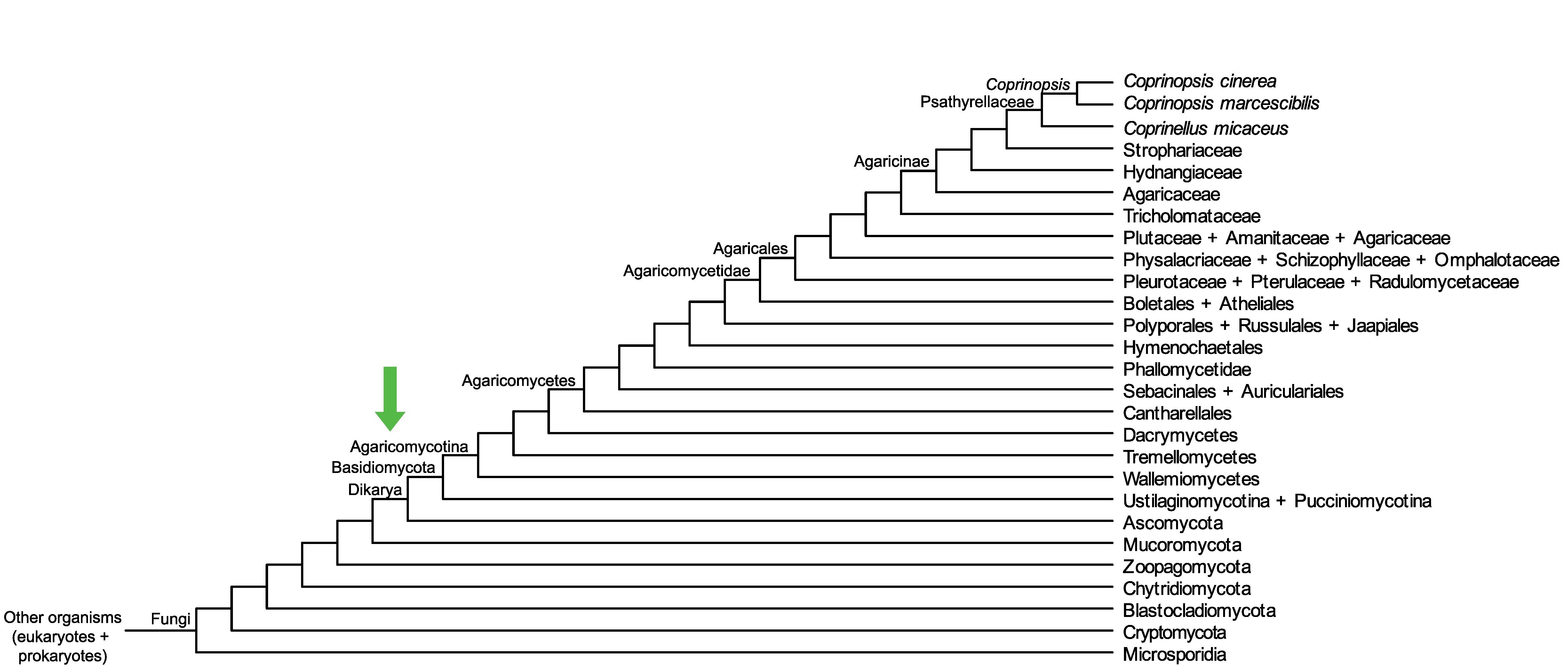
Conservation of CC1G_01353 across fungi.
Arrow shows the origin of gene family containing CC1G_01353.
