CC1G_05428
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_05428 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NQ28 | Functional description | Uncharacterized protein |
| Location | Chr_8:295831..299870 | Strand | + |
| Gene length (nt) | 4040 | Transcript length (nt) | 2514 |
| CDS length (nt) | 2514 | Protein length (aa) | 837 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_194940 | 57.9 | 9.554E-160 | 504 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_121554 | 57.6 | 2.207E-159 | 503 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB28139 | 56.1 | 3.367E-159 | 503 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_146110 | 54.2 | 8.19E-155 | 490 |
| Pleurotus eryngii ATCC 90797 | Pleery1_451035 | 50.3 | 1.373E-149 | 475 |
| Grifola frondosa | Grifr_OBZ72754 | 54.6 | 1.359E-148 | 472 |
| Agrocybe aegerita | Agrae_CAA7268813 | 53.3 | 1.832E-146 | 466 |
| Lentinula edodes NBRC 111202 | Lenedo1_1033606 | 49.8 | 2.142E-134 | 431 |
| Auricularia subglabra | Aurde3_1_146384 | 50.1 | 9.043E-132 | 424 |
| Pleurotus ostreatus PC9 | PleosPC9_1_82769 | 46.7 | 5.975E-129 | 415 |
| Schizophyllum commune H4-8 | Schco3_235495 | 49.1 | 1.94E-127 | 411 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1020172 | 47.7 | 3.512E-126 | 407 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_22344 | 55.5 | 3.141E-109 | 358 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 4681 |
| Description | Uncharacterized protein |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00295 | Glycosyl hydrolases family 28 | IPR000743 | 104 | 422 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 22 | 0.9992 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR012334 | Pectin lyase fold |
| IPR011050 | Pectin lyase fold/virulence factor |
