CC1G_09141
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09141 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P9P2 | Functional description | CAMK/CAMK-Unique protein kinase |
| Location | Chr_2:2759126..2761693 | Strand | - |
| Gene length (nt) | 2568 | Transcript length (nt) | 2568 |
| CDS length (nt) | 2568 | Protein length (aa) | 855 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7265270 | 38.1 | 9.562E-166 | 542 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_118488 | 38.4 | 9.675E-160 | 524 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_183603 | 41.9 | 2.366E-156 | 514 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1110814 | 34.2 | 1.865E-127 | 429 |
| Pleurotus ostreatus PC9 | PleosPC9_1_68860 | 34.1 | 8.898E-126 | 424 |
| Lentinula edodes B17 | Lened_B_1_1_2966 | 31.3 | 4.082E-124 | 419 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_11892 | 31.3 | 5.119E-124 | 419 |
| Lentinula edodes NBRC 111202 | Lenedo1_1166228 | 31.2 | 1.181E-121 | 412 |
| Flammulina velutipes | Flave_chr09AA00337 | 36.2 | 2.69E-115 | 393 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_132780 | 35.5 | 6.238E-110 | 377 |
| Grifola frondosa | Grifr_OBZ75982 | 31.9 | 4.107E-79 | 284 |
| Pleurotus eryngii ATCC 90797 | Pleery1_834833 | 42.7 | 7.967E-65 | 240 |
| Auricularia subglabra | Aurde3_1_1324498 | 27.9 | 2.619E-51 | 198 |
| Schizophyllum commune H4-8 | Schco3_2004633 | 29.6 | 5.434E-32 | 135 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 7818 |
| Description | CAMK/CAMK-Unique protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 427 | 769 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K14864 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
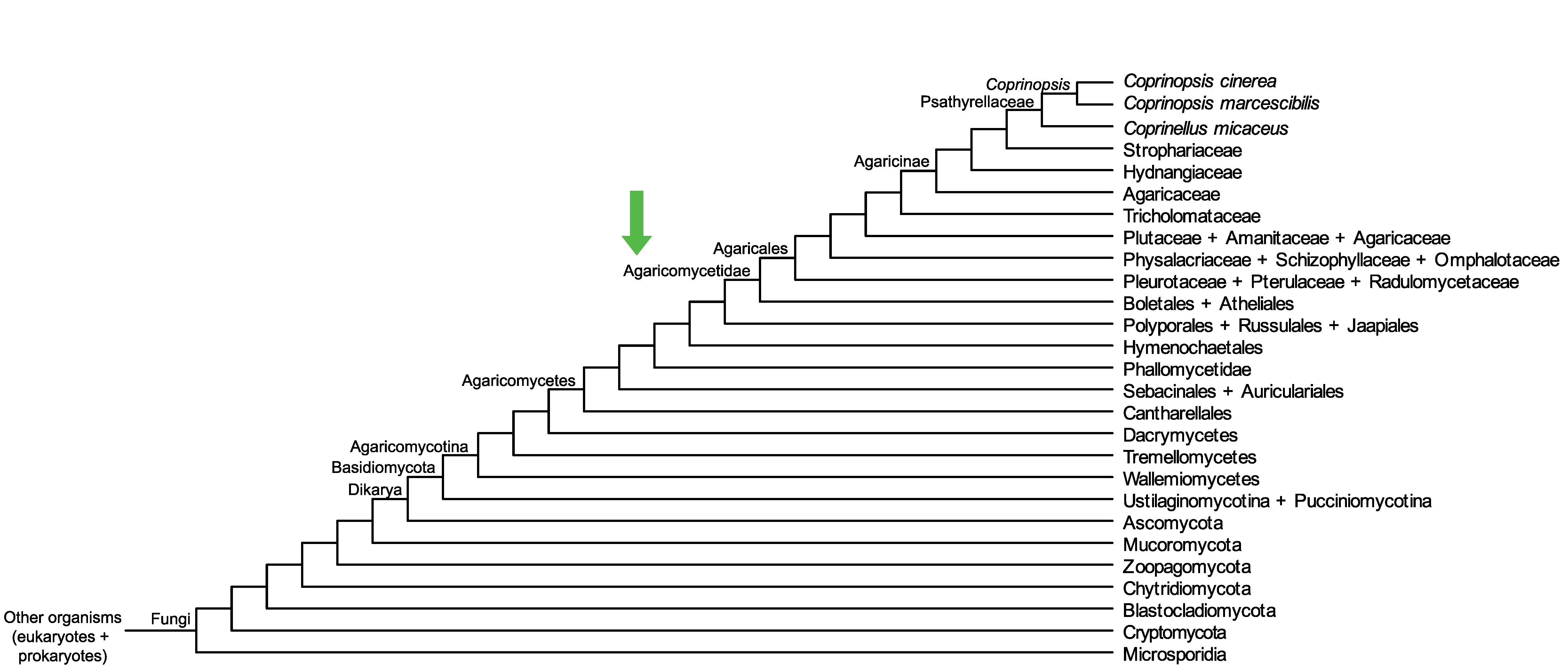
Conservation of CC1G_09141 across fungi.
Arrow shows the origin of gene family containing CC1G_09141.
Protein
| Sequence id | 7818 |
|---|---|
| Sequence |
>7818 MSTSSASTRSTSSSFSSTFSDVDDPMFSPPSSPPASSKTHAFFASSFAASPPPPRPPLSLKKSDNKPTAVKNRDD NGTNPPPAASPGLFSSAKTSRFNVSRIFPSRYARSRRDSAEQQDVQNAFSSNALRRKPDFLFIDVDGDADPNEIH HIDHRETPFKDVFLSLPTAPSYHDRAGSDSSLSPPSSISSSSSHAEIRLPTPPPPPPLLTASSNASDNEFTPRPA DLEPSIAAVQPQELSPLSPLSEDNSIPADTELHPGDVIADSSFASATSPSLRLLRPLGQGAFSAVWLAEDLSSIP LVLSSKRSVRDLKRQASLQSKGSVSRKSSLKSPTSSRGVSRNSSMKRFMARVTGTQPSVDSLLLDGHVHHEGRET TWTSPDGHLHPMPPSSMHPSPSPSSSISSLPSPEVGLGASLSRQSSTSTRRSATSRAEARVVAVKLTPRRPEPNS PLTEERTRVGFIREVEVLRHISHPNITPLLAHFSTPTYHVLVLPYLKGGDLLSLVNNDAVWGRLSESVLRRIWCE ICRAVGWMHSVGIVHRDIKLENVLLTWDGLQSYSNLISTELSSTPTESSILSIPRPTVADLPTPIVKLTDFGLSR FIDIGNGERGQGEMLNTRCGSEAYAAPELVMGGGPRGVYDGRETDAWACGVVLYALVGRKLPFGEGVGIGMDGGH GTQSHINGERVHPPGYSSRKHAVERRAWLMRIAKGEYEWPEVPSDAAAVEDGDGELVGPRLALSEGAKRVVGRLL VRDPKKRARIVDLWEDDWMRGDEIGLGMWEAIQLDRNASDRVSDGSGEVKPATNENPITVLKEDGLDDGEWEPLD EDEYLEEEDEHEGWLLDEQSISSIVRQEVV |
| Length | 855 |
Coding
| Sequence id | CC1G_09141T0 |
|---|---|
| Sequence |
>CC1G_09141T0 ATGTCCACATCCTCGGCGTCGACTCGGTCCACGTCCTCCTCATTCTCCTCTACCTTTTCAGATGTCGACGACCCA ATGTTCAGCCCGCCCTCGTCGCCCCCAGCTTCCTCAAAGACCCATGCCTTTTTTGCTTCCTCCTTCGCCGCCAGC CCGCCGCCGCCCCGCCCACCTCTCTCTTTGAAGAAGTCCGACAACAAGCCCACCGCCGTCAAGAACAGGGACGAC AATGGCACAAACCCTCCACCAGCAGCGAGCCCGGGTCTCTTCTCGTCCGCCAAAACATCGCGCTTCAATGTTTCA CGGATCTTTCCCTCAAGATATGCCCGCTCTCGCCGTGACTCTGCAGAGCAGCAAGACGTCCAGAACGCATTCTCC TCGAACGCCCTGCGCAGAAAACCCGACTTTCTCTTCATAGACGTCGACGGAGATGCAGACCCGAATGAAATACAT CACATTGACCATAGAGAGACTCCATTCAAGGACGTGTTCCTCTCTCTTCCCACAGCCCCGTCCTACCACGACCGC GCAGGATCAGACTCGTCGCTCTCCCCACCCTCGTCGATATCTTCGTCGTCTTCGCACGCAGAGATTCGGCTACCC ACCCCGCCGCCGCCCCCGCCCCTCCTAACCGCAAGTTCCAACGCCTCAGACAATGAATTCACACCCCGGCCAGCT GACCTCGAACCTTCCATAGCCGCTGTACAGCCCCAGGAACTTTCTCCCTTATCGCCTCTCAGCGAAGACAACAGT ATCCCAGCCGACACCGAATTGCACCCTGGTGATGTCATAGCCGACTCCAGTTTCGCCTCGGCTACTTCCCCGTCC CTGCGCCTCCTCCGTCCTCTCGGCCAGGGCGCCTTTTCCGCAGTATGGCTTGCAGAAGACCTGTCGTCTATACCC CTCGTTCTCTCCTCGAAGAGGAGCGTCCGTGACCTCAAGCGACAGGCGAGCCTGCAATCGAAAGGAAGTGTCTCG CGCAAGTCGAGTCTGAAAAGCCCAACGTCGAGCAGGGGTGTTTCCCGCAACTCGAGTATGAAGAGGTTCATGGCA CGCGTCACTGGCACACAGCCTTCGGTCGATAGCCTGTTGTTGGACGGCCATGTCCACCATGAAGGGCGGGAAACT ACTTGGACCAGTCCAGATGGTCACCTCCACCCCATGCCCCCGTCGTCAATGCACCCTAGTCCATCACCATCATCC TCAATATCATCTCTTCCTTCTCCCGAGGTCGGGTTGGGTGCATCGTTGTCACGCCAAAGCTCCACAAGTACACGC CGCTCGGCTACTTCTCGGGCAGAGGCCCGAGTAGTCGCGGTCAAGCTGACACCCCGGCGTCCGGAGCCAAACTCT CCTTTGACTGAAGAGAGGACCAGGGTGGGATTCATTCGTGAAGTCGAGGTACTCCGACACATCTCTCATCCCAAC ATCACGCCCTTGCTGGCCCACTTCTCCACTCCGACATATCACGTCCTCGTGCTGCCCTACCTCAAGGGCGGGGAT CTGTTGTCGCTTGTCAATAATGATGCCGTTTGGGGTAGACTGTCTGAGAGTGTGTTAAGGCGGATATGGTGTGAG ATATGCCGTGCGGTCGGGTGGATGCATAGCGTCGGAATCGTGCACCGCGACATCAAGTTGGAGAATGTCCTGTTG ACCTGGGATGGCCTCCAGTCGTATTCCAACCTCATCTCGACCGAGCTCTCGTCGACGCCTACCGAATCGTCGATA TTGTCAATACCACGACCCACCGTGGCTGATCTCCCCACCCCCATTGTCAAACTCACCGACTTTGGTCTGTCGCGG TTCATTGACATCGGCAATGGCGAACGCGGGCAGGGCGAGATGCTCAATACCCGCTGCGGATCAGAAGCCTATGCC GCACCTGAATTGGTTATGGGTGGCGGTCCACGAGGCGTTTATGACGGACGCGAAACGGATGCGTGGGCCTGTGGT GTAGTCTTGTATGCGCTTGTGGGTCGCAAGCTTCCTTTCGGTGAAGGTGTTGGAATTGGTATGGACGGTGGACAC GGCACACAGAGCCATATCAATGGCGAACGTGTCCACCCTCCTGGCTACTCTAGCCGGAAGCATGCCGTGGAGCGT CGTGCGTGGTTGATGAGGATTGCGAAGGGCGAGTACGAGTGGCCTGAAGTCCCGTCTGATGCAGCTGCGGTAGAG GATGGGGATGGGGAACTCGTTGGGCCTCGGTTGGCGTTGAGCGAGGGTGCGAAGAGGGTTGTTGGGCGGTTGTTG GTTCGTGATCCGAAGAAGAGGGCTAGGATTGTGGATCTGTGGGAGGATGACTGGATGCGCGGGGATGAGATTGGG TTGGGGATGTGGGAAGCTATCCAGCTCGATCGTAATGCCTCGGATCGTGTCTCGGATGGCTCTGGGGAGGTGAAG CCTGCGACAAACGAGAACCCCATCACCGTGCTCAAGGAGGACGGGCTCGATGATGGGGAGTGGGAGCCTCTTGAC GAAGATGAATATCTCGAAGAGGAGGATGAACATGAAGGATGGCTGTTGGATGAGCAGAGTATCTCCAGTATAGTG AGGCAAGAAGTTGTG |
| Length | 2568 |
Transcript
| Sequence id | CC1G_09141T0 |
|---|---|
| Sequence |
>CC1G_09141T0 ATGTCCACATCCTCGGCGTCGACTCGGTCCACGTCCTCCTCATTCTCCTCTACCTTTTCAGATGTCGACGACCCA ATGTTCAGCCCGCCCTCGTCGCCCCCAGCTTCCTCAAAGACCCATGCCTTTTTTGCTTCCTCCTTCGCCGCCAGC CCGCCGCCGCCCCGCCCACCTCTCTCTTTGAAGAAGTCCGACAACAAGCCCACCGCCGTCAAGAACAGGGACGAC AATGGCACAAACCCTCCACCAGCAGCGAGCCCGGGTCTCTTCTCGTCCGCCAAAACATCGCGCTTCAATGTTTCA CGGATCTTTCCCTCAAGATATGCCCGCTCTCGCCGTGACTCTGCAGAGCAGCAAGACGTCCAGAACGCATTCTCC TCGAACGCCCTGCGCAGAAAACCCGACTTTCTCTTCATAGACGTCGACGGAGATGCAGACCCGAATGAAATACAT CACATTGACCATAGAGAGACTCCATTCAAGGACGTGTTCCTCTCTCTTCCCACAGCCCCGTCCTACCACGACCGC GCAGGATCAGACTCGTCGCTCTCCCCACCCTCGTCGATATCTTCGTCGTCTTCGCACGCAGAGATTCGGCTACCC ACCCCGCCGCCGCCCCCGCCCCTCCTAACCGCAAGTTCCAACGCCTCAGACAATGAATTCACACCCCGGCCAGCT GACCTCGAACCTTCCATAGCCGCTGTACAGCCCCAGGAACTTTCTCCCTTATCGCCTCTCAGCGAAGACAACAGT ATCCCAGCCGACACCGAATTGCACCCTGGTGATGTCATAGCCGACTCCAGTTTCGCCTCGGCTACTTCCCCGTCC CTGCGCCTCCTCCGTCCTCTCGGCCAGGGCGCCTTTTCCGCAGTATGGCTTGCAGAAGACCTGTCGTCTATACCC CTCGTTCTCTCCTCGAAGAGGAGCGTCCGTGACCTCAAGCGACAGGCGAGCCTGCAATCGAAAGGAAGTGTCTCG CGCAAGTCGAGTCTGAAAAGCCCAACGTCGAGCAGGGGTGTTTCCCGCAACTCGAGTATGAAGAGGTTCATGGCA CGCGTCACTGGCACACAGCCTTCGGTCGATAGCCTGTTGTTGGACGGCCATGTCCACCATGAAGGGCGGGAAACT ACTTGGACCAGTCCAGATGGTCACCTCCACCCCATGCCCCCGTCGTCAATGCACCCTAGTCCATCACCATCATCC TCAATATCATCTCTTCCTTCTCCCGAGGTCGGGTTGGGTGCATCGTTGTCACGCCAAAGCTCCACAAGTACACGC CGCTCGGCTACTTCTCGGGCAGAGGCCCGAGTAGTCGCGGTCAAGCTGACACCCCGGCGTCCGGAGCCAAACTCT CCTTTGACTGAAGAGAGGACCAGGGTGGGATTCATTCGTGAAGTCGAGGTACTCCGACACATCTCTCATCCCAAC ATCACGCCCTTGCTGGCCCACTTCTCCACTCCGACATATCACGTCCTCGTGCTGCCCTACCTCAAGGGCGGGGAT CTGTTGTCGCTTGTCAATAATGATGCCGTTTGGGGTAGACTGTCTGAGAGTGTGTTAAGGCGGATATGGTGTGAG ATATGCCGTGCGGTCGGGTGGATGCATAGCGTCGGAATCGTGCACCGCGACATCAAGTTGGAGAATGTCCTGTTG ACCTGGGATGGCCTCCAGTCGTATTCCAACCTCATCTCGACCGAGCTCTCGTCGACGCCTACCGAATCGTCGATA TTGTCAATACCACGACCCACCGTGGCTGATCTCCCCACCCCCATTGTCAAACTCACCGACTTTGGTCTGTCGCGG TTCATTGACATCGGCAATGGCGAACGCGGGCAGGGCGAGATGCTCAATACCCGCTGCGGATCAGAAGCCTATGCC GCACCTGAATTGGTTATGGGTGGCGGTCCACGAGGCGTTTATGACGGACGCGAAACGGATGCGTGGGCCTGTGGT GTAGTCTTGTATGCGCTTGTGGGTCGCAAGCTTCCTTTCGGTGAAGGTGTTGGAATTGGTATGGACGGTGGACAC GGCACACAGAGCCATATCAATGGCGAACGTGTCCACCCTCCTGGCTACTCTAGCCGGAAGCATGCCGTGGAGCGT CGTGCGTGGTTGATGAGGATTGCGAAGGGCGAGTACGAGTGGCCTGAAGTCCCGTCTGATGCAGCTGCGGTAGAG GATGGGGATGGGGAACTCGTTGGGCCTCGGTTGGCGTTGAGCGAGGGTGCGAAGAGGGTTGTTGGGCGGTTGTTG GTTCGTGATCCGAAGAAGAGGGCTAGGATTGTGGATCTGTGGGAGGATGACTGGATGCGCGGGGATGAGATTGGG TTGGGGATGTGGGAAGCTATCCAGCTCGATCGTAATGCCTCGGATCGTGTCTCGGATGGCTCTGGGGAGGTGAAG CCTGCGACAAACGAGAACCCCATCACCGTGCTCAAGGAGGACGGGCTCGATGATGGGGAGTGGGAGCCTCTTGAC GAAGATGAATATCTCGAAGAGGAGGATGAACATGAAGGATGGCTGTTGGATGAGCAGAGTATCTCCAGTATAGTG AGGCAAGAAGTTGTGTAG |
| Length | 2568 |
Gene
| Sequence id | CC1G_09141T0 |
|---|---|
| Sequence |
>CC1G_09141T0 ATGTCCACATCCTCGGCGTCGACTCGGTCCACGTCCTCCTCATTCTCCTCTACCTTTTCAGATGTCGACGACCCA ATGTTCAGCCCGCCCTCGTCGCCCCCAGCTTCCTCAAAGACCCATGCCTTTTTTGCTTCCTCCTTCGCCGCCAGC CCGCCGCCGCCCCGCCCACCTCTCTCTTTGAAGAAGTCCGACAACAAGCCCACCGCCGTCAAGAACAGGGACGAC AATGGCACAAACCCTCCACCAGCAGCGAGCCCGGGTCTCTTCTCGTCCGCCAAAACATCGCGCTTCAATGTTTCA CGGATCTTTCCCTCAAGATATGCCCGCTCTCGCCGTGACTCTGCAGAGCAGCAAGACGTCCAGAACGCATTCTCC TCGAACGCCCTGCGCAGAAAACCCGACTTTCTCTTCATAGACGTCGACGGAGATGCAGACCCGAATGAAATACAT CACATTGACCATAGAGAGACTCCATTCAAGGACGTGTTCCTCTCTCTTCCCACAGCCCCGTCCTACCACGACCGC GCAGGATCAGACTCGTCGCTCTCCCCACCCTCGTCGATATCTTCGTCGTCTTCGCACGCAGAGATTCGGCTACCC ACCCCGCCGCCGCCCCCGCCCCTCCTAACCGCAAGTTCCAACGCCTCAGACAATGAATTCACACCCCGGCCAGCT GACCTCGAACCTTCCATAGCCGCTGTACAGCCCCAGGAACTTTCTCCCTTATCGCCTCTCAGCGAAGACAACAGT ATCCCAGCCGACACCGAATTGCACCCTGGTGATGTCATAGCCGACTCCAGTTTCGCCTCGGCTACTTCCCCGTCC CTGCGCCTCCTCCGTCCTCTCGGCCAGGGCGCCTTTTCCGCAGTATGGCTTGCAGAAGACCTGTCGTCTATACCC CTCGTTCTCTCCTCGAAGAGGAGCGTCCGTGACCTCAAGCGACAGGCGAGCCTGCAATCGAAAGGAAGTGTCTCG CGCAAGTCGAGTCTGAAAAGCCCAACGTCGAGCAGGGGTGTTTCCCGCAACTCGAGTATGAAGAGGTTCATGGCA CGCGTCACTGGCACACAGCCTTCGGTCGATAGCCTGTTGTTGGACGGCCATGTCCACCATGAAGGGCGGGAAACT ACTTGGACCAGTCCAGATGGTCACCTCCACCCCATGCCCCCGTCGTCAATGCACCCTAGTCCATCACCATCATCC TCAATATCATCTCTTCCTTCTCCCGAGGTCGGGTTGGGTGCATCGTTGTCACGCCAAAGCTCCACAAGTACACGC CGCTCGGCTACTTCTCGGGCAGAGGCCCGAGTAGTCGCGGTCAAGCTGACACCCCGGCGTCCGGAGCCAAACTCT CCTTTGACTGAAGAGAGGACCAGGGTGGGATTCATTCGTGAAGTCGAGGTACTCCGACACATCTCTCATCCCAAC ATCACGCCCTTGCTGGCCCACTTCTCCACTCCGACATATCACGTCCTCGTGCTGCCCTACCTCAAGGGCGGGGAT CTGTTGTCGCTTGTCAATAATGATGCCGTTTGGGGTAGACTGTCTGAGAGTGTGTTAAGGCGGATATGGTGTGAG ATATGCCGTGCGGTCGGGTGGATGCATAGCGTCGGAATCGTGCACCGCGACATCAAGTTGGAGAATGTCCTGTTG ACCTGGGATGGCCTCCAGTCGTATTCCAACCTCATCTCGACCGAGCTCTCGTCGACGCCTACCGAATCGTCGATA TTGTCAATACCACGACCCACCGTGGCTGATCTCCCCACCCCCATTGTCAAACTCACCGACTTTGGTCTGTCGCGG TTCATTGACATCGGCAATGGCGAACGCGGGCAGGGCGAGATGCTCAATACCCGCTGCGGATCAGAAGCCTATGCC GCACCTGAATTGGTTATGGGTGGCGGTCCACGAGGCGTTTATGACGGACGCGAAACGGATGCGTGGGCCTGTGGT GTAGTCTTGTATGCGCTTGTGGGTCGCAAGCTTCCTTTCGGTGAAGGTGTTGGAATTGGTATGGACGGTGGACAC GGCACACAGAGCCATATCAATGGCGAACGTGTCCACCCTCCTGGCTACTCTAGCCGGAAGCATGCCGTGGAGCGT CGTGCGTGGTTGATGAGGATTGCGAAGGGCGAGTACGAGTGGCCTGAAGTCCCGTCTGATGCAGCTGCGGTAGAG GATGGGGATGGGGAACTCGTTGGGCCTCGGTTGGCGTTGAGCGAGGGTGCGAAGAGGGTTGTTGGGCGGTTGTTG GTTCGTGATCCGAAGAAGAGGGCTAGGATTGTGGATCTGTGGGAGGATGACTGGATGCGCGGGGATGAGATTGGG TTGGGGATGTGGGAAGCTATCCAGCTCGATCGTAATGCCTCGGATCGTGTCTCGGATGGCTCTGGGGAGGTGAAG CCTGCGACAAACGAGAACCCCATCACCGTGCTCAAGGAGGACGGGCTCGATGATGGGGAGTGGGAGCCTCTTGAC GAAGATGAATATCTCGAAGAGGAGGATGAACATGAAGGATGGCTGTTGGATGAGCAGAGTATCTCCAGTATAGTG AGGCAAGAAGTTGTGTAG |
| Length | 2568 |