CC1G_05049
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_05049 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NSP1 | Functional description | Other/FunK1 protein kinase |
| Location | Chr_8:1921119..1923779 | Strand | - |
| Gene length (nt) | 2661 | Transcript length (nt) | 2391 |
| CDS length (nt) | 2391 | Protein length (aa) | 796 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_132224 | 30.1 | 3.198E-66 | 243 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_122759 | 27 | 2.262E-54 | 206 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1249338 | 23.9 | 1.027E-21 | 101 |
| Auricularia subglabra | Aurde3_1_1411434 | 23.5 | 1.849E-18 | 91 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 4359 |
| Description | Other/FunK1 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF17667 | Fungal protein kinase | IPR040976 | 373 | 580 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR040976 | Fungal-type protein kinase |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| No records | ||
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | other FunK1 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
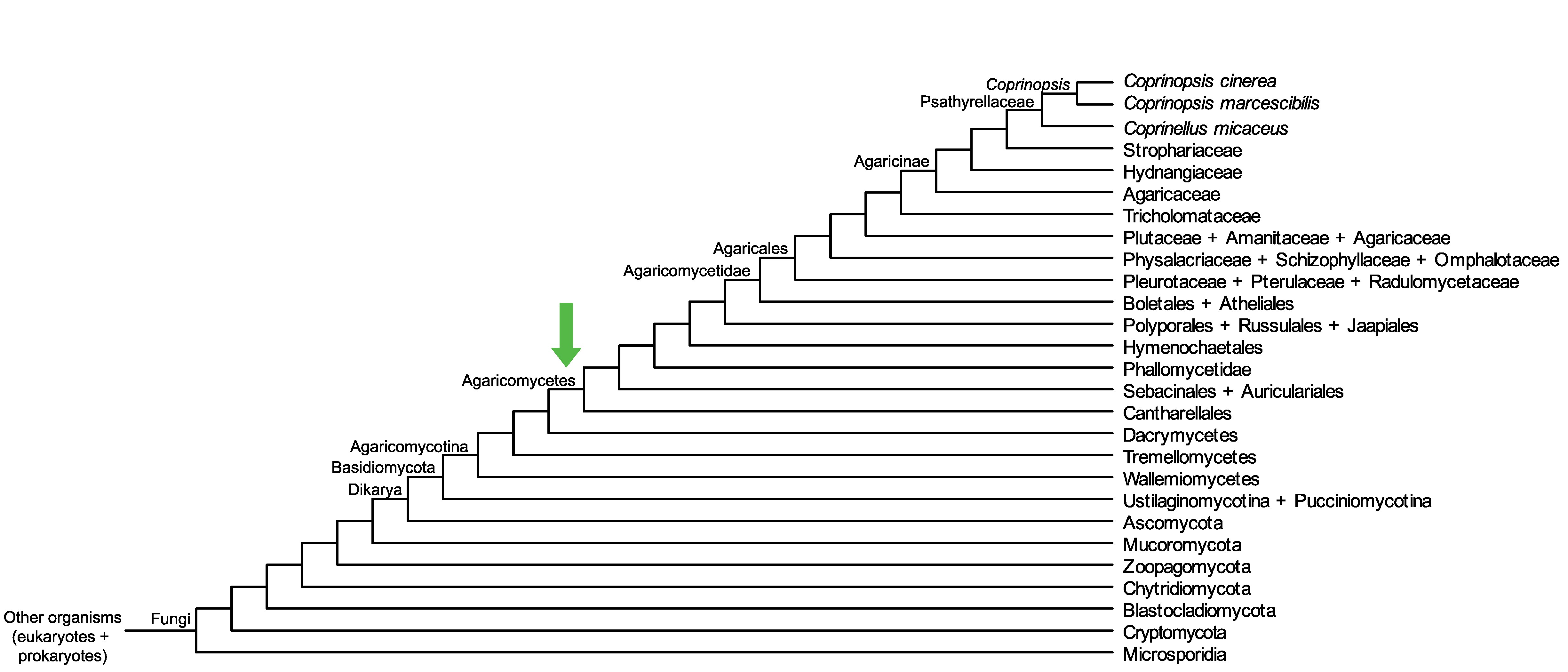
Conservation of CC1G_05049 across fungi.
Arrow shows the origin of gene family containing CC1G_05049.
Protein
| Sequence id | 4359 |
|---|---|
| Sequence |
>4359 MSASTPVIVRQAPFALNNRPERQIFAAYTPLSVHIDDASPPFLAKVNLTIGDPALKLDGTPQFNSLNEFFKDVNA VCEQMRAAFNFKRLLIFKETQNTIQQGHVSDTVAKPDLVAGFEDHWYDGRAPATQKKSEAGKGGSADPHKEDLKS HMLWPLIRLAGEIALSSETQGEQIQHAGTYLDLLLEARPDFKAAFGLLLSENSVFVLVGETGAGIRLFSFSWGSR DLRTAMRAMVYRLYNPGEWANTSIEACFRTASTKDKPPSCVYNLTFPCSDSQKAPVYKNYFCRYGKSSFGTRTHV FVHGGPQPQTINGFPLRAIKIQLCRDSGRFNEIMVLNHIHKNAVLPGVIRLLCSHSSSHLFGHRKEIWLGLDKEG EPFMAIKTVREMLMVAYDVLEITRMLFARRRVLHRDISKGNVMYISRRTMTQIIKTIKAPDATAVGKNQGDGSCY CFVRYLLGESIDSMETSALLIDFNYSEIVPEDESTGGHAGTPMFMARAVQNGEPIKLEPYHTVTLVPIPSSAHLG TYEKNFPDRISRFRELDRKENIEANEVGEPTHEILLPWRQRLYHDAESVYWLMYYWGLLAKPSTSIKEKGAEDFD PGIPANIWTELHAGRKTLSAHANDTFHPSYSPLLDLFVQMRAYLLTDPHWFPHDSPRAEPDYIHECFQRLILRFL KDNVDKPFMELKKSDHERLPFAVPGIPARSSSTTDTYLSDQRAQRPETPPIPREPFAVNYVAPPVVAGFQSTDNT PIQRTMSLPGKEGDEDSVIEQLVFPQGSSRQGPGRSQESNNDDVFT |
| Length | 796 |
Coding
| Sequence id | CC1G_05049T0 |
|---|---|
| Sequence |
>CC1G_05049T0 ATGTCCGCGTCGACCCCTGTTATCGTGCGGCAAGCGCCCTTCGCGCTGAACAACAGACCTGAACGCCAAATCTTC GCTGCGTACACACCGCTATCTGTGCACATCGACGATGCGAGTCCACCGTTCTTGGCAAAAGTCAACCTCACGATT GGGGATCCTGCTCTGAAGCTTGATGGAACCCCACAATTTAACTCGCTGAACGAGTTCTTCAAAGACGTGAATGCC GTCTGTGAGCAGATGAGGGCAGCATTCAACTTCAAGCGTCTCCTCATCTTCAAAGAGACACAAAATACCATCCAG CAAGGACATGTTTCAGATACAGTTGCAAAACCCGACTTGGTTGCCGGGTTCGAAGATCATTGGTACGATGGTCGA GCTCCTGCCACTCAGAAGAAATCCGAGGCCGGCAAGGGCGGCAGTGCGGACCCTCATAAAGAGGACCTCAAGTCC CACATGCTATGGCCTCTCATCAGGCTTGCCGGGGAGATTGCTTTGTCAAGCGAAACCCAGGGAGAACAAATCCAA CATGCTGGCACCTACCTCGACCTTCTGCTTGAGGCTCGGCCCGATTTCAAAGCCGCCTTCGGTCTTCTGCTCAGC GAAAACAGCGTGTTCGTGCTCGTTGGGGAGACGGGTGCGGGTATCCGCCTTTTCTCGTTTTCCTGGGGAAGCCGC GACCTGCGGACGGCGATGCGCGCTATGGTATACCGACTATACAACCCAGGGGAGTGGGCGAACACCTCTATCGAG