CC1G_06324
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_06324 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NTI7 | Functional description | Endoglucanase |
| Location | Chr_4:1818499..1820356 | Strand | + |
| Gene length (nt) | 1858 | Transcript length (nt) | 1143 |
| CDS length (nt) | 1143 | Protein length (aa) | 380 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN1285_eglA |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB26262 | 65.8 | 5.776E-182 | 567 |
| Agrocybe aegerita | Agrae_CAA7267109 | 63.6 | 8.001E-177 | 552 |
| Auricularia subglabra | Aurde3_1_1163753 | 60.8 | 7.266E-165 | 518 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1067505 | 60.9 | 3.845E-165 | 518 |
| Pleurotus ostreatus PC9 | PleosPC9_1_116228 | 60.9 | 3.763E-165 | 518 |
| Pleurotus eryngii ATCC 90797 | Pleery1_682179 | 60.9 | 2.429E-163 | 513 |
| Grifola frondosa | Grifr_OBZ72550 | 58.6 | 4.903E-163 | 512 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_124054 | 59.4 | 5.358E-162 | 509 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_191420 | 60.1 | 1.141E-159 | 502 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_85704 | 59.7 | 2.638E-159 | 501 |
| Lentinula edodes NBRC 111202 | Lenedo1_1059630 | 56.1 | 1.173E-153 | 485 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_11376 | 56.1 | 1.164E-153 | 485 |
| Lentinula edodes B17 | Lened_B_1_1_6666 | 58.5 | 2.606E-141 | 449 |
| Schizophyllum commune H4-8 | Schco3_2502504 | 61.4 | 9.023E-140 | 445 |
| Flammulina velutipes | Flave_chr09AA01045 | 57 | 1.911E-118 | 383 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 5449 |
| Description | Endoglucanase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00734 | Fungal cellulose binding domain | IPR000254 | 26 | 53 |
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 183 | 349 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 22 | 0.9985 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR035971 | Cellulose-binding domain superfamily |
| IPR017853 | Glycoside hydrolase superfamily |
| IPR018087 | Glycoside hydrolase, family 5, conserved site |
| IPR001547 | Glycoside hydrolase, family 5 |
| IPR000254 | Cellulose-binding domain, fungal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005576 | extracellular region | CC |
| GO:0005975 | carbohydrate metabolic process | BP |
| GO:0030248 | cellulose binding | MF |
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| K01179 |
EggNOG
| COG category | Description |
|---|---|
| G | Belongs to the glycosyl hydrolase 5 (cellulase A) family |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| CBM | CBM1 | |
| GH | GH5 | GH5_5 |
Transcription factor
| Group |
|---|
| No records |
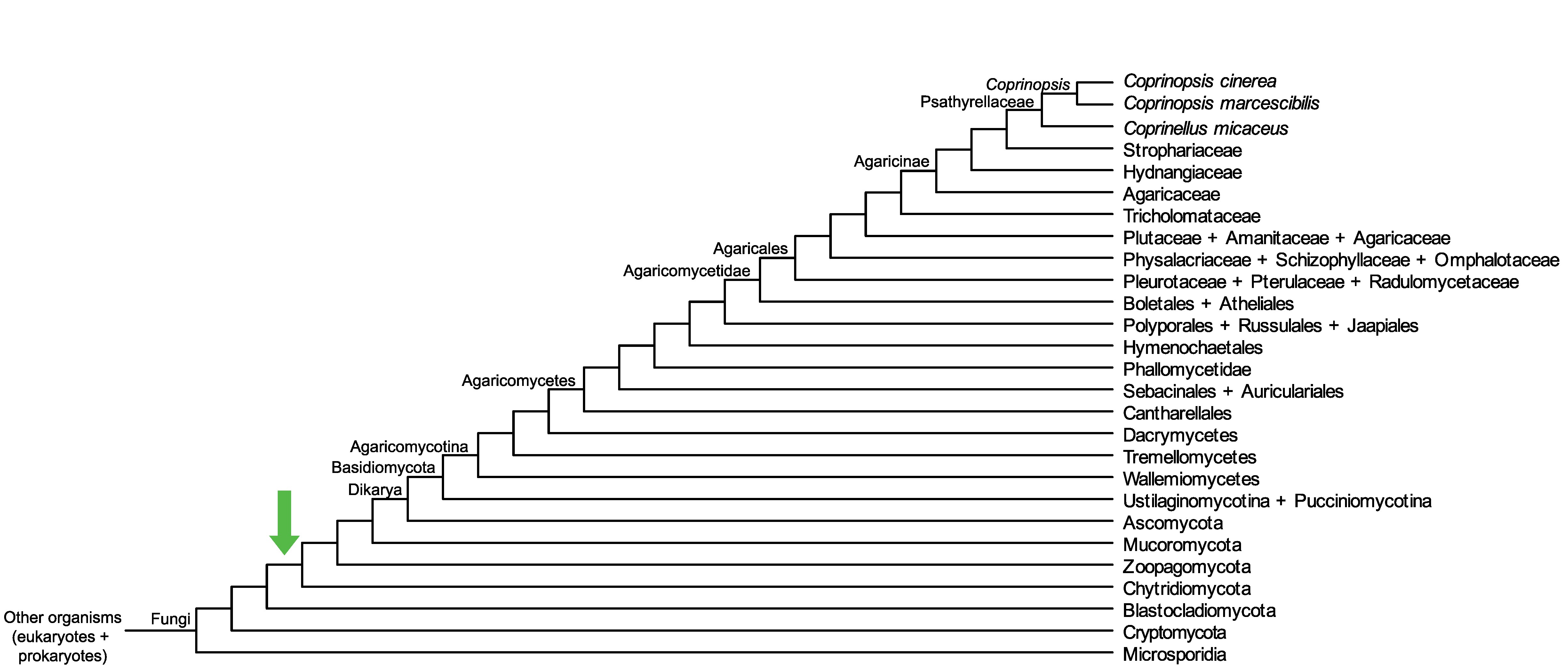
Conservation of CC1G_06324 across fungi.
Arrow shows the origin of gene family containing CC1G_06324.
Protein
| Sequence id | 5449 |
|---|---|
| Sequence |
>5449 MKSVLSPLSATVIALLSTAAVAVPPYGQCGGSGYTGPSDCDSGYTCVPVNQWYHQCQPGSSAPTNPPNPPVATTT TTAPRPTNSACPGAVTKFRYFGVNQAGAEFGSNIIPGELGTHYIWPAPSSIDFFVNEGFNTFRIPFQLERLNPPA RGLTGSFEQPYLQDLKRTVDYITRNKNSFAIIERWRNLATEFRDNDKVIFDVMNEPHTMDARVVFDLNQAAVNAI REAGATRQLILVEGTSWTGAWTWTTTSGNGNVFQNIRDPNNNVAIQMHQYLDSDGSGTSPTCVSSSIGRERLAAA TAWLKQHNLKGFLGELGAGSNPTCIEAIKGALCSLQESDVWIGWAWWAAGPWWGNYFQSIEPPNGPALAQMYPQA IKPFI |
| Length | 380 |
Coding
| Sequence id | CC1G_06324T0 |
|---|---|
| Sequence |
>CC1G_06324T0 ATGAAGTCTGTGCTCTCCCCGCTGTCTGCAACTGTGATTGCTCTGTTGAGCACTGCGGCTGTTGCCGTTCCCCCC TACGGCCAGTGCGGTGGCTCTGGATACACTGGACCTTCCGACTGTGACTCTGGCTATACCTGTGTCCCGGTGAAC CAATGGTACCACCAGTGCCAACCCGGTAGCTCCGCCCCCACCAACCCTCCCAATCCCCCTGTCGCTACTACCACT ACCACTGCGCCCAGGCCCACCAACAGTGCTTGCCCAGGCGCCGTCACCAAGTTCCGCTACTTCGGTGTCAACCAA GCTGGTGCTGAGTTCGGCAGCAACATCATCCCCGGAGAGCTCGGGACCCACTACATCTGGCCCGCCCCTAGTTCC ATCGACTTCTTCGTTAACGAAGGTTTCAACACTTTCCGAATTCCCTTCCAATTGGAGCGACTGAACCCCCCTGCT CGTGGGTTGACCGGTTCCTTCGAGCAGCCCTACCTCCAGGACTTGAAGAGGACTGTCGACTACATCACCCGAAAC AAGAACTCTTTCGCCATCATCGAACGGTGGAGGAACCTTGCAACTGAATTCAGGGATAATGACAAGGTTATCTTT GATGTCATGAACGAGCCCCACACTATGGATGCTCGTGTCGTTTTCGACCTCAACCAAGCGGCGGTCAATGCTATC CGTGAAGCTGGTGCTACCCGCCAATTGATCCTCGTTGAGGGAACCTCCTGGACCGGTGCCTGGACCTGGACTACC ACCAGCGGAAACGGCAACGTCTTCCAGAATATCCGTGATCCCAACAACAATGTCGCCATTCAGATGCACCAGTAC CTCGACAGTGACGGTTCGGGTACCTCTCCCACTTGTGTTTCCAGCTCCATCGGTCGCGAGCGTCTCGCTGCTGCC ACTGCCTGGTTGAAGCAACACAACCTCAAGGGCTTCCTCGGTGAACTCGGTGCTGGTTCCAACCCCACTTGCATT GAGGCCATCAAGGGTGCTCTCTGCTCCCTCCAGGAGTCTGATGTCTGGATTGGTTGGGCCTGGTGGGCTGCTGGT CCCTGGTGGGGCAACTACTTCCAATCCATTGAGCCCCCCAATGGACCCGCTCTCGCTCAGATGTACCCTCAGGCC ATCAAACCCTTCATC |
| Length | 1143 |
Transcript
| Sequence id | CC1G_06324T0 |
|---|---|
| Sequence |
>CC1G_06324T0 ATGAAGTCTGTGCTCTCCCCGCTGTCTGCAACTGTGATTGCTCTGTTGAGCACTGCGGCTGTTGCCGTTCCCCCC TACGGCCAGTGCGGTGGCTCTGGATACACTGGACCTTCCGACTGTGACTCTGGCTATACCTGTGTCCCGGTGAAC CAATGGTACCACCAGTGCCAACCCGGTAGCTCCGCCCCCACCAACCCTCCCAATCCCCCTGTCGCTACTACCACT ACCACTGCGCCCAGGCCCACCAACAGTGCTTGCCCAGGCGCCGTCACCAAGTTCCGCTACTTCGGTGTCAACCAA GCTGGTGCTGAGTTCGGCAGCAACATCATCCCCGGAGAGCTCGGGACCCACTACATCTGGCCCGCCCCTAGTTCC ATCGACTTCTTCGTTAACGAAGGTTTCAACACTTTCCGAATTCCCTTCCAATTGGAGCGACTGAACCCCCCTGCT CGTGGGTTGACCGGTTCCTTCGAGCAGCCCTACCTCCAGGACTTGAAGAGGACTGTCGACTACATCACCCGAAAC AAGAACTCTTTCGCCATCATCGAACGGTGGAGGAACCTTGCAACTGAATTCAGGGATAATGACAAGGTTATCTTT GATGTCATGAACGAGCCCCACACTATGGATGCTCGTGTCGTTTTCGACCTCAACCAAGCGGCGGTCAATGCTATC CGTGAAGCTGGTGCTACCCGCCAATTGATCCTCGTTGAGGGAACCTCCTGGACCGGTGCCTGGACCTGGACTACC ACCAGCGGAAACGGCAACGTCTTCCAGAATATCCGTGATCCCAACAACAATGTCGCCATTCAGATGCACCAGTAC CTCGACAGTGACGGTTCGGGTACCTCTCCCACTTGTGTTTCCAGCTCCATCGGTCGCGAGCGTCTCGCTGCTGCC ACTGCCTGGTTGAAGCAACACAACCTCAAGGGCTTCCTCGGTGAACTCGGTGCTGGTTCCAACCCCACTTGCATT GAGGCCATCAAGGGTGCTCTCTGCTCCCTCCAGGAGTCTGATGTCTGGATTGGTTGGGCCTGGTGGGCTGCTGGT CCCTGGTGGGGCAACTACTTCCAATCCATTGAGCCCCCCAATGGACCCGCTCTCGCTCAGATGTACCCTCAGGCC ATCAAACCCTTCATCTAA |
| Length | 1143 |
Gene
| Sequence id | CC1G_06324T0 |
|---|---|
| Sequence |
>CC1G_06324T0 ATGAAGTCTGTGCTCTCCCCGCTGTCTGCAACTGTGATTGCTCTGTTGAGCACTGCGGCTGTTGCCGTTCCCCCC TACGGCCAGTGCGGTGTAAGTGTCGCACTCAATTGACGGTGGTGTGTTCTCTGACGCTTGCTTCTCTTAGGGCTC TGGATACACTGGACCTTCCGACTGTGACTCTGGCTATACCTGTGTCCCGGTGAACCAATGTACGGCACCTACTCC TACGGCCATTGTTCTCACAAGACTGACTGCCGTTTGAATTAGGGTACCACCAGTGCCAACCCGGTAGCTCCGCCC CCACCAACCCTCCCAATCCCCCTGTCGCTACTACCACTACCACTGCGCCCAGGCCCACCAACAGTGCTTGCCCAG GCGCCGTCACCAAGTTCCGCTACTTCGGTGTCAACCAAGCTGGTGCTGAGTTCGGCAGCAACATCATCCCCGTAC GCTGCTCTCCTTCCACCATCCCCTGACAGTTGAACTTACGCCCGACGATGCTCGGTTTCAGGGAGAGCTCGGGAC CCACTACATCTGGCCCGCCCCTAGTTCCATCGACTTCTTCGTTAACGAAGGTTTCAACACTTTCCGAATTCCCTT CCAATTGGAGCGACTGAACCCCCCTGCTCGTGGGTTGACCGGTTCCTTCGAGCAGCCCTACCTCCAGGACTTGAA GAGGACTGTCGACTACATCACCCGAAACAAGAACTCTTTCGCCATCATCGAACGTGTGTTATTTACTCTTTCTGA CACTTGGTTTGTGGAGACTGAAGGGGACATGCAGCCCACAACTACATGCGATATGCCAACCAGACCATCACCAAC GTTTCTCAGTGAGTTATTTACCTCTGAGAGGATATAAACTGTTGCTTACGCTTTGTCGTTATAGATTCAGCACCT GTAAGTTTCTCGCATCGCTTGAGACCTGTTCCAGAGATTTAACCGTGTTGCGTAGGGTGGAGGAACCTTGCAACT GAATTCGTAAGTTCGATTTTTCCATTGGAAACAAGTTCACCCTCTGACTTTGTTTCTAGAGGGATAATGACAAGG TTATCTTTGGTGTGTATCCATCGAAGCCAAGCGGGCAAGAAAGAGATCTAAACACTGTCTAATAGATGTCATGAA CGAGCCCCACACTATGGATGCTCGTGTCGTTTTCGACCTCAACCAAGCGGCGGTCAATGCTATCCGTGAAGCTGG TGCTACCCGCCAATTGATCCTCGTTGAGGGAACCTCCTGGACCGGTGCCTGGAGTAAGCGATCCACCTTTTCCTC GATAGAGAATTACCTCATTGACATGTTGACGGAATTTAGCCTGGACTACCACCAGCGGAAACGGCAACGTCTTCC AGAATATCCGTGATCCCAACAACAATGTCGCCATTCGTACGTCTTGTTCATCGACATCTCCTTCTAACAATTCCT GATCAACGTTTTGGCACCACTCGTTACCACTTTCAGAGATGCACCAGTACCTCGACAGTGACGGTTCGGGTACCT CTCCCACTTGTGTTTCCAGCTCCATCGGTCGCGAGCGTCTCGCTGCTGCCACTGCCTGGTTGAAGCAACACAACC TCAAGGGCTTCCTCGGTGAACTCGGTGCTGGTTCCAACCCCACTTGCATTGAGGCCATCAAGGGTGCTCTCTGCT CCCTCCAGGAGTCTGATGTCTGGATTGGTTGGGCCTGGTGGGCTGCTGGTCCCTGGTGGGGCAACGTAAGTTGTT TCTGCCTTTCGTGTGGACGGGATGCTGATGCAATGTTTTATTTTCTTCCTTATAGTACTTCCAATCCATTGAGCC CCCCAATGGACCCGCTCTCGCTCAGATGTACCCTCAGGCCATCAAACCCTTCATCTAA |
| Length | 1858 |