CC1G_10524
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10524 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8N1A3 | Functional description | STE/STE11 protein kinase |
| Location | Chr_1:1485682..1488683 | Strand | + |
| Gene length (nt) | 3002 | Transcript length (nt) | 2747 |
| CDS length (nt) | 2538 | Protein length (aa) | 845 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB29221 | 36.7 | 3.806E-130 | 437 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_1005 | 33.1 | 7.708E-127 | 427 |
| Lentinula edodes NBRC 111202 | Lenedo1_1124773 | 33.6 | 3.68E-126 | 425 |
| Agrocybe aegerita | Agrae_CAA7258667 | 34.3 | 9.126E-123 | 415 |
| Lentinula edodes B17 | Lened_B_1_1_18077 | 32.5 | 7.099E-122 | 412 |
| Schizophyllum commune H4-8 | Schco3_2684679 | 33.6 | 2.213E-121 | 411 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_103706 | 34 | 9.025E-108 | 370 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_140569 | 33.8 | 4.048E-107 | 368 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 8961 |
| Description | STE/STE11 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 95 | 359 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K11229 |
EggNOG
| COG category | Description |
|---|---|
| T | Ste ste11 protein kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
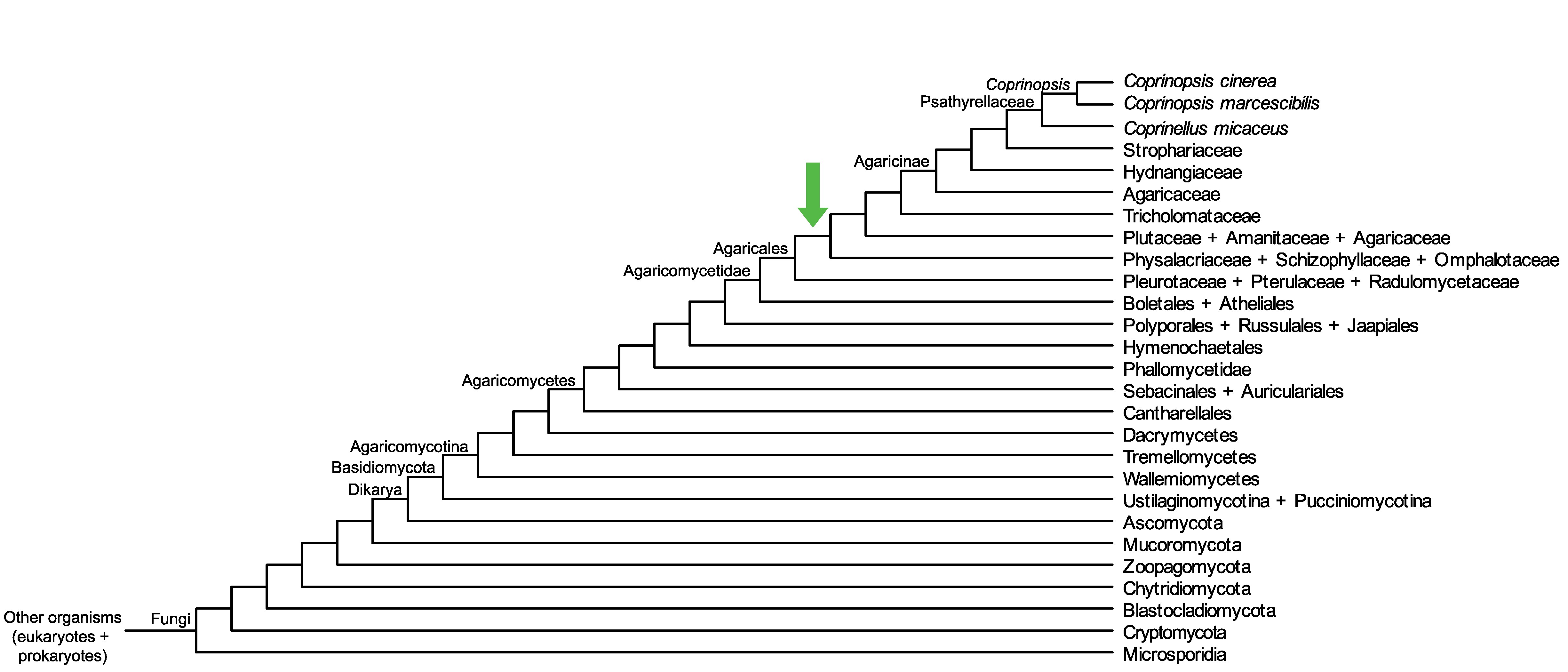
Conservation of CC1G_10524 across fungi.
Arrow shows the origin of gene family containing CC1G_10524.
Protein
| Sequence id | 8961 |
|---|---|
| Sequence |
>8961 MDSRPASTLRTLQTWAVPFRETVPPVPDLPGRLLPQPSSSPHNSALDNAPDYSDSDDDDSIWQARPRERQPRRSS GQRLPYQRSFVKPTFQWIRGELLGKGSYGRVYLALNATTGEVMAVKQVELPKTPSDKMKPQQLDVMKALKFEGDT LKDLDHPNIVSYLGFEESQDYLSIFLEYVPGGTVGSLLVKNGRLREEVTKSWLRQILQGLDYLHGKGILHRDLKA DNILVDHSGVCKISDFGISKKAGEINRAKAHTGMKGTSFWMAPEILSPGEKGYDVKVDIWSVGCVAVEMWTGKRP WYGHEWWPVLMKVAEDKSPPPIPEDIPMGHLAQSFHNQCFRPDPADRPHASVMLKHPYLEIQSPWVFNWDDLADN SRPPRIYPELVPPVVRERTVTQSTFKANGPPTEKPRAHKPPLEPLKIPAYGPTSTQRKPSVNGAGPPVVWITPPN TPRRTAKPEDSSASTSTSDAAPWKSTSKRRLVIVNPDLDDDIGPAPQNTPPKPKFVYTPPPLPDPPQPPYASSPR PLRHAVSTSFASVSSMGSISSKAGSPSRPRALVDPGLSSTRTPPRPLPNPLSPPLGRSPAPLPVLPSPSKRRGSS RDRSHTVHTTFDASASKLYEEGNPTAKASVHNLPISSSGSRTIRRLPISPQQLNHGRPATTTTPSMPGSSTPRPL RPQKSVPDVSIFAFSRDAYHSRHHPSFKSKSNRPLYTSRGSFDSEPEDINGASDNDSVSSTSTTHTKHPQRGESL LAMRPRTEDVYKDLEAWFPNHDLDRPVDGADTPASGALEPRHHRVDVRKSIRMIAKEQNRRSHNDPASSRRRTML WNTHMEELSSDKRKDSMPRF |
| Length | 845 |
Coding
| Sequence id | CC1G_10524T0 |
|---|---|
| Sequence |
>CC1G_10524T0 ATGGATAGTAGGCCCGCGTCCACCCTGCGCACCCTCCAGACATGGGCTGTCCCTTTCAGAGAGACAGTCCCACCC GTTCCAGATCTTCCTGGTCGCCTACTGCCCCAGCCATCTTCGTCTCCTCACAATTCTGCCCTTGACAATGCCCCG GACTACTCGGACTCGGACGACGATGATAGTATCTGGCAAGCTAGACCTCGCGAACGCCAACCTCGGAGATCTTCA GGCCAGCGCCTGCCCTACCAGCGATCGTTTGTTAAGCCAACGTTCCAATGGATCAGAGGGGAGCTTCTTGGGAAA GGAAGCTATGGACGGGTTTACCTTGCCCTCAACGCAACCACAGGGGAGGTCATGGCAGTCAAGCAGGTCGAGCTA CCAAAGACCCCCAGTGACAAGATGAAGCCTCAGCAGCTAGACGTTATGAAAGCTCTCAAATTCGAGGGAGATACC CTCAAGGACTTGGATCATCCCAATATTGTCTCTTACCTCGGGTTCGAAGAGAGCCAGGACTACTTGAGCATTTTC CTGGAATATGTTCCAGGCGGTACAGTCGGGTCTCTCCTGGTAAAAAATGGTCGACTGCGGGAGGAAGTCACCAAG TCATGGCTTAGACAAATTCTTCAAGGGTTGGACTACCTCCACGGTAAAGGCATCCTTCACAGAGACTTGAAGGCG GATAACATCCTCGTCGACCATTCCGGGGTTTGCAAGATATCAGACTTTGGTATCTCCAAGAAGGCAGGGGAAATT AATCGTGCAAAAGCGCACACCGGAATGAAAGGTACCAGTTTCTGGATGGCACCAGAGATACTGTCACCCGGAGAG AAAGGGTACGATGTCAAGGTTGACATCTGGAGTGTGGGCTGCGTGGCTGTGGAAATGTGGACCGGTAAACGCCCA TGGTACGGCCACGAATGGTGGCCTGTGTTGATGAAGGTTGCTGAGGACAAGTCACCGCCCCCAATCCCTGAGGAT ATACCGATGGGTCATCTGGCACAGAGTTTCCACAATCAATGTTTTCGCCCAGATCCCGCCGACCGACCACATGCC TCTGTGATGCTTAAGCACCCTTACCTGGAAATTCAATCTCCCTGGGTGTTCAATTGGGACGATCTGGCCGACAAT TCGAGACCGCCACGGATCTATCCTGAGCTAGTCCCTCCAGTAGTCCGCGAGCGGACCGTAACCCAATCCACATTC AAAGCTAATGGCCCACCTACAGAGAAGCCCAGGGCTCACAAACCCCCACTGGAGCCCCTCAAAATTCCTGCGTAT GGACCCACATCAACCCAAAGAAAACCCAGCGTCAATGGGGCTGGACCTCCAGTCGTGTGGATCACCCCTCCGAAC ACCCCACGGAGAACAGCCAAGCCGGAAGACTCTAGCGCTTCCACAAGTACCTCTGACGCAGCCCCTTGGAAGAGC ACTTCTAAGCGTCGACTTGTCATCGTCAACCCCGACCTTGACGACGACATCGGACCCGCACCCCAGAATACCCCA CCGAAACCCAAGTTCGTGTACACACCGCCCCCTCTGCCGGACCCTCCTCAGCCTCCGTATGCTTCTTCACCCCGA CCCTTACGCCATGCCGTTAGCACGAGTTTTGCTTCTGTGTCGTCGATGGGATCGATTTCCTCGAAGGCGGGCTCA CCCTCTCGCCCCCGTGCCCTGGTCGACCCAGGACTTTCTTCCACGCGGACACCCCCAAGGCCACTCCCGAACCCC TTGTCTCCTCCCCTAGGTCGGTCCCCTGCACCCCTCCCCGTCTTGCCCTCCCCTTCAAAGCGAAGGGGATCCAGC CGCGACAGATCACACACGGTACATACTACCTTTGACGCCTCGGCCTCTAAATTATACGAGGAAGGTAATCCAACC GCCAAAGCTTCTGTTCACAACCTCCCGATCTCCTCTTCCGGCTCCCGCACCATCCGCCGCCTTCCCATCTCGCCT CAACAGTTGAACCACGGCAGACCTGCAACCACGACCACACCTTCGATGCCAGGCTCCTCGACCCCTCGGCCACTG CGACCACAGAAATCAGTCCCTGATGTATCCATCTTTGCTTTCAGCCGCGACGCTTATCATTCCCGGCATCATCCT TCGTTCAAGTCGAAGAGCAATCGTCCACTTTACACCTCACGCGGAAGCTTCGACTCGGAACCAGAAGATATCAAC GGGGCATCTGACAACGACAGTGTTTCTTCGACGTCTACGACTCATACCAAGCATCCGCAGCGAGGCGAATCACTG TTGGCGATGCGGCCACGGACGGAGGACGTGTATAAAGATTTAGAGGCTTGGTTCCCGAATCATGATCTCGACCGG CCAGTGGATGGCGCCGACACACCCGCCTCGGGAGCGCTGGAACCCAGGCATCACAGGGTGGACGTCAGGAAGAGT ATTCGAATGATCGCCAAGGAGCAAAACAGGCGCTCTCATAACGATCCAGCTTCTTCTCGTCGGCGAACGATGCTG TGGAACACACATATGGAAGAACTTTCGAGCGACAAGAGAAAGGACAGCATGCCGCGCTTT |
| Length | 2538 |
Transcript
| Sequence id | CC1G_10524T0 |
|---|---|
| Sequence |
>CC1G_10524T0 GAACCGCCGTAATGGACGATAATTGGTGGAGAAGGATTTAAAGCACTGTGCTTCATGCGGTTCCGTTTGCTCTCT GGCGATCCATCTCCAGTCCACTGTGATTCCCTCCGGCTAACCAGCATCTCCTAATCCACCCTCTCCAGTTTCCTA TACACTCTGTCTCACCCAGGGTCGCCCACCGCCTTCCCCGTTCTTCCCATCTGCGACGGATGGATAGTAGGCCCG CGTCCACCCTGCGCACCCTCCAGACATGGGCTGTCCCTTTCAGAGAGACAGTCCCACCCGTTCCAGATCTTCCTG GTCGCCTACTGCCCCAGCCATCTTCGTCTCCTCACAATTCTGCCCTTGACAATGCCCCGGACTACTCGGACTCGG ACGACGATGATAGTATCTGGCAAGCTAGACCTCGCGAACGCCAACCTCGGAGATCTTCAGGCCAGCGCCTGCCCT ACCAGCGATCGTTTGTTAAGCCAACGTTCCAATGGATCAGAGGGGAGCTTCTTGGGAAAGGAAGCTATGGACGGG TTTACCTTGCCCTCAACGCAACCACAGGGGAGGTCATGGCAGTCAAGCAGGTCGAGCTACCAAAGACCCCCAGTG ACAAGATGAAGCCTCAGCAGCTAGACGTTATGAAAGCTCTCAAATTCGAGGGAGATACCCTCAAGGACTTGGATC ATCCCAATATTGTCTCTTACCTCGGGTTCGAAGAGAGCCAGGACTACTTGAGCATTTTCCTGGAATATGTTCCAG GCGGTACAGTCGGGTCTCTCCTGGTAAAAAATGGTCGACTGCGGGAGGAAGTCACCAAGTCATGGCTTAGACAAA TTCTTCAAGGGTTGGACTACCTCCACGGTAAAGGCATCCTTCACAGAGACTTGAAGGCGGATAACATCCTCGTCG ACCATTCCGGGGTTTGCAAGATATCAGACTTTGGTATCTCCAAGAAGGCAGGGGAAATTAATCGTGCAAAAGCGC ACACCGGAATGAAAGGTACCAGTTTCTGGATGGCACCAGAGATACTGTCACCCGGAGAGAAAGGGTACGATGTCA AGGTTGACATCTGGAGTGTGGGCTGCGTGGCTGTGGAAATGTGGACCGGTAAACGCCCATGGTACGGCCACGAAT GGTGGCCTGTGTTGATGAAGGTTGCTGAGGACAAGTCACCGCCCCCAATCCCTGAGGATATACCGATGGGTCATC TGGCACAGAGTTTCCACAATCAATGTTTTCGCCCAGATCCCGCCGACCGACCACATGCCTCTGTGATGCTTAAGC ACCCTTACCTGGAAATTCAATCTCCCTGGGTGTTCAATTGGGACGATCTGGCCGACAATTCGAGACCGCCACGGA TCTATCCTGAGCTAGTCCCTCCAGTAGTCCGCGAGCGGACCGTAACCCAATCCACATTCAAAGCTAATGGCCCAC CTACAGAGAAGCCCAGGGCTCACAAACCCCCACTGGAGCCCCTCAAAATTCCTGCGTATGGACCCACATCAACCC AAAGAAAACCCAGCGTCAATGGGGCTGGACCTCCAGTCGTGTGGATCACCCCTCCGAACACCCCACGGAGAACAG CCAAGCCGGAAGACTCTAGCGCTTCCACAAGTACCTCTGACGCAGCCCCTTGGAAGAGCACTTCTAAGCGTCGAC TTGTCATCGTCAACCCCGACCTTGACGACGACATCGGACCCGCACCCCAGAATACCCCACCGAAACCCAAGTTCG TGTACACACCGCCCCCTCTGCCGGACCCTCCTCAGCCTCCGTATGCTTCTTCACCCCGACCCTTACGCCATGCCG TTAGCACGAGTTTTGCTTCTGTGTCGTCGATGGGATCGATTTCCTCGAAGGCGGGCTCACCCTCTCGCCCCCGTG CCCTGGTCGACCCAGGACTTTCTTCCACGCGGACACCCCCAAGGCCACTCCCGAACCCCTTGTCTCCTCCCCTAG GTCGGTCCCCTGCACCCCTCCCCGTCTTGCCCTCCCCTTCAAAGCGAAGGGGATCCAGCCGCGACAGATCACACA CGGTACATACTACCTTTGACGCCTCGGCCTCTAAATTATACGAGGAAGGTAATCCAACCGCCAAAGCTTCTGTTC ACAACCTCCCGATCTCCTCTTCCGGCTCCCGCACCATCCGCCGCCTTCCCATCTCGCCTCAACAGTTGAACCACG GCAGACCTGCAACCACGACCACACCTTCGATGCCAGGCTCCTCGACCCCTCGGCCACTGCGACCACAGAAATCAG TCCCTGATGTATCCATCTTTGCTTTCAGCCGCGACGCTTATCATTCCCGGCATCATCCTTCGTTCAAGTCGAAGA GCAATCGTCCACTTTACACCTCACGCGGAAGCTTCGACTCGGAACCAGAAGATATCAACGGGGCATCTGACAACG ACAGTGTTTCTTCGACGTCTACGACTCATACCAAGCATCCGCAGCGAGGCGAATCACTGTTGGCGATGCGGCCAC GGACGGAGGACGTGTATAAAGATTTAGAGGCTTGGTTCCCGAATCATGATCTCGACCGGCCAGTGGATGGCGCCG ACACACCCGCCTCGGGAGCGCTGGAACCCAGGCATCACAGGGTGGACGTCAGGAAGAGTATTCGAATGATCGCCA AGGAGCAAAACAGGCGCTCTCATAACGATCCAGCTTCTTCTCGTCGGCGAACGATGCTGTGGAACACACATATGG AAGAACTTTCGAGCGACAAGAGAAAGGACAGCATGCCGCGCTTTTAG |
| Length | 2747 |
Gene
| Sequence id | CC1G_10524T0 |
|---|---|
| Sequence |
>CC1G_10524T0 GAACCGCCGTAATGGACGATAATTGGTGGAGAAGGATTTAAAGCACTGTGCTTCATGCGGTTCCGTTTGCTCTCT GGCGATCCATCTCCAGTCCACTGTGATTCCCTCCGGCTAACCAGCATCTCCTAATCCACCCTCTCCAGTTTCCTA TACACTCTGTCTCACCCAGGGTCGCCCACCGCCTTCCCCGTTCTTCCCATCTGCGACGGATGGATAGTAGGCCCG CGTCCACCCTGCGCACCCTCCAGACATGGGCTGTCCCTTTCAGAGAGACAGTCCCACCCGTTCCAGATCTTCCTG GTCGCCTACTGCCCCAGCCATCTTCGTCTCCTCACAATTCTGCCCTTGACAATGCCCCGGACTACTCGGACTCGG ACGACGATGATAGTATCTGGCAAGCTAGACCTCGCGAACGCCAACCTCGGAGATCTTCAGGCCAGCGCCTGCCCT ACCAGCGATCGTTTGTTAAGCGTATGTCTTACTCTTTTCTCTGAACATTCAACAGCTGACACGGATCCATAAGCA ACGTTCCAATGGATCAGAGGGGAGCTTCTTGGGAAAGGAAGCTATGGACGGGTTTACCTTGCCCTCAACGCAACC ACAGGGGAGGTCATGGCAGTCAAGCAGGTCGAGCTACCAAAGACCCCCAGTGACAAGATGAAGCCTCAGCAGCTA GACGTTATGAAAGCTCTCAAATTCGAGGGAGATACCCTCAAGGACTTGGATCATCCCAATATTGTCTCTTACCTC GGGTTCGAAGAGAGCCAGGACTACTTGAGCATGTAAGTGGTAACCTGCTGCTATGGAATCCCTGCTGAGAGCGGA CAGTTTCCTGGAATATGTTCCAGGCGGTACAGTCGGGTCTCTCCTGGTAAAAAATGGTCGACTGCGGGAGGAAGT CACCAAGTCATGGCTTAGACAAATTCTTCAAGGGTTGGACTACCTCCACGGTAAAGGCATCCTTCACAGAGTCAG TTCCTCTTTTCGGTCTAACAGAGTTGTAATAACCGAATCGTCTCTCAGGACTTGAAGGCGGATAACATCCTCGTC GACCATTCCGGGGTTTGCAAGATATCAGACTTTGGTATCTCCAAGAAGGCAGGGGAAATTAATCGTGCAAAAGCG CACACCGGAATGAAAGGTACCAGTTTCTGGATGGCACCAGAGATACTGTCACCCGGAGAGAAAGGGTACGATGTC AAGGTTGACATCTGGAGTGTGGGCTGCGTGGCTGTGGAAATGTGGACCGGTAAACGCCCATGGTACGGCCACGAA TGGTGGCCTGTGTTGATGAAGGTAACGGGAGACTCGTCTCTGTTGGCGCCATTCACTGACCTGTGCACCACAGGT TGCTGAGGACAAGTCACCGCCCCCAATCCCTGAGGATATACCGATGGGTCATCTGGCACAGAGTTTCCACAATCA ATGTTTTCGCCCGTGAGTAATGTGTCGAAGTCCACCTCGTTCTTCTTCTCACAAGCTCGGGCAGAGATCCCGCCG ACCGACCACATGCCTCTGTGATGCTTAAGCACCCTTACCTGGAAATTCAATCTCCCTGGGTGTTCAATTGGGACG ATCTGGCCGACAATTCGAGACCGCCACGGATCTATCCTGAGCTAGTCCCTCCAGTAGTCCGCGAGCGGACCGTAA CCCAATCCACATTCAAAGCTAATGGCCCACCTACAGAGAAGCCCAGGGCTCACAAACCCCCACTGGAGCCCCTCA AAATTCCTGCGTATGGACCCACATCAACCCAAAGAAAACCCAGCGTCAATGGGGCTGGACCTCCAGTCGTGTGGA TCACCCCTCCGAACACCCCACGGAGAACAGCCAAGCCGGAAGACTCTAGCGCTTCCACAAGTACCTCTGACGCAG CCCCTTGGAAGAGCACTTCTAAGCGTCGACTTGTCATCGTCAACCCCGACCTTGACGACGACATCGGACCCGCAC CCCAGAATACCCCACCGAAACCCAAGTTCGTGTACACACCGCCCCCTCTGCCGGACCCTCCTCAGCCTCCGTATG CTTCTTCACCCCGACCCTTACGCCATGCCGTTAGCACGAGTTTTGCTTCTGTGTCGTCGATGGGATCGATTTCCT CGAAGGCGGGCTCACCCTCTCGCCCCCGTGCCCTGGTCGACCCAGGACTTTCTTCCACGCGGACACCCCCAAGGC CACTCCCGAACCCCTTGTCTCCTCCCCTAGGTCGGTCCCCTGCACCCCTCCCCGTCTTGCCCTCCCCTTCAAAGC GAAGGGGATCCAGCCGCGACAGATCACACACGGTACATACTACCTTTGACGCCTCGGCCTCTAAATTATACGAGG AAGGTAATCCAACCGCCAAAGCTTCTGTTCACAACCTCCCGATCTCCTCTTCCGGCTCCCGCACCATCCGCCGCC TTCCCATCTCGCCTCAACAGTTGAACCACGGCAGACCTGCAACCACGACCACACCTTCGATGCCAGGCTCCTCGA CCCCTCGGCCACTGCGACCACAGAAATCAGTCCCTGATGTATCCATCTTTGCTTTCAGCCGCGACGCTTATCATT CCCGGCATCATCCTTCGTTCAAGTCGAAGAGCAATCGTCCACTTTACACCTCACGCGGAAGCTTCGACTCGGAAC CAGAAGATATCAACGGGGCATCTGACAACGACAGTGTTTCTTCGACGTCTACGACTCATACCAAGCATCCGCAGC GAGGCGAATCACTGTTGGCGATGCGGCCACGGACGGAGGACGTGTATAAAGATTTAGAGGCTTGGTTCCCGAATC ATGATCTCGACCGGCCAGTGGATGGCGCCGACACACCCGCCTCGGGAGCGCTGGAACCCAGGCATCACAGGGTGG ACGTCAGGAAGAGTATTCGAATGATCGCCAAGGAGCAAAACAGGCGCTCTCATAACGATCCAGCTTCTTCTCGTC GGCGAACGATGCTGTGGAACACACATATGGAAGAACTTTCGAGCGACAAGAGAAAGGACAGCATGCCGCGCTTTT AG |
| Length | 3002 |