GCATGCTTCAGGACAGCGTCGACCAAAGACAAGCCTCCTTCGTGTGTATACAACCTCACTTTCCCGTGCTCGGAT TCCCAAAAGGCGCCCGTATACAAGAATTACTTCTGTCGATATGGAAAAAGTTCCTTCGGTACTCGGACGCACGTT TTCGTCCACGGTGGCCCCCAGCCTCAAACTATCAACGGTTTTCCTCTCAGGGCCATCAAGATACAGCTCTGTCGC GACTCGGGTCGTTTTAACGAAATCATGGTGCTGAACCACATACACAAAAATGCCGTCCTCCCTGGGGTGATCCGT TTGCTCTGTTCCCATAGTTCCTCGCACCTCTTCGGACATAGGAAAGAAATCTGGTTGGGATTAGACAAAGAGGGC GAACCTTTCATGGCGATCAAGACCGTTCGGGAGATGCTCATGGTGGCCTATGATGTCCTAGAAATCACCCGCATG CTCTTCGCCCGACGCAGGGTCCTGCACCGCGACATAAGCAAAGGGAATGTCATGTATATTTCCCGGCGCACAATG ACACAGATCATTAAGACCATTAAGGCCCCCGACGCGACTGCCGTAGGAAAGAATCAAGGAGACGGTTCCTGCTAC TGTTTCGTCAGGTATTTGCTCGGCGAAAGCATCGATTCTATGGAGACTTCCGCCCTGTTAATCGATTTCAACTAT AGTGAAATAGTGCCTGAGGACGAGTCAACAGGGGGACATGCGGGAACTCCCATGTTCATGGCCAGAGCCGTTCAA AATGGAGAGCCGATCAAGCTCGAGCCTTATCACACGGTCACCTTGGTCCCGATACCAAGCTCTGCACACTTGGGT ACCTACGAGAAAAACTTCCCGGACCGCATTTCTCGGTTCCGTGAGCTGGACAGGAAGGAGAATATTGAGGCAAAC GAAGTCGGGGAGCCCACGCACGAGATTCTCCTCCCCTGGAGACAACGACTGTATCATGATGCCGAATCGGTCTAT TGGCTCATGTACTATTGGGGCTTGCTGGCAAAGCCTTCGACCAGTATCAAGGAGAAAGGGGCGGAAGATTTCGAC CCGGGCATCCCTGCGAACATCTGGACAGAATTGCACGCGGGCCGCAAGACGCTCTCTGCTCACGCGAACGACACA TTCCATCCCTCCTACAGCCCTCTTCTTGATCTCTTCGTGCAAATGAGGGCCTACCTGCTGACTGATCCTCATTGG TTCCCGCACGACTCTCCCAGGGCTGAGCCGGATTACATCCACGAATGTTTTCAGCGGCTTATTCTCAGATTTCTA AAGGACAACGTCGATAAGCCATTCATGGAATTGAAGAAGTCGGATCATGAGCGCCTCCCCTTCGCTGTTCCCGGG ATCCCTGCTCGTTCCTCCTCGACAACTGATACCTACCTGTCGGATCAGCGAGCTCAAAGGCCTGAAACTCCTCCA ATCCCCCGTGAGCCGTTCGCTGTCAATTATGTGGCACCCCCAGTCGTGGCTGGCTTCCAATCGACCGATAATACC CCGATTCAGCGCACGATGTCCCTCCCAGGCAAAGAGGGCGATGAAGACAGTGTCATTGAACAGCTTGTTTTCCCC CAAGGTTCGAGCCGCCAGGGTCCTGGTCGATCCCAAGAGTCGAACAACGATGATGTCTTCACT |
| Length | 2391 |
Transcript
| Sequence id | CC1G_05049T0 |
|---|---|