Protein
| Sequence id | 1167 |
|---|---|
| Sequence |
>1167 MLSAQTKQVNAYGKRARRVVNVTASSSGPAPGGIISIFDDLPPAPALMPLASRMKKRENIAPKPKSQLSPKPVGG KQRKRRLSPVLTPVKKVPRVAQLIKESRTQPLDNKLDGGVRQANAKVNLTTEAEASPFDASSFSSPRRPFSSFSV NVPGSPALPASLRASKSRVPSAKSIPFKLAKPSSPVVNMDIIVLDDDGQVVRKERRSSKTGVETNPVKDVPKKRA RPSRAAASKAAILVESDSDPDVARQPAQPKRTQRQKALVVVSDVSDSETENAPTAPSPAPPKTNRLSKLPTVEVV IPPAPYPIRPLARPSPPAGTQHRAATPTKPKPAPPTARPGPAFQLPPSPIPRARPLTPIKGMRRNGLFDPPSPPS PSLTDFDLSLDLSELNIDAECVDAHDVEPNIPAYLLPLLEECHQEECGPHDFSSFIDSFPFDPILRDGRSDAPSE LEFRKIGEASYSEVFGIADVVLKVIPLRDESAPGAISTELEEGPPPSDAQDVRKEIIVTRAMGEVYGGFVKFLKT YIVRGKYPELLLNLWDEYNETKGSESMRPDTFKLSQVYAIIVLPNGGPDLEAYSFNNPTKQGWKQACSIFWQVAK SLAHAEHLVSFEHRDLHWGQILVKNVPSQKPKLQPINVNGVKSRKQRLMMDDKSHGVQTTIIDLGLSRMDAGDGS GGYRVQWTPFDEEVFMGEGEYQFDVYRMMRDHTGDDWEGYHPLTNVMWLHYLATKLLYGKGLKAPVVRKPKSGSE APLATSSDAFSERDCYESLLDIEQWLGSFLTGAFPAQSKAIAKTKGRRKTIALSSCLALRDGPSCAGEVVAYGVK KGWVSATKLF |
| Length | 835 |
Coding
| Sequence id | CC1G_01353T0 |
|---|---|
| Sequence |
>CC1G_01353T0 ATGCTCAGCGCACAGACAAAGCAGGTCAATGCATATGGCAAGCGGGCCAGGCGCGTTGTGAACGTTACCGCCAGC TCAAGTGGGCCAGCACCTGGCGGGATCATCAGCATATTCGACGATCTTCCGCCAGCACCCGCATTGATGCCTCTA GCATCGCGCATGAAGAAGCGGGAAAACATCGCTCCTAAACCAAAATCCCAACTTTCCCCCAAACCTGTCGGCGGA AAGCAGCGCAAGAGACGACTCTCGCCGGTCCTCACGCCTGTGAAGAAAGTACCACGAGTCGCCCAGCTGATCAAG GAGTCTCGAACTCAGCCCTTAGACAACAAATTGGACGGTGGCGTACGGCAAGCCAATGCTAAAGTTAATCTGACA ACGGAAGCAGAGGCTTCGCCGTTTGATGCAAGTTCATTTTCGTCTCCTCGCCGTCCTTTCTCAAGTTTCTCGGTC AATGTTCCCGGGTCTCCTGCTCTTCCTGCTAGCTTGCGCGCCTCCAAGTCACGCGTTCCCTCGGCCAAGAGCATT CCGTTTAAGCTGGCGAAGCCTAGCAGTCCGGTCGTAAACATGGACATTATCGTCCTCGACGATGATGGTCAAGTC GTTCGCAAAGAGAGAAGGTCCTCCAAGACAGGCGTTGAAACTAACCCTGTGAAGGATGTCCCGAAGAAGAGAGCT CGTCCATCCAGAGCAGCTGCCTCCAAAGCAGCAATCCTCGTAGAGTCCGACAGTGACCCTGATGTGGCTCGCCAA CCTGCCCAACCTAAACGCACACAACGGCAGAAAGCACTAGTTGTCGTCTCTGACGTGTCAGACTCAGAGACAGAA