CC1G_06734
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_06734 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N1Q4 | Functional description | Chondroitin AC lyase |
| Location | Chr_1:1705089..1707824 | Strand | + |
| Gene length (nt) | 2736 | Transcript length (nt) | 2184 |
| CDS length (nt) | 2184 | Protein length (aa) | 727 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB29606 | 57 | 3.272E-293 | 911 |
| Agrocybe aegerita | Agrae_CAA7266471 | 53.5 | 6.629E-273 | 852 |
| Grifola frondosa | Grifr_OBZ79298 | 50.8 | 5.764E-253 | 794 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1476771 | 51 | 3.097E-252 | 792 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_214326 | 51.4 | 2.656E-250 | 786 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_31645 | 51.3 | 2.99E-249 | 783 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1111478 | 50 | 1.624E-248 | 781 |
| Pleurotus ostreatus PC9 | PleosPC9_1_53101 | 49.8 | 1.717E-247 | 778 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_124358 | 49 | 6.094E-242 | 762 |
| Flammulina velutipes | Flave_chr08AA00957 | 48.5 | 5.908E-232 | 733 |
| Schizophyllum commune H4-8 | Schco3_2628008 | 45.1 | 6.907E-211 | 672 |
| Auricularia subglabra | Aurde3_1_1244861 | 43.8 | 3.316E-204 | 653 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 5794 |
| Description | Chondroitin AC lyase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF08124 | Polysaccharide lyase family 8, N terminal alpha-helical domain | IPR012970 | 117 | 268 |
| Pfam | PF02278 | Polysaccharide lyase family 8, super-sandwich domain | IPR003159 | 352 | 598 |
| Pfam | PF02884 | Polysaccharide lyase family 8, C-terminal beta-sandwich domain | IPR004103 | 614 | 685 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR012970 | Polysaccharide lyase 8, N-terminal alpha-helical |