| Sequence |
>CC1G_05049T0 ATGTCCGCGTCGACCCCTGTTATCGTGCGGCAAGCGCCCTTCGCGCTGAACAACAGACCTGAACGCCAAATCTTC GCTGCGTACACACCGCTATCTGTGCACATCGACGATGCGAGTCCACCGTTCTTGGCAAAAGTCAACCTCACGATT GGGGATCCTGCTCTGAAGCTTGATGGAACCCCACAATTTAACTCGCTGAACGAGTTCTTCAAAGACGTGAATGCC GTCTGTGAGCAGATGAGGGCAGCATTCAACTTCAAGCGTCTCCTCATCTTCAAAGAGACACAAAATACCATCCAG CAAGGACATGTTTCAGATACAGTTGCAAAACCCGACTTGGTTGCCGGGTTCGAAGATCATTGGTACGATGGTCGA GCTCCTGCCACTCAGAAGAAATCCGAGGCCGGCAAGGGCGGCAGTGCGGACCCTCATAAAGAGGACCTCAAGTCC CACATGCTATGGCCTCTCATCAGGCTTGCCGGGGAGATTGCTTTGTCAAGCGAAACCCAGGGAGAACAAATCCAA CATGCTGGCACCTACCTCGACCTTCTGCTTGAGGCTCGGCCCGATTTCAAAGCCGCCTTCGGTCTTCTGCTCAGC GAAAACAGCGTGTTCGTGCTCGTTGGGGAGACGGGTGCGGGTATCCGCCTTTTCTCGTTTTCCTGGGGAAGCCGC GACCTGCGGACGGCGATGCGCGCTATGGTATACCGACTATACAACCCAGGGGAGTGGGCGAACACCTCTATCGAG GCATGCTTCAGGACAGCGTCGACCAAAGACAAGCCTCCTTCGTGTGTATACAACCTCACTTTCCCGTGCTCGGAT TCCCAAAAGGCGCCCGTATACAAGAATTACTTCTGTCGATATGGAAAAAGTTCCTTCGGTACTCGGACGCACGTT TTCGTCCACGGTGGCCCCCAGCCTCAAACTATCAACGGTTTTCCTCTCAGGGCCATCAAGATACAGCTCTGTCGC GACTCGGGTCGTTTTAACGAAATCATGGTGCTGAACCACATACACAAAAATGCCGTCCTCCCTGGGGTGATCCGT TTGCTCTGTTCCCATAGTTCCTCGCACCTCTTCGGACATAGGAAAGAAATCTGGTTGGGATTAGACAAAGAGGGC GAACCTTTCATGGCGATCAAGACCGTTCGGGAGATGCTCATGGTGGCCTATGATGTCCTAGAAATCACCCGCATG CTCTTCGCCCGACGCAGGGTCCTGCACCGCGACATAAGCAAAGGGAATGTCATGTATATTTCCCGGCGCACAATG ACACAGATCATTAAGACCATTAAGGCCCCCGACGCGACTGCCGTAGGAAAGAATCAAGGAGACGGTTCCTGCTAC TGTTTCGTCAGGTATTTGCTCGGCGAAAGCATCGATTCTATGGAGACTTCCGCCCTGTTAATCGATTTCAACTAT AGTGAAATAGTGCCTGAGGACGAGTCAACAGGGGGACATGCGGGAACTCCCATGTTCATGGCCAGAGCCGTTCAA AATGGAGAGCCGATCAAGCTCGAGCCTTATCACACGGTCACCTTGGTCCCGATACCAAGCTCTGCACACTTGGGT ACCTACGAGAAAAACTTCCCGGACCGCATTTCTCGGTTCCGTGAGCTGGACAGGAAGGAGAATATTGAGGCAAAC GAAGTCGGGGAGCCCACGCACGAGATTCTCCTCCCCTGGAGACAACGACTGTATCATGATGCCGAATCGGTCTAT TGGCTCATGTACTATTGGGGCTTGCTGGCAAAGCCTTCGACCAGTATCAAGGAGAAAGGGGCGGAAGATTTCGAC CCGGGCATCCCTGCGAACATCTGGACAGAATTGCACGCGGGCCGCAAGACGCTCTCTGCTCACGCGAACGACACA TTCCATCCCTCCTACAGCCCTCTTCTTGATCTCTTCGTGCAAATGAGGGCCTACCTGCTGACTGATCCTCATTGG TTCCCGCACGACTCTCCCAGGGCTGAGCCGGATTACATCCACGAATGTTTTCAGCGGCTTATTCTCAGATTTCTA AAGGACAACGTCGATAAGCCATTCATGGAATTGAAGAAGTCGGATCATGAGCGCCTCCCCTTCGCTGTTCCCGGG ATCCCTGCTCGTTCCTCCTCGACAACTGATACCTACCTGTCGGATCAGCGAGCTCAAAGGCCTGAAACTCCTCCA ATCCCCCGTGAGCCGTTCGCTGTCAATTATGTGGCACCCCCAGTCGTGGCTGGCTTCCAATCGACCGATAATACC CCGATTCAGCGCACGATGTCCCTCCCAGGCAAAGAGGGCGATGAAGACAGTGTCATTGAACAGCTTGTTTTCCCC CAAGGTTCGAGCCGCCAGGGTCCTGGTCGATCCCAAGAGTCGAACAACGATGATGTCTTCACTTGA |
| Length | 2391 |
Gene
| Sequence id | CC1G_05049T0 |
|---|---|
| Sequence |
>CC1G_05049T0 ATGTCCGCGTCGACCCCTGTTATCGTGCGGCAAGCGCCCTTCGCGCTGAACAACAGACCTGAACGCCAAATCTTC GCTGCGTACACACCGCTATCTGTGCACATCGACGATGCGAGTCCACCGTTCTTGGCAAAAGTCAACCTCACGATT GGGGATCCTGCTCTGAAGCTTGATGGAACCCCACAATTTAACTCGCTGAACGAGTTCTTCAAAGACGTGAATGCC GTCTGTGAGCAGATGAGGGCAGGTGCGTACTTTTCAAGTTCGTTGCCACTGACTCGGATCTGATCTGAACACCAG CATTCAACTTCAAGCGTCTCCTCATCTTCAAAGAGACACAAAATACCATCCAGCAAGGACATGTTTCAGATACAG TTGCAAAACCCGACTTGGTTGCCGGGTTCGAAGATCATTGGTACGATGGTCGAGCTCCTGCCACTCAGAAGAAAT CCGAGGCCGGCAAGGGCGGCAGTGCGGACCCTCATAAAGAGGACCTCAAGTCCCACATGCTATGGCCTCTCATCA GGCTTGCCGGGGAGATTGCTTTGTCAAGCGAAACCCAGGGAGAACAAATCCAACATGCTGGCACCTACCTCGACC TTCTGCTTGAGGCTCGGCCCGATTTCAAAGCCGCCTTCGGTCTTCTGCTCAGCGAAAACAGCGTGTTCGTGCTCG TTGGGGAGACGGGTGCGGGTATCCGCCTTTTCTCGTTTTCCTGGGGAAGCCGCGACCTGCGGACGGCGATGCGCG CTATGGTATACCGACTATACAACCCAGGGGAGTGGGCGAACACCTCTATCGAGGCATGCTTCAGGACAGCGTCGA CCAAAGACAAGCCTCCTTCGTGTGTATACAACCTCACTTTCCCGTGCTCGGATTCCCAAAAGGCGCCCGTATACA AGAATTACTTCTGTCGATATGGAAAAAGTTCCTTCGGTACTCGGACGCACGTTTTCGTCCACGGTGGCCCCCAGC