CC1G_09923
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_09923 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NN13 | Functional description | Cellobiose dehydrogenase |
| Location | Chr_12:1236764..1239941 | Strand | + |
| Gene length (nt) | 3178 | Transcript length (nt) | 2286 |
| CDS length (nt) | 2286 | Protein length (aa) | 761 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN7230 |
| Neurospora crassa | cdh-2 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7262555 | 65.7 | 0 | 1092 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB26844 | 65.7 | 0 | 1082 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1592473 | 63.5 | 0 | 1030 |
| Pleurotus ostreatus PC15 | PleosPC15_2_41743 | 64 | 0 | 1016 |
| Pleurotus ostreatus PC9 | PleosPC9_1_62103 | 64 | 0 | 1016 |
| Schizophyllum commune H4-8 | Schco3_2642438 | 62.8 | 0 | 1005 |
| Flammulina velutipes | Flave_chr01AA00302 | 61.5 | 1.976E-304 | 997 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_86428 | 60.6 | 5.958E-304 | 987 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_6040 | 60.7 | 6.442E-304 | 987 |
| Lentinula edodes NBRC 111202 | Lenedo1_1176330 | 59.4 | 1.852E-304 | 977 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_107890 | 57.2 | 7.952E-304 | 943 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_188178 | 56.9 | 1.69E-304 | 942 |
| Auricularia subglabra | Aurde3_1_1329463 | 55.2 | 4.273E-283 | 881 |
| Lentinula edodes B17 | Lened_B_1_1_5826 | 58.1 | 5.532E-271 | 845 |
| Grifola frondosa | Grifr_OBZ78256 | 44.8 | 1.758E-205 | 655 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8465 |
| Description | Cellobiose dehydrogenase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd09630 | CDH_like_cytochrome | IPR015920 | 21 | 179 |
| Pfam | PF16010 | Cytochrome domain of cellobiose dehydrogenase | IPR015920 | 22 | 192 |
| Pfam | PF00732 | GMC oxidoreductase | IPR000172 | 228 | 501 |
| Pfam | PF05199 | GMC oxidoreductase | IPR007867 | 627 | 749 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 21 | 0.9961 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR015920 | Cellobiose dehydrogenase, cytochrome domain |
| IPR036188 | FAD/NAD(P)-binding domain superfamily |
| IPR007867 | Glucose-methanol-choline oxidoreductase, C-terminal |
| IPR000172 | Glucose-methanol-choline oxidoreductase, N-terminal |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0016614 | oxidoreductase activity, acting on CH-OH group of donors | MF |
| GO:0050660 | flavin adenine dinucleotide binding | MF |
KEGG
| KEGG Orthology |
|---|
| K19069 |
EggNOG
| COG category | Description |
|---|---|
| E | Cytochrome domain of cellobiose dehydrogenase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| AA | AA8 | |
| AA | AA3 | AA3_1 |
Transcription factor
| Group |
|---|
| No records |
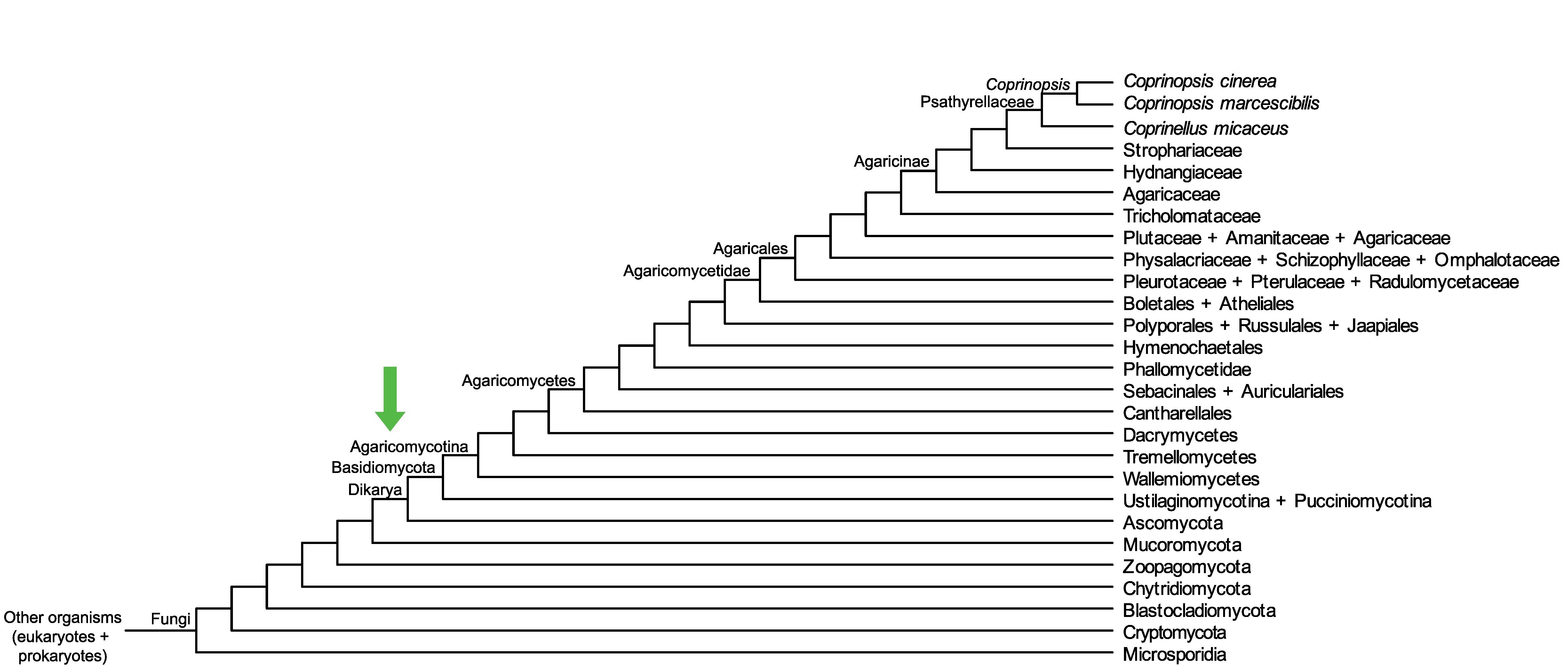
Conservation of CC1G_09923 across fungi.
Arrow shows the origin of gene family containing CC1G_09923.
Protein
| Sequence id | 8465 |
|---|---|
| Sequence |
>8465 MLGRLFTSLLLAGLALAQTESYVDPDTGITFQGRTDPVHGVTIGYVLPPLEPASDEFIGQILAPIENGWVGIAPG GGMINNLLVVAWPNGNEVVASVRMAKPFNDPVLTILPSTKVNATHWKLDYRCQGCTTWETANGPRSLPIDSAGAA AWALSKSPVDDPSDPDTTFAQHTDFGFYGQIWALSHVDAETYEHWASGGTGGGPTPTTPPTEPPTPTEPVPTVEP TPYDYIVVGAGPGGLVTADRLSEAGHKVLLIERGGPSLGSTGGTTQPDWLKGTNLTKFDVPGLFETMFMDADPYW WCKDINVFAGCLLGGGTAINGGLYWYPPDIDFSHTYGWPPSWQSHHQYTDKLKQRIPSTDAPSTDGKRYLMETFD VVEKLLRPQGYHQQTINNNPNQKDRVYGYSAYSFIDGKRAGPIATYYKTAIARPNLTYFSHTTVLNVVREGSTIT GVNTDNPLIGPNGFVPLNPRGRVILSAGAFGSARLLFRSGIGPRDMLEIVKNDRNAGPNMPAEEDWIDLPVGENV QDNPSINLVFTHPDIDAYENWANVWSNPRQADAAQYIDSQSGVFSQSSPRINFWRKLMGSDKKPRWMQGTARPGA ASITTDFPYNASNIFTITTYLATGITSRGRIGIDAALTARALKNPWFTDPVDKEVLLKGIHELIDAMEHVPGLTL ITPDNTTTIEDYVDNYPTGWLNSNHWVGSNSIGKVVDENTKVFNTDNLFVVDASIIPSMPMGNPQGAIMSTAEQG VARILALQGGP |
| Length | 761 |
Coding
| Sequence id | CC1G_09923T0 |
|---|---|
| Sequence |
>CC1G_09923T0 ATGTTGGGACGACTCTTTACGAGTCTCCTCCTCGCAGGGCTCGCCCTCGCGCAGACTGAATCGTATGTCGACCCT GACACCGGGATCACCTTCCAAGGTAGAACCGACCCCGTGCACGGCGTGACCATTGGTTACGTCCTTCCACCGCTC GAGCCTGCCTCCGATGAATTCATTGGCCAAATTCTTGCGCCCATTGAGAACGGATGGGTCGGCATTGCCCCTGGT GGAGGCATGATTAACAACCTCCTCGTCGTTGCTTGGCCTAATGGCAACGAGGTCGTTGCTTCCGTTCGGATGGCA AAACCTTTCAACGATCCTGTCCTTACCATTCTTCCATCGACCAAGGTCAACGCGACCCACTGGAAACTCGACTAC CGCTGCCAAGGCTGCACCACTTGGGAAACCGCCAACGGACCCCGCTCACTCCCCATCGACTCTGCCGGTGCCGCC GCCTGGGCACTCTCCAAGTCCCCCGTCGACGACCCCTCCGACCCCGACACCACCTTCGCTCAACACACTGACTTC GGCTTCTACGGCCAAATCTGGGCTCTCTCCCATGTTGACGCTGAGACCTACGAGCACTGGGCTTCTGGAGGCACT GGTGGCGGTCCCACCCCTACCACTCCTCCCACTGAACCTCCTACTCCTACTGAGCCTGTTCCTACCGTAGAGCCT ACTCCCTACGACTACATCGTCGTCGGAGCCGGCCCCGGTGGATTGGTCACTGCTGACCGTCTCTCCGAGGCAGGC CACAAGGTCCTCCTTATTGAGAGGGGTGGACCCAGCTTGGGCTCGACCGGCGGTACCACTCAGCCCGATTGGTTG AAGGGAACTAACCTCACGAAATTCGATGTCCCTGGATTGTTCGAGACTATGTTCATGGATGCCGATCCTTACTGG TGGTGCAAGGACATCAACGTTTTCGCCGGATGCTTGCTCGGCGGAGGAACTGCTATCAACGGAGGCTTGTACTGG TACCCTCCCGACATCGATTTCTCTCACACCTACGGCTGGCCTCCCTCGTGGCAGAGCCATCACCAATACACCGAC AAGCTTAAGCAGCGTATCCCCAGTACTGATGCTCCCTCGACCGATGGCAAGCGATATCTCATGGAGACCTTCGAC GTCGTCGAGAAGTTGCTCCGCCCTCAAGGATACCACCAGCAAACCATCAACAACAACCCTAACCAGAAGGATAGG GTTTACGGTTACAGCGCCTACTCTTTCATCGACGGCAAGCGCGCTGGTCCCATCGCAACCTACTACAAGACCGCC ATCGCCCGACCCAACTTGACCTACTTCTCGCACACCACCGTCCTCAACGTCGTTCGTGAAGGCTCCACCATCACC GGTGTCAACACCGACAACCCATTGATCGGTCCCAACGGCTTCGTCCCTCTCAACCCCCGCGGCCGTGTCATCCTC TCCGCTGGCGCCTTCGGCTCTGCACGTCTCCTCTTCCGCTCTGGAATTGGCCCTCGCGATATGCTCGAGATCGTC AAGAATGACAGGAACGCCGGCCCCAACATGCCCGCTGAGGAGGACTGGATCGACCTCCCTGTTGGCGAGAACGTC CAGGACAACCCTTCGATTAACTTGGTCTTCACCCACCCCGACATTGATGCCTATGAGAACTGGGCCAACGTTTGG AGCAACCCCAGGCAGGCTGATGCTGCTCAGTATATCGACAGCCAGTCTGGCGTCTTCTCTCAATCTTCCCCTCGT ATCAACTTCTGGAGGAAACTTATGGGCAGCGACAAGAAGCCTCGATGGATGCAAGGAACTGCTCGCCCTGGTGCC GCCTCCATCACCACCGACTTCCCCTACAACGCTAGCAACATCTTCACCATCACCACCTACCTCGCCACTGGTATC ACCTCCCGTGGTCGTATTGGTATCGATGCTGCCCTTACTGCTCGTGCCCTCAAGAACCCCTGGTTCACCGACCCC GTCGACAAAGAGGTCCTCCTCAAGGGTATCCATGAACTCATTGACGCCATGGAGCATGTCCCCGGATTGACCCTC ATCACTCCCGACAACACGACCACCATCGAGGACTACGTCGACAACTACCCCACCGGCTGGCTCAACTCCAACCAC TGGGTCGGGTCCAACTCCATCGGAAAGGTTGTCGATGAGAACACCAAGGTCTTCAACACCGATAACCTCTTCGTT GTTGATGCTTCCATCATTCCTTCGATGCCCATGGGTAACCCACAGGGTGCTATCATGTCGACTGCTGAACAGGGT GTGGCTAGGATTCTCGCCCTCCAAGGCGGCCCT |
| Length | 2286 |
Transcript
| Sequence id | CC1G_09923T0 |
|---|---|
| Sequence |
>CC1G_09923T0 ATGTTGGGACGACTCTTTACGAGTCTCCTCCTCGCAGGGCTCGCCCTCGCGCAGACTGAATCGTATGTCGACCCT GACACCGGGATCACCTTCCAAGGTAGAACCGACCCCGTGCACGGCGTGACCATTGGTTACGTCCTTCCACCGCTC GAGCCTGCCTCCGATGAATTCATTGGCCAAATTCTTGCGCCCATTGAGAACGGATGGGTCGGCATTGCCCCTGGT GGAGGCATGATTAACAACCTCCTCGTCGTTGCTTGGCCTAATGGCAACGAGGTCGTTGCTTCCGTTCGGATGGCA AAACCTTTCAACGATCCTGTCCTTACCATTCTTCCATCGACCAAGGTCAACGCGACCCACTGGAAACTCGACTAC CGCTGCCAAGGCTGCACCACTTGGGAAACCGCCAACGGACCCCGCTCACTCCCCATCGACTCTGCCGGTGCCGCC GCCTGGGCACTCTCCAAGTCCCCCGTCGACGACCCCTCCGACCCCGACACCACCTTCGCTCAACACACTGACTTC GGCTTCTACGGCCAAATCTGGGCTCTCTCCCATGTTGACGCTGAGACCTACGAGCACTGGGCTTCTGGAGGCACT GGTGGCGGTCCCACCCCTACCACTCCTCCCACTGAACCTCCTACTCCTACTGAGCCTGTTCCTACCGTAGAGCCT ACTCCCTACGACTACATCGTCGTCGGAGCCGGCCCCGGTGGATTGGTCACTGCTGACCGTCTCTCCGAGGCAGGC CACAAGGTCCTCCTTATTGAGAGGGGTGGACCCAGCTTGGGCTCGACCGGCGGTACCACTCAGCCCGATTGGTTG AAGGGAACTAACCTCACGAAATTCGATGTCCCTGGATTGTTCGAGACTATGTTCATGGATGCCGATCCTTACTGG TGGTGCAAGGACATCAACGTTTTCGCCGGATGCTTGCTCGGCGGAGGAACTGCTATCAACGGAGGCTTGTACTGG TACCCTCCCGACATCGATTTCTCTCACACCTACGGCTGGCCTCCCTCGTGGCAGAGCCATCACCAATACACCGAC AAGCTTAAGCAGCGTATCCCCAGTACTGATGCTCCCTCGACCGATGGCAAGCGATATCTCATGGAGACCTTCGAC GTCGTCGAGAAGTTGCTCCGCCCTCAAGGATACCACCAGCAAACCATCAACAACAACCCTAACCAGAAGGATAGG GTTTACGGTTACAGCGCCTACTCTTTCATCGACGGCAAGCGCGCTGGTCCCATCGCAACCTACTACAAGACCGCC ATCGCCCGACCCAACTTGACCTACTTCTCGCACACCACCGTCCTCAACGTCGTTCGTGAAGGCTCCACCATCACC GGTGTCAACACCGACAACCCATTGATCGGTCCCAACGGCTTCGTCCCTCTCAACCCCCGCGGCCGTGTCATCCTC TCCGCTGGCGCCTTCGGCTCTGCACGTCTCCTCTTCCGCTCTGGAATTGGCCCTCGCGATATGCTCGAGATCGTC AAGAATGACAGGAACGCCGGCCCCAACATGCCCGCTGAGGAGGACTGGATCGACCTCCCTGTTGGCGAGAACGTC CAGGACAACCCTTCGATTAACTTGGTCTTCACCCACCCCGACATTGATGCCTATGAGAACTGGGCCAACGTTTGG AGCAACCCCAGGCAGGCTGATGCTGCTCAGTATATCGACAGCCAGTCTGGCGTCTTCTCTCAATCTTCCCCTCGT ATCAACTTCTGGAGGAAACTTATGGGCAGCGACAAGAAGCCTCGATGGATGCAAGGAACTGCTCGCCCTGGTGCC GCCTCCATCACCACCGACTTCCCCTACAACGCTAGCAACATCTTCACCATCACCACCTACCTCGCCACTGGTATC ACCTCCCGTGGTCGTATTGGTATCGATGCTGCCCTTACTGCTCGTGCCCTCAAGAACCCCTGGTTCACCGACCCC GTCGACAAAGAGGTCCTCCTCAAGGGTATCCATGAACTCATTGACGCCATGGAGCATGTCCCCGGATTGACCCTC ATCACTCCCGACAACACGACCACCATCGAGGACTACGTCGACAACTACCCCACCGGCTGGCTCAACTCCAACCAC TGGGTCGGGTCCAACTCCATCGGAAAGGTTGTCGATGAGAACACCAAGGTCTTCAACACCGATAACCTCTTCGTT GTTGATGCTTCCATCATTCCTTCGATGCCCATGGGTAACCCACAGGGTGCTATCATGTCGACTGCTGAACAGGGT GTGGCTAGGATTCTCGCCCTCCAAGGCGGCCCTTAG |
| Length | 2286 |
Gene
| Sequence id | CC1G_09923T0 |
|---|---|
| Sequence |
>CC1G_09923T0 ATGTTGGGACGACTCTTTACGAGTCTCCTCCTCGCAGGGCTCGGTGCGTCTCATCGTCTTCATCGCACCATATTT AGAAACTAATAGTACCTTCACTAGCCCTCGCGCAGACTGAATCGTATGTCGACCCTGACACCGGGATCACCTTCC AAGGTAGAACCGACCCCGTGCACGGCGTGACCATTGGTTACGTCCTTCCACCGCTCGAGCCTGCCTCCGATGAAT TCATTGGCCAAATTCTTGCGCCCATTGAGAACGGATGGGTCGGCATTGCCCCTGGTGGAGGCATGATTAACAACC TCCTCGTCGTTGCTTGGCCTAATGGCAACGAGGTCGTTGCTTCCGTTCGGATGGCAAAGTGAGTGCACGTCTTGT GTATAACGCCCCTTGTGGAACGGAGTGCTGACCCATGGTTTTATCTTTCTATAGCACCTACGTCCTCCCTCAGTA CGTTACTCTATCAGCGCTTGCTATCTTCTACCTCGGTCCTCAGACTTATCTCCTACTCTAGACCTTTCAACGATC CTGTCCTTACCATTCTTCCATCGACCAAGGTCAACGCGACCCACTGGAAACTCGACTACCGCTGCCAAGGCTGCA CCAGTATGTACCCCCGCCTTCCAATCACACCCAACAGGTCCCTTACCACCATTTCCTTACAGCTTGGGAAACCGC CAACGGACCCCGCTCACTCCCCATCGACTCTGCCGGTGCCGCCGCCTGGGCACTCTCCAAGTCCCCCGTCGACGA CCCCTCCGACCCCGACACCACCTTCGCTCAACACACTGACTGTACGCCTTCTTCCCCGCTCTACCGTTACCCTAG GACACTGCCTAACACTCCTTTGTAGTCGGCTTCTACGGCCAAATCTGGGCTCTCTCCCATGTTGACGCTGAGACC TACGAGCACTGGGCTTCTGGAGGCACTGGTGGCGGTCCCACCCCTACCACTCCTCCCACTGAACCTCCTACTCCT ACTGAGCCTGTTCCTACCGTAGAGGTACGCATGTTTTCCTCGACTTCTGACTGCAAATGTTAAACGTGTCTTTTC CTATAGCCTACTCCCTACGACTACATCGTCGTCGGAGCCGGCCCCGGTGGATTGGTCACTGCTGACCGTCTCTCC GAGGCAGGCCACAAGGTCCTCCTTATTGAGAGGGGTGGACCCAGCTTGGGCTCGACCGGCGGTACCACTCAGCCC GATTGGTTGAAGGGAACTAACGTACGTGATTTATACTTGAATCGGGAAAGCAACACCGTACTGAGAAATGCATTC AGCTCACGAAATTCGATGTCCCTGGATTGTTCGAGACTATGTTCATGGATGCCGATCCTTACTGGTGGTGCAAGG GTACGTTTTGGACATTGCAGGGCTGTGGAGTTGTGGGTTAACCCGGCTATGGACAGACATCAACGTTTTCGCCGG ATGCTTGCTCGGCGGAGGAACTGCTATCAACGGAGGGTATGTCGCAGTGGCGTCCTTTCTCGCAAATTATCCCCT GACTAACCACCCAATAGCTTGTACTGGTACCCTCCCGACATCGATTTCTCTCACACCTACGGCTGGCCTCCCTCG TGGCAGAGCCATCACCAATACACCGACAAGCTTAAGCAGCGTATCCCCAGTACTGATGCTCCCTCGACCGATGGC AAGCGATATCTCATGGAGACCTTCGACGTCGTCGAGAAGTTGCTCCGCCCTCAAGGATACCACCAGCAAACCATC AACAACAACCCTAACCAGAAGGATAGGGTTTACGGTTACAGCGCCTACTCTGTGAGTTCCTTGTCTCCATCTCCT CCACTTCCATAACTAACAAACCACCCCCGTAGTTCATCGACGGCAAGCGCGCTGGTCCCATCGCAACCTACTACA AGACCGCCATCGCCCGACCCAACTTGACCTACTTCTCGCACACCACCGTCCTCAACGTCGTTCGTGAAGGCTCCA CCATCACCGGTGTCAACACCGACAACCCATTGATCGGTCCCAACGGCTTCGTCCCTCTCAACCCCCGCGGCCGTG TCATCCTCTCCGCTGGCGCCTTCGGCTCTGCACGTCTCCTCTTCCGCTCTGGAATTGGCCCTCGCGATATGCTCG AGATCGTCAAGAATGACAGGAACGCCGGCCCCAACATGCCCGCTGAGGAGGACTGGATCGACCTCCCTGTTGGCG AGAACGTCCAGGACAACCCTTCGATTAACTTGGTCTTCACCCACCCCGACATTGATGCCTATGAGAACTGGGCCA ACGTTTGGAGCAACCCCAGGCAGGCTGATGCTGCTCAGTATATCGACAGCCAGTCTGGCGTCTTCTCTCAATCTT CCCCTCGGTGGGTTTTAATCTTCTGCCTGTGCCTGAACGAGTAACAAACTGACGAAATCTCGTTCGCTAGTATCA ACTTCTGGAGGAAACTTATGGGCAGCGACAAGAAGCCTCGATGGGTATGTGACAATAGCGTGGGTCAGGACACCA AAATCTTAACGCCCTTCGTAGATGCAAGGAACTGCTCGCCCTGGTGCCGCCTCCATCACCACCGACTTCCCCTAC AACGCTAGCAACATCTTCACCATCACCACCTACCTGTACGTGTCAACTCTTCAACCCTTTCTAGACCCTCGCTCT GACCTTGAACCATTTCAGCGCCACTGGTATCACCTCCCGTGGTCGTATTGGTATCGATGCTGCCCTTACTGCTCG TGCCCTCAAGAACCCCTGGTTCACCGACCCCGTCGACAAAGAGGTCCTCCTCAAGGGTATCCATGAACTCATTGA CGCCATGGAGCATGGTACGTACCAGTGCTTCGTCTTACCGACTTTGACCTGAGGTTCTGTCCCACCAGTCCCCGG ATTGACCCTCATCACTCCCGACAACACGACCACCATCGAGGACTACGTCGACAACTACCCCACCGGCTGGCTCAA CTCCAACCACTGGGTCGGGTCCAACTCCATCGGAAAGGTTGTCGATGAGAACACCAAGGTCTTCAACACCGATAA CCTCTTCGTTGTTGATGCTTCCATCGTACGTCGCTTGTCATATTTTCTCAATACCAAAGGTTTTCTGACTTGTGC GATCCAGATTCCTTCGATGCCCATGGGTAACCCACAGGGTGCTATCATGTCGACTGCTGAACAGGGTGTGGCTAG GATTCTCGCCCTCCAAGGCGGCCCTTAG |
| Length | 3178 |