CC1G_04354
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_04354 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N0Q1 | Functional description | AGC/AGC-Unique protein kinase |
| Location | Chr_1:717103..720222 | Strand | + |
| Gene length (nt) | 3120 | Transcript length (nt) | 2568 |
| CDS length (nt) | 2568 | Protein length (aa) | 855 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7267722 | 32.6 | 3.493E-93 | 327 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB24586 | 29.1 | 6.052E-81 | 290 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_130693 | 27.2 | 1.574E-66 | 245 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_114695 | 27.7 | 1.05E-62 | 233 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1452165 | 25.9 | 1.05E-59 | 224 |
| Lentinula edodes NBRC 111202 | Lenedo1_49119 | 28.1 | 1.936E-58 | 220 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1111154 | 24.9 | 7.134E-58 | 218 |
| Pleurotus ostreatus PC9 | PleosPC9_1_90612 | 25.4 | 2.66E-56 | 213 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_4465 | 26.6 | 2.18E-48 | 188 |
| Grifola frondosa | Grifr_OBZ79374 | 35.1 | 2.268E-36 | 149 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 3787 |
| Description | AGC/AGC-Unique protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 200 | 422 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K13302 |
| K13303 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
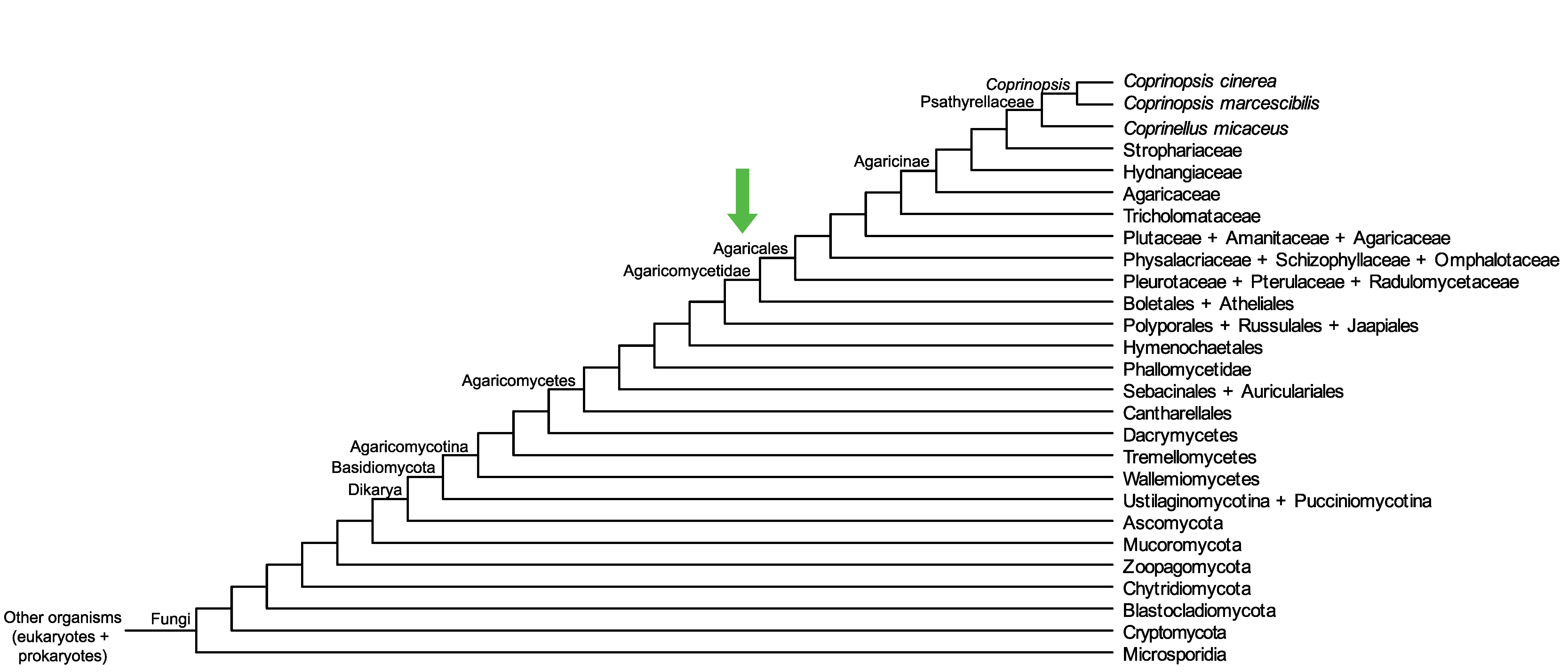
Conservation of CC1G_04354 across fungi.