AATGCCCCAACTGCACCTTCCCCTGCCCCGCCGAAAACCAATCGACTCTCGAAGCTTCCTACGGTGGAAGTAGTG ATACCCCCCGCACCTTATCCTATACGACCACTCGCGAGGCCCTCTCCACCAGCGGGTACGCAACATCGGGCTGCA ACACCGACGAAACCCAAACCCGCCCCACCTACTGCACGGCCAGGGCCCGCTTTCCAGCTACCACCCTCCCCCATA CCGAGAGCTCGCCCGCTAACCCCCATCAAGGGCATGCGGCGGAATGGCCTATTTGATCCACCTTCTCCCCCATCC CCTTCACTCACAGACTTTGACTTGTCTCTGGATCTCTCCGAGCTCAATATCGACGCCGAATGTGTTGATGCTCAC GATGTTGAACCAAACATTCCCGCTTACCTGCTTCCACTCCTGGAAGAGTGTCATCAAGAGGAATGCGGACCTCAT GACTTTTCCTCCTTCATTGACAGCTTTCCGTTCGATCCTATTCTCCGCGATGGGCGGTCTGATGCGCCGAGCGAG TTGGAATTCAGGAAGATTGGGGAGGCTAGCTACTCGGAAGTCTTTGGTATAGCCGATGTCGTCCTCAAGGTCATT CCGTTGCGCGACGAGTCTGCCCCAGGAGCAATCTCAACGGAGCTGGAGGAAGGACCTCCTCCAAGTGATGCGCAG GACGTCCGCAAGGAAATCATCGTCACCAGGGCCATGGGCGAAGTCTACGGTGGATTTGTGAAATTCTTGAAGACT TATATCGTCAGGGGAAAGTATCCGGAACTTCTTCTCAACCTTTGGGATGAATATAACGAAACGAAGGGATCAGAG AGTATGCGACCAGACACGTTCAAACTCTCTCAAGTCTACGCTATCATCGTACTGCCCAACGGTGGCCCTGACCTC GAGGCTTACTCGTTTAACAACCCTACCAAACAGGGATGGAAGCAAGCCTGCAGCATCTTCTGGCAAGTGGCCAAA TCACTCGCTCACGCGGAGCACCTGGTCTCGTTTGAGCATCGCGACCTGCACTGGGGTCAGATACTGGTGAAAAAT GTCCCGTCACAGAAGCCCAAACTCCAACCTATCAACGTGAATGGAGTCAAATCTAGGAAGCAACGCCTCATGATG GACGACAAGTCCCATGGGGTCCAAACAACCATCATTGACTTGGGCCTCTCGCGCATGGACGCTGGAGATGGATCA GGTGGATATCGTGTGCAATGGACACCATTCGACGAGGAGGTTTTCATGGGCGAAGGCGAATACCAGTTCGATGTT TATCGGATGATGAGGGACCACACTGGAGATGATTGGGAAGGTTACCACCCTTTGACCAATGTGATGTGGCTACAC TACCTTGCAACCAAACTTCTCTATGGCAAAGGGCTCAAGGCGCCGGTGGTGCGCAAACCGAAATCCGGGTCTGAA GCGCCTCTGGCAACCTCCTCCGACGCTTTCTCAGAAAGGGACTGCTACGAGTCGTTGCTTGATATTGAGCAATGG TTGGGAAGTTTCTTGACCGGGGCATTCCCTGCACAGTCGAAGGCGATTGCCAAAACCAAGGGAAGGCGTAAGACA ATTGCCCTTTCCAGCTGTCTTGCCTTGCGCGATGGGCCTTCCTGTGCTGGCGAAGTCGTTGCCTACGGTGTCAAA AAGGGCTGGGTCAGTGCTACGAAATTATTC |
| Length | 2508 |
Transcript
| Sequence id | CC1G_01353T0 |
|---|---|