| IPR000743 | Glycoside hydrolase, family 28 |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004650 | polygalacturonase activity | MF |
| GO:0005975 | carbohydrate metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | Belongs to the glycosyl hydrolase 28 family |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH28 |
Transcription factor
| Group |
|---|
| No records |
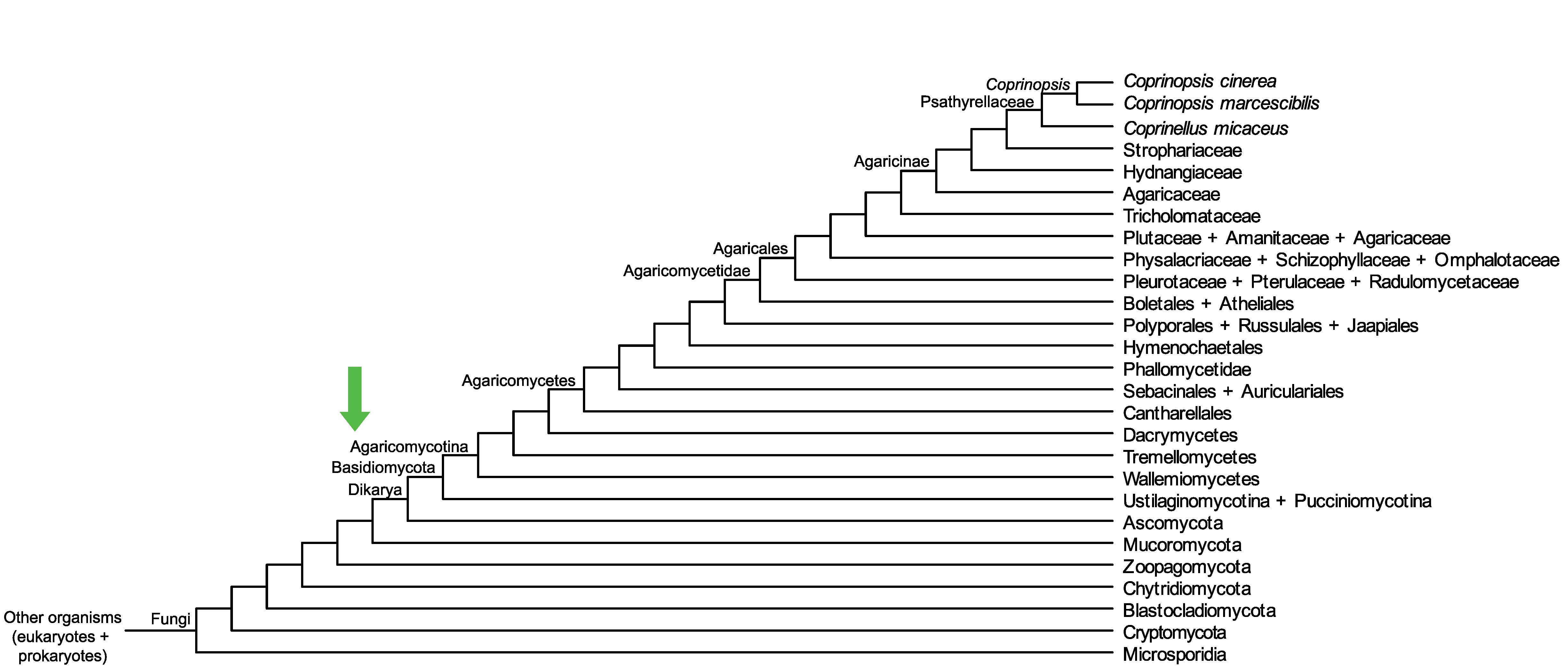
Conservation of CC1G_05428 across fungi.
Arrow shows the origin of gene family containing CC1G_05428.
Protein
| Sequence id | 4681 |
|---|---|
| Sequence |
>4681 MVLKSSWLLALCSLAVLGPVSGTPVDLDVATDKGKVCRLKPLGRGRDDTDQVEAAIKRCGNGGTTIFEEGDYKIT RKLFWELNSARVELKGRLSFEPKVEYWLDPANTFRVVFIQSQASWFVVTGKNFVIDGKKKGGIEGNGQPWWEYFT VVPRQDGNGRPIAFTLWKAKNAVIKDFNIISPPFWANAVAESSEVLYDGMFVNATNLNPKYFGQNVVWNTDGIDT YRSERITMKNWDVTSGDDCIAVKGNSSKIVARDFVCRGGTGIAFGSLGQYAHLTDYVTDVLVENVKVLRLPSRQQ PNMNYGIYFKAWDGPITGTPPTGGGGGRGLVSNAIFRNVIFDRVMTGVQIWQNFGSDGEAPVTSKVKFDGLLFEN IKGTTNTSNIVRLECSSEAPCSNFTFRNFRVHGPNKTESTYICDNTENIRGLPDLKRLSAKAKKGLGLPVGDART PAIEDDVGDGEGKNANVSENESLVEPKFYPWTISNRYYTANVHFSLHSLSRTYPAVFEGIPALVVAWTHGEPIEE YMKDLQKAMGGHEPEILLGVRLPGDKDKETGGIEEEDDLDSMMISYGFEYIDASRPLDPTRTRNEDEDGVPHLPR VLDALSAFMWPSMTTNTDLPHDDNDNNADGSDTDSPSSSQHTSPRPPRHQPTLDHIINRDPFAILQALEELDAEF NFEDNEEGGASGYHETLKQLAMLEAESKAAGIITDSPPSGFTDLSPTNANPPNQNSDLSIPFGLSETRSLKPKIS IGFEDDFSAFVTAPPEDDDDAEELRKDFAAVHIHSGRTSPDYDLLLSADPAGEFASRGSLYRSLGSMSDLGDLET SPNTAAKELESK |
| Length | 837 |
Coding
| Sequence id | CC1G_05428T0 |
|---|---|
| Sequence |
>CC1G_05428T0 ATGGTCCTCAAATCCAGTTGGCTTTTGGCGCTCTGTAGTCTCGCTGTTCTTGGACCTGTCTCTGGAACGCCTGTT GATCTTGATGTCGCCACCGACAAAGGAAAAGTGTGTCGATTGAAACCGTTGGGACGAGGAAGAGATGACACCGAT CAGGTCGAAGCTGCGATTAAGCGCTGTGGAAATGGCGGTACAACCATCTTTGAAGAGGGAGACTACAAAATTACA AGGAAACTCTTCTGGGAACTCAACTCGGCTCGAGTAGAGCTCAAAGGACGATTAAGCTTCGAGCCGAAGGTGGAG