Arrow shows the origin of gene family containing CC1G_04354.
Protein
| Sequence id | 3787 |
|---|---|
| Sequence |
>3787 MQTLIIEGDEPAFGQCTDTSTGTVLRDLSLSPRPSVVDGLGEVSTNSTTPPRLDVEWPNSPPLAVALRFSGIFDD ADVAEIEGDLTRQTHQSRSPTFDMTYDIHSFPNIKDINLEMGNDSDISEVVVMSQKQLPTALSTIPEANEPSPVL AYTTSLSDFDIISSYNAPDSDTRVMICQRKRNGNLYKIRSRRIYDHFPWMEQDILETLRDMGAPFLPYLKSVFRE ENQVHLVLDYWPSASLRELLAKYGTLGSQRVLFYASELLTGIANLHGVGIMHRNLNPDDIILDKRGHIVITNFEF ANTIPPSGVNANSFNSDLVLSIPRFHGYQAPEMVLGWAHDISVDCWGFGMLLYFMYFGKHPFQEDRNPVDHRVLR ARIIQGSLSPESLRLIHPHTRDIILKCVERNPRIRLNVDGIKNHEYFNNVPWGKVADKLVEVPPLPGFFNDNGSS GELLRRSHSSGLRHTLYQEGAEPVVATPEQPRPALLSPIPSHRPSHPLPLSPSPSAVTFASRPMSPSVLTEMSEP LEGNLSIQSPKPRTFRPFLDPQASAQSAKGGQVDSGMEIWDLLDREEQGSIASSNLGRSHVLGFLRPRKLRKNNS STSLFRPFVLNLSTSSLTRGLKKKKSRSSTRLGESSATVHDPQQRNQDVELPAGIEHIGSGIGFHRNTLSSDSGH SRSSASSNLPRFCRGGVKLGHRFSFSALRPSGARKIFGRNTRSRSLSSTMATNSGDASALGGLRLAHNGNSPAYV HGHTGALPGSHTSPRTPHEVQASTPILQMNPMSPSGSSSTSASASSSPRTEDGPLTPTTVACDEECQARVSSKAV MDFDEVNKERGRNDLTLRLVPSSRGLQLSV |
| Length | 855 |
Coding
| Sequence id | CC1G_04354T0 |
|---|---|
| Sequence |
>CC1G_04354T0 ATGCAAACTCTTATTATTGAAGGTGACGAACCCGCCTTTGGACAGTGCACCGATACCTCGACGGGAACCGTTCTT CGTGATCTCTCCCTCTCACCTCGACCTTCGGTTGTCGACGGACTTGGGGAAGTCTCTACCAACAGTACAACCCCT CCCCGCCTTGACGTGGAATGGCCCAATTCGCCTCCGTTGGCGGTTGCCCTCAGGTTCTCGGGCATATTCGACGAT GCTGATGTCGCAGAGATCGAAGGAGATCTTACTCGCCAGACTCACCAAAGCAGATCGCCCACTTTCGACATGACC TATGACATTCATAGCTTCCCGAATATCAAGGACATCAACTTGGAGATGGGGAACGACAGTGACATCTCCGAGGTT GTGGTCATGTCGCAGAAACAGCTCCCCACCGCGCTTTCTACGATCCCAGAGGCAAATGAGCCAAGCCCTGTTCTT GCGTATACGACGAGCCTGTCCGACTTTGATATCATCTCCTCTTACAATGCCCCTGATTCTGATACTCGTGTTATG ATCTGCCAAAGGAAAAGGAATGGAAACCTTTACAAGATTCGTTCTCGCCGCATCTATGACCATTTTCCCTGGATG GAGCAAGACATCCTGGAGACGCTACGAGATATGGGAGCTCCCTTCCTGCCCTATCTGAAGTCTGTCTTCCGAGAG GAAAATCAAGTGCATCTTGTTCTGGATTATTGGCCTTCAGCGAGTTTGAGAGAGCTCCTCGCAAAGTACGGAACT CTTGGCTCTCAGCGTGTCCTGTTCTATGCTTCTGAACTCCTGACTGGGATTGCCAACCTCCACGGTGTCGGGATC