CC1G_01961
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_01961 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N641 | Functional description | Other/WEE protein kinase |
| Location | Chr_3:1681094..1684856 | Strand | + |
| Gene length (nt) | 3763 | Transcript length (nt) | 3333 |
| CDS length (nt) | 3333 | Protein length (aa) | 1110 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7259040 | 52.2 | 0 | 1062 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB25234 | 50.7 | 0 | 1032 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_118110 | 48.1 | 4.031E-292 | 955 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_56372 | 49.7 | 1.227E-291 | 942 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1438533 | 45.3 | 8.18E-274 | 870 |
| Pleurotus ostreatus PC9 | PleosPC9_1_94551 | 45.9 | 8.839E-270 | 858 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1076762 | 45.8 | 1.988E-269 | 857 |
| Flammulina velutipes | Flave_chr07AA00627 | 45.8 | 1.43E-263 | 840 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_16438 | 45.1 | 8.998E-260 | 829 |
| Lentinula edodes NBRC 111202 | Lenedo1_296217 | 44.8 | 4.388E-259 | 827 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_127149 | 40.6 | 9.064E-232 | 747 |
| Lentinula edodes B17 | Lened_B_1_1_2612 | 49.1 | 3.787E-216 | 701 |
| Schizophyllum commune H4-8 | Schco3_2601543 | 39.6 | 5.999E-214 | 695 |
| Grifola frondosa | Grifr_OBZ68042 | 36.6 | 7.276E-159 | 532 |
| Auricularia subglabra | Aurde3_1_1210495 | 33.5 | 9.212E-113 | 394 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1689 |
| Description | Other/WEE protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 788 | 1058 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR017441 | Protein kinase, ATP binding site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K03114 |
EggNOG
| COG category | Description |
|---|---|
| D | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
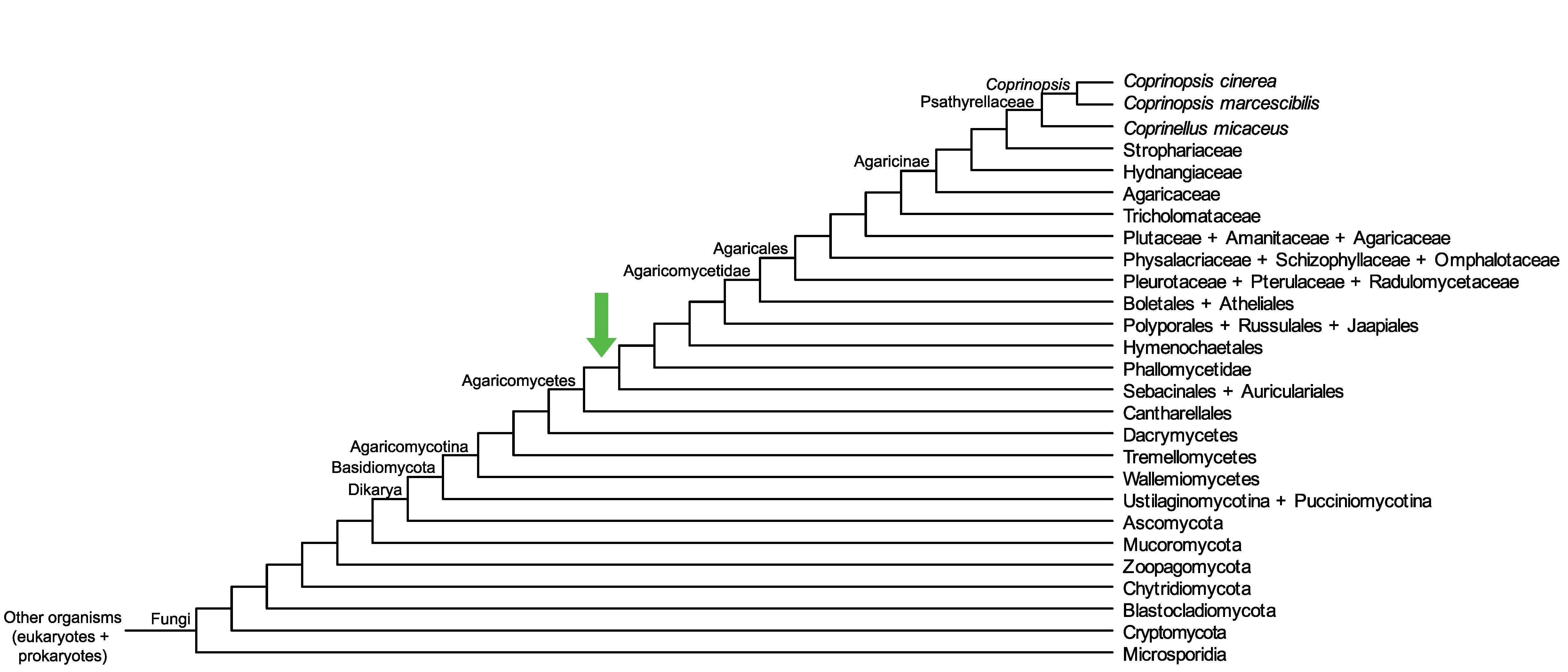
Conservation of CC1G_01961 across fungi.
Arrow shows the origin of gene family containing CC1G_01961.
Protein
| Sequence id | 1689 |
|---|---|
| Sequence |
>1689 MSPTYHCTPPRRCADTVRPFDSPMLTPSPLRQPTIFSPKFNNDAQDIDDLFRNSPYRSPAQAHIFQNPAYSTKPL PIQADDEEGRIFLSSNSNSPRLSSPTSQPIFTPLKSPYNTAGRVALADRNLNEPQPIATSSNGPMLTSRAGIGTK RKVTPQCTPLKIEASGSFQKLGPLPAPKFATKTPHSKAEAEEFLRKQTATLTKLKLSDRDNRMDTSNDSDCDFDE EAGANLFRTASKGKEKEEVVEAVSPGGRVVKRRARTRPLSAELRNQQPFESPSPVKKPFLSKTRPRHSGTIAFPS SNAYRSRASPSGSSSSEAGSPAPRRRISNVASRPYIKPPVFAPRPPISRQDNLSAATLFFGPVIPQSAPLQSPAR TRTTTSTGIPNPDIKSARSKAPNRHSYGGTGTSGDWAHIAHPSSPSPMYGVPPAAQRDNSYISTDEDEEMSFEGP AQSSFTFSLTGSTPSPSSKKPLPRKFESIKRRSLGDYEMSVSRPYGGSLAVMPGASTSSSSLGSDDGLITPLTTA PTNWPGPQVHDKDSDDHRPRFTDDEAEVDEFIVRTLAAATKGPAPGSKRPPGTPVKKVRTAFLGPDRPWQSAVAS KIGIKEDVAPLRTRKIPRQSMPAVMPMGGKSLLDQCTDTEDEEDSPSAKKDSRYTKLGLGHPVGLFGGSGPFANP RTRWLMRRSSSGAFSSGSETTSQANTPTRTKGIDWQLPKLAANLSPSGTFSKLTERSASGSSTSSGVASSPTNRK GGSTRGTDVKPPRVSLVNRRLSEPSLTEQSGRFERDFVTVDEVGSGEFGSVIKVRSKGGDENKVYAIKRSKRFEG AKHRLRLWEEVEVLKHLSESAELCGLDGRHPNVLAYIDSWEEDEALFIQTELCESGNLAHFLWEYGKVFPRLDEA RVWKCVVDLSNGLRFIHESGVIHLDLKPSNVFVTHEGRFKIGDFGMASLWPRMAIVEADGSETTSSFEREGDKLY LAPEVLQGRYSKAADVFSFGMTILETATNIVVPDQGESWHRLRREDFSEVDWEGSNELLTLIQDMMRTDPAERID VQEVYNHCVVARAREKMEMTYAEAKANGSTVFAASPLASVPRGFLEEILGRDSSAMDESL |
| Length | 1110 |
Coding
| Sequence id | CC1G_01961T0 |
|---|---|
| Sequence |
>CC1G_01961T0 ATGTCTCCAACTTATCATTGTACACCGCCCAGACGATGCGCAGACACCGTTCGCCCATTTGATTCGCCAATGCTC ACTCCCTCGCCCCTGCGACAACCGACAATATTCTCCCCAAAATTCAACAATGATGCCCAGGACATCGACGACCTC TTCAGAAACTCCCCCTACAGGTCTCCAGCGCAGGCGCATATCTTCCAGAATCCAGCCTATTCGACAAAACCACTA CCTATCCAAGCGGATGACGAGGAGGGTCGCATCTTCCTCTCTTCCAACTCCAACTCTCCTCGATTATCTTCTCCA ACCTCACAGCCTATCTTTACACCCCTCAAGTCACCCTACAACACCGCTGGACGCGTAGCACTCGCCGACAGGAAC CTCAACGAACCGCAGCCCATCGCCACCTCATCCAATGGTCCGATGCTGACTTCGCGCGCAGGGATCGGCACCAAG CGCAAAGTCACTCCTCAATGCACTCCGTTGAAGATAGAGGCCTCGGGCAGCTTCCAGAAACTCGGCCCTCTCCCT GCTCCCAAGTTCGCCACCAAGACCCCGCACAGCAAGGCCGAGGCCGAGGAATTCCTCCGCAAGCAGACAGCGACC CTCACAAAACTCAAGCTCAGCGATAGGGACAATCGTATGGATACCAGTAACGATTCCGATTGCGACTTTGACGAA GAAGCTGGGGCCAACCTGTTTAGGACTGCGTCGAAAGGGAAGGAAAAGGAAGAAGTTGTCGAGGCTGTCTCCCCT GGCGGGCGTGTTGTGAAGCGAAGGGCTCGGACAAGACCCCTGTCCGCCGAGCTTCGCAACCAACAGCCTTTCGAG TCCCCTTCGCCGGTCAAGAAGCCTTTCCTGAGCAAGACGCGTCCAAGGCACAGTGGAACGATTGCCTTTCCCTCT TCGAATGCCTATCGCAGCCGCGCTTCACCCAGTGGTTCCTCTTCGTCCGAAGCCGGCTCTCCAGCCCCTCGTCGC AGAATTAGCAACGTCGCCTCTCGACCTTATATTAAACCACCCGTATTCGCTCCCCGCCCGCCTATCAGTCGTCAG GACAATTTAAGTGCGGCTACTCTCTTCTTTGGCCCCGTTATTCCGCAGTCAGCTCCACTGCAATCCCCGGCCAGG ACACGGACCACTACTTCCACTGGCATTCCCAACCCTGACATCAAGTCTGCTCGCTCTAAAGCCCCCAACCGCCAT AGCTATGGCGGTACAGGAACCAGTGGCGACTGGGCCCATATTGCCCACCCCAGCTCCCCATCCCCTATGTACGGT GTGCCCCCAGCGGCTCAACGTGACAACAGCTACATCAGTACCGACGAGGACGAGGAAATGTCGTTCGAAGGACCT GCTCAAAGCTCCTTCACTTTCAGTCTCACTGGCAGCACTCCGTCCCCGAGCTCCAAGAAACCTCTCCCTCGGAAG TTCGAGTCAATCAAACGACGGTCCTTGGGCGACTACGAAATGTCAGTCAGCCGGCCCTACGGTGGCTCACTCGCT GTCATGCCAGGAGCCTCCACCAGTTCAAGCTCTCTCGGATCTGACGATGGTCTCATTACGCCTTTGACCACTGCA CCGACTAACTGGCCGGGACCGCAGGTTCACGATAAAGACTCGGACGATCATCGGCCCAGGTTCACAGATGACGAA GCCGAAGTCGACGAGTTCATCGTACGGACACTAGCAGCTGCGACCAAGGGACCTGCACCGGGAAGCAAAAGGCCT CCCGGCACTCCCGTGAAGAAAGTTCGCACCGCATTCTTGGGTCCCGACAGGCCATGGCAAAGCGCAGTTGCCTCT AAGATTGGGATCAAGGAAGATGTTGCACCTCTCAGGACCAGGAAGATACCCCGCCAGAGCATGCCAGCAGTGATG CCCATGGGTGGCAAGAGCCTTTTGGACCAATGCACCGACACTGAAGACGAAGAAGACAGTCCGAGCGCCAAAAAG GATAGCCGATATACCAAGTTGGGATTGGGCCATCCTGTTGGGTTGTTTGGGGGAAGCGGCCCTTTCGCCAATCCT CGAACCCGATGGCTCATGCGCCGTAGCAGCAGCGGTGCCTTCTCCAGTGGTAGCGAAACCACCTCTCAGGCCAAC ACCCCGACTCGAACGAAAGGAATAGACTGGCAACTTCCCAAACTCGCGGCGAACCTGTCGCCGTCCGGAACATTT TCCAAGTTGACAGAACGGTCCGCTTCCGGTTCATCGACGAGTTCAGGCGTTGCGAGCTCGCCTACGAACCGCAAG GGTGGTTCAACTCGCGGAACGGATGTCAAACCACCGAGGGTTAGCCTGGTGAATCGACGTTTGTCAGAGCCATCC TTGACTGAGCAATCTGGACGTTTTGAGCGCGATTTTGTTACTGTCGATGAAGTCGGCAGTGGGGAATTCGGCAGT GTCATCAAAGTTCGAAGTAAAGGCGGGGATGAAAACAAGGTGTACGCAATCAAGAGATCGAAGCGATTCGAGGGT GCTAAACATAGACTGCGGCTATGGGAAGAAGTTGAGGTCCTCAAACACCTCTCTGAATCCGCCGAACTCTGTGGA TTAGACGGCCGACACCCCAACGTTTTGGCGTACATCGACAGTTGGGAAGAGGACGAAGCGCTTTTCATCCAAACG GAGTTGTGTGAGTCGGGCAACCTGGCGCACTTCTTATGGGAATACGGCAAGGTGTTCCCGCGATTGGACGAAGCC AGAGTTTGGAAGTGTGTGGTAGATCTGAGTAACGGTCTCCGCTTCATCCATGAATCAGGCGTCATCCACCTGGAC TTGAAGCCTTCGAACGTCTTCGTGACGCATGAGGGACGATTCAAGATTGGTGATTTTGGGATGGCATCGCTCTGG CCGCGAATGGCGATCGTCGAAGCTGATGGTTCTGAAACGACGAGCAGCTTCGAGCGAGAAGGCGACAAACTGTAC TTGGCGCCAGAAGTGCTACAAGGGCGGTATAGCAAAGCTGCTGATGTGTTCAGTTTCGGCATGACAATCTTGGAA ACTGCAACCAACATCGTGGTCCCTGATCAAGGAGAATCGTGGCATCGACTTCGACGAGAAGATTTCTCAGAGGTT GACTGGGAGGGGAGCAACGAGTTGCTGACCCTGATCCAGGATATGATGCGCACCGATCCCGCGGAGCGGATCGAT GTCCAAGAGGTATACAACCACTGTGTGGTTGCGCGTGCGAGAGAGAAGATGGAGATGACATATGCAGAGGCCAAA GCCAACGGAAGTACTGTTTTTGCGGCATCACCGCTGGCAAGTGTCCCTCGAGGGTTTCTGGAGGAGATACTGGGG CGCGATTCAAGTGCGATGGATGAAAGTTTG |
| Length | 3333 |
Transcript
| Sequence id | CC1G_01961T0 |
|---|---|
| Sequence |
>CC1G_01961T0 ATGTCTCCAACTTATCATTGTACACCGCCCAGACGATGCGCAGACACCGTTCGCCCATTTGATTCGCCAATGCTC ACTCCCTCGCCCCTGCGACAACCGACAATATTCTCCCCAAAATTCAACAATGATGCCCAGGACATCGACGACCTC TTCAGAAACTCCCCCTACAGGTCTCCAGCGCAGGCGCATATCTTCCAGAATCCAGCCTATTCGACAAAACCACTA CCTATCCAAGCGGATGACGAGGAGGGTCGCATCTTCCTCTCTTCCAACTCCAACTCTCCTCGATTATCTTCTCCA ACCTCACAGCCTATCTTTACACCCCTCAAGTCACCCTACAACACCGCTGGACGCGTAGCACTCGCCGACAGGAAC CTCAACGAACCGCAGCCCATCGCCACCTCATCCAATGGTCCGATGCTGACTTCGCGCGCAGGGATCGGCACCAAG CGCAAAGTCACTCCTCAATGCACTCCGTTGAAGATAGAGGCCTCGGGCAGCTTCCAGAAACTCGGCCCTCTCCCT GCTCCCAAGTTCGCCACCAAGACCCCGCACAGCAAGGCCGAGGCCGAGGAATTCCTCCGCAAGCAGACAGCGACC CTCACAAAACTCAAGCTCAGCGATAGGGACAATCGTATGGATACCAGTAACGATTCCGATTGCGACTTTGACGAA GAAGCTGGGGCCAACCTGTTTAGGACTGCGTCGAAAGGGAAGGAAAAGGAAGAAGTTGTCGAGGCTGTCTCCCCT GGCGGGCGTGTTGTGAAGCGAAGGGCTCGGACAAGACCCCTGTCCGCCGAGCTTCGCAACCAACAGCCTTTCGAG TCCCCTTCGCCGGTCAAGAAGCCTTTCCTGAGCAAGACGCGTCCAAGGCACAGTGGAACGATTGCCTTTCCCTCT TCGAATGCCTATCGCAGCCGCGCTTCACCCAGTGGTTCCTCTTCGTCCGAAGCCGGCTCTCCAGCCCCTCGTCGC AGAATTAGCAACGTCGCCTCTCGACCTTATATTAAACCACCCGTATTCGCTCCCCGCCCGCCTATCAGTCGTCAG GACAATTTAAGTGCGGCTACTCTCTTCTTTGGCCCCGTTATTCCGCAGTCAGCTCCACTGCAATCCCCGGCCAGG ACACGGACCACTACTTCCACTGGCATTCCCAACCCTGACATCAAGTCTGCTCGCTCTAAAGCCCCCAACCGCCAT AGCTATGGCGGTACAGGAACCAGTGGCGACTGGGCCCATATTGCCCACCCCAGCTCCCCATCCCCTATGTACGGT GTGCCCCCAGCGGCTCAACGTGACAACAGCTACATCAGTACCGACGAGGACGAGGAAATGTCGTTCGAAGGACCT GCTCAAAGCTCCTTCACTTTCAGTCTCACTGGCAGCACTCCGTCCCCGAGCTCCAAGAAACCTCTCCCTCGGAAG TTCGAGTCAATCAAACGACGGTCCTTGGGCGACTACGAAATGTCAGTCAGCCGGCCCTACGGTGGCTCACTCGCT GTCATGCCAGGAGCCTCCACCAGTTCAAGCTCTCTCGGATCTGACGATGGTCTCATTACGCCTTTGACCACTGCA CCGACTAACTGGCCGGGACCGCAGGTTCACGATAAAGACTCGGACGATCATCGGCCCAGGTTCACAGATGACGAA GCCGAAGTCGACGAGTTCATCGTACGGACACTAGCAGCTGCGACCAAGGGACCTGCACCGGGAAGCAAAAGGCCT CCCGGCACTCCCGTGAAGAAAGTTCGCACCGCATTCTTGGGTCCCGACAGGCCATGGCAAAGCGCAGTTGCCTCT AAGATTGGGATCAAGGAAGATGTTGCACCTCTCAGGACCAGGAAGATACCCCGCCAGAGCATGCCAGCAGTGATG CCCATGGGTGGCAAGAGCCTTTTGGACCAATGCACCGACACTGAAGACGAAGAAGACAGTCCGAGCGCCAAAAAG GATAGCCGATATACCAAGTTGGGATTGGGCCATCCTGTTGGGTTGTTTGGGGGAAGCGGCCCTTTCGCCAATCCT CGAACCCGATGGCTCATGCGCCGTAGCAGCAGCGGTGCCTTCTCCAGTGGTAGCGAAACCACCTCTCAGGCCAAC ACCCCGACTCGAACGAAAGGAATAGACTGGCAACTTCCCAAACTCGCGGCGAACCTGTCGCCGTCCGGAACATTT TCCAAGTTGACAGAACGGTCCGCTTCCGGTTCATCGACGAGTTCAGGCGTTGCGAGCTCGCCTACGAACCGCAAG GGTGGTTCAACTCGCGGAACGGATGTCAAACCACCGAGGGTTAGCCTGGTGAATCGACGTTTGTCAGAGCCATCC TTGACTGAGCAATCTGGACGTTTTGAGCGCGATTTTGTTACTGTCGATGAAGTCGGCAGTGGGGAATTCGGCAGT GTCATCAAAGTTCGAAGTAAAGGCGGGGATGAAAACAAGGTGTACGCAATCAAGAGATCGAAGCGATTCGAGGGT GCTAAACATAGACTGCGGCTATGGGAAGAAGTTGAGGTCCTCAAACACCTCTCTGAATCCGCCGAACTCTGTGGA TTAGACGGCCGACACCCCAACGTTTTGGCGTACATCGACAGTTGGGAAGAGGACGAAGCGCTTTTCATCCAAACG GAGTTGTGTGAGTCGGGCAACCTGGCGCACTTCTTATGGGAATACGGCAAGGTGTTCCCGCGATTGGACGAAGCC AGAGTTTGGAAGTGTGTGGTAGATCTGAGTAACGGTCTCCGCTTCATCCATGAATCAGGCGTCATCCACCTGGAC TTGAAGCCTTCGAACGTCTTCGTGACGCATGAGGGACGATTCAAGATTGGTGATTTTGGGATGGCATCGCTCTGG CCGCGAATGGCGATCGTCGAAGCTGATGGTTCTGAAACGACGAGCAGCTTCGAGCGAGAAGGCGACAAACTGTAC TTGGCGCCAGAAGTGCTACAAGGGCGGTATAGCAAAGCTGCTGATGTGTTCAGTTTCGGCATGACAATCTTGGAA ACTGCAACCAACATCGTGGTCCCTGATCAAGGAGAATCGTGGCATCGACTTCGACGAGAAGATTTCTCAGAGGTT GACTGGGAGGGGAGCAACGAGTTGCTGACCCTGATCCAGGATATGATGCGCACCGATCCCGCGGAGCGGATCGAT GTCCAAGAGGTATACAACCACTGTGTGGTTGCGCGTGCGAGAGAGAAGATGGAGATGACATATGCAGAGGCCAAA GCCAACGGAAGTACTGTTTTTGCGGCATCACCGCTGGCAAGTGTCCCTCGAGGGTTTCTGGAGGAGATACTGGGG CGCGATTCAAGTGCGATGGATGAAAGTTTGTAG |
| Length | 3333 |
Gene
| Sequence id | CC1G_01961T0 |
|---|---|
| Sequence |
>CC1G_01961T0 ATGTCTCCAACTTATCATTGTACACCGCCCAGACGATGCGCAGACACCGTTCGCCCATTTGATTCGCCAATGCTC ACTCCCTCGCCCCTGCGACAACCGACAATATTCTCCCCAAAATTCAACAATGATGCCCAGGACATCGACGACCTC TTCAGAAACTCCCCCTACAGGTCTCCAGCGCAGGCGCATATCTTCCAGAATCCAGCCTATTCGACAAAACCACTA CCTATCCAAGCGGATGACGAGGAGGGTCGCATCTTCCTCTCTTCCAACTCCAACTCTCCTCGATTATCTTCTCCA ACCTCACAGCCTATCTTTACACCCCTCAAGTCACCCTACAACACCGCTGGACGCGTAGCACTCGCCGACAGGAAC CTCAACGAACCGCAGCCCATCGCCACCTCATCCAATGGTCCGATGCTGACTTCGCGCGCAGGGATCGGCACCAAG CGCAAAGTCACTCCTCAATGCACTCCGTTGAAGATAGAGGCCTCGGGCAGCTTCCAGAAACTCGGCCCTCTCCCT GCTCCCAAGTTCGCCACCAAGACCCCGCACAGCAAGGCCGAGGCCGAGGAATTCCTCCGCAAGCAGACAGCGACC CTCACAAAACTCAAGCTCAGCGATAGGGACAATCGTATGGATACCAGTAACGATTCCGATTGCGACTTTGACGAA GAAGCTGGGGCCAACCTGTTTAGGACTGCGTCGAAAGGGAAGGAAAAGGAAGAAGTTGTCGAGGCTGTCTCCCCT GGCGGGCGTGTTGTGAAGCGAAGGGCTCGGACAAGACCCCTGTCCGCCGAGCTTCGCAACCAACAGCCTTTCGAG TCCCCTTCGCCGGTCAAGGTATGTAACGTGCTACAACGTCGCTTGGCCCGCCCTTACGCGTCTTTAAAGAAGCCT TTCCTGAGCAAGACGCGTCCAAGGCACAGTGGAACGATTGCCTTTCCCTCTTCGAATGCCTATCGCAGCCGCGCT TCACCCAGTGGTTCCTCTTCGTCCGAAGCCGGCTCTCCAGCCCCTCGTCGCAGAATTAGCAACGTCGCCTCTCGA CCTTATATTAAACCACCCGTATTCGCTCCCCGCCCGCCTATCAGTCGTCAGGACAATTTAAGTGCGGCTACTCTC TTCTTTGGCCCCGTTATTCCGCAGTCAGCTCCACTGCAATCCCCGGCCAGGACACGGACCACTACTTCCACTGGC ATTCCCAACCCTGACATCAAGTCTGCTCGCTCTAAAGCCCCCAACCGCCATAGCTATGGCGGTACAGGAACCAGT GGCGACTGGGCCCATATTGCCCACCCCAGCTCCCCATCCCCTATGTACGGTGTGCCCCCAGCGGCTCAACGTGAC AACAGCTACATCAGTACCGACGAGGACGAGGAAATGTCGTTCGAAGGACCTGCTCAAAGCTCCTTCACTTTCAGT CTCACTGGCAGCACTCCGTCCCCGAGCTCCAAGAAACCTCTCCCTCGGAAGTTCGAGTCAATCAAACGACGGTCC TTGGGCGACTACGAAATGTCAGTCAGCCGGCCCTACGGTGGCTCACTCGCTGTCATGCCAGGAGCCTCCACCAGT TCAAGCTCTCTCGGATCTGACGATGGTCTCATTACGCCTTTGACCACTGCACCGACTAACTGGCCGGGACCGCAG GTTCACGATAAAGACTCGGACGATCATCGGCCCAGGTTCACAGATGACGAAGCCGAAGTCGACGAGTTCATCGTA CGGACACTAGCAGCTGCGACCAAGGGACCTGCACCGGGAAGCAAAAGGCCTCCCGGCACTCCCGTGAAGAAAGTT CGCACCGCATTCTTGGGTCCCGACAGGCCATGGCAAAGCGCAGTTGCCTCTAAGATTGGGATCAAGGAAGATGTT GCACCTCTCAGGACCAGGAAGATACCCCGCCAGAGCATGCCAGCAGTGATGCCCATGGGTGGCAAGAGCCTTTTG GACCAATGCACCGACACTGAAGACGAAGAAGACAGTCCGAGCGCCAAAAAGGATAGCCGATATACCAAGTTGGGA TTGGGCCATCCTGTTGGGTTGTTTGGGGGAAGCGGCCCTTTCGCCAATCCTCGAACCCGATGGCTCATGCGCCGT AGCAGCAGCGGTGCCTTCTCCAGTGGTAGCGAAACCACCTCTCAGGCCAACACCCCGACTCGAACGAAAGGAATA GGTAAGTCTGTTTAACTGTAATTCTCGCTCAGTACACTAATGATTGCCCTCCCCTATCAGACTGGCAACTTCCCA AACTCGCGGCGAACCTGTCGCCGTCCGGAACATTTTCCAAGTTGACAGAACGGTCCGCTTCCGGTTCATCGACGA GTTCAGGCGTTGCGAGCTCGCCTACGAACCGCAAGGGTGGTTCAACTCGCGGAACGGATGTCAAACCACCGAGGG TTAGCCTGGTGAATCGACGTTTGTCAGAGCCATCCTTGACTGAGCAATCTGGACGTTTTGAGCGCGATTTTGTTA CTGTCGATGAAGTCGGCAGTGGGGAATTCGGCAGTGTCATCAAAGTTCGAAGTAAAGGCGGGGATGAAAACAAGG TGTACGCAATCAAGAGATCGAAGCGATTCGAGGGTGCTAAACATAGGTGAGTTGCTTTTTCGGGACTTCTGAGGC CGCCTCCGCACTATGCGAATGAGGAATGACGACAAAAATCTTCTCAACTTCTTCGGTTGTTATGGAAATGGAGCG CTGACTTGGGATTTGTGACAGACTGCGGCTATGGGAAGAAGTTGAGGTCCTCAAACACCTCTCTGAATCCGCCGA ACTCTGTGGATTAGACGGCCGACACCCCAACGTTTTGGCGTACATCGACAGTTGGGAAGAGGACGAAGCGCTTTT CATCCAAACGGAGTTGTGTGAGTCGGGCAACCTGGCGCACTTCTTATGGGAATACGGCAAGGTGTTCCCGCGATT GGACGAAGCCAGAGTTTGGAAGTGTGTGGTAGATCTGAGTAACGTAAGTAATTAATCTCGCTCGCTTTCAACAGC AACGTCGGTGCTCAACATTGTTTATTCACCAGGGTCTCCGCTTCATCCATGAATCAGGCGTCATCCACCTGGACT TGAAGCCTTCGAACGTCTTCGTGACGCATGAGGGACGATTCAAGATTGGTGATTTTGGGATGGCATCGCTCTGGC CGCGAATGGCGATCGTCGAAGCTGATGGTTCTGAAACGACGAGCAGCTTCGAGCGAGAAGGCGACAAACTGTACT TGGCGCCAGAAGTGCTACAAGGGCGGTATAGCAAAGCTGCTGATGTGTTCAGGTAAGCCTCGCACGGTTCCATCG GTGTTCTGTTTTTACAACCTTCTCATGTCAACCTTCCAGTTTCGGCATGACAATCTTGGAAACTGCAACCAACAT CGTGGTCCCTGATCAGTGAGTGTTTCCCGCGGACCGTCCGTTCCGTTGCTGTGATACTGAAGGATTGCGTCTGTC TTTTTCCAGAGGAGAATCGTGGCATCGACTTCGACGAGAAGATTTCTCAGAGGTTGACTGGGAGGGGAGCAACGA GTTGCTGACCCTGATCCAGGATATGATGCGCACCGATCCCGCGGAGCGGATCGATGTCCAAGAGGTATACAACCA CTGTGTGGTTGCGCGTGCGAGAGAGAAGATGGAGATGACATATGCAGAGGCCAAAGCCAACGGAAGTACTGTTTT TGCGGCATCACCGCTGGCAAGTGTCCCTCGAGGGTTTCTGGAGGAGATACTGGGGCGCGATTCAAGTGCGATGGA TGAAAGTTTGTAG |
| Length | 3763 |