CC1G_06628
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_06628 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N333 | Functional description | Chitin synthase (EC 2.4.1.16) |
| Location | Chr_1:2991178..2994751 | Strand | + |
| Gene length (nt) | 3574 | Transcript length (nt) | 2649 |
| CDS length (nt) | 2547 | Protein length (aa) | 848 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Ustilago maydis | CHS2 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7264741 | 83.2 | 0 | 1458 |
| Pleurotus ostreatus PC9 | PleosPC9_1_115957 | 78.4 | 0 | 1420 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1437737 | 78 | 0 | 1416 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB28666 | 78.4 | 0 | 1409 |
| Flammulina velutipes | Flave_chr08AA00385 | 77.2 | 0 | 1398 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_114159 | 74.8 | 0 | 1368 |
| Lentinula edodes NBRC 111202 | Lenedo1_1031833 | 74.4 | 0 | 1361 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_345 | 74.5 | 0 | 1360 |
| Schizophyllum commune H4-8 | Schco3_2613031 | 73.6 | 0 | 1360 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1036823 | 83.2 | 0 | 1329 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_60607 | 78.8 | 0 | 1318 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_31788 | 78.8 | 0 | 1318 |
| Grifola frondosa | Grifr_OBZ78918 | 72.3 | 0 | 1290 |
| Auricularia subglabra | Aurde3_1_99027 | 74.6 | 0 | 1269 |
| Lentinula edodes B17 | Lened_B_1_1_16258 | 70.6 | 0 | 1267 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 5704 |
| Description | Chitin synthase (EC 2.4.1.16) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd04190 | Chitin_synth_C | - | 172 | 492 |
| Pfam | PF08407 | Chitin synthase N-terminal | IPR013616 | 107 | 175 |
| Pfam | PF01644 | Chitin synthase | IPR004834 | 176 | 335 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 485 | 504 | 19 |