| Sequence |
>CC1G_01353T0 ATGCTCAGCGCACAGACAAAGCAGGTCAATGCATATGGCAAGCGGGCCAGGCGCGTTGTGAACGTTACCGCCAGC TCAAGTGGGCCAGCACCTGGCGGGATCATCAGCATATTCGACGATCTTCCGCCAGCACCCGCATTGATGCCTCTA GCATCGCGCATGAAGAAGCGGGAAAACATCGCTCCTAAACCAAAATCCCAACTTTCCCCCAAACCTGTCGGCGGA AAGCAGCGCAAGAGACGACTCTCGCCGGTCCTCACGCCTGTGAAGAAAGTACCACGAGTCGCCCAGCTGATCAAG GAGTCTCGAACTCAGCCCTTAGACAACAAATTGGACGGTGGCGTACGGCAAGCCAATGCTAAAGTTAATCTGACA ACGGAAGCAGAGGCTTCGCCGTTTGATGCAAGTTCATTTTCGTCTCCTCGCCGTCCTTTCTCAAGTTTCTCGGTC AATGTTCCCGGGTCTCCTGCTCTTCCTGCTAGCTTGCGCGCCTCCAAGTCACGCGTTCCCTCGGCCAAGAGCATT CCGTTTAAGCTGGCGAAGCCTAGCAGTCCGGTCGTAAACATGGACATTATCGTCCTCGACGATGATGGTCAAGTC GTTCGCAAAGAGAGAAGGTCCTCCAAGACAGGCGTTGAAACTAACCCTGTGAAGGATGTCCCGAAGAAGAGAGCT CGTCCATCCAGAGCAGCTGCCTCCAAAGCAGCAATCCTCGTAGAGTCCGACAGTGACCCTGATGTGGCTCGCCAA CCTGCCCAACCTAAACGCACACAACGGCAGAAAGCACTAGTTGTCGTCTCTGACGTGTCAGACTCAGAGACAGAA AATGCCCCAACTGCACCTTCCCCTGCCCCGCCGAAAACCAATCGACTCTCGAAGCTTCCTACGGTGGAAGTAGTG ATACCCCCCGCACCTTATCCTATACGACCACTCGCGAGGCCCTCTCCACCAGCGGGTACGCAACATCGGGCTGCA ACACCGACGAAACCCAAACCCGCCCCACCTACTGCACGGCCAGGGCCCGCTTTCCAGCTACCACCCTCCCCCATA CCGAGAGCTCGCCCGCTAACCCCCATCAAGGGCATGCGGCGGAATGGCCTATTTGATCCACCTTCTCCCCCATCC CCTTCACTCACAGACTTTGACTTGTCTCTGGATCTCTCCGAGCTCAATATCGACGCCGAATGTGTTGATGCTCAC GATGTTGAACCAAACATTCCCGCTTACCTGCTTCCACTCCTGGAAGAGTGTCATCAAGAGGAATGCGGACCTCAT GACTTTTCCTCCTTCATTGACAGCTTTCCGTTCGATCCTATTCTCCGCGATGGGCGGTCTGATGCGCCGAGCGAG TTGGAATTCAGGAAGATTGGGGAGGCTAGCTACTCGGAAGTCTTTGGTATAGCCGATGTCGTCCTCAAGGTCATT CCGTTGCGCGACGAGTCTGCCCCAGGAGCAATCTCAACGGAGCTGGAGGAAGGACCTCCTCCAAGTGATGCGCAG GACGTCCGCAAGGAAATCATCGTCACCAGGGCCATGGGCGAAGTCTACGGTGGATTTGTGAAATTCTTGAAGACT TATATCGTCAGGGGAAAGTATCCGGAACTTCTTCTCAACCTTTGGGATGAATATAACGAAACGAAGGGATCAGAG AGTATGCGACCAGACACGTTCAAACTCTCTCAAGTCTACGCTATCATCGTACTGCCCAACGGTGGCCCTGACCTC GAGGCTTACTCGTTTAACAACCCTACCAAACAGGGATGGAAGCAAGCCTGCAGCATCTTCTGGCAAGTGGCCAAA