CC1G_09146
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09146 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P9Q2 | Functional description | Beta-glucosidase |
| Location | Chr_2:2769053..2772325 | Strand | + |
| Gene length (nt) | 3273 | Transcript length (nt) | 2328 |
| CDS length (nt) | 2328 | Protein length (aa) | 775 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB26964 | 74.4 | 0 | 1118 |
| Agrocybe aegerita | Agrae_CAA7265302 | 71.4 | 0 | 1100 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_217305 | 68 | 0 | 1051 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_69320 | 68 | 0 | 1051 |
| Flammulina velutipes | Flave_chr11AA01097 | 64 | 2.658E-304 | 985 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1398709 | 66 | 1.39E-304 | 957 |
| Pleurotus ostreatus PC9 | PleosPC9_1_61232 | 65.5 | 6.744E-304 | 949 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1034680 | 65.2 | 8.169E-304 | 943 |
| Schizophyllum commune H4-8 | Schco3_2538080 | 61 | 3.668E-300 | 927 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_20658 | 61.3 | 9.164E-292 | 917 |
| Lentinula edodes NBRC 111202 | Lenedo1_1166622 | 61.1 | 1.005E-295 | 914 |
| Auricularia subglabra | Aurde3_1_1406150 | 51.7 | 3.599E-237 | 745 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 7822 |
| Description | Beta-glucosidase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00933 | Glycosyl hydrolase family 3 N terminal domain | IPR001764 | 93 | 258 |
| Pfam | PF01915 | Glycosyl hydrolase family 3 C-terminal domain | IPR002772 | 401 | 662 |
| Pfam | PF14310 | Fibronectin type III-like domain | IPR026891 | 697 | 764 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017853 | Glycoside hydrolase superfamily |
| IPR001764 | Glycoside hydrolase, family 3, N-terminal |
| IPR002772 | Glycoside hydrolase family 3 C-terminal domain |
| IPR013783 | Immunoglobulin-like fold |
| IPR026891 | Fibronectin type III-like domain |
| IPR036962 | Glycoside hydrolase, family 3, N-terminal domain superfamily |
| IPR036881 | Glycoside hydrolase family 3 C-terminal domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0005975 | carbohydrate metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| K05349 |
EggNOG
| COG category | Description |
|---|---|
| G | Glycoside hydrolase family 3 protein |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH3 |
Transcription factor
| Group |
|---|
| No records |
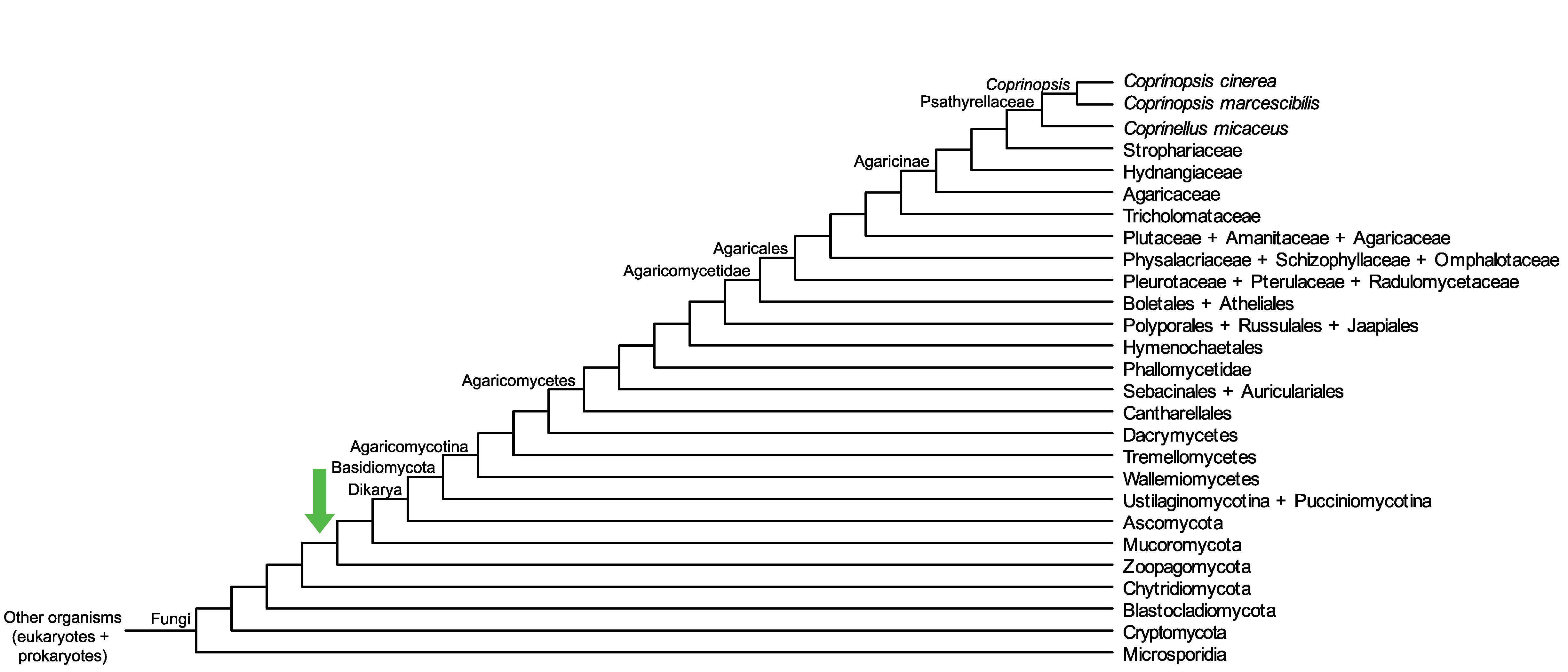
Conservation of CC1G_09146 across fungi.
Arrow shows the origin of gene family containing CC1G_09146.
Protein
| Sequence id | 7822 |
|---|---|
| Sequence |
>7822 MRGTRNISMGQRRKPVFDARTTGNSTDDDKIVAYLDACLPALPRDTIMRSSFSLLVLLAILQGTVARRTWDEAYD LANNVVSQMTLDEKLGIVRGTGQLNPNRRCVGDTKAVPRLGIPSICFADGPAGMRLVKETTGFPTGINAAATFSR RLMRERGEALGREFRGKGSHVFLGPSVDVMRNPKGGRAWEAFGPDPYLNGEGAYETIMGVQSVGVQACIKHLIGN TQEHWRYGYSANMDDRTLHEMYFYPFLRSIEASREPRRRLVRHNAGLLGDNGILRKAGFKGYVVSDWGATHDSAE VNANNGLDMEQPGDYIVVGGGVFGGLKDAVNKGRVSQRRLNEMVARILAPWYYLEQDSPDYPETNFDVQRRDGSG PKNLRVNVRSEEHTALAREIASASSVLLKNARSTTDGTPSGITTRGLPLSKDRIKSIAVIGQDARQLNQNCSEMG ECNDGTMVVGWGSGSINFDHVVPPIDAIKSFTSDTATITESLTNNLDDGVRAARGKDAALVFVNAASGELAFYTV VHGNMGDRNDLDLWWRGGSLIERVAAVNNNTIVVVHSVGPVYMPWSTHPNITGIIYAGAPGEQTGPSIVDILYGN YNPSGKLPFSIADNEAAYGTTIVYNSLGFPDIDFTEKLLLDYRYMDEKNIRPRFEFGFGLSYTTFGYSNLAITRD GPGFQVSFTVANTGAFAGAEKPQLYLAYPPNAGQPKKVLRGFEEAILEVGASTRVTINLSERDMSVWDVPSQSYV RLPGVYTIYVGASSLDTRLQGTVTI |
| Length | 775 |
Coding
| Sequence id | CC1G_09146T0 |
|---|---|
| Sequence |
>CC1G_09146T0 ATGCGGGGTACCAGGAACATCTCGATGGGCCAACGACGAAAGCCCGTGTTTGACGCCCGAACTACGGGAAACTCC ACAGACGATGACAAGATAGTCGCATATTTGGATGCCTGCCTTCCAGCTCTTCCTCGGGACACCATCATGCGTTCT TCCTTCTCATTACTTGTGTTGCTCGCCATTCTCCAGGGCACTGTAGCCAGGAGAACATGGGACGAAGCTTATGAC CTAGCCAACAATGTGGTGAGCCAGATGACCTTGGACGAGAAGTTGGGAATCGTCAGGGGCACAGGCCAACTCAAC CCTAACCGTCGTTGTGTTGGTGATACCAAGGCTGTTCCCCGACTGGGCATCCCGTCAATCTGTTTCGCAGATGGC CCCGCAGGAATGCGTCTCGTAAAAGAGACGACCGGCTTCCCTACTGGCATTAACGCCGCAGCAACCTTCAGTCGT CGCCTCATGAGAGAGCGTGGTGAGGCTTTGGGTCGGGAGTTCCGAGGCAAAGGATCACACGTATTCTTGGGCCCA TCCGTGGACGTTATGAGGAACCCCAAGGGAGGCCGTGCTTGGGAAGCCTTTGGTCCTGATCCTTATCTGAACGGA GAAGGCGCTTATGAGACTATCATGGGCGTCCAGAGCGTTGGAGTTCAAGCCTGCATCAAGCACCTCATCGGCAAT ACCCAGGAGCACTGGAGATATGGTTACAGCGCCAACATGGACGACAGAACACTTCACGAGATGTACTTTTATCCA TTCCTTCGAAGTATTGAGGCAAGCAGGGAACCTCGCCGACGTCTCGTCCGTCATAATGCGGGTCTTTTGGGCGAT AATGGTATTTTGCGCAAGGCGGGTTTCAAGGGATACGTCGTCAGCGATTGGGGTGCAACGCACGATTCTGCAGAA GTGAACGCGAACAATGGTTTGGACATGGAGCAACCCGGCGATTACATCGTGGTCGGAGGAGGCGTCTTTGGTGGG CTCAAGGACGCAGTCAACAAGGGACGGGTTTCCCAGAGACGTCTCAACGAAATGGTCGCGCGAATTCTTGCTCCT TGGTACTACCTCGAACAAGATTCTCCTGACTATCCTGAGACCAATTTTGACGTTCAACGACGCGATGGATCTGGC CCCAAGAACCTTCGGGTCAACGTTCGCTCCGAAGAACACACCGCCCTCGCCAGGGAGATTGCCTCTGCTTCTTCA GTCCTGTTGAAGAACGCCCGCTCCACCACCGACGGTACCCCTTCCGGAATCACTACGCGCGGCTTGCCACTCTCT AAAGACAGAATCAAGTCGATCGCTGTCATTGGTCAAGATGCCCGTCAGCTGAACCAGAATTGTTCGGAAATGGGT GAATGTAACGATGGCACCATGGTCGTTGGCTGGGGTTCTGGCTCTATCAACTTTGATCATGTCGTCCCTCCCATC GACGCCATCAAGTCTTTCACCAGTGACACTGCTACCATCACTGAGTCTCTAACGAACAACTTGGATGACGGTGTG CGGGCTGCGCGAGGCAAGGATGCTGCTCTTGTCTTTGTGAACGCAGCGAGCGGTGAACTTGCCTTCTACACCGTC GTCCACGGAAACATGGGTGACAGGAATGACCTTGACCTTTGGTGGAGGGGTGGTAGCTTGATCGAGCGTGTAGCT GCTGTCAACAACAACACTATCGTCGTCGTTCATTCTGTTGGACCCGTCTACATGCCCTGGAGCACCCATCCTAAT ATCACTGGTATCATTTACGCTGGCGCCCCTGGAGAGCAGACTGGACCTTCGATCGTCGACATCCTCTACGGAAAC TACAACCCCAGTGGCAAGCTTCCTTTCAGCATTGCCGATAACGAAGCTGCATACGGAACGACCATCGTTTACAAC AGCCTTGGCTTCCCGGACATCGACTTCACTGAGAAGCTCCTCCTCGACTACCGATACATGGATGAGAAGAACATC CGCCCACGCTTCGAATTCGGTTTCGGTCTCTCCTACACCACCTTTGGATACTCCAACCTCGCTATCACTCGTGAT GGCCCAGGATTCCAGGTTTCGTTCACTGTGGCCAACACTGGCGCATTTGCTGGTGCTGAGAAGCCTCAACTCTAT CTTGCTTACCCTCCCAATGCTGGCCAGCCTAAGAAGGTTTTGCGTGGATTCGAAGAGGCTATTTTGGAGGTTGGT GCTAGCACCCGTGTCACTATCAACCTTAGCGAGCGCGATATGAGCGTTTGGGATGTTCCCAGCCAAAGCTATGTC CGCCTCCCGGGTGTTTACACGATCTACGTGGGTGCCTCGTCGCTCGATACCCGTCTGCAAGGAACCGTCACTATC |
| Length | 2328 |
Transcript
| Sequence id | CC1G_09146T0 |
|---|---|
| Sequence |
>CC1G_09146T0 ATGCGGGGTACCAGGAACATCTCGATGGGCCAACGACGAAAGCCCGTGTTTGACGCCCGAACTACGGGAAACTCC ACAGACGATGACAAGATAGTCGCATATTTGGATGCCTGCCTTCCAGCTCTTCCTCGGGACACCATCATGCGTTCT TCCTTCTCATTACTTGTGTTGCTCGCCATTCTCCAGGGCACTGTAGCCAGGAGAACATGGGACGAAGCTTATGAC CTAGCCAACAATGTGGTGAGCCAGATGACCTTGGACGAGAAGTTGGGAATCGTCAGGGGCACAGGCCAACTCAAC CCTAACCGTCGTTGTGTTGGTGATACCAAGGCTGTTCCCCGACTGGGCATCCCGTCAATCTGTTTCGCAGATGGC CCCGCAGGAATGCGTCTCGTAAAAGAGACGACCGGCTTCCCTACTGGCATTAACGCCGCAGCAACCTTCAGTCGT CGCCTCATGAGAGAGCGTGGTGAGGCTTTGGGTCGGGAGTTCCGAGGCAAAGGATCACACGTATTCTTGGGCCCA TCCGTGGACGTTATGAGGAACCCCAAGGGAGGCCGTGCTTGGGAAGCCTTTGGTCCTGATCCTTATCTGAACGGA GAAGGCGCTTATGAGACTATCATGGGCGTCCAGAGCGTTGGAGTTCAAGCCTGCATCAAGCACCTCATCGGCAAT ACCCAGGAGCACTGGAGATATGGTTACAGCGCCAACATGGACGACAGAACACTTCACGAGATGTACTTTTATCCA TTCCTTCGAAGTATTGAGGCAAGCAGGGAACCTCGCCGACGTCTCGTCCGTCATAATGCGGGTCTTTTGGGCGAT AATGGTATTTTGCGCAAGGCGGGTTTCAAGGGATACGTCGTCAGCGATTGGGGTGCAACGCACGATTCTGCAGAA GTGAACGCGAACAATGGTTTGGACATGGAGCAACCCGGCGATTACATCGTGGTCGGAGGAGGCGTCTTTGGTGGG CTCAAGGACGCAGTCAACAAGGGACGGGTTTCCCAGAGACGTCTCAACGAAATGGTCGCGCGAATTCTTGCTCCT TGGTACTACCTCGAACAAGATTCTCCTGACTATCCTGAGACCAATTTTGACGTTCAACGACGCGATGGATCTGGC CCCAAGAACCTTCGGGTCAACGTTCGCTCCGAAGAACACACCGCCCTCGCCAGGGAGATTGCCTCTGCTTCTTCA GTCCTGTTGAAGAACGCCCGCTCCACCACCGACGGTACCCCTTCCGGAATCACTACGCGCGGCTTGCCACTCTCT AAAGACAGAATCAAGTCGATCGCTGTCATTGGTCAAGATGCCCGTCAGCTGAACCAGAATTGTTCGGAAATGGGT GAATGTAACGATGGCACCATGGTCGTTGGCTGGGGTTCTGGCTCTATCAACTTTGATCATGTCGTCCCTCCCATC GACGCCATCAAGTCTTTCACCAGTGACACTGCTACCATCACTGAGTCTCTAACGAACAACTTGGATGACGGTGTG CGGGCTGCGCGAGGCAAGGATGCTGCTCTTGTCTTTGTGAACGCAGCGAGCGGTGAACTTGCCTTCTACACCGTC GTCCACGGAAACATGGGTGACAGGAATGACCTTGACCTTTGGTGGAGGGGTGGTAGCTTGATCGAGCGTGTAGCT GCTGTCAACAACAACACTATCGTCGTCGTTCATTCTGTTGGACCCGTCTACATGCCCTGGAGCACCCATCCTAAT ATCACTGGTATCATTTACGCTGGCGCCCCTGGAGAGCAGACTGGACCTTCGATCGTCGACATCCTCTACGGAAAC TACAACCCCAGTGGCAAGCTTCCTTTCAGCATTGCCGATAACGAAGCTGCATACGGAACGACCATCGTTTACAAC AGCCTTGGCTTCCCGGACATCGACTTCACTGAGAAGCTCCTCCTCGACTACCGATACATGGATGAGAAGAACATC CGCCCACGCTTCGAATTCGGTTTCGGTCTCTCCTACACCACCTTTGGATACTCCAACCTCGCTATCACTCGTGAT GGCCCAGGATTCCAGGTTTCGTTCACTGTGGCCAACACTGGCGCATTTGCTGGTGCTGAGAAGCCTCAACTCTAT CTTGCTTACCCTCCCAATGCTGGCCAGCCTAAGAAGGTTTTGCGTGGATTCGAAGAGGCTATTTTGGAGGTTGGT GCTAGCACCCGTGTCACTATCAACCTTAGCGAGCGCGATATGAGCGTTTGGGATGTTCCCAGCCAAAGCTATGTC CGCCTCCCGGGTGTTTACACGATCTACGTGGGTGCCTCGTCGCTCGATACCCGTCTGCAAGGAACCGTCACTATC TAA |
| Length | 2328 |
Gene
| Sequence id | CC1G_09146T0 |
|---|---|
| Sequence |
>CC1G_09146T0 ATGCGGGGTACCAGGAACATCTCGATGGGCCAACGACGAAAGCCCGTGTTTGACGCCCGAACTGTAAGGGCTTTC ACCGCTCAGCTATCTAACAAACAATGTAGAACTAATACACAACAGAGCTTATAATAGACGGGAAACTCCACAGAC GATGACAAGATAGTCGTAAGGTGAACGGAGCATCACGTCGTTGAAGGTTCTGCGACAGATGCAAGCACAAAAGCG GCTCACATGGGTGCTTCTGCCCAGCTACGGAATCTGATCAACCTCCGTCCGTTGGCACTGGTCTGACCACACGGC TCAGGGCTATAAAGGCATATTTGGATGCCTGCCTTCCAGCTCTTCCTCGGGACACCATCATGCGTTCTTCCTTCT CATTACTTGTGTTGCTCGCCATTCTCCAGGGCACTGTAGCCAGGAGTACGCTTTTCTGAATCCACAGTACGTTGT CTTATGCTAACGCCGTCTGTAGGAACATGGGACGAAGCTTATGACCTAGCCAACAATGTGGTGAGCCAGATGACC TTGGACGAGAAGTTGGGAATCGTCAGGGGCACAGGCCAACTCAACCCTAACCGTACGCCGGTCTCTGCAATGTCC AGGATCTGCCACTCACGCTGTTAACAGGTCGTTGTGTTGGTGATACCAAGGCTGTTCCCCGACTGGGCATCCCGT CAATCTGTTTCGCAGATGGCCCCGCAGGAATGCGTCTCGTAAAAGAGACGACCGGCTTCCCTACTGGCATTAACG CCGCAGCAACCTTCAGTCGTCGCCTCATGAGAGAGCGTGGTGAGGCTTTGGGTCGGGAGTTCCGAGGCAAAGGAT CACAGTGAGTTCGCCTGCGCATTTGTGGATTCCCACTCGGCTCATACTTCCCGCCGCAGCGTATTCTTGGGCCCA TCCGTGGACGTTGTAAGTGGCTGCCCTGTAATTTGACCACTGGTACCCTCAATGTCGTGCATCTAGATGAGGAAC CCCAAGGGAGGCCGTGCTTGGGAAGCGTACGTTCATCCTTTCACTCTAAATATAGCCCTTCGTCTAAATCCTCGT GTGCAGCTTTGGTCCTGATCCTTATCTGAACGGAGAAGGCGCTTATGAGACTATCATGGGCGTCCAGAGCGTTGG AGTTCAAGCCTGCATCAAGCACCTCATCGGCAATACCCAGGAGCACTGGAGATATGGTTACAGCGCCAACATGGA CGACAGAACACTTCACGAGATGTACTTTTATCCATTCCTTCGAAGTATTGAGGCAAGCAGGGAACCTCGTCTGGT CAAGGCAACTGGTGTTAACTAACTGATTATTTGTAGGCCGACGTCTCGTCCGTCATGTGCGCTTACAATCGCTTC AACGGCACCTCTTCGTGCCAGAATGCGGGTCTTTTGGGCGATAATGGTATTTTGCGCAAGGCGGGTTTCAAGGGA TACGTCGTCAGCGATTGGGGTGCAACGCACGATTCTGCAGAAGTGAACGCGAACAATGGTTTGGACATGGAGCAA CCCGGCGATTACATCGTGGTCGGAGGAGGCGTCTTTGGTGGGCTCAAGGACGCAGTCAACAAGGGACGGGTTTCC CAGAGAGTAAGTGGCATGACCTCCTCTGACCGGCTTGTTACTAACCTATTTTCAGCGTCTCAACGAAATGGTCGC GCGAATTCTTGCTCCTTGGTACTACCTCGAACAAGATTCTCCTGTAAGTAATGGATTGGCCAACCTTCTTCAATG GACTTGAAGCTCAATTTACGCCTGTAGGACTATCCTGAGACCAATTTTGACGTTCAACGACGCGATGGATCTGGC CCCAAGAACCTTCGGGTCAACGTTCGCTCCGAAGAACACACCGCCCTCGCCAGGGAGATTGCCTCTGCTTCTTCA GTCCTGTTGAAGAACGCCCGCTCCACCACCGACGGTACCCCTTCCGGAATCACTACGCGCGGCTTGCCACTCTCT AAAGACAGAATCAAGTCGATCGCTGTCATTGGTCAAGATGCCCGTCAGCTGAACCAGAATTGTTCGGAAATGGGT GAATGTAACGATGGCACCATGGTCGTTGGGTATGTAGGAATCTCCATTCTGTCGAGCAATTCGTTGACACTCATA CTTAGCTGGGGTTCTGGCTCTATCAACTTTGATCATGTCGTCCCTCCCATCGACGCCATCAAGTCTTTCACCAGT GACACTGCTACCATCACTGAGTCTCTAACGAACAACTTGGATGACGGTGTGCGGGCTGCGCGAGGCAAGGATGCT GCTCTTGTCTTTGTGAACGCGTAAGTTGCACCTCACAGATGTAGTGAAACCAGCTGACAGGGCCCCTCAGAGCGA GCGGTGAACTTGCCTTCTACACCGTCGTCCACGGAAACATGGGTGACAGGAATGACCTTGACCTTTGGTGGAGGG GTGGTAGCTTGGTTAGTTTAATTTTGCTGTTCGTCCCAAGCTAATACTAAACTCACACTGGTGTAGATCGAGCGT GTAGCTGCTGTCAACAACAACACTATCGTCGTCGTTCATTCTGTTGGACCCGTCTACATGCCCTGGAGCACCCAT CCTAATATCACTGGTATCATTTACGCTGGCGCCCCTGGAGAGCAGACTGGACCTTCGATCGTCGACATCCTCTAC GGAAACTACAACCCCAGTGGCAAGCTTCCTTTCAGCATTGCCGATGTACGTCGCTTCCCTCTCGCTGCTTTGACC TTTGACTAAAGATGGTTTCTTTCACAGAACGAAGCTGCATACGGAACGACCATCGTTTACAACAGCCTTGGCTTC CCGGACATCGACTTCACTGAGAAGCTCCTCCTCGACTACCGATACATGGATGAGAAGAACATCCGCCCACGCTTC GAATTCGGTTTCGGTCTCTCCTACACCACCTTTGGATACTCCAACCTCGCTATCACTCGTGATGGCCCAGGATTC CAGGTTTCGTTCACTGTGGCCAACACTGGCGCATTTGCTGGTGCTGAGAAGCCTCAACTCTATCTTGCTTACCCT CCCAATGCTGGCCAGCCTAAGAAGGTTTTGCGTGGATTCGAAGAGGCTATTTTGGAGGTTGGTGCTAGCACCCGT GTCACTATCAACCTTAGCGAGCGCGATATGAGGTGCGTTCTTCGTGTTGCTTTTAGAGATGATCCGGAAGTTGAT GGCATCCTTTGTAGCGTTTGGGATGTTCCCAGCCAAAGCTATGTCCGCCTCCCGGGTGTTTACACGATCTACGTG GGTGCCTCGTCGCTCGATACCCGTCTGCAAGGAACCGTCACTATCTAA |
| Length | 3273 |