| 2 | 525 | 547 | 22 |
| 3 | 567 | 589 | 22 |
| 4 | 601 | 623 | 22 |
| 5 | 648 | 670 | 22 |
| 6 | 779 | 801 | 22 |
| 7 | 821 | 843 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR013616 | Chitin synthase N-terminal |
| IPR029044 | Nucleotide-diphospho-sugar transferases |
| IPR004835 | Chitin synthase |
| IPR004834 | Fungal chitin synthase |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004100 | chitin synthase activity | MF |
| GO:0016758 | transferase activity, transferring hexosyl groups | MF |
| GO:0006031 | chitin biosynthetic process | BP |
KEGG
| KEGG Orthology |
|---|
| K00698 |
EggNOG
| COG category | Description |
|---|---|
| M | Chitin synthase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GT | GT2 | GT2_Chitin_synth_1 |
Transcription factor
| Group |
|---|
| No records |
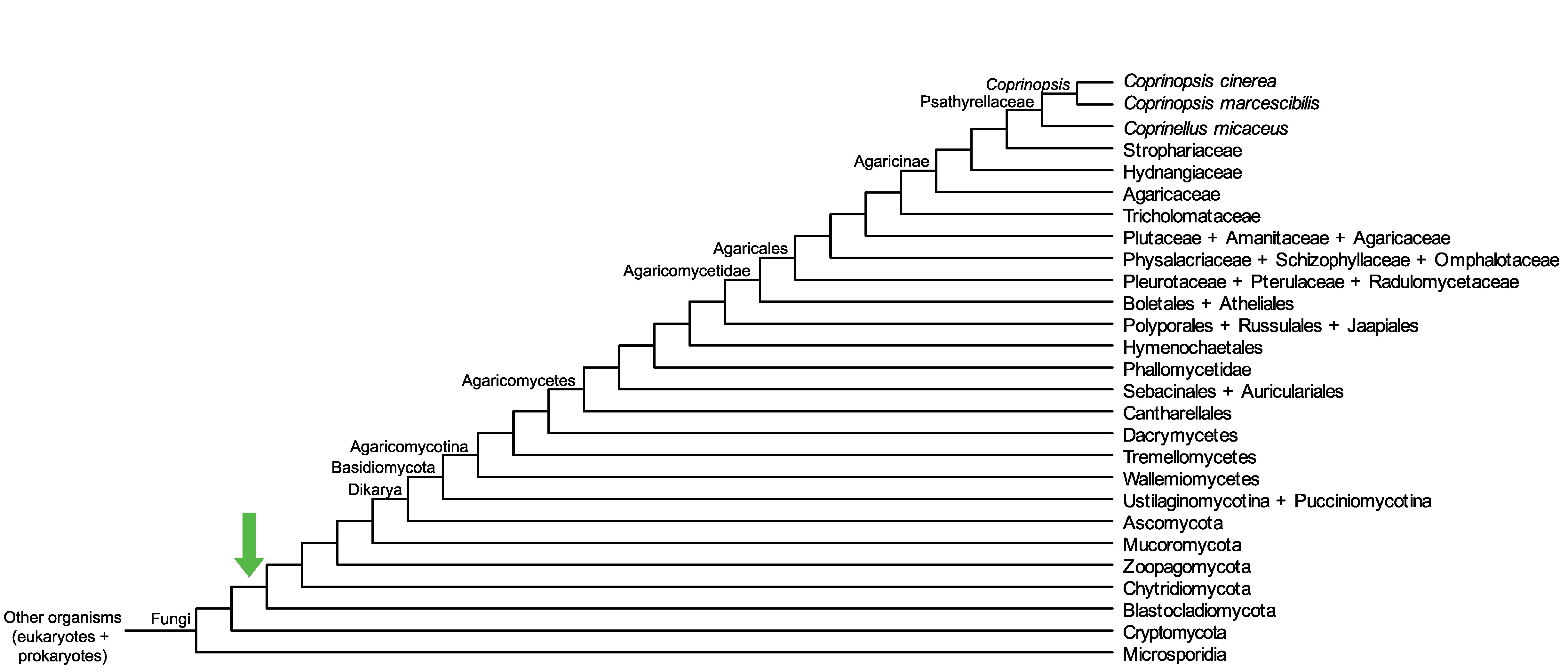
Conservation of CC1G_06628 across fungi.
Arrow shows the origin of gene family containing CC1G_06628.
Protein
| Sequence id | 5704 |
|---|---|
| Sequence |
>5704 MAYRPSHNDPYYNQPSYPPATGYGDSSNWDAKSTKSYQSSYAGSQAHLNPSSYEMQQVNQHPVPAMPYNGGYPPQ QTMPSPGGFRDNGSVAGWSLARDKLMKRRSIKKVFLTQGNLVLDVPVPSHIVPVGKQDLEEFSKMRYTAATCDPD DFKASRYTLRPYLMGRETELFIVMTMYNEDEVLFVRTMNAVLKNVAHLCSRQKSKTWGPEGWKKVVVCVVSDGRN KVNKRTLQVLNLMGCYQEGIAKDSVAGKDVTAHIFEYTTTAIVTETGEVSQNTCPVQVLFCLKEQNKKKLNSHRW FFNAFGPLLNPNVCILLDVGTKPTGTSIYELWKCFDKHKHVGGACGEITVDSGRGCSLLLTSPLAASQNFEYKMS NILDKPLESVFGYISVLPGAFSAYRYKALLNGPDGKGPLASYFKGEAMHGGGSDAGLFERNMYLAEDRILCFEIV TKKKEAWTLKYVKSAKASTDVPATVPEFISQRRRWLNGSLFASIHATVFFFRIWTSGQGFFRKIALQFEFIYNAV QLLFTWTSLANFYLAFFFLVSSATAEGSTDAFNFLSTGAGKIVFQIFLNLYIGLLFVVLVCSLGNRPQGSKWTYT IAMFLFGLCNIITTWCAAYTVYLAVPHDIEGWRNFPELFKENRTLQEIVVAVLATYGMYFISSFIHFEPWHMFTS FAQYMFLLPSYVNILMMYAMCNLHDVTWGTKGDNGAAKDLGGAKKVKGEDGKEMMEVAVPTAREDVDQLWAASRA ALKVKPPEQKESRDAATKQADHDRNSRTNVVLAWVGSNMVLIIVFTSQAFLDWVNQNTSLGGSAFNPYLQFLFFA FAGLSAIRFTGSVVYLIFRLFGH |
| Length | 848 |
Coding
| Sequence id | CC1G_06628T0 |
|---|---|
| Sequence |
>CC1G_06628T0 ATGGCTTATCGTCCATCCCACAACGATCCTTACTACAATCAACCGAGCTATCCTCCAGCTACCGGTTACGGAGAT TCCTCAAATTGGGACGCAAAGTCCACAAAGTCGTACCAAAGTAGTTATGCAGGTTCCCAAGCCCACTTGAATCCA TCCAGCTACGAGATGCAACAGGTTAACCAGCACCCAGTTCCTGCAATGCCATACAACGGCGGCTACCCACCACAG CAAACTATGCCTTCCCCAGGCGGCTTTAGGGACAATGGCTCTGTCGCGGGCTGGTCCCTGGCCAGAGACAAGCTT ATGAAAAGGCGGTCTATCAAGAAAGTCTTCCTCACACAGGGAAACCTCGTCCTTGATGTACCCGTTCCCTCCCAC ATCGTCCCTGTTGGCAAGCAGGATCTCGAAGAATTCTCCAAGATGCGCTACACGGCGGCGACCTGCGACCCTGAC GACTTCAAAGCTTCTCGCTACACCCTCAGGCCCTACCTCATGGGCCGCGAGACCGAGCTCTTTATTGTCATGACC ATGTACAACGAAGACGAAGTCCTATTCGTCCGCACTATGAATGCCGTCCTCAAGAACGTTGCTCATTTATGCAGC CGTCAAAAGTCAAAAACTTGGGGTCCAGAAGGCTGGAAGAAGGTCGTCGTCTGTGTCGTGTCAGATGGTCGTAAC AAGGTCAACAAGCGGACACTGCAAGTATTGAACTTGATGGGATGCTACCAAGAAGGTATCGCTAAAGATTCCGTG GCGGGCAAGGATGTCACAGCCCACATCTTCGAGTACACCACCACAGCTATCGTGACAGAGACCGGCGAAGTCAGC CAGAACACATGTCCAGTCCAAGTTCTCTTCTGCTTGAAGGAACAGAACAAGAAGAAGTTGAACAGCCATAGATGG TTCTTCAATGCATTCGGACCTTTGCTGAACCCTAATGTCTGTATCCTCCTGGACGTCGGCACAAAGCCCACCGGA ACTTCAATCTATGAGCTATGGAAATGCTTCGATAAGCACAAACATGTCGGTGGTGCTTGTGGCGAAATCACTGTT GACAGTGGCCGCGGGTGCAGCCTCCTTCTCACAAGTCCTCTCGCAGCCTCCCAGAACTTTGAGTACAAAATGTCC AATATCCTTGACAAACCTTTGGAGAGCGTGTTTGGTTACATTAGCGTGTTGCCTGGTGCATTCAGCGCTTACCGA TACAAGGCTCTTTTGAACGGCCCTGATGGAAAGGGCCCGTTGGCATCTTACTTCAAGGGTGAGGCCATGCACGGA GGAGGTAGCGACGCTGGTCTCTTCGAGCGTAACATGTACCTCGCCGAAGATCGTATCCTCTGCTTCGAGATTGTC ACCAAGAAGAAGGAGGCCTGGACATTGAAGTATGTCAAGAGCGCAAAGGCATCTACTGACGTCCCCGCGACTGTC CCGGAATTCATCTCTCAACGTCGTCGATGGTTGAACGGTTCCTTATTCGCTTCCATCCATGCAACGGTTTTCTTC TTCAGGATCTGGACGTCTGGTCAGGGCTTCTTCCGCAAGATCGCTCTCCAATTCGAGTTCATCTACAATGCCGTC CAACTTCTCTTCACATGGACATCACTGGCCAACTTTTACCTCGCTTTCTTCTTCTTGGTTTCCTCGGCTACGGCA GAGGGCTCTACGGACGCATTCAACTTTCTGAGCACTGGTGCAGGCAAGATCGTGTTCCAAATCTTCCTCAATCTC TACATCGGTCTTCTGTTCGTCGTCTTGGTCTGTTCTCTGGGTAATCGACCTCAAGGTTCAAAATGGACGTACACA ATCGCCATGTTCTTGTTTGGTTTGTGTAATATCATCACCACATGGTGCGCTGCCTACACTGTCTACCTGGCTGTC CCCCACGATATCGAAGGATGGAGAAACTTCCCTGAACTGTTCAAGGAGAACCGCACGCTTCAGGAGATCGTCGTC GCCGTCCTCGCCACCTACGGCATGTACTTCATCAGTTCCTTCATCCACTTTGAACCTTGGCACATGTTCACCTCC TTTGCGCAATACATGTTCCTCCTCCCCTCGTACGTCAACATCCTCATGATGTACGCCATGTGCAACTTGCATGAT GTCACTTGGGGAACGAAAGGAGACAACGGCGCAGCGAAGGATTTGGGCGGCGCGAAGAAGGTGAAGGGAGAGGAT GGCAAGGAGATGATGGAAGTTGCGGTGCCTACTGCGAGGGAGGACGTGGATCAACTTTGGGCCGCGTCGAGGGCT GCGTTGAAGGTCAAGCCCCCGGAGCAGAAGGAGAGTCGAGATGCCGCTACCAAGCAGGCTGATCATGATCGGAAT AGTAGGACGAATGTTGTGTTGGCGTGGGTTGGTTCGAACATGGTGCTTATCATTGTTTTCACTTCCCAAGCCTTC TTGGACTGGGTGAACCAGAACACTTCGCTCGGTGGAAGTGCTTTCAACCCATACCTGCAATTCCTCTTCTTTGCC TTTGCCGGCCTATCAGCCATCCGCTTCACAGGTTCAGTCGTATACCTGATATTCAGACTATTCGGTCAC |
| Length | 2547 |
Transcript
| Sequence id | CC1G_06628T0 |
|---|---|
| Sequence |
>CC1G_06628T0 CTCACGAGCGTTGCCAACGCTATTCCATTCTTTTTCACAGCCGGTCTGGTCAACATATCTACCTAATATCCCTAC GGACGCCAGCCACGACTCACAAACACAATGGCTTATCGTCCATCCCACAACGATCCTTACTACAATCAACCGAGC TATCCTCCAGCTACCGGTTACGGAGATTCCTCAAATTGGGACGCAAAGTCCACAAAGTCGTACCAAAGTAGTTAT GCAGGTTCCCAAGCCCACTTGAATCCATCCAGCTACGAGATGCAACAGGTTAACCAGCACCCAGTTCCTGCAATG CCATACAACGGCGGCTACCCACCACAGCAAACTATGCCTTCCCCAGGCGGCTTTAGGGACAATGGCTCTGTCGCG GGCTGGTCCCTGGCCAGAGACAAGCTTATGAAAAGGCGGTCTATCAAGAAAGTCTTCCTCACACAGGGAAACCTC GTCCTTGATGTACCCGTTCCCTCCCACATCGTCCCTGTTGGCAAGCAGGATCTCGAAGAATTCTCCAAGATGCGC TACACGGCGGCGACCTGCGACCCTGACGACTTCAAAGCTTCTCGCTACACCCTCAGGCCCTACCTCATGGGCCGC GAGACCGAGCTCTTTATTGTCATGACCATGTACAACGAAGACGAAGTCCTATTCGTCCGCACTATGAATGCCGTC CTCAAGAACGTTGCTCATTTATGCAGCCGTCAAAAGTCAAAAACTTGGGGTCCAGAAGGCTGGAAGAAGGTCGTC GTCTGTGTCGTGTCAGATGGTCGTAACAAGGTCAACAAGCGGACACTGCAAGTATTGAACTTGATGGGATGCTAC CAAGAAGGTATCGCTAAAGATTCCGTGGCGGGCAAGGATGTCACAGCCCACATCTTCGAGTACACCACCACAGCT ATCGTGACAGAGACCGGCGAAGTCAGCCAGAACACATGTCCAGTCCAAGTTCTCTTCTGCTTGAAGGAACAGAAC AAGAAGAAGTTGAACAGCCATAGATGGTTCTTCAATGCATTCGGACCTTTGCTGAACCCTAATGTCTGTATCCTC CTGGACGTCGGCACAAAGCCCACCGGAACTTCAATCTATGAGCTATGGAAATGCTTCGATAAGCACAAACATGTC GGTGGTGCTTGTGGCGAAATCACTGTTGACAGTGGCCGCGGGTGCAGCCTCCTTCTCACAAGTCCTCTCGCAGCC TCCCAGAACTTTGAGTACAAAATGTCCAATATCCTTGACAAACCTTTGGAGAGCGTGTTTGGTTACATTAGCGTG TTGCCTGGTGCATTCAGCGCTTACCGATACAAGGCTCTTTTGAACGGCCCTGATGGAAAGGGCCCGTTGGCATCT TACTTCAAGGGTGAGGCCATGCACGGAGGAGGTAGCGACGCTGGTCTCTTCGAGCGTAACATGTACCTCGCCGAA GATCGTATCCTCTGCTTCGAGATTGTCACCAAGAAGAAGGAGGCCTGGACATTGAAGTATGTCAAGAGCGCAAAG GCATCTACTGACGTCCCCGCGACTGTCCCGGAATTCATCTCTCAACGTCGTCGATGGTTGAACGGTTCCTTATTC GCTTCCATCCATGCAACGGTTTTCTTCTTCAGGATCTGGACGTCTGGTCAGGGCTTCTTCCGCAAGATCGCTCTC CAATTCGAGTTCATCTACAATGCCGTCCAACTTCTCTTCACATGGACATCACTGGCCAACTTTTACCTCGCTTTC TTCTTCTTGGTTTCCTCGGCTACGGCAGAGGGCTCTACGGACGCATTCAACTTTCTGAGCACTGGTGCAGGCAAG ATCGTGTTCCAAATCTTCCTCAATCTCTACATCGGTCTTCTGTTCGTCGTCTTGGTCTGTTCTCTGGGTAATCGA CCTCAAGGTTCAAAATGGACGTACACAATCGCCATGTTCTTGTTTGGTTTGTGTAATATCATCACCACATGGTGC GCTGCCTACACTGTCTACCTGGCTGTCCCCCACGATATCGAAGGATGGAGAAACTTCCCTGAACTGTTCAAGGAG AACCGCACGCTTCAGGAGATCGTCGTCGCCGTCCTCGCCACCTACGGCATGTACTTCATCAGTTCCTTCATCCAC TTTGAACCTTGGCACATGTTCACCTCCTTTGCGCAATACATGTTCCTCCTCCCCTCGTACGTCAACATCCTCATG ATGTACGCCATGTGCAACTTGCATGATGTCACTTGGGGAACGAAAGGAGACAACGGCGCAGCGAAGGATTTGGGC GGCGCGAAGAAGGTGAAGGGAGAGGATGGCAAGGAGATGATGGAAGTTGCGGTGCCTACTGCGAGGGAGGACGTG GATCAACTTTGGGCCGCGTCGAGGGCTGCGTTGAAGGTCAAGCCCCCGGAGCAGAAGGAGAGTCGAGATGCCGCT ACCAAGCAGGCTGATCATGATCGGAATAGTAGGACGAATGTTGTGTTGGCGTGGGTTGGTTCGAACATGGTGCTT ATCATTGTTTTCACTTCCCAAGCCTTCTTGGACTGGGTGAACCAGAACACTTCGCTCGGTGGAAGTGCTTTCAAC CCATACCTGCAATTCCTCTTCTTTGCCTTTGCCGGCCTATCAGCCATCCGCTTCACAGGTTCAGTCGTATACCTG ATATTCAGACTATTCGGTCACTAG |
| Length | 2649 |
Gene
| Sequence id | CC1G_06628T0 |
|---|---|
| Sequence |
>CC1G_06628T0 CTCACGAGCGTTGCCAACGCTATTCCATTCTTTTTCACAGCCGGTCTGGTCAACATATCTACCTAATATCCCTAC GGACGCCAGCCACGACTCACAAACACAATGGCTTATCGTCCATCCCACAACGATCCTTACTACAATCAACCGAGC TATCCTCCAGCTACCGGTTACGGAGATTCCTCAAATTGGGACGCAAAGTCCACAAAGTCGTACCAAAGTAGTTAT GCAGGTTCCCAAGCCCACTTGAATCCATCCAGCTACGAGATGCAACAGGTTAACCAGCACCCAGTTCCTGCAATG CCATACAACGGCGGCTACCCACCACAGCAAACTATGCCTTCCCCAGGCGGCTTTAGGGACAATGGCTCTGTCGCG GGCTGGTCCCTGGCCAGAGACAAGCTTATGAAAAGGCGGTCTATCAAGAAAGTCTTCCTCACACAGGGAAACCTC GTCCTTGATGTACCCGTTCCCTCCCACATCGTCCCTGTTGGCAAGCAGGATCTCGAAGAATTCTCCAAGATGCGC TACACGGCGGCGACCTGCGACCCTGACGACTTCAAAGCTTCTCGCTACACCCTCAGGCCCTACCTCATGGGCCGC GAGACCGAGCTCTTTATTGTCATGACCATGTACAACGAAGACGAAGTCCTATTCGTCCGCACTATGAATGCGTAC GTGTTTATTGCCCTCTGTGAGATTCATAATGTATCTCTGACCCATTATACAGCGTCCTCAAGAACGTTGCTCATT TATGCAGCCGTCAAAAGTCAAAAACTTGGGGTCCAGAAGGCTGGAAGAAGGTCGTCGTCTGTGTCGTGTCAGATG GTCGTAACAAGGTCAACAAGCGGACACTGCAAGTATTGAACTTGGTAAGTTTCATCGTTCCCATCAGATATTATC CCGTCCTAACCACCCAACGTTGGCAGATGGGATGCTACCAAGAAGGTATCGCTAAAGATTCCGTGGCGGGCAAGG ATGTCACAGCCCACATCTTCGAGTATGTTATCTCCATCTCCCGTCTTTCAGAACACGGGCTCAACTCCCCGTAGG TACACCACCACAGCTATCGTGACAGAGACCGGCGAAGTCAGCCAGAACACATGTCCAGTCCAAGTTCTCTTCTGC TTGAAGGAACAGAACAAGAAGAAGTTGAACAGCCATAGATGGTTCTTCAATGCATTCGGACCTTTGCTGAACCCT AATGGTAAGTGCTATATTTAGCGTACAACGATGGATATCCTTGTTAATCGCATGCCTATAGTCTGTATCCTCCTG GACGTCGGCACAAAGCCCACCGGAACTTCAATCTATGAGCTATGGAAATGTAAGGTCTATCTATATCGTCTGGGA ATTTCAACTCAACTCGGCCCACCCAGGCTTCGATAAGCACAAACATGTCGGTGGTGCTTGTGGCGAGTAAGTAAC CCCGCCGTATACTCATCGGTCTTGTTCTGATCGTCTTCTCCAGAATCACTGTTGACAGTGGCCGCGGGTGCAGCC TCCTTCTCACAAGTCCTCTCGCAGCCTCCCAGAACTTTGAGGTATAACCACCCTTCCTCTTTCTAGAAGTCCTCG TCGTCAAGTGCGTTAACAACGTGTCCGTGTTTCCTGTTCACAGTACAAAATGTCCAATATCCTTGACAAACCTTT GGAGGTGGGTTGACATGGTTATTTCATTGAGGACCGTGGTTATTGATTCAAATTACGTGGTCTAGAGCGTGTTTG GTTACATTAGCGTGTTGCCTGGTGCATTCAGCGCTTACCGATACAAGGCTCTTTTGAACGGCCCTGATGGAAAGG GCCCGTTGGCATCTTACTTCAAGGGTGAGGCCATGCACGGAGGAGGTAGCGACGCTGGTCTCTTCGGTAAGTGAA CATCCTAGAAATCCGATGCGATGGACGTTGGCTGACTCTCTTTTCAGAGGTAATGCCATTATTATCGAGTCGGAG GGATGACGCTGAATGTTCCGTTTCCAGCGTAACATGTACCTCGCCGAAGATCGTATCCTCTGCTTCGAGATTGTC ACCAAGAAGAAGGAGGCCTGGACGTAAGTCTCCCACTTCATCTGTATCCTATCCACTTGAAGCTTATTGTGTTCT ATTAATAGATTGAAGTATGTCAAGAGCGCAAAGGCATCTACTGACGTCCCCGCGACTGTCCCGGAATTCATCTCT CAACGTCGTCGATGGTTGAACGGTTCCTTATTCGCTTCCATCCATGCAACGGTTTTCTTCTTCAGGATCTGGACG TCTGGTCAGGGCTTCTTCCGCAAGATCGCTCTCCAATTCGAGTTCATCTACAATGCCGTCCAACTTCTCTTCACA TGGACATCACTGGCCAACTTTTACCTCGCTTTCTTCTTCGTAAGCTGGTTTTTAGTTCCAACACATGCCAGTCGC TGATCGAGCATTGATTGTAGTTGGTTTCCTCGGCTACGGCAGAGGGCTCTACGGACGCATTCAACTTTCTGAGCA CTGGTGCAGGCAAGATCGTGTTCCAAATCTTCCTCAATCTCTACATCGGTCTTCTGTTCGTCGTCTTGGTCTGTT CTCTGGGTAATCGACCTCAAGTATGTACCATCCGCATAATGCGTGTTTCTGGCGATCGTCTTACTGATTTGAATC GTTTAGGGTTCAAAATGGACGTACACAATCGCCATGTTCTTGTTTGGTTTGTGTAATATCATCACCACATGGTGC GCTGCCTACACTGTCTACCTGGCTGTCCCCCACGATATCGAAGGATGGAGAAACTTCCCTGAGTAAGTCTACTTC CTGTTTCAAGATGCAAGACGTCATTGATTCCTTTTCCACAGACTGTTCAAGGAGAACCGCACGCTTCAGGAGATC GTCGTCGCCGTCCTCGCCACCTACGGCATGTACTTCATCAGTTCCTTCATCCACTTTGAACCTTGGCACATGTTC ACCTCCTTTGCGCAATACATGTTCCTCCTCCCCTCGTACGTCAACATCCTCATGATGTACGCCATGTGCAACTTG CATGATGTCACTTGGGGAACGAAAGGAGACAACGGCGCAGCGAAGGATTTGGGCGGCGCGAAGAAGGTGAAGGGA GAGGATGGCAAGGAGATGATGGAAGTTGCGGTGCCTACTGCGAGGGAGGACGTGGATCAACTTTGGGCCGCGTCG AGGGCTGCGTTGAAGGTCAAGCCCCCGGAGCAGAAGGAGAGTCGAGATGCCGCTACCAAGCAGGCTGATCATGAT CGGAATAGTAGGACGAATGTTGTGTTGGCGTGGGTTGGTTCGAACATGTGAGTGCAGTCGACGGTTCTAGATGCT TCTCGTTGGCGGATGACTGACTGATCTTTTTGCAGGGTGCTTATCATTGTTTTCACTTCCCAAGCCTTCTTGGAC TGGGTGAACCAGAACACTTCGCTCGGTGGAAGTGCTTTCAACCCATACCTGCAATTCCTCTTCTTTGCCTTGTAC GTCCTCCTCCTTTGACAACCCTATGCCCAGGCTCAGACACCTTTCTTTCTCTAGTGCCGGCCTATCAGCCATCCG CTTCACAGGTTCAGTCGTATACCTGATATTCAGACTATTCGGTCACTAG |
| Length | 3574 |