TCACTCGCTCACGCGGAGCACCTGGTCTCGTTTGAGCATCGCGACCTGCACTGGGGTCAGATACTGGTGAAAAAT GTCCCGTCACAGAAGCCCAAACTCCAACCTATCAACGTGAATGGAGTCAAATCTAGGAAGCAACGCCTCATGATG GACGACAAGTCCCATGGGGTCCAAACAACCATCATTGACTTGGGCCTCTCGCGCATGGACGCTGGAGATGGATCA GGTGGATATCGTGTGCAATGGACACCATTCGACGAGGAGGTTTTCATGGGCGAAGGCGAATACCAGTTCGATGTT TATCGGATGATGAGGGACCACACTGGAGATGATTGGGAAGGTTACCACCCTTTGACCAATGTGATGTGGCTACAC TACCTTGCAACCAAACTTCTCTATGGCAAAGGGCTCAAGGCGCCGGTGGTGCGCAAACCGAAATCCGGGTCTGAA GCGCCTCTGGCAACCTCCTCCGACGCTTTCTCAGAAAGGGACTGCTACGAGTCGTTGCTTGATATTGAGCAATGG TTGGGAAGTTTCTTGACCGGGGCATTCCCTGCACAGTCGAAGGCGATTGCCAAAACCAAGGGAAGGCGTAAGACA ATTGCCCTTTCCAGCTGTCTTGCCTTGCGCGATGGGCCTTCCTGTGCTGGCGAAGTCGTTGCCTACGGTGTCAAA AAGGGCTGGGTCAGTGCTACGAAATTATTCTAA |
| Length | 2508 |
Gene
| Sequence id | CC1G_01353T0 |
|---|---|
| Sequence |
>CC1G_01353T0 ATGCTCAGCGCACAGACAAAGCAGGTCAATGCATATGGCAAGCGGGCCAGGCGCGTTGTGAACGTTACCGCCAGC TCAAGTGGGCCAGCACCTGGCGGGATCATCAGCATATTCGACGATCTTCCGCCAGCACCCGCATTGATGCCTCTA GCATCGCGCATGAAGAAGCGGGAAAACATCGCTCCTAAACCAAAATCCCAACTTTCCCCCAAACCTGTCGGCGGA AAGCAGCGCAAGAGACGACTCTCGCCGGTCCTCACGCCTGTGAAGAAAGTACCACGAGTCGCCCAGCTGATCAAG GAGTCTCGAACTCAGCCCTTAGACAACAAATTGGACGGTGGCGTACGGCAAGCCAATGCTAAAGTTAATCTGACA ACGGAAGCAGAGGCTTCGCCGTTTGATGCAAGTTCATTTTCGTCTCCTCGCCGTCCTTTCTCAAGTTTCTCGGTC AATGTTCCCGGGTCTCCTGCTCTTCCTGCTAGCTTGCGCGCCTCCAAGTCACGCGTTCCCTCGGCCAAGAGCATT CCGTTTAAGCTGGCGAAGCCTAGCAGTCCGGTCGTAAACATGGACATTATCGTCCTCGACGATGATGGTCAAGTC GTTCGCAAAGAGAGAAGGTCCTCCAAGACAGGCGTTGAAACTAACCCTGTGAAGGATGTCCCGAAGAAGAGAGCT CGTCCATCCAGAGCAGCTGCCTCCAAAGCAGCAATCCTCGTAGAGTCCGACAGTGACCCTGATGTGGCTCGCCAA CCTGCCCAACCTAAACGCACACAACGGCAGAAAGCACTAGTTGTCGTCTCTGACGTGTCAGACTCAGAGACAGAA AATGCCCCAACTGCACCTTCCCCTGCCCCGCCGAAAACCAATCGACTCTCGAAGCTTCCTACGGTGGAAGTAGTG ATACCCCCCGCACCTTATCCTATACGACCACTCGCGAGGCCCTCTCCACCAGCGGGTACGCAACATCGGGCTGCA