CC1G_10446
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10446 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8PDT1 | Functional description | Mala s 12 allergen |
| Location | Chr_7:377099..379910 | Strand | + |
| Gene length (nt) | 2812 | Transcript length (nt) | 2496 |
| CDS length (nt) | 2088 | Protein length (aa) | 695 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Aspergillus nidulans | AN4006 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_105031 | 48.8 | 1.461E-208 | 659 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB27685 | 46.8 | 2.602E-206 | 653 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_205329 | 46.7 | 7.998E-206 | 651 |
| Auricularia subglabra | Aurde3_1_1236104 | 45.6 | 4.133E-183 | 586 |
| Schizophyllum commune H4-8 | Schco3_2511180 | 45.9 | 6.875E-182 | 582 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1451848 | 45.2 | 7.056E-180 | 576 |
| Pleurotus ostreatus PC9 | PleosPC9_1_117616 | 45.1 | 5.872E-180 | 576 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1088797 | 45 | 1.423E-178 | 572 |
| Flammulina velutipes | Flave_chr08AA01120 | 45.3 | 1.224E-170 | 549 |
| Lentinula edodes NBRC 111202 | Lenedo1_1061718 | 43 | 1.326E-170 | 549 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_4405 | 43 | 2.902E-170 | 548 |
| Lentinula edodes B17 | Lened_B_1_1_3883 | 42.8 | 9.332E-149 | 485 |
| Grifola frondosa | Grifr_OBZ73613 | 35.7 | 3.393E-112 | 378 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8902 |
| Description | Mala s 12 allergen |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00732 | GMC oxidoreductase | IPR000172 | 49 | 372 |
| Pfam | PF05199 | GMC oxidoreductase | IPR007867 | 495 | 632 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 20 | 0.9644 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR007867 | Glucose-methanol-choline oxidoreductase, C-terminal |
| IPR027424 | Glucose Oxidase, domain 2 |
| IPR036188 | FAD/NAD(P)-binding domain superfamily |
| IPR000172 | Glucose-methanol-choline oxidoreductase, N-terminal |
| IPR012132 | Glucose-methanol-choline oxidoreductase |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0016614 | oxidoreductase activity, acting on CH-OH group of donors | MF |
| GO:0050660 | flavin adenine dinucleotide binding | MF |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| E | Belongs to the GMC oxidoreductase family |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| AA | AA3 | AA3_2 |
Transcription factor
| Group |
|---|
| No records |
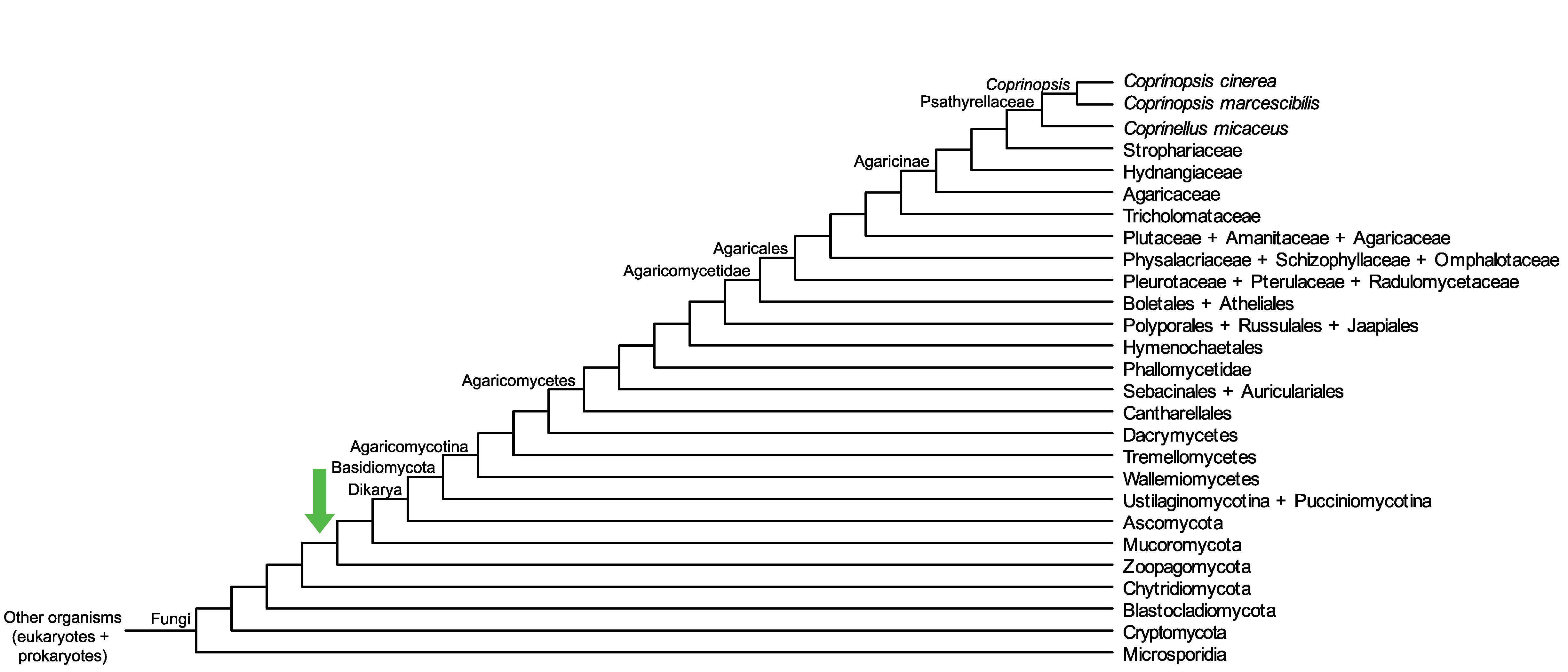
Conservation of CC1G_10446 across fungi.
Arrow shows the origin of gene family containing CC1G_10446.
Protein
| Sequence id | 8902 |
|---|---|
| Sequence |
>8902 MLSLELLVLTLTALTAPVLAHRDYNNVHARRFGLTPRDYITPETRLESYDYIIAGGGLAGLVLASKLSADGETTV LVLEAGGTGDEQRETIDRPGLTYFRSLLNTEHDYAYKTTPQDGAGGRIMNWPRGKILGGSSAVNGMYLVRPNALE VNAMHEMNADNDAKEYADAWTWDSLLEAMKQGETFTPPTQEALDVAGMRFNPDSHGSSGPLQATYSAYMVPISSA WLPTLEAAGVPISNDAYSGDNVGGFFSIMAINPSNWTRSYAKSAYIDNLPPRSNLHILTNSAVTRILFADNAQDG LQVASGVEFASDANDTPKTVLANKEVILAGGAVGSPHMLLVSGVGDRALLESLDIPVRVDLPGVGHHMQDHLAVS VAWSTEEDTQGTIFESGSEFSQSPEFLSFVNSGTSYVNGRFLFDGQEQFDAYLQGLRDTFSSADDLAPLLPGTSD EVDEGYRTIYQTLVDKVYPEAGLVEMLYSINAAGRIIVQAAIQTPLSQGRLSINSTSIFDPPVVDPKYFSHPGDI VLMRQGVKQVRRMSTLSPLRDILGDELSPGPDVQSDEDIENWIRQNANTEFHPGCTCVMLPRDKGGVIDQSLKVH GTANLRVIDGSIFPLSMSAHLMAPIYGVAEKAAELILNPPSSSGGGSGGKGGSSGGKGGSGKNDEDDDESAAAGL SSSLFITVAGSLFTALLSAF |
| Length | 695 |
Coding
| Sequence id | CC1G_10446T0 |
|---|---|
| Sequence |
>CC1G_10446T0 ATGCTGTCTCTTGAACTTCTCGTTCTTACGCTAACGGCACTAACCGCCCCTGTTCTCGCCCATCGCGACTACAAC AATGTTCACGCCCGACGGTTTGGTCTAACCCCTCGGGACTACATCACCCCCGAAACACGACTCGAATCCTACGAC TATATCATTGCCGGAGGAGGTCTTGCAGGACTGGTACTTGCTTCCAAGCTCTCGGCTGATGGGGAAACCACTGTT CTCGTCCTCGAGGCTGGAGGAACAGGCGACGAGCAGAGAGAGACTATTGACCGTCCTGGCTTGACATACTTCCGC TCTCTCCTCAACACCGAGCACGATTATGCCTACAAGACCACCCCTCAGGACGGTGCTGGTGGTCGTATCATGAAC TGGCCTCGTGGAAAGATCCTTGGAGGCTCTTCTGCGGTTAACGGCATGTATCTCGTTCGACCCAACGCGCTCGAA GTTAATGCCATGCACGAGATGAACGCCGATAACGACGCCAAGGAATATGCTGACGCGTGGACCTGGGACTCCCTT CTCGAAGCTATGAAGCAGGGCGAGACCTTCACCCCTCCCACCCAGGAAGCCCTCGATGTTGCGGGCATGCGCTTC AACCCGGACAGCCATGGCTCCAGCGGACCTCTGCAGGCCACTTACTCTGCCTACATGGTTCCCATCTCGAGCGCA TGGCTCCCGACCCTCGAAGCTGCTGGTGTTCCCATTTCCAATGACGCCTACTCCGGAGACAACGTTGGCGGCTTC TTCAGTATCATGGCAATCAACCCCTCCAACTGGACTCGATCATACGCCAAGTCTGCCTATATCGACAACCTTCCT CCCCGCTCCAACCTCCACATCCTCACCAACAGTGCCGTCACCCGTATCCTCTTTGCCGACAATGCTCAAGATGGC CTCCAGGTCGCGAGCGGAGTCGAGTTCGCCAGCGATGCCAATGATACTCCCAAGACTGTTCTCGCCAACAAGGAA GTGATTCTCGCTGGTGGTGCCGTCGGCAGCCCACACATGTTGTTGGTCAGCGGTGTTGGTGACAGGGCACTGCTT GAGAGCTTGGACATCCCCGTTCGTGTGGACCTCCCTGGTGTTGGCCACCACATGCAAGACCATTTGGCCGTCAGC GTCGCCTGGAGCACTGAGGAAGACACCCAAGGCACCATCTTCGAATCCGGATCCGAGTTCTCTCAATCCCCCGAG TTCCTTTCCTTCGTAAACTCCGGTACTTCCTATGTCAACGGACGATTCCTGTTCGACGGCCAGGAGCAATTCGAC GCCTACCTCCAAGGTCTCCGTGACACCTTCAGCAGCGCCGATGATCTCGCTCCCCTCCTCCCAGGCACCAGCGAC GAGGTTGATGAGGGTTACAGGACCATCTACCAGACTTTGGTCGACAAGGTCTACCCCGAGGCTGGCCTGGTCGAG ATGCTTTACAGCATCAACGCTGCCGGTCGCATCATCGTCCAGGCTGCAATCCAGACCCCTCTGAGCCAAGGCCGC CTCTCCATCAACTCGACCTCGATCTTCGACCCGCCCGTCGTTGACCCCAAGTACTTCTCCCACCCCGGCGATATC GTCCTCATGCGCCAAGGTGTGAAGCAGGTCCGCCGCATGTCGACCCTCTCACCCCTCCGTGATATCCTTGGCGAC GAGCTCAGCCCCGGTCCTGATGTCCAGTCCGACGAGGACATCGAGAACTGGATCAGGCAGAATGCCAACACCGAG TTCCACCCCGGCTGCACTTGCGTGATGTTGCCCCGCGACAAGGGCGGTGTTATCGACCAGTCCCTCAAGGTTCAC GGTACCGCCAACCTCCGCGTTATTGATGGATCCATCTTCCCTCTCTCTATGTCCGCTCACTTGATGGCCCCGATC TACGGTGTCGCCGAGAAGGCTGCCGAACTCATCCTCAACCCTCCCTCGTCATCCGGCGGTGGCTCTGGTGGCAAG GGCGGCTCCTCTGGTGGCAAAGGTGGATCCGGCAAGAACGACGAAGATGACGACGAGAGCGCAGCTGCTGGTCTT TCCAGCTCGCTCTTCATCACTGTCGCTGGTTCCCTCTTCACCGCTCTCCTCAGCGCTTTC |
| Length | 2088 |
Transcript
| Sequence id | CC1G_10446T0 |
|---|---|
| Sequence |
>CC1G_10446T0 CGCACCTTTATCCACTGGCGGGAGACGTTCTGAACCTCCCTCCCTTTCGTTCTTTACCCTAAATCACCTTTTTCT TCCTCCTTTCCGCCCGATGCTGTCTCTTGAACTTCTCGTTCTTACGCTAACGGCACTAACCGCCCCTGTTCTCGC CCATCGCGACTACAACAATGTTCACGCCCGACGGTTTGGTCTAACCCCTCGGGACTACATCACCCCCGAAACACG ACTCGAATCCTACGACTATATCATTGCCGGAGGAGGTCTTGCAGGACTGGTACTTGCTTCCAAGCTCTCGGCTGA TGGGGAAACCACTGTTCTCGTCCTCGAGGCTGGAGGAACAGGCGACGAGCAGAGAGAGACTATTGACCGTCCTGG CTTGACATACTTCCGCTCTCTCCTCAACACCGAGCACGATTATGCCTACAAGACCACCCCTCAGGACGGTGCTGG TGGTCGTATCATGAACTGGCCTCGTGGAAAGATCCTTGGAGGCTCTTCTGCGGTTAACGGCATGTATCTCGTTCG ACCCAACGCGCTCGAAGTTAATGCCATGCACGAGATGAACGCCGATAACGACGCCAAGGAATATGCTGACGCGTG GACCTGGGACTCCCTTCTCGAAGCTATGAAGCAGGGCGAGACCTTCACCCCTCCCACCCAGGAAGCCCTCGATGT TGCGGGCATGCGCTTCAACCCGGACAGCCATGGCTCCAGCGGACCTCTGCAGGCCACTTACTCTGCCTACATGGT TCCCATCTCGAGCGCATGGCTCCCGACCCTCGAAGCTGCTGGTGTTCCCATTTCCAATGACGCCTACTCCGGAGA CAACGTTGGCGGCTTCTTCAGTATCATGGCAATCAACCCCTCCAACTGGACTCGATCATACGCCAAGTCTGCCTA TATCGACAACCTTCCTCCCCGCTCCAACCTCCACATCCTCACCAACAGTGCCGTCACCCGTATCCTCTTTGCCGA CAATGCTCAAGATGGCCTCCAGGTCGCGAGCGGAGTCGAGTTCGCCAGCGATGCCAATGATACTCCCAAGACTGT TCTCGCCAACAAGGAAGTGATTCTCGCTGGTGGTGCCGTCGGCAGCCCACACATGTTGTTGGTCAGCGGTGTTGG TGACAGGGCACTGCTTGAGAGCTTGGACATCCCCGTTCGTGTGGACCTCCCTGGTGTTGGCCACCACATGCAAGA CCATTTGGCCGTCAGCGTCGCCTGGAGCACTGAGGAAGACACCCAAGGCACCATCTTCGAATCCGGATCCGAGTT CTCTCAATCCCCCGAGTTCCTTTCCTTCGTAAACTCCGGTACTTCCTATGTCAACGGACGATTCCTGTTCGACGG CCAGGAGCAATTCGACGCCTACCTCCAAGGTCTCCGTGACACCTTCAGCAGCGCCGATGATCTCGCTCCCCTCCT CCCAGGCACCAGCGACGAGGTTGATGAGGGTTACAGGACCATCTACCAGACTTTGGTCGACAAGGTCTACCCCGA GGCTGGCCTGGTCGAGATGCTTTACAGCATCAACGCTGCCGGTCGCATCATCGTCCAGGCTGCAATCCAGACCCC TCTGAGCCAAGGCCGCCTCTCCATCAACTCGACCTCGATCTTCGACCCGCCCGTCGTTGACCCCAAGTACTTCTC CCACCCCGGCGATATCGTCCTCATGCGCCAAGGTGTGAAGCAGGTCCGCCGCATGTCGACCCTCTCACCCCTCCG TGATATCCTTGGCGACGAGCTCAGCCCCGGTCCTGATGTCCAGTCCGACGAGGACATCGAGAACTGGATCAGGCA GAATGCCAACACCGAGTTCCACCCCGGCTGCACTTGCGTGATGTTGCCCCGCGACAAGGGCGGTGTTATCGACCA GTCCCTCAAGGTTCACGGTACCGCCAACCTCCGCGTTATTGATGGATCCATCTTCCCTCTCTCTATGTCCGCTCA CTTGATGGCCCCGATCTACGGTGTCGCCGAGAAGGCTGCCGAACTCATCCTCAACCCTCCCTCGTCATCCGGCGG TGGCTCTGGTGGCAAGGGCGGCTCCTCTGGTGGCAAAGGTGGATCCGGCAAGAACGACGAAGATGACGACGAGAG CGCAGCTGCTGGTCTTTCCAGCTCGCTCTTCATCACTGTCGCTGGTTCCCTCTTCACCGCTCTCCTCAGCGCTTT CTAAAGCTCCTCCTGTCTGACTGACTGACTGACTAACTAACGATATGGACGTTCTATGACCCTTCGGATTCCCAT TGCTGGATTTGTTTCTTGACCACGACACTCATTTGGCTGTCTTATGGACTTGACTTGATACTCGTATATCTTTTC GTTCATTCCTAGCCTAATGAACAGGGACTTTCCATGCGACCTTTTGATACCATCGCTGTAGATGACGCTGTTATA TTAGAGAAAGATGTAATACTGTTGCAAAGTAGTTACCCCCCCCCCCCCCTGTGTAGCATAGGAATGAACGGACTA TTGTTTGATTTTTGGAACTTA |
| Length | 2496 |
Gene
| Sequence id | CC1G_10446T0 |
|---|---|
| Sequence |
>CC1G_10446T0 CGCACCTTTATCCACTGGCGGGAGACGTTCTGAACCTCCCTCCCTTTCGTTCTTTACCCTAAATCACCTTTTTCT TCCTCCTTTCCGCCCGATGCTGTCTCTTGAACTTCTCGTTCTTACGCTAACGGCACTAACCGCCCCTGTTCTCGC CCATCGCGACTACAACAATGTTCACGCCCGACGGTTTGGTCTAACCCCTCGGGACTACATCACCCCCGAAACACG ACTCGAATCCTACGACTATATCATTGCCGGAGGAGGTCTTGCAGGACTGGTACTTGCTTCCAAGCTCTCGGCTGA TGGGGAAACCACTGTTCTCGTCCTCGAGGCTGGAGGAACAGGCGACGAGCAGAGAGAGACTATTGGTGCGTCCCT TCTGAAATAACATCCTTGAATTATCAACTAACGTCCTCTAGACCGTCCTGGCTTGACATACTTCCGCTCTCTCCT CAACACCGAGCACGATTATGCCTACAAGACCACCCCTCAGGACGGTGCTGGTGGTCGTATCATGAACTGGCCTCG TGGAAAGGTGAGCTTCGATGCATCCTGGTACGTTAATGCTTCTTGCTAACTAAGGCTAGATCCTTGGAGGCTCTT CTGCGGTTAACGGCATGTATCTCGTTCGACCCAACGCGCTCGAAGTTAATGCCATGCACGAGATGAACGCCGATA ACGACGCCAAGGAATATGCTGACGCGTGGACCTGGGACTCCCTTCTCGAAGCTATGAAGCAGGGCGAGACCTTCA CCCCTCCCACCCAGGAAGCCCTCGATGTTGCGGGCATGCGCTTCAACCCGGACAGCCATGGCTCCAGCGGACCTC TGCAGGCCACTTACTCTGCCTAGTGAGTGCCACCCGTATTTGCATCTGAAGCTTTGTCTAACCCTTTTCCAGCAT GGTTCCCATCTCGAGCGCATGGCTCCCGACCCTCGAAGCTGCTGGTGTTCCCATTTCCAATGACGCCTACTCCGG AGACAACGTTGGCGGCTTCTTCAGTATCATGGCAATCAACCCCTCCAACTGGACTCGATCATACGCCAAGTCTGC CTATATCGACAACCTTCCTCCCCGCTCCAACCTCCACATCCTCACCAACAGTGCCGTCACCCGTATCCTCTTTGC CGACAATGCTCAAGATGGCCTCCAGGTCGCGAGCGGAGTCGAGTTCGCCAGCGATGCCAATGATACTCCCAAGAC TGTTCTCGCCAACAAGGAAGTGATTCTCGCTGGTGGTGCCGTCGGCAGCCCACACATGTTGTTGGTCAGCGGTGT TGGTGACAGGGCACTGCTTGAGAGCTTGGACATCCCCGTTCGTGTGGACCTCCCTGGTGTTGGCCACCACATGCA AGACCATTTGGTGAGTTCCTTTGTTCATCATTCCTTACTGACACATCTGACGGGTACCCTAGGCCGTCAGCGTCG CCTGGAGCACTGAGGAAGACACCCAAGGCACCATCTTCGAATCCGGATCCGAGTTCTCTGTAAGTCGCAACGTTT CCATCGCTGTGCACATCGACTCATCGTTGCCATTAGCAATCCCCCGAGTTCCTTTCCTTCGTAAACTCCGGTACT TCCTATGTCAACGGACGATTCCTGTTCGACGGCCAGGAGCAATTCGACGCCTACCTCCAAGGTCTCCGTGACACC TTCAGCAGCGCCGATGATCTCGCTCCCCTCCTCCCAGGCACCAGCGACGAGGTTGATGAGGGTTACAGGACCATC TACCAGACTTTGGTCGACAAGGTCTACCCCGAGGCTGGCCTGGTCGAGATGCTTTACAGCATCAACGCTGCCGGT CGCATCATCGTCCAGGCTGCAATCCAGACCCCTCTGAGCCAAGGCCGCCTCTCCATCAACTCGACCTCGATCTTC GACCCGCCCGTCGTTGACCCCAAGTACTTCTCCCACCCCGGCGATATCGTCCTCATGCGCCAAGGTGTGAAGCAG GTCCGCCGCATGTCGACCCTCTCACCCCTCCGTGATATCCTTGGCGACGAGCTCAGCCCCGGTCCTGATGTCCAG TCCGACGAGGACATCGAGAACTGGATCAGGCAGAATGCCAACACCGAGTTCCACCCCGGCTGCACTTGCGTGATG TTGCCCCGCGACAAGGGCGGTGTTATCGACCAGTCCCTCAAGGTTCACGGTACCGCCAACCTCCGCGTTATTGAT GGATCCATCTTCCCTCTCTCTATGTCCGCTCACGTATGTTCCCTCGTTACCATGTGCTCCGTTTACAATGCTGAT TGACCTTTGCTCTTCAGTTGATGGCCCCGATCTACGGTGTCGCCGAGAAGGCTGCCGAACTCATCCTCAACCCTC CCTCGTCATCCGGCGGTGGCTCTGGTGGCAAGGGCGGCTCCTCTGGTGGCAAAGGTGGATCCGGCAAGAACGACG AAGATGACGACGAGAGCGCAGCTGCTGGTCTTTCCAGCTCGCTCTTCATCACTGTCGCTGGTTCCCTCTTCACCG CTCTCCTCAGCGCTTTCTAAAGCTCCTCCTGTCTGACTGACTGACTGACTAACTAACGATATGGACGTTCTATGA CCCTTCGGATTCCCATTGCTGGATTTGTTTCTTGACCACGACACTCATTTGGCTGTCTTATGGACTTGACTTGAT ACTCGTATATCTTTTCGTTCATTCCTAGCCTAATGAACAGGGACTTTCCATGCGACCTTTTGATACCATCGCTGT AGATGACGCTGTTATATTAGAGAAAGATGTAATACTGTTGCAAAGTAGTTACCCCCCCCCCCCCCTGTGTAGCAT AGGAATGAACGGACTATTGTTTGATTTTTGGAACTTA |
| Length | 2812 |