CC1G_09533
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09533 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P0W5 | Functional description | Cytoplasmic protein |
| Location | Chr_6:1291520..1294464 | Strand | - |
| Gene length (nt) | 2945 | Transcript length (nt) | 2316 |
| CDS length (nt) | 2316 | Protein length (aa) | 771 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7263297 | 64.3 | 0 | 1108 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB17369 | 63.8 | 0 | 1086 |
| Pleurotus eryngii ATCC 90797 | Pleery1_592183 | 64.1 | 0 | 1076 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1091243 | 64.1 | 0 | 1076 |
| Pleurotus ostreatus PC9 | PleosPC9_1_114491 | 64.1 | 0 | 1076 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_73767 | 65.1 | 0 | 1063 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_10427 | 62.5 | 0 | 1040 |
| Lentinula edodes NBRC 111202 | Lenedo1_736401 | 62.5 | 0 | 1039 |
| Flammulina velutipes | Flave_chr09AA00318 | 63 | 0 | 1013 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_75777 | 58.7 | 2.04E-304 | 987 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_194782 | 57.1 | 9.619E-304 | 985 |
| Grifola frondosa | Grifr_OBZ77054 | 58.2 | 1.059E-304 | 962 |
| Schizophyllum commune H4-8 | Schco3_2622489 | 61.7 | 6.438E-291 | 960 |
| Auricularia subglabra | Aurde3_1_1228860 | 52.1 | 1.556E-275 | 858 |
| Lentinula edodes B17 | Lened_B_1_1_11912 | 68.9 | 1.105E-134 | 447 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8151 |
| Description | Cytoplasmic protein |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 122 | 305 |
| Pfam | PF18564 | Glycoside hydrolase family 5 C-terminal domain | IPR041036 | 635 | 725 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| 1 | 743 | 765 | 22 |
InterPro
| Accession | Description |
|---|---|
| IPR017853 | Glycoside hydrolase superfamily |
| IPR001547 | Glycoside hydrolase, family 5 |
| IPR013780 | Glycosyl hydrolase, all-beta |
| IPR041036 | Glycoside hydrolase family 5, C-terminal domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | Cellulase (glycosyl hydrolase family 5) |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_12 |
Transcription factor
| Group |
|---|
| No records |
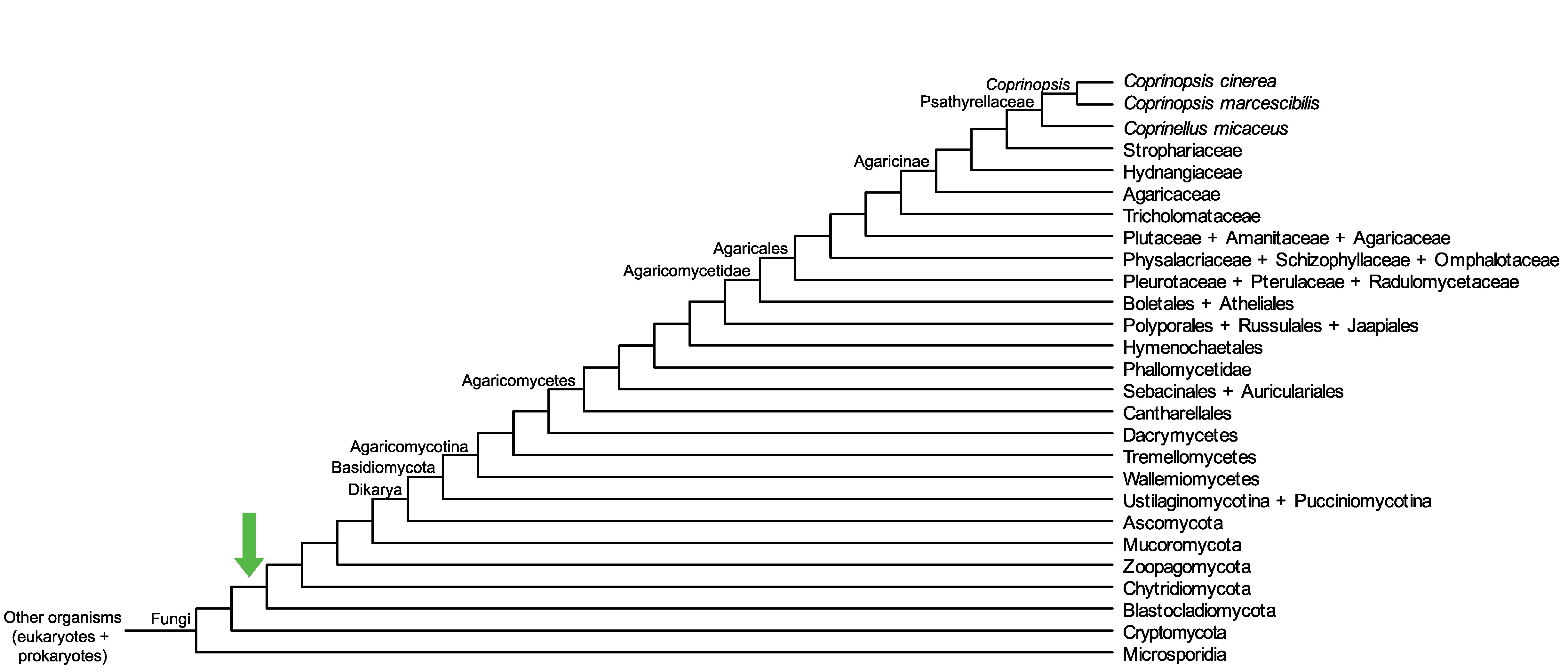
Conservation of CC1G_09533 across fungi.
Arrow shows the origin of gene family containing CC1G_09533.
Protein
| Sequence id | 8151 |
|---|---|
| Sequence |
>8151 MSIPSTLDSSFILVENDARKPNPIVQDAKPNIPATHPSLEPGYKPGSANTYAHDWSPLATGGSIKTQGRHFVDGY GRVCHLRGANVSGCCKTPFDHDHENFPGDHRSVTFVGRPFPLEEAPEHFARLRRWGLTFIRFLVTWEAVEHAGPG IYDKEYLAYIRALLSLLPKYGLTAFVSMHQDVWSRYSGGSGAPAWTLEAAGFDLGAIEETGAGWLQGQKRGGHTE PDRGIWPCGYQKLSAATMATLFWGGDTFAPKLRVKGTDGEEVTIQKYLQDAFLGTWEEIVKAVGDLEGVIGVQMM NEPHRGYIELPSLHSFDYNTDLHLAHVPSAFQSFQLGAGHPTEVPHYERSFPWPTKLTGNTLVNANGVKAWREDG PTNGKCIWELHNVWGWDQKKNEAVILREGYFLVHPKTKEKVDWYVDCYFPLMQRWEKRIRPSIGADKMIFAEPIP NEFCPKTWTEERRPSNLVYAPHWYDLNALFSKAFGDFTVNVQGLSRGMFLPKALYWGQKGARDNYSLQIRNIVQK GYEALGDKPIVIGECGIPMDMNNKEAFETGDFTWHARMMDALMTALERSFVGFTLWNYNPSNNDVHGDDWNGENF SWFSRYRALPPSLLDYSQTSPTLDNGGRILTSIVRPYPAKTCGIPIKMEYEMTTGTFTYEWANSSGPLLSAETEI FYPSLIAQSRDVMVNGLEKGDRYVYDERRQTLFIVCQDVKTPGKRHRVEVSVSPGLDYPRPEFYLNDIWTDFGGQ ISAAVFVVLLVMALLTTRWLV |
| Length | 771 |
Coding
| Sequence id | CC1G_09533T0 |
|---|---|
| Sequence |
>CC1G_09533T0 ATGTCGATACCCTCAACATTAGACAGTTCCTTTATTCTCGTCGAAAACGACGCTCGCAAACCAAATCCTATCGTC CAGGATGCTAAACCCAATATTCCGGCAACGCACCCTTCGCTTGAACCAGGATATAAACCGGGTTCAGCAAATACA TACGCTCACGACTGGTCACCTTTAGCGACGGGAGGCTCAATAAAGACCCAAGGCCGCCATTTTGTCGACGGCTAC GGGCGAGTCTGCCATCTTCGCGGTGCCAACGTATCAGGCTGTTGCAAGACACCATTCGACCATGACCACGAAAAC TTCCCTGGGGACCATCGCTCTGTTACCTTTGTTGGCCGTCCCTTTCCCTTGGAGGAGGCTCCGGAGCACTTTGCA AGGCTGAGGAGATGGGGGTTAACTTTCATTCGTTTTCTTGTTACTTGGGAGGCCGTTGAGCACGCTGGACCAGGT ATCTACGACAAGGAATACCTTGCTTATATTCGAGCTCTTCTCTCCCTTCTCCCCAAGTACGGCCTGACCGCCTTC GTATCGATGCATCAAGATGTCTGGTCTCGTTACTCTGGTGGCTCAGGAGCGCCTGCCTGGACGCTGGAAGCTGCA GGATTCGACCTCGGCGCAATCGAAGAAACCGGAGCGGGTTGGCTTCAGGGTCAGAAGCGGGGCGGGCATACTGAA CCTGACCGCGGCATCTGGCCTTGCGGGTACCAGAAGCTGAGCGCAGCTACTATGGCAACGCTGTTCTGGGGCGGA GATACCTTCGCTCCAAAGCTCCGTGTCAAGGGGACGGATGGGGAGGAGGTCACCATCCAGAAGTACCTCCAAGAC GCCTTCCTTGGTACCTGGGAAGAAATAGTCAAGGCTGTTGGCGACCTGGAAGGCGTGATCGGCGTCCAAATGATG AATGAGCCTCATCGAGGCTACATCGAGCTACCTTCCCTTCATAGCTTTGACTACAACACAGATTTGCATCTTGCC CACGTCCCATCTGCTTTCCAATCGTTCCAGCTCGGCGCTGGTCACCCAACCGAAGTTCCTCACTACGAACGCTCC TTCCCCTGGCCGACCAAACTGACTGGAAACACCCTCGTCAACGCGAACGGCGTGAAAGCCTGGAGAGAAGACGGG CCTACCAACGGAAAGTGTATCTGGGAGCTGCACAACGTATGGGGATGGGACCAGAAGAAAAACGAAGCTGTTATC CTGAGGGAAGGATACTTCCTGGTACATCCGAAGACTAAAGAAAAGGTTGACTGGTATGTCGATTGCTATTTCCCT CTCATGCAGAGGTGGGAGAAGCGTATTCGACCGAGCATCGGTGCGGATAAGATGATCTTTGCCGAACCGATTCCG AACGAGTTCTGCCCCAAGACATGGACTGAGGAACGCCGTCCCTCAAATCTGGTGTATGCGCCCCACTGGTACGAC CTCAATGCTCTTTTCTCCAAGGCCTTCGGCGACTTTACTGTCAATGTACAAGGCCTCTCTCGGGGCATGTTCCTC CCGAAGGCCCTCTACTGGGGCCAGAAAGGTGCCAGGGATAACTACAGTCTTCAGATTCGCAACATTGTCCAGAAG GGTTATGAAGCCCTCGGGGACAAGCCTATTGTTATCGGCGAATGTGGTATTCCAATGGACATGAATAACAAAGAG GCTTTCGAGACTGGAGACTTTACCTGGCACGCTCGCATGATGGACGCGTTGATGACCGCCTTGGAACGGTCATTC GTTGGTTTTACCCTGTGGAATTACAATCCCTCAAACAACGATGTCCACGGCGACGACTGGAACGGCGAGAACTTT TCATGGTTCAGTCGTTATCGAGCCCTGCCACCCTCCCTGCTCGACTACTCCCAAACATCACCCACCTTGGATAAC GGTGGACGAATCCTCACCTCAATCGTCCGGCCGTACCCAGCCAAGACCTGCGGGATACCGATCAAGATGGAATAT GAAATGACGACGGGGACATTCACCTACGAATGGGCCAACTCCTCAGGGCCCCTGCTCTCCGCCGAGACAGAGATC TTCTACCCATCGCTTATCGCCCAGTCAAGGGACGTCATGGTTAATGGCCTGGAGAAAGGGGACCGATACGTCTAC GACGAGCGACGCCAGACTTTGTTCATCGTCTGCCAGGACGTCAAGACACCCGGCAAGCGACACCGAGTGGAGGTG TCTGTTTCACCTGGATTGGACTATCCTCGACCTGAGTTTTATCTTAACGATATTTGGACGGACTTTGGAGGGCAG ATTTCTGCTGCTGTTTTTGTTGTTTTGTTGGTTATGGCGTTGCTCACGACCCGGTGGTTGGTT |
| Length | 2316 |
Transcript
| Sequence id | CC1G_09533T0 |
|---|---|
| Sequence |
>CC1G_09533T0 ATGTCGATACCCTCAACATTAGACAGTTCCTTTATTCTCGTCGAAAACGACGCTCGCAAACCAAATCCTATCGTC CAGGATGCTAAACCCAATATTCCGGCAACGCACCCTTCGCTTGAACCAGGATATAAACCGGGTTCAGCAAATACA TACGCTCACGACTGGTCACCTTTAGCGACGGGAGGCTCAATAAAGACCCAAGGCCGCCATTTTGTCGACGGCTAC GGGCGAGTCTGCCATCTTCGCGGTGCCAACGTATCAGGCTGTTGCAAGACACCATTCGACCATGACCACGAAAAC TTCCCTGGGGACCATCGCTCTGTTACCTTTGTTGGCCGTCCCTTTCCCTTGGAGGAGGCTCCGGAGCACTTTGCA AGGCTGAGGAGATGGGGGTTAACTTTCATTCGTTTTCTTGTTACTTGGGAGGCCGTTGAGCACGCTGGACCAGGT ATCTACGACAAGGAATACCTTGCTTATATTCGAGCTCTTCTCTCCCTTCTCCCCAAGTACGGCCTGACCGCCTTC GTATCGATGCATCAAGATGTCTGGTCTCGTTACTCTGGTGGCTCAGGAGCGCCTGCCTGGACGCTGGAAGCTGCA GGATTCGACCTCGGCGCAATCGAAGAAACCGGAGCGGGTTGGCTTCAGGGTCAGAAGCGGGGCGGGCATACTGAA CCTGACCGCGGCATCTGGCCTTGCGGGTACCAGAAGCTGAGCGCAGCTACTATGGCAACGCTGTTCTGGGGCGGA GATACCTTCGCTCCAAAGCTCCGTGTCAAGGGGACGGATGGGGAGGAGGTCACCATCCAGAAGTACCTCCAAGAC GCCTTCCTTGGTACCTGGGAAGAAATAGTCAAGGCTGTTGGCGACCTGGAAGGCGTGATCGGCGTCCAAATGATG AATGAGCCTCATCGAGGCTACATCGAGCTACCTTCCCTTCATAGCTTTGACTACAACACAGATTTGCATCTTGCC CACGTCCCATCTGCTTTCCAATCGTTCCAGCTCGGCGCTGGTCACCCAACCGAAGTTCCTCACTACGAACGCTCC TTCCCCTGGCCGACCAAACTGACTGGAAACACCCTCGTCAACGCGAACGGCGTGAAAGCCTGGAGAGAAGACGGG CCTACCAACGGAAAGTGTATCTGGGAGCTGCACAACGTATGGGGATGGGACCAGAAGAAAAACGAAGCTGTTATC CTGAGGGAAGGATACTTCCTGGTACATCCGAAGACTAAAGAAAAGGTTGACTGGTATGTCGATTGCTATTTCCCT CTCATGCAGAGGTGGGAGAAGCGTATTCGACCGAGCATCGGTGCGGATAAGATGATCTTTGCCGAACCGATTCCG AACGAGTTCTGCCCCAAGACATGGACTGAGGAACGCCGTCCCTCAAATCTGGTGTATGCGCCCCACTGGTACGAC CTCAATGCTCTTTTCTCCAAGGCCTTCGGCGACTTTACTGTCAATGTACAAGGCCTCTCTCGGGGCATGTTCCTC CCGAAGGCCCTCTACTGGGGCCAGAAAGGTGCCAGGGATAACTACAGTCTTCAGATTCGCAACATTGTCCAGAAG GGTTATGAAGCCCTCGGGGACAAGCCTATTGTTATCGGCGAATGTGGTATTCCAATGGACATGAATAACAAAGAG GCTTTCGAGACTGGAGACTTTACCTGGCACGCTCGCATGATGGACGCGTTGATGACCGCCTTGGAACGGTCATTC GTTGGTTTTACCCTGTGGAATTACAATCCCTCAAACAACGATGTCCACGGCGACGACTGGAACGGCGAGAACTTT TCATGGTTCAGTCGTTATCGAGCCCTGCCACCCTCCCTGCTCGACTACTCCCAAACATCACCCACCTTGGATAAC GGTGGACGAATCCTCACCTCAATCGTCCGGCCGTACCCAGCCAAGACCTGCGGGATACCGATCAAGATGGAATAT GAAATGACGACGGGGACATTCACCTACGAATGGGCCAACTCCTCAGGGCCCCTGCTCTCCGCCGAGACAGAGATC TTCTACCCATCGCTTATCGCCCAGTCAAGGGACGTCATGGTTAATGGCCTGGAGAAAGGGGACCGATACGTCTAC GACGAGCGACGCCAGACTTTGTTCATCGTCTGCCAGGACGTCAAGACACCCGGCAAGCGACACCGAGTGGAGGTG TCTGTTTCACCTGGATTGGACTATCCTCGACCTGAGTTTTATCTTAACGATATTTGGACGGACTTTGGAGGGCAG ATTTCTGCTGCTGTTTTTGTTGTTTTGTTGGTTATGGCGTTGCTCACGACCCGGTGGTTGGTTTAA |
| Length | 2316 |
Gene
| Sequence id | CC1G_09533T0 |
|---|---|
| Sequence |
>CC1G_09533T0 ATGTCGATACCCTCAACATTAGACAGTTCCTTTATTCTCGTCGAAAACGACGCTCGCAAACCAAATCCTATCGTC CAGGATGCTAAACCCAATATTCCGGTGAGTAGCATCATCCCAGAACTCTGAGCTCGAGCTAATTTAGCGCGCGAC AGGCAACGCACCCTTCGCTTGAACCAGGATATAAACCGGGTTCAGCAAATACATACGCTCACGACTGGTCACCTT TAGCGACGGGAGGCTCAATAAAGACCCAAGGCCGCCATTTTGTCGACGGCTACGGGCGAGTCTGCCATCTTCGCG GTGCCAACGTATCAGGCTGTTGCAAGACGTCCGTTGTCTACAGCCTCCCGCATTACATCGTCTGACAACGCTTCT TTAGACCATTCGACCATGACCACGAAAACTTCCCTGGGGACCATCGCTCTGTTACCTTTGTTGGCCGTCCCTTTC CCTTGGAGGAGGCTCCGGAGCACTTTGCAAGGCTGAGGAGATGGGGGTTAACTTTCAGTGAGTGTGGACGGGCTC TAGGACGCGTCTTTATTCACCAAGGTTCTCAGTTCGTTTTCTTGTTACTTGGGAGGCCGTTGAGCACGCTGGACC GTACGTCTCATTGAAGTGACCCGTCTCCGGTTGGCACAAACTGACTTTGCAGCTAAAGAGGTATCTACGACAAGG AATACCTTGCTTATATTCGAGCTCTTCTCTCCCTTCTCCCCAAGTACGGCCTGACCGCCTTCGTATCGATGCATC AAGATGTCTGGTCTCGTTACTCTGGTGGCTCAGGAGCGCCTGCCTGGACGCTGGAAGCTGCAGGATTCGACCTCG GCGCAATCGAAGAAACCGGAGCGGGTTGGCTTCAGGGTCAGAAGCGGGGCGGGCATACTGAACCTGACCGCGGCA TCTGGCCTTGCGGGTACCAGAAGCTGAGCGCAGCTACTATGGCGTAAGTCTATTCCCTTTCTGCTCAGGTACATC GCATCGACTGAAACGCGTCGCTTAGAACGCTGTTCTGGGGCGGAGATACCTTCGCTCCAAAGCTCCGTGTCAAGG GGACGGATGGGGAGGAGGTCACCATCCAGAAGTACCTCCAAGACGCCTTCCTTGGTACCTGGGAAGAAATAGTCA AGGCTGTTGGCGACCTGGAAGGCGTGATCGGCGTCCAAGTATGTAGTGACTACGTTTCCTGGTTTCAAAGCTTAC CCCCTCTACAGATGATGAATGAGCCTCATCGAGGCTACATCGAGCTACCTTCCCTTCATAGCTTTGACTACAACA CAGATTTGCATCTTGCCCACGTCCGTAAGTACGGACTTCGCCTTCAATTGAACTCGTACTAAAGTTTTGTATAGC ATCTGCTTTCCAATCGTTCCAGCTCGGCGCTGGTCACCCAACCGAAGTTCCTCACTACGAACGCTCCTTCCCCTG GCCGACCAAACTGACTGGAAACACCCTCGTCAACGCGAACGGCGTGAAAGCCTGGAGAGAAGACGGGCCTACCAA CGGAAAGTGTATCTGGGAGCTGCACAACGTATGGGGATGGGACCAGAAGAAAAACGAAGCTGTTATCCTGAGGGA AGGATACTTCCTGGTACATCCGAAGACTAAAGAAAAGGTTGACTGGTATGTCGATTGCTATTTCCCTCTCATGCA GAGGTGGGAGAAGCGTATTCGACCGAGCATCGGTGCGGATAAGATGATCTTTGCCGAACCGATTCCGAACGAGGT ATGTACGATGCTCGGTAATAGGTTCTTATCTAATTGGCATGTGTTGTCAGTTCTGCCCCAAGACATGGACTGAGG AACGCCGTCCCTCAAATCTGGTGTATGCGCCCCACTGGTTAGTCCTCAGATGCCTTCATTTATTTACCTTGCTGA CATTGGATTGCTAGGTACGACCTCAATGCTCTTTTCTCCAAGGCCTTCGGCGACTTTACTGTCAATGTACAAGGC CTCTCTCGGGTAGGTCCTTCGCTTGACTCTTGAGTGTCTTGCCTATTTTCTTACATTCACCTAGGGCATGTTCCT CCCGAAGGCCCTCTACTGGGGCCAGAAAGGTGCCAGGGATAACTACAGTCTTCAGATTCGCAACATTGTCCAGAA GGGTTATGAAGCCCTCGGGGACAAGCCTATTGTTATCGGCGAATGTGGTATTCCAATGGACATGAAGTGAGTGTC TGGATCTTAGAAACAATCCGCTGTTGCTGAACCGCTGCTGCAGTAACAAAGAGGCTTTCGAGACTGGAGACTTTA CCTGGCACGCTCGCATGATGGACGCGTTGATGACCGCCTTGGAACGGTCATTCGTTGGTTTTACGTGAGTCTGTC CAAAGTACACGCAGCATCTTTCTTGATGCCATGTTTCCAGCCTGTGGAATTACAATCCCTCAAACAACGATGTCC ACGGCGACGACTGGAACGGCGAGAACTTTTCATGGTTCAGTCGTTATCGAGCCCTGCCACCCTCCCTGCTCGACT ACTCCCAAACATCACCCACCTTGGATAACGGTGGACGAATCCTCACCTCAATCGTCCGGCCGTACCCAGCCAAGA CCTGCGGGATACCGATCAAGATGGAATATGAAATGACGACGGGGACATTCACCTACGAATGGGCCAACTCCTCAG GGCCCCTGCTCTCCGCCGAGACAGAGATCTTCTACCCATCGCTTATCGCCCAGTCAAGGGACGTCATGGTTAATG GCCTGGAGAAAGGGGACCGATACGTCTACGACGAGCGACGCCAGACTTTGTTCATCGTCTGCCAGGACGTCAAGA CACCCGGCAAGCGACACCGAGTGGAGGTGTCTGTTTCACCTGGATTGGACTATCCTCGACCTGAGTTTTATCTTA ACGATATTTGGACGGACTTTGGAGGGCAGATTTCTGCTGCTGTTTTTGTTGTTTTGTTGGTTATGGCGTTGCTCA CGACCCGGTGGTTGGTTTAA |
| Length | 2945 |