ATGCATCGCAACCTTAACCCTGACGATATCATCTTGGACAAGCGGGGGCACATTGTCATTACCAACTTTGAATTC GCCAACACGATTCCCCCTTCCGGTGTTAACGCCAATTCGTTTAACAGTGATTTGGTTTTGTCGATACCGAGGTTC CATGGATATCAGGCCCCAGAGATGGTTCTGGGTTGGGCGCATGATATCTCCGTTGATTGCTGGGGATTTGGGATG TTGCTTTACTTCATGTACTTTGGGAAGCACCCCTTCCAAGAGGACAGAAACCCGGTAGATCATCGCGTCTTGCGC GCACGCATCATTCAAGGCTCTTTGTCTCCAGAGTCTCTCAGGTTGATTCATCCGCACACGAGGGATATCATCTTG AAGTGTGTCGAAAGGAATCCGCGTATTCGATTGAATGTCGATGGGATTAAGAACCACGAATATTTTAACAACGTG CCTTGGGGAAAGGTGGCCGATAAGCTCGTCGAAGTCCCACCACTACCCGGGTTCTTCAACGATAATGGATCCAGT GGGGAGCTTTTGAGAAGGTCCCATTCGTCAGGCTTGCGACACACCCTCTACCAAGAGGGAGCCGAGCCTGTTGTC GCAACACCTGAGCAACCTCGACCTGCGCTACTGAGTCCTATCCCTTCCCATCGTCCTTCTCACCCGCTTCCTCTC TCCCCTTCTCCTTCCGCTGTCACATTCGCCTCTCGTCCCATGTCTCCATCTGTCCTGACTGAGATGTCAGAACCT CTGGAGGGCAATCTCAGCATCCAATCTCCTAAGCCCCGGACGTTTCGACCCTTTCTCGACCCTCAGGCGAGCGCT CAGTCGGCGAAAGGAGGACAAGTAGACTCGGGCATGGAAATCTGGGATCTACTGGATCGTGAGGAGCAAGGCTCG ATCGCCTCTTCCAACCTGGGCCGTAGCCACGTTCTTGGATTCCTCAGGCCTCGTAAGCTTCGCAAGAACAATTCG TCGACCAGTCTCTTCAGGCCGTTCGTACTCAACCTGAGCACGTCGTCCTTGACTCGTGGGTTGAAGAAGAAGAAG TCTAGAAGCTCCACTCGCTTGGGCGAGAGTTCCGCTACCGTACATGACCCTCAGCAGCGCAACCAGGACGTTGAG CTCCCAGCCGGAATCGAACATATCGGTAGTGGAATTGGATTCCACCGTAATACTCTCTCCTCTGATTCAGGCCAT TCGAGGTCTTCAGCTTCCTCAAACTTGCCCAGGTTCTGCCGCGGAGGTGTCAAGCTTGGTCATCGATTCTCATTC AGTGCTTTGCGGCCCAGCGGTGCTCGCAAGATCTTTGGAAGGAATACCCGCTCGAGGTCTCTCTCTTCTACTATG GCGACCAATTCCGGGGATGCTTCTGCACTCGGGGGCCTCCGGTTGGCTCACAATGGGAATAGCCCTGCCTATGTT CACGGTCACACAGGAGCTCTTCCCGGTTCACATACTTCTCCTAGGACGCCTCACGAGGTGCAAGCTAGTACTCCT ATCCTCCAAATGAATCCCATGTCACCTAGCGGTTCGTCATCCACCTCCGCTTCTGCGTCATCATCTCCTAGGACC GAGGATGGCCCATTGACTCCAACCACTGTGGCTTGCGACGAGGAGTGTCAAGCCCGAGTATCCTCCAAGGCAGTG ATGGACTTTGACGAGGTCAACAAAGAAAGGGGAAGGAATGATTTGACTTTGCGATTGGTTCCCAGTTCCAGAGGT CTCCAGCTATCGGTT |
| Length | 2568 |
Transcript
| Sequence id | CC1G_04354T0 |
|---|---|
| Sequence |
>CC1G_04354T0 ATGCAAACTCTTATTATTGAAGGTGACGAACCCGCCTTTGGACAGTGCACCGATACCTCGACGGGAACCGTTCTT CGTGATCTCTCCCTCTCACCTCGACCTTCGGTTGTCGACGGACTTGGGGAAGTCTCTACCAACAGTACAACCCCT CCCCGCCTTGACGTGGAATGGCCCAATTCGCCTCCGTTGGCGGTTGCCCTCAGGTTCTCGGGCATATTCGACGAT GCTGATGTCGCAGAGATCGAAGGAGATCTTACTCGCCAGACTCACCAAAGCAGATCGCCCACTTTCGACATGACC TATGACATTCATAGCTTCCCGAATATCAAGGACATCAACTTGGAGATGGGGAACGACAGTGACATCTCCGAGGTT GTGGTCATGTCGCAGAAACAGCTCCCCACCGCGCTTTCTACGATCCCAGAGGCAAATGAGCCAAGCCCTGTTCTT GCGTATACGACGAGCCTGTCCGACTTTGATATCATCTCCTCTTACAATGCCCCTGATTCTGATACTCGTGTTATG ATCTGCCAAAGGAAAAGGAATGGAAACCTTTACAAGATTCGTTCTCGCCGCATCTATGACCATTTTCCCTGGATG GAGCAAGACATCCTGGAGACGCTACGAGATATGGGAGCTCCCTTCCTGCCCTATCTGAAGTCTGTCTTCCGAGAG GAAAATCAAGTGCATCTTGTTCTGGATTATTGGCCTTCAGCGAGTTTGAGAGAGCTCCTCGCAAAGTACGGAACT CTTGGCTCTCAGCGTGTCCTGTTCTATGCTTCTGAACTCCTGACTGGGATTGCCAACCTCCACGGTGTCGGGATC ATGCATCGCAACCTTAACCCTGACGATATCATCTTGGACAAGCGGGGGCACATTGTCATTACCAACTTTGAATTC GCCAACACGATTCCCCCTTCCGGTGTTAACGCCAATTCGTTTAACAGTGATTTGGTTTTGTCGATACCGAGGTTC CATGGATATCAGGCCCCAGAGATGGTTCTGGGTTGGGCGCATGATATCTCCGTTGATTGCTGGGGATTTGGGATG TTGCTTTACTTCATGTACTTTGGGAAGCACCCCTTCCAAGAGGACAGAAACCCGGTAGATCATCGCGTCTTGCGC GCACGCATCATTCAAGGCTCTTTGTCTCCAGAGTCTCTCAGGTTGATTCATCCGCACACGAGGGATATCATCTTG AAGTGTGTCGAAAGGAATCCGCGTATTCGATTGAATGTCGATGGGATTAAGAACCACGAATATTTTAACAACGTG CCTTGGGGAAAGGTGGCCGATAAGCTCGTCGAAGTCCCACCACTACCCGGGTTCTTCAACGATAATGGATCCAGT GGGGAGCTTTTGAGAAGGTCCCATTCGTCAGGCTTGCGACACACCCTCTACCAAGAGGGAGCCGAGCCTGTTGTC GCAACACCTGAGCAACCTCGACCTGCGCTACTGAGTCCTATCCCTTCCCATCGTCCTTCTCACCCGCTTCCTCTC TCCCCTTCTCCTTCCGCTGTCACATTCGCCTCTCGTCCCATGTCTCCATCTGTCCTGACTGAGATGTCAGAACCT CTGGAGGGCAATCTCAGCATCCAATCTCCTAAGCCCCGGACGTTTCGACCCTTTCTCGACCCTCAGGCGAGCGCT CAGTCGGCGAAAGGAGGACAAGTAGACTCGGGCATGGAAATCTGGGATCTACTGGATCGTGAGGAGCAAGGCTCG ATCGCCTCTTCCAACCTGGGCCGTAGCCACGTTCTTGGATTCCTCAGGCCTCGTAAGCTTCGCAAGAACAATTCG TCGACCAGTCTCTTCAGGCCGTTCGTACTCAACCTGAGCACGTCGTCCTTGACTCGTGGGTTGAAGAAGAAGAAG TCTAGAAGCTCCACTCGCTTGGGCGAGAGTTCCGCTACCGTACATGACCCTCAGCAGCGCAACCAGGACGTTGAG CTCCCAGCCGGAATCGAACATATCGGTAGTGGAATTGGATTCCACCGTAATACTCTCTCCTCTGATTCAGGCCAT TCGAGGTCTTCAGCTTCCTCAAACTTGCCCAGGTTCTGCCGCGGAGGTGTCAAGCTTGGTCATCGATTCTCATTC AGTGCTTTGCGGCCCAGCGGTGCTCGCAAGATCTTTGGAAGGAATACCCGCTCGAGGTCTCTCTCTTCTACTATG GCGACCAATTCCGGGGATGCTTCTGCACTCGGGGGCCTCCGGTTGGCTCACAATGGGAATAGCCCTGCCTATGTT CACGGTCACACAGGAGCTCTTCCCGGTTCACATACTTCTCCTAGGACGCCTCACGAGGTGCAAGCTAGTACTCCT ATCCTCCAAATGAATCCCATGTCACCTAGCGGTTCGTCATCCACCTCCGCTTCTGCGTCATCATCTCCTAGGACC GAGGATGGCCCATTGACTCCAACCACTGTGGCTTGCGACGAGGAGTGTCAAGCCCGAGTATCCTCCAAGGCAGTG ATGGACTTTGACGAGGTCAACAAAGAAAGGGGAAGGAATGATTTGACTTTGCGATTGGTTCCCAGTTCCAGAGGT CTCCAGCTATCGGTTTGA |
| Length | 2568 |
Gene
| Sequence id | CC1G_04354T0 |
|---|---|
| Sequence |
>CC1G_04354T0 ATGCAAACTCTTATTATTGAAGGTGACGAACCCGCCTTTGGACAGTGCACCGATACCTCGACGGGAACCGTTCTT CGTGATCTCTCCCTCTCACCTCGACCTTCGGTTGTCGACGGACTTGGGGAAGTCTCTACCAACAGTACAACCCCT CCCCGCCTTGACGTGGAATGGCCCAATTCGCCTCCGTTGGCGGTGAGCTTCATTCCCATCCAGTTTCCCTAGAAT CGCCTAACTGATTCGTATTTGGCCAGGTTGCCCTCAGGTTCTCGGGCATATTCGACGATGCTGATGTCGCAGAGA TCGAAGGAGATCTTACTCGCCAGACTCACCAAAGCAGATCGCCCACTTTCGACATGACCTATGACATTCATGTAA GGTCTAGTTGAAGATGGGCGAGAAGGACGCTAACCCAGCTTCATTAGAGCTTCCCGAATATCAAGGACATCAACT TGGAGATGGGGAACGACAGTGACATCTCCGTAAGTCCTTGCGTTTCTGCAGCTGGAGTTGCTTAAGTTAATCGTG AGGCCGGCGGTGGGTAGGAGGTTGTGGTCATGTCGCAGAAACAGCTCCCCACCGCGCTTTCTACGATCCCAGAGG CAAATGAGCCAAGCCCTGTTCTTGCGGTCCGTGGTCTTCTTCATTATCTGTTGCCTGCTCACTGATTCGTGTTAA TCATGTCCAGTATACGACGAGCCTGTCCGACTTTGATATCATCTCCTCTTACAATGCCCCTGATTCTGATACTCG TGTTATGATCTGCCAAAGGAAAAGGAATGGAAACCTTTACAAGATTCGTTCTCGCCGCATCTATGACCATTTTCC CTGGATGGAGCAAGACATCCTGGAGACGCTACGAGATATGGGAGCTCCCTTCCTGCCCTATCTGAAGTCTGTCTT CCGAGAGGAAAATCAAGTGCATCTTGTTCTGGTGAGTTCTTCTGTGTACTCTTTACGCGCATACCCCTGACGACT GTGTTACCTGAAGGATTATTGGCCTTCAGCGAGTTTGAGAGAGCTCCTCGCAAAGTACGGAACTCTTGGCTCTCA GCGTGTCCTGTTCTATGCTTCTGAACTCGTTCGTCTTCTCCGCTCACTGCGTGGTTTCCGCTCACCTGCTCTCTT AGCTGACTGGGATTGCCAACCTCCACGGTGTCGGGATCATGCATCGCAACCTTAACCCTGACGATATCATCTTGG ACAAGCGGGGGCACATTGTCATTACCAACTTTGAATTCGCCAACACGATTCCCCCTTCCGGTGTTAACGCCAATT CGTTTAACAGTGATTTGGTTTTGTCGATACCGAGGTTCCATGGATATCAGGCCCCAGAGATGGTTCTGGGTTGGG CGCATGATATCTCCGTTGATTGCTGGGGATTTGGGATGTTGCTTTACTTCATGTACTTTGGGAAGGTGCGCCACG TTTTCTGCGATCTTGGGACTTGTCGTCCTAAATCATCTGTAGCACCCCTTCCAAGAGGACAGAAACCCGGTAGAT CATCGCGTCTTGCGCGCACGCATCATTCAAGGCTCTTTGTCTCCAGAGTCTCTCAGGTTGATTCATCCGCACACG AGGGATATCATCTTGAAGGTACGTTGCTCTTCATCCGCCTGTGTTATGGGAGTAATCAGTTTTTCCTAGTGTGTC GAAAGGAATCCGCGTATTCGATTGAATGTCGATGGGATTAAGAACCACGAATATTTTAACAACGTGTAAGTCACG CTCCACTTGCCCAGTTGACCTGAAACTGACACAATGCTTCAGGCCTTGGGGAAAGGTGGCCGATAAGCTCGTCGA AGGTCAGTTAAACGAGTATTTATTTCAGAGACTAAAACTCATTATACCCGACCACATGTAGTCCCACCACTACCC GGGTTCTTCAACGATAATGGATCCAGTGGGGAGCTTTTGAGAAGGTCCCATTCGTCAGGCTTGCGACACACCCTC TACCAAGAGGGAGCCGAGCCTGTTGTCGCAACACCTGAGCAACCTCGACCTGCGCTACTGAGTCCTATCCCTTCC CATCGTCCTTCTCACCCGCTTCCTCTCTCCCCTTCTCCTTCCGCTGTCACATTCGCCTCTCGTCCCATGTCTCCA TCTGTCCTGACTGAGATGTCAGAACCTCTGGAGGGCAATCTCAGCATCCAATCTCCTAAGCCCCGGACGTTTCGA CCCTTTCTCGACCCTCAGGCGAGCGCTCAGTCGGCGAAAGGAGGACAAGTAGACTCGGGCATGGAAATCTGGGAT CTACTGGATCGTGAGGAGCAAGGCTCGATCGCCTCTTCCAACCTGGGCCGTAGCCACGTTCTTGGATTCCTCAGG CCTCGTAAGCTTCGCAAGAACAATTCGTCGACCAGTCTCTTCAGGCCGTTCGTACTCAACCTGAGCACGTCGTCC TTGACTCGTGGGTTGAAGAAGAAGAAGTCTAGAAGCTCCACTCGCTTGGGCGAGAGTTCCGCTACCGTACATGAC CCTCAGCAGCGCAACCAGGACGTTGAGCTCCCAGCCGGAATCGAACATATCGGTAGTGGAATTGGATTCCACCGT AATACTCTCTCCTCTGATTCAGGCCATTCGAGGTCTTCAGCTTCCTCAAACTTGCCCAGGTTCTGCCGCGGAGGT GTCAAGCTTGGTCATCGATTCTCATTCAGTGCTTTGCGGCCCAGCGGTGCTCGCAAGATCTTTGGAAGGAATACC CGCTCGAGGTCTCTCTCTTCTACTATGGCGACCAATTCCGGGGATGCTTCTGCACTCGGGGGCCTCCGGTTGGCT CACAATGGGAATAGCCCTGCCTATGTTCACGGTCACACAGGAGCTCTTCCCGGTTCACATACTTCTCCTAGGACG CCTCACGAGGTGCAAGCTAGTACTCCTATCCTCCAAATGAATCCCATGTCACCTAGCGGTTCGTCATCCACCTCC GCTTCTGCGTCATCATCTCCTAGGACCGAGGATGGCCCATTGACTCCAACCACTGTGGCTTGCGACGAGGAGTGT CAAGCCCGAGTATCCTCCAAGGCAGTGATGGACTTTGACGAGGTCAACAAAGAAAGGGGAAGGAATGATTTGACT TTGCGATTGGTTCCCAGTTCCAGAGGTCTCCAGCTATCGGTTTGA |
| Length | 3120 |