| IPR008929 | Chondroitin AC/alginate lyase |
| IPR011071 | Polysaccharide lyase family 8-like, C-terminal |
| IPR011013 | Galactose mutarotase-like domain superfamily |
| IPR038970 | Polysaccharide lyase 8 |
| IPR003159 | Polysaccharide lyase family 8, central domain |
| IPR014718 | Glycoside hydrolase-type carbohydrate-binding |
| IPR004103 | Polysaccharide lyase family 8, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005975 | carbohydrate metabolic process | BP |
| GO:0003824 | catalytic activity | MF |
| GO:0030246 | carbohydrate binding | MF |
| GO:0016829 | lyase activity | MF |
| GO:0005576 | extracellular region | CC |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | Polysaccharide lyase family 8, N terminal alpha-helical domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| PL | PL8 | PL8_4 |
Transcription factor
| Group |
|---|
| No records |
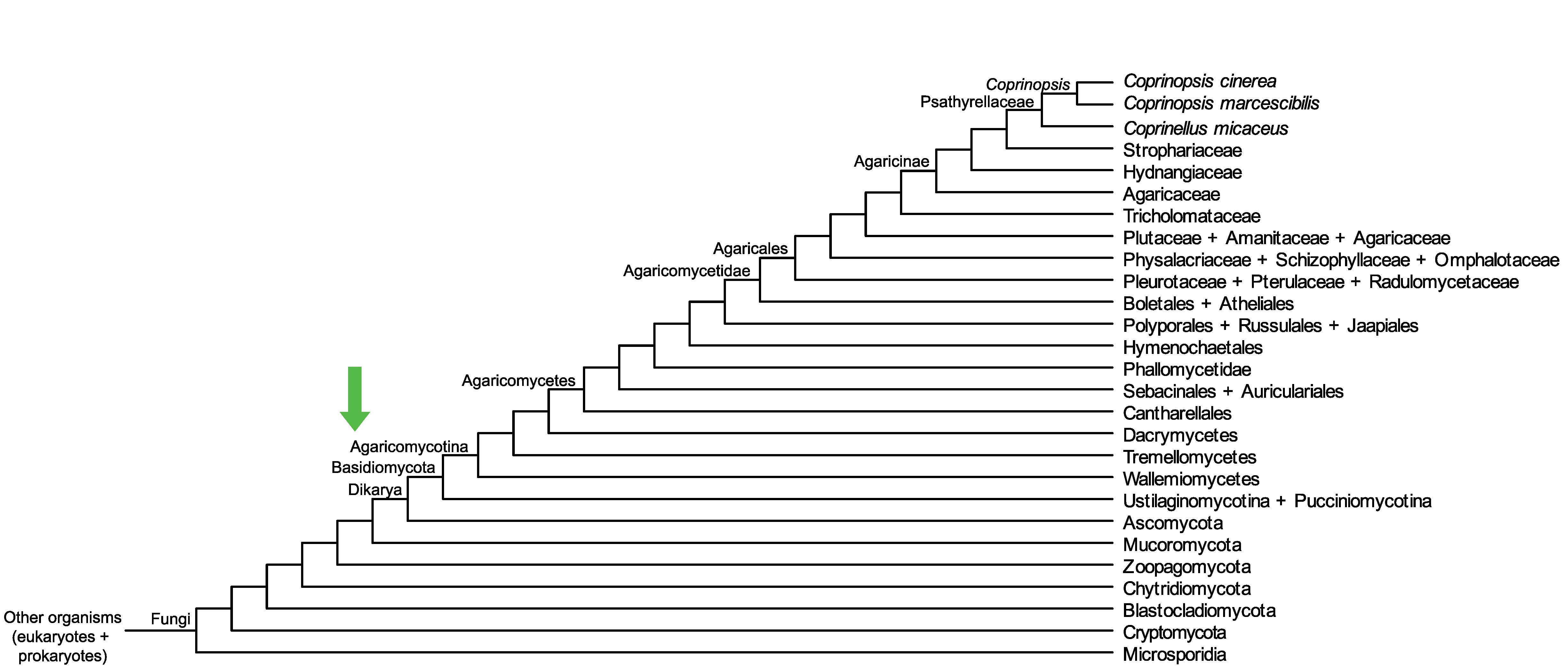
Conservation of CC1G_06734 across fungi.
Arrow shows the origin of gene family containing CC1G_06734.
Protein
| Sequence id | 5794 |
|---|---|
| Sequence |
>5794 MALAGVHKWELARCRLDSLDNLTGKWPDTEVDYTTGCGARRANWPAQAHWQRILVMSGAWHGGYRGAEQWVKDER LRTTIGRAMEYWFSRDITNVDCLDWGGTPRCPCDNVDDSLWNTNWFSNIILIPRLAGQSCLLLSDSLTLREREVC SNITRRSFGTFGIKLNQVGYLTGANTLDVARVGIDCGLLNSNISMIADAYRRIHDELVIQNVTKVDGIRADGSFA QHAGVLYNGNYGKDYSNAVLDVEVIAAGTSFSADTTAQTAFETLFDGHRWMIFSNTLSQVLHFDFSVLGRFITFP VIDDQATGSIQINLTKTWELGRLWSSPSLTTFGESLMQNFSSANAGGLTGTRMFFANDYMVHRGPNFFSSLKMYS SRTLNTECINSQNPLGFHLSDGTLYTYLRGNEYTDISAAWDWDLIPGTTVDYRNTLLHCSGATVTGRESFVGGLS DGKTGIAAMRYTNPTTRSLRWQKTWFFLNDGAQHVVINILASSSGAPVYSVLDQKRRNGLTVVDRREVLNSSTIT GPQRLWHDNVGYAFRSLTNATTPLHVRMGERTGSWSAIGTSTQPPVSVDMWAGLLEHIDLSQPLEYTILPGTSYP DFLQRTELPRVETIANNDNVTAIYDQRTGIAMVVFWNNGESSIAIDTRTPIAQMTITSTANVIVMFSTKNGTVLV SDPTQMLDTVVLKFTIGRGKRPLYWKGQAEKSLVFQLPGGGRRGDSVSGTIR |
| Length | 727 |
Coding
| Sequence id | CC1G_06734T0 |
|---|---|
| Sequence |
>CC1G_06734T0 ATGGCTCTAGCGGGTGTTCACAAATGGGAATTGGCTCGTTGTAGGCTTGACTCGCTGGACAATTTGACAGGCAAA TGGCCTGATACAGAAGTTGATTACACGACCGGCTGCGGGGCGCGAAGGGCTAACTGGCCTGCTCAGGCGCATTGG CAGAGGATCCTGGTCATGTCCGGGGCTTGGCACGGAGGATACAGAGGAGCAGAACAATGGGTCAAGGACGAAAGG CTGAGAACTACCATTGGACGAGCCATGGAATATTGGTTCTCCCGTGATATCACGAATGTTGACTGTCTCGATTGG GGTGGAACCCCCCGCTGCCCGTGTGACAACGTCGATGATTCTCTATGGAATACCAACTGGTTCTCAAACATTATC CTCATTCCCAGACTCGCAGGACAATCATGTCTGCTCTTAAGCGATTCGCTGACCTTGAGGGAAAGAGAAGTTTGT TCGAACATTACTCGACGATCGTTTGGAACCTTTGGGATTAAGCTGAATCAGGTTGGATACCTGACTGGCGCGAAT ACACTCGATGTAGCACGAGTCGGAATTGACTGCGGGCTGCTCAATAGCAATATTTCAATGATCGCCGACGCTTAT CGTCGAATCCACGACGAATTGGTCATTCAAAACGTCACAAAAGTAGACGGAATACGGGCAGACGGTTCCTTTGCG CAACATGCAGGTGTTCTTTACAATGGAAACTATGGAAAGGACTACTCGAACGCAGTGTTGGACGTCGAGGTGATT GCGGCGGGAACATCGTTCTCGGCAGATACGACTGCTCAGACCGCATTCGAGACGTTGTTCGACGGACATAGGTGG ATGATCTTCTCCAATACGCTTTCCCAGGTCTTGCACTTTGACTTTTCCGTTCTTGGGCGATTTATCACGTTCCCT GTCATCGACGACCAGGCTACTGGGAGCATCCAAATCAACCTCACCAAAACTTGGGAACTAGGGCGCCTATGGTCT TCCCCATCCTTGACTACATTCGGGGAGTCACTCATGCAGAACTTCTCCAGCGCAAACGCAGGAGGATTGACGGGA ACGAGAATGTTCTTTGCAAATGATTATATGGTCCACAGAGGTCCAAACTTTTTCTCGTCTCTCAAGATGTACTCC AGTCGAACGCTTAACACAGAATGCATCAACTCACAGAATCCGCTCGGGTTCCACCTCTCCGATGGAACGCTTTAC ACTTACCTCCGAGGAAATGAATATACCGATATCTCTGCTGCATGGGACTGGGATCTGATTCCCGGAACAACAGTG GATTACCGCAACACGCTTTTACATTGCAGTGGGGCCACGGTCACAGGCCGGGAGAGTTTCGTTGGCGGTTTATCC GATGGAAAGACTGGAATAGCGGCCATGCGTTATACGAACCCCACCACTCGATCGCTGCGATGGCAAAAGACATGG TTCTTCCTCAACGACGGTGCCCAACACGTCGTGATCAACATTCTGGCGTCCAGTAGCGGGGCCCCCGTATATTCA GTTTTGGATCAAAAGCGTCGCAACGGACTCACCGTCGTAGACAGGAGGGAAGTATTGAACTCGTCGACTATCACT GGCCCTCAACGGCTATGGCACGACAATGTCGGGTATGCCTTCAGGAGCTTGACAAATGCCACTACTCCCTTGCAC GTACGCATGGGCGAGAGGACTGGGAGCTGGTCGGCGATTGGTACGTCGACCCAACCCCCGGTGTCTGTTGACATG TGGGCAGGGTTGCTGGAACATATCGACCTGTCGCAACCTCTGGAATATACCATCCTTCCTGGAACTTCATACCCA GACTTCCTGCAGAGAACCGAATTACCCAGAGTGGAGACCATCGCCAACAACGACAACGTTACCGCTATTTACGAT CAGCGAACGGGAATCGCGATGGTCGTATTTTGGAACAACGGCGAAAGTTCAATTGCAATCGATACCCGGACACCC ATTGCTCAAATGACCATTACATCCACAGCCAATGTCATTGTAATGTTTTCCACCAAAAACGGCACAGTGCTTGTC TCCGACCCGACCCAAATGCTTGACACAGTCGTACTGAAATTCACTATCGGCCGGGGCAAACGACCTTTGTACTGG AAGGGGCAGGCGGAAAAATCGCTGGTATTTCAGTTGCCTGGTGGAGGACGGAGGGGAGACAGTGTATCTGGCACC ATTCGA |
| Length | 2184 |
Transcript
| Sequence id | CC1G_06734T0 |
|---|---|
| Sequence |
>CC1G_06734T0 ATGGCTCTAGCGGGTGTTCACAAATGGGAATTGGCTCGTTGTAGGCTTGACTCGCTGGACAATTTGACAGGCAAA TGGCCTGATACAGAAGTTGATTACACGACCGGCTGCGGGGCGCGAAGGGCTAACTGGCCTGCTCAGGCGCATTGG CAGAGGATCCTGGTCATGTCCGGGGCTTGGCACGGAGGATACAGAGGAGCAGAACAATGGGTCAAGGACGAAAGG CTGAGAACTACCATTGGACGAGCCATGGAATATTGGTTCTCCCGTGATATCACGAATGTTGACTGTCTCGATTGG GGTGGAACCCCCCGCTGCCCGTGTGACAACGTCGATGATTCTCTATGGAATACCAACTGGTTCTCAAACATTATC CTCATTCCCAGACTCGCAGGACAATCATGTCTGCTCTTAAGCGATTCGCTGACCTTGAGGGAAAGAGAAGTTTGT TCGAACATTACTCGACGATCGTTTGGAACCTTTGGGATTAAGCTGAATCAGGTTGGATACCTGACTGGCGCGAAT ACACTCGATGTAGCACGAGTCGGAATTGACTGCGGGCTGCTCAATAGCAATATTTCAATGATCGCCGACGCTTAT CGTCGAATCCACGACGAATTGGTCATTCAAAACGTCACAAAAGTAGACGGAATACGGGCAGACGGTTCCTTTGCG CAACATGCAGGTGTTCTTTACAATGGAAACTATGGAAAGGACTACTCGAACGCAGTGTTGGACGTCGAGGTGATT GCGGCGGGAACATCGTTCTCGGCAGATACGACTGCTCAGACCGCATTCGAGACGTTGTTCGACGGACATAGGTGG ATGATCTTCTCCAATACGCTTTCCCAGGTCTTGCACTTTGACTTTTCCGTTCTTGGGCGATTTATCACGTTCCCT GTCATCGACGACCAGGCTACTGGGAGCATCCAAATCAACCTCACCAAAACTTGGGAACTAGGGCGCCTATGGTCT TCCCCATCCTTGACTACATTCGGGGAGTCACTCATGCAGAACTTCTCCAGCGCAAACGCAGGAGGATTGACGGGA ACGAGAATGTTCTTTGCAAATGATTATATGGTCCACAGAGGTCCAAACTTTTTCTCGTCTCTCAAGATGTACTCC AGTCGAACGCTTAACACAGAATGCATCAACTCACAGAATCCGCTCGGGTTCCACCTCTCCGATGGAACGCTTTAC ACTTACCTCCGAGGAAATGAATATACCGATATCTCTGCTGCATGGGACTGGGATCTGATTCCCGGAACAACAGTG GATTACCGCAACACGCTTTTACATTGCAGTGGGGCCACGGTCACAGGCCGGGAGAGTTTCGTTGGCGGTTTATCC GATGGAAAGACTGGAATAGCGGCCATGCGTTATACGAACCCCACCACTCGATCGCTGCGATGGCAAAAGACATGG TTCTTCCTCAACGACGGTGCCCAACACGTCGTGATCAACATTCTGGCGTCCAGTAGCGGGGCCCCCGTATATTCA GTTTTGGATCAAAAGCGTCGCAACGGACTCACCGTCGTAGACAGGAGGGAAGTATTGAACTCGTCGACTATCACT GGCCCTCAACGGCTATGGCACGACAATGTCGGGTATGCCTTCAGGAGCTTGACAAATGCCACTACTCCCTTGCAC GTACGCATGGGCGAGAGGACTGGGAGCTGGTCGGCGATTGGTACGTCGACCCAACCCCCGGTGTCTGTTGACATG TGGGCAGGGTTGCTGGAACATATCGACCTGTCGCAACCTCTGGAATATACCATCCTTCCTGGAACTTCATACCCA GACTTCCTGCAGAGAACCGAATTACCCAGAGTGGAGACCATCGCCAACAACGACAACGTTACCGCTATTTACGAT CAGCGAACGGGAATCGCGATGGTCGTATTTTGGAACAACGGCGAAAGTTCAATTGCAATCGATACCCGGACACCC ATTGCTCAAATGACCATTACATCCACAGCCAATGTCATTGTAATGTTTTCCACCAAAAACGGCACAGTGCTTGTC TCCGACCCGACCCAAATGCTTGACACAGTCGTACTGAAATTCACTATCGGCCGGGGCAAACGACCTTTGTACTGG AAGGGGCAGGCGGAAAAATCGCTGGTATTTCAGTTGCCTGGTGGAGGACGGAGGGGAGACAGTGTATCTGGCACC ATTCGATAA |
| Length | 2184 |
Gene
| Sequence id | CC1G_06734T0 |
|---|---|
| Sequence |
>CC1G_06734T0 ATGGCTCTAGCGGGTGTTCACAAATGGGAATTGGCTCGTTGTAGGCTTGACTCGCTGGACAATTTGACAGGCAAA TGGCCTGATACAGAAGTTGATTACACGACCGGCTGCGGGGCGCGAAGGGCTAACTGGCCTGCTCAGGCGCATTGG CAGAGGATCCGTGCGTCATACATGCAATATGCCATTTAATCTTTGGTTCTGACATCTGGACAGTGGTCATGTCCG GGGCTTGGCACGGAGGATACAGAGGAGCAGAACAATGGGTCAAGGACGAAAGGCTGAGAACTACCATTGGACGAG CCATGGAATATTGGTTCTCCCGTGATATCACGAATGTTGACTGTCTCGATTGGGGTGGAACCCCCCGCTGCCCGT GTGACAACGTCGATGATTCTCTATGGTAAGCCGTCTTCCCGTCATCTGCATCTAAATGTCTCTCTGAAGGGCCAC TCCACAGGAATACCAACTGGTTCTCAAACGTAAGCTTAAAGTCACTCCATGTCTTGATGAAGATAACGTACTGAC CTCGCAAAACAGATTATCCTCATTCCCAGACTCGCAGGACAATCATGTCTGCTCTTAAGCGATTCGCTGACCTTG AGGGAAAGAGAAGTTTGTTCGAACATTACTCGACGATCGTTTGGAACCTTTGGGATTAAGCTGAATCAGGTTGGA TACCTGACTGGCGCGAATACACTCGATGTAGCACGAGTCGGAATTGACTGCGGGCTGCTCAATAGCAATATTTCA ATGATCGCCGACGCTTATCGTCGAATCCACGACGAATTGGTCATTCAAAACGTCACAAAAGTAGACGGAATACGG GCAGACGGTTCCTTTGGTGCGTCTATGCGTTCACTTCACGAACGTATTTCAAACATATTTCATCCAGCGCAACAT GCAGGTGTTCTTTACAATGGAAACTATGGTACGTTCTATGCCACGTGGTATATTGTCTAAACCAATTAAGGTGCG ACCAGGAAAGGACTAGTAAGGGGTTGACAGTTCTGTCGACCTTGCCAGACAATGAACACTCCTCTTAGCTCGAAC GCAGTGTTGGACGTCGAGGTGATTGCGGCGGGAACATCGTTCTCGGCAGATACGACTGCTCAGACCGCATTCGAG ACGTTGTTCGACGGACATAGGTGGATGATCTTCTCCAATACGCTTTCCCAGGTCTTGCACTTTGACTTTGTGAGT TCGTTCGCATTCGCGCAAGCTGCGACTCATGAGGCCGTCCTTCCAACTAGTCCGTTCTTGGGCGATTTATCACGT TCCCTGTCATCGACGACCAGTAAGTCCAAACCTCAATAGCCTGTCAAATATCATGTCTGAGCGTTTCTAATAGGG CTACTGGGAGCATCCAAATCAACCTCACCAAAACTTGGGAACTAGGGCGCCTATGGTCTTCCCCATCCTTGACTA CATTCGGGGAGTCACTCATGCAGAACTTCTCCAGCGCAAACGCAGGAGGATTGACGGGAACGAGAATGTTCTTTG CAAATGATTATATGGTGGGCCACCACATTCACTAGCAGCTCGCTCAACCGGATTCGAGTCTATGATTCACAGGTC CACAGAGGTCCAAACTTTTTCTCGTCTCTCAAGATGTACTCCAGTCGAACGCTTAACACAGAATGCATCAACTCA CAGAATGTAAGTCGTATTTTAACGAACGTATGTTATCTGGGCTGATCCTTGCTCCGATCCGATTAGCCGCTCGGG TTCCACCTCTCCGATGGAACGCTTTACACTTACCTCCGAGGAAATGAATATACCGATATCTCTGCTGCATGGGAC TGGGATCTGATTCCCGGAACAACAGTGGATTACCGCAACACGCTTTTACATTGCAGTGGGGCCACGGTCACAGGC CGGGAGAGTTTCGTTGGCGGTTTATCCGATGGAAAGACTGGAATAGCGGCCATGCGTTATACGAACCCCACCACT CGATCGCTGCGATGGCAAAAGACATGGTTCTTCCTCAACGACGGTGCCCAACACGTCGTGATCAACATTCTGGCG TCCAGTAGCGGGGCCCCCGTATATTCAGTTTTGGATCAAAAGCGTCGCAACGGACTCACCGTCGTAGACAGGAGG GAAGTATTGAACTCGTCGACTATCACTGGCCCTCAACGGCTATGGCACGACAATGTCGGGTATGCCTTCAGGAGC TTGACAAATGCCACTACTCCCTTGCACGTACGCATGGGCGAGAGGACTGGGAGCTGGTCGGCGATTGGTACGTCG ACCCAACCCCCGGTGTCTGTTGACATGTGGGCAGGGTTGCTGGAACATATCGACCTGTCGCAACCTCTGGAATAT ACCATCCTTCCTGGAACTTCATACCCAGACTTCCTGCAGAGAACCGAATTACCCAGAGTGGAGACCATCGCCAAC AACGACAACGTTACCGCTATTTACGATCAGCGAACGGGAATCGCGATGGTCGTATTTTGGAACAACGGCGAAAGT TCAATTGCAATCGATACCCGGACACCCATTGCTCAAATGACCATTACATCCACAGCCAATGTCATTGTAATGTTT TCCACCAAAAACGGCACAGTGCTTGTCTCCGACCCGACCCAAATGCTTGACACAGTCGTACTGAAATTCACTATC GGCCGGGGCAAACGACCTTTGTACTGGAAGGGGCAGGCGGAAAAATCGCTGGTATTTCAGTTGCCTGGTGGAGGA CGGAGGGGAGACAGTGTATCTGGCACCATTCGATAA |
| Length | 2736 |