ACACCGACGAAACCCAAACCCGCCCCACCTACTGCACGGCCAGGGCCCGCTTTCCAGCTACCACCCTCCCCCATA CCGAGAGCTCGCCCGCTAACCCCCATCAAGGGCATGCGGCGGAATGGCCTATTTGATCCACCTTCTCCCCCATCC CCTTCACTCACAGACTTTGACTTGTCTCTGGATCTCTCCGAGCTCAATATCGACGCCGAATGTGTTGATGCTCAC GATGTTGAACCAAACATTCCCGCTTACCTGCTTCCACTCCTGGAAGAGTGTCATCAAGAGGAATGCGGACCTCAT GACTTTTCCTCCTTCATTGACAGCTTTCCGTTCGATCCTATTCTCCGCGATGGGCGGTCTGATGCGCCGAGCGAG TTGGAATTCAGGAAGATTGGGGAGGCTAGCTACTCGGAAGTCTTTGGTATAGCCGATGTCGTCCTCAAGGTCATT CCGTTGCGCGACGAGTCTGCCCCAGGAGCAATCTCAACGGAGCTGGAGGAAGGACCTCCTCCAAGTGATGCGCAG GACGTCCGCAAGGAAATCATCGTCACCAGGGCCATGGGCGAAGTCTACGGTGGATTTGTGAAATTCTTGAAGACT TATATCGTCAGGGGAAAGTATCCGGAACTTCTTCTCAACCTTTGGGATGAATATAACGAAACGAAGGGATCAGAG AGTATGCGACCAGGTACGGGTAGTCTTTTCGGAAAGGTGGAATTCACTAAGGTCCCCTTGCCAGACACGTTCAAA CTCTCTCAAGTCTACGCTATCATCGTACTGCCCAACGGTGGCCCTGACCTCGAGGCTTACTCGTTTAACAACCCT ACCAAACAGGGATGGAAGCAAGCCTGCAGCATCTTCTGGCAAGTGGCCAAATCACTCGCTCACGCGGAGCACCTG GTCTCGTTTGAGGTACGACCTGGCACGGCTTCCTGCATTCTCGTTCTGACTAGTCTTTCTAATAGCATCGCGACC TGCACTGGGGTCAGATACTGGTGAAAAATGTCCCGTCACAGAAGCCCAAACTCCAACCTATCAACGTGAATGGAG TCAAATCTAGGAAGCAACGCCTCATGATGGACGACAAGTCCCATGGGGTCCAAACAACCATCATTGACTTGGGCC TCTCGCGCATGGACGCTGGAGATGGATCAGGTGGATATCGTGTGCAATGGACACCATTCGACGAGGAGGTTTTCA TGGGCGAAGGTAAGCTTCCTCCGACTCTCGCCAAGGCAGTCACTGAAAGATGAATGGTAGGCGAATACCAGTTCG ATGTTTATCGGATGATGAGGGACCACACTGGAGATGATTGGGAAGGTTACCACCCTTTGACCAATGTGATGGTAG GTACTTACTTTCTGGTCGTCGTGATTTATGACCAACTTTCTTGTTAGTGGCTACACTACCTTGCAACCAAACTTC TCTATGGCAAAGGGCTCAAGGCGCCGGTGGTGCGCAAACCGAAATCCGGGTCTGAAGCGCCTCTGGCAACCTCCT CCGACGCTTTCTCAGAAAGGGACTGCTACGAGTCGTTGCTTGATATTGAGCAATGGTTGGGAAGTTTCTTGACCG GGGCATTCCCTGCACAGTCGAAGGCGATTGCCAAAACCAAGGGAAGGCGTAAGACAATTGCCCTTTCCAGCTGTC TTGCCTTGCGCGATGGGCCTTCCTGTGCTGGCGAAGTCGTTGCCTACGGTGTCAAAAAGGGCTGGGTCAGTGCTA CGAAATTATTCTAA |
| Length | 2714 |