CC1G_10232
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10232 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NPC2 | Functional description | CMGC/CLK protein kinase |
| Location | Chr_12:1973672..1976495 | Strand | + |
| Gene length (nt) | 2824 | Transcript length (nt) | 2001 |
| CDS length (nt) | 2001 | Protein length (aa) | 666 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits | |
|---|---|---|---|---|---|
| No records | |||||
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8718 |
| Description | CMGC/CLK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 362 | 662 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K08287 |
| K08823 |
| K18669 |
EggNOG
| COG category | Description |
|---|---|
| Q | protein serine/threonine/tyrosine kinase activity |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
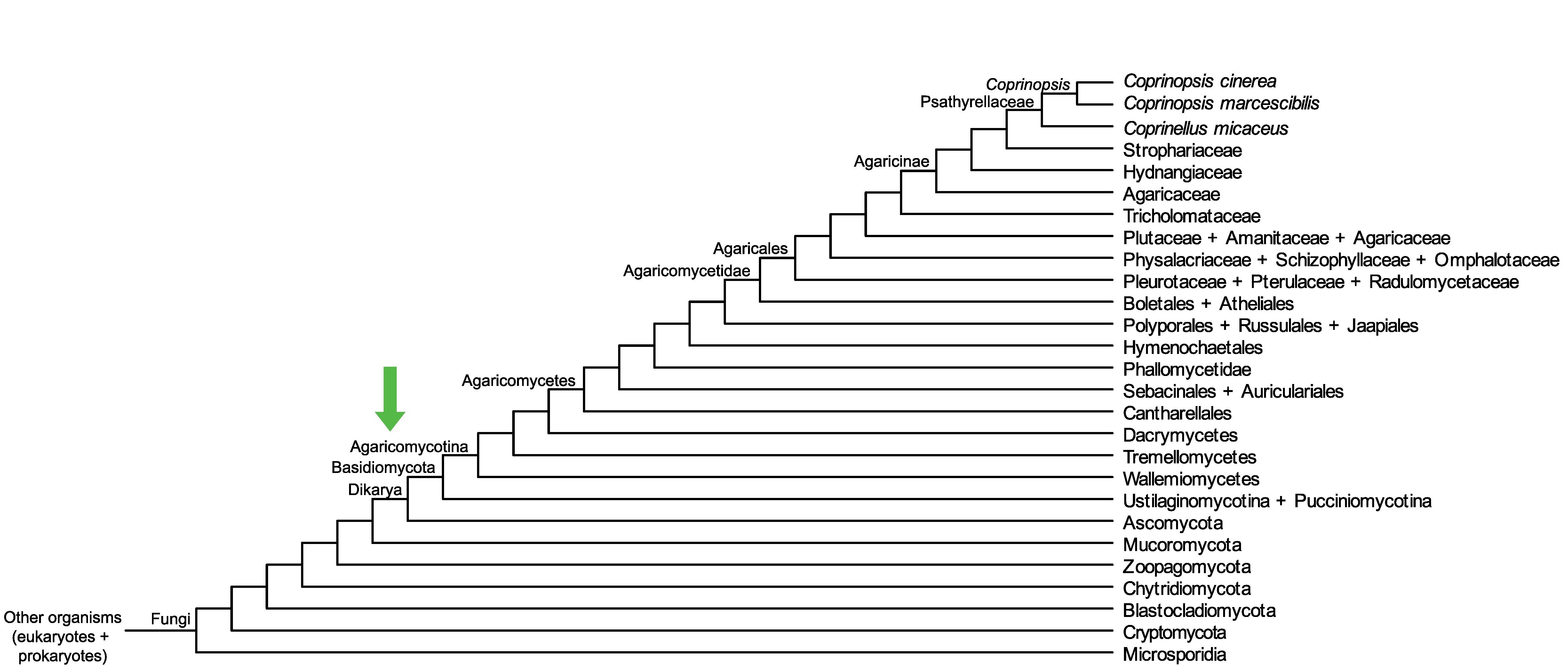
Conservation of CC1G_10232 across fungi.
Arrow shows the origin of gene family containing CC1G_10232.
Protein
| Sequence id | 8718 |
|---|---|
| Sequence |
>8718 MDTTPLLPPGLSFPYRRNGSRFELWLIKMSFPLLFTILLHLELDDLRQLGATSQRLRNLINAYRRRVWYFPRFLT AWHLGPDIFLAKMELTGAICAGWQALRFLDRLPPDPSTGLDVFVRIAGAIALGRHLFEAGYVLGRFDVPAIIQYR QFERDVLGLSGGTQIRQLMDTYGIIAWFPFKKLVVRLGRREVVRVSLAITNVNPIDFVINNSGCTAMMQIITPRR SISIFPAHTFIKRVSFLLHTDKDAVKCAISMHEKYPIPFEISSSCRGFPPDGFPLGVRWLADNTCWIQPVNDELV LDYLIQDYEHQYAAGQGKPSLATTVYNGAVTLRRIEIGDFLDKKFCVYQLGSFSGPCQTIRAREIRTGRSLLLRA IRKSSVLPDALFKDLQAVEVVSKAEDHFVRFTRLFQTELDTFLVFEDEGVPLSSIIRNNNIATFSPRQVREIVWQ TANALDFLHSHGITHGDLCPSNIKLSSIATVQEVYFDWESRSFDTRKVLKSTELRVCFFGSLGVDNRSRNHDRFR SPEVVAGIGVDYKTDIFSLGCLMKELIINRPFLYDCMDSMFYVRDKLWVMENILGSFPQELAETIEAKHAGVFTP WWRVATSSEDHFDDKIVEFVGDSDTLPELIRDRDALEVIRSMTAYRPSDRPSIWVLTSADYFRTEF |
| Length | 666 |
Coding
| Sequence id | CC1G_10232T0 |
|---|---|
| Sequence |
>CC1G_10232T0 ATGGATACCACCCCTCTGCTCCCTCCCGGGCTTTCCTTCCCTTATCGTCGCAATGGATCCAGGTTCGAGTTATGG CTCATCAAGATGAGTTTTCCCCTACTGTTTACCATACTCCTTCATCTTGAACTCGACGACCTTCGGCAACTTGGT GCAACTTCTCAAAGATTGCGCAACCTAATCAACGCCTATCGGAGGAGGGTCTGGTACTTCCCGCGTTTCCTAACT GCATGGCATCTGGGCCCAGACATTTTCCTTGCAAAGATGGAGCTTACCGGCGCGATATGTGCAGGATGGCAAGCC TTGCGATTCCTCGATCGACTTCCGCCCGACCCTTCGACTGGACTGGATGTCTTCGTGCGGATAGCGGGCGCTATA GCACTCGGACGCCACCTATTCGAGGCTGGTTATGTTCTTGGCCGCTTCGACGTACCTGCCATCATTCAGTACCGT CAATTCGAACGCGATGTCCTTGGACTTTCCGGTGGGACTCAGATACGCCAGCTCATGGACACCTATGGCATCATA GCGTGGTTTCCATTCAAGAAGTTGGTTGTTCGTTTGGGAAGGCGTGAAGTTGTGCGGGTATCCCTTGCTATAACA AATGTCAATCCTATTGACTTTGTGATCAATAACTCAGGATGCACTGCGATGATGCAGATCATTACCCCGCGTCGT TCCATCTCCATTTTTCCGGCCCACACCTTCATCAAGCGTGTCTCGTTCTTATTGCACACAGACAAGGACGCCGTG AAGTGCGCCATATCGATGCACGAGAAATACCCAATACCCTTTGAGATCTCTTCCTCCTGTCGAGGATTTCCTCCA GATGGATTCCCGTTAGGAGTGCGATGGTTAGCAGACAACACTTGCTGGATTCAGCCTGTCAACGACGAACTGGTT TTGGATTACCTGATACAGGACTACGAACACCAATATGCGGCGGGCCAAGGCAAGCCCTCGTTGGCAACAACTGTG TACAATGGGGCTGTCACACTGAGAAGGATTGAGATAGGTGACTTCCTGGACAAGAAATTTTGCGTCTACCAATTA GGTTCTTTCTCGGGGCCATGCCAGACTATAAGGGCTCGCGAGATACGGACTGGTCGGTCCTTGCTTTTGCGAGCC ATTCGGAAATCGAGTGTCCTTCCGGATGCTCTGTTCAAGGACCTCCAGGCAGTAGAAGTCGTGTCAAAGGCGGAA GACCATTTTGTGCGGTTCACTCGGCTCTTCCAGACCGAGTTAGATACCTTCTTAGTATTCGAAGATGAAGGAGTA CCGTTATCTTCTATCATCCGAAACAATAATATAGCAACATTCTCACCCCGGCAAGTACGCGAAATTGTTTGGCAA ACCGCAAACGCGTTGGACTTCTTACACTCCCATGGTATAACCCACGGCGATCTTTGTCCTTCCAACATCAAGTTG TCGAGTATCGCCACTGTCCAAGAAGTATACTTCGACTGGGAAAGTCGCTCCTTCGACACTCGGAAAGTACTGAAG TCCACCGAGCTTCGAGTATGTTTCTTCGGTTCTCTTGGGGTCGACAACCGCTCCAGGAATCACGATCGTTTTCGT TCCCCTGAGGTTGTAGCGGGCATTGGCGTTGACTACAAGACGGATATTTTCTCTCTGGGATGCTTGATGAAGGAG TTGATTATCAATCGACCATTCCTTTACGACTGCATGGATTCGATGTTCTACGTCCGAGACAAGCTGTGGGTCATG GAGAATATCCTGGGTAGTTTCCCCCAAGAGCTTGCAGAGACGATTGAGGCGAAACACGCGGGAGTCTTCACACCC TGGTGGCGTGTTGCCACTAGCAGTGAAGATCATTTCGACGACAAGATTGTGGAATTCGTGGGAGATAGCGATACA CTACCGGAATTGATTCGGGATAGGGATGCTCTAGAAGTCATCCGATCTATGACAGCCTATAGGCCCAGCGACAGG CCATCAATATGGGTTCTCACAAGCGCAGACTACTTCAGGACAGAATTC |
| Length | 2001 |
Transcript
| Sequence id | CC1G_10232T0 |
|---|---|
| Sequence |
>CC1G_10232T0 ATGGATACCACCCCTCTGCTCCCTCCCGGGCTTTCCTTCCCTTATCGTCGCAATGGATCCAGGTTCGAGTTATGG CTCATCAAGATGAGTTTTCCCCTACTGTTTACCATACTCCTTCATCTTGAACTCGACGACCTTCGGCAACTTGGT GCAACTTCTCAAAGATTGCGCAACCTAATCAACGCCTATCGGAGGAGGGTCTGGTACTTCCCGCGTTTCCTAACT GCATGGCATCTGGGCCCAGACATTTTCCTTGCAAAGATGGAGCTTACCGGCGCGATATGTGCAGGATGGCAAGCC TTGCGATTCCTCGATCGACTTCCGCCCGACCCTTCGACTGGACTGGATGTCTTCGTGCGGATAGCGGGCGCTATA GCACTCGGACGCCACCTATTCGAGGCTGGTTATGTTCTTGGCCGCTTCGACGTACCTGCCATCATTCAGTACCGT CAATTCGAACGCGATGTCCTTGGACTTTCCGGTGGGACTCAGATACGCCAGCTCATGGACACCTATGGCATCATA GCGTGGTTTCCATTCAAGAAGTTGGTTGTTCGTTTGGGAAGGCGTGAAGTTGTGCGGGTATCCCTTGCTATAACA AATGTCAATCCTATTGACTTTGTGATCAATAACTCAGGATGCACTGCGATGATGCAGATCATTACCCCGCGTCGT TCCATCTCCATTTTTCCGGCCCACACCTTCATCAAGCGTGTCTCGTTCTTATTGCACACAGACAAGGACGCCGTG AAGTGCGCCATATCGATGCACGAGAAATACCCAATACCCTTTGAGATCTCTTCCTCCTGTCGAGGATTTCCTCCA GATGGATTCCCGTTAGGAGTGCGATGGTTAGCAGACAACACTTGCTGGATTCAGCCTGTCAACGACGAACTGGTT TTGGATTACCTGATACAGGACTACGAACACCAATATGCGGCGGGCCAAGGCAAGCCCTCGTTGGCAACAACTGTG TACAATGGGGCTGTCACACTGAGAAGGATTGAGATAGGTGACTTCCTGGACAAGAAATTTTGCGTCTACCAATTA GGTTCTTTCTCGGGGCCATGCCAGACTATAAGGGCTCGCGAGATACGGACTGGTCGGTCCTTGCTTTTGCGAGCC ATTCGGAAATCGAGTGTCCTTCCGGATGCTCTGTTCAAGGACCTCCAGGCAGTAGAAGTCGTGTCAAAGGCGGAA GACCATTTTGTGCGGTTCACTCGGCTCTTCCAGACCGAGTTAGATACCTTCTTAGTATTCGAAGATGAAGGAGTA CCGTTATCTTCTATCATCCGAAACAATAATATAGCAACATTCTCACCCCGGCAAGTACGCGAAATTGTTTGGCAA ACCGCAAACGCGTTGGACTTCTTACACTCCCATGGTATAACCCACGGCGATCTTTGTCCTTCCAACATCAAGTTG TCGAGTATCGCCACTGTCCAAGAAGTATACTTCGACTGGGAAAGTCGCTCCTTCGACACTCGGAAAGTACTGAAG TCCACCGAGCTTCGAGTATGTTTCTTCGGTTCTCTTGGGGTCGACAACCGCTCCAGGAATCACGATCGTTTTCGT TCCCCTGAGGTTGTAGCGGGCATTGGCGTTGACTACAAGACGGATATTTTCTCTCTGGGATGCTTGATGAAGGAG TTGATTATCAATCGACCATTCCTTTACGACTGCATGGATTCGATGTTCTACGTCCGAGACAAGCTGTGGGTCATG GAGAATATCCTGGGTAGTTTCCCCCAAGAGCTTGCAGAGACGATTGAGGCGAAACACGCGGGAGTCTTCACACCC TGGTGGCGTGTTGCCACTAGCAGTGAAGATCATTTCGACGACAAGATTGTGGAATTCGTGGGAGATAGCGATACA CTACCGGAATTGATTCGGGATAGGGATGCTCTAGAAGTCATCCGATCTATGACAGCCTATAGGCCCAGCGACAGG CCATCAATATGGGTTCTCACAAGCGCAGACTACTTCAGGACAGAATTCTAG |
| Length | 2001 |
Gene
| Sequence id | CC1G_10232T0 |
|---|---|
| Sequence |
>CC1G_10232T0 ATGGATACCACCCCTCTGCTCCCTCCCGGGCTTTCCTTCCCTTATCGTCGCAATGGATCCAGGTTCGAGTTATGG CTCATCAAGATGAGTTTTCCCCTACTGTTTACCATACTCCTTCATCTTGAACTCGACGACCTTCGGCAACTTGGT GCAACTTCTCAAAGATTGCGCAACCTAATCAACGCCTATCGGAGGAGGGTCTGGTACTTCCCGCGTTTCCTAACT GCATGGCATCTGGGCCCAGACATTTTCCTTGCAAAGATGGAGCTTACCGGCGCGATATGTGCAGGATGGCAAGCC TTGCGATTCCTCGATCGACTTCCGCCCGACCCTTCGACTGGACTGGATGTCTTCGTGCGGATAGCGGGCGCTATA GCACTCGGACGCCACCTATTCGAGGCTGGTTATGTTCTTGGCCGCTTCGACGTACCTGCCATCATTCAGTACCGT CAATTCGAACGCGATGTCCTTGGACTTTCCGGTGGGACTCAGATACGCCAGCTCATGGACACCTATGGCATCATA GCGTGGTTTCCATTCAAGAAGTTGGTTGTTCGTTTGGGAAGGCGTGAAGTTGTGCGGGTATCCCTTGCTATAACA AATGTCAATCCTATTGACTTTGTGATCAATAACTCAGGATGCAGTAAGTAGGGCTTTCACTTCGAATGGCAATTC CAACGGATTTATTCATTCTCCTAGCTGCGATGATGCAGATCATTACCCCGCGTCGTTCCATCTCCATTTTTCCGG CCCACACCTTCATCAAGCGTGTCTCGTTCTTATTGCACACAGACAAGGACGCCGTGAAGTGCGCCATATCGATGC ACGAGAAATACCCAATACCCTTTGAGATCTCTTCCTCCTGTCGAGGATTTCCTCCAGATGGATTCCCGTTAGGAG TGCGATGGTTAGCAGACAACACTTGCTGGATTCAGCCTGTCAACGGTATGCAGCGTCTACCTTGAGCCGTGAAGT TTGAATCTCATCGGTTGCCTTTAGACGAACTGGTTTTGGATTACCTGATACAGGACTACGAACACCAATATGCGT ACGCGAGTACACCTTTACGTCATTTTGTCTTCAAGACGGAGGTTGAGCGACTCCACGGAACCTTTCGATGGGTTT ACAAGATACATTCTTACGCGCCCCCCACCTTCCTGATGCAAGCACAACTTGTTACGACGTAGAACCTGGAGGATT TTTCGCTGTTCGTACCTTAATTATATTGTCGTCATCGAGGCACTATGGCACAATTATTGTTATCGTGTGTGCCCC GGTTTGATCTTCCATCGGATGCTTTCACTGATACCTGTACGGACACCGATCCTCCTGGAATCGGAAGCACGAGAA ACTGAATGAGACCTGAAGGGAGTGAACACACTCCTACTGTTATAACTAGGGCGGGCCAAGGCAAGCCCTCGTTGG CAACAACTGTGTACAATGGGGTGAGTCACCTGCGCCTTCACCAGTTGATGGGAGACTTAAGGCTGTCACACTGAG AAGGATTGAGATAGGTGACTTCCTGGACAAGAAATGTAAGTGAACGAGATTACCAGGCGTCCAATACCTTGGCTC ATCGTTCCCTTAGTTTGCGTCTACCAATTAGGTTCTTTCTCGGGGCCATGCCAGACTATAAGGGCTCGCGAGATA CGGACTGGTCGGTCCTTGCTTTTGCGAGCCATTCGGAAATCGAGTGTCCTTCCGGATGCTCTGTTCAAGGACCTC CAGGCAGTAGAAGTCGTGTCAAAGGCGGAAGAGTGAGTACACCTGCCCTTCATATTTCACCTCCACCTAATAAGA ACAAGCCATTTTGTGCGGTTCACTCGGCTCTTCCAGACCGAGTTAGATACCTTCTTAGTATTCGAAGATGAAGGA GTACCGTTATCTTCTATCATCCGAAACAATAATATAGCAACATTCTCACCCCGGCAAGTACGCGAAATTGTTTGG CAAACCGCAAACGCGTTGGACTGTGAGTAATTCATGCTTCGGTTGTTTTGATGCATTGAACCCAATCTTTCGCGG ACCTAGTCTTACACTCCCATGGTATAACCCACGGCGATCTTTGTCCTTCCAACATCAAGTTGTCGAGTATCGCCA CTGTCCAAGAAGTATACTTCGACTGGGAAAGTCGCTCCTTCGACACTCGGGTCCGTCTTATGTTTTATGGTCACG TAGAGATGCTGAGACGGAGACGAATGTTCATTTAGAAAGTACTGAAGTCCACCGAGCTTCGAGTATGTTTCTTCG GTTCTCTTGGGGTCGACAACCGCTCCAGGAATCACGATCGTTTTCGTTCCCCTGAGGTTGTAGCGGGTATGTAAT AGTCCAACGTAACTCATATTTGTTCTCATCCTCTGCAGGCATTGGCGTTGACTACAAGACGGATATTTTCTCTCT GGGATGCTTGATGAAGGAGTTGATTATCAATCGACCATTCCTTTACGACTGCATGGATTCGATGTTCTACGTCCG AGACAAGCTGTGGGTCATGGAGAATATCCTGGGTAGTTTCCCCCAAGAGCTTGCAGAGACGATTGAGGCGAAACA CGCGGGAGTCTTCACACCCTGGTGGCGTGTTGCCACTAGCAGTGAAGATCATTTCGACGACAAGATTGTGGAATT CGTGGGAGATAGCGATACACTACCGGTGCGTATTTGGCATTAGAGACACTGCATACAAGTATCTCAGAACCCGCC CCAGGAATTGATTCGGGATAGGGATGCTCTAGAAGTCATCCGATCTATGACAGCCTATAGGCCCAGCGACAGGCC ATCAATATGGGTTCTCACAAGCGCAGACTACTTCAGGACAGAATTCTAG |
| Length | 2824 |