CC1G_08740
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_08740 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NIZ6 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_10:948978..953061 | Strand | - |
| Gene length (nt) | 4084 | Transcript length (nt) | 3663 |
| CDS length (nt) | 3663 | Protein length (aa) | 1220 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7262169 | 65.3 | 0 | 1519 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB17700 | 54.8 | 0 | 1212 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1584331 | 51.2 | 0 | 1123 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_12102 | 52.7 | 0 | 1121 |
| Lentinula edodes NBRC 111202 | Lenedo1_1255126 | 52.7 | 0 | 1119 |
| Flammulina velutipes | Flave_chr04AA00474 | 52.3 | 0 | 1087 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_130424 | 48.9 | 1.223E-304 | 998 |
| Grifola frondosa | Grifr_OBZ74539 | 47.1 | 9.131E-286 | 908 |
| Auricularia subglabra | Aurde3_1_1237586 | 44.4 | 3.634E-259 | 831 |
| Lentinula edodes B17 | Lened_B_1_1_7405 | 71.4 | 1.886E-212 | 693 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1048733 | 78.9 | 8.53E-163 | 546 |
| Schizophyllum commune H4-8 | Schco3_2514250 | 80.3 | 5.451E-142 | 484 |
| Pleurotus ostreatus PC9 | PleosPC9_1_98061 | 91.5 | 1.857E-141 | 482 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_210033 | 91 | 3.518E-141 | 481 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_78306 | 91 | 3.666E-141 | 481 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 7486 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 141 | 401 |
| Pfam | PF02149 | Kinase associated domain 1 | IPR001772 | 1174 | 1212 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR001772 | Kinase associated domain 1 (KA1) |
| IPR028375 | KA1 domain/Ssp2, C-terminal |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K08286 |
EggNOG
| COG category | Description |
|---|---|
| T | Camk camkl kin4 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
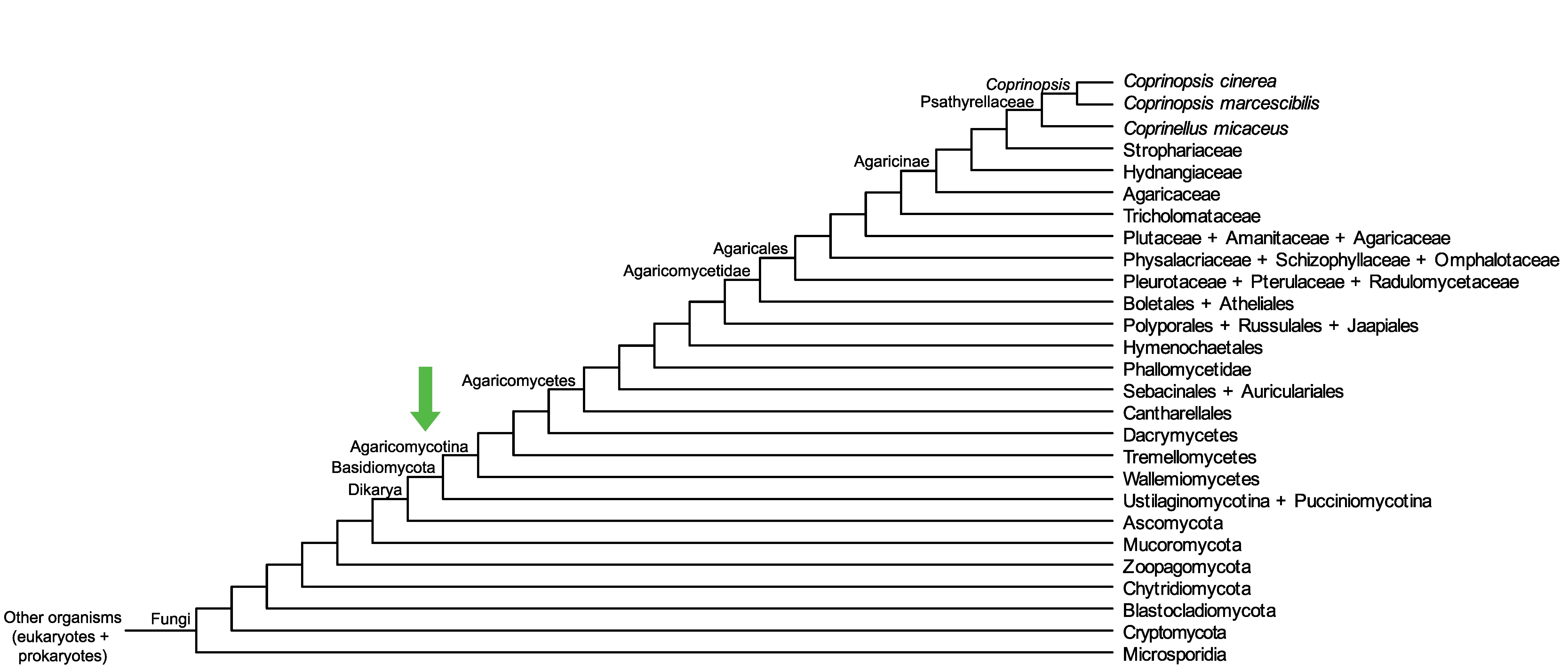
Conservation of CC1G_08740 across fungi.
Arrow shows the origin of gene family containing CC1G_08740.
Protein
| Sequence id | 7486 |
|---|---|
| Sequence |
>7486 MANQAVFSPSLVDEVNTLLMAPPSQSTSLQIPPAETERGSSRQAAHNSPAHPGSASAYRPASVAVHSATPSSSHA GSSSSRRQQRASHSVVSGTSNDQDRRNGHSRHEGSPYPDVYSHPAAVAYAAAHPRRTIPKFGPYLLLQTLGEGEF GKVKLGLHCQWGEEVAVKLIRRGNVDSSVRMSKVEREIEVLRTLKHPNIVRLYDVIETDKYIGIILEYASGGELF DHILAHRHLRERDAAKLFSQLISGVWYIHQKKIVHRDLKLENLLLDRHRNVIITDFGFANRFEHRSDDLMQTSCG SPCYAAPELVISEGLYVGSAVDIWSCGVILYAMLAGYLPFDDDPANPDGDNINLLYRYIVNTPLSFPDFVSAEAR DLLSLMLVPDPTRRANLDTVMRHPWLSAYHGTPRTDGVPNAFGKSVADLEKAAMEQHQQKRIAYQKQMKANAVLN NTSAPSPRSHSHRPEPTSAAPTSGRSRSVQPEFIYDSSVDQSISAPVPSANANATPKHNGTTPKAFDSPAALGLA DDDPFAPPPGTKVNSGVATATSPSKQRPSEDSARTPAAGLSPTDNKTPSKGHRSSTSGGGRDIRHTIQVEYDEPK SAKRSDDKRRDRSGSQGQPSQASAQPNGVLPNVQNGQPATRERRPSHGGATKPLPPQPVAPSAYKPPPTPATPKG SSHQQPSATPVKAASGGDVPTVNVSSPPQTPSFHQLSHPKDKDKDASSQNSASSKRGHKKGKSSIDKIGLGKIFG SGNSAPAPPVPPLNGSEHNLQSPSAPSSRVPSESQGSASSLQAPQEPAPPKDGKKSRRNTLTVMVEPFIGTIRNR KGRPPTTPATAEPVPTAQTSVNATHPPVPSSATVPALPTAPHDADLTHPDIPVEDGPGLSASSNKAKKVMQWFRT KSKGRESVGIGLGGEAEHHDSLSTPITEQKYKKGFSASSSTVNQTSTPASAMSPQVVVTQAQQATTPKTPKVSAP GHPQRAASSATETPSFVARFRNSVTVGGGSHSHSSKHSNQPGGQLRIHQGAVDQTTITTRPPPEVMAKVKAVLEG MGVEIQLESEYKYRCIRHKKKKGATSAAGTAPNGAPANLAAVQVTGSAASNGVDRRGLPLPSPSAFSATGGMLRG LLMRRQSSQVSSSSQPSLAFDDETSVVVSEPLLMSDITYGDPSQDAGDEVRFSVELTRIDRLNDTYSLDIRRLKG NLRSYKYLYDTIRQRADLQR |
| Length | 1220 |
Coding
| Sequence id | CC1G_08740T0 |
|---|---|
| Sequence |
>CC1G_08740T0 ATGGCAAATCAAGCGGTCTTTTCCCCCTCTCTTGTCGACGAGGTCAACACCCTTCTGATGGCGCCGCCGTCCCAA TCGACCAGCTTGCAGATACCTCCAGCAGAAACAGAACGGGGATCGTCGAGGCAGGCAGCGCACAACTCCCCAGCG CATCCAGGGTCGGCCTCAGCTTACCGCCCAGCGTCGGTAGCAGTGCACTCGGCAACCCCCTCTTCAAGCCATGCA GGATCCAGTTCCTCAAGACGCCAACAGCGCGCATCGCACAGCGTAGTCTCAGGAACATCCAACGACCAGGACCGT CGCAATGGCCATTCACGACACGAAGGCTCGCCGTACCCAGATGTTTACTCGCACCCAGCTGCTGTTGCTTACGCA GCCGCCCACCCCCGCCGAACTATCCCTAAATTCGGACCCTATCTGTTGCTGCAGACCCTTGGAGAAGGAGAGTTC GGCAAGGTGAAGCTTGGCTTGCATTGCCAATGGGGAGAAGAGGTCGCTGTTAAGCTCATTCGACGTGGAAACGTT GACAGCAGTGTTCGCATGTCCAAGGTCGAACGCGAAATTGAAGTCCTCAGGACCCTGAAGCACCCCAACATTGTT CGACTCTACGATGTGATTGAAACCGACAAGTACATCGGCATTATCCTCGAATACGCTTCTGGTGGAGAGCTATTC GACCATATTCTTGCCCACCGTCATCTGCGCGAACGAGACGCAGCCAAACTCTTCTCTCAACTCATCTCCGGCGTG TGGTACATCCACCAAAAGAAGATCGTCCACCGCGACCTCAAATTGGAGAACCTTCTCCTCGACCGTCACCGCAAT GTCATCATCACCGATTTCGGTTTCGCAAACCGTTTCGAGCACAGGTCCGATGACCTGATGCAAACCTCCTGTGGT AGTCCGTGTTACGCTGCTCCAGAACTCGTCATCAGCGAAGGGCTCTATGTCGGTAGCGCTGTGGATATCTGGAGT TGTGGTGTCATTCTCTACGCGATGTTGGCGGGCTATCTCCCCTTTGATGACGACCCAGCAAACCCCGATGGCGAC AACATCAACCTTTTGTACCGATACATCGTCAACACACCCCTGTCGTTCCCCGATTTCGTCTCTGCAGAAGCCCGA GACTTGCTCAGTCTCATGCTGGTTCCGGACCCCACCCGTCGAGCCAACCTGGACACGGTGATGCGCCATCCATGG CTATCAGCCTACCATGGGACCCCTCGCACTGACGGGGTTCCTAATGCCTTTGGCAAGTCGGTTGCTGACCTTGAG AAGGCAGCGATGGAGCAACACCAGCAGAAACGCATTGCTTACCAAAAGCAGATGAAGGCAAATGCTGTTCTGAAC AACACTTCGGCTCCTTCACCCCGCAGCCACAGCCATCGTCCCGAGCCAACGAGCGCCGCCCCTACGTCCGGCCGG AGCCGCTCAGTACAGCCCGAGTTCATCTACGACTCCTCTGTTGATCAGTCGATATCCGCCCCAGTTCCAAGCGCC AATGCCAATGCTACGCCGAAGCACAACGGAACAACTCCCAAGGCCTTTGACAGCCCCGCAGCACTTGGTTTGGCG GATGACGATCCTTTTGCACCTCCCCCCGGCACCAAGGTAAACAGCGGTGTCGCCACCGCCACATCTCCTTCGAAG CAACGTCCCTCAGAAGATTCTGCTCGAACGCCTGCTGCAGGTCTATCGCCCACCGACAACAAGACCCCGTCCAAG GGTCACAGATCGAGCACGAGCGGCGGCGGAAGGGACATCCGTCACACTATTCAGGTCGAGTACGACGAGCCGAAG AGTGCCAAGAGGAGCGACGACAAAAGACGAGATAGAAGCGGCAGTCAAGGACAGCCAAGCCAAGCTAGTGCTCAG CCCAACGGTGTTCTTCCCAATGTCCAGAATGGACAGCCGGCGACTAGAGAGAGGCGACCATCTCATGGTGGTGCT ACCAAGCCTCTTCCGCCACAGCCCGTCGCTCCCTCCGCTTACAAACCCCCGCCGACGCCAGCCACGCCTAAGGGC TCGTCGCACCAGCAGCCGAGTGCGACTCCCGTCAAGGCTGCTTCTGGAGGCGACGTGCCAACCGTCAACGTTTCT TCGCCCCCACAGACGCCTTCTTTTCACCAGCTCTCCCACCCAAAAGACAAGGATAAAGACGCCAGTAGCCAAAAC TCCGCCTCCTCAAAACGAGGTCACAAAAAGGGCAAGTCTAGCATCGACAAAATAGGTCTCGGCAAGATCTTTGGA AGCGGAAACAGTGCTCCTGCTCCCCCGGTCCCTCCCCTGAACGGCAGCGAGCATAACCTCCAATCCCCTAGTGCT CCATCTTCTCGTGTTCCTTCCGAAAGCCAGGGTAGCGCCTCTTCACTTCAAGCTCCTCAGGAACCGGCGCCGCCC AAGGATGGGAAGAAAAGCCGTCGCAACACTTTGACAGTGATGGTCGAGCCTTTTATTGGCACTATCCGAAACCGC AAGGGACGTCCTCCCACCACTCCCGCTACCGCTGAGCCCGTACCAACTGCCCAGACGTCGGTCAATGCGACACAC CCACCTGTCCCCTCTTCGGCGACCGTTCCTGCACTCCCCACCGCCCCGCACGATGCCGACCTTACTCACCCGGAT ATTCCTGTCGAAGACGGCCCTGGATTGTCAGCATCGAGTAACAAAGCCAAGAAGGTCATGCAGTGGTTCCGAACC AAGTCGAAGGGGCGTGAATCTGTCGGCATTGGATTGGGCGGTGAAGCCGAGCACCACGATTCTCTGAGCACGCCC ATAACTGAACAGAAATACAAGAAGGGATTCTCCGCGTCGAGCAGCACCGTCAACCAAACCTCGACACCTGCATCC GCCATGTCGCCTCAGGTGGTTGTCACACAGGCACAGCAGGCTACCACGCCTAAGACTCCCAAGGTTTCCGCTCCC GGTCATCCCCAGCGGGCTGCTAGCTCCGCTACCGAAACCCCCAGTTTCGTCGCTCGGTTCCGCAACTCAGTTACA GTCGGTGGCGGCTCCCATTCGCACTCATCCAAGCACTCGAACCAACCTGGGGGCCAACTGCGTATTCACCAGGGT GCTGTGGACCAGACCACCATTACTACGAGGCCACCACCCGAGGTTATGGCCAAAGTCAAGGCCGTGTTGGAGGGG ATGGGTGTTGAGATTCAGCTGGAGAGCGAGTACAAGTACAGGTGCATCCGTCACAAGAAGAAGAAGGGGGCGACT AGTGCTGCGGGGACTGCTCCCAACGGTGCTCCAGCTAACCTCGCTGCTGTACAAGTCACCGGCAGCGCTGCTTCG AATGGGGTTGATCGCCGTGGCCTGCCGCTTCCATCTCCTTCGGCTTTCTCTGCCACTGGTGGCATGTTGCGAGGA TTGCTCATGAGGCGACAGTCGTCCCAAGTTTCGTCTTCGTCGCAACCCTCACTCGCCTTCGACGACGAGACTTCC GTCGTGGTCAGCGAACCATTGCTCATGTCCGACATTACCTACGGTGATCCCTCTCAAGATGCGGGTGACGAAGTT CGCTTCTCGGTCGAGCTTACTCGAATTGATCGTTTGAACGATACCTACTCCCTCGACATTCGTCGACTCAAGGGT AACCTCCGAAGCTACAAGTATCTGTACGATACCATTAGACAACGGGCTGATCTACAACGC |
| Length | 3663 |
Transcript
| Sequence id | CC1G_08740T0 |
|---|---|
| Sequence |
>CC1G_08740T0 ATGGCAAATCAAGCGGTCTTTTCCCCCTCTCTTGTCGACGAGGTCAACACCCTTCTGATGGCGCCGCCGTCCCAA TCGACCAGCTTGCAGATACCTCCAGCAGAAACAGAACGGGGATCGTCGAGGCAGGCAGCGCACAACTCCCCAGCG CATCCAGGGTCGGCCTCAGCTTACCGCCCAGCGTCGGTAGCAGTGCACTCGGCAACCCCCTCTTCAAGCCATGCA GGATCCAGTTCCTCAAGACGCCAACAGCGCGCATCGCACAGCGTAGTCTCAGGAACATCCAACGACCAGGACCGT CGCAATGGCCATTCACGACACGAAGGCTCGCCGTACCCAGATGTTTACTCGCACCCAGCTGCTGTTGCTTACGCA GCCGCCCACCCCCGCCGAACTATCCCTAAATTCGGACCCTATCTGTTGCTGCAGACCCTTGGAGAAGGAGAGTTC GGCAAGGTGAAGCTTGGCTTGCATTGCCAATGGGGAGAAGAGGTCGCTGTTAAGCTCATTCGACGTGGAAACGTT GACAGCAGTGTTCGCATGTCCAAGGTCGAACGCGAAATTGAAGTCCTCAGGACCCTGAAGCACCCCAACATTGTT CGACTCTACGATGTGATTGAAACCGACAAGTACATCGGCATTATCCTCGAATACGCTTCTGGTGGAGAGCTATTC GACCATATTCTTGCCCACCGTCATCTGCGCGAACGAGACGCAGCCAAACTCTTCTCTCAACTCATCTCCGGCGTG TGGTACATCCACCAAAAGAAGATCGTCCACCGCGACCTCAAATTGGAGAACCTTCTCCTCGACCGTCACCGCAAT GTCATCATCACCGATTTCGGTTTCGCAAACCGTTTCGAGCACAGGTCCGATGACCTGATGCAAACCTCCTGTGGT AGTCCGTGTTACGCTGCTCCAGAACTCGTCATCAGCGAAGGGCTCTATGTCGGTAGCGCTGTGGATATCTGGAGT TGTGGTGTCATTCTCTACGCGATGTTGGCGGGCTATCTCCCCTTTGATGACGACCCAGCAAACCCCGATGGCGAC AACATCAACCTTTTGTACCGATACATCGTCAACACACCCCTGTCGTTCCCCGATTTCGTCTCTGCAGAAGCCCGA GACTTGCTCAGTCTCATGCTGGTTCCGGACCCCACCCGTCGAGCCAACCTGGACACGGTGATGCGCCATCCATGG CTATCAGCCTACCATGGGACCCCTCGCACTGACGGGGTTCCTAATGCCTTTGGCAAGTCGGTTGCTGACCTTGAG AAGGCAGCGATGGAGCAACACCAGCAGAAACGCATTGCTTACCAAAAGCAGATGAAGGCAAATGCTGTTCTGAAC AACACTTCGGCTCCTTCACCCCGCAGCCACAGCCATCGTCCCGAGCCAACGAGCGCCGCCCCTACGTCCGGCCGG AGCCGCTCAGTACAGCCCGAGTTCATCTACGACTCCTCTGTTGATCAGTCGATATCCGCCCCAGTTCCAAGCGCC AATGCCAATGCTACGCCGAAGCACAACGGAACAACTCCCAAGGCCTTTGACAGCCCCGCAGCACTTGGTTTGGCG GATGACGATCCTTTTGCACCTCCCCCCGGCACCAAGGTAAACAGCGGTGTCGCCACCGCCACATCTCCTTCGAAG CAACGTCCCTCAGAAGATTCTGCTCGAACGCCTGCTGCAGGTCTATCGCCCACCGACAACAAGACCCCGTCCAAG GGTCACAGATCGAGCACGAGCGGCGGCGGAAGGGACATCCGTCACACTATTCAGGTCGAGTACGACGAGCCGAAG AGTGCCAAGAGGAGCGACGACAAAAGACGAGATAGAAGCGGCAGTCAAGGACAGCCAAGCCAAGCTAGTGCTCAG CCCAACGGTGTTCTTCCCAATGTCCAGAATGGACAGCCGGCGACTAGAGAGAGGCGACCATCTCATGGTGGTGCT ACCAAGCCTCTTCCGCCACAGCCCGTCGCTCCCTCCGCTTACAAACCCCCGCCGACGCCAGCCACGCCTAAGGGC TCGTCGCACCAGCAGCCGAGTGCGACTCCCGTCAAGGCTGCTTCTGGAGGCGACGTGCCAACCGTCAACGTTTCT TCGCCCCCACAGACGCCTTCTTTTCACCAGCTCTCCCACCCAAAAGACAAGGATAAAGACGCCAGTAGCCAAAAC TCCGCCTCCTCAAAACGAGGTCACAAAAAGGGCAAGTCTAGCATCGACAAAATAGGTCTCGGCAAGATCTTTGGA AGCGGAAACAGTGCTCCTGCTCCCCCGGTCCCTCCCCTGAACGGCAGCGAGCATAACCTCCAATCCCCTAGTGCT CCATCTTCTCGTGTTCCTTCCGAAAGCCAGGGTAGCGCCTCTTCACTTCAAGCTCCTCAGGAACCGGCGCCGCCC AAGGATGGGAAGAAAAGCCGTCGCAACACTTTGACAGTGATGGTCGAGCCTTTTATTGGCACTATCCGAAACCGC AAGGGACGTCCTCCCACCACTCCCGCTACCGCTGAGCCCGTACCAACTGCCCAGACGTCGGTCAATGCGACACAC CCACCTGTCCCCTCTTCGGCGACCGTTCCTGCACTCCCCACCGCCCCGCACGATGCCGACCTTACTCACCCGGAT ATTCCTGTCGAAGACGGCCCTGGATTGTCAGCATCGAGTAACAAAGCCAAGAAGGTCATGCAGTGGTTCCGAACC AAGTCGAAGGGGCGTGAATCTGTCGGCATTGGATTGGGCGGTGAAGCCGAGCACCACGATTCTCTGAGCACGCCC ATAACTGAACAGAAATACAAGAAGGGATTCTCCGCGTCGAGCAGCACCGTCAACCAAACCTCGACACCTGCATCC GCCATGTCGCCTCAGGTGGTTGTCACACAGGCACAGCAGGCTACCACGCCTAAGACTCCCAAGGTTTCCGCTCCC GGTCATCCCCAGCGGGCTGCTAGCTCCGCTACCGAAACCCCCAGTTTCGTCGCTCGGTTCCGCAACTCAGTTACA GTCGGTGGCGGCTCCCATTCGCACTCATCCAAGCACTCGAACCAACCTGGGGGCCAACTGCGTATTCACCAGGGT GCTGTGGACCAGACCACCATTACTACGAGGCCACCACCCGAGGTTATGGCCAAAGTCAAGGCCGTGTTGGAGGGG ATGGGTGTTGAGATTCAGCTGGAGAGCGAGTACAAGTACAGGTGCATCCGTCACAAGAAGAAGAAGGGGGCGACT AGTGCTGCGGGGACTGCTCCCAACGGTGCTCCAGCTAACCTCGCTGCTGTACAAGTCACCGGCAGCGCTGCTTCG AATGGGGTTGATCGCCGTGGCCTGCCGCTTCCATCTCCTTCGGCTTTCTCTGCCACTGGTGGCATGTTGCGAGGA TTGCTCATGAGGCGACAGTCGTCCCAAGTTTCGTCTTCGTCGCAACCCTCACTCGCCTTCGACGACGAGACTTCC GTCGTGGTCAGCGAACCATTGCTCATGTCCGACATTACCTACGGTGATCCCTCTCAAGATGCGGGTGACGAAGTT CGCTTCTCGGTCGAGCTTACTCGAATTGATCGTTTGAACGATACCTACTCCCTCGACATTCGTCGACTCAAGGGT AACCTCCGAAGCTACAAGTATCTGTACGATACCATTAGACAACGGGCTGATCTACAACGCTAG |
| Length | 3663 |
Gene
| Sequence id | CC1G_08740T0 |
|---|---|
| Sequence |
>CC1G_08740T0 ATGGCAAATCAAGCGGTCGTATGTGGGGGAAAAGGCTAAAGGTGATCGTGGCGTTCCCAGGGATTTCTTGACAAA ATCGGCACATCTTCCCACGTCTCGAGCCATTTGCCTTTGTTTGAATTCAACCCTTAGTTTCCCTCCCGTCACCGA ATCCCGTATTCAACATCTTCCTCGTCGTTGACGGTGACGACGACGACCTCGACCACATAAAACATCCAGCACAGT CTGTATATCCAGTCGTCGTCGCCGTGATCTACCCGTTGACACGTCGTTGCCGCAGTTTTCCCCCTCTCTTGTCGA CGAGGTCAACACCCTTCTGATGGCGCCGCCGTCCCAATCGACCAGCTTGCAGATACCTCCAGCAGAAACAGAACG GGGATCGTCGAGGCAGGCAGCGCACAACTCCCCAGCGCATCCAGGGTCGGCCTCAGCTTACCGCCCAGCGTCGGT AGCAGTGCACTCGGCAACCCCCTCTTCAAGCCATGCAGGATCCAGTTCCTCAAGACGCCAACAGCGCGCATCGCA CAGCGTAGTCTCAGGAACATCCAACGACCAGGACCGTCGCAATGGCCATTCACGACACGAAGGCTCGCCGTACCC AGATGTTTACTCGCACCCAGCTGCTGTTGCTTACGCAGCCGCCCACCCCCGCCGAACTATCCCTAAATTCGGACC CTATCTGTTGCTGCAGACCCTTGGAGAAGGAGAGTTCGGCAAGGTGAAGCTTGGCTTGCATTGCCAATGGGGAGA AGAGGTCGCTGTTAAGCTCATTCGACGTGGAAACGTTGACAGCAGTGTTCGCATGTCCAAGGTCGAACGCGAAAT TGAAGTCCTCAGGGTAAGTTAACCTCGTATCGAACGTGGATGCCTGCTGACTCTGGATCTAGACCCTGAAGCACC CCAACATTGTTCGACTCTACGATGTGATTGAAACCGACAAGTACATCGGCATTATCCTCGAATACGCTTCTGGTG GAGAGCTATTCGACCATATTCTTGCCCACCGTCATCTGCGCGAACGAGACGCAGCCAAACTCTTCTCTCAACTCA TCTCCGGCGTGTGGTACATCCACCAAAAGAAGATCGTCCACCGCGACCTCAAATTGGAGAACCTTCTCCTCGACC GTCACCGCAATGTCATCATCACCGATTTCGGTTTCGCAAACCGTTTCGAGCACAGGTCCGATGACCTGATGCAAA CCTCCTGTGGTAGTCCGTGTTACGCTGCTCCAGAACTCGTCATCAGCGAAGGGCTCTATGTCGGTAGCGCTGTGG ATATCTGGAGTTGTGGTGTCATTCTCTACGCGATGTTGGCGGGCTATCTCCCCTTTGATGACGACCCAGCAAACC CCGATGGCGACAACATCAACCTTTTGTACCGATACATCGTCAACACACCCCTGTCGTTCCCCGATTTCGTCTCTG CAGAAGCCCGAGACTTGCTCAGTCTCATGCTGGTTCCGGACCCCACCCGTCGAGCCAACCTGGACACGGTGATGC GCCATCCATGGCTATCAGCCTACCATGGGACCCCTCGCACTGACGGGGTTCCTAATGCCTTTGGCAAGTCGGTTG CTGACCTTGAGAAGGCAGCGATGGAGCAACACCAGCAGAAACGCATTGCTTACCAAAAGCAGATGAAGGCAAATG CTGTTCTGAACAACACTTCGGCTCCTTCACCCCGCAGCCACAGCCATCGTCCCGAGCCAACGAGCGCCGCCCCTA CGTCCGGCCGGAGCCGCTCAGTACAGCCCGAGTTCATCTACGACTCCTCTGTTGATCAGTCGATATCCGCCCCAG TTCCAAGCGCCAATGCCAATGCTACGCCGAAGCACAACGGAACAACTCCCAAGGCCTTTGACAGCCCCGCAGCAC TTGGTTTGGCGGATGACGATCCTTTTGCACCTCCCCCCGGCACCAAGGTAAACAGCGGTGTCGCCACCGCCACAT CTCCTTCGAAGCAACGTCCCTCAGAAGATTCTGCTCGAACGCCTGCTGCAGGTCTATCGCCCACCGACAACAAGA CCCCGTCCAAGGGTCACAGATCGAGCACGAGCGGCGGCGGAAGGGACATCCGTCACACTATTCAGGTCGAGTACG ACGAGCCGAAGAGTGCCAAGAGGAGCGACGACAAAAGACGAGATAGAAGCGGCAGTCAAGGACAGCCAAGCCAAG CTAGTGCTCAGCCCAACGGTGTTCTTCCCAATGTCCAGAATGGACAGCCGGCGACTAGAGAGAGGCGACCATCTC ATGGTGGTGCTACCAAGCCTCTTCCGCCACAGCCCGTCGCTCCCTCCGCTTACAAACCCCCGCCGACGCCAGCCA CGCCTAAGGGCTCGTCGCACCAGCAGCCGAGTGCGACTCCCGTCAAGGCTGCTTCTGGAGGCGACGTGCCAACCG TCAACGTTTCTTCGCCCCCACAGACGCCTTCTTTTCACCAGCTCTCCCACCCAAAAGACAAGGATAAAGACGCCA GTAGCCAAAACTCCGCCTCCTCAAAACGAGGTCACAAAAAGGGCAAGTCTAGCATCGACAAAATAGGTCTCGGCA AGATCTTTGGAAGCGGAAACAGTGCTCCTGCTCCCCCGGTCCCTCCCCTGAACGGCAGCGAGCATAACCTCCAAT CCCCTAGTGCTCCATCTTCTCGTGTTCCTTCCGAAAGCCAGGGTAGCGCCTCTTCACTTCAAGCTCCTCAGGAAC CGGCGCCGCCCAAGGATGGGAAGAAAAGCCGTCGCAACACTTTGACAGTGATGGTCGAGCCTTTTATTGGCACTA TCCGAAACCGCAAGGGACGTCCTCCCACCACTCCCGCTACCGCTGAGCCCGTACCAACTGCCCAGACGTCGGTCA ATGCGACACACCCACCTGTCCCCTCTTCGGCGACCGTTCCTGCACTCCCCACCGCCCCGCACGATGCCGACCTTA CTCACCCGGATATTCCTGTCGAAGACGGCCCTGGATTGTCAGCATCGAGTAACAAAGCCAAGAAGGTCATGCAGT GGTTCCGAACCAAGTCGAAGGGGCGTGAATCTGTCGGCATTGGATTGGGCGGTGAAGCCGAGCACCACGATTCTC TGAGCACGCCCATAACTGAACAGAAATACAAGAAGGGATTCTCCGCGTCGAGCAGCACCGTCAACCAAACCTCGA CACCTGCATCCGCCATGTCGCCTCAGGTGGTTGTCACACAGGCACAGCAGGCTACCACGCCTAAGACTCCCAAGG TTTCCGCTCCCGGTCATCCCCAGCGGGCTGCTAGCTCCGCTACCGAAACCCCCAGTTTCGTCGCTCGGTTCCGCA ACTCAGTTACAGTCGGTGGCGGCTCCCATTCGCACTCATCCAAGCACTCGAACCAACCTGGGGGCCAACTGCGTA TTCACCAGGGTGCTGTGGACCAGACCACCATTACTACGAGGCCACCACCCGAGGTTATGGCCAAAGTCAAGGCCG TGTTGGAGGGGATGGGTGTTGAGATTCAGCTGGAGAGCGAGTACAAGTACAGGTGCATCCGTCACAAGAAGAAGA AGGGGGCGACTAGTGCTGCGGGGACTGCTCCCAACGGTGCTCCAGCTAACCTCGCTGCTGTACAAGTCACCGGCA GCGCTGCTTCGAATGGGGTGAGTAATTCAAATGTTGTTTAATCCACTTTCTGTCCTGACGATGATTATGTAGGTT GATCGCCGTGGCCTGCCGCTTCCATCTCCTTCGGCTTTCTCTGCCACTGGTGGCATGTTGCGAGGATTGCTCATG AGGCGACAGTCGTCCCAAGTTTCGTCTTCGTCGCAACCCTCACTCGCCTTCGACGACGAGACTTCCGTCGTGGTC AGCGAACCATTGCTCATGTCCGACATTACCTACGGTGATCCCTCTCAAGATGCGGGTGACGAAGTTCGCTTCTCG GTCGAGCTTACTCGAATTGATCGTTTGAACGATACCTACTCCCTCGACATTCGTCGACTCAAGGGTAACCTCCGA AGCTACAAGTATCTGTACGATACCATTAGACAGTAAGCCTATCTGTCTTCCGTCTGGCCGTCCATTTGATTAACG CTTTCTATCTAGACGGGCTGATCTACAACGCTAG |
| Length | 4084 |