TACTGGCTCGACCCAGCCAACACCTTCCGGGTGGTCTTCATCCAAAGCCAAGCCTCCTGGTTCGTCGTAACCGGC AAGAACTTCGTGATCGACGGAAAGAAGAAGGGTGGGATTGAGGGGAACGGCCAGCCTTGGTGGGAATACTTTACG GTAGTCCCAAGGCAAGACGGGAACGGGCGGCCCATCGCGTTCACGTTGTGGAAAGCGAAGAATGCTGTTATCAAG GATTTCAACATCATCTCGCCACCGTTTTGGGCTAATGCGGTAGCGGAATCGAGTGAGGTTTTGTATGATGGTATG TTCGTCAATGCTACGAACTTAAATCCCAAGTACTTTGGACAAAATGTCGTCTGGAATACCGATGGAATTGATACA TATCGAAGCGAACGTATCACGATGAAGAATTGGGATGTTACCAGCGGAGATGATTGCATTGCCGTCAAGGGCAAT TCTTCCAAGATCGTTGCCCGAGACTTTGTTTGTCGGGGCGGAACTGGGATCGCATTCGGCTCGCTAGGCCAATAC GCTCACTTGACGGATTATGTCACCGATGTCTTGGTCGAGAATGTCAAGGTGTTGCGCCTTCCTTCAAGGCAACAA CCAAACATGAACTATGGTATCTACTTCAAAGCTTGGGACGGCCCAATCACCGGTACTCCTCCAACTGGAGGAGGC GGAGGACGAGGACTCGTCAGCAACGCCATCTTCCGAAACGTCATCTTCGACCGGGTCATGACCGGCGTCCAAATC TGGCAAAACTTTGGTAGCGACGGAGAAGCGCCCGTAACCAGCAAAGTCAAATTTGACGGCCTCCTTTTTGAGAAC ATAAAGGGAACTACGAACACCAGTAACATCGTACGATTGGAGTGCAGCTCTGAAGCCCCTTGCTCCAACTTCACC TTCCGCAACTTCCGAGTCCACGGCCCCAACAAGACTGAATCGACCTACATCTGTGACAACACCGAAAACATTCGA GGACTACCAGACTTGAAACGGCTATCGGCGAAGGCGAAGAAGGGGTTAGGTCTACCTGTGGGGGATGCACGTACA CCTGCGATAGAGGACGACGTAGGGGATGGAGAAGGGAAGAATGCGAATGTGAGCGAGAACGAGAGTTTGGTAGAA CCCAAGTTCTACCCATGGACGATCTCGAATCGATACTACACCGCCAACGTGCATTTCTCTCTACACTCCCTTTCA CGGACGTATCCTGCCGTGTTTGAGGGGATTCCGGCGCTAGTTGTAGCTTGGACGCATGGAGAGCCAATCGAGGAG TACATGAAGGATCTACAGAAGGCTATGGGTGGACACGAACCTGAAATCTTACTTGGTGTGCGGTTGCCGGGAGAT AAAGATAAAGAGACTGGGGGGATTGAAGAAGAGGATGATCTCGATTCTATGATGATCTCGTACGGGTTCGAGTAC ATCGACGCTTCAAGACCGCTGGATCCAACTCGAACGAGGAATGAAGACGAGGATGGCGTACCACACCTCCCACGA GTCCTCGACGCACTAAGCGCATTCATGTGGCCATCTATGACCACCAACACAGACCTCCCACACGACGACAACGAC AACAACGCCGACGGCTCCGACACCGACTCCCCTTCCTCCTCCCAGCACACCTCGCCCAGACCTCCCCGCCACCAA CCCACCCTCGACCACATCATCAACCGCGACCCCTTCGCAATCCTCCAAGCCCTCGAAGAACTGGATGCCGAATTC AACTTTGAAGACAACGAGGAAGGCGGGGCGAGCGGGTACCACGAAACACTCAAACAACTCGCCATGCTCGAAGCG GAATCCAAAGCTGCGGGTATCATAACCGATTCACCTCCGTCCGGATTCACCGACCTCTCGCCAACTAATGCGAAT CCACCGAATCAGAATTCAGATCTGTCAATACCCTTTGGCCTCTCAGAAACACGCTCTCTGAAACCAAAGATTTCG ATAGGCTTCGAGGACGATTTTAGCGCATTTGTTACTGCACCACCAGAGGACGACGACGATGCTGAAGAGCTCAGG AAGGACTTTGCGGCTGTACACATCCACTCTGGGAGGACGAGTCCGGATTACGATTTGCTGCTGTCAGCGGACCCA GCTGGTGAATTCGCAAGTCGAGGGTCATTATACAGGTCGCTCGGGTCCATGTCTGATCTAGGTGACCTCGAGACA TCACCAAACACCGCTGCTAAGGAACTGGAAAGCAAA |
| Length | 2514 |
Transcript
| Sequence id | CC1G_05428T0 |
|---|---|
| Sequence |
>CC1G_05428T0 ATGGTCCTCAAATCCAGTTGGCTTTTGGCGCTCTGTAGTCTCGCTGTTCTTGGACCTGTCTCTGGAACGCCTGTT GATCTTGATGTCGCCACCGACAAAGGAAAAGTGTGTCGATTGAAACCGTTGGGACGAGGAAGAGATGACACCGAT CAGGTCGAAGCTGCGATTAAGCGCTGTGGAAATGGCGGTACAACCATCTTTGAAGAGGGAGACTACAAAATTACA AGGAAACTCTTCTGGGAACTCAACTCGGCTCGAGTAGAGCTCAAAGGACGATTAAGCTTCGAGCCGAAGGTGGAG TACTGGCTCGACCCAGCCAACACCTTCCGGGTGGTCTTCATCCAAAGCCAAGCCTCCTGGTTCGTCGTAACCGGC AAGAACTTCGTGATCGACGGAAAGAAGAAGGGTGGGATTGAGGGGAACGGCCAGCCTTGGTGGGAATACTTTACG GTAGTCCCAAGGCAAGACGGGAACGGGCGGCCCATCGCGTTCACGTTGTGGAAAGCGAAGAATGCTGTTATCAAG GATTTCAACATCATCTCGCCACCGTTTTGGGCTAATGCGGTAGCGGAATCGAGTGAGGTTTTGTATGATGGTATG TTCGTCAATGCTACGAACTTAAATCCCAAGTACTTTGGACAAAATGTCGTCTGGAATACCGATGGAATTGATACA TATCGAAGCGAACGTATCACGATGAAGAATTGGGATGTTACCAGCGGAGATGATTGCATTGCCGTCAAGGGCAAT TCTTCCAAGATCGTTGCCCGAGACTTTGTTTGTCGGGGCGGAACTGGGATCGCATTCGGCTCGCTAGGCCAATAC GCTCACTTGACGGATTATGTCACCGATGTCTTGGTCGAGAATGTCAAGGTGTTGCGCCTTCCTTCAAGGCAACAA CCAAACATGAACTATGGTATCTACTTCAAAGCTTGGGACGGCCCAATCACCGGTACTCCTCCAACTGGAGGAGGC GGAGGACGAGGACTCGTCAGCAACGCCATCTTCCGAAACGTCATCTTCGACCGGGTCATGACCGGCGTCCAAATC TGGCAAAACTTTGGTAGCGACGGAGAAGCGCCCGTAACCAGCAAAGTCAAATTTGACGGCCTCCTTTTTGAGAAC ATAAAGGGAACTACGAACACCAGTAACATCGTACGATTGGAGTGCAGCTCTGAAGCCCCTTGCTCCAACTTCACC TTCCGCAACTTCCGAGTCCACGGCCCCAACAAGACTGAATCGACCTACATCTGTGACAACACCGAAAACATTCGA