CC1G_02503
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_02503 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NBP3 | Functional description | CAMK/CAMKL/GIN4 protein kinase |
| Location | Chr_9:982067..985518 | Strand | - |
| Gene length (nt) | 3452 | Transcript length (nt) | 3300 |
| CDS length (nt) | 3300 | Protein length (aa) | 1099 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7269950 | 45.7 | 5.789E-284 | 898 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB27944 | 44.2 | 1.58E-270 | 859 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_179815 | 43.8 | 6.209E-254 | 810 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_108248 | 43.8 | 6.47E-254 | 810 |
| Schizophyllum commune H4-8 | Schco3_2693043 | 45.2 | 1.551E-218 | 707 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_5721 | 37.8 | 7.255E-216 | 699 |
| Lentinula edodes B17 | Lened_B_1_1_9660 | 38.4 | 1.268E-215 | 698 |
| Grifola frondosa | Grifr_OBZ67823 | 43.8 | 2.326E-206 | 671 |
| Pleurotus eryngii ATCC 90797 | Pleery1_340616 | 52 | 7.121E-201 | 655 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1053218 | 74.4 | 6.345E-200 | 652 |
| Pleurotus ostreatus PC9 | PleosPC9_1_98890 | 78.3 | 5.283E-162 | 540 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_57189 | 74.9 | 5.925E-161 | 537 |
| Lentinula edodes NBRC 111202 | Lenedo1_1159006 | 75.1 | 6.766E-159 | 531 |
| Auricularia subglabra | Aurde3_1_1229635 | 57 | 6.678E-131 | 448 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 2166 |
| Description | CAMK/CAMKL/GIN4 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 52 | 315 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K02515 |
| K06668 |
| K18679 |
| K18680 |
EggNOG
| COG category | Description |
|---|---|
| D | Serine/Threonine protein kinases, catalytic domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
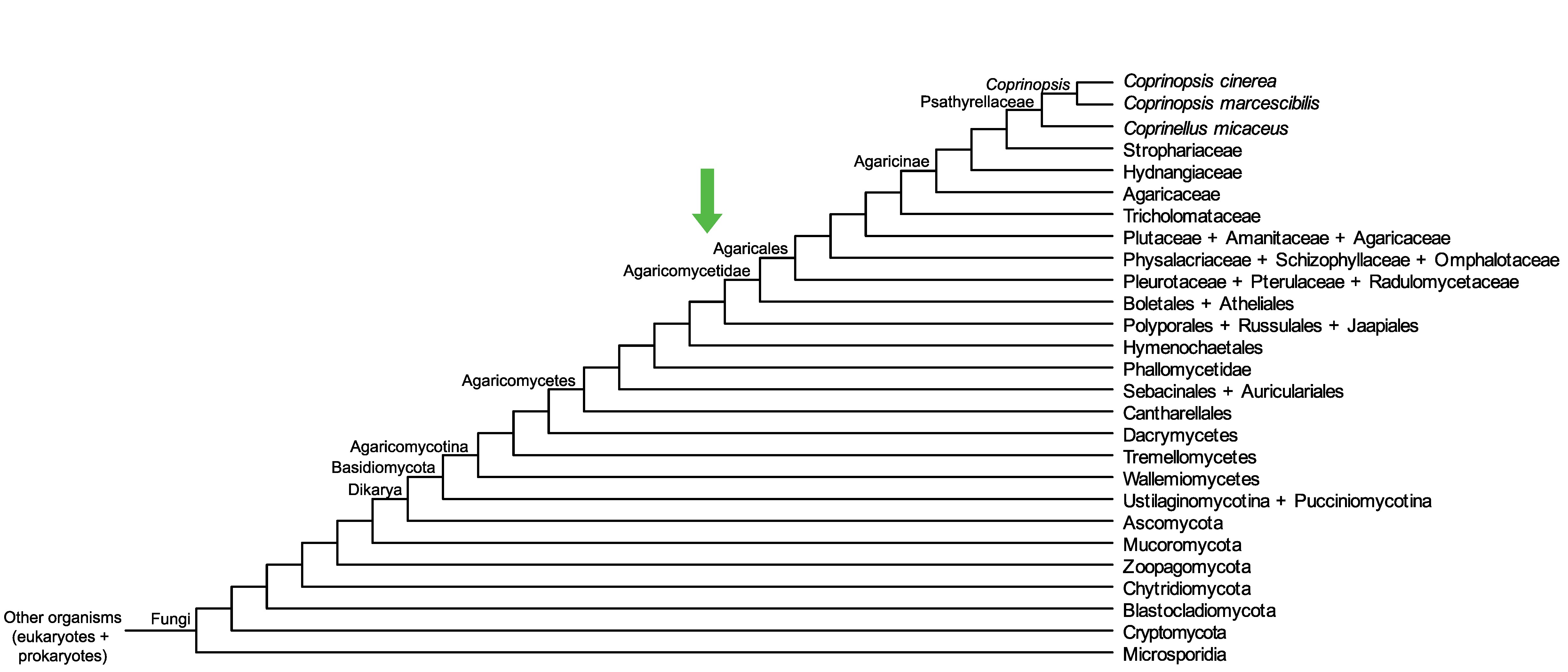
Conservation of CC1G_02503 across fungi.
Arrow shows the origin of gene family containing CC1G_02503.
Protein
| Sequence id | 2166 |
|---|---|
| Sequence |
>2166 MQNSQDSPPRAPPIQYNAPLGTRWAKEKAAAGGSAAFDLPSDPKSIGPWILGECIGKGASGRVKIARHQRTRQLA AVKILPIAPLVNSRASLATQQAKSEKQRLGIDREITMMKLMNHPNIMRIYDVYEGEKELFLVLEYVEGGELFDFL VNRGRLPPSEALLYFRQIIYGLNYAHTFSIIHRDLKPENILIASLDPPVVKIADWGMAAFAPPMLQLETSCGSPH YASPEIVNGEKYFGTATDIWSCGVILYALLTGRLPFDDKNVRTLLSKVKSGKYDIPSWMDPMAKDLLTKMLVVDV HKRITIPDILVHPWFVKGPTSTSQHTMDITLAQPPLPPSPSTLARPIASPDLIDPELFASLRIIWGRHADPDGAA IQQDLCSPAGQGLHAKAFYFLLDRYREESLRNRSDDAADRIQTPRSETECQSDKLYLGWDLDQTRARRSLEAVVN TSSPADKAVSPYRSTTPANEPFTADDPRSNELVLPTASRSAHQSIRHPMDTRKRQTTHSYSTTSTATSATRSTAS SINTISSPRSAIPKRGYTHSMTHGQTRSSHEKRRATDPSIQSMPGTPIPTTRHPNLLGEDRSFLKELQRRASAVP FHASVHPGRVPPPSLMDVDSSAVTLRQSMVERSDLRENVDRPGAVRTDVSVIPSDNHIHHRQSTRRRASLDAEKE NAMAVDDGWTHVETESANAHSRPSPFGVTTNREVGRDVVNTPETTHSIPSAKTKKEKERKSRPPPIELPPIHQRR TLVGSSFHTPSPGLHGGTGTAHTGSTSNRIMASPVVGEFKGWFSNLFNWKSHSAHPPASVFYSPEDIPKTREMTL RFFQSLAFGISRVILDLNADSSEIYHCRLDQSVVDLATNTTLKPVRLRVEFSLVVPASPGPTTGGGTGAMTSSAG TTPTPTPTTATSEFWTFTTGQLQQHAQQPLDPSSNTFLSAGTAGFGARATRNSLAALGRTASNAIGHHHQSHHHH HHLHHHPTVNTTSATTTTTAPTSGGQGATVNANATALLSTHWEMPLGCACVIVMTFEKGSGSAFRAVKQRLQDMF SDSQVVGSGVGAGVGVGAGGGVGAGGGAISPTCFSPVLTAAGGGDRMVM |
| Length | 1099 |
Coding
| Sequence id | CC1G_02503T0 |
|---|---|
| Sequence |
>CC1G_02503T0 ATGCAGAACAGTCAAGACAGCCCGCCTCGCGCACCTCCTATTCAGTACAATGCCCCACTGGGAACTCGCTGGGCA AAGGAAAAGGCCGCCGCTGGGGGCTCAGCAGCCTTCGATCTCCCTTCAGATCCAAAGTCTATCGGTCCCTGGATC CTGGGCGAATGCATCGGCAAAGGCGCTTCTGGTCGTGTAAAGATTGCCCGCCACCAACGAACCCGCCAGCTTGCA GCCGTCAAGATCCTCCCCATTGCACCGTTGGTCAACTCCAGAGCCTCTCTCGCCACCCAGCAGGCCAAATCCGAA AAGCAGCGTCTCGGCATCGACCGCGAAATCACAATGATGAAACTCATGAACCATCCCAACATCATGCGCATCTAC GACGTCTACGAGGGCGAGAAGGAGCTCTTTCTCGTTCTCGAGTACGTCGAGGGTGGCGAGCTCTTTGACTTTTTG GTCAACCGCGGTCGTCTTCCACCGAGCGAAGCTCTTCTCTATTTTCGACAGATCATCTATGGTCTCAACTATGCA CATACCTTTTCCATCATCCACAGAGATCTCAAGCCCGAGAATATCCTCATCGCCTCTCTCGACCCGCCTGTCGTC AAGATTGCCGACTGGGGCATGGCGGCCTTTGCTCCCCCTATGCTCCAACTCGAAACTAGTTGTGGATCTCCTCAC TACGCCAGTCCCGAGATCGTCAATGGAGAAAAGTACTTTGGAACGGCAACGGATATCTGGAGCTGTGGTGTCATT CTCTATGCTCTCTTGACTGGCCGACTTCCCTTTGACGACAAAAACGTTCGCACTCTACTCTCCAAGGTCAAGAGC GGCAAGTACGACATTCCTTCTTGGATGGATCCCATGGCCAAAGACCTCTTGACCAAAATGCTTGTCGTAGACGTT CACAAACGCATCACGATTCCAGACATTCTTGTCCACCCATGGTTCGTCAAGGGTCCGACATCCACCTCGCAACAT ACTATGGACATTACTTTGGCTCAACCTCCACTACCCCCTTCTCCTAGTACTCTGGCGCGCCCCATTGCTTCTCCT GATCTCATTGACCCTGAACTCTTTGCCTCGTTGCGTATCATCTGGGGACGACACGCCGATCCCGACGGCGCTGCC ATCCAACAAGACCTTTGTTCCCCCGCAGGTCAAGGGCTACACGCCAAGGCATTCTACTTCCTTTTGGACAGATAC AGAGAAGAATCACTTCGCAACCGGTCTGATGACGCTGCGGATAGGATACAAACTCCACGTTCTGAAACTGAATGT CAATCGGACAAACTCTATCTTGGCTGGGACCTCGATCAAACTCGTGCACGCAGGAGCCTCGAGGCTGTCGTGAAC ACTTCATCTCCGGCGGACAAAGCTGTCTCACCCTACAGATCGACCACGCCCGCGAATGAACCCTTTACTGCGGAT GATCCACGATCCAATGAATTGGTGCTGCCTACTGCGTCTCGCTCAGCCCATCAGTCCATTCGACATCCGATGGAT ACGCGAAAGAGGCAAACGACACATTCTTACTCTACGACATCTACGGCAACCTCCGCGACCCGGAGTACAGCTTCT TCGATAAACACTATCAGCTCTCCTCGGTCTGCCATTCCCAAGCGCGGGTATACGCATTCGATGACCCACGGCCAA ACACGAAGTTCTCATGAGAAACGACGTGCGACTGACCCGAGTATCCAGTCGATGCCTGGAACGCCTATACCGACC ACACGACACCCCAACCTCCTCGGAGAAGATCGATCGTTCTTGAAGGAGCTTCAGCGTCGTGCATCAGCTGTACCA TTCCATGCATCCGTGCACCCAGGTCGGGTCCCGCCGCCGTCTTTGATGGACGTGGACTCTTCTGCGGTCACGTTG AGACAGTCCATGGTCGAACGTTCCGATCTCCGTGAAAACGTGGATAGACCTGGGGCGGTTAGAACTGACGTTTCA GTTATTCCATCTGACAACCATATCCACCACCGGCAATCTACTCGTCGTCGTGCCTCACTAGACGCCGAAAAGGAG AACGCCATGGCTGTCGATGATGGGTGGACTCACGTCGAAACCGAGTCTGCTAATGCTCATTCTCGACCTAGTCCT TTCGGCGTAACGACCAATCGGGAGGTTGGACGAGATGTGGTCAACACGCCGGAGACCACCCACTCCATTCCGAGC GCCAAAACCAAAAAGGAGAAAGAAAGGAAAAGTCGACCGCCGCCGATTGAATTACCGCCCATCCATCAGCGTCGC ACTTTGGTTGGTTCCTCTTTCCATACGCCTTCTCCGGGCCTCCATGGTGGTACTGGGACTGCCCATACTGGTAGT ACGAGCAACAGGATTATGGCCTCCCCTGTTGTCGGCGAGTTCAAAGGCTGGTTCTCGAATTTGTTCAACTGGAAG AGCCACTCTGCTCATCCTCCCGCCTCTGTCTTCTACTCCCCAGAAGACATCCCCAAAACTCGCGAAATGACGCTC CGGTTCTTCCAGAGTCTCGCTTTTGGCATTTCTCGTGTTATTCTGGATCTTAACGCCGACAGCAGTGAGATTTAT CATTGTCGATTGGACCAGAGCGTGGTTGATCTTGCTACGAATACGACGCTGAAACCTGTCCGGTTGAGGGTGGAG TTTAGTCTTGTTGTTCCTGCTAGTCCTGGGCCCACTACTGGTGGTGGGACTGGTGCTATGACGAGCTCGGCTGGG ACTACGCCGACGCCTACGCCGACCACTGCTACCTCGGAATTCTGGACGTTTACTACTGGGCAACTTCAACAACAT GCGCAACAGCCGTTGGATCCTAGTTCCAACACCTTTTTGAGCGCTGGGACGGCTGGATTTGGAGCGAGAGCGACT CGGAATAGTCTTGCTGCACTTGGTCGGACGGCTTCGAATGCGATTGGGCATCACCATCAAAGTCACCATCATCAT CATCATCTTCACCATCATCCTACTGTAAATACGACCTCAGCTACTACCACTACTACGGCTCCTACCTCAGGTGGG CAGGGTGCTACGGTCAACGCCAACGCAACGGCTCTGCTCTCGACACACTGGGAGATGCCTCTCGGCTGTGCGTGT GTGATTGTGATGACGTTTGAGAAGGGGTCGGGGTCTGCGTTTAGGGCGGTTAAGCAGCGGTTGCAGGATATGTTT TCGGATTCGCAGGTGGTTGGGTCGGGTGTAGGCGCGGGTGTGGGTGTGGGTGCAGGTGGGGGTGTTGGGGCGGGA GGAGGCGCTATTTCGCCGACGTGTTTCAGTCCTGTTTTGACTGCTGCTGGTGGTGGGGATCGGATGGTGATG |
| Length | 3300 |
Transcript
| Sequence id | CC1G_02503T0 |
|---|---|
| Sequence |
>CC1G_02503T0 ATGCAGAACAGTCAAGACAGCCCGCCTCGCGCACCTCCTATTCAGTACAATGCCCCACTGGGAACTCGCTGGGCA AAGGAAAAGGCCGCCGCTGGGGGCTCAGCAGCCTTCGATCTCCCTTCAGATCCAAAGTCTATCGGTCCCTGGATC CTGGGCGAATGCATCGGCAAAGGCGCTTCTGGTCGTGTAAAGATTGCCCGCCACCAACGAACCCGCCAGCTTGCA GCCGTCAAGATCCTCCCCATTGCACCGTTGGTCAACTCCAGAGCCTCTCTCGCCACCCAGCAGGCCAAATCCGAA AAGCAGCGTCTCGGCATCGACCGCGAAATCACAATGATGAAACTCATGAACCATCCCAACATCATGCGCATCTAC GACGTCTACGAGGGCGAGAAGGAGCTCTTTCTCGTTCTCGAGTACGTCGAGGGTGGCGAGCTCTTTGACTTTTTG GTCAACCGCGGTCGTCTTCCACCGAGCGAAGCTCTTCTCTATTTTCGACAGATCATCTATGGTCTCAACTATGCA CATACCTTTTCCATCATCCACAGAGATCTCAAGCCCGAGAATATCCTCATCGCCTCTCTCGACCCGCCTGTCGTC AAGATTGCCGACTGGGGCATGGCGGCCTTTGCTCCCCCTATGCTCCAACTCGAAACTAGTTGTGGATCTCCTCAC TACGCCAGTCCCGAGATCGTCAATGGAGAAAAGTACTTTGGAACGGCAACGGATATCTGGAGCTGTGGTGTCATT CTCTATGCTCTCTTGACTGGCCGACTTCCCTTTGACGACAAAAACGTTCGCACTCTACTCTCCAAGGTCAAGAGC GGCAAGTACGACATTCCTTCTTGGATGGATCCCATGGCCAAAGACCTCTTGACCAAAATGCTTGTCGTAGACGTT CACAAACGCATCACGATTCCAGACATTCTTGTCCACCCATGGTTCGTCAAGGGTCCGACATCCACCTCGCAACAT ACTATGGACATTACTTTGGCTCAACCTCCACTACCCCCTTCTCCTAGTACTCTGGCGCGCCCCATTGCTTCTCCT GATCTCATTGACCCTGAACTCTTTGCCTCGTTGCGTATCATCTGGGGACGACACGCCGATCCCGACGGCGCTGCC ATCCAACAAGACCTTTGTTCCCCCGCAGGTCAAGGGCTACACGCCAAGGCATTCTACTTCCTTTTGGACAGATAC AGAGAAGAATCACTTCGCAACCGGTCTGATGACGCTGCGGATAGGATACAAACTCCACGTTCTGAAACTGAATGT CAATCGGACAAACTCTATCTTGGCTGGGACCTCGATCAAACTCGTGCACGCAGGAGCCTCGAGGCTGTCGTGAAC ACTTCATCTCCGGCGGACAAAGCTGTCTCACCCTACAGATCGACCACGCCCGCGAATGAACCCTTTACTGCGGAT GATCCACGATCCAATGAATTGGTGCTGCCTACTGCGTCTCGCTCAGCCCATCAGTCCATTCGACATCCGATGGAT ACGCGAAAGAGGCAAACGACACATTCTTACTCTACGACATCTACGGCAACCTCCGCGACCCGGAGTACAGCTTCT TCGATAAACACTATCAGCTCTCCTCGGTCTGCCATTCCCAAGCGCGGGTATACGCATTCGATGACCCACGGCCAA ACACGAAGTTCTCATGAGAAACGACGTGCGACTGACCCGAGTATCCAGTCGATGCCTGGAACGCCTATACCGACC ACACGACACCCCAACCTCCTCGGAGAAGATCGATCGTTCTTGAAGGAGCTTCAGCGTCGTGCATCAGCTGTACCA TTCCATGCATCCGTGCACCCAGGTCGGGTCCCGCCGCCGTCTTTGATGGACGTGGACTCTTCTGCGGTCACGTTG AGACAGTCCATGGTCGAACGTTCCGATCTCCGTGAAAACGTGGATAGACCTGGGGCGGTTAGAACTGACGTTTCA GTTATTCCATCTGACAACCATATCCACCACCGGCAATCTACTCGTCGTCGTGCCTCACTAGACGCCGAAAAGGAG AACGCCATGGCTGTCGATGATGGGTGGACTCACGTCGAAACCGAGTCTGCTAATGCTCATTCTCGACCTAGTCCT TTCGGCGTAACGACCAATCGGGAGGTTGGACGAGATGTGGTCAACACGCCGGAGACCACCCACTCCATTCCGAGC GCCAAAACCAAAAAGGAGAAAGAAAGGAAAAGTCGACCGCCGCCGATTGAATTACCGCCCATCCATCAGCGTCGC ACTTTGGTTGGTTCCTCTTTCCATACGCCTTCTCCGGGCCTCCATGGTGGTACTGGGACTGCCCATACTGGTAGT ACGAGCAACAGGATTATGGCCTCCCCTGTTGTCGGCGAGTTCAAAGGCTGGTTCTCGAATTTGTTCAACTGGAAG AGCCACTCTGCTCATCCTCCCGCCTCTGTCTTCTACTCCCCAGAAGACATCCCCAAAACTCGCGAAATGACGCTC CGGTTCTTCCAGAGTCTCGCTTTTGGCATTTCTCGTGTTATTCTGGATCTTAACGCCGACAGCAGTGAGATTTAT CATTGTCGATTGGACCAGAGCGTGGTTGATCTTGCTACGAATACGACGCTGAAACCTGTCCGGTTGAGGGTGGAG TTTAGTCTTGTTGTTCCTGCTAGTCCTGGGCCCACTACTGGTGGTGGGACTGGTGCTATGACGAGCTCGGCTGGG ACTACGCCGACGCCTACGCCGACCACTGCTACCTCGGAATTCTGGACGTTTACTACTGGGCAACTTCAACAACAT GCGCAACAGCCGTTGGATCCTAGTTCCAACACCTTTTTGAGCGCTGGGACGGCTGGATTTGGAGCGAGAGCGACT CGGAATAGTCTTGCTGCACTTGGTCGGACGGCTTCGAATGCGATTGGGCATCACCATCAAAGTCACCATCATCAT CATCATCTTCACCATCATCCTACTGTAAATACGACCTCAGCTACTACCACTACTACGGCTCCTACCTCAGGTGGG CAGGGTGCTACGGTCAACGCCAACGCAACGGCTCTGCTCTCGACACACTGGGAGATGCCTCTCGGCTGTGCGTGT GTGATTGTGATGACGTTTGAGAAGGGGTCGGGGTCTGCGTTTAGGGCGGTTAAGCAGCGGTTGCAGGATATGTTT TCGGATTCGCAGGTGGTTGGGTCGGGTGTAGGCGCGGGTGTGGGTGTGGGTGCAGGTGGGGGTGTTGGGGCGGGA GGAGGCGCTATTTCGCCGACGTGTTTCAGTCCTGTTTTGACTGCTGCTGGTGGTGGGGATCGGATGGTGATGTAG |
| Length | 3300 |
Gene
| Sequence id | CC1G_02503T0 |
|---|---|
| Sequence |
>CC1G_02503T0 ATGCAGAACAGTCAAGACAGCCCGCCTCGCGCACCTCCTATTCAGTACAATGCCCCACTGGGAACTCGCTGGGCA AAGGAAAAGGCCGCCGCTGGGGGCTCAGCAGCCTTCGATCTCCCTTCAGATCCAAAGTCTATCGGTCCCTGGATC CTGGGCGAATGCATCGGCAAAGGCGCTTCTGGTCGTGTAAAGATTGCCCGCCACCAACGAACCCGCCAGCTTGCA GCCGTCAAGATCCTCCCCATTGCACCGTTGGTCAACTCCAGAGCCTCTCTCGCCACCCAGCAGGCCAAATCCGAA AAGCAGCGTCTCGGCATCGACCGCGAAATCACAATGATGAAACTCATGAACCATCCCAACATCATGCGCATCTAC GACGTCTACGAGGGCGAGAAGGAGCTCTTTCTCGTTCTCGAGTACGTCGAGGGTGGCGAGCTCTTTGACTTTTTG GTCAACCGCGGTCGTCTTCCACCGAGCGAAGCTCTTCTCTATTTTCGACAGATCATCTATGGTCTCAACTATGCA CATACCTTTTCCATCATCCACAGAGATCTCAAGCCCGAGAATATCCTCATCGCCTCTCTCGACCCGCCTGTCGTC AAGATTGCCGACTGGGGCATGGCGGCCTTTGCTCCCCCTATGCTCCAACTCGAAACTAGTTGTGGATCTCCTCAC TACGCCAGTCCCGAGATCGTCAATGGAGAAAAGTACTTTGGAACGGCAACGGATATCTGGAGCTGTGGTGTCATT CTCTATGCTCTCTTGACTGGCCGACTTCCCTTTGACGACAAAAACGTTCGCACTCTACTCTCCAAGGTCAAGAGC GGCAAGTACGACATTCCTTCTTGGATGGATCCCATGGCCAAAGACCTCTTGACCAAAATGCTTGTCGTAGACGTT CACAAACGCATCACGGTATGGATTACCGTCCTTGAGTAGTTCTTTGCTGACCGCTTTCCAGATTCCAGACATTCT TGTCCACCCATGGTTCGTCAAGGGTCCGACATCCACCTCGCAACATACTATGGACATTACTTTGGCTCAACCTCC ACTACCCCCTTCTCCTAGTACTCTGGCGCGCCCCATTGCTTCTCCTGATCTCATTGACCCTGAACTCTTTGCCTC GTTGCGTATCATCTGGGGACGACACGCCGATCCCGACGGCGCTGCCATCCAACAAGACCTTTGTTCCCCCGCAGG TCAAGGGCTACACGCCAAGGCATTCTACTTCCTTTTGGACAGATACAGAGAAGAATCACTTCGCAACCGGTCTGA TGACGCTGCGGATAGGATACAAACTCCACGTTCTGAAACTGAATGTCAATCGGACAAACTCTATCTTGGCTGGGA CCTCGATCAAACTCGTGCACGCAGGAGCCTCGAGGCTGTCGTGAACACTTCATCTCCGGCGGACAAAGCTGTCTC ACCCTACAGATCGACCACGCCCGCGAATGAACCCTTTACTGCGGATGATCCACGATCCAATGAATTGGTGCTGCC TACTGCGTCTCGCTCAGCCCATCAGTCCATTCGACATCCGATGGATACGCGAAAGAGGCAAACGACACATTCTTA CTCTACGACATCTACGGCAACCTCCGCGACCCGGAGTACAGCTTCTTCGATAAACACTATCAGCTCTCCTCGGTC TGCCATTCCCAAGCGCGGGTATACGCATTCGATGACCCACGGCCAAACACGAAGTTCTCATGAGAAACGACGTGC GACTGACCCGAGTATCCAGTCGATGCCTGGAACGCCTATACCGACCACACGACACCCCAACCTCCTCGGAGAAGA TCGATCGTTCTTGAAGGAGCTTCAGCGTCGTGCATCAGCTGTACCATTCCATGCATCCGTGCACCCAGGTCGGGT CCCGCCGCCGTCTTTGATGGACGTGGACTCTTCTGCGGTCACGTTGAGACAGTCCATGGTCGAACGTTCCGATCT CCGTGAAAACGTGGATAGACCTGGGGCGGTTAGAACTGACGTTTCAGTTATTCCATCTGACAACCATATCCACCA CCGGCAATCTACTCGTCGTCGTGCCTCACTAGACGCCGAAAAGGAGAACGCCATGGCTGTCGATGATGGGTGGAC TCACGTCGAAACCGAGTCTGCTAATGCTCATTCTCGACCTAGTCCTTTCGGCGTAACGACCAATCGGGAGGTTGG ACGAGATGTGGTCAACACGCCGGAGACCACCCACTCCATTCCGAGCGCCAAAACCAAAAAGGAGAAAGAAAGGAA AAGTCGACGTAAGTACCCGCTCCTGTCGGTCCCCCGAGTTATTGGCCCCTGGATAGATATCACCGGCATTTGGAA ATACCTTTACTCACGAATGCCGAATTTGTCATTTTACAGCGCCGCCGATTGAATTACCGCCCATCCATCAGCGTC GCACTTTGGTTGGTTCCTCTTTCCATACGCCTTCTCCGGGCCTCCATGGTGGTACTGGGACTGCCCATACTGGTA GTACGAGCAACAGGATTATGGCCTCCCCTGTTGTCGGCGAGTTCAAAGGCTGGTTCTCGAATTTGTTCAACTGGA AGAGCCACTCTGCTCATCCTCCCGCCTCTGTCTTCTACTCCCCAGAAGACATCCCCAAAACTCGCGAAATGACGC TCCGGTTCTTCCAGAGTCTCGCTTTTGGCATTTCTCGTGTTATTCTGGATCTTAACGCCGACAGCAGTGAGATTT ATCATTGTCGATTGGACCAGAGCGTGGTTGATCTTGCTACGAATACGACGCTGAAACCTGTCCGGTTGAGGGTGG AGTTTAGTCTTGTTGTTCCTGCTAGTCCTGGGCCCACTACTGGTGGTGGGACTGGTGCTATGACGAGCTCGGCTG GGACTACGCCGACGCCTACGCCGACCACTGCTACCTCGGAATTCTGGACGTTTACTACTGGGCAACTTCAACAAC ATGCGCAACAGCCGTTGGATCCTAGTTCCAACACCTTTTTGAGCGCTGGGACGGCTGGATTTGGAGCGAGAGCGA CTCGGAATAGTCTTGCTGCACTTGGTCGGACGGCTTCGAATGCGATTGGGCATCACCATCAAAGTCACCATCATC ATCATCATCTTCACCATCATCCTACTGTAAATACGACCTCAGCTACTACCACTACTACGGCTCCTACCTCAGGTG GGCAGGGTGCTACGGTCAACGCCAACGCAACGGCTCTGCTCTCGACACACTGGGAGATGCCTCTCGGCTGTGCGT GTGTGATTGTGATGACGTTTGAGAAGGGGTCGGGGTCTGCGTTTAGGGCGGTTAAGCAGCGGTTGCAGGATATGT TTTCGGATTCGCAGGTGGTTGGGTCGGGTGTAGGCGCGGGTGTGGGTGTGGGTGCAGGTGGGGGTGTTGGGGCGG GAGGAGGCGCTATTTCGCCGACGTGTTTCAGTCCTGTTTTGACTGCTGCTGGTGGTGGGGATCGGATGGTGATGT AG |
| Length | 3452 |