CC1G_07190
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_07190 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NRE4 | Functional description | AGC/PKC protein kinase |
| Location | Chr_8:1090927..1095048 | Strand | + |
| Gene length (nt) | 4122 | Transcript length (nt) | 3481 |
| CDS length (nt) | 3321 | Protein length (aa) | 1106 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN0106_pkcA |
| Aspergillus niger | pkcA |
| Schizosaccharomyces pombe | pck2 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7261465 | 74.1 | 0 | 1672 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB17927 | 71.3 | 0 | 1613 |
| Lentinula edodes NBRC 111202 | Lenedo1_1126815 | 71 | 0 | 1602 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_14587 | 71 | 0 | 1602 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_152055 | 68.6 | 0 | 1565 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_100325 | 69.2 | 0 | 1565 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1423704 | 69.2 | 0 | 1559 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1106275 | 68.2 | 0 | 1554 |
| Flammulina velutipes | Flave_chr05AA00510 | 69 | 0 | 1553 |
| Pleurotus ostreatus PC9 | PleosPC9_1_63445 | 68.5 | 0 | 1547 |
| Schizophyllum commune H4-8 | Schco3_2614950 | 69 | 0 | 1530 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_107336 | 65.6 | 0 | 1512 |
| Auricularia subglabra | Aurde3_1_1323188 | 62.6 | 0 | 1412 |
| Lentinula edodes B17 | Lened_B_1_1_17104 | 88.8 | 2.434E-217 | 704 |
| Grifola frondosa | Grifr_OBZ69016 | 45.5 | 5.193E-160 | 535 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 6198 |
| Description | AGC/PKC protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd11620 | HR1_PKC-like_2_fungi | IPR037312 | 109 | 180 |
| CDD | cd20822 | C1_ScPKC1-like_rpt1 | - | 425 | 477 |
| CDD | cd20823 | C1_ScPKC1-like_rpt2 | - | 489 | 547 |
| CDD | cd05570 | STKc_PKC | - | 783 | 1100 |
| Pfam | PF02185 | Hr1 repeat | IPR011072 | 119 | 180 |
| Pfam | PF00130 | Phorbol esters/diacylglycerol binding domain (C1 domain) | IPR002219 | 427 | 476 |
| Pfam | PF00130 | Phorbol esters/diacylglycerol binding domain (C1 domain) | IPR002219 | 493 | 544 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 781 | 1038 |
| Pfam | PF00433 | Protein kinase C terminal domain | IPR017892 | 1061 | 1098 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR046349 | C1-like domain superfamily |
| IPR036274 | HR1 repeat superfamily |
| IPR002219 | Protein kinase C-like, phorbol ester/diacylglycerol-binding domain |
| IPR000008 | C2 domain |
| IPR000719 | Protein kinase domain |
| IPR017892 | Protein kinase, C-terminal |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000961 | AGC-kinase, C-terminal |
| IPR011072 | HR1 rho-binding domain |
| IPR035892 | C2 domain superfamily |
| IPR017441 | Protein kinase, ATP binding site |
| IPR037312 | Protein kinase C-like, HR1 domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004674 | protein serine/threonine kinase activity | MF |
| GO:0007165 | signal transduction | BP |
| GO:0004697 | protein kinase C activity | MF |
| GO:0009272 | fungal-type cell wall biogenesis | BP |
KEGG
| KEGG Orthology |
|---|
| K02677 |
| K18050 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein kinase c |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
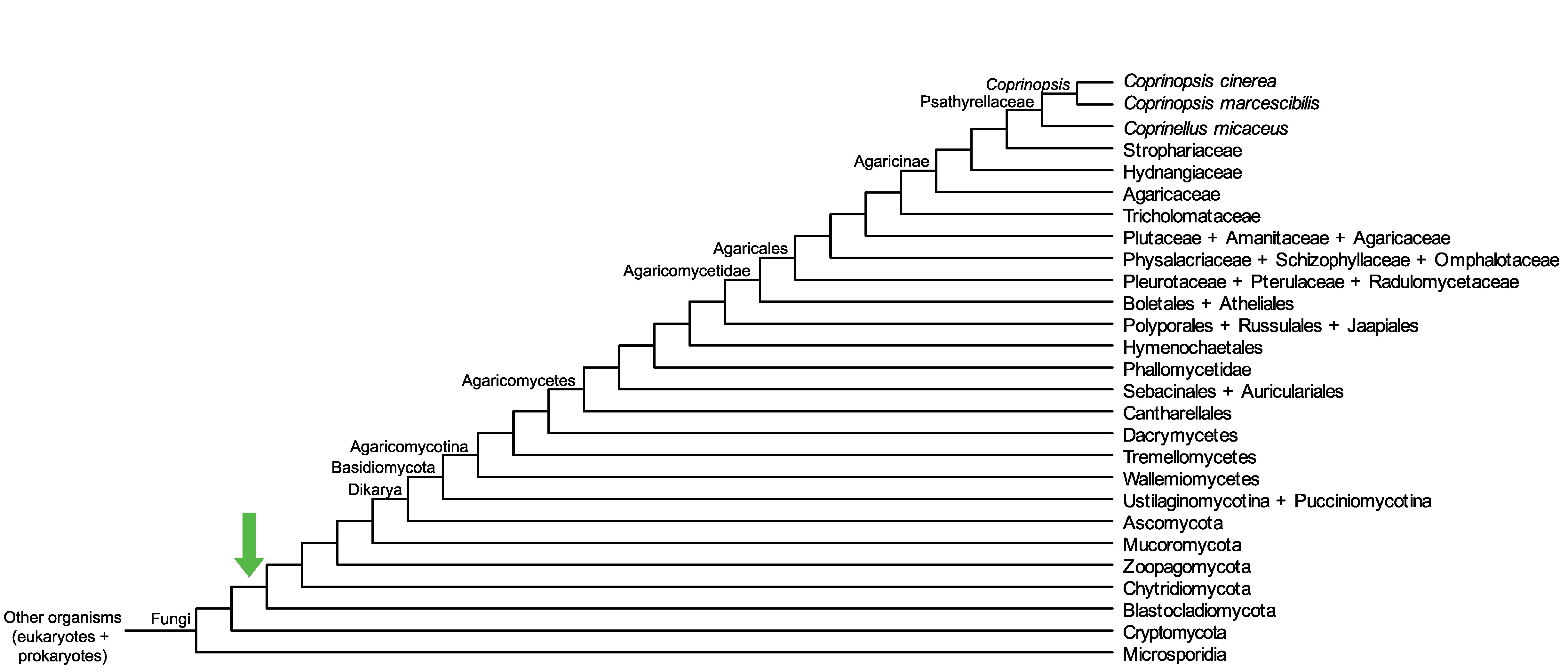
Conservation of CC1G_07190 across fungi.
Arrow shows the origin of gene family containing CC1G_07190.
Protein
| Sequence id | 6198 |
|---|---|
| Sequence |
>6198 MSDFTERKILEATQHLRLATTNQDVLKRNDAKVRETERSLAYLEGVLRELQTRKAQQMQQGDPSRFPSGPTPQVP PKDFDGRGFSPDGTVARPQRKQYTNLDLIKADTPFTPRKISRTLHQLEFKLQVEKQYKLGIDKMAKLYQADGDKK SKADAEAKRIESDKKIQLLETALKRYRNLHVLDDVAEDDEQDTGTEGDRREKLRAKPLSGTLYVTVKGARELDHA PVVTRFRSSAKQVTETHVSIKAEGNQLARSHPSRTDRWNEDFEIAVEKANEIEIVLYDKQVSEPHAVPIGLLWIK ITDLVDALRRQKIGQESQGGWVTANAMHGDGPMGPGGIHHHPSQPITGDINAPIAFQDNLSASGHGASHTEGIEA WFSVEPAGAIALQLNFVKENVRKRPFDAPLGGLGRQGAVRKRKGDVHEMNGHKFIQRQFYQLMKCAFCGDFLLNA AGYQCEDCRYTCHQKCYEKVVTKCISKSSTGEDEDKINHRIPHRFESITNIGANWCCHCGYMLPFGRKNARRCTE CDITCHANCAHLVPDFCGMRMEVANELLRSMQDIKRRREDREQRRPPTHQPEQLHTSTPSLDARLGQMTLGGPPQ HEPGPPAQLPSSDPFGRQMPMPAPQTYGPPPDRSYYSQSPPPPAQSPPYGSPPTQQMPPRPPGARVPVPYQQEHQ APPRPPPGAYDPSASGYGSPYTSPRSQPQGLPEKPSLPSVPQQQQYQQQRPPVGLPPHVQPQRIPPPQAAPQQGM VPPQHQQQMIQAQPQRQPSKKRKVGLDDFNFLAVLGKGNFGKVMLAEEKKTNGLYAIKVLKKEFIIDNDEVESTR SEKRVFLTAAKERHPFLLGLHSCFQTETRIYFVMEYVSGGDLMLHIQRKQFSLRQAKFYASEVLLALEYFHQNGI IYRDLKLDNILLTLDGHVKVADYGLCKEQMWYGQTTSTFCGTPEFMAPEILLEQRYGRAVDWWAFGVLTYEMLLG QSPFRGDDEDEIFDAILEDEPLYPITMPRDAVSILQKLLTRDPARRLGSGKEDAEEIKRQPFFKDVNWDDVFHKR IPPPYFPTISGSADTSNFDEEFTREQPTLTPVHGQLSSRDQAEFNGFSWVASWADI |
| Length | 1106 |
Coding
| Sequence id | CC1G_07190T0 |
|---|---|
| Sequence |
>CC1G_07190T0 ATGTCTGATTTCACAGAGCGCAAGATTCTTGAGGCGACCCAGCATCTGCGGCTGGCGACGACGAACCAAGATGTC CTCAAGCGCAACGATGCAAAGGTCAGAGAGACAGAGCGCAGTCTCGCCTATCTAGAGGGCGTCCTTCGCGAGCTG CAGACCCGGAAAGCACAGCAAATGCAACAAGGTGATCCTTCACGATTTCCCTCTGGGCCTACGCCTCAAGTACCA CCAAAGGATTTCGATGGGCGCGGCTTTTCCCCCGACGGCACCGTCGCTCGACCCCAGAGGAAGCAATATACCAAC CTCGATCTCATCAAGGCTGATACCCCGTTCACACCCAGGAAAATCTCGCGTACTCTCCACCAGTTAGAATTCAAG CTCCAGGTCGAAAAACAATACAAACTCGGCATAGATAAGATGGCAAAATTGTACCAAGCTGACGGCGACAAGAAA TCGAAAGCGGACGCAGAGGCCAAGCGGATCGAGAGCGACAAGAAGATTCAGCTCCTCGAAACCGCATTGAAGCGT TATCGAAACCTTCATGTACTCGACGATGTAGCCGAAGACGATGAGCAAGACACTGGGACCGAAGGCGACCGTCGA GAGAAATTGCGCGCGAAACCTCTCTCTGGTACCCTCTATGTCACCGTCAAGGGAGCTCGCGAGCTCGACCATGCC CCGGTTGTCACGCGCTTCCGTTCATCAGCGAAGCAGGTCACCGAAACACATGTCTCTATCAAGGCCGAAGGCAAT CAATTGGCTCGATCGCATCCCTCGCGGACGGACCGCTGGAATGAAGATTTCGAGATCGCCGTCGAAAAAGCCAAC GAAATCGAAATCGTCCTTTACGACAAGCAAGTCAGCGAGCCACATGCAGTCCCCATTGGCCTGCTATGGATCAAG ATCACTGACCTTGTTGACGCCCTTCGTCGGCAGAAGATTGGTCAGGAAAGTCAAGGAGGATGGGTGACAGCTAAT GCGATGCACGGGGATGGTCCAATGGGACCCGGCGGGATCCACCACCACCCAAGCCAGCCCATTACTGGCGACATT AACGCACCTATCGCATTCCAAGACAACCTTTCTGCTTCCGGTCATGGGGCTAGTCATACCGAAGGAATCGAGGCA TGGTTTTCGGTCGAGCCAGCTGGTGCAATTGCCCTTCAACTCAACTTCGTTAAGGAAAATGTCCGCAAGCGTCCT TTCGATGCGCCGCTTGGTGGCCTTGGGCGCCAAGGCGCCGTCCGCAAGCGCAAGGGCGATGTACACGAAATGAAT GGCCACAAGTTCATCCAACGCCAATTCTACCAGCTGATGAAATGCGCATTCTGCGGCGACTTCCTTCTCAATGCC GCCGGTTACCAATGCGAGGATTGTCGGTACACTTGTCACCAAAAATGCTATGAGAAAGTGGTCACCAAATGTATA TCCAAGTCAAGCACAGGGGAGGACGAGGATAAGATCAATCATCGTATTCCTCACCGATTCGAATCAATCACCAAT ATCGGTGCCAACTGGTGTTGCCATTGTGGCTACATGCTTCCCTTTGGCCGCAAGAATGCCCGCCGTTGCACAGAA TGCGACATCACTTGCCACGCCAATTGCGCACATTTGGTTCCCGATTTCTGCGGTATGAGGATGGAGGTTGCGAAC GAACTCCTCCGAAGTATGCAGGATATCAAGCGAAGACGCGAAGATCGCGAGCAACGACGCCCTCCCACTCACCAG CCCGAGCAGCTCCATACTTCGACGCCTTCCCTCGATGCCAGGTTGGGCCAGATGACTCTAGGAGGGCCACCCCAG CACGAACCGGGTCCCCCGGCACAGTTGCCTTCCAGTGATCCATTTGGACGACAAATGCCAATGCCCGCTCCTCAG ACCTACGGGCCACCTCCGGATAGATCTTACTATTCCCAATCGCCACCTCCGCCTGCTCAATCTCCCCCTTATGGA TCACCTCCTACCCAACAGATGCCGCCTCGCCCTCCAGGGGCCCGAGTACCAGTCCCTTATCAGCAGGAGCATCAA GCACCACCTCGACCTCCGCCTGGAGCGTACGACCCAAGTGCCTCTGGATATGGCTCTCCCTATACGAGCCCTCGA TCTCAGCCACAAGGGCTCCCCGAGAAACCTTCATTACCTTCCGTTCCTCAGCAGCAACAGTACCAGCAACAGCGA CCCCCCGTTGGACTGCCTCCTCATGTCCAGCCTCAACGCATCCCTCCGCCTCAAGCTGCCCCCCAGCAAGGCATG GTCCCGCCCCAACACCAACAACAGATGATACAGGCTCAGCCGCAGCGTCAACCCTCGAAGAAGCGGAAGGTCGGA TTGGACGATTTCAACTTCCTTGCAGTCCTTGGAAAGGGTAATTTCGGAAAGGTCATGTTGGCGGAGGAAAAAAAG ACGAATGGACTATATGCGATCAAGGTTTTGAAGAAGGAGTTTATCATCGACAACGATGAAGTTGAGAGCACGCGT TCCGAAAAGCGCGTTTTCTTGACCGCTGCAAAGGAGCGCCATCCCTTCCTTTTGGGTCTTCACTCGTGCTTCCAG ACTGAAACTCGGATATACTTTGTGATGGAATATGTCAGTGGTGGTGACTTGATGCTGCACATTCAGCGGAAGCAG TTCTCGCTGCGTCAGGCCAAGTTCTACGCATCGGAGGTCCTGTTGGCTTTGGAGTACTTCCACCAAAACGGCATC ATCTATCGTGATCTCAAGCTCGACAATATCCTGCTTACTCTCGACGGACATGTCAAGGTTGCCGATTACGGTCTC TGCAAGGAACAGATGTGGTATGGTCAGACGACGAGCACTTTCTGTGGCACTCCAGAGTTCATGGCGCCCGAAATT TTGCTTGAGCAACGATACGGTCGAGCTGTCGACTGGTGGGCGTTTGGTGTATTGACCTATGAAATGTTGTTGGGT CAATCACCCTTCCGAGGAGACGACGAAGATGAAATCTTCGACGCAATCCTGGAAGACGAGCCATTGTATCCCATT ACCATGCCTCGTGACGCTGTGTCGATATTGCAAAAGCTGTTGACGAGGGACCCTGCTCGTCGTCTCGGATCAGGA AAGGAGGACGCCGAAGAAATCAAAAGACAGCCTTTCTTCAAGGATGTCAACTGGGATGATGTGTTCCACAAGCGT ATTCCTCCACCCTACTTCCCGACAATCAGCGGAAGCGCCGATACCAGCAACTTCGACGAAGAGTTCACACGCGAA CAGCCAACATTAACCCCAGTGCACGGTCAACTCTCTTCGCGAGACCAAGCCGAATTCAACGGTTTCTCTTGGGTT GCGAGTTGGGCGGATATC |
| Length | 3321 |
Transcript
| Sequence id | CC1G_07190T0 |
|---|---|
| Sequence |
>CC1G_07190T0 ATGTCTGATTTCACAGAGCGCAAGATTCTTGAGGCGACCCAGCATCTGCGGCTGGCGACGACGAACCAAGATGTC CTCAAGCGCAACGATGCAAAGGTCAGAGAGACAGAGCGCAGTCTCGCCTATCTAGAGGGCGTCCTTCGCGAGCTG CAGACCCGGAAAGCACAGCAAATGCAACAAGGTGATCCTTCACGATTTCCCTCTGGGCCTACGCCTCAAGTACCA CCAAAGGATTTCGATGGGCGCGGCTTTTCCCCCGACGGCACCGTCGCTCGACCCCAGAGGAAGCAATATACCAAC CTCGATCTCATCAAGGCTGATACCCCGTTCACACCCAGGAAAATCTCGCGTACTCTCCACCAGTTAGAATTCAAG CTCCAGGTCGAAAAACAATACAAACTCGGCATAGATAAGATGGCAAAATTGTACCAAGCTGACGGCGACAAGAAA TCGAAAGCGGACGCAGAGGCCAAGCGGATCGAGAGCGACAAGAAGATTCAGCTCCTCGAAACCGCATTGAAGCGT TATCGAAACCTTCATGTACTCGACGATGTAGCCGAAGACGATGAGCAAGACACTGGGACCGAAGGCGACCGTCGA GAGAAATTGCGCGCGAAACCTCTCTCTGGTACCCTCTATGTCACCGTCAAGGGAGCTCGCGAGCTCGACCATGCC CCGGTTGTCACGCGCTTCCGTTCATCAGCGAAGCAGGTCACCGAAACACATGTCTCTATCAAGGCCGAAGGCAAT CAATTGGCTCGATCGCATCCCTCGCGGACGGACCGCTGGAATGAAGATTTCGAGATCGCCGTCGAAAAAGCCAAC GAAATCGAAATCGTCCTTTACGACAAGCAAGTCAGCGAGCCACATGCAGTCCCCATTGGCCTGCTATGGATCAAG ATCACTGACCTTGTTGACGCCCTTCGTCGGCAGAAGATTGGTCAGGAAAGTCAAGGAGGATGGGTGACAGCTAAT GCGATGCACGGGGATGGTCCAATGGGACCCGGCGGGATCCACCACCACCCAAGCCAGCCCATTACTGGCGACATT AACGCACCTATCGCATTCCAAGACAACCTTTCTGCTTCCGGTCATGGGGCTAGTCATACCGAAGGAATCGAGGCA TGGTTTTCGGTCGAGCCAGCTGGTGCAATTGCCCTTCAACTCAACTTCGTTAAGGAAAATGTCCGCAAGCGTCCT TTCGATGCGCCGCTTGGTGGCCTTGGGCGCCAAGGCGCCGTCCGCAAGCGCAAGGGCGATGTACACGAAATGAAT GGCCACAAGTTCATCCAACGCCAATTCTACCAGCTGATGAAATGCGCATTCTGCGGCGACTTCCTTCTCAATGCC GCCGGTTACCAATGCGAGGATTGTCGGTACACTTGTCACCAAAAATGCTATGAGAAAGTGGTCACCAAATGTATA TCCAAGTCAAGCACAGGGGAGGACGAGGATAAGATCAATCATCGTATTCCTCACCGATTCGAATCAATCACCAAT ATCGGTGCCAACTGGTGTTGCCATTGTGGCTACATGCTTCCCTTTGGCCGCAAGAATGCCCGCCGTTGCACAGAA TGCGACATCACTTGCCACGCCAATTGCGCACATTTGGTTCCCGATTTCTGCGGTATGAGGATGGAGGTTGCGAAC GAACTCCTCCGAAGTATGCAGGATATCAAGCGAAGACGCGAAGATCGCGAGCAACGACGCCCTCCCACTCACCAG CCCGAGCAGCTCCATACTTCGACGCCTTCCCTCGATGCCAGGTTGGGCCAGATGACTCTAGGAGGGCCACCCCAG CACGAACCGGGTCCCCCGGCACAGTTGCCTTCCAGTGATCCATTTGGACGACAAATGCCAATGCCCGCTCCTCAG ACCTACGGGCCACCTCCGGATAGATCTTACTATTCCCAATCGCCACCTCCGCCTGCTCAATCTCCCCCTTATGGA TCACCTCCTACCCAACAGATGCCGCCTCGCCCTCCAGGGGCCCGAGTACCAGTCCCTTATCAGCAGGAGCATCAA GCACCACCTCGACCTCCGCCTGGAGCGTACGACCCAAGTGCCTCTGGATATGGCTCTCCCTATACGAGCCCTCGA TCTCAGCCACAAGGGCTCCCCGAGAAACCTTCATTACCTTCCGTTCCTCAGCAGCAACAGTACCAGCAACAGCGA CCCCCCGTTGGACTGCCTCCTCATGTCCAGCCTCAACGCATCCCTCCGCCTCAAGCTGCCCCCCAGCAAGGCATG GTCCCGCCCCAACACCAACAACAGATGATACAGGCTCAGCCGCAGCGTCAACCCTCGAAGAAGCGGAAGGTCGGA TTGGACGATTTCAACTTCCTTGCAGTCCTTGGAAAGGGTAATTTCGGAAAGGTCATGTTGGCGGAGGAAAAAAAG ACGAATGGACTATATGCGATCAAGGTTTTGAAGAAGGAGTTTATCATCGACAACGATGAAGTTGAGAGCACGCGT TCCGAAAAGCGCGTTTTCTTGACCGCTGCAAAGGAGCGCCATCCCTTCCTTTTGGGTCTTCACTCGTGCTTCCAG ACTGAAACTCGGATATACTTTGTGATGGAATATGTCAGTGGTGGTGACTTGATGCTGCACATTCAGCGGAAGCAG TTCTCGCTGCGTCAGGCCAAGTTCTACGCATCGGAGGTCCTGTTGGCTTTGGAGTACTTCCACCAAAACGGCATC ATCTATCGTGATCTCAAGCTCGACAATATCCTGCTTACTCTCGACGGACATGTCAAGGTTGCCGATTACGGTCTC TGCAAGGAACAGATGTGGTATGGTCAGACGACGAGCACTTTCTGTGGCACTCCAGAGTTCATGGCGCCCGAAATT TTGCTTGAGCAACGATACGGTCGAGCTGTCGACTGGTGGGCGTTTGGTGTATTGACCTATGAAATGTTGTTGGGT CAATCACCCTTCCGAGGAGACGACGAAGATGAAATCTTCGACGCAATCCTGGAAGACGAGCCATTGTATCCCATT ACCATGCCTCGTGACGCTGTGTCGATATTGCAAAAGCTGTTGACGAGGGACCCTGCTCGTCGTCTCGGATCAGGA AAGGAGGACGCCGAAGAAATCAAAAGACAGCCTTTCTTCAAGGATGTCAACTGGGATGATGTGTTCCACAAGCGT ATTCCTCCACCCTACTTCCCGACAATCAGCGGAAGCGCCGATACCAGCAACTTCGACGAAGAGTTCACACGCGAA CAGCCAACATTAACCCCAGTGCACGGTCAACTCTCTTCGCGAGACCAAGCCGAATTCAACGGTTTCTCTTGGGTT GCGAGTTGGGCGGATATCTAATGAACGAATGGCAAGAATTACGGACAGGACAATTGTTTCGCATCTTTATATCGC CTACTTTTCTTTATGCAGTCTGTAGTAGTGTTTACCTCCTCCCCCGTTGTTGTGGATGTACCACCCTTTGCCCCA GAGGCATCTGATTTCTATTTATACCATTTCC |
| Length | 3481 |
Gene
| Sequence id | CC1G_07190T0 |
|---|---|
| Sequence |
>CC1G_07190T0 ATGTCTGATTTCGTCAGGATGAACTCGACCAGAAGATTGGGGACACTTGGCGGCGCATCCAGACAGAGCGCAAGA TTCTTGAGGCGACCCAGCATCTGCGGCTGGCGACGACGAACCAAGATGTCCTCAAGCGCAACGATGCAAAGGTCA GAGAGACAGAGCGCAGTCTCGCCTATCTAGAGGGCGTCCTTCGCGAGCTGCAGACCCGGAAAGCACAGCAAATGC AACAAGGTGATCCTTCACGATTTCCCTCTGGGCCTACGCCTCAAGTATGTATGCAACGCCAGATAGAAGCCTCTG TGTCCAATTGACTGCTTTTGTCCTTACAGGTACCACCAAAGGATTTCGATGGGCGCGGCTTTTCCCCCGACGGCA CCGTCGCTCGACCCCAGAGGAAGCAATATACCAACCTCGATCTCATCAAGGCTGATACCCCGTTCACACCCAGGA AAATCTCGCGTACTCTCCACCAGTTAGAATTCAAGCTCCAGGTCGAAAAACAATACAAACTCGGCATAGATAAGA TGGCAAAATTGTACCAAGCTGACGGCGACAAGAAATCGAAAGCGGACGCAGAGGCCAAGCGGATCGAGAGCGACA AGAAGATTCAGCTCCTCGAAACCGCATTGAAGCGTTATCGAAACCTTCATGTACTCGACGATGTAGCCGAAGACG ATGAGCAAGGTTCGGGTATAATTCATCGTTCACACCTCTCTAATTAAACCCCATCATATCAGACACTGGGACCGA AGGCGACCGTCGAGAGAAATTGCGCGCGAAACCTCTCTCTGGTACCCTCTATGTCACCGTCAAGGGAGCTCGCGA GCTCGACCATGCCCCGGTTGTCACGCGCTTCCGTTCATCAGCGAAGCAGGTCACCGAAACACATGTCTCTATCAA GGCCGAAGGCAATCAATTGGCTCGATCGCATCCCTCGCGGACGGACCGCTGGAATGAAGATTTCGAGATCGCCGT CGAAAAAGCCAACGAAATCGAAATCGTCCTTTACGACAAGCAAGTCAGCGAGCCACATGCAGTCCCCATTGGCCT GCTATGGATCAAGATCACTGACCTTGTTGACGCCCTTCGTCGGCAGAAGATTGGTCAGGAAAGTCAAGGAGGATG GGTGACAGCTAATGCGATGCACGGGGATGGTCCAATGGGACCCGGCGGGATCCACCACCACCCAAGCCAGCCCAT TACTGGCGACATTAACGCACCTATCGCATTCCAAGACAACCTTTCTGCTTCCGGTCATGGGGCTAGTCATACCGA AGGAATCGAGGCATGGTTTTCGGTCGAGCCAGCTGGTGCAATTGCCCTTCAACTCAACTTCGGTGAGTTCCTTCA CCATCGCCCTATCGCCCCCTTCCTAACAAAGGTTTAAGTTAAGGAAAATGTCCGCAAGCGTCCTTTCGATGCGCC GCTTGGTGGCCTTGGGCGCCAAGGCGCCGTCCGCAAGCGCAAGGGCGATGTACACGAAATGAATGGCCACAAGTT CATCCAACGCCAATTCTACCAGCTGATGAAATGCGCATTCTGCGGCGACTTCCTTCTCAATGCCGCCGGTTACCA ATGCGAGGATTGTCGGTACACTTGTCACCAAAAATGCTATGAGAAAGTGGTCACCAAATGTATATCCAAGTCAAG CACAGGGGTAGGTGTCTATCTATTATTATGAGACGAAACGGCTCATCATGTCTTCACCTGCAGGAGGACGAGGAT AAGATCAATCATCGTATTCCTCACCGATTCGAATCAATCACCAATATCGGTGCCAACTGGTGTTGCCATTGTGGC TACATGCTTCCCTTTGGCCGCAAGAATGCCCGCCGTTGCACAGAATGCGACATCACTTGCCACGCCAATTGCGCA CATTTGGTTCCCGATTTCTGCGGTATGAGGATGGAGGTTGCGAACGAACTCCTCCGAAGTATGCAGGATATCAAG CGAAGACGCGAAGATCGCGAGCAACGACGCCCTCCCACTCACCAGCCCGAGCAGCTCCATACTTCGACGCCTTCC CTCGATGCCAGGTTGGGCCAGATGACTCTAGGAGGGCCACCCCAGCACGAACCGGGTCCCCCGGCACAGTTGCCT TCCAGTGATCCATTTGGACGACAAATGCCAATGCCCGCTCCTCAGACCTACGGGCCACCTCCGGATAGATCTTAC TATTCCCAATCGCCACCTCCGCCTGCTCAATCTCCCCCTTATGGATCACCTCCTACCCAACAGATGCCGCCTCGC CCTCCAGGGGCCCGAGTACCAGTCCCTTATCAGCAGGAGCATCAAGCACCACCTCGACCTCCGCCTGGAGCGTAC GACCCAAGTGCCTCTGGATATGGCTCTCCCTATACGGTAAGTTGCGTTGCTTTGGAAATCAACAGAGGCTCATGG CGGATAGCAGAGCCCTCGATCTCAGCCACAAGGGCTCCCCGAGAAACCTTCATTACCTTCCGTTCCTCAGCAGCA ACAGTACCAGCAACAGCGACCCCCCGTTGGACTGCCTCCTCATGTCCAGCCTCAACGCATCCCTCCGCCTCAAGC TGCCCCCCAGCAAGGCATGGTCCCGCCCCAACACCAACAACAGATGATACAGGCTCAGCCGCAGCGTCAACCCTC GAAGAAGCGGAAGGTCGGATTGGACGATTTCAACTTCCTTGCAGTCCTTGGAAAGGGTAATTTCGGAAAGGTCAT GTTGGCGGAGGAAAAAAAGACGAATGGACTATATGCGATCAAGGTTTTGAAGAAGGAGTTTATCATCGACAACGA TGAAGTTGAGAGGTGAATGGTAACTGACTTTGTCGCCGGACGTCTGCTCACTGCTCGATATCTAGCACGCGTTCC GAAAAGCGCGTTTTCTTGACCGCTGCAAAGGAGCGCCATCCCTTCCTTTTGGGTCTTCACTCGTGCTTCCAGACT GAAACTCGGATATACTTTGTGATGGAATATGTCAGTGGTGGTGACTTGATGCTGCACATTCAGCGGAAGCAGTTC TCGCTGCGTCAGGCCAAGTTCTACGCATCGGAGGTCCTGTTGGCTTTGGAGTACTTCCACCAAAACGGCATCATC TATCGGTGTGTTTCTTCCTTCATTTGGCATGACTTGTTGCTAAATCCCGAGCTAGTGATCTCAAGCTCGACAATA TCCTGCTTACTCTCGACGGACATGTCAAGGTTGCCGATTACGGTCTCTGCAAGGAACAGATGTGGTATGGTCAGA CGACGAGCACTTTCTGTGGCACTCCAGAGTTCATGGCGCCCGAAGTGGGTCACAATTGTTGCTGTCGAGAGGTCC CTTTCTAATCGCTTCCTAGATTTTGCTTGAGCAACGATACGGTCGAGCTGTCGACTGGTGGGCGTTTGGTGTATT GACCTATGAAATGTTGTTGGGTCAATCACCCTTCCGAGGAGACGACGAAGATGAAATCTTCGACGCAATCCTGGA AGACGAGCCATTGTATCCCATTACCATGCCTCGTGACGCTGTGTCGATATTGCAAAAGGTTCGTTTTCTCTCATT TGAACATTTCTTTTTATTTTCGCTTACGCCGTAAAACAGCTGTTGACGAGGGACCCTGCTCGTCGTCTCGGATCA GGAAAGGAGGACGCCGAAGAAATCAAAAGACAGCCTTTCTTCAAGGATGTCAACTGGGATGATGTGTTCCACAAG CGTATTCCTCCACCCTACTTCCCGACAATCGTGAGTCGCCTTTGGTTCGACTGTGCTACATCCATTGCTGATGAT CCTTCTTGCAGAGCGGAAGCGCCGATACCAGCAACTTCGACGAAGAGTTCACACGCGAACAGCCAACATTAACCC CAGTGCACGGTCAACTCTCTTCGCGAGACCAAGCCGAATTCAACGGTTTCTCTTGGGTGAGTTCGTTTATCCGTA TCTTGATTAATCCCTTAACCTTTGATCTATCTCGTCAGGTTGCGAGTTGGGCGGATATCTAATGAACGAATGGCA AGAATTACGGACAGGACAATTGTTTCGCATCTTTATATCGCCTACTTTTCTTTATGCAGTCTGTAGTAGTGTTTA CCTCCTCCCCCGTTGTTGTGGATGTACCACCCTTTGCCCCAGAGGCATCTGATTTCTATTTATACCATTTCC |
| Length | 4122 |