CC1G_08008
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_08008 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NQ88 | Functional description | Exo-beta-1,3-glucanase |
| Location | Chr_8:386366..389967 | Strand | + |
| Gene length (nt) | 3602 | Transcript length (nt) | 2410 |
| CDS length (nt) | 2199 | Protein length (aa) | 732 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7262821 | 72.1 | 1.218E-304 | 974 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_114151 | 70.4 | 6.298E-291 | 934 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_14671 | 69.1 | 1.964E-291 | 930 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB14918 | 66.5 | 3.616E-291 | 915 |
| Lentinula edodes NBRC 111202 | Lenedo1_1000518 | 70.1 | 1.047E-283 | 873 |
| Pleurotus ostreatus PC9 | PleosPC9_1_87373 | 68.1 | 1.457E-268 | 829 |
| Pleurotus ostreatus PC15 | PleosPC15_2_45975 | 67.9 | 7.319E-268 | 827 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_72051 | 67.8 | 1.402E-267 | 826 |
| Flammulina velutipes | Flave_chr10AA00936 | 59.4 | 6.34E-252 | 781 |
| Schizophyllum commune H4-8 | Schco3_81800 | 62.9 | 7.794E-252 | 781 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1568598 | 64.3 | 1.534E-251 | 780 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 6892 |
| Description | Exo-beta-1,3-glucanase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 239 | 317 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 80 | 102 | 22 |
| 2 | 343 | 365 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR001547 | Glycoside hydrolase, family 5 |
| IPR017853 | Glycoside hydrolase superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| S | Cellulase (glycosyl hydrolase family 5) |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_9 |
Transcription factor
| Group |
|---|
| No records |
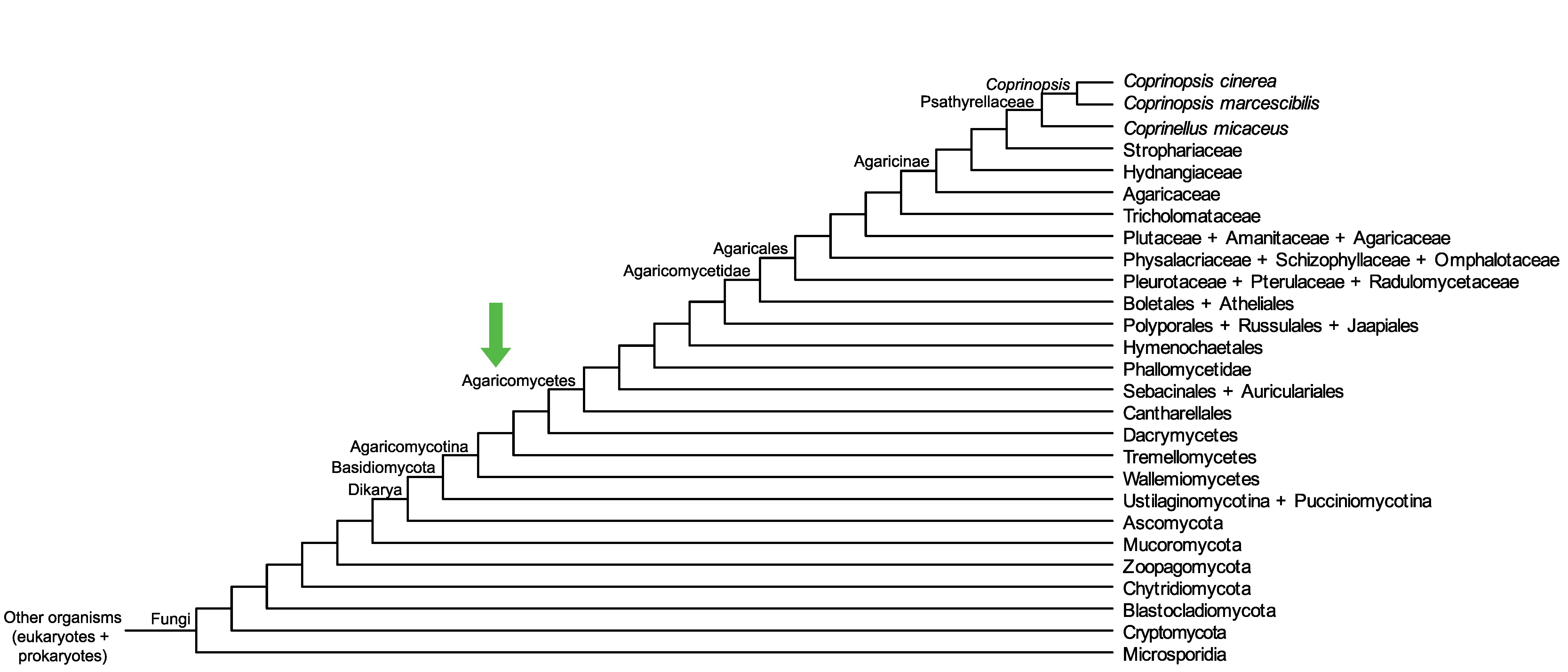
Conservation of CC1G_08008 across fungi.
Arrow shows the origin of gene family containing CC1G_08008.
Protein
| Sequence id | 6892 |
|---|---|
| Sequence |
>6892 MPGVYKSVTSSDEFELVKPRGSRETVHEPEEVIDMYAAADGSPHHVPYSFSPPDSGDRALPEESTTSMGPGKPMK KGVKISIAVAVLIAVITIAIAVPLAVTVGKSKNGTSSSGGGAGGGSSGGGSATSGKSGSLVTMEDGSTFTYVNEF GGDWAADPARPFGSGGKAQEWSPRVGVEEWKWGEHVIRGVNLGGWLVTEPFICPELYERFIENDENVTVVDEWTL SLAMGDRLPEEMENHYKTFITEQDFAEIAAAGLNWIRVPIGYWAIETMGEEPFLVGTSWTYFLKAIQWARKYGLR IYLDLHALPGSQNGWNHSGKGLLASTPPFVENRLTNAVLTVKLALLICEIIVTSVPLVLNLVLIAKFFSSMHGTM GIANAQRTLTYLRIFTQFVSQPQYKDVVPIVGIVNEILWDTIGEEAVQSFYYAAYEAMRGASGIGEGNGPYIAIH EGFQGPAIWEGFLLGSDRVVLDQHPYLAFMGDPNSTPESSAPRPCEWAIATNQSQQVFGVTVGGEFSTAINNCGL WLNGVDGAPIPGCELWDDWNSWNSTIISGLKQVTLASMDALQHFFFWTWKIGNSTRLGTSSSPMWHYKLGLERGW IPKDPREAIGHCAEVLGTSQLFDGRYPSTATGGAAAGTLDPTRASAHPFPPATISPSFSGDLLSLLPTYTPTGTL QTLFAPTFTAAPSAVVGTGWNNPDDNSPAYVPVAGCSYPDAWDAVDVPLSEPFCTGS |
| Length | 732 |
Coding
| Sequence id | CC1G_08008T0 |
|---|---|
| Sequence |
>CC1G_08008T0 ATGCCTGGCGTATACAAGAGCGTCACCTCAAGCGATGAATTCGAATTGGTCAAACCACGAGGCAGCAGGGAGACG GTGCACGAGCCAGAAGAAGTGATAGACATGTACGCCGCCGCCGATGGAAGCCCGCACCACGTTCCCTACTCTTTC TCGCCACCAGACAGCGGTGACCGTGCCCTCCCTGAAGAGTCGACGACGAGTATGGGTCCAGGCAAACCGATGAAA AAAGGCGTCAAGATCAGTATCGCGGTGGCCGTTCTTATTGCTGTCATTACGATTGCGATAGCCGTCCCGTTGGCC GTCACGGTTGGGAAGAGCAAGAATGGCACGAGTTCGTCGGGGGGAGGGGCTGGGGGTGGCTCCAGTGGGGGTGGG TCGGCGACGTCTGGAAAGTCTGGGAGTCTCGTTACGATGGAGGACGGTTCGACGTTCACGTATGTGAACGAGTTT GGGGGCGACTGGGCTGCTGACCCTGCGCGTCCCTTTGGTTCGGGTGGAAAGGCCCAGGAGTGGTCGCCACGCGTC GGTGTGGAAGAATGGAAATGGGGAGAACATGTTATTCGTGGCGTCAACCTGGGAGGGTGGTTAGTCACCGAACCG TTCATCTGCCCCGAGTTATATGAGAGATTTATCGAGAATGATGAAAATGTGACCGTGGTCGACGAGTGGACCCTT TCGCTAGCTATGGGCGACCGCCTTCCAGAAGAGATGGAAAACCATTACAAGACCTTCATCACTGAACAAGACTTT GCAGAAATTGCAGCCGCCGGACTGAACTGGATAAGAGTTCCCATCGGTTATTGGGCAATTGAGACGATGGGCGAG GAGCCTTTCCTCGTAGGTACATCGTGGACCTATTTCCTGAAGGCGATTCAATGGGCGAGAAAATACGGTCTTCGA ATTTACCTCGATCTCCATGCTCTCCCGGGAAGCCAAAATGGCTGGAACCATTCTGGAAAAGGTTTGCTTGCCTCT ACACCGCCATTCGTCGAAAATAGACTGACAAATGCCGTTCTCACTGTGAAGCTGGCACTGTTAATTTGTGAGATC ATTGTGACATCCGTTCCGTTGGTTCTGAATCTGGTGCTAATCGCGAAATTCTTTTCCAGTATGCACGGCACAATG GGAATCGCCAATGCTCAAAGAACACTTACGTATCTGCGAATTTTCACGCAATTTGTGAGCCAACCTCAGTACAAG GACGTTGTTCCGATTGTTGGTATAGTGAACGAAATTCTTTGGGATACTATTGGCGAGGAAGCGGTTCAGAGCTTC TATTACGCCGCCTATGAGGCCATGAGGGGTGCTTCAGGTATTGGTGAAGGAAATGGCCCCTATATTGCTATCCAT GAGGGCTTCCAAGGGCCTGCGATCTGGGAAGGATTCCTTTTAGGCTCGGATCGAGTAGTTCTTGACCAGCACCCG TACTTGGCGTTCATGGGTGATCCAAACAGCACCCCTGAATCTAGTGCTCCCAGACCCTGTGAATGGGCGATCGCC ACCAACCAGTCCCAGCAAGTTTTCGGCGTGACGGTTGGCGGAGAATTCTCGACTGCTATTAACAACTGTGGACTC TGGTTGAACGGCGTCGACGGAGCTCCTATTCCTGGATGCGAACTTTGGGATGATTGGAACTCGTGGAACTCGACG ATAATCTCGGGATTGAAACAAGTCACGCTGGCTTCTATGGATGCCTTGCAGCACTTTTTCTTCTGGACTTGGAAG ATAGGTAATTCTACGAGGCTTGGCACGTCCTCCTCGCCGATGTGGCACTATAAACTTGGTTTGGAAAGGGGCTGG ATCCCGAAAGATCCGAGGGAAGCTATTGGACACTGTGCTGAAGTTTTGGGCACGTCTCAATTATTCGATGGTCGA TACCCGTCGACTGCGACCGGAGGCGCTGCTGCTGGGACACTTGACCCTACCCGAGCTTCAGCGCACCCCTTCCCG CCAGCTACGATTTCACCCTCTTTCTCGGGTGATTTACTCTCTCTTCTGCCCACCTATACTCCGACAGGGACGCTG CAGACATTGTTTGCCCCTACATTCACCGCTGCTCCGTCTGCTGTGGTGGGCACCGGTTGGAATAATCCCGATGAT AATTCGCCCGCCTATGTTCCCGTAGCTGGTTGTTCATATCCTGATGCGTGGGATGCTGTCGATGTGCCGCTCTCA GAACCGTTCTGCACCGGCTCT |
| Length | 2199 |
Transcript
| Sequence id | CC1G_08008T0 |
|---|---|
| Sequence |
>CC1G_08008T0 ATGCCTGGCGTATACAAGAGCGTCACCTCAAGCGATGAATTCGAATTGGTCAAACCACGAGGCAGCAGGGAGACG GTGCACGAGCCAGAAGAAGTGATAGACATGTACGCCGCCGCCGATGGAAGCCCGCACCACGTTCCCTACTCTTTC TCGCCACCAGACAGCGGTGACCGTGCCCTCCCTGAAGAGTCGACGACGAGTATGGGTCCAGGCAAACCGATGAAA AAAGGCGTCAAGATCAGTATCGCGGTGGCCGTTCTTATTGCTGTCATTACGATTGCGATAGCCGTCCCGTTGGCC GTCACGGTTGGGAAGAGCAAGAATGGCACGAGTTCGTCGGGGGGAGGGGCTGGGGGTGGCTCCAGTGGGGGTGGG TCGGCGACGTCTGGAAAGTCTGGGAGTCTCGTTACGATGGAGGACGGTTCGACGTTCACGTATGTGAACGAGTTT GGGGGCGACTGGGCTGCTGACCCTGCGCGTCCCTTTGGTTCGGGTGGAAAGGCCCAGGAGTGGTCGCCACGCGTC GGTGTGGAAGAATGGAAATGGGGAGAACATGTTATTCGTGGCGTCAACCTGGGAGGGTGGTTAGTCACCGAACCG TTCATCTGCCCCGAGTTATATGAGAGATTTATCGAGAATGATGAAAATGTGACCGTGGTCGACGAGTGGACCCTT TCGCTAGCTATGGGCGACCGCCTTCCAGAAGAGATGGAAAACCATTACAAGACCTTCATCACTGAACAAGACTTT GCAGAAATTGCAGCCGCCGGACTGAACTGGATAAGAGTTCCCATCGGTTATTGGGCAATTGAGACGATGGGCGAG GAGCCTTTCCTCGTAGGTACATCGTGGACCTATTTCCTGAAGGCGATTCAATGGGCGAGAAAATACGGTCTTCGA ATTTACCTCGATCTCCATGCTCTCCCGGGAAGCCAAAATGGCTGGAACCATTCTGGAAAAGGTTTGCTTGCCTCT ACACCGCCATTCGTCGAAAATAGACTGACAAATGCCGTTCTCACTGTGAAGCTGGCACTGTTAATTTGTGAGATC ATTGTGACATCCGTTCCGTTGGTTCTGAATCTGGTGCTAATCGCGAAATTCTTTTCCAGTATGCACGGCACAATG GGAATCGCCAATGCTCAAAGAACACTTACGTATCTGCGAATTTTCACGCAATTTGTGAGCCAACCTCAGTACAAG GACGTTGTTCCGATTGTTGGTATAGTGAACGAAATTCTTTGGGATACTATTGGCGAGGAAGCGGTTCAGAGCTTC TATTACGCCGCCTATGAGGCCATGAGGGGTGCTTCAGGTATTGGTGAAGGAAATGGCCCCTATATTGCTATCCAT GAGGGCTTCCAAGGGCCTGCGATCTGGGAAGGATTCCTTTTAGGCTCGGATCGAGTAGTTCTTGACCAGCACCCG TACTTGGCGTTCATGGGTGATCCAAACAGCACCCCTGAATCTAGTGCTCCCAGACCCTGTGAATGGGCGATCGCC ACCAACCAGTCCCAGCAAGTTTTCGGCGTGACGGTTGGCGGAGAATTCTCGACTGCTATTAACAACTGTGGACTC TGGTTGAACGGCGTCGACGGAGCTCCTATTCCTGGATGCGAACTTTGGGATGATTGGAACTCGTGGAACTCGACG ATAATCTCGGGATTGAAACAAGTCACGCTGGCTTCTATGGATGCCTTGCAGCACTTTTTCTTCTGGACTTGGAAG ATAGGTAATTCTACGAGGCTTGGCACGTCCTCCTCGCCGATGTGGCACTATAAACTTGGTTTGGAAAGGGGCTGG ATCCCGAAAGATCCGAGGGAAGCTATTGGACACTGTGCTGAAGTTTTGGGCACGTCTCAATTATTCGATGGTCGA TACCCGTCGACTGCGACCGGAGGCGCTGCTGCTGGGACACTTGACCCTACCCGAGCTTCAGCGCACCCCTTCCCG CCAGCTACGATTTCACCCTCTTTCTCGGGTGATTTACTCTCTCTTCTGCCCACCTATACTCCGACAGGGACGCTG CAGACATTGTTTGCCCCTACATTCACCGCTGCTCCGTCTGCTGTGGTGGGCACCGGTTGGAATAATCCCGATGAT AATTCGCCCGCCTATGTTCCCGTAGCTGGTTGTTCATATCCTGATGCGTGGGATGCTGTCGATGTGCCGCTCTCA GAACCGTTCTGCACCGGCTCTTGAATTCATTCATTCATTTTATTTTTTCATGCTTTCGCATGGATAGTTATGGCT GTGGCATGACCCCCCGAGCATGACATGATGACCCTGTGTAGTGTACGCTGCTTTCTTGGACGATGTTGTGACCTG ACTGTTTGCTTCATCTTCTTTTGTTCTCGCATTTCTTGGACTACTTATTGGAAGTGATATGGACTTTTTGCATCT CTGTATTTTA |
| Length | 2410 |
Gene
| Sequence id | CC1G_08008T0 |
|---|---|
| Sequence |
>CC1G_08008T0 ATGCCTGGCGTATACAAGAGCGTCACCTCAAGCGATGAATTCGAATTGGTCAAACCACGAGGCAGCAGGGAGACG GTGCACGAGCCAGAAGAAGTGATAGACATGGTACGCAAGTTGCCGTCAGCGTTCAGGCTGGACCCTGATGGAAGG ATTTGATTTGGGAATGGCTTATTATTTGGTCTGCCCTTTTTATTACAGTACGCCGCCGCCGATGGAAGCCCGCAC CACGTTCCCTACTCTTTCTCGCCACCAGACAGCGGTGACCGTGCCCTCCCTGAAGAGTCGACGACGAGTATGGGT CCAGGCAAACCGATGAAAAAAGGCGTCAAGATCAGTATCGCGGTGGCCGTTCTTATTGCTGTCATTACGATTGCG ATAGCCGTCCCGTTGGCCGTCACGGTTGGGAAGAGCAAGAATGGCACGAGTTCGTCGGGGGGAGGGGCTGGGGGT GGCTCCAGTGGGGGTGGGTCGGCGACGTCTGGAAAGTCTGGGAGTCTCGTTACGATGGAGGACGGTTCGACGTTC ACGTATGTGAACGAGTTTGGGGGCGACTGGGCTGCTGACCCTGCGCGTCCCTTTGGTTCGGGTGGAAAGGCCCAG GAGTGGTCGCCACGCGTCGGTGTGGAAGAATGGAAATGGGGAGAACATGTTATTCGTGGCGTCAACCTGGGGTAC GTTTTCTTTAACCGTATAGACGCGTACTTTGCTCACTTGGCGACTATTTCTTCCTAAAGAGGGTGGTTAGGTGAG TATGGTCTTTGTGGTCTGTTTCCACGTTCTGATGTTTGCAGTCACCGAACCGTTCATCTGCCCCGAGTTATATGA GAGATTTATCGAGAATGATGAAAATGTGACCGTGGTCGACGAGTGGACCCTTTCGCTAGCTATGGGCGACCGCCT TCCAGAAGAGATGGAAAACCATTACAAGACCTTCATCGTGTGTTGTCCTACTGGCTTCTATTCTCGTCAGCGACT GATCACGTCCAACAGACTGAACAAGACTTTGCAGAAATTGCAGGTATGAGCGGACAAGCCTCTTCACAACTGGTC GAATGTCAACATGTCTATTTTAGCCGCCGGACTGAACTGGATAAGAGTTCCCATCGGTTATTGGGCAATTGAGAC GATGGGCGAGGAGCCTTTCCTCGTAGGTACATCGTGGACCTATTTCCTGAAGGCGTGAGTGCTCTGATACCGCAT TCGAATCCCTTTGACGCTGATGATACCGCGTAGGATTCAATGGGCGAGAAAATACGGTCTTCGAATTTACCTCGA TCTCCATGCTCTCCCGGGAAGCCAAAATGGCTGGGTAAGTATCTCATCTTGTTCACAAAAACTTCCCGCTCAATG ATGTCTATGATAGAACCATTCTGGAAAAGGTTTGCTTGCCTCTACACCGCCATTCGTCGAAAATAGACTGACAAA TGCCGTTCTCACTGTGAAGCTGGCACTGTTAATTTGTGAGATCATTGTGACATCCGTTCCGTTGGTTCTGAATCT GGTGCTAATCGCGAAATTCTTTTCCAGTATGCACGGCACAATGGGAATCGCCAATGCTCAAAGAACACTTACGTA TCTGCGAATTTTCACGCAATTTGTGAGCCAACCTCAGTACAAGGACGTTGTTCCGATGTGAGTGAGAAGTATCGG TGGTTTCTCGCCTTGACTGAACACCCTTCTTTCAAGTGTTGGTATAGTGAACGAAATTCTTTGGGATACTATTGG CGAGGAAGCGGTTCAGAGCTTCTATTACGCCGCCTATGAGGCCATGAGGGGTGCTTCGTACGTTACTCGAACTTC ACCTCGGTCGACTGAACGTTAACGTATCTATTGCAGAGGTATTGGTGAAGGAAATGGCCCCTATATTGCTATCCA TGAGGGCTTCCAAGGGGTACGTCCGGGATTTCTAGGTTCAGTTCATTATCTGAATGATGTTAACTTGGTTTGCGT AGCCTGCGATCTGGGAAGGGTACGCCTTCTCCCACTGGTTCTGGTTCTGGTGTACTCAATGAATTTTAGATTCCT TTTAGGCTCGGATCGAGTAGTTCTTGACCAGCACCCGGTACGTTCGTTCCTTTTCTCTAGATGCCTTGTACTCAA CGGAGTCGATAGTACTTGGCGTTCATGGGTGATCCAAACAGCACGTAAGTCTCGTCTTGTGGAGTTCTTTGACCA GAGCTAGACCCTTTCTTTCGATAGCCCTGAATCTAGTGCTCCCAGACCCTGGTAAGGACGATTTTGTCGGTTGAT GTTAAAGTTATTCATTGGATCTGCAGTGAATGGGCGATCGCCACCAACCAGTCCCAGCAAGTTTTCGGCGTGACG GTTGGCGGAGAATTCTCGACTGCTATTAACAACTGTGGACTCTGGTTCGTTCTTGGTACCCTCTCCAGGCTTCTC GACTCACACGAGATCGTCCTTAGGTTGAACGGCGTCGACGGAGCTCCTATTCCTGGATGCGAACTTTGGGATGAT TGGAACGTAAGTCTTCCATCCTTCTTCCTTCCTTTCCGCGATTCCCGATTGTTAAGTTGTCCTTCGTATCATCCA GTCGTGGAACTCGACGATAATCTCGGGATTGAAACAAGTCACGCTGGCTTCTATGGATGCCTTGCAGCACTTTTT CTTCTGGACTTGGAAGATAGGTAATTCTACGAGGCTTGGCACGTCCTCCTCGCCGATGTGGCACTATAAACTTGG TTTGGAAAGGGGCTGGATCCCGAAAGGTATGCCGCCCAGCTCGTTTTTGTTGGCTCGCTGGTTTTACTCACAAGG TGGGGTCCCCGTGTAGATCCGAGGGAAGCTATTGGACACTGTGCTGAAGTTTTGGGCACGTCTCAATTATTCGAT GGTCGATACCCGTCGACTGCGACCGGAGGCGTAAGTAATTTACCCACTGTTATGTCACTCTTGAGGCGCCCTTGT GCTGATTATGTTAACCCTTCTTTCGCAGGCTGCTGCTGGGACACTTGACCCTACCCGAGCTTCAGCGCACCCCTT CCCGCCAGCTACGATTTCACCCTCTTTCTCGGGTGATTTACTCTCTCTTCTGCCCACCTATACTCCGACAGGGAC GCTGCAGACATTGTTTGCCCCTACATTCACCGCTGCTCCGTCTGCTGTGGTGGGCACCGGTTGGAATAATCCCGA TGATAATTCGCCCGCCTATGTGTAAGTTTCTGCCGCGTTTTTTTCTGCATTCCATTTTCCGTGAGACTCATTTAC TGTTCTGCCGTTTCATGATATAGTCCCGTAGCTGGTTGTTCATATCCTGAGTGGGTGCCTGAAACTTCTTGACTT CTCTCTCTCAGATCACTAACGCTTGGTTCTTTGTAGTGCGTGGGATGCTGTCGATGTGCCGCTCTCAGAACCGTT CTGCACCGGCTCTTGAATTCATTCATTCATTTTATTTTTTCATGCTTTCGCATGGATAGTTATGGCTGTGGCATG ACCCCCCGAGCATGACATGATGACCCTGTGTAGTGTACGCTGCTTTCTTGGACGATGTTGTGACCTGACTGTTTG CTTCATCTTCTTTTGTTCTCGCATTTCTTGGACTACTTATTGGAAGTGATATGGACTTTTTGCATCTCTGTATTT TA |
| Length | 3602 |