CC1G_08425
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_08425 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NAQ6 | Functional description | Aryl-alcohol oxidase |
| Location | Chr_7:2891857..2894200 | Strand | - |
| Gene length (nt) | 2344 | Transcript length (nt) | 1611 |
| CDS length (nt) | 1611 | Protein length (aa) | 536 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits | |
|---|---|---|---|---|---|
| No records | |||||
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 7247 |
| Description | Aryl-alcohol oxidase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00732 | GMC oxidoreductase | IPR000172 | 29 | 289 |
| Pfam | PF05199 | GMC oxidoreductase | IPR007867 | 386 | 527 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 22 | 0.9611 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR036188 | FAD/NAD(P)-binding domain superfamily |
| IPR000172 | Glucose-methanol-choline oxidoreductase, N-terminal |
| IPR012132 | Glucose-methanol-choline oxidoreductase |
| IPR007867 | Glucose-methanol-choline oxidoreductase, C-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0016614 | oxidoreductase activity, acting on CH-OH group of donors | MF |
| GO:0050660 | flavin adenine dinucleotide binding | MF |
KEGG
| KEGG Orthology |
|---|
| K00108 |
EggNOG
| COG category | Description |
|---|---|
| E | Aryl-alcohol oxidase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| AA | AA3 | AA3_2 |
Transcription factor
| Group |
|---|
| No records |
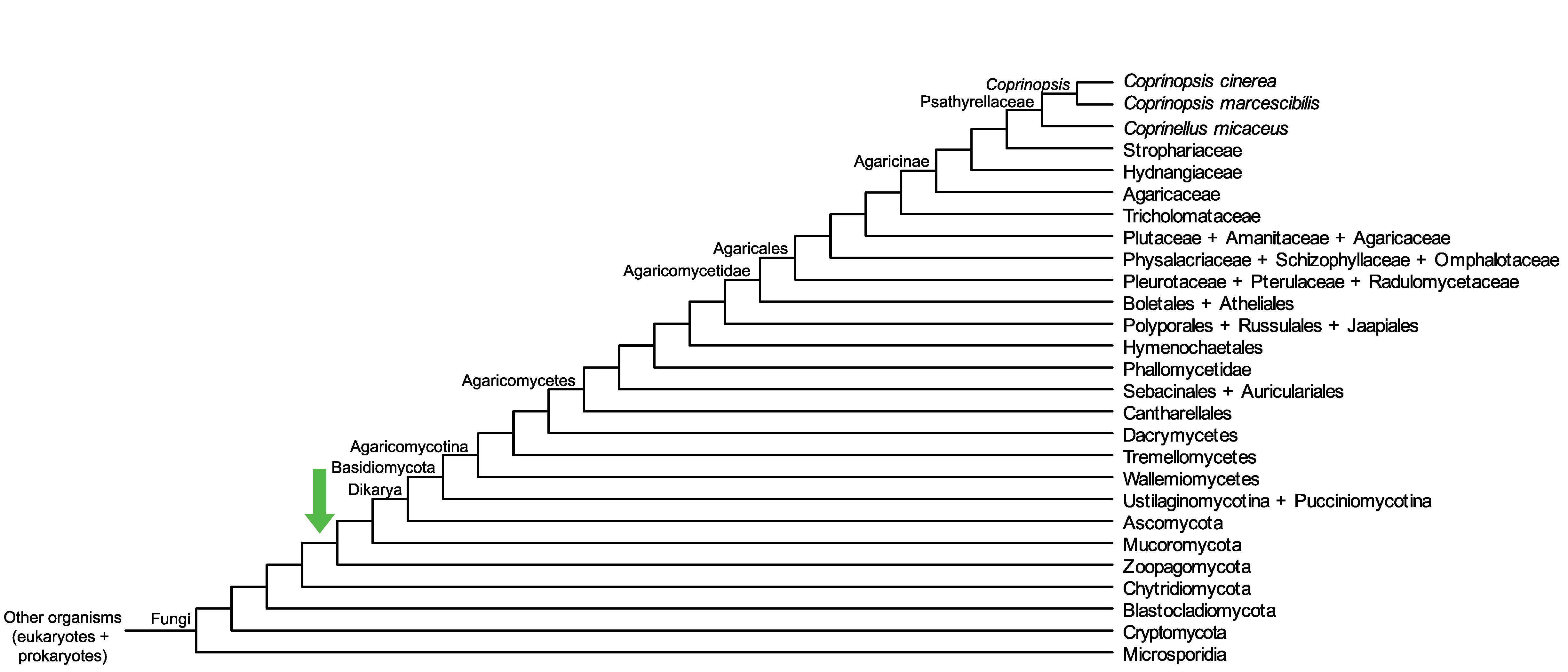
Conservation of CC1G_08425 across fungi.
Arrow shows the origin of gene family containing CC1G_08425.
Protein
| Sequence id | 7247 |
|---|---|
| Sequence |
>7247 MFLRVLPLSLLVVALFLHETIPNILVPGISAVAPNTSWDWNYTSTPQPSLGNTSIYIPRGHVLGGSNTINGMFYV RGSSSDYDRWAKVTGDDGWSWKKILPYVFKTEKWTKLSDSHGSRGKYDPRWHSETGITSVSLSAAPQAIDAKVVE ASRELGGEFAYNRDMNDGNMLGVGWTQLTVGNGERSGAAMTYLAPKYANRPNLVVLSILFPPTILRKVCPPPAVL RNILLAIPELRVTAFKEVIVSAGVFNSPQILQLSGIGDVSLLQALGIEPVVNLPSVGQNLTDQPLMFLNWGLGIE GTVTPDAELQRKWLDQWRTNRTGPLTSSGSNHIISLRIPDNSSIWSGYDDPSSGKNTPHFELAISANGNPYLPPS IAVVVIAIQTTSRGSVKLRSADPFDPPLIDSAVYASNFDFLTMKEGIKAAQRFFSAPTWSEWNLTVSPPLPPLSD EEAWNAQVDSILRLTTANAGHNGGTCAMSPRGAKWGVVDPDLKVKKVEGLRVVDSSVTPFVTAGSTQAGIYAIAE RAADLIKELWM |
| Length | 536 |
Coding
| Sequence id | CC1G_08425T0 |
|---|---|
| Sequence |
>CC1G_08425T0 ATGTTCCTCCGCGTTTTGCCACTCTCGCTCCTCGTCGTCGCGCTCTTCCTACACGAGACCATTCCCAACATTCTC GTACCAGGGATCTCAGCGGTGGCGCCGAATACCTCTTGGGATTGGAACTACACGTCTACACCCCAGCCGTCGCTT GGCAATACGAGCATCTACATCCCCAGGGGCCATGTATTGGGCGGGAGTAACACCATAAACGGAATGTTCTACGTT CGAGGATCATCCTCGGACTACGATCGATGGGCGAAGGTCACTGGGGACGACGGATGGTCGTGGAAGAAGATTTTA CCGTATGTGTTCAAGACCGAAAAGTGGACCAAGTTATCGGACAGCCATGGCTCGAGGGGGAAGTACGATCCTCGT TGGCACAGCGAGACCGGAATCACATCTGTGAGCCTCTCCGCAGCACCTCAAGCAATCGACGCCAAAGTAGTGGAG GCGAGCCGCGAGCTAGGAGGAGAGTTTGCCTACAATCGGGATATGAACGATGGGAATATGCTCGGCGTCGGTTGG ACTCAGCTAACCGTTGGTAACGGTGAACGCAGTGGGGCAGCTATGACATACCTAGCACCGAAATACGCGAACCGG CCAAACCTGGTAGTTCTGTCCATTTTGTTTCCGCCCACGATACTTCGAAAGGTGTGTCCACCGCCCGCTGTGCTA CGCAATATCCTCTTAGCCATTCCAGAGCTTCGAGTCACAGCTTTCAAAGAGGTGATCGTCTCGGCTGGGGTCTTC AACTCTCCGCAAATCCTGCAGCTCTCGGGGATAGGAGACGTCTCCCTACTTCAAGCCCTGGGTATTGAACCGGTG GTAAATTTACCAAGCGTTGGACAGAACCTGACGGATCAGCCATTGATGTTCTTGAATTGGGGGTTAGGAATTGAA GGGACAGTCACCCCAGACGCCGAACTTCAGCGTAAATGGCTCGATCAATGGCGTACCAATCGTACAGGGCCACTA ACCAGTTCAGGGTCCAACCACATCATTTCGCTTCGGATCCCTGACAACTCGAGTATCTGGAGCGGGTACGACGAC CCTTCTAGCGGCAAGAACACCCCTCATTTCGAATTGGCCATTTCCGCGAATGGGAACCCATACCTCCCGCCGTCG ATCGCGGTCGTAGTCATCGCCATTCAAACCACCTCTCGAGGCTCGGTAAAACTGCGCTCGGCGGACCCGTTCGAT CCACCACTCATCGATTCCGCCGTTTACGCTTCCAACTTTGATTTTCTAACCATGAAAGAAGGGATAAAGGCCGCT CAGCGGTTCTTCTCTGCCCCTACGTGGAGCGAATGGAACCTCACAGTCTCGCCGCCTCTCCCGCCTTTATCCGAC GAAGAAGCGTGGAACGCCCAAGTCGACTCAATATTACGATTGACGACAGCAAACGCCGGTCACAATGGCGGGACG TGCGCAATGTCGCCTCGAGGTGCGAAATGGGGAGTTGTCGACCCGGATCTGAAAGTGAAAAAGGTTGAGGGACTG AGGGTTGTCGATTCAAGTGTAACACCGTTCGTAACTGCGGGCTCGACCCAGGCTGGGATTTATGCCATTGCGGAG AGGGCGGCTGATCTGATCAAGGAGCTGTGGATG |
| Length | 1611 |
Transcript
| Sequence id | CC1G_08425T0 |
|---|---|
| Sequence |
>CC1G_08425T0 ATGTTCCTCCGCGTTTTGCCACTCTCGCTCCTCGTCGTCGCGCTCTTCCTACACGAGACCATTCCCAACATTCTC GTACCAGGGATCTCAGCGGTGGCGCCGAATACCTCTTGGGATTGGAACTACACGTCTACACCCCAGCCGTCGCTT GGCAATACGAGCATCTACATCCCCAGGGGCCATGTATTGGGCGGGAGTAACACCATAAACGGAATGTTCTACGTT CGAGGATCATCCTCGGACTACGATCGATGGGCGAAGGTCACTGGGGACGACGGATGGTCGTGGAAGAAGATTTTA CCGTATGTGTTCAAGACCGAAAAGTGGACCAAGTTATCGGACAGCCATGGCTCGAGGGGGAAGTACGATCCTCGT TGGCACAGCGAGACCGGAATCACATCTGTGAGCCTCTCCGCAGCACCTCAAGCAATCGACGCCAAAGTAGTGGAG GCGAGCCGCGAGCTAGGAGGAGAGTTTGCCTACAATCGGGATATGAACGATGGGAATATGCTCGGCGTCGGTTGG ACTCAGCTAACCGTTGGTAACGGTGAACGCAGTGGGGCAGCTATGACATACCTAGCACCGAAATACGCGAACCGG CCAAACCTGGTAGTTCTGTCCATTTTGTTTCCGCCCACGATACTTCGAAAGGTGTGTCCACCGCCCGCTGTGCTA CGCAATATCCTCTTAGCCATTCCAGAGCTTCGAGTCACAGCTTTCAAAGAGGTGATCGTCTCGGCTGGGGTCTTC AACTCTCCGCAAATCCTGCAGCTCTCGGGGATAGGAGACGTCTCCCTACTTCAAGCCCTGGGTATTGAACCGGTG GTAAATTTACCAAGCGTTGGACAGAACCTGACGGATCAGCCATTGATGTTCTTGAATTGGGGGTTAGGAATTGAA GGGACAGTCACCCCAGACGCCGAACTTCAGCGTAAATGGCTCGATCAATGGCGTACCAATCGTACAGGGCCACTA ACCAGTTCAGGGTCCAACCACATCATTTCGCTTCGGATCCCTGACAACTCGAGTATCTGGAGCGGGTACGACGAC CCTTCTAGCGGCAAGAACACCCCTCATTTCGAATTGGCCATTTCCGCGAATGGGAACCCATACCTCCCGCCGTCG ATCGCGGTCGTAGTCATCGCCATTCAAACCACCTCTCGAGGCTCGGTAAAACTGCGCTCGGCGGACCCGTTCGAT CCACCACTCATCGATTCCGCCGTTTACGCTTCCAACTTTGATTTTCTAACCATGAAAGAAGGGATAAAGGCCGCT CAGCGGTTCTTCTCTGCCCCTACGTGGAGCGAATGGAACCTCACAGTCTCGCCGCCTCTCCCGCCTTTATCCGAC GAAGAAGCGTGGAACGCCCAAGTCGACTCAATATTACGATTGACGACAGCAAACGCCGGTCACAATGGCGGGACG TGCGCAATGTCGCCTCGAGGTGCGAAATGGGGAGTTGTCGACCCGGATCTGAAAGTGAAAAAGGTTGAGGGACTG AGGGTTGTCGATTCAAGTGTAACACCGTTCGTAACTGCGGGCTCGACCCAGGCTGGGATTTATGCCATTGCGGAG AGGGCGGCTGATCTGATCAAGGAGCTGTGGATGTGA |
| Length | 1611 |
Gene
| Sequence id | CC1G_08425T0 |
|---|---|
| Sequence |
>CC1G_08425T0 ATGTTCCTCCGCGTTTTGCCACTCTCGCTCCTCGTCGTCGCGCTCTTCCTGTTAGTTCCGACTTCCTCTTTGATA ACTGATACTCTACCACGCAGCCTCCCAAGGTTCGATTTCATCATCGCAGGAGGTCAGTCATAGGTTGTCTCATCC ATAGCGCATGTTTGCTGAGCACTCCAGCAGGTGGAAATGCAGGCCTTGTTCTCGCTAACCGATTGACGGAGAATC CTCGATGGAATGTCTTGGTTATCGAAGCAGGTCCAACGTATGGTCTCTTTCCACTCGTCATTTTACGACACCGTT GCTGATTCGTCGTTCTTTCAGACACGAGACCATTCCCAACATTCTCGTACCAGGGATCTCAGCGGTGGCGCCGAA TACCTCTTGGGATTGGAACTACACGTCTACACCCCAGCCGTCGCTTGGCAATACGAGCATCTACATCCCCAGGGG CCATGTATTGGGCGGGAGTAACACCATAAGTGAGTTTCCACTCTCGCTATACCACCCTTCGACCCAACGAGACTC TATAAATAGACGGAATGTTCTACGTTCGAGGATCATCCTCGGACTACGATCGATGGGCGAAGGTCACTGGGGACG ACGGATGGTCGTGGAAGAAGATTTTACCGTATGTGTTCAAGGTGGGCGCCTTAGTCACATTCGAAGTGCAGTCCT TCCAACCTGACGAGCGGGTTTAGACCGAAAAGTGGACCAAGTTATCGGACAGCCATGGCTCGAGGGGGAAGTACG ATCCTCGTTGGCACAGCGAGACCGGAATCACATCTGTGAGCCTCTCCGCAGCACCTCAAGCAATCGACGCCAAAG TAGTGGAGGCGAGCCGCGAGCTAGGAGGAGAGTTTGCCTACAATCGGGATATGAACGATGGGAATATGCTCGGCG TCGGTTGGTAGCCCTGCCCCTACCCGTGATCTAACATCGTCTGACATGATGCATAGGTTGGACTCAGCTAACCGT TGGTAACGGTGAACGCAGTGGGGCAGCTATGACATACCTAGCACCGAAATACGCGAACCGGCCAAACCTGGTAGT TCTGGTAGGTCATCGTGTCACGAAGGTTTCCGCGACTCGGAGACCTAGTGGCCGTGTTCCTCTCTTTACGACAGT CCATTTTGTTTCCGCCCACGATACTTCGAAAGGTGTGTCCACCGCCCGCTGTGCTACGCAATATCCTCTTAGCCA TTCCAGAGCTTCGAGTCACAGCTTTCAAAGAGGTGATCGTCTCGGCTGGGGTCTTCAACTCTCCGCAAATCCTGC AGCTCTCGGGGATAGGAGACGTCTCCCTACTTCAAGCCCTGGGTATTGAACCGGTGGTAAATTTACCAAGCGTTG GACAGAACCTGACGGATCAGCCATTGATGTTCTTGAATTGGGGGTTAGGAATTGAAGGGACAGTCACCCCGTAAG TCCTCGGCTCAGCCTCGAACTTCTGTTGCCATGTTCTAATTCAAGTTCCAGAGACGCCGAACTTCAGCGTAAATG GCTCGATCAATGGCGTACCAATCGTACAGGGCCACTAACCAGTTCAGGGTCCAACCACATCATTTCGCTTCGGAT CCCTGACAACTCGAGTATCTGGAGCGGGTACGACGACCCTTCTAGCGGCAAGAACACCCCTCATTTCGAATTGGC CATTTCCGTGAGTAGCTCTCGACTTTCATCGCGATAGAATTTGACAGACCCTCATTAGGCGAATGGGAACCCATA CCTCCCGCCGTCGATCGCGGTCGTAGTCATCGCCATTCAAACCACCTCTCGTGAGCTCCCTCCGCTCAATCTGAG ACCCAGCTCCCCCTCACCTCATTGTAGGAGGCTCGGTAAAACTGCGCTCGGCGGACCCGTTCGATCCACCACTCA TCGATTCCGCCGTTTACGCTTCCAACTTTGATTTTCTAACCATGAAAGAAGGGATAAAGGCCGCTCAGCGGTTCT TCTCTGCCCCTACGTGGAGCGAATGGAACCTCACAGTCTCGCCGCCTCTCCCGCCTTTATCCGACGAAGAAGCGT GGAACGCCCAAGTCGACTCAATATTACGATTGACGACAGCAAACGCCGGTCACAATGGCGGGACGTGCGCAATGT CGCCTCGAGGTGCGAAATGGGGAGTTGTCGACCCGGATCTGAAAGTGAAAAAGGTTGAGGGACTGAGGGTTGTCG ATTCAAGTGTAACAGTGAGTCTCGTCAAATTCGTAGTGCTCGCATGTGATGATCTCGAAGCTGAATCTGTTTGAA TTTAAAGCCGTTCGTAACTGCGGGCTCGACCCAGGCTGGGATTTATGCCATTGCGGAGAGGGCGGCTGATCTGAT CAAGGAGCTGTGGATGTGA |
| Length | 2344 |