CC1G_02232
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_02232 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NKM9 | Functional description | TKL/TKL-ccin protein kinase |
| Location | Chr_10:1983714..1988365 | Strand | - |
| Gene length (nt) | 4652 | Transcript length (nt) | 3956 |
| CDS length (nt) | 3870 | Protein length (aa) | 1289 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7263929 | 48.4 | 0 | 1089 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB18261 | 40.3 | 8.143E-304 | 965 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_132545 | 42.3 | 5.444E-291 | 927 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_187489 | 41.8 | 6.652E-287 | 915 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_138451 | 39.7 | 1.666E-274 | 879 |
| Grifola frondosa | Grifr_OBZ74270 | 40.2 | 2.753E-265 | 852 |
| Flammulina velutipes | Flave_chr01AA00426 | 40.8 | 7.154E-262 | 842 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1078986 | 38.1 | 1.801E-257 | 829 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1507416 | 40 | 4.016E-227 | 740 |
| Lentinula edodes NBRC 111202 | Lenedo1_1177310 | 29.4 | 2.007E-203 | 670 |
| Auricularia subglabra | Aurde3_1_1271681 | 32.4 | 2.77E-174 | 584 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_15355 | 36.3 | 1.697E-174 | 584 |
| Schizophyllum commune H4-8 | Schco3_2737152 | 36.9 | 9.566E-166 | 558 |
| Lentinula edodes B17 | Lened_B_1_1_17497 | 34.5 | 1.049E-110 | 390 |
| Pleurotus ostreatus PC9 | PleosPC9_1_58721 | 47.7 | 2.541E-96 | 345 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 1924 |
| Description | TKL/TKL-ccin protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd21037 | MLKL_NTD | - | 216 | 346 |
| Pfam | PF07714 | Protein tyrosine and serine/threonine kinase | IPR001245 | 583 | 896 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR001245 | Serine-threonine/tyrosine-protein kinase, catalytic domain |
| IPR036537 | Adaptor protein Cbl, N-terminal domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0007166 | cell surface receptor signaling pathway | BP |
KEGG
| KEGG Orthology |
|---|
| K05126 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
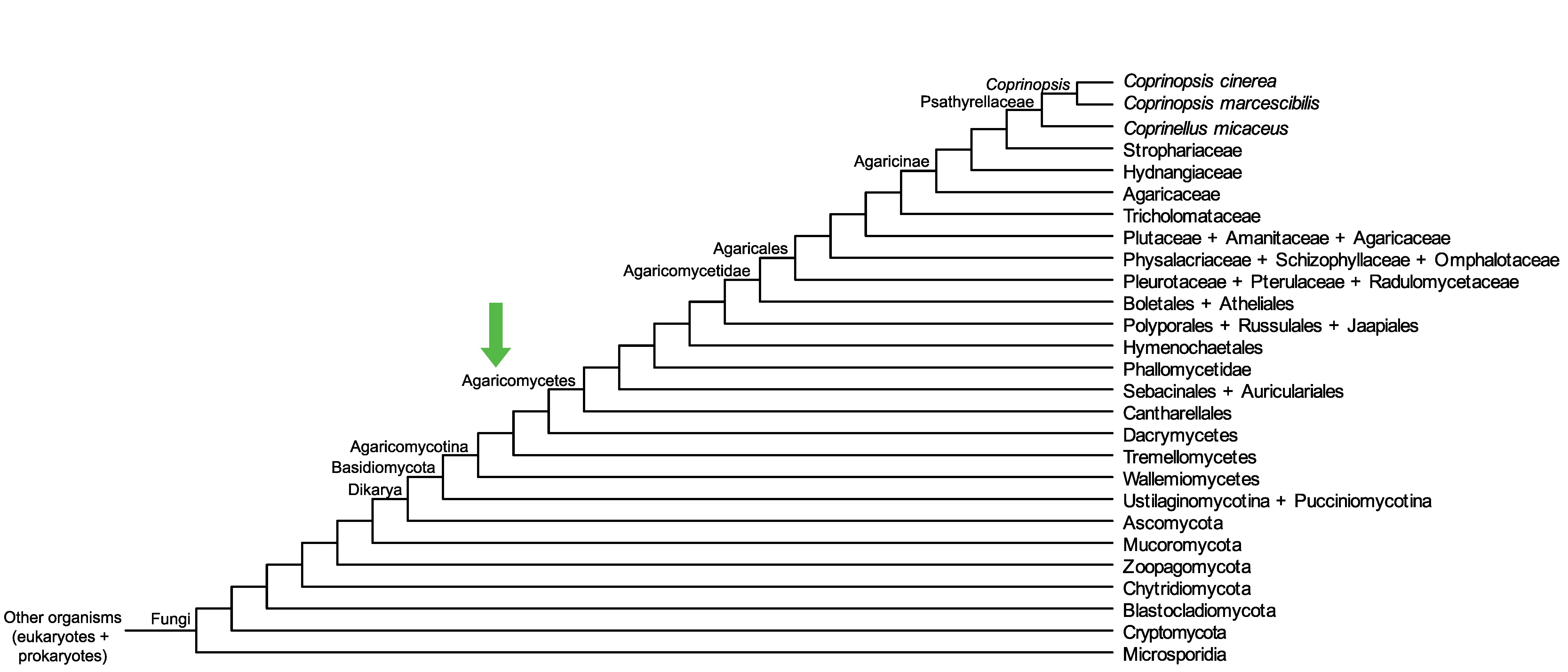
Conservation of CC1G_02232 across fungi.
Arrow shows the origin of gene family containing CC1G_02232.
Protein
| Sequence id | 1924 |
|---|---|
| Sequence |
>1924 MTSPPSDTSALTPRLRTTSLPQSTSNSKSAVTPQAAPVATLSPSSESSSDDEFPDLEAFRSRGQAPSSQYHLPRK QYPRSSPAIKIDGAGTDVRRAQSASASLASSLGSDLGFNIGRGRSLSPSSNPRSRDISPTPSAGLDASWWALPET GAPPWKDQPKRKSSIPASEVDGYDRTKERVALAVRSCLGNVVDVGHELLSIGVDLLELAPVPGLAPAARTLLNIW DAVDGVDVNFNRCLRLADRCARLLISIREEVREAGDAVGEELRDPIAALEEVFLHVLEFMRKQVRRPFLKRFLKR DETQEDIDECNKRLDDATKLFTTSIVIRILRKTYEMDAQRQKDTRAIIKTIISSSIPQTDPPLSPILLSPEDNRP TDDPSKEKPAPVTHFITTSNALGLSETIDISTIPPDNVIPLLNSLQESQNSLDRTNDIASLRQLMLKAIQASSDA EMIDMLQVKHEQMPDAIKTLQRALETIEKRRNQSPLDTIPPGVVIGKVKRRYSLKSGDNQEGGLQRSKTVLSIES TTSSKSTGGSSSAGGGSKRTRDTLEQEFIESGISALVRMSQGQNTNLPSWTITKFEINREKKIGVGGFSDVYRGT WKGRTVAIKVLKMETEKKLFIREVEIWKTLHHPHVLELYGASSALEPPWFFVSPYQKHGSLVDYLKKVGRDLQDP ALTPTFRPDRSPRKTSTIPLPLRSNRATSPTPQRSPLSALGPNTAKAPLREEFKVRSEWDLLRFMHEIAKGMEYL HSRGVLHGDLKAANVLVDDSYRCVITDFGQSEMRSTAFRITGRQPTRGTLRWQAPEILMGKSELTREADVYAFAI ACVEIINMGKLPWGSLLEDETIRNMVVKEDSRPEIAEDSRFNTPALQVILKACWNRDPDRRPPFFEVSKDLKRIR QTFENGDVMDTPKGSLTPLPEEQPPSSPSPDMKPLPLPPVGSPVGTAINILWPEASGGGHREETVANGPIEFPVP VFFKDLTPKPSVPISSVDDDVSDDIELVDLDYYPEVARVDATTAAVWNERRYRLLLTHDFHPSLVLPLWQPSAVS LGAVGYLSKPRGEFITLFNALYPDNSKHPLAKSFPSIHGYGKVEHGSQTRDTRSLSQKGWDSIAGLLSRANKNDH KEGDIPISRRFTYPLRAGHVSAHLCTQITKYVYLQDLKAAKRWFKANIDSIMHAYPTIQREDIYLVIGLLNTPNY GLFVSHSHPDGHVHFNVHKASKIGQPWGTFTTDSTAHAARNQSGPCYDEADTRPRIEASKVSIHGGEWETVLISR LRFRADEDEPTARL |
| Length | 1289 |
Coding
| Sequence id | CC1G_02232T0 |
|---|---|
| Sequence |
>CC1G_02232T0 ATGACATCCCCTCCCAGTGATACCTCTGCTCTGACCCCGCGATTGAGAACGACTTCACTACCCCAATCCACTTCC AATAGTAAATCCGCAGTGACACCACAGGCAGCGCCCGTTGCGACGCTTTCACCGTCCTCAGAATCAAGCAGTGAC GACGAGTTCCCGGACTTGGAGGCTTTCAGGAGCAGGGGACAAGCTCCATCTAGCCAATACCACCTCCCACGCAAG CAGTATCCGCGGTCGTCACCCGCTATCAAGATCGATGGGGCTGGCACCGACGTACGGAGGGCACAATCAGCATCT GCATCTCTCGCTTCCAGTCTGGGGAGCGATCTAGGGTTCAACATTGGACGAGGCAGGTCCCTCTCACCATCGTCG AATCCTAGGTCACGAGATATCTCCCCTACCCCTTCTGCTGGCCTGGATGCTTCGTGGTGGGCTTTACCGGAGACG GGGGCACCACCCTGGAAAGACCAACCGAAGCGAAAGAGTAGCATCCCAGCAAGTGAGGTAGATGGATACGACCGC ACGAAAGAGCGTGTCGCTTTGGCTGTCCGGTCTTGTCTGGGAAACGTCGTGGACGTGGGGCACGAGTTACTTTCC ATCGGAGTGGACCTTTTGGAATTGGCCCCAGTACCAGGGTTGGCTCCCGCAGCCAGAACATTGCTGAACATTTGG GATGCTGTCGATGGAGTTGATGTCAACTTCAACCGGTGTCTTCGGTTGGCAGATCGATGTGCACGACTACTCATA TCAATTCGCGAAGAAGTTCGGGAAGCAGGAGATGCTGTGGGAGAGGAATTGCGAGACCCGATAGCAGCCTTAGAA GAGGTGTTCCTCCATGTACTGGAGTTCATGAGAAAACAGGTTCGAAGACCGTTTTTGAAGCGTTTCTTGAAGAGA GATGAAACCCAGGAAGATATCGACGAGTGCAATAAGAGATTAGACGACGCTACGAAACTATTTACCACCTCGATC GTGATTCGTATTCTGAGGAAAACCTATGAGATGGACGCTCAACGCCAGAAAGACACCCGAGCGATCATCAAGACC ATCATTAGCTCCAGCATCCCCCAAACGGACCCTCCATTATCCCCCATCCTACTCTCTCCGGAGGATAACCGCCCT ACAGACGACCCCTCAAAGGAGAAGCCAGCACCTGTCACCCATTTCATAACCACTTCCAATGCCCTCGGTCTTTCA GAGACCATCGACATCTCGACTATCCCTCCGGACAACGTCATCCCTCTACTCAACAGTCTTCAAGAGAGCCAGAAC TCCCTCGACCGCACAAACGACATTGCATCCCTTCGACAGCTCATGCTAAAGGCTATCCAAGCCAGCAGCGACGCA GAAATGATCGACATGCTTCAGGTCAAGCACGAGCAGATGCCTGATGCGATCAAAACTCTGCAAAGAGCGCTCGAG ACGATAGAGAAGCGTCGCAACCAGTCACCTCTCGATACAATCCCGCCGGGGGTAGTTATCGGAAAGGTCAAGCGT CGGTATAGTCTCAAGTCTGGCGACAACCAGGAAGGGGGGCTACAACGGTCTAAGACTGTTCTCAGCATCGAAAGC ACCACCAGCTCGAAATCGACCGGAGGTTCGAGCAGTGCTGGCGGAGGATCAAAGAGAACGAGGGACACCTTGGAG CAGGAGTTCATCGAGAGTGGAATCTCTGCTCTAGTGCGAATGAGCCAGGGTCAGAACACCAACCTTCCCAGCTGG ACGATCACCAAGTTCGAAATCAATCGAGAGAAGAAGATTGGGGTTGGCGGCTTCTCGGATGTCTATCGAGGAACT TGGAAAGGCCGCACCGTGGCGATCAAGGTCTTGAAGATGGAGACTGAGAAGAAGCTGTTTATACGGGAGGTCGAG ATATGGAAGACGCTTCATCACCCCCATGTTCTTGAACTCTACGGGGCTAGCAGTGCTCTCGAGCCGCCGTGGTTC TTCGTAAGCCCGTATCAGAAACATGGCAGCTTGGTCGACTATCTCAAGAAGGTGGGGCGCGACCTTCAGGATCCT GCCTTGACCCCAACCTTCCGCCCTGATCGCTCTCCTAGGAAGACGTCCACCATCCCTCTCCCACTGAGGTCCAAT CGAGCGACTTCCCCTACGCCACAAAGATCACCGTTATCGGCCCTGGGACCCAATACCGCCAAAGCTCCGCTTCGG GAAGAGTTCAAGGTTCGGTCAGAATGGGATCTTTTGCGGTTCATGCATGAAATCGCGAAAGGAATGGAGTACCTT CATAGTCGCGGGGTTCTTCACGGTGATTTGAAGGCGGCGAACGTTCTCGTGGACGATTCCTACCGGTGTGTAATC ACGGACTTCGGGCAGAGCGAGATGAGGTCGACCGCTTTCCGAATCACTGGGAGGCAGCCAACACGTGGAACCCTT CGATGGCAGGCTCCAGAAATCCTGATGGGAAAATCGGAACTGACAAGAGAAGCAGACGTGTACGCTTTTGCCATC GCCTGTGTTGAAATCATCAATATGGGCAAGCTCCCTTGGGGAAGCTTGTTAGAAGACGAGACGATTCGAAACATG GTCGTCAAAGAAGATAGTCGCCCTGAAATCGCTGAAGACTCTAGATTTAACACGCCCGCACTCCAAGTGATACTG AAAGCTTGTTGGAACCGCGATCCGGACCGCCGCCCCCCTTTCTTTGAGGTGTCGAAGGATTTGAAGCGTATTCGT CAGACGTTTGAAAATGGGGATGTTATGGATACTCCCAAGGGTTCTCTGACACCTTTACCAGAGGAACAACCCCCG TCATCCCCATCGCCCGATATGAAGCCTTTGCCTCTCCCGCCGGTTGGCAGTCCGGTTGGAACCGCGATTAATATT CTTTGGCCGGAGGCCTCGGGTGGCGGCCACAGGGAAGAGACGGTGGCGAATGGGCCCATCGAATTTCCAGTTCCG GTATTCTTCAAAGACTTGACCCCGAAACCCTCGGTCCCAATTAGTAGTGTGGACGACGACGTCTCCGACGATATT GAATTGGTGGACCTCGATTACTACCCAGAAGTCGCGCGTGTCGATGCCACAACCGCAGCCGTTTGGAACGAAAGA AGGTATCGTTTGCTGTTAACGCACGATTTCCATCCTTCACTTGTCTTGCCACTGTGGCAACCTTCGGCCGTCTCC CTCGGTGCAGTCGGGTACCTTAGCAAACCTCGTGGGGAGTTTATCACTCTCTTCAACGCCTTGTACCCGGATAAC TCTAAACACCCTCTGGCCAAGAGCTTCCCTTCCATCCACGGCTATGGCAAAGTCGAGCACGGCTCCCAAACTCGT GATACGCGGTCGCTCTCTCAGAAGGGATGGGACTCCATAGCTGGGCTGCTGAGCCGTGCCAATAAGAACGATCAC AAGGAGGGTGATATCCCAATTAGCCGCCGCTTCACGTATCCATTACGCGCCGGTCACGTCTCCGCTCACCTCTGC ACCCAAATTACGAAATATGTCTATCTTCAAGATCTCAAGGCGGCGAAGAGGTGGTTCAAGGCGAACATCGATAGC ATAATGCACGCCTACCCGACGATACAAAGAGAAGACATCTATCTCGTTATTGGTCTCCTCAACACCCCCAATTAC GGGTTATTTGTCAGTCACAGTCATCCTGACGGTCATGTTCACTTTAACGTGCATAAAGCCAGTAAAATCGGTCAG CCTTGGGGCACTTTTACCACAGATTCTACTGCCCATGCAGCTCGCAATCAATCAGGACCTTGTTACGACGAAGCT GACACTCGTCCCCGAATCGAAGCAAGCAAAGTATCGATTCACGGAGGAGAGTGGGAAACCGTCTTGATTTCACGT CTGCGGTTCAGAGCAGATGAAGATGAGCCAACGGCGAGACTG |
| Length | 3870 |
Transcript
| Sequence id | CC1G_02232T0 |
|---|---|
| Sequence |
>CC1G_02232T0 CACCCACCCACAACCTCGATTCATCGAGGACACCCAGCGGGGAGCTGGTTCTTTCCCTGGACCAGCGCGAAGTAC AACTCTATTCAATGACATCCCCTCCCAGTGATACCTCTGCTCTGACCCCGCGATTGAGAACGACTTCACTACCCC AATCCACTTCCAATAGTAAATCCGCAGTGACACCACAGGCAGCGCCCGTTGCGACGCTTTCACCGTCCTCAGAAT CAAGCAGTGACGACGAGTTCCCGGACTTGGAGGCTTTCAGGAGCAGGGGACAAGCTCCATCTAGCCAATACCACC TCCCACGCAAGCAGTATCCGCGGTCGTCACCCGCTATCAAGATCGATGGGGCTGGCACCGACGTACGGAGGGCAC AATCAGCATCTGCATCTCTCGCTTCCAGTCTGGGGAGCGATCTAGGGTTCAACATTGGACGAGGCAGGTCCCTCT CACCATCGTCGAATCCTAGGTCACGAGATATCTCCCCTACCCCTTCTGCTGGCCTGGATGCTTCGTGGTGGGCTT TACCGGAGACGGGGGCACCACCCTGGAAAGACCAACCGAAGCGAAAGAGTAGCATCCCAGCAAGTGAGGTAGATG GATACGACCGCACGAAAGAGCGTGTCGCTTTGGCTGTCCGGTCTTGTCTGGGAAACGTCGTGGACGTGGGGCACG AGTTACTTTCCATCGGAGTGGACCTTTTGGAATTGGCCCCAGTACCAGGGTTGGCTCCCGCAGCCAGAACATTGC TGAACATTTGGGATGCTGTCGATGGAGTTGATGTCAACTTCAACCGGTGTCTTCGGTTGGCAGATCGATGTGCAC GACTACTCATATCAATTCGCGAAGAAGTTCGGGAAGCAGGAGATGCTGTGGGAGAGGAATTGCGAGACCCGATAG CAGCCTTAGAAGAGGTGTTCCTCCATGTACTGGAGTTCATGAGAAAACAGGTTCGAAGACCGTTTTTGAAGCGTT TCTTGAAGAGAGATGAAACCCAGGAAGATATCGACGAGTGCAATAAGAGATTAGACGACGCTACGAAACTATTTA CCACCTCGATCGTGATTCGTATTCTGAGGAAAACCTATGAGATGGACGCTCAACGCCAGAAAGACACCCGAGCGA TCATCAAGACCATCATTAGCTCCAGCATCCCCCAAACGGACCCTCCATTATCCCCCATCCTACTCTCTCCGGAGG ATAACCGCCCTACAGACGACCCCTCAAAGGAGAAGCCAGCACCTGTCACCCATTTCATAACCACTTCCAATGCCC TCGGTCTTTCAGAGACCATCGACATCTCGACTATCCCTCCGGACAACGTCATCCCTCTACTCAACAGTCTTCAAG AGAGCCAGAACTCCCTCGACCGCACAAACGACATTGCATCCCTTCGACAGCTCATGCTAAAGGCTATCCAAGCCA GCAGCGACGCAGAAATGATCGACATGCTTCAGGTCAAGCACGAGCAGATGCCTGATGCGATCAAAACTCTGCAAA GAGCGCTCGAGACGATAGAGAAGCGTCGCAACCAGTCACCTCTCGATACAATCCCGCCGGGGGTAGTTATCGGAA AGGTCAAGCGTCGGTATAGTCTCAAGTCTGGCGACAACCAGGAAGGGGGGCTACAACGGTCTAAGACTGTTCTCA GCATCGAAAGCACCACCAGCTCGAAATCGACCGGAGGTTCGAGCAGTGCTGGCGGAGGATCAAAGAGAACGAGGG ACACCTTGGAGCAGGAGTTCATCGAGAGTGGAATCTCTGCTCTAGTGCGAATGAGCCAGGGTCAGAACACCAACC TTCCCAGCTGGACGATCACCAAGTTCGAAATCAATCGAGAGAAGAAGATTGGGGTTGGCGGCTTCTCGGATGTCT ATCGAGGAACTTGGAAAGGCCGCACCGTGGCGATCAAGGTCTTGAAGATGGAGACTGAGAAGAAGCTGTTTATAC GGGAGGTCGAGATATGGAAGACGCTTCATCACCCCCATGTTCTTGAACTCTACGGGGCTAGCAGTGCTCTCGAGC CGCCGTGGTTCTTCGTAAGCCCGTATCAGAAACATGGCAGCTTGGTCGACTATCTCAAGAAGGTGGGGCGCGACC TTCAGGATCCTGCCTTGACCCCAACCTTCCGCCCTGATCGCTCTCCTAGGAAGACGTCCACCATCCCTCTCCCAC TGAGGTCCAATCGAGCGACTTCCCCTACGCCACAAAGATCACCGTTATCGGCCCTGGGACCCAATACCGCCAAAG CTCCGCTTCGGGAAGAGTTCAAGGTTCGGTCAGAATGGGATCTTTTGCGGTTCATGCATGAAATCGCGAAAGGAA TGGAGTACCTTCATAGTCGCGGGGTTCTTCACGGTGATTTGAAGGCGGCGAACGTTCTCGTGGACGATTCCTACC GGTGTGTAATCACGGACTTCGGGCAGAGCGAGATGAGGTCGACCGCTTTCCGAATCACTGGGAGGCAGCCAACAC GTGGAACCCTTCGATGGCAGGCTCCAGAAATCCTGATGGGAAAATCGGAACTGACAAGAGAAGCAGACGTGTACG CTTTTGCCATCGCCTGTGTTGAAATCATCAATATGGGCAAGCTCCCTTGGGGAAGCTTGTTAGAAGACGAGACGA TTCGAAACATGGTCGTCAAAGAAGATAGTCGCCCTGAAATCGCTGAAGACTCTAGATTTAACACGCCCGCACTCC AAGTGATACTGAAAGCTTGTTGGAACCGCGATCCGGACCGCCGCCCCCCTTTCTTTGAGGTGTCGAAGGATTTGA AGCGTATTCGTCAGACGTTTGAAAATGGGGATGTTATGGATACTCCCAAGGGTTCTCTGACACCTTTACCAGAGG AACAACCCCCGTCATCCCCATCGCCCGATATGAAGCCTTTGCCTCTCCCGCCGGTTGGCAGTCCGGTTGGAACCG CGATTAATATTCTTTGGCCGGAGGCCTCGGGTGGCGGCCACAGGGAAGAGACGGTGGCGAATGGGCCCATCGAAT TTCCAGTTCCGGTATTCTTCAAAGACTTGACCCCGAAACCCTCGGTCCCAATTAGTAGTGTGGACGACGACGTCT CCGACGATATTGAATTGGTGGACCTCGATTACTACCCAGAAGTCGCGCGTGTCGATGCCACAACCGCAGCCGTTT GGAACGAAAGAAGGTATCGTTTGCTGTTAACGCACGATTTCCATCCTTCACTTGTCTTGCCACTGTGGCAACCTT CGGCCGTCTCCCTCGGTGCAGTCGGGTACCTTAGCAAACCTCGTGGGGAGTTTATCACTCTCTTCAACGCCTTGT ACCCGGATAACTCTAAACACCCTCTGGCCAAGAGCTTCCCTTCCATCCACGGCTATGGCAAAGTCGAGCACGGCT CCCAAACTCGTGATACGCGGTCGCTCTCTCAGAAGGGATGGGACTCCATAGCTGGGCTGCTGAGCCGTGCCAATA AGAACGATCACAAGGAGGGTGATATCCCAATTAGCCGCCGCTTCACGTATCCATTACGCGCCGGTCACGTCTCCG CTCACCTCTGCACCCAAATTACGAAATATGTCTATCTTCAAGATCTCAAGGCGGCGAAGAGGTGGTTCAAGGCGA ACATCGATAGCATAATGCACGCCTACCCGACGATACAAAGAGAAGACATCTATCTCGTTATTGGTCTCCTCAACA CCCCCAATTACGGGTTATTTGTCAGTCACAGTCATCCTGACGGTCATGTTCACTTTAACGTGCATAAAGCCAGTA AAATCGGTCAGCCTTGGGGCACTTTTACCACAGATTCTACTGCCCATGCAGCTCGCAATCAATCAGGACCTTGTT ACGACGAAGCTGACACTCGTCCCCGAATCGAAGCAAGCAAAGTATCGATTCACGGAGGAGAGTGGGAAACCGTCT TGATTTCACGTCTGCGGTTCAGAGCAGATGAAGATGAGCCAACGGCGAGACTGTGA |
| Length | 3956 |
Gene
| Sequence id | CC1G_02232T0 |
|---|---|
| Sequence |
>CC1G_02232T0 CACCCACCCACAACCTCGATTCATCGAGGACACCCAGCGGGGAGCTGGTTCTTTCCCTGGACCAGCGCGAAGTAC AACTCTATTCAATGACATCCCCTCCCAGTGATACCTCTGCTCTGACCCCGCGATTGAGAACGACTTCACTACCCC AATCCACTTCCAATAGTAAATCCGCAGTGACACCACAGGCAGCGCCCGTTGCGACGCTTTCACCGTCCTCAGAAT CAAGCAGTGACGACGAGTTCCCGGACTTGGAGGCTTTCAGGAGCAGGGGACAAGCTCCATCTAGCCAATACCACC TCCCACGCAAGCAGTATCCGCGGTCGTCACCCGCTATCAAGATCGATGGGGCTGGCACCGACGTACGGAGGGCAC AATCAGCATCTGCATCTCTCGCTTCCAGTCTGGGGAGCGATCTAGGGTTCAACATTGGACGAGGCAGGTCCCTCT CACCATCGTCGAATCCTAGGTCACGAGATATCTCCCCTACCCCTTCTGCTGGCCTGGATGCTTCGTGGTGGGCTT TACCGGAGACGGGGGCACCACCCTGGAAAGACCAACCGAAGCGAAAGAGTAGCATCCCAGCAAGTGAGGTAGATG GATACGACCGCACGAAAGAGGTGAGCTTCGCTCTTCGAACCACACAGTGCCGTCTCCTTTAGGGTGCATCAGTGA TCGGTTGACTGACTTTGCATCCCTTCTTTCTGGACAGCGTGTCGCTTTGGCTGTCCGGTCTTGTCTGGGAAACGT CGTGGACGTGGGGCACGAGTTACTTTCCATCGGAGTGGACCTTTTGGAATTGGCCCCAGTACCAGGGTTGGCTCC CGCAGCCAGAACATTGCTGAACATTTGGGATGCTGTCGATGGAGTTGATGTGCGTGTTCCGGTTTACTCGAGGAG CTAAAACCGACTTAGAGAGACTTCCTTCTAGGTCAACTTCAACCGGTGTCTTCGGTTGGCAGATCGATGTGCACG ACTACTCATATCAATTCGCGAAGAAGTTCGGGAAGCAGGAGATGCTGTGGGAGAGGAATTGCGAGACCCGATAGC AGCCTTAGAAGAGTGAGTCTTGTGATGGTTCTGACATTGGCTGATAACCCACATGGTCAATAGGGTGTTCCTCCA TGTACTGGAGTTCATGAGAAAACAGGTTCGAAGACCGTTTTTGAAGCGTTTCTTGAAGAGAGATGAAACCCAGGA AGATATCGACGAGTGCAATAAGAGATTAGACGACGCTACGAAACTATTTACCGTGAGTTGACCGAACCTTTCCCA TCGCTGTTGTCTAACAGCATGCCAGACCTCGATCGTGATTCGTATTCTGAGGAAAACCTATGAGATGGACGCTCA ACGCCAGAAAGACACCCGAGCGATCATCAAGACCATCATTAGCTCCAGCATCCCCCAAACGGACCCTCCATTATC CCCCATCCTACTCTCTCCGGAGGATAACCGCCCTACAGACGACCCCTCAAAGGAGAAGCCAGCACCTGTCACCCA TTTCATAACCACTTCCAATGCCCTCGGTCTTTCAGAGACCATCGACATCTCGACTATCCCTCCGGACAACGTCAT CCCTCTACTCAACAGTCTTCAAGAGAGCCAGAACTCCCTCGACCGCACAAACGACATTGCATCCCTTCGACAGCT CATGCTAAAGGCTATCCAAGCCAGCAGCGACGCAGAAATGATCGACATGCTTCAGGTCAAGCACGAGCAGATGCC TGATGCGATCAAAACTCTGCAAAGAGCGCTCGAGACGATAGAGAAGCGTCGCAACCAGTCACCTCTCGATACAAT CCCGCCGGGGGTAGTTATCGGAAAGGTCAAGCGTCGGTATAGTCTCAAGTCTGGCGACAACCAGGAAGGGGGGCT ACAACGGTCTAAGACTGTTCTCAGCATCGAAAGCACCACCAGCTCGAAATCGACCGGAGGTTCGAGCAGTGCTGG CGGAGGATCAAAGAGAACGAGGGACACCTTGGAGCAGGAGTTCATCGAGAGTGGAATCTCTGCTCTAGTGCGAAT GAGCCAGGGTCAGAACACCAACCTTCCCAGCTGGACGATCACCAAGTTCGAAATCAATCGAGAGAAGAAGATTGG GGTTGGCGGCTTCTCGGATGTCTATCGAGGAACTTGGAAAGGCCGCACCGTGGCGATCAAGGTCTTGAAGATGGA GACTGAGAAGAAGCTGTTTATACGGGAGGTCGAGATATGGAAGACGCTTCATCACCCCCATGTTCTTGAACTCTA CGGGGCTAGCAGTGCTCTCGAGCCGCCGTGGTTCTTCGTAAGCCCGTATCAGAAACATGGCAGCTTGGTCGACTA TCTCAAGAAGGTGGGGCGCGACCTTCAGGATCCTGCCTTGACCCCAACCTTCCGCCCTGATCGCTCTCCTAGGAA GACGTCCACCATCCCTCTCCCACTGAGGTCCAATCGAGCGACTTCCCCTACGCCACAAAGATCACCGTTATCGGC CCTGGGACCCAATACCGCCAAAGCTCCGCTTCGGGAAGAGTTCAAGGTTCGGTCAGAATGGGATCTTTTGCGGTT CATGCATGAAATCGCGAAAGGAATGGAGTACCTTCATAGTCGCGGGGTTCTTCACGGTGATTTGAAGGCGGCGAA CGTTCTCGTGGACGATTCCTACCGGTGTGTAATCACGGACTTCGGGCAGAGCGAGATGAGGTCGACCGCTTTCCG AATCACTGGGAGGCAGCCAACACGTAACGTCCCTCTGACTATCCTGGTCCCCCTATTACTAACTGACATTCCTCT AGGTGGAACCCTTCGATGGCAGGCTCCAGAAATCCTGATGGGAAAATCGGAACTGACAAGAGAAGCAGACGTGTA CGCTTTTGCCATCGCCTGTGTTGAAATCATCAATATGGGCAAGCTCCCTTGGGGAAGCTTGTTAGAAGACGAGAC GATTCGAAACATGGTCGTCAGTACGTTCTTCCATGTTCGCTGAAATGACTCTATTGGAGACTAACCCCCTCCTCC TCCACAGAAGAAGATAGTCGCCCTGAAATCGCTGAAGACTCTAGATTTAACACGCCCGCACTCCAAGTGATACTG AAAGCTTGTTGGAACCGCGATCCGGACCGCCGCCCCCCTTTCTTTGAGGTGTCGAAGGATTTGAAGCGTATTCGT CAGACGTTTGAAAATGGGGATGTTATGGATACTCCCAAGGGTTCTCTGACACCTTTACCAGAGGAACAACCCCCG TCATCCCCATCGCCCGATATGAAGCCTTTGCCTCTCCCGCCGGTTGGCAGTCCGGTTGGAACCGCGAGTACGTCT TAATTCTTGTTTCTTGAGCATCTCTTCGACTGTCTGACCATGTCACATCAGTTAATATTCTTTGGCCGGAGGCCT CGGGTACGTTTGATTGGTACTTTATGAAATGCTGGCTGACGTCGGGGTTCTGCCCTCAGGTGGCGGCCACAGGGA AGAGACGGTGGCGAATGGGCCCATCGAATTTCCAGTTCCGGTATTCTTCAAAGACTTGACCCCGAAACCCTCGGT CCCAATTAGTAGTGTGGACGACGACGTCTCCGACGATATTGAATTGGTGGACCTCGATTACTACCCAGAAGTCGC GCGTGTCGATGCCACAACCGCAGCCGTTTGGAACGAAAGAAGGTATCGTTTGCTGTTAACGCACGATTTCCATCC TTCACGTAGGTCCTTCCGAGAGTTATTTTAGTTATTCACTCACGTTGCTTCCAGTTGTCTTGCCACTGTGGCAAC CTTCGGCCGTCTCCCTCGGTGCAGTCGGGTACCTTAGCAAACCTCGTGGGGAGTTTATCACTCTCTTCAACGCCT TGTACCCGGATAACTCTAAACACCCTCTGGCCAAGAGCTTCCCTTCCATCCACGGCTATGGCAAAGTCGAGCACG GCTCCCAAACTCGTGATACGCGGTCGCTCTCTCAGAAGGGATGGGACTCCATAGCTGGGCTGCTGAGCCGTGCCA ATAAGAACGATCACAAGGAGGGTGATATCCCGTAAGCACTCCCCCGATGCAAACAGTTTTGATATTGACTGCTGA TCACCGTCTAACAGAATTAGCCGCCGCTTCACGTATCCATTACGCGCCGGTCACGTCTCCGCTCACCTCTGCACC CAAATTACGAAATATGTCTATCTTCAAGATCTCAAGGCGGCGAAGAGGTGGTTCAAGGCGAACATCGATAGCATA ATGCACGCCTACCCGACGATACAAAGAGAAGACATCTATCTCGGTAAGATCTTGGCCGTACCCCCTCAATGTCAC GGAAGGCTGACAGTGGTTATAGTTATTGGTCTCCTCAACACCCCCAATTACGGGTTATTTGTCAGTCACAGTCAT CCTGACGGTCATGTACGTGAACACCGCTTCAGACACTGACACCCCGAGGGGCTAACTCGCGAACTTAGGTTCACT TTAACGTGCATAAAGCCAGTAAAATCGGTCAGCCTTGGGGCACTTTTACCACAGATTCTACTGCCCATGCAGCTC GCAATCAATCAGGACCTTGTTACGACGAAGCTGACACTCGTCCCCGAATCGAAGCAAGCAAAGTATCGATTCACG GAGGAGAGTGGGAAACCGTCTTGATTTCACGTCTGCGGTTCAGAGCAGATGAAGATGAGCCAACGGCGAGACTGT GA |
| Length | 4652 |