GGACTACCAGACTTGAAACGGCTATCGGCGAAGGCGAAGAAGGGGTTAGGTCTACCTGTGGGGGATGCACGTACA CCTGCGATAGAGGACGACGTAGGGGATGGAGAAGGGAAGAATGCGAATGTGAGCGAGAACGAGAGTTTGGTAGAA CCCAAGTTCTACCCATGGACGATCTCGAATCGATACTACACCGCCAACGTGCATTTCTCTCTACACTCCCTTTCA CGGACGTATCCTGCCGTGTTTGAGGGGATTCCGGCGCTAGTTGTAGCTTGGACGCATGGAGAGCCAATCGAGGAG TACATGAAGGATCTACAGAAGGCTATGGGTGGACACGAACCTGAAATCTTACTTGGTGTGCGGTTGCCGGGAGAT AAAGATAAAGAGACTGGGGGGATTGAAGAAGAGGATGATCTCGATTCTATGATGATCTCGTACGGGTTCGAGTAC ATCGACGCTTCAAGACCGCTGGATCCAACTCGAACGAGGAATGAAGACGAGGATGGCGTACCACACCTCCCACGA GTCCTCGACGCACTAAGCGCATTCATGTGGCCATCTATGACCACCAACACAGACCTCCCACACGACGACAACGAC AACAACGCCGACGGCTCCGACACCGACTCCCCTTCCTCCTCCCAGCACACCTCGCCCAGACCTCCCCGCCACCAA CCCACCCTCGACCACATCATCAACCGCGACCCCTTCGCAATCCTCCAAGCCCTCGAAGAACTGGATGCCGAATTC AACTTTGAAGACAACGAGGAAGGCGGGGCGAGCGGGTACCACGAAACACTCAAACAACTCGCCATGCTCGAAGCG GAATCCAAAGCTGCGGGTATCATAACCGATTCACCTCCGTCCGGATTCACCGACCTCTCGCCAACTAATGCGAAT CCACCGAATCAGAATTCAGATCTGTCAATACCCTTTGGCCTCTCAGAAACACGCTCTCTGAAACCAAAGATTTCG ATAGGCTTCGAGGACGATTTTAGCGCATTTGTTACTGCACCACCAGAGGACGACGACGATGCTGAAGAGCTCAGG AAGGACTTTGCGGCTGTACACATCCACTCTGGGAGGACGAGTCCGGATTACGATTTGCTGCTGTCAGCGGACCCA GCTGGTGAATTCGCAAGTCGAGGGTCATTATACAGGTCGCTCGGGTCCATGTCTGATCTAGGTGACCTCGAGACA TCACCAAACACCGCTGCTAAGGAACTGGAAAGCAAATAG |
| Length | 2514 |
Gene
| Sequence id | CC1G_05428T0 |
|---|---|
| Sequence |
>CC1G_05428T0 ATGGTCCTCAAATCCAGTTGGCTTTTGGCGCTCTGTAGTCTCGCTGTTCTTGGACCTGTCTCTGGAACGCCTGTT GATCTTGATGTCGCCACCGACAAAGGAAAAGTGTGTCGATTGAAACCGTTGGGACGAGGAAGAGATGACACCGAT CAGGTTCGTTTAAACTAGGTCACTATCTAGCAGTTGTACGCCGGATTGACATGACTTGCTAGGTCGAAGCTGCGA TTAAGCGCTGTGGAAATGGCGGTACAACCATCTTTGAAGAGGGAGACTACAAAATTACAAGGTCAGCGACTACCT CGGGGTGTCGGGATTGCCGCTGAACAACAACATCTTCCTCTAGGAAACTCTTCTGGGAACTCAACTCGGCTCGAG TAGAGCTCAAAGGACGATTAAGCGTGAGCCTTTCTATCCATCCACAACCCTTCCTACTCTTCTTCTTACTCTTCG AACATCTTCTGATCCCTCTTCTCATCTAGTTCGAGCCGAAGGTGGAGTACTGGCTCGACCCAGCCAACACCTTCC GGGTGGTCTTCATCCAAGTACGTACATATTTCCACATTTCTACGTACTGTGTACCTACGACCGTCCCGCCCCGTA CCGGTGCTGTCCGGCTAACCCGTCATGATCATCATCTTCGCAGAGCCAAGCCTCCTGGTTCGTCGTAACCGGCAA GAACTTCGTGATCGACGGAAAGAAGAAGGGTGGGATTGAGGGGAACGGCCAGGTAAGTCCACCTACAAACCTTCA ACTTCCCTCAGCACCTTCGAAGCATGCATATGGAGAATTGATTTTTCCGATTCCTATACTTACCACTTCTGAATC TGTGCCGATCATCAATGGCCCGGGCAGCCTTGGTGGGAATACTTTACGGTAGTCCCAAGGCAAGACGGGAACGGG CGGCCCATCGCGTTCACGTTGTGGAAAGCGAAGAATGCTGTTATCAAGGATTTCAACATCATCTCGCCACCGTTT TGGGCTAATGCGGTAGCGGAATCGAGTGAGGTTTTGTATGATGGTATGTTCGTCAATGCTACGAACTTAAATCCC AAGTACTTTGGACAAAAGTGAGAGCTTCAAGTATCGTTCTAACTTCGGGGGGCTATGCGATTGACTTTTTTTTCT TGACAGTGTCGTCTGGAATACCGATGGTCAGCAGCGATAAACTTCATGTTGTTGATGTTTGGCTTACATCCAACA GGAATTGATACATATCGAAGCGAACGTATCACGATGAAGAATTGGGATGTTACCAGCGGAGATGATTGCATTGCC GTCAAGGGCGTAAGTTTAGACCAGACTCCAGAGACCATCTACCTAGCTGCATGCTGACTCTGTAATTGCAGAATT CTTCCAAGATCGTTGCCCGAGACTTTGTTTGTCGGGGCGGAACTGGGATCGCATTCGGCTCGCTAGGCCAATACG CTCACTTGGTAGGGTTCCTGTTCTACATTTATCTTCTTATCCTCTGTGCTAATACAGGGCGCAGACGGATTATGT CACCGATGTCTTGGTCGAGAATGTCAAGGTCGGTATCATCGCTGCCACCTGCTACCCCCAATACATTCTCATTCT CGACGAACACAGGTGTTGCGCCTTCCTTCAAGGCAACAACCAAACATGAACTATGGTGTAGGCCATGCTCAAAAT TAGGATTACTTCATCTATACTCACAAAGCTCTAGATCTACTTCAAAGCTTGGGACGGCCCAATCACCGGTACTCC TCCAACTGGAGGAGGCGGAGGACGAGGTAATCCAAATCCCTCTCCATTCCACAATCACAAACCTTCTCTCTAAAC TGAGATTCCGTTATAGGACTCGTCAGCAACGCCATCTTCCGAAACGTCATCTTCGACCGGGTCATGACCGGCGTC CAAATCTGGCAAAACTTTGGTAGCGAGTGCGTTCTGCAGGGTTTTCCTCGAGTCCATCCACCTTCCAAACCTAAC ATTGTTTCCTCAGCGGAGAAGCGCCCGTAACCAGCAAAGTCAAATTTGACGGCCTCCTTTTTGAGAACATAAAGG GAACTACGAACACCAGTAACAGTACGTCGAACCCACTCGAGCGTTGACGGGACCAAGTTGACCCCAGTGGCTCTA CTACGACAGTCGTACGATTGGAGTGCAGCTCTGAAGCCCCTTGCTCCAACTTCACCTTCCGCAACTTCCGAGTCC ACGGCCCCAACAAGACTGAATCGACCTACATCTGTGACAACACCGAAAACATTCGAGGACTACCAGGTCAGTTTC ATTTGCGCCACACTTACCTCGAAGGTTCTGACGGTCGTTTTAGCACCTTGCAACAATTAAGGGTTGAGTTCCTTC GAGTCTCATCAGGAGTAAAGCCTGAAAAGGAGCCTCTTTTGCGTAATGAACTACCTATTGTGTACCTGCCTACAG CCTCTTCGAAAATACCGTGAATAAACGCTGAATTTAGCGCCCTAATTCAGGGGGATTATGTAAGAAACCAAGAAC ACCAAGCCCCGCAAAGCTGTGAAGTGCTCCATCAAGATCTTCTTCTCTCTCCAACCACCACGACCCCAACCACCG CCGCACCCCTTCCAATCCGACATGGACGACATCTCGTGCAGAATAGTCGTCGTCTCCTCATCATTATCCAAGGGA GACATCCTAGTGCAAAGTCGGACGGATTTTATCTCTTCTATATAAAGCATTGAGGATCCTGACGACTACGCGCTG CTAGACTTGAAACGGCTATCGGCGAAGGCGAAGAAGGGGTTAGGTCTACCTGTGGGGGATGCACGTACACCTGCG ATAGAGGACGACGTAGGGGATGGAGAAGGGAAGAATGCGAATGTGAGCGAGAACGAGAGTTTGGTAGAACCCAAG TTCTACCCATGGACGATCTCGAATCGATACTACACCGCCAACGTGCATTTCTCTCTACACTCCCTTTCACGGACG TATCCTGCCGTGTTTGAGGGGATTCCGGCGCTAGTTGTAGCTTGGACGCATGGAGAGGTATGTTCTGTCGACTCC CCTGTCGTTGCAGCTGACCGATCTCTTGTGTGAACAGCCAATCGAGGAGTACATGAAGGATCTACAGAAGGCTAT GGGTGGACACGAACCTGAAATCTTACTTGGTGTGCGGTTGCCGGGAGATAAAGATAAAGAGACTGGGGGGATTGA AGAAGAGGATGATCTCGATTCTATGATGATCTCGTACGGGTTCGAGTACATCGACGCTTCAAGACCGCTGGATCC AACTCGAACGAGGAATGAAGACGAGGATGGTGAGACCCAGCGTATCACACTAGTCCGCTGTCCTAACGTCCGCAT CCTAAGGCGTACCACACCTCCCACGAGTCCTCGACGCACTAAGCGCATTCATGTGGCCATCTATGACCACCAACA CAGACCTCCCACACGACGACAACGACAACAACGCCGACGGCTCCGACACCGACTCCCCTTCCTCCTCCCAGCACA CCTCGCCCAGACCTCCCCGCCACCAACCCACCCTCGACCACATCATCAACCGCGACCCCTTCGCAATCCTCCAAG CCCTCGAAGAACTGGATGCCGAATTCAACTTTGAAGACAACGAGGAAGGCGGGGCGAGCGGGTACCACGAAACAC TCAAACAACTCGCCATGCTCGAAGCGGAATCCAAAGCTGCGGGTATCATAACCGATTCACCTCCGTCCGGATTCA CCGACCTCTCGCCAACTAATGCGAATCCACCGAATCAGAATTCAGATCTGTCAATACCCTTTGGCCTCTCAGAAA CACGCTCTCTGAAACCAAAGATTTCGATAGGCTTCGAGGACGATTTTAGCGCATTTGTTACTGCACCACCAGAGG ACGACGACGATGCTGAAGAGCTCAGGAAGGACTTTGCGGCTGTACACATCCACTCTGGGAGGACGAGTCCGGATT ACGATTTGCTGCTGTCAGCGGACCCAGCTGGTGAATTCGCAAGTCGAGGGTCATTATACAGGTCGCTCGGGTCCA TGTCTGATCTAGGTGACCTCGAGACATCACCAAACACCGCTGCTAAGGAACTGGAAAGCAAATAG |
| Length | 4040 |