CTCAAACTATCAACGGTTTTCCTCTCAGGGCCATCAAGATACAGCTCTGTCGCGACTCGGGTCGTTTTAACGAAA TCATGGTGCTGAACCACATACACAAAAATGCCGTCCTCCCTGGGGTGATCCGTTTGCTCTGTTCCCATAGTTCCT CGCACCTCTTCGGACATAGGAAAGAAATCTGGTTGGGATTAGACAAAGAGGGCGAACCTTTCATGGCGATCAAGA CCGTTCGGGAGATGCTCATGGTGGCCTATGATGTCCTAGAAAGTATGTCCATCTTTTCACGTCGATTGGGCAGAT ACTGACGGAACAAGTCACCCGCATGCTCTTCGCCCGACGCAGGGTCCTGCACCGCGACATAAGCAAAGGGAATGT CATGTATATTTCCCGGCGCACAATGACACAGATCATTAAGACCATTAAGGCCCCCGACGCGACTGCCGTAGGAAA GAATCAAGGAGACGGTTCCTGCTACTGTTTCGTCAGGTATTTGCTCGGCGAAAGGTAGGTGGCTGGTCTAGCTCT CTTCATATCTGACGACATGTTTCAGCATCGATTCTATGGAGACTTCCGCCCTGTTAATCGATTTCAACTATAGTG AAATAGTGCCTGAGGACGAGTCAACAGGGGGACATGCGGTAGGTGCCCGAACAGTGAGATGCCATGTTTTCTTTC AGAAAGGTCCTGTCACTCACCTGTTGGATCAAGGGAACTCCCATGTTCATGGCCAGAGCCGTTCAAAATGGAGAG CCGATCAAGCTCGAGCCTTATCACACGGTCACCTTGGTCCCGATACCAAGCTCTGCACACTTGGGTACCTACGAG AAAAACTTCCCGGACCGCATTTCTCGGTTCCGTGAGCTGGACAGGAAGGAGAATATTGAGGCAAACGAAGTCGGG GAGCCCACGCACGAGATTCTCCTCCCCTGGAGACAACGACTGTATCATGATGCCGAATCGGTCTATTGGCTCATG TACTATTGGGGCTTGCTGGCAAAGCCTTCGACCAGTATCAAGGAGAAAGGGGCGGAAGATTTCGACCCGGGCATC CCTGCGAACATCTGGACAGAATTGCACGCGGGCCGCAAGACGCTCTCTGCTCACGCGAACGACACATTCCATCCC TCCTACAGCCCTCTTCTTGATCTCTTCGTGCAAATGAGGGCCTACCTGCTGACTGATCCTCATTGGTTCCCGCAC GACTCTCCCAGGGCTGAGCCGGATTACATCCACGAATGTTTTCAGCGGCTTATTCTCAGATTTCTAAAGGACAAC GTCGATAAGCCATTCATGGAATTGAAGAAGTCGGATCATGAGCGCCTCCCCTTCGCTGTTCCCGGGATCCCTGCT CGTTCCTCCTCGACAACTGATACCTACCTGTCGGATCAGCGAGCTCAAAGGCCTGAAACTCCTCCAATCCCCCGT GAGCCGTTCGCTGTCAATGTGCGTATCTCGCTTGTTTCTATATCCTTCTAGCATTAACGTTGTTTCCCTTAGTAT GTGGCACCCCCAGTCGTGGCTGGCTTCCAATCGACCGATAATACCCCGATTCAGCGCACGATGTCCCTCCCAGGC AAAGAGGGCGATGAAGACAGTGTCATTGAACAGCTTGTTTTCCCCCAAGGTTCGAGCCGCCAGGGTCCTGGTCGA TCCCAAGAGTCGAACAACGATGATGTCTTCACTTGA |
| Length | 2661 |