CC1G_10582
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_10582 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NDZ6 | Functional description | Endoglucanase family 5 glycoside hydrolase |
| Location | Chr_2:593892..595615 | Strand | + |
| Gene length (nt) | 1724 | Transcript length (nt) | 1440 |
| CDS length (nt) | 1440 | Protein length (aa) | 479 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7270937 | 74 | 2.344E-258 | 792 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_92417 | 69.6 | 1.342E-245 | 755 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB21881 | 71.9 | 3.817E-245 | 754 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1079888 | 68 | 1.153E-237 | 732 |
| Grifola frondosa | Grifr_OBZ72767 | 66.5 | 6.077E-237 | 730 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1447403 | 67.8 | 6.679E-237 | 730 |
| Pleurotus ostreatus PC9 | PleosPC9_1_64780 | 66.8 | 6.643E-235 | 724 |
| Lentinula edodes B17 | Lened_B_1_1_12316 | 66.5 | 1.52E-233 | 720 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_16912 | 65.3 | 2.084E-232 | 717 |
| Lentinula edodes NBRC 111202 | Lenedo1_1059714 | 65.4 | 5.093E-231 | 713 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_77559 | 64.8 | 1.243E-226 | 700 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_188761 | 65 | 2.646E-226 | 699 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 9012 |
| Description | Endoglucanase family 5 glycoside hydrolase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 79 | 341 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR001547 | Glycoside hydrolase, family 5 |
| IPR017853 | Glycoside hydrolase superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| G | Belongs to the glycosyl hydrolase 5 (cellulase A) family |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_22 |
Transcription factor
| Group |
|---|
| No records |
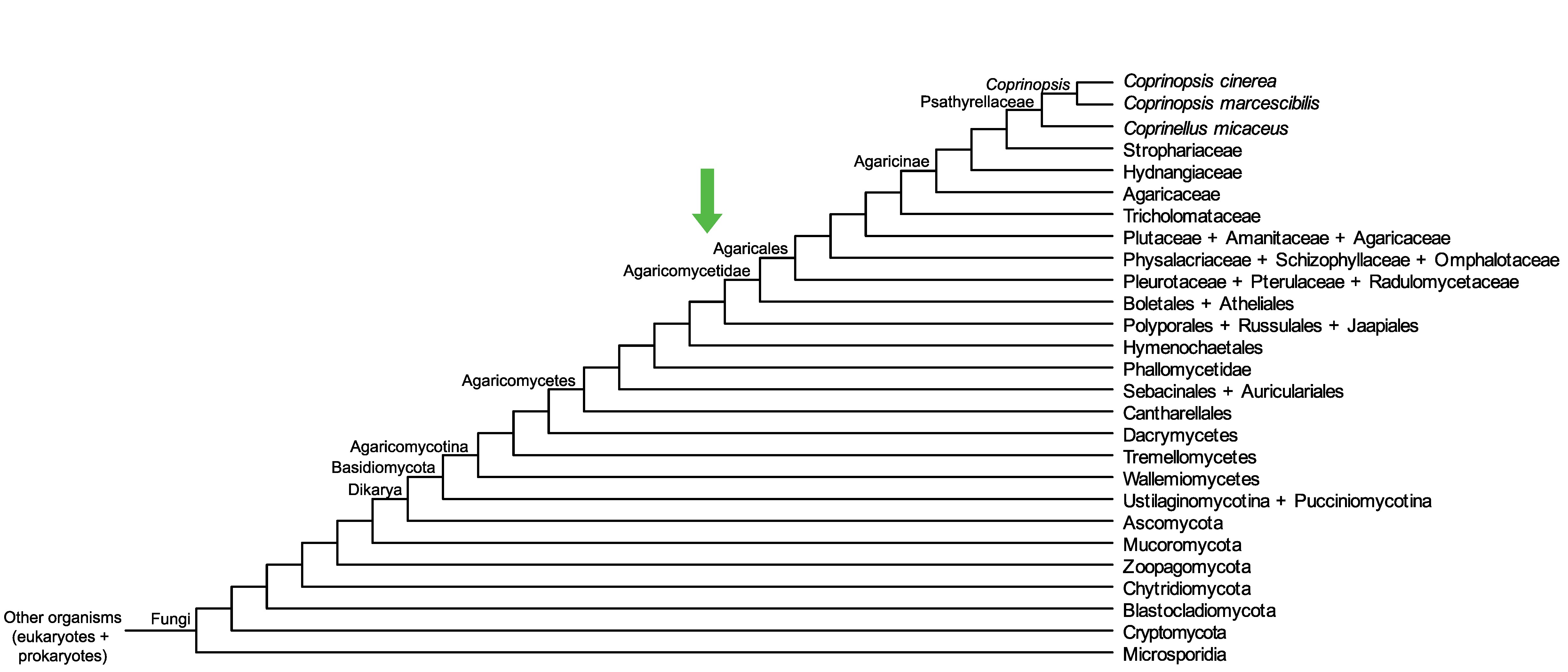
Conservation of CC1G_10582 across fungi.
Arrow shows the origin of gene family containing CC1G_10582.
Protein
| Sequence id | 9012 |
|---|---|
| Sequence |
>9012 MAAGAFLKVDGTRIVDQDNNEVVLHGAGLGGWMTLNEPVRDALEETIGKEKAAFFFDKVHSDEGMTFLEHFFTEK DAIFFKSLGLNCIRIAVGYRHFEDDMNPRVLKPDAFKHLDRAISLCAKHSIYTVIDVHTAPGGQSGGWHADAGVH IANFWRHKDFQDRLVWLWTELAKHYKDNPWIAGYNVLNEPADPHPQHAGLIKMYDRLHQAIREIDGNHIIFLDGN TFATDFTKFPEDAGTRWTNTAYAIHDYAVYGFPSAPEPYEGSEAQKERLLKTYKRKREWMDQRGLCVWNGEWGPV YARREYDGDAMEDINERRYNVLKDQLEIYEKDRLSWSIWLYKDIGFQGMVYVSPDTPYRQRFKDFLAKKHRLAAD AWGKDDQHVKQFYSPIISLIEDNIKDKSHLKLYPPLWTVPERTTRLARTMLVAEYLVQEWADLFLGLDEQQLEEL AKSFSFDNCLKRDGLNEVLTAHAERVSKK |
| Length | 479 |
Coding
| Sequence id | CC1G_10582T0 |
|---|---|
| Sequence |
>CC1G_10582T0 ATGGCTGCAGGCGCGTTCTTGAAAGTGGATGGAACCCGGATTGTGGACCAGGACAACAATGAGGTTGTGTTGCAT GGGGCTGGGCTTGGTGGTTGGATGACGCTGAATGAGCCGGTACGCGATGCGTTGGAGGAGACCATCGGCAAGGAG AAGGCCGCTTTCTTCTTTGACAAGGTACACTCTGACGAAGGAATGACCTTCCTGGAGCATTTCTTCACGGAGAAG GATGCCATCTTCTTCAAGTCTTTGGGCTTGAACTGCATTCGAATCGCAGTGGGGTACCGACACTTTGAAGACGAC ATGAACCCCCGCGTCCTCAAACCAGACGCCTTCAAGCACCTCGACAGGGCCATCTCCCTCTGCGCCAAACACTCC ATCTACACCGTCATCGACGTGCACACCGCACCCGGCGGGCAGAGCGGGGGCTGGCACGCCGACGCCGGCGTGCAC ATCGCCAACTTCTGGAGACACAAAGACTTCCAAGACCGGCTGGTCTGGCTCTGGACCGAGCTCGCAAAGCACTAC AAAGACAACCCCTGGATCGCGGGCTACAACGTCCTCAACGAGCCCGCGGACCCGCACCCCCAGCACGCGGGTTTG ATCAAGATGTACGACAGGCTGCATCAGGCTATTCGCGAGATTGATGGGAACCATATCATCTTCCTCGATGGGAAC ACGTTTGCGACGGATTTTACAAAGTTTCCCGAGGATGCGGGGACGAGGTGGACGAATACGGCGTATGCGATACAT GATTACGCTGTTTATGGGTTTCCGAGTGCGCCGGAGCCGTATGAGGGCTCCGAGGCCCAGAAGGAGAGGTTGCTA AAGACGTATAAGAGGAAGAGGGAGTGGATGGATCAGAGGGGTTTGTGTGTGTGGAATGGGGAGTGGGGGCCTGTG TATGCGAGGAGGGAGTATGATGGCGATGCGATGGAGGATATTAATGAGAGGAGATATAACGTGTTGAAGGACCAA TTGGAGATTTATGAAAAGGATCGCCTCAGCTGGTCCATCTGGCTCTATAAAGACATTGGCTTCCAAGGGATGGTC TACGTCTCCCCAGACACGCCCTACCGCCAACGCTTCAAAGACTTCCTCGCCAAGAAACACAGACTCGCAGCAGAC GCCTGGGGTAAAGACGACCAACACGTCAAGCAATTCTATAGCCCCATCATCTCCTTGATCGAGGACAACATCAAG GATAAATCCCACCTCAAGCTCTACCCGCCATTGTGGACCGTTCCGGAGAGGACGACAAGACTGGCGAGAACGATG TTGGTGGCAGAATACCTGGTGCAAGAGTGGGCAGACTTGTTCCTGGGATTGGACGAACAACAGCTGGAGGAACTA GCGAAGAGTTTTTCGTTCGATAACTGCTTGAAGCGGGATGGGTTGAACGAGGTTCTAACGGCTCATGCCGAAAGG GTCAGCAAGAAA |
| Length | 1440 |
Transcript
| Sequence id | CC1G_10582T0 |
|---|---|
| Sequence |
>CC1G_10582T0 ATGGCTGCAGGCGCGTTCTTGAAAGTGGATGGAACCCGGATTGTGGACCAGGACAACAATGAGGTTGTGTTGCAT GGGGCTGGGCTTGGTGGTTGGATGACGCTGAATGAGCCGGTACGCGATGCGTTGGAGGAGACCATCGGCAAGGAG AAGGCCGCTTTCTTCTTTGACAAGGTACACTCTGACGAAGGAATGACCTTCCTGGAGCATTTCTTCACGGAGAAG GATGCCATCTTCTTCAAGTCTTTGGGCTTGAACTGCATTCGAATCGCAGTGGGGTACCGACACTTTGAAGACGAC ATGAACCCCCGCGTCCTCAAACCAGACGCCTTCAAGCACCTCGACAGGGCCATCTCCCTCTGCGCCAAACACTCC ATCTACACCGTCATCGACGTGCACACCGCACCCGGCGGGCAGAGCGGGGGCTGGCACGCCGACGCCGGCGTGCAC ATCGCCAACTTCTGGAGACACAAAGACTTCCAAGACCGGCTGGTCTGGCTCTGGACCGAGCTCGCAAAGCACTAC AAAGACAACCCCTGGATCGCGGGCTACAACGTCCTCAACGAGCCCGCGGACCCGCACCCCCAGCACGCGGGTTTG ATCAAGATGTACGACAGGCTGCATCAGGCTATTCGCGAGATTGATGGGAACCATATCATCTTCCTCGATGGGAAC ACGTTTGCGACGGATTTTACAAAGTTTCCCGAGGATGCGGGGACGAGGTGGACGAATACGGCGTATGCGATACAT GATTACGCTGTTTATGGGTTTCCGAGTGCGCCGGAGCCGTATGAGGGCTCCGAGGCCCAGAAGGAGAGGTTGCTA AAGACGTATAAGAGGAAGAGGGAGTGGATGGATCAGAGGGGTTTGTGTGTGTGGAATGGGGAGTGGGGGCCTGTG TATGCGAGGAGGGAGTATGATGGCGATGCGATGGAGGATATTAATGAGAGGAGATATAACGTGTTGAAGGACCAA TTGGAGATTTATGAAAAGGATCGCCTCAGCTGGTCCATCTGGCTCTATAAAGACATTGGCTTCCAAGGGATGGTC TACGTCTCCCCAGACACGCCCTACCGCCAACGCTTCAAAGACTTCCTCGCCAAGAAACACAGACTCGCAGCAGAC GCCTGGGGTAAAGACGACCAACACGTCAAGCAATTCTATAGCCCCATCATCTCCTTGATCGAGGACAACATCAAG GATAAATCCCACCTCAAGCTCTACCCGCCATTGTGGACCGTTCCGGAGAGGACGACAAGACTGGCGAGAACGATG TTGGTGGCAGAATACCTGGTGCAAGAGTGGGCAGACTTGTTCCTGGGATTGGACGAACAACAGCTGGAGGAACTA GCGAAGAGTTTTTCGTTCGATAACTGCTTGAAGCGGGATGGGTTGAACGAGGTTCTAACGGCTCATGCCGAAAGG GTCAGCAAGAAATAG |
| Length | 1440 |
Gene
| Sequence id | CC1G_10582T0 |
|---|---|
| Sequence |
>CC1G_10582T0 ATGGCTGCAGGCGCGTTCTTGAAAGTGGATGGAACCCGGATTGTGGACCAGGACAACAATGAGGTTGTGTTGCAT GGGGCTGGGCTTGGTGGTTGGATGACGTGAGTCACCGTTTGATATGCTGCGGGTGCGAAGGCTGAATGAGCCGGT TAGGATGGAGAACTTCATTTCAGGTATTGCAAGGCAGACTTGACGCTGCGGGAAAGTTAATCTTTGGGCCTCGTT GACTAGGTTTCCCGGCCTGTGAGTTCCAGGTACGCGATGCGTTGGAGGAGACCATCGGCAAGGAGAAGGCCGCTT TCTTCTTTGACAAGGTACACTCTGACGAAGGAATGACCGTCAGTCTAGCTGACAAGGCAGTGTCGTAGTTCCTGG AGCATTTCTTCACGGAGAAGGATGCCATCTTCTTCAAGTCTTTGGGCTTGAACTGCATTCGAATCGCAGTGGGGT ACCGACACTTTGAAGGTGCGCATCACTAGCCCCTATCCCCGCATTTAAATGACCACTCACCGTGCTACACCCAGA CGACATGAACCCCCGCGTCCTCAAACCAGACGCCTTCAAGCACCTCGACAGGGCCATCTCCCTCTGCGCCAAACA CTCCATCTACACCGTCATCGACGTGCACACCGCACCCGGCGGGCAGAGCGGGGGCTGGCACGCCGACGCCGGCGT GCACATCGCCAACTTCTGGAGACACAAAGACTTCCAAGACCGGCTGGTCTGGCTCTGGACCGAGCTCGCAAAGCA CTACAAAGACAACCCCTