CC1G_06931
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_06931 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NZQ7 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_6:619818..623580 | Strand | + |
| Gene length (nt) | 3763 | Transcript length (nt) | 3477 |
| CDS length (nt) | 3477 | Protein length (aa) | 1158 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN0235_ireA |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB19766 | 57.7 | 0 | 1284 |
| Agrocybe aegerita | Agrae_CAA7269916 | 57 | 0 | 1238 |
| Schizophyllum commune H4-8 | Schco3_2629108 | 55.7 | 0 | 1234 |
| Flammulina velutipes | Flave_chr11AA01750 | 56.4 | 0 | 1174 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_37330 | 53.9 | 0 | 1158 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_120939 | 51.8 | 0 | 1114 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1060565 | 52.9 | 0 | 1105 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1471524 | 49.5 | 0 | 1095 |
| Lentinula edodes NBRC 111202 | Lenedo1_739048 | 48.9 | 0 | 1033 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_10463 | 48.9 | 0 | 1033 |
| Grifola frondosa | Grifr_OBZ76674 | 49.2 | 2.094E-304 | 1004 |
| Auricularia subglabra | Aurde3_1_1272235 | 48.1 | 4.079E-295 | 934 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_60620 | 74 | 7.946E-234 | 754 |
| Lentinula edodes B17 | Lened_B_1_1_11946 | 51.3 | 1.244E-225 | 730 |
| Pleurotus ostreatus PC9 | PleosPC9_1_82636 | 79.6 | 1.387E-224 | 727 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 5975 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd09769 | Luminal_IRE1 | - | 63 | 384 |
| CDD | cd10422 | RNase_Ire1 | - | 1024 | 1153 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 714 | 906 |
| Pfam | PF06479 | Ribonuclease 2-5A | IPR010513 | 1026 | 1153 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 20 | 0.9802 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR018391 | Pyrrolo-quinoline quinone beta-propeller repeat |
| IPR045133 | Serine/threonine-protein kinase/endoribonuclease IRE1/2-like |
| IPR000719 | Protein kinase domain |
| IPR010513 | KEN domain |
| IPR015943 | WD40/YVTN repeat-like-containing domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR038357 | KEN domain superfamily |
| IPR011047 | Quinoprotein alcohol dehydrogenase-like superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004521 | endoribonuclease activity | MF |
| GO:0004674 | protein serine/threonine kinase activity | MF |
| GO:0030968 | endoplasmic reticulum unfolded protein response | BP |
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004540 | ribonuclease activity | MF |
| GO:0006397 | mRNA processing | BP |
| GO:0005515 | protein binding | MF |
KEGG
| KEGG Orthology |
|---|
| K08852 |
EggNOG
| COG category | Description |
|---|---|
| T | domain in protein kinases, N-glycanases and other nuclear proteins |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
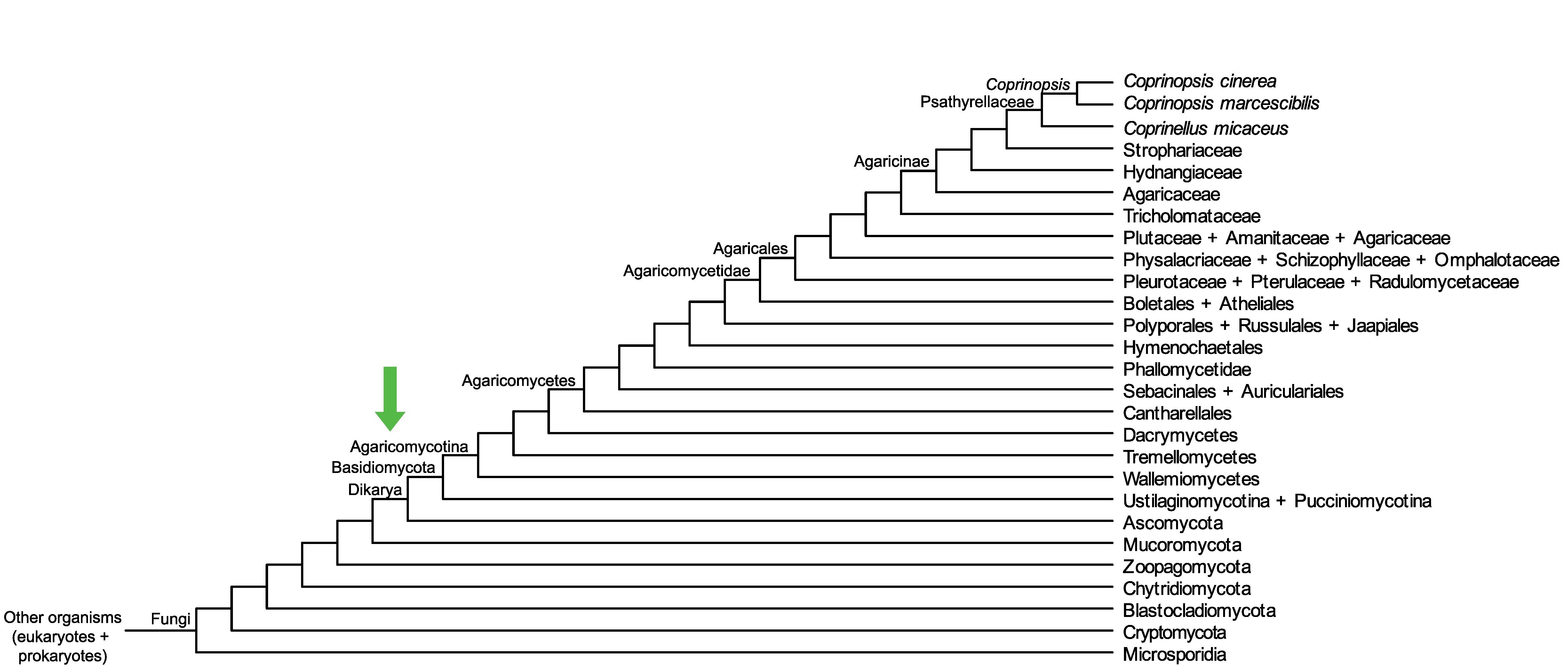
Conservation of CC1G_06931 across fungi.
Arrow shows the origin of gene family containing CC1G_06931.
Protein
| Sequence id | 5975 |
|---|---|
| Sequence |
>5975 MAFVFFLQFLLLIVGAVCWAEIVNVRSTIPAAETAALIQRTRPAPTYATGGILEPTKDLELLDIVLVASIDGKFH ALSRSTGKILWSMPAFARAEGSSTLSSLAPLVRTTHPENDPDDFDDDTTPETYIIEPQSGHIYVVNSEDDSLQRF PFSMAELVDMSPFTSPGDDEKRVFIGRKETSLLLLELETGRIKATLNSECPPYDDRRIDLDELEEPESRGSSTTE VFIGRTDYYISIYPHRSKGYGTRAPVQNLSFSVYGPNNEDNLLQANYRRTSDDAYIQGFPNGDVYSFKTKSEGGR VQTQPLWVQKFHAPTVAVFDVLRGSTPLQPHPHAFVLLQPRPRAEDVIPGLDRSLLRGAKSAYVGMVEETGSLYA MSPSHYPLVAFGDAEEGRKGRLIEGSGGSAQSIHDIIRNQKEADRRIRCEDNPRDRECLLGMHPLDETDGHESRM RRLLEGPSSISPIPTFRPGQNQWIDHGIEVVPNIEAPPNNSQQPATPVPPEEVRKTGWEYLGVTLGLGLVSLWFL FKKFGQREGFKVPKFIPVPNGDAQIARPLAPIPDTATEPAPAPEPATVQPLQIIPEQPAPPAPLPLPLPPLEDPT TDALAGTGEEGDDTDREGDPEPETVATPGRKKPRRGKRGKKKKKDATPIPGEEGVEGKAPNGPDGPAANGTPNIN PPDNNPDATIAPAAPQSPSLVVSSPIIPAAAGPSLVVSDTILGFGSHGTVVFQGSLQGRAVAVKRLLKDFVTLAS REVSILQESDDHPNVIRYYYQEAHANFLYIALELCPASLADIIETPDREAFRDIAISFDPKRALKQITSGLKHLH ALKLVHRDIKPQNILITTNKSTGRGRPTYRMLISDFGLCKKLDVDQTSFLPTMNGGMGAGTVGWRAPEILRGEVK LDDLSDDHSMSSRGSVSTINGSSSSSSTSGLSTAKPTRLTKSVDIFALGCLYYYTLTNGSHPYGDRFEREVNILK DAKSLDLLERFGEEGTEACDLIEKMLDPEASERPDTTACLLHPFFWDPARRLNFLQDASDRFEIMCRDPKDPLLL QLETGALAIVGNDWHARLDRLFVENLGKFRKYDGKSVQDLLRALRNKKHHYQDLPDNVKRSLGPMPEGFLAYFTK RFPRLFLHVHRVISDTVLRTESMFRSYFELPDS |
| Length | 1158 |
Coding
| Sequence id | CC1G_06931T0 |
|---|---|
| Sequence |
>CC1G_06931T0 ATGGCGTTCGTATTCTTCCTACAGTTCTTGCTCCTCATCGTGGGCGCGGTCTGCTGGGCAGAGATCGTCAATGTC CGGTCAACCATCCCAGCAGCGGAGACGGCGGCGCTCATACAACGAACGAGACCAGCACCTACTTATGCGACCGGA GGGATTCTAGAACCCACCAAAGACCTAGAGCTGCTGGACATTGTCCTGGTAGCCTCGATCGACGGCAAATTCCAT GCACTCAGTCGCTCGACGGGCAAGATCTTGTGGTCTATGCCTGCATTCGCACGGGCAGAAGGCTCGTCAACTCTT TCAAGCTTGGCGCCTCTGGTTAGGACGACACACCCAGAAAACGACCCCGACGACTTTGACGACGATACAACACCA GAAACCTATATCATTGAACCGCAGTCTGGCCACATCTATGTCGTAAACTCAGAAGACGACTCGTTGCAACGGTTC CCGTTCTCAATGGCGGAGTTGGTTGACATGTCGCCGTTCACCTCCCCAGGTGACGACGAGAAGAGGGTATTCATT GGGCGCAAGGAGACTTCACTATTGTTACTGGAGCTCGAAACAGGAAGAATCAAGGCGACCCTCAACTCCGAATGT CCGCCTTATGACGACAGGCGTATTGACCTCGACGAGCTGGAAGAACCAGAGTCGCGGGGCTCATCGACCACCGAA GTATTCATTGGGCGAACAGATTATTACATTTCCATCTATCCCCACCGCTCTAAGGGCTACGGCACTCGGGCGCCC GTCCAAAACCTGTCATTCTCAGTCTACGGACCCAACAACGAAGACAACTTGCTCCAAGCAAACTATCGAAGGACT AGCGACGATGCGTACATCCAAGGTTTTCCCAACGGGGATGTCTACTCCTTTAAGACCAAGTCGGAAGGGGGTAGA GTCCAAACACAACCTTTATGGGTTCAGAAATTCCATGCACCGACGGTCGCTGTTTTTGATGTCCTACGGGGCTCA ACTCCACTTCAGCCACATCCTCACGCCTTTGTTCTCCTGCAACCACGACCACGCGCGGAAGATGTCATCCCAGGT CTCGACCGCTCTCTCTTACGTGGTGCAAAGTCGGCCTACGTTGGGATGGTGGAGGAAACGGGGAGCCTTTACGCT ATGAGCCCTTCACATTATCCACTGGTTGCGTTTGGGGACGCAGAGGAGGGCAGAAAGGGACGACTTATTGAGGGT TCTGGGGGTTCAGCGCAAAGCATCCATGATATCATCCGCAACCAGAAGGAGGCTGACAGGCGGATTAGATGCGAG GATAACCCGAGAGACCGCGAGTGTCTACTGGGTATGCATCCGCTTGACGAAACGGACGGCCATGAAAGTCGAATG CGACGACTGCTCGAAGGACCTTCAAGCATCAGCCCCATCCCGACGTTCAGACCCGGTCAGAACCAATGGATCGAT CACGGAATCGAAGTCGTCCCCAACATTGAAGCTCCACCCAACAATTCTCAACAACCTGCCACGCCTGTCCCCCCG GAGGAAGTACGGAAGACGGGATGGGAATATCTGGGAGTAACACTCGGGCTGGGTTTGGTGTCTTTGTGGTTCTTA TTCAAGAAGTTCGGCCAGCGAGAGGGATTCAAGGTACCCAAATTCATTCCCGTACCCAACGGGGACGCGCAGATC GCCCGTCCCCTTGCTCCCATACCGGACACTGCCACCGAGCCAGCACCAGCACCCGAACCAGCTACGGTCCAGCCT CTTCAGATCATCCCCGAACAGCCTGCACCACCGGCACCCCTACCATTGCCTCTGCCTCCATTGGAGGACCCCACT ACGGATGCACTTGCCGGAACTGGCGAAGAAGGTGATGACACCGACCGTGAAGGCGATCCAGAGCCCGAGACAGTC GCAACCCCTGGAAGGAAGAAGCCGAGGAGAGGTAAACGAGGAAAGAAGAAGAAGAAGGACGCCACGCCTATCCCT GGTGAAGAAGGTGTTGAGGGCAAGGCGCCTAATGGACCCGATGGACCAGCTGCGAATGGCACACCAAACATCAAT CCGCCAGACAACAACCCAGATGCCACTATCGCTCCTGCAGCCCCACAATCTCCTTCACTTGTCGTCTCATCTCCC ATAATTCCTGCGGCCGCAGGTCCATCGTTAGTCGTGTCCGATACCATTCTCGGCTTTGGCTCTCATGGAACTGTT GTCTTCCAAGGTTCTCTACAGGGTCGAGCAGTCGCAGTGAAGCGGCTCCTCAAAGACTTTGTTACTCTGGCTTCA CGTGAAGTCAGCATCCTCCAAGAGAGTGACGACCACCCGAATGTTATCCGATATTACTACCAAGAAGCCCACGCC AATTTCCTCTATATCGCTCTTGAACTCTGCCCCGCATCCCTAGCCGACATCATCGAAACTCCTGACCGAGAAGCC TTCAGAGATATCGCCATTTCCTTCGACCCCAAGAGGGCGTTGAAGCAGATCACGAGCGGTCTCAAGCACCTCCAT GCGCTCAAACTCGTCCACCGTGACATCAAGCCCCAGAATATTCTTATTACGACAAACAAGAGCACTGGACGTGGG CGACCGACATATCGTATGCTCATCTCTGACTTCGGATTGTGCAAGAAGTTGGACGTTGACCAAACGAGTTTCTTA CCAACCATGAATGGCGGGATGGGTGCTGGGACGGTCGGGTGGAGAGCACCGGAGATTTTACGTGGCGAGGTCAAG CTTGATGATTTGAGCGATGATCACTCCATGAGTTCGAGAGGAAGTGTGTCAACCATTAACGGGTCATCATCGTCG TCGTCGACGTCGGGTCTCTCAACCGCGAAGCCAACACGACTCACCAAGTCTGTGGATATCTTCGCCCTTGGTTGC CTGTACTACTACACCTTGACCAACGGCAGCCATCCTTACGGGGATCGATTCGAGCGGGAAGTCAACATCTTGAAG GACGCCAAGTCGCTGGATTTACTGGAGAGATTTGGAGAGGAAGGAACCGAAGCGTGCGATTTGATCGAGAAGATG TTGGATCCCGAGGCATCTGAAAGACCGGATACGACTGCGTGCCTATTGCACCCCTTCTTCTGGGATCCCGCACGC CGCCTTAACTTCCTCCAAGACGCCTCGGACCGGTTCGAAATCATGTGTCGGGACCCCAAGGATCCTCTCCTACTG CAACTCGAAACCGGTGCGCTGGCCATCGTTGGAAATGACTGGCATGCAAGACTGGACAGGTTGTTTGTTGAGAAC CTTGGCAAGTTTAGAAAGTATGACGGAAAGTCTGTACAAGATTTGCTTCGTGCTCTTCGTAACAAGAAACACCAT TATCAAGACTTGCCTGACAATGTTAAGCGAAGTCTTGGGCCGATGCCAGAGGGCTTCCTGGCCTACTTCACGAAA CGTTTCCCCCGCCTCTTCTTACATGTCCATCGTGTCATCTCCGACACTGTACTACGGACAGAGTCTATGTTTAGA TCTTACTTTGAACTGCCTGACTCC |
| Length | 3477 |
Transcript
| Sequence id | CC1G_06931T0 |
|---|---|
| Sequence |
>CC1G_06931T0 ATGGCGTTCGTATTCTTCCTACAGTTCTTGCTCCTCATCGTGGGCGCGGTCTGCTGGGCAGAGATCGTCAATGTC CGGTCAACCATCCCAGCAGCGGAGACGGCGGCGCTCATACAACGAACGAGACCAGCACCTACTTATGCGACCGGA GGGATTCTAGAACCCACCAAAGACCTAGAGCTGCTGGACATTGTCCTGGTAGCCTCGATCGACGGCAAATTCCAT GCACTCAGTCGCTCGACGGGCAAGATCTTGTGGTCTATGCCTGCATTCGCACGGGCAGAAGGCTCGTCAACTCTT TCAAGCTTGGCGCCTCTGGTTAGGACGACACACCCAGAAAACGACCCCGACGACTTTGACGACGATACAACACCA GAAACCTATATCATTGAACCGCAGTCTGGCCACATCTATGTCGTAAACTCAGAAGACGACTCGTTGCAACGGTTC CCGTTCTCAATGGCGGAGTTGGTTGACATGTCGCCGTTCACCTCCCCAGGTGACGACGAGAAGAGGGTATTCATT GGGCGCAAGGAGACTTCACTATTGTTACTGGAGCTCGAAACAGGAAGAATCAAGGCGACCCTCAACTCCGAATGT CCGCCTTATGACGACAGGCGTATTGACCTCGACGAGCTGGAAGAACCAGAGTCGCGGGGCTCATCGACCACCGAA GTATTCATTGGGCGAACAGATTATTACATTTCCATCTATCCCCACCGCTCTAAGGGCTACGGCACTCGGGCGCCC GTCCAAAACCTGTCATTCTCAGTCTACGGACCCAACAACGAAGACAACTTGCTCCAAGCAAACTATCGAAGGACT AGCGACGATGCGTACATCCAAGGTTTTCCCAACGGGGATGTCTACTCCTTTAAGACCAAGTCGGAAGGGGGTAGA GTCCAAACACAACCTTTATGGGTTCAGAAATTCCATGCACCGACGGTCGCTGTTTTTGATGTCCTACGGGGCTCA ACTCCACTTCAGCCACATCCTCACGCCTTTGTTCTCCTGCAACCACGACCACGCGCGGAAGATGTCATCCCAGGT CTCGACCGCTCTCTCTTACGTGGTGCAAAGTCGGCCTACGTTGGGATGGTGGAGGAAACGGGGAGCCTTTACGCT ATGAGCCCTTCACATTATCCACTGGTTGCGTTTGGGGACGCAGAGGAGGGCAGAAAGGGACGACTTATTGAGGGT TCTGGGGGTTCAGCGCAAAGCATCCATGATATCATCCGCAACCAGAAGGAGGCTGACAGGCGGATTAGATGCGAG GATAACCCGAGAGACCGCGAGTGTCTACTGGGTATGCATCCGCTTGACGAAACGGACGGCCATGAAAGTCGAATG CGACGACTGCTCGAAGGACCTTCAAGCATCAGCCCCATCCCGACGTTCAGACCCGGTCAGAACCAATGGATCGAT CACGGAATCGAAGTCGTCCCCAACATTGAAGCTCCACCCAACAATTCTCAACAACCTGCCACGCCTGTCCCCCCG GAGGAAGTACGGAAGACGGGATGGGAATATCTGGGAGTAACACTCGGGCTGGGTTTGGTGTCTTTGTGGTTCTTA TTCAAGAAGTTCGGCCAGCGAGAGGGATTCAAGGTACCCAAATTCATTCCCGTACCCAACGGGGACGCGCAGATC GCCCGTCCCCTTGCTCCCATACCGGACACTGCCACCGAGCCAGCACCAGCACCCGAACCAGCTACGGTCCAGCCT CTTCAGATCATCCCCGAACAGCCTGCACCACCGGCACCCCTACCATTGCCTCTGCCTCCATTGGAGGACCCCACT ACGGATGCACTTGCCGGAACTGGCGAAGAAGGTGATGACACCGACCGTGAAGGCGATCCAGAGCCCGAGACAGTC GCAACCCCTGGAAGGAAGAAGCCGAGGAGAGGTAAACGAGGAAAGAAGAAGAAGAAGGACGCCACGCCTATCCCT GGTGAAGAAGGTGTTGAGGGCAAGGCGCCTAATGGACCCGATGGACCAGCTGCGAATGGCACACCAAACATCAAT CCGCCAGACAACAACCCAGATGCCACTATCGCTCCTGCAGCCCCACAATCTCCTTCACTTGTCGTCTCATCTCCC ATAATTCCTGCGGCCGCAGGTCCATCGTTAGTCGTGTCCGATACCATTCTCGGCTTTGGCTCTCATGGAACTGTT GTCTTCCAAGGTTCTCTACAGGGTCGAGCAGTCGCAGTGAAGCGGCTCCTCAAAGACTTTGTTACTCTGGCTTCA CGTGAAGTCAGCATCCTCCAAGAGAGTGACGACCACCCGAATGTTATCCGATATTACTACCAAGAAGCCCACGCC AATTTCCTCTATATCGCTCTTGAACTCTGCCCCGCATCCCTAGCCGACATCATCGAAACTCCTGACCGAGAAGCC TTCAGAGATATCGCCATTTCCTTCGACCCCAAGAGGGCGTTGAAGCAGATCACGAGCGGTCTCAAGCACCTCCAT GCGCTCAAACTCGTCCACCGTGACATCAAGCCCCAGAATATTCTTATTACGACAAACAAGAGCACTGGACGTGGG CGACCGACATATCGTATGCTCATCTCTGACTTCGGATTGTGCAAGAAGTTGGACGTTGACCAAACGAGTTTCTTA CCAACCATGAATGGCGGGATGGGTGCTGGGACGGTCGGGTGGAGAGCACCGGAGATTTTACGTGGCGAGGTCAAG CTTGATGATTTGAGCGATGATCACTCCATGAGTTCGAGAGGAAGTGTGTCAACCATTAACGGGTCATCATCGTCG TCGTCGACGTCGGGTCTCTCAACCGCGAAGCCAACACGACTCACCAAGTCTGTGGATATCTTCGCCCTTGGTTGC CTGTACTACTACACCTTGACCAACGGCAGCCATCCTTACGGGGATCGATTCGAGCGGGAAGTCAACATCTTGAAG GACGCCAAGTCGCTGGATTTACTGGAGAGATTTGGAGAGGAAGGAACCGAAGCGTGCGATTTGATCGAGAAGATG TTGGATCCCGAGGCATCTGAAAGACCGGATACGACTGCGTGCCTATTGCACCCCTTCTTCTGGGATCCCGCACGC CGCCTTAACTTCCTCCAAGACGCCTCGGACCGGTTCGAAATCATGTGTCGGGACCCCAAGGATCCTCTCCTACTG CAACTCGAAACCGGTGCGCTGGCCATCGTTGGAAATGACTGGCATGCAAGACTGGACAGGTTGTTTGTTGAGAAC CTTGGCAAGTTTAGAAAGTATGACGGAAAGTCTGTACAAGATTTGCTTCGTGCTCTTCGTAACAAGAAACACCAT TATCAAGACTTGCCTGACAATGTTAAGCGAAGTCTTGGGCCGATGCCAGAGGGCTTCCTGGCCTACTTCACGAAA CGTTTCCCCCGCCTCTTCTTACATGTCCATCGTGTCATCTCCGACACTGTACTACGGACAGAGTCTATGTTTAGA TCTTACTTTGAACTGCCTGACTCCTGA |
| Length | 3477 |
Gene
| Sequence id | CC1G_06931T0 |
|---|---|
| Sequence |
>CC1G_06931T0 ATGGCGTTCGTATTCTTCCTACAGTTCTTGCTCCTCATCGTGGGCGCGGTCTGCTGGGCAGAGATCGTCAATGTC CGGTCAACCATCCCAGCAGCGGAGACGGCGGCGCTCATACAACGAACGAGACCAGCACCTACTTATGCGACCGGA GGGATTCTAGAACCCACCAAAGACCTAGAGCTGCTGGACATTGTCCTGGTAGCCTCGATCGACGGCAAATTCCAT GCACTCAGTCGCTCGACGGGCAAGATCTTGTGGTCTATGCCTGCATTCGCACGGGCAGAAGGCTCGTCAACTCTT TCAAGCTTGGCGCCTCTGGTTAGGACGACACACCCAGAAAACGACCCCGACGACTTTGACGACGATACAACACCA GAAACCTATATCATTGAACCGCAGTCTGGCCACATCTATGTCGTAAACTCAGAAGACGACTCGTTGCAACGGTTC CCGTTCTCAATGGCGGAGTTGGTTGACATGTCGCCGTTCACCTCCCCAGGTGACGACGAGAAGAGGGTATTCATT GGGCGCAAGGAGACTTCACTATTGTTACTGGAGCTCGAAACAGGAAGAATCAAGGCGACCCTCAACTCCGAATGT CCGCCTTATGACGACAGGCGTATTGACCTCGACGAGCTGGAAGAACCAGAGTCGCGGGGCTCATCGACCACCGAA GTATTCATTGGGCGAACAGGTGCGGTGTTGACAGATTTGCGACCTGGAATTCAGCGCTGATGGCTAATTTCCCTA CTTGGCAGATTATTACATTTCCATCTATCCCCACCGCTCTAAGGGCTACGGCACTCGGGCGCCCGTCCAAAACCT GTCATTCTCAGTCTACGGACCCAACAACGAAGACAACTTGCTCCAAGCAAACTATCGAAGGACTAGCGACGATGC GTACATCCAAGGTTTTCCCAACGGGGATGTCTACTCCTTTAAGACCAAGTCGGAAGGGGGTAGAGTCCAAACACA ACCTTTATGGGTTCAGAAATTCCATGCACCGACGTGAGTTTGACGTTAAGAGTACCCTCGTTACATACTCAACAG CTTGCAGGGTCGCTGTTTTTGATGTCCTACGGGGCTCAACTCCACTTCAGCCACATCCTCACGCCTTTGTTCTCC TGCAACCACGACCACGCGCGGAAGATGTCATCCCAGGTCTCGACCGCTCTCTCTTACGTGGTGCAAAGTCGGCCT ACGTTGGGATGGTGGAGGAAACGGGGAGCCTTTACGCTATGAGCCCTTCACATTATCCACTGGTTGCGTTTGGGG ACGCAGAGGAGGGCAGAAAGGGACGACTTATTGAGGGTTCTGGGGGTTCAGCGCAAAGCATCCATGATATCATCC GCAACCAGAAGGAGGCTGACAGGCGGATTAGATGCGAGGATAACCCGAGAGACCGCGAGTGTCTACTGGGTATGC ATCCGCTTGACGAAACGGACGGCCATGAAAGTCGAATGCGACGACTGCTCGAAGGACCTTCAAGCATCAGCCCCA TCCCGACGTTCAGACCCGGTCAGAACCAATGGATCGATCACGGAATCGAAGTCGTCCCCAACATTGAAGCTCCAC CCAACAATTCTCAACAACCTGCCACGCCTGTCCCCCCGGAGGAAGTACGGAAGACGGGATGGGAATATCTGGGAG TAACACTCGGGCTGGGTTTGGTGTCTTTGTGGTTCTTATTCAAGAAGTTCGGCCAGCGAGAGGGATTCAAGGTAC CCAAATTCATTCCCGTACCCAACGGGGACGCGCAGATCGCCCGTCCCCTTGCTCCCATACCGGACACTGCCACCG AGCCAGCACCAGCACCCGAACCAGCTACGGTCCAGCCTCTTCAGATCATCCCCGAACAGCCTGCACCACCGGCAC CCCTACCATTGCCTCTGCCTCCATTGGAGGACCCCACTACGGATGCACTTGCCGGAACTGGCGAAGAAGGTGATG ACACCGACCGTGAAGGCGATCCAGAGCCCGAGACAGTCGCAACCCCTGGAAGGAAGAAGCCGAGGAGAGGTAAAC GAGGAAAGAAGAAGAAGAAGGACGCCACGCCTATCCCTGGTGAAGAAGGTGTTGAGGGCAAGGCGCCTAATGGAC CCGATGGACCAGCTGCGAATGGCACACCAAACATCAATCCGCCAGACAACAACCCAGATGCCACTATCGCTCCTG CAGCCCCACAATCTCCTTCACTTGTCGTCTCATCTCCCATAATTCCTGCGGCCGCAGGTCCATCGTTAGTCGTGT CCGATACCATTCTCGGTGAGCACTGCCCTTCCTGTCACTGTCAATCAATTGAACTGACTTCTTCTTAGGCTTTGG CTCTCATGGAACTGTTGTCTTCCAAGGTTCTCTACAGGGTCGAGCAGTCGCAGTGAAGCGGCTCCTCAAAGACTT TGTTACTCTGGCTTCACGTGAAGTCAGCATCCTCCAAGAGAGTGACGACCACCCGAATGTTATCCGATATTACTA CCAAGAAGCCCACGCCAATTTCCTCTATATCGCTCTTGAACTCTGCCCCGCATCCCTAGCCGACATCATCGAAAC TCCTGACCGAGAAGCCTTCAGAGATATCGCCATTTCCTTCGACCCCAAGAGGGCGTTGAAGCAGATCACGAGCGG TCTCAAGCACCTCCATGCGCTCAAACTCGTCCACCGTGACATCAAGCCCCAGAATATTCTTATTACGACAAACAA GAGCACTGGACGTGGGCGACCGACATATCGTATGCTCATCTCTGACTTCGGATTGTGCAAGAAGTTGGACGTTGA CCAAACGAGTTTCTTACCAACCATGAATGGCGGGATGGGTGCTGGGACGGTCGGGTGGAGAGCACCGGAGATTTT ACGTGGCGAGGTCAAGCTTGATGATTTGAGCGATGATCACTCCATGAGTTCGAGAGGAAGTGTGTCAACCATTAA CGGGTCATCATCGTCGTCGTCGACGTCGGGTCTCTCAACCGCGAAGCCAACACGACTCACCAAGTCTGTGGATAT CTTCGCCCTTGGTTGCCTGTACTACTACACCTTGACCAACGGCAGCCATCCTTACGGGGATCGATTCGAGCGGGA AGTCAACATCTTGAAGGACGCCAAGTCGCTGGATTTACTGGAGAGATTTGGAGAGGAAGGAACCGAAGCGTGCGA TTTGATCGAGAAGATGTTGGATCCCGAGGCATCTGAAAGGTATGCCAGCTTTGATACTCTAATTGCCTATTTTCG GACGGAACGCCTAACCCTTGATCATCAGACCGGATACGACTGCGTGCCTATTGCACCCCTTCTTCTGGGATCCCG CACGCCGCCTTAACTTCCTCCAAGACGCCTCGGACCGGTTCGAAATCATGTGTCGGGACCCCAAGGATCCTCTCC TACTGCAACTCGAAACCGGTGCGCTGGCCATCGTTGGAAATGACTGGCATGCAAGACTGGACAGGTTGTTTGTTG AGAACCTTGGCAAGTTTAGAAAGTATGACGGAAAGTCTGTACAAGATTTGCTTCGTGCTCTTCGTAACAAGGTAT GCTGTTTCCGCCTTGATGCCTCCTCCAATGGATACTCACATCTCATTTGTAGAAACACCATTATCAAGACTTGCC TGACAATGTTAAGCGAAGTCTTGGGCCGATGCCAGAGGGCTTCCTGGCCTACTTCACGAAACGTTTCCCCCGCCT CTTCTTACATGTCCATCGTGTCATCTCCGACACTGTACTACGGACAGAGTCTATGTTTAGATCTTACTTTGAACT GCCTGACTCCTGA |
| Length | 3763 |