CC1G_03420
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_03420 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NQN5 | Functional description | Beta-hexosaminidase (EC 3.2.1.52) |
| Location | Chr_8:778496..780599 | Strand | - |
| Gene length (nt) | 2104 | Transcript length (nt) | 1635 |
| CDS length (nt) | 1635 | Protein length (aa) | 544 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN1502_nagA |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB14630 | 71.8 | 1.177E-277 | 852 |
| Agrocybe aegerita | Agrae_CAA7261537 | 67.6 | 2.312E-259 | 799 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_120598 | 66.8 | 2.425E-255 | 787 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1526800 | 65 | 3.427E-245 | 758 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_186352 | 64.5 | 5.581E-245 | 757 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_116762 | 64.1 | 1.07E-239 | 742 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1094009 | 63 | 1.188E-237 | 736 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_13165 | 62.2 | 6.766E-237 | 734 |
| Lentinula edodes NBRC 111202 | Lenedo1_1052620 | 61.6 | 3.656E-235 | 729 |
| Flammulina velutipes | Flave_chr06AA00028 | 60.3 | 2.786E-228 | 709 |
| Grifola frondosa | Grifr_OBZ71292 | 61.8 | 3.489E-216 | 674 |
| Lentinula edodes B17 | Lened_B_1_1_3886 | 59.9 | 3.279E-215 | 671 |
| Auricularia subglabra | Aurde3_1_1302918 | 57 | 4.629E-210 | 657 |
| Pleurotus ostreatus PC9 | PleosPC9_1_87509 | 69 | 9.586E-174 | 551 |
| Schizophyllum commune H4-8 | Schco3_66483 | 59.6 | 8.44E-149 | 479 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 2961 |
| Description | Beta-hexosaminidase (EC 3.2.1.52) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd06562 | GH20_HexA_HexB-like | - | 177 | 522 |
| Pfam | PF14845 | beta-acetyl hexosaminidase like | IPR029019 | 20 | 154 |
| Pfam | PF00728 | Glycosyl hydrolase family 20, catalytic domain | IPR015883 | 177 | 499 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 19 | 0.9839 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR029018 | Beta-hexosaminidase-like, domain 2 |
| IPR025705 | Beta-hexosaminidase |
| IPR029019 | Beta-hexosaminidase, eukaryotic type, N-terminal |
| IPR017853 | Glycoside hydrolase superfamily |
| IPR015883 | Glycoside hydrolase family 20, catalytic domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004563 | beta-N-acetylhexosaminidase activity | MF |
| GO:0005975 | carbohydrate metabolic process | BP |
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
KEGG
| KEGG Orthology |
|---|
| K12373 |
EggNOG
| COG category | Description |
|---|---|
| G | Glycoside hydrolase family 20 protein |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH20 |
Transcription factor
| Group |
|---|
| No records |
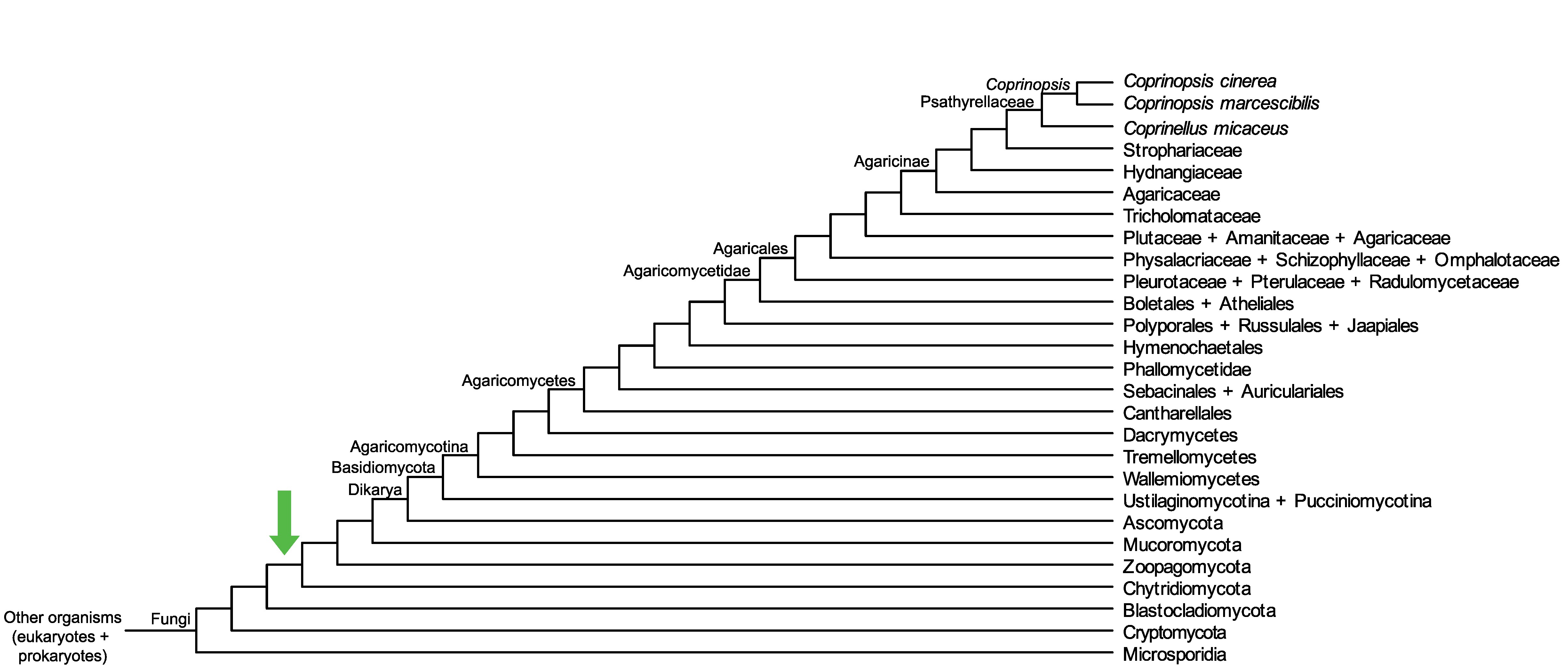
Conservation of CC1G_03420 across fungi.
Arrow shows the origin of gene family containing CC1G_03420.
Protein
| Sequence id | 2961 |
|---|---|
| Sequence |
>2961 MLILATFSAFLALLPGASALWPIPNDITTGTSPLRLARDFSINLNGVRHAPKDLVDAVSRTQHFLREDKLQLLVP DRGASLKSSISNSPFLKSLTVTLNSRTAKTRSIAEEAIADIGTRQEGYTLTVPADGSEAVLTANSTLGLFRGLTT FSQLWYELDGHVYTVQAPVSIRDAPQYVYRGLMLDTSRNYFPIADIKRTLDAMSWVKVNTLHWHIVDAQSFPLVV PGFEELSRKGAYNPASIYTPNDVKDIVNYAAQRGIDILVEVDTPGHTSIIHHAHPEHIACFEASPWTRYAYGKST VNFTSSLLTSVARLFPSKFFSTGGDEINQPCYEDDAATQKELEKQGKTLEQALDTFTQVTHRALHDMGKTTVVWQ EMVLDHKVTLSNDTVAMVWISSQHAKAVAQRGHRLIHAASDYFYLDCGGGGWIGNNPNGNSWCDPFKTWQKAYSF NPRANLTEEEAKLVLGGQQLLWAEQSGPSNLDPIVWPRAAASAEVFWSGHGRDGRTALPRLHDLAYRFVQRGVRA IPLQPQWCALRPGACDIDA |
| Length | 544 |
Coding
| Sequence id | CC1G_03420T0 |
|---|---|
| Sequence |
>CC1G_03420T0 ATGCTCATCCTCGCCACCTTCTCCGCGTTCTTAGCCTTACTGCCTGGAGCGTCTGCTTTATGGCCTATCCCCAAC GACATCACGACGGGTACGAGCCCGTTGAGGCTCGCTCGAGACTTTTCCATCAACCTGAACGGTGTGCGCCACGCA CCGAAGGACCTGGTCGACGCAGTCTCGCGCACACAGCACTTCCTGAGGGAGGACAAGCTCCAGCTCCTCGTTCCT GATCGCGGTGCATCCCTCAAGAGTTCCATCAGCAACTCGCCTTTCCTCAAGTCGCTCACAGTCACACTGAACAGC AGAACTGCGAAGACCAGGTCCATCGCTGAAGAGGCGATCGCAGATATCGGGACTCGCCAGGAGGGTTATACGCTC ACTGTTCCAGCGGACGGCTCGGAAGCGGTCTTAACTGCCAATTCGACCTTGGGGTTATTCCGTGGTCTGACGACG TTCAGCCAGCTGTGGTATGAGTTGGATGGCCATGTATACACAGTACAGGCTCCTGTCTCTATTCGAGATGCGCCA CAATATGTGTATCGCGGTCTTATGCTCGACACTTCGCGAAACTATTTCCCTATTGCCGACATCAAACGAACGCTG GATGCCATGAGCTGGGTCAAGGTCAACACCCTCCACTGGCACATCGTTGATGCTCAATCCTTCCCTCTCGTTGTT CCTGGGTTCGAGGAATTGTCACGCAAAGGAGCCTACAACCCGGCATCCATCTACACCCCCAATGACGTCAAGGAT ATCGTCAACTACGCTGCTCAGCGAGGAATCGATATTCTCGTTGAAGTAGACACTCCTGGGCACACGTCGATCATC CATCACGCGCATCCCGAACACATCGCTTGTTTCGAGGCCTCCCCCTGGACCCGCTACGCCTACGGCAAGTCTACT GTCAACTTTACATCCTCCCTTTTGACCTCGGTCGCTAGGTTGTTCCCTTCCAAGTTCTTCAGCACTGGAGGGGAT GAGATCAATCAGCCTTGCTATGAAGATGATGCCGCCACCCAGAAGGAATTGGAGAAGCAAGGAAAGACTCTGGAG CAGGCACTCGATACCTTCACTCAAGTTACGCACAGGGCTTTACATGACATGGGCAAGACAACTGTTGTCTGGCAG GAGATGGTGCTCGACCATAAAGTTACCCTCTCAAACGATACCGTAGCCATGGTATGGATCTCTTCACAGCACGCC AAAGCAGTTGCCCAGCGAGGCCACAGACTCATCCACGCTGCATCCGATTACTTCTACCTCGACTGCGGTGGTGGA GGTTGGATTGGCAACAATCCCAACGGAAACAGCTGGTGTGACCCATTCAAGACCTGGCAGAAGGCCTATTCTTTC AACCCCAGAGCCAACCTGACTGAAGAGGAAGCGAAGCTGGTTCTTGGAGGCCAACAACTCCTCTGGGCAGAGCAG TCTGGTCCGTCTAACTTGGATCCTATCGTGTGGCCCCGAGCTGCTGCATCCGCAGAGGTATTCTGGTCTGGCCAC GGCCGCGATGGTCGAACTGCATTACCGCGCTTGCATGATCTTGCATACCGTTTCGTTCAACGAGGCGTCCGTGCC ATCCCTTTGCAGCCGCAATGGTGTGCCCTTCGCCCTGGTGCATGTGATATCGATGCA |
| Length | 1635 |
Transcript
| Sequence id | CC1G_03420T0 |
|---|---|
| Sequence |
>CC1G_03420T0 ATGCTCATCCTCGCCACCTTCTCCGCGTTCTTAGCCTTACTGCCTGGAGCGTCTGCTTTATGGCCTATCCCCAAC GACATCACGACGGGTACGAGCCCGTTGAGGCTCGCTCGAGACTTTTCCATCAACCTGAACGGTGTGCGCCACGCA CCGAAGGACCTGGTCGACGCAGTCTCGCGCACACAGCACTTCCTGAGGGAGGACAAGCTCCAGCTCCTCGTTCCT GATCGCGGTGCATCCCTCAAGAGTTCCATCAGCAACTCGCCTTTCCTCAAGTCGCTCACAGTCACACTGAACAGC AGAACTGCGAAGACCAGGTCCATCGCTGAAGAGGCGATCGCAGATATCGGGACTCGCCAGGAGGGTTATACGCTC ACTGTTCCAGCGGACGGCTCGGAAGCGGTCTTAACTGCCAATTCGACCTTGGGGTTATTCCGTGGTCTGACGACG TTCAGCCAGCTGTGGTATGAGTTGGATGGCCATGTATACACAGTACAGGCTCCTGTCTCTATTCGAGATGCGCCA CAATATGTGTATCGCGGTCTTATGCTCGACACTTCGCGAAACTATTTCCCTATTGCCGACATCAAACGAACGCTG GATGCCATGAGCTGGGTCAAGGTCAACACCCTCCACTGGCACATCGTTGATGCTCAATCCTTCCCTCTCGTTGTT CCTGGGTTCGAGGAATTGTCACGCAAAGGAGCCTACAACCCGGCATCCATCTACACCCCCAATGACGTCAAGGAT ATCGTCAACTACGCTGCTCAGCGAGGAATCGATATTCTCGTTGAAGTAGACACTCCTGGGCACACGTCGATCATC CATCACGCGCATCCCGAACACATCGCTTGTTTCGAGGCCTCCCCCTGGACCCGCTACGCCTACGGCAAGTCTACT GTCAACTTTACATCCTCCCTTTTGACCTCGGTCGCTAGGTTGTTCCCTTCCAAGTTCTTCAGCACTGGAGGGGAT GAGATCAATCAGCCTTGCTATGAAGATGATGCCGCCACCCAGAAGGAATTGGAGAAGCAAGGAAAGACTCTGGAG CAGGCACTCGATACCTTCACTCAAGTTACGCACAGGGCTTTACATGACATGGGCAAGACAACTGTTGTCTGGCAG GAGATGGTGCTCGACCATAAAGTTACCCTCTCAAACGATACCGTAGCCATGGTATGGATCTCTTCACAGCACGCC AAAGCAGTTGCCCAGCGAGGCCACAGACTCATCCACGCTGCATCCGATTACTTCTACCTCGACTGCGGTGGTGGA GGTTGGATTGGCAACAATCCCAACGGAAACAGCTGGTGTGACCCATTCAAGACCTGGCAGAAGGCCTATTCTTTC AACCCCAGAGCCAACCTGACTGAAGAGGAAGCGAAGCTGGTTCTTGGAGGCCAACAACTCCTCTGGGCAGAGCAG TCTGGTCCGTCTAACTTGGATCCTATCGTGTGGCCCCGAGCTGCTGCATCCGCAGAGGTATTCTGGTCTGGCCAC GGCCGCGATGGTCGAACTGCATTACCGCGCTTGCATGATCTTGCATACCGTTTCGTTCAACGAGGCGTCCGTGCC ATCCCTTTGCAGCCGCAATGGTGTGCCCTTCGCCCTGGTGCATGTGATATCGATGCATGA |
| Length | 1635 |
Gene
| Sequence id | CC1G_03420T0 |
|---|---|
| Sequence |
>CC1G_03420T0 ATGCTCATCCTCGCCACCTTCTCCGCGTTCTTAGCCTTACTGCCTGGAGCGTCTGCTTTATGGCCTATCCCCAAC GACATCACGACGGGTACGAGCCCGTTGAGGCTCGCTCGAGACTTTTCCATCAACCTGAACGGTGTGCGCCACGCA CCGAAGGACCTGGTCGACGCAGTCTCGCGCACACAGCACTTCCTGAGGGAGGACAAGCTCCAGCTCCTCGTTCCT GATCGCGGTGCATCCCTCAAGAGTTCCATCAGCAACTCGCCTTTCCTCAAGTCGCTCACAGTCACACTGAACAGC AGAACTGCGAAGACCAGGTCCATCGCTGAAGAGGCGATCGCAGATATCGGGACTCGCCAGGAGGGTTATACGCTC ACTGTTCCAGCGGACGGCTCGGAAGCGGTCTTAACTGCCAATTCGACCTTGGGGTTATTCCGTGGTCTGACGACG TTCAGCCAGCTGTGGTATGAGTTGGATGGCCATGTATACACAGTACAGGCTCCTGTCTCTATTCGAGATGCGCCA CAATATGTGCGTGCAGTTTCTTTTCATGAATTCAGTGTGGATACTCACAGGCCGTTTTGACATGCAGGTGTATCG CGGTCTTATGCTCGACACTTCGCGAAACTAGTGAGAGGCTTCCCCAGTCCCTCAGTACAGGATGCTCACGTCTCT CAGTTTCCCTATTGCCGACATCAAACGAACGCTGGATGCCATGAGCTGGGTCAAGGTGTGTTTAAACAACGTTTT GACGAGCTTGATACAAATTCATGGCAGGTCAACACCCTCCACTGGCACATCGTTGATGCTCAATCCTTCCCTCTC GTTGTTCCTGGGTTCGAGGAATTGTCACGCAAAGGAGCCTACAACCCGGCATCCATCTACACCCCCAATGACGTC AAGGATATCGTCAACTACGCTGCTCAGCGAGGAATCGATATTCTCGTTGAAGTAGACACTCCTGGGCACACGTCG ATCATCCATCACGCGCATCCCGAACACATCGCTTGTTTCGAGGCCTCCCCCTGGACCCGCTACGCCTACGGCAAG TGTATTCTTTTGTGCGGCGTGTCTTTCTCATCCCAAACCCCGTCCACTAGAACCACCCGCTGGACAGCTACGATT GGCTTCTCCAGCTACTGTCAACTTTACATCCTCCCTTTTGACCTCGGTCGCTAGGTTGTTCCCTTCCAAGTTCTT CAGCACTGGAGGGGATGAGATCAATCAGCCTTGCTATGAAGATGATGCCGCCACCCAGAAGGAATTGGGTATGTT GCATTTTATGTGAATGGATAAGACCCTGATTATCTCGGACTTGTAGAGAAGCAAGGAAAGACTCTGGAGCAGGCA CTCGATACCTTCACTCAAGTTACGCACAGGGCTTTACATGACATGGGCAAGACAACTGTTGTCTGGCAGGGTATG TCTCATACTTACTCCTACGACCGCGTTGAGAACTCAAGCAGCGCTGTAGAGATGGTGCTCGACCATAAAGTTACC CTCTCAAACGATACCGTAGCCATGTATGTCCTTCCACTGACCTACACCACACCCACCGAACGTTCATATTGCTCT TTCCAGGGTATGGATCTCTTCACAGCACGCCAAAGCAGTTGCCCAGCGAGGCCACAGACTCATCCACGCTGCATC CGATTACTTCTACCTCGACTGCGGTGGTGGAGGTTGGATTGGCAACAATCCCAACGGAAACAGCTGGTGTGACCC ATTCAAGACCTGGCAGAAGGCCTATTCTTTCAACCCCAGAGCCAACCTGACTGAAGAGGAAGCGAAGCTGGTTCT TGGAGGCCAACAACTCCTCTGGGCAGAGCAGTCTGGTCCGTCTAACTTGGATCCTATCGTGTGGCCCCGAGCTGC TGCATCCGCAGAGGTGAGTTTAGATAGATACAAACGACGTGGGCTTGGAACTGAAACCTGATGCGCTGTACTCTA GGTATTCTGGTCTGGCCACGGCCGCGATGGTCGAACTGCATTACCGCGCTTGCATGATCTTGCATACCGTTTCGT TCAACGAGGCGTCCGTGCCATCCCTTTGCAGCCGCAATGGTGTGCCCTTCGCCCTGGTGCATGTGATATCGATGC ATGA |
| Length | 2104 |