CC1G_09195
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09195 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P9X2 | Functional description | Cytoplasmic protein |
| Location | Chr_2:2880278..2883652 | Strand | + |
| Gene length (nt) | 3375 | Transcript length (nt) | 3327 |
| CDS length (nt) | 3327 | Protein length (aa) | 1108 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Neurospora crassa | NCU02233 |
| Saccharomyces cerevisiae | YIR007W_YIR007W |
| Aspergillus nidulans | AN3013 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7260938 | 48.4 | 0 | 1122 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB19404 | 54.6 | 0 | 1082 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1056414 | 53.9 | 0 | 1073 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1444949 | 53.6 | 0 | 1065 |
| Flammulina velutipes | Flave_chr09AA00385 | 50.9 | 0 | 1050 |
| Pleurotus ostreatus PC9 | PleosPC9_1_115324 | 53 | 0 | 1048 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_15215 | 52.4 | 0 | 1044 |
| Lentinula edodes NBRC 111202 | Lenedo1_463385 | 52.1 | 0 | 1037 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_94718 | 47.9 | 2.175E-291 | 955 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_122667 | 49.2 | 3.224E-295 | 931 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_188502 | 49.1 | 3.32E-294 | 928 |
| Grifola frondosa | Grifr_OBZ75321 | 48.8 | 9.731E-293 | 924 |
| Schizophyllum commune H4-8 | Schco3_2603975 | 48.6 | 5.303E-282 | 893 |
| Auricularia subglabra | Aurde3_1_1274844 | 46.7 | 1.695E-269 | 857 |
| Lentinula edodes B17 | Lened_B_1_1_205 | 76.5 | 5.253E-69 | 256 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 7863 |
| Description | Cytoplasmic protein |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 88 | 278 |
| Pfam | PF18564 | Glycoside hydrolase family 5 C-terminal domain | IPR041036 | 758 | 825 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR041036 | Glycoside hydrolase family 5, C-terminal domain |
| IPR001547 | Glycoside hydrolase, family 5 |
| IPR018087 | Glycoside hydrolase, family 5, conserved site |
| IPR017853 | Glycoside hydrolase superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
| GO:0005975 | carbohydrate metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| E | Cellulase (glycosyl hydrolase family 5) |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_12 |
Transcription factor
| Group |
|---|
| No records |
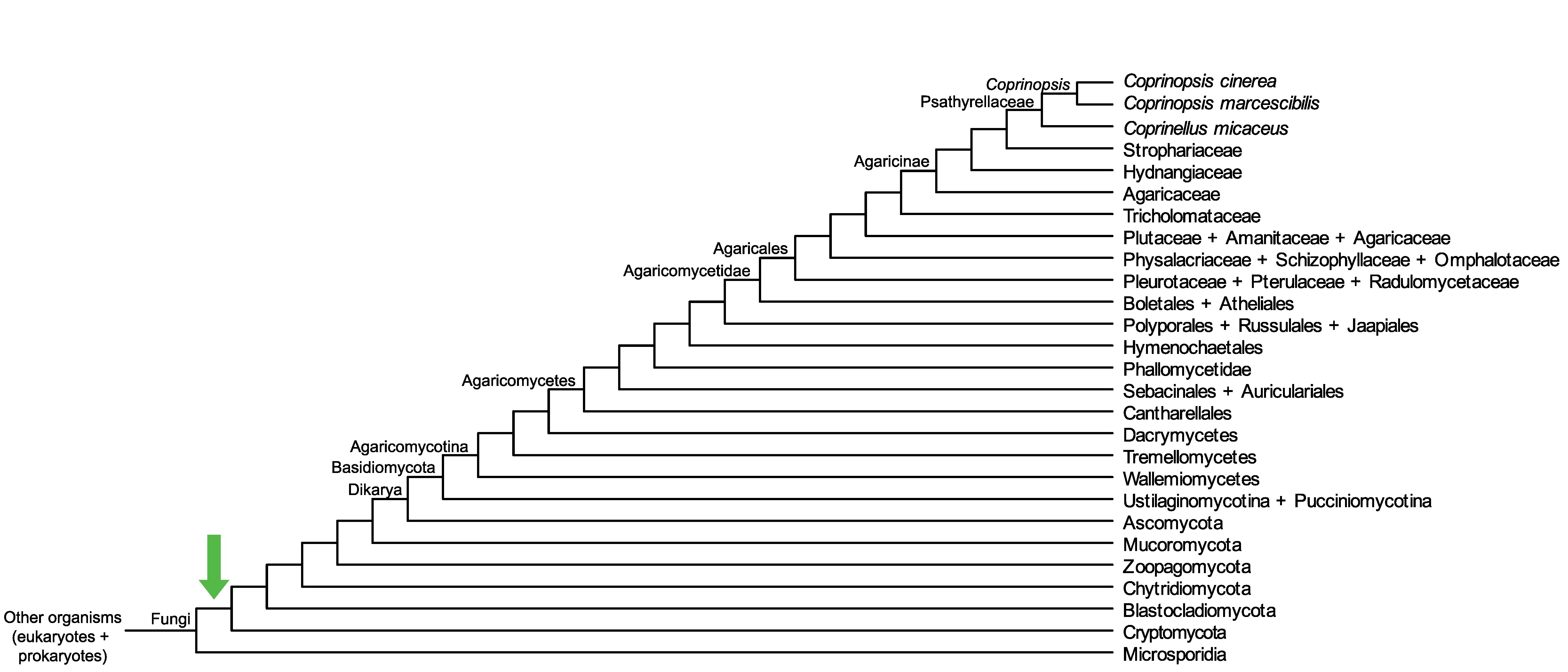
Conservation of CC1G_09195 across fungi.
Arrow shows the origin of gene family containing CC1G_09195.
Protein
| Sequence id | 7863 |
|---|---|
| Sequence |
>7863 MPRVPSTSPATGQPVPPSYIHTFNYNFVDTSGRTLLLRGVNLSGASKAPVGHLSHQLDDFWDSAEAGGESFIRRP LNLDDGSADVHLARLRGWGFNMLRFPITWEALEHEGPGKYDDEFIDYTIRVLQKCRDYGFRVFMDPHQDTWSRFS GGSGAPFWTLAACGINPNNITATQSAIVHCEYPLAHAPDPASLPAMIWSTNYGRLLSQTLFTLFFAGRTFAPLCV IDDLNIQDYLQNHYIEAFGRLADRIREIDPSLYDNCIIGWDSLNEPFEGLCGWENLNANPTAQGSTLKKGTYPTP AQSLRLGMGQPQTVENWSFGAFGPSRNGSVTIDPKGHKLWAEDSPDARWGFKRAESWPLGTCIWALHNVWDIQTG YVLRPDYFKFHPETQEEVSFISDFWKPHFLAYSSRLRKSHPEAIWFVQPPVFAKPPQIATDDLRGRACYSPHYYD GLTLITRHWNWFNADALGVLRGKYSSPIQAVKIGESAIRASIQSQLGILKSDALILGDYPTLIGEIGIPFDMDDK RSYGWTDKGKYKGDYSRQVKALDASLNACDGPNGLNFTVWTFCPDDHSHEWGDGWNLEDLSLWSMADVWERERVE KEAMMVDEEDRKSVGTVSTSSVGSSSRESLGSGTAPAVQLDQGVSSNNNSRVSLVNRKNRKRRKDGAEQMKPSLA MVAAASSLSVATFGTVATASTLAGETSSPESRSKDIVNIKRTNDDNDTTSPTPSPALLASLGWHANPYDFLCDGA RAVKAFSRPFPVKTVGTPKHIEFDVNKAVWKCTVVVTADDAPVYVKGVVEEGEGGETKKLGTEIYIPIVHFAHER LLLDGDAEGKRRRRRRVEGASNKKGEDGVVVQSDSVSTLSLREGGDEVTPTPSVDPTPQALSIPMVGAAPIISKT PSNAIRYTSVAARCPSEITLGAQPVVPYVGYSSEEDEVVEGAVDAYTDEDEPEGEDGGPLVDIEVFVSEGTWKVE GQALFWWYDVPEAPPSASSTTESLGLPKPPYVTSASTTSVNTLSSRRSANANGRKDKLPPGVKEVTIEIRRRGGV IKKEEEEGRKRRVVERGLRSGVYPSERVKSELRAGAKGRRKGDKGCCEELCSEGCVVM |
| Length | 1108 |
Coding
| Sequence id | CC1G_09195T0 |
|---|---|
| Sequence |
>CC1G_09195T0 ATGCCCCGCGTTCCCTCGACGTCGCCGGCGACTGGCCAGCCAGTCCCACCGTCCTACATCCACACATTCAACTAC AACTTTGTCGACACCTCGGGACGAACCCTTTTACTGAGAGGCGTCAACCTCAGTGGCGCATCCAAGGCACCTGTT GGCCACCTGTCCCACCAGCTCGATGATTTCTGGGACAGTGCAGAGGCTGGCGGCGAGAGTTTCATCAGGAGACCT TTGAATTTAGACGATGGATCGGCGGACGTGCACCTGGCAAGACTGAGAGGATGGGGGTTTAATATGTTGCGATTT CCGATTACCTGGGAGGCTTTGGAACACGAGGGGCCAGGGAAATACGACGATGAATTCATCGACTACACAATCCGA GTCCTGCAAAAGTGCAGGGACTATGGGTTCAGAGTCTTCATGGACCCGCACCAAGACACTTGGTCCCGCTTCTCT GGCGGCTCTGGCGCTCCATTCTGGACACTGGCTGCCTGCGGAATCAATCCCAACAACATCACCGCTACTCAATCC GCCATCGTTCATTGCGAATACCCCCTCGCCCATGCTCCCGACCCAGCCTCGCTCCCAGCCATGATCTGGAGCACA AACTACGGCAGACTATTGTCACAAACCCTATTCACCCTCTTCTTCGCTGGACGAACATTCGCGCCTCTCTGTGTC ATCGACGACCTTAATATTCAAGATTATCTCCAAAATCACTATATCGAGGCATTCGGAAGACTGGCGGATCGTATA CGCGAGATAGACCCCAGTCTGTACGACAACTGCATCATCGGCTGGGATTCCCTCAATGAGCCCTTTGAGGGTCTC TGTGGATGGGAAAACCTGAACGCAAACCCTACAGCCCAGGGCTCCACACTCAAAAAGGGCACCTATCCCACTCCC GCCCAGTCCCTTCGACTCGGCATGGGCCAGCCTCAAACAGTCGAGAACTGGTCCTTTGGCGCGTTTGGGCCCTCG CGCAACGGCTCTGTCACCATCGATCCCAAAGGGCACAAACTATGGGCCGAAGATTCCCCTGACGCCCGTTGGGGG TTCAAGCGCGCTGAATCATGGCCCCTAGGCACCTGCATATGGGCATTGCACAACGTCTGGGACATCCAAACCGGC TACGTCCTCCGGCCCGACTACTTCAAATTCCACCCGGAAACCCAAGAAGAAGTCTCTTTCATCTCCGACTTCTGG AAGCCCCACTTCCTCGCTTACTCTTCACGCCTGCGCAAATCCCACCCCGAGGCGATCTGGTTCGTCCAACCACCG GTGTTTGCTAAACCGCCCCAGATAGCCACTGACGACCTCCGCGGACGGGCGTGCTATTCGCCGCACTATTATGAT GGGCTGACGCTCATCACGCGGCACTGGAACTGGTTCAACGCGGACGCCTTGGGTGTGCTACGAGGCAAGTACTCC TCACCCATCCAAGCCGTCAAAATTGGTGAATCAGCTATTCGAGCTTCGATCCAATCCCAACTCGGTATCCTCAAA TCCGACGCTCTCATTCTTGGGGACTACCCCACCCTCATCGGGGAGATCGGCATCCCCTTTGATATGGACGATAAA CGTTCGTATGGGTGGACGGATAAAGGAAAGTACAAGGGCGACTATTCGAGACAGGTCAAGGCTCTCGATGCGAGC TTGAACGCGTGTGATGGACCGAATGGGCTGAACTTTACGGTGTGGACGTTCTGTCCGGACGATCATTCGCATGAG TGGGGTGATGGGTGGAATTTGGAGGATTTGAGTTTGTGGAGTATGGCTGATGTGTGGGAGAGGGAGCGGGTGGAG AAGGAGGCGATGATGGTTGATGAGGAGGATAGGAAGAGTGTTGGGACTGTTTCGACGAGTTCGGTGGGATCGAGC TCGAGGGAGAGTTTGGGTTCTGGTACTGCACCTGCTGTACAACTGGATCAGGGTGTCAGCAGTAACAACAACTCG CGGGTCTCGCTTGTCAACCGGAAGAATAGGAAACGGCGGAAGGATGGTGCAGAGCAGATGAAACCTTCGTTGGCG ATGGTAGCTGCTGCTTCGTCGCTGAGCGTTGCTACCTTTGGTACAGTCGCGACTGCCAGCACGCTCGCTGGCGAA ACCTCCAGTCCGGAATCGCGGTCAAAGGATATCGTCAATATCAAACGCACTAACGACGACAACGACACTACCTCG CCTACCCCTTCACCCGCTCTCCTCGCTTCGCTCGGGTGGCACGCGAATCCCTACGACTTCCTCTGCGATGGTGCG CGAGCGGTTAAAGCCTTCTCGCGCCCGTTCCCCGTCAAGACCGTCGGCACGCCCAAACACATCGAGTTTGATGTC AACAAGGCGGTGTGGAAGTGCACTGTGGTGGTGACTGCGGACGACGCGCCGGTGTATGTCAAGGGCGTCGTGGAG GAAGGCGAGGGTGGGGAGACGAAGAAGCTCGGGACGGAGATTTATATTCCTATTGTTCACTTTGCGCACGAACGG CTGTTGTTAGATGGGGATGCCGAGGGGAAGAGGCGGAGGAGGAGGAGAGTGGAGGGAGCGAGTAACAAGAAGGGG GAGGATGGGGTGGTCGTGCAGAGTGATAGTGTTTCGACTCTTTCGTTGAGAGAAGGAGGGGATGAAGTGACACCT ACGCCTTCCGTGGATCCGACCCCGCAGGCATTGTCTATACCCATGGTTGGTGCTGCGCCGATTATCAGCAAGACT CCCTCCAACGCAATCCGTTATACCTCTGTGGCTGCGAGGTGTCCGTCTGAGATCACGCTCGGGGCGCAGCCTGTT GTTCCGTATGTTGGGTACTCGTCGGAGGAGGATGAGGTGGTGGAAGGTGCAGTTGACGCGTACACGGATGAGGAT GAACCGGAAGGAGAAGATGGCGGGCCTTTGGTTGATATTGAAGTTTTTGTTAGTGAAGGGACGTGGAAAGTGGAA GGACAGGCTTTGTTCTGGTGGTACGACGTCCCCGAAGCACCGCCCTCTGCGTCCTCGACGACTGAATCCCTCGGA CTCCCTAAACCCCCGTATGTTACGTCCGCCTCTACGACTTCGGTTAACACCCTCTCCTCGCGTCGGAGCGCCAAC GCGAATGGGAGGAAAGACAAGCTCCCACCTGGGGTGAAGGAGGTCACGATTGAGATTAGGAGAAGGGGAGGGGTG ATTAAGAAAGAGGAAGAGGAGGGGAGGAAGAGGAGGGTTGTTGAGCGTGGTTTGAGGAGTGGGGTGTACCCTTCT GAGAGAGTGAAGAGTGAGTTGAGGGCTGGTGCGAAGGGGCGGAGGAAAGGAGATAAGGGGTGTTGTGAGGAGTTG TGTTCTGAGGGGTGTGTTGTTATG |
| Length | 3327 |
Transcript
| Sequence id | CC1G_09195T0 |
|---|---|
| Sequence |
>CC1G_09195T0 ATGCCCCGCGTTCCCTCGACGTCGCCGGCGACTGGCCAGCCAGTCCCACCGTCCTACATCCACACATTCAACTAC AACTTTGTCGACACCTCGGGACGAACCCTTTTACTGAGAGGCGTCAACCTCAGTGGCGCATCCAAGGCACCTGTT GGCCACCTGTCCCACCAGCTCGATGATTTCTGGGACAGTGCAGAGGCTGGCGGCGAGAGTTTCATCAGGAGACCT TTGAATTTAGACGATGGATCGGCGGACGTGCACCTGGCAAGACTGAGAGGATGGGGGTTTAATATGTTGCGATTT CCGATTACCTGGGAGGCTTTGGAACACGAGGGGCCAGGGAAATACGACGATGAATTCATCGACTACACAATCCGA GTCCTGCAAAAGTGCAGGGACTATGGGTTCAGAGTCTTCATGGACCCGCACCAAGACACTTGGTCCCGCTTCTCT GGCGGCTCTGGCGCTCCATTCTGGACACTGGCTGCCTGCGGAATCAATCCCAACAACATCACCGCTACTCAATCC GCCATCGTTCATTGCGAATACCCCCTCGCCCATGCTCCCGACCCAGCCTCGCTCCCAGCCATGATCTGGAGCACA AACTACGGCAGACTATTGTCACAAACCCTATTCACCCTCTTCTTCGCTGGACGAACATTCGCGCCTCTCTGTGTC ATCGACGACCTTAATATTCAAGATTATCTCCAAAATCACTATATCGAGGCATTCGGAAGACTGGCGGATCGTATA CGCGAGATAGACCCCAGTCTGTACGACAACTGCATCATCGGCTGGGATTCCCTCAATGAGCCCTTTGAGGGTCTC TGTGGATGGGAAAACCTGAACGCAAACCCTACAGCCCAGGGCTCCACACTCAAAAAGGGCACCTATCCCACTCCC GCCCAGTCCCTTCGACTCGGCATGGGCCAGCCTCAAACAGTCGAGAACTGGTCCTTTGGCGCGTTTGGGCCCTCG CGCAACGGCTCTGTCACCATCGATCCCAAAGGGCACAAACTATGGGCCGAAGATTCCCCTGACGCCCGTTGGGGG TTCAAGCGCGCTGAATCATGGCCCCTAGGCACCTGCATATGGGCATTGCACAACGTCTGGGACATCCAAACCGGC TACGTCCTCCGGCCCGACTACTTCAAATTCCACCCGGAAACCCAAGAAGAAGTCTCTTTCATCTCCGACTTCTGG AAGCCCCACTTCCTCGCTTACTCTTCACGCCTGCGCAAATCCCACCCCGAGGCGATCTGGTTCGTCCAACCACCG GTGTTTGCTAAACCGCCCCAGATAGCCACTGACGACCTCCGCGGACGGGCGTGCTATTCGCCGCACTATTATGAT GGGCTGACGCTCATCACGCGGCACTGGAACTGGTTCAACGCGGACGCCTTGGGTGTGCTACGAGGCAAGTACTCC TCACCCATCCAAGCCGTCAAAATTGGTGAATCAGCTATTCGAGCTTCGATCCAATCCCAACTCGGTATCCTCAAA TCCGACGCTCTCATTCTTGGGGACTACCCCACCCTCATCGGGGAGATCGGCATCCCCTTTGATATGGACGATAAA CGTTCGTATGGGTGGACGGATAAAGGAAAGTACAAGGGCGACTATTCGAGACAGGTCAAGGCTCTCGATGCGAGC TTGAACGCGTGTGATGGACCGAATGGGCTGAACTTTACGGTGTGGACGTTCTGTCCGGACGATCATTCGCATGAG TGGGGTGATGGGTGGAATTTGGAGGATTTGAGTTTGTGGAGTATGGCTGATGTGTGGGAGAGGGAGCGGGTGGAG AAGGAGGCGATGATGGTTGATGAGGAGGATAGGAAGAGTGTTGGGACTGTTTCGACGAGTTCGGTGGGATCGAGC TCGAGGGAGAGTTTGGGTTCTGGTACTGCACCTGCTGTACAACTGGATCAGGGTGTCAGCAGTAACAACAACTCG CGGGTCTCGCTTGTCAACCGGAAGAATAGGAAACGGCGGAAGGATGGTGCAGAGCAGATGAAACCTTCGTTGGCG ATGGTAGCTGCTGCTTCGTCGCTGAGCGTTGCTACCTTTGGTACAGTCGCGACTGCCAGCACGCTCGCTGGCGAA ACCTCCAGTCCGGAATCGCGGTCAAAGGATATCGTCAATATCAAACGCACTAACGACGACAACGACACTACCTCG CCTACCCCTTCACCCGCTCTCCTCGCTTCGCTCGGGTGGCACGCGAATCCCTACGACTTCCTCTGCGATGGTGCG CGAGCGGTTAAAGCCTTCTCGCGCCCGTTCCCCGTCAAGACCGTCGGCACGCCCAAACACATCGAGTTTGATGTC AACAAGGCGGTGTGGAAGTGCACTGTGGTGGTGACTGCGGACGACGCGCCGGTGTATGTCAAGGGCGTCGTGGAG GAAGGCGAGGGTGGGGAGACGAAGAAGCTCGGGACGGAGATTTATATTCCTATTGTTCACTTTGCGCACGAACGG CTGTTGTTAGATGGGGATGCCGAGGGGAAGAGGCGGAGGAGGAGGAGAGTGGAGGGAGCGAGTAACAAGAAGGGG GAGGATGGGGTGGTCGTGCAGAGTGATAGTGTTTCGACTCTTTCGTTGAGAGAAGGAGGGGATGAAGTGACACCT ACGCCTTCCGTGGATCCGACCCCGCAGGCATTGTCTATACCCATGGTTGGTGCTGCGCCGATTATCAGCAAGACT CCCTCCAACGCAATCCGTTATACCTCTGTGGCTGCGAGGTGTCCGTCTGAGATCACGCTCGGGGCGCAGCCTGTT GTTCCGTATGTTGGGTACTCGTCGGAGGAGGATGAGGTGGTGGAAGGTGCAGTTGACGCGTACACGGATGAGGAT GAACCGGAAGGAGAAGATGGCGGGCCTTTGGTTGATATTGAAGTTTTTGTTAGTGAAGGGACGTGGAAAGTGGAA GGACAGGCTTTGTTCTGGTGGTACGACGTCCCCGAAGCACCGCCCTCTGCGTCCTCGACGACTGAATCCCTCGGA CTCCCTAAACCCCCGTATGTTACGTCCGCCTCTACGACTTCGGTTAACACCCTCTCCTCGCGTCGGAGCGCCAAC GCGAATGGGAGGAAAGACAAGCTCCCACCTGGGGTGAAGGAGGTCACGATTGAGATTAGGAGAAGGGGAGGGGTG ATTAAGAAAGAGGAAGAGGAGGGGAGGAAGAGGAGGGTTGTTGAGCGTGGTTTGAGGAGTGGGGTGTACCCTTCT GAGAGAGTGAAGAGTGAGTTGAGGGCTGGTGCGAAGGGGCGGAGGAAAGGAGATAAGGGGTGTTGTGAGGAGTTG TGTTCTGAGGGGTGTGTTGTTATGTGA |
| Length | 3327 |
Gene
| Sequence id | CC1G_09195T0 |
|---|---|
| Sequence |
>CC1G_09195T0 ATGCCCCGCGTTCCCTCGACGTCGCCGGCGACTGGCCAGCCAGTCCCACCGTCCTACATCCACACATTCAACTAC AACTTTGTCGACACCTCGGGACGAACCCTTTTACTGAGAGGCGTCAACCTCAGTGGCGCATCCAAGGCACCTGTT GGCCACCTGTCCCACCAGCTCGATGATTTCTGGGACAGTGCAGAGGCTGGCGGCGAGAGTTTCATCAGGAGACCT TTGAATTTAGACGATGGATCGGCGGACGTGCACCTGGCAAGACTGAGAGGATGGGGGTTTAATATGTTGCGATTT CCGATTACCTGGGAGGCTTTGGAACACGAGGGGCCGTAAGTCGCTTTTATTATTTTCGTAACCAACCTCTAAATG ATCTATAGAGGGAAATACGACGATGAATTCATCGACTACACAATCCGAGTCCTGCAAAAGTGCAGGGACTATGGG TTCAGAGTCTTCATGGACCCGCACCAAGACACTTGGTCCCGCTTCTCTGGCGGCTCTGGCGCTCCATTCTGGACA CTGGCTGCCTGCGGAATCAATCCCAACAACATCACCGCTACTCAATCCGCCATCGTTCATTGCGAATACCCCCTC GCCCATGCTCCCGACCCAGCCTCGCTCCCAGCCATGATCTGGAGCACAAACTACGGCAGACTATTGTCACAAACC CTATTCACCCTCTTCTTCGCTGGACGAACATTCGCGCCTCTCTGTGTCATCGACGACCTTAATATTCAAGATTAT CTCCAAAATCACTATATCGAGGCATTCGGAAGACTGGCGGATCGTATACGCGAGATAGACCCCAGTCTGTACGAC AACTGCATCATCGGCTGGGATTCCCTCAATGAGCCCTTTGAGGGTCTCTGTGGATGGGAAAACCTGAACGCAAAC CCTACAGCCCAGGGCTCCACACTCAAAAAGGGCACCTATCCCACTCCCGCCCAGTCCCTTCGACTCGGCATGGGC CAGCCTCAAACAGTCGAGAACTGGTCCTTTGGCGCGTTTGGGCCCTCGCGCAACGGCTCTGTCACCATCGATCCC AAAGGGCACAAACTATGGGCCGAAGATTCCCCTGACGCCCGTTGGGGGTTCAAGCGCGCTGAATCATGGCCCCTA GGCACCTGCATATGGGCATTGCACAACGTCTGGGACATCCAAACCGGCTACGTCCTCCGGCCCGACTACTTCAAA TTCCACCCGGAAACCCAAGAAGAAGTCTCTTTCATCTCCGACTTCTGGAAGCCCCACTTCCTCGCTTACTCTTCA CGCCTGCGCAAATCCCACCCCGAGGCGATCTGGTTCGTCCAACCACCGGTGTTTGCTAAACCGCCCCAGATAGCC ACTGACGACCTCCGCGGACGGGCGTGCTATTCGCCGCACTATTATGATGGGCTGACGCTCATCACGCGGCACTGG AACTGGTTCAACGCGGACGCCTTGGGTGTGCTACGAGGCAAGTACTCCTCACCCATCCAAGCCGTCAAAATTGGT GAATCAGCTATTCGAGCTTCGATCCAATCCCAACTCGGTATCCTCAAATCCGACGCTCTCATTCTTGGGGACTAC CCCACCCTCATCGGGGAGATCGGCATCCCCTTTGATATGGACGATAAACGTTCGTATGGGTGGACGGATAAAGGA AAGTACAAGGGCGACTATTCGAGACAGGTCAAGGCTCTCGATGCGAGCTTGAACGCGTGTGATGGACCGAATGGG CTGAACTTTACGGTGTGGACGTTCTGTCCGGACGATCATTCGCATGAGTGGGGTGATGGGTGGAATTTGGAGGAT TTGAGTTTGTGGAGTATGGCTGATGTGTGGGAGAGGGAGCGGGTGGAGAAGGAGGCGATGATGGTTGATGAGGAG GATAGGAAGAGTGTTGGGACTGTTTCGACGAGTTCGGTGGGATCGAGCTCGAGGGAGAGTTTGGGTTCTGGTACT GCACCTGCTGTACAACTGGATCAGGGTGTCAGCAGTAACAACAACTCGCGGGTCTCGCTTGTCAACCGGAAGAAT AGGAAACGGCGGAAGGATGGTGCAGAGCAGATGAAACCTTCGTTGGCGATGGTAGCTGCTGCTTCGTCGCTGAGC GTTGCTACCTTTGGTACAGTCGCGACTGCCAGCACGCTCGCTGGCGAAACCTCCAGTCCGGAATCGCGGTCAAAG GATATCGTCAATATCAAACGCACTAACGACGACAACGACACTACCTCGCCTACCCCTTCACCCGCTCTCCTCGCT TCGCTCGGGTGGCACGCGAATCCCTACGACTTCCTCTGCGATGGTGCGCGAGCGGTTAAAGCCTTCTCGCGCCCG TTCCCCGTCAAGACCGTCGGCACGCCCAAACACATCGAGTTTGATGTCAACAAGGCGGTGTGGAAGTGCACTGTG GTGGTGACTGCGGACGACGCGCCGGTGTATGTCAAGGGCGTCGTGGAGGAAGGCGAGGGTGGGGAGACGAAGAAG CTCGGGACGGAGATTTATATTCCTATTGTTCACTTTGCGCACGAACGGCTGTTGTTAGATGGGGATGCCGAGGGG AAGAGGCGGAGGAGGAGGAGAGTGGAGGGAGCGAGTAACAAGAAGGGGGAGGATGGGGTGGTCGTGCAGAGTGAT AGTGTTTCGACTCTTTCGTTGAGAGAAGGAGGGGATGAAGTGACACCTACGCCTTCCGTGGATCCGACCCCGCAG GCATTGTCTATACCCATGGTTGGTGCTGCGCCGATTATCAGCAAGACTCCCTCCAACGCAATCCGTTATACCTCT GTGGCTGCGAGGTGTCCGTCTGAGATCACGCTCGGGGCGCAGCCTGTTGTTCCGTATGTTGGGTACTCGTCGGAG GAGGATGAGGTGGTGGAAGGTGCAGTTGACGCGTACACGGATGAGGATGAACCGGAAGGAGAAGATGGCGGGCCT TTGGTTGATATTGAAGTTTTTGTTAGTGAAGGGACGTGGAAAGTGGAAGGACAGGCTTTGTTCTGGTGGTACGAC GTCCCCGAAGCACCGCCCTCTGCGTCCTCGACGACTGAATCCCTCGGACTCCCTAAACCCCCGTATGTTACGTCC GCCTCTACGACTTCGGTTAACACCCTCTCCTCGCGTCGGAGCGCCAACGCGAATGGGAGGAAAGACAAGCTCCCA CCTGGGGTGAAGGAGGTCACGATTGAGATTAGGAGAAGGGGAGGGGTGATTAAGAAAGAGGAAGAGGAGGGGAGG AAGAGGAGGGTTGTTGAGCGTGGTTTGAGGAGTGGGGTGTACCCTTCTGAGAGAGTGAAGAGTGAGTTGAGGGCT GGTGCGAAGGGGCGGAGGAAAGGAGATAAGGGGTGTTGTGAGGAGTTGTGTTCTGAGGGGTGTGTTGTTATGTGA |
| Length | 3375 |