CC1G_02087
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_02087 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NK50 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_10:1620398..1623735 | Strand | - |
| Gene length (nt) | 3338 | Transcript length (nt) | 2896 |
| CDS length (nt) | 2433 | Protein length (aa) | 810 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Saccharomyces cerevisiae | YNL298W_CLA4 |
| Aspergillus nidulans | AN8836_cla4 |
| Neurospora crassa | vel |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7264025 | 74.7 | 0 | 1203 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB18207 | 71.6 | 0 | 1199 |
| Pleurotus eryngii ATCC 90797 | Pleery1_142286 | 71.1 | 0 | 1134 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_102264 | 66.3 | 0 | 1091 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_153517 | 66.2 | 0 | 1087 |
| Flammulina velutipes | Flave_chr10AA01255 | 66 | 0 | 1060 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_130362 | 64.3 | 0 | 1049 |
| Schizophyllum commune H4-8 | Schco3_2638161 | 69.4 | 0 | 1024 |
| Pleurotus ostreatus PC15 | PleosPC15_2_34426 | 64 | 1.195E-304 | 987 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_17003 | 57.2 | 1.032E-304 | 970 |
| Auricularia subglabra | Aurde3_1_1274621 | 61.7 | 3.729E-304 | 969 |
| Pleurotus ostreatus PC9 | PleosPC9_1_87656 | 65.1 | 2.695E-304 | 957 |
| Lentinula edodes NBRC 111202 | Lenedo1_1060871 | 58.7 | 4.717E-285 | 887 |
| Lentinula edodes B17 | Lened_B_1_1_12395 | 53.3 | 2.332E-251 | 789 |
| Grifola frondosa | Grifr_OBZ74620 | 60.8 | 2.42E-221 | 702 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1795 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd13279 | PH_Cla4_Ste20 | - | 81 | 169 |
| CDD | cd01093 | CRIB_PAK_like | IPR033923 | 179 | 220 |
| CDD | cd06614 | STKc_PAK | - | 536 | 790 |
| Pfam | PF00169 | PH domain | IPR001849 | 82 | 165 |
| Pfam | PF00786 | P21-Rho-binding domain | IPR000095 | 179 | 234 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 537 | 789 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR000095 | CRIB domain |
| IPR011993 | PH-like domain superfamily |
| IPR001849 | Pleckstrin homology domain |
| IPR036936 | CRIB domain superfamily |
| IPR033923 | p21 activated kinase binding domain |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004674 | protein serine/threonine kinase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K19833 |
EggNOG
| COG category | Description |
|---|---|
| T | P21-Rho-binding domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
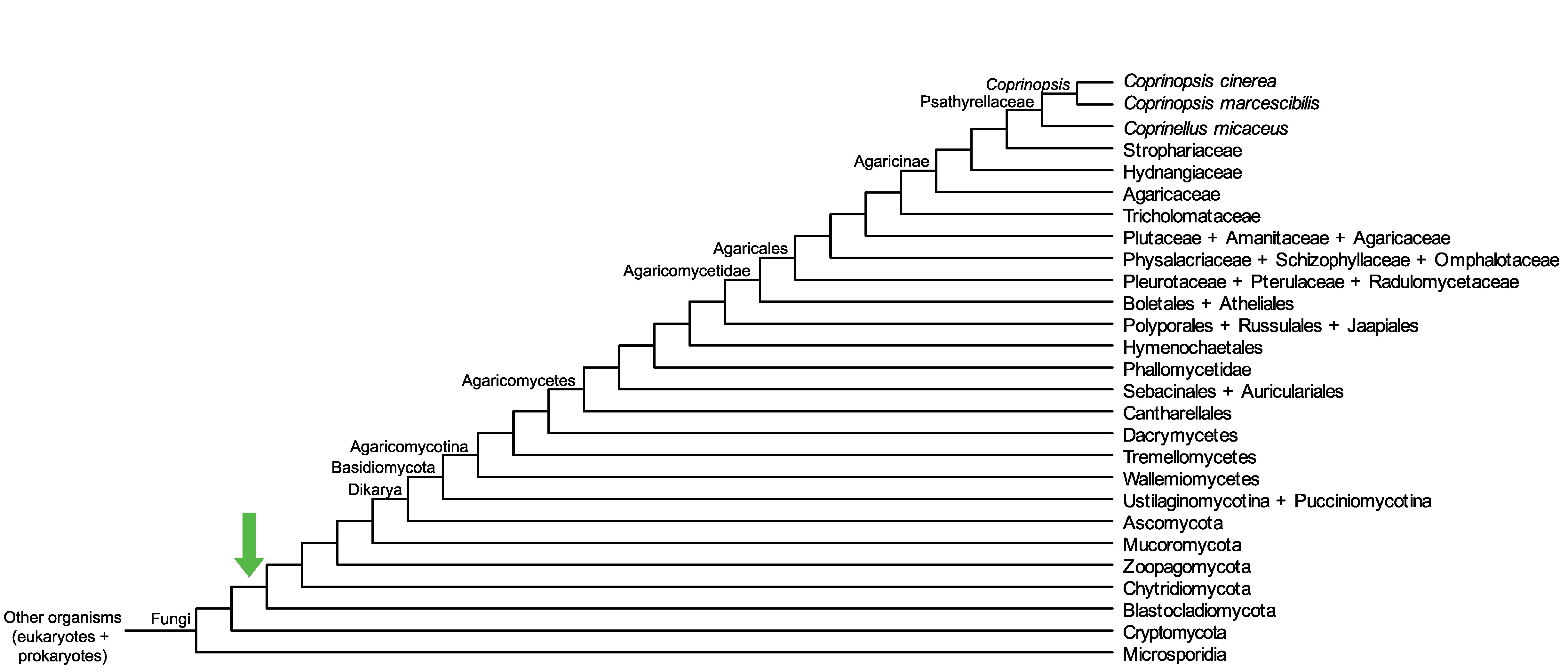
Conservation of CC1G_02087 across fungi.
Arrow shows the origin of gene family containing CC1G_02087.
Protein
| Sequence id | 1795 |
|---|---|
| Sequence |
>1795 MSYHQVSANSLQPTRPAPQAPQRRNDAQPLYSSNNLLSSSGYNPSFAYSSSTPINQNYSQSYSGIGGTPNRGADD TMNQQIVRNGSVSMKEDGFGNWLWQRKWLILREQALTIHKNENSPHQTMILLRDISNIERTDLKPYCLLLETKDK RYFLSLKNDEELYGWQDDVYSRSPLMGFSNPTNFVHKVHVGFDPVSGAFTGLPEQWSKLLTKSAITREDYAKDPQ AVLDVLEFYTDRQKQELEDLSIGAPPRFNAGTGLGGLGKQPGPAEIRPLPKRNETSPPGLTGTDSDNLSSAAARA AEHVNGSHVANAISSVQGPRGPLPVPTLPQATRAAPPRPIAASRPPPQPPKDVTPSTDDLRNRVKPQGPVPLPVR NDSLPTAPGIHQSASQRSQQEQRERQQQQEQRRLEQREREREQREREREREREREEREAYRAQQERPPLAPSKSA PGTAQPATQPATGPAGALEGPPPVLPLQPKKVQIQAADKPAKPAGGVAAAAAALEKPKEKRISTMTEVQIMEKLR QVVSDEDPKLIYSKIKKVGQGASGHVYVAKELATGKKVAIKEMDLSHQPRKELIVNEILVMKESQHPNIVNFLNS YLVKNNELWVVMEYMEGGALTDVIENNTLEEDQISSICLETCKGLQHLHSQSIIHRDIKSDNVLLDAQGRVKITD FGFCAKLTDQKSKRATMVGTPYWMAPEVVKQKEYGAKVDIWSLGIMAIEMIENEPPYLDEEPLKALYLIATNGTP TLKKPEALSKELKSFLAVCLCVDVASRATAIELLDHEFLKKACQLSGLAPLLRFKTKQAS |
| Length | 810 |
Coding
| Sequence id | CC1G_02087T0 |
|---|---|
| Sequence |
>CC1G_02087T0 ATGTCTTATCACCAGGTCTCAGCCAACTCGCTCCAGCCAACAAGACCAGCACCCCAGGCACCGCAAAGACGAAAC GACGCACAACCGCTGTACTCGTCGAACAACCTGCTCTCCAGCTCTGGATACAACCCTTCTTTCGCCTACTCGTCA TCAACGCCCATAAACCAGAACTATTCACAGTCGTACTCTGGGATCGGTGGAACACCAAATCGTGGCGCAGACGAT ACCATGAACCAGCAGATTGTGCGGAACGGGAGTGTGAGTATGAAGGAGGATGGATTTGGCAACTGGCTATGGCAG AGAAAGTGGTTGATCCTGAGGGAGCAGGCCCTGACAATACACAAGAACGAAAATTCACCGCACCAAACCATGATT CTCCTTCGCGACATCTCCAACATTGAGCGCACTGATTTGAAGCCATATTGCCTGCTACTCGAGACCAAAGACAAG CGATATTTCCTTTCTTTGAAGAACGATGAGGAGCTTTATGGTTGGCAAGACGATGTGTATTCGCGAAGCCCGCTG ATGGGCTTCAGCAACCCGACGAATTTCGTCCACAAGGTCCACGTCGGTTTCGATCCTGTTTCAGGTGCCTTCACG GGTCTGCCCGAACAATGGAGCAAGCTGCTGACCAAATCTGCAATCACTCGCGAGGATTATGCCAAGGATCCCCAA GCGGTGTTGGATGTCCTAGAGTTCTATACGGATCGCCAAAAGCAGGAACTGGAAGATCTCTCAATAGGTGCTCCT CCCCGCTTCAACGCTGGGACCGGCCTGGGAGGCCTTGGGAAGCAACCGGGCCCCGCTGAAATCCGCCCACTGCCC AAGCGCAACGAGACCTCACCGCCTGGCCTTACTGGCACGGATAGCGATAACCTTTCCAGCGCGGCCGCTCGTGCA GCTGAACACGTCAACGGATCTCATGTCGCGAACGCCATCTCCTCTGTGCAAGGTCCCCGAGGCCCTCTGCCTGTC CCCACCCTTCCTCAAGCCACCCGCGCAGCACCACCCCGTCCCATCGCGGCCTCTCGGCCACCTCCCCAGCCTCCC AAGGATGTCACTCCATCCACCGACGATCTCCGCAATCGCGTGAAGCCGCAAGGCCCCGTCCCTCTCCCCGTCCGC AACGATTCCCTCCCTACTGCCCCTGGAATCCATCAATCCGCCAGCCAGAGAAGCCAGCAAGAGCAACGCGAGCGC CAGCAGCAGCAGGAGCAGCGTCGGCTGGAGCAACGCGAGAGAGAGCGAGAGCAGCGTGAACGTGAGCGCGAGCGC GAGCGAGAGAGAGAGGAAAGAGAGGCGTATAGGGCTCAGCAAGAGCGACCCCCTCTCGCGCCTTCCAAGTCTGCT CCTGGGACTGCTCAGCCGGCGACGCAGCCTGCTACAGGCCCCGCTGGTGCCCTTGAGGGACCACCGCCGGTTCTT CCCCTCCAGCCCAAGAAAGTGCAGATCCAAGCGGCTGATAAGCCAGCGAAACCTGCCGGCGGTGTTGCTGCTGCC GCTGCGGCATTGGAGAAGCCCAAGGAGAAGAGGATCAGTACCATGACTGAGGTTCAGATCATGGAGAAACTGCGT CAAGTGGTATCAGACGAGGACCCCAAGCTTATCTACAGCAAGATTAAGAAAGTCGGACAAGGCGCGTCTGGCCAC GTCTATGTTGCGAAGGAGCTTGCCACCGGAAAGAAGGTTGCGATCAAGGAGATGGATCTCTCACACCAGCCGCGT AAAGAGCTCATCGTCAATGAGATCTTGGTGATGAAGGAGTCGCAGCATCCTAACATTGTCAACTTCTTGAACTCG TATCTCGTGAAGAACAATGAGCTATGGGTGGTCATGGAGTACATGGAGGGAGGTGCGTTGACGGATGTTATTGAG AATAACACGTTGGAGGAAGATCAGATCTCGAGTATCTGCTTGGAGACTTGCAAGGGTTTGCAACATCTGCATAGC CAGAGCATCATTCACCGTGACATCAAGTCCGACAACGTCCTTCTCGATGCTCAGGGTCGGGTCAAGATCACTGAC TTTGGCTTCTGCGCCAAACTAACGGACCAGAAGTCGAAGCGGGCGACCATGGTTGGTACTCCCTACTGGATGGCT CCCGAAGTCGTCAAGCAGAAGGAGTACGGTGCCAAGGTCGATATTTGGTCGCTTGGTATCATGGCGATTGAGATG ATTGAGAACGAGCCTCCCTATCTCGACGAAGAACCTCTCAAGGCGCTGTATCTGATCGCTACCAACGGAACTCCC ACTCTGAAGAAGCCTGAGGCTCTGAGCAAGGAGCTCAAGAGCTTCTTGGCGGTGTGTCTCTGCGTGGATGTTGCT AGTCGGGCGACTGCCATTGAACTTTTGGATCACGAGTTCTTGAAAAAGGCGTGCCAATTGTCCGGGCTAGCTCCA CTTTTGCGCTTCAAGACCAAGCAAGCGTCC |
| Length | 2433 |
Transcript
| Sequence id | CC1G_02087T0 |
|---|---|
| Sequence |
>CC1G_02087T0 ATGTCTTATCACCAGGTCTCAGCCAACTCGCTCCAGCCAACAAGACCAGCACCCCAGGCACCGCAAAGACGAAAC GACGCACAACCGCTGTACTCGTCGAACAACCTGCTCTCCAGCTCTGGATACAACCCTTCTTTCGCCTACTCGTCA TCAACGCCCATAAACCAGAACTATTCACAGTCGTACTCTGGGATCGGTGGAACACCAAATCGTGGCGCAGACGAT ACCATGAACCAGCAGATTGTGCGGAACGGGAGTGTGAGTATGAAGGAGGATGGATTTGGCAACTGGCTATGGCAG AGAAAGTGGTTGATCCTGAGGGAGCAGGCCCTGACAATACACAAGAACGAAAATTCACCGCACCAAACCATGATT CTCCTTCGCGACATCTCCAACATTGAGCGCACTGATTTGAAGCCATATTGCCTGCTACTCGAGACCAAAGACAAG CGATATTTCCTTTCTTTGAAGAACGATGAGGAGCTTTATGGTTGGCAAGACGATGTGTATTCGCGAAGCCCGCTG ATGGGCTTCAGCAACCCGACGAATTTCGTCCACAAGGTCCACGTCGGTTTCGATCCTGTTTCAGGTGCCTTCACG GGTCTGCCCGAACAATGGAGCAAGCTGCTGACCAAATCTGCAATCACTCGCGAGGATTATGCCAAGGATCCCCAA GCGGTGTTGGATGTCCTAGAGTTCTATACGGATCGCCAAAAGCAGGAACTGGAAGATCTCTCAATAGGTGCTCCT CCCCGCTTCAACGCTGGGACCGGCCTGGGAGGCCTTGGGAAGCAACCGGGCCCCGCTGAAATCCGCCCACTGCCC AAGCGCAACGAGACCTCACCGCCTGGCCTTACTGGCACGGATAGCGATAACCTTTCCAGCGCGGCCGCTCGTGCA GCTGAACACGTCAACGGATCTCATGTCGCGAACGCCATCTCCTCTGTGCAAGGTCCCCGAGGCCCTCTGCCTGTC CCCACCCTTCCTCAAGCCACCCGCGCAGCACCACCCCGTCCCATCGCGGCCTCTCGGCCACCTCCCCAGCCTCCC AAGGATGTCACTCCATCCACCGACGATCTCCGCAATCGCGTGAAGCCGCAAGGCCCCGTCCCTCTCCCCGTCCGC AACGATTCCCTCCCTACTGCCCCTGGAATCCATCAATCCGCCAGCCAGAGAAGCCAGCAAGAGCAACGCGAGCGC CAGCAGCAGCAGGAGCAGCGTCGGCTGGAGCAACGCGAGAGAGAGCGAGAGCAGCGTGAACGTGAGCGCGAGCGC GAGCGAGAGAGAGAGGAAAGAGAGGCGTATAGGGCTCAGCAAGAGCGACCCCCTCTCGCGCCTTCCAAGTCTGCT CCTGGGACTGCTCAGCCGGCGACGCAGCCTGCTACAGGCCCCGCTGGTGCCCTTGAGGGACCACCGCCGGTTCTT CCCCTCCAGCCCAAGAAAGTGCAGATCCAAGCGGCTGATAAGCCAGCGAAACCTGCCGGCGGTGTTGCTGCTGCC GCTGCGGCATTGGAGAAGCCCAAGGAGAAGAGGATCAGTACCATGACTGAGGTTCAGATCATGGAGAAACTGCGT CAAGTGGTATCAGACGAGGACCCCAAGCTTATCTACAGCAAGATTAAGAAAGTCGGACAAGGCGCGTCTGGCCAC GTCTATGTTGCGAAGGAGCTTGCCACCGGAAAGAAGGTTGCGATCAAGGAGATGGATCTCTCACACCAGCCGCGT AAAGAGCTCATCGTCAATGAGATCTTGGTGATGAAGGAGTCGCAGCATCCTAACATTGTCAACTTCTTGAACTCG TATCTCGTGAAGAACAATGAGCTATGGGTGGTCATGGAGTACATGGAGGGAGGTGCGTTGACGGATGTTATTGAG AATAACACGTTGGAGGAAGATCAGATCTCGAGTATCTGCTTGGAGACTTGCAAGGGTTTGCAACATCTGCATAGC CAGAGCATCATTCACCGTGACATCAAGTCCGACAACGTCCTTCTCGATGCTCAGGGTCGGGTCAAGATCACTGAC TTTGGCTTCTGCGCCAAACTAACGGACCAGAAGTCGAAGCGGGCGACCATGGTTGGTACTCCCTACTGGATGGCT CCCGAAGTCGTCAAGCAGAAGGAGTACGGTGCCAAGGTCGATATTTGGTCGCTTGGTATCATGGCGATTGAGATG ATTGAGAACGAGCCTCCCTATCTCGACGAAGAACCTCTCAAGGCGCTGTATCTGATCGCTACCAACGGAACTCCC ACTCTGAAGAAGCCTGAGGCTCTGAGCAAGGAGCTCAAGAGCTTCTTGGCGGTGTGTCTCTGCGTGGATGTTGCT AGTCGGGCGACTGCCATTGAACTTTTGGATCACGAGTTCTTGAAAAAGGCGTGCCAATTGTCCGGGCTAGCTCCA CTTTTGCGCTTCAAGACCAAGCAAGCGTCCTAAACGCTTGTGTTGGTCGTTTATGATTGATTGATTCGTTCTTTC TTCGTCTATCTGTGTTTCTTCTTATAGTTGTTTGTTTGTTTTTGTTCCACCCATATACCGATATTCAAGATTTAA GGATACGACCTCCCTCACCATGAACTATCCCCCCTAATGCTTCGTCGTCTTTCTGTCTTGTTTCTTTAAACCTCA TGTGTGCCCTTCATTCTACCGTTGCCTGGAATTTACATGTTTCACTCGGTGCCCCCCTTTTTCGACGTTGTCTCC TTTTAAGCAGGTGCTTTCTGTAAATTCTTCTTCTCTATCTTTCCCTTCCTCCTTCCTTTTGCACATTTTGTTCTT TTACAATTACGAGATCCCTTTTTTTTGTCTTTTATTATTACCCCCCTCTTGTCTGTTTGTTTGCTACACCCTCCA TGTATTTGTTGCCGAATGTGTAACCTCTTTTTTTCGCCTGTTTCTT |
| Length | 2896 |
Gene
| Sequence id | CC1G_02087T0 |
|---|---|
| Sequence |
>CC1G_02087T0 ATGTCTTATCACCAGGTCTCAGCCAACTCGCTCCAGCCAACAAGACCAGCACCCCAGGCACCGCAAAGACGAAAC GACGCACAACCGCTGTACTCGTCGAACAACCTGCTCTCCAGCTCTGGATACAACCCTTCTTTCGCCTACTCGTCA TCAACGCCCATAAACCAGAACTATTCACAGTCGTACTCTGGGATCGGTGGAACACCAAATCGTGGCGCAGACGAT ACCATGAACCAGCAGATTGTGCGGAACGGGAGTGTGAGTATGAAGGAGGATGGATTTGGCAACTGGCTATGGCAG AGAAAGTGGTTGATCCTGAGGGAGCAGGCCCTGACAATACACAAGAACGAAGTGAGTAACGAATATCCTCTTTTC AAAGGATATGCTAATCAGTGCTGTTAACAGAATTCACCGCACCAAACCATGATTCTCCTTCGCGACATCTCCAAC ATTGAGCGCACTGATTTGAAGCCATATTGCCTGCTACTCGAGACCAAAGACAAGCGATATTTCCTTTCTTTGAAG AACGATGAGGAGCTTTATGGTTGGCAAGACGATGTGTATTCGCGAAGCCCGCTGATGGGCTTCAGCAACCCGACG AATTTCGTCCACAAGGTCCACGTCGGTTTCGATCCTGTTTCAGGTGCCTTCACGGTAAGCCTTCATCAGAACGTT CTGCCGTGCCCCTGGTCCTGACTCAATTAATTCAAGGGTCTGCCCGAACAATGGAGCAAGCTGCTGACCAAATCT GCAATCACTCGCGAGGATTATGCCAAGGATCCCCAAGCGGTGTTGGATGTCCTAGAGTTCTATACGGATCGCCAA AAGCAGGAACTGGAAGATCTCTCAATAGGTGCGTGGTCACATACCCGTGCTCGGGATCCCCTCTGATCCCACGCT ATCATTACTAGGTGCTCCTCCCCGCTTCAACGCTGGGACCGGCCTGGGAGGCCTTGGGAAGCAACCGGGCCCCGC TGAAATCCGCCCACTGCCCAAGCGCAACGAGACCTCACCGCCTGGCCTTACTGGCACGGATAGCGATAACCTTTC CAGCGCGGCCGCTCGTGCAGCTGAACACGTCAACGGATCTCATGTCGCGAACGCCATCTCCTCTGTGCAAGGTCC CCGAGGCCCTCTGCCTGTCCCCACCCTTCCTCAAGCCACCCGCGCAGCACCACCCCGTCCCATCGCGGCCTCTCG GCCACCTCCCCAGCCTCCCAAGGATGTCACTCCATCCACCGACGATCTCCGCAATCGCGTGAAGCCGCAAGGCCC CGTCCCTCTCCCCGTCCGCAACGATTCCCTCCCTACTGCCCCTGGAATCCATCAATCCGCCAGCCAGAGAAGCCA GCAAGAGCAACGCGAGCGCCAGCAGCAGCAGGAGCAGCGTCGGCTGGAGCAACGCGAGAGAGAGCGAGAGCAGCG TGAACGTGAGCGCGAGCGCGAGCGAGAGAGAGAGGAAAGAGAGGCGTATAGGGCTCAGCAAGAGCGACCCCCTCT CGCGCCTTCCAAGTCTGCTCCTGGGACTGCTCAGCCGGCGACGCAGCCTGCTACAGGCCCCGCTGGTGCCCTTGA GGGACCACCGCCGGTTCTTCCCCTCCAGCCCAAGAAAGTGCAGATCCAAGCGGCTGATAAGCCAGCGAAACCTGC CGGCGGTGTTGCTGCTGCCGCTGCGGCATTGGAGAAGCCCAAGGAGAAGAGGATCAGTACCATGACTGAGGTTCA GATCATGGAGAAACTGCGTCAAGTGGTATCAGACGAGGACCCCAAGCTTATCTACAGCAAGATTAAGAAAGTCGG ACAAGGGTGAGTAAACACGAGGCCAATCGTTTCTTTTTGTTATTCCCTCGTTGGTACTTTTTGTTGGAGCGATGT CACTGACGAGACGTTTTTTGTGACTTCTAGCGCGTCTGGCCACGTCTATGTTGCGAAGGAGCTTGCCACCGGAAA GAAGGTTGCGATCAAGGAGATGGATCTCTCACACCAGCCGCGTAAAGAGCTCATCGTCAATGAGATCTTGGTGAT GAAGGAGTCGCAGCATCCTAACATTGTCAACTTCTTGAACTCGTATCTCGTGAAGAACAATGAGCTATGGGTGGT CATGGAGTACATGGAGGGAGGTGCGTTGACGGATGTTATTGAGAATAACACGTTGGAGGAAGATCAGATCTCGAG TATCTGCTTGGAGGTGCGTGGTTGGCGCTATGAGATAGGAACGTAACTGACGTTGACGTGACTGTAGACTTGCAA GGGTTTGCAACATCTGCATAGCCAGAGCATCATTCACCGTGACATCAAGTCCGACAACGTCCTTCTCGATGCTCA GGGTCGGGTCAAGATCAGTGCGTGTGCCCCCTGTGACATTTATCGCCACATTCTGACGTTTTCTTCAACAGCTGA CTTTGGCTTCTGCGCCAAACTAACGGACCAGAAGTCGAAGCGGGCGACCATGGTTGGTACTCCCTACTGGATGGC TCCCGAAGTCGTCAAGCAGAAGGAGTACGGTGCCAAGGTCGATATTTGGTCGCTTGGTATCATGGCGATTGAGAT GATTGAGAACGAGCCTCCCTATCTCGACGAAGAACCTCTCAAGGCGCTGTATCTGATCGCTACCAACGGAACTCC CACTCTGAAGAAGCCTGAGGCTCTGAGCAAGGAGCTCAAGAGCTTCTTGGCGGTGTGTCTCTGCGTGGATGTTGC TAGTCGGGCGACTGCCATTGAACTTTTGGATGTGAGTGCTCTTTTTTTCCTTTGAGGTGGGCCGATGCTGATCGC CGCGGTACCTGCCTTTTTACAGCACGAGTTCTTGAAAAAGGCGTGCCAATTGTCCGGGCTAGCTCCACTTTTGCG CTTCAAGACCAAGCAAGCGTCCTAAACGCTTGTGTTGGTCGTTTATGATTGATTGATTCGTTCTTTCTTCGTCTA TCTGTGTTTCTTCTTATAGTTGTTTGTTTGTTTTTGTTCCACCCATATACCGATATTCAAGATTTAAGGATACGA CCTCCCTCACCATGAACTATCCCCCCTAATGCTTCGTCGTCTTTCTGTCTTGTTTCTTTAAACCTCATGTGTGCC CTTCATTCTACCGTTGCCTGGAATTTACATGTTTCACTCGGTGCCCCCCTTTTTCGACGTTGTCTCCTTTTAAGC AGGTGCTTTCTGTAAATTCTTCTTCTCTATCTTTCCCTTCCTCCTTCCTTTTGCACATTTTGTTCTTTTACAATT ACGAGATCCCTTTTTTTTGTCTTTTATTATTACCCCCCTCTTGTCTGTTTGTTTGCTACACCCTCCATGTATTTG TTGCCGAATGTGTAACCTCTTTTTTTCGCCTGTTTCTT |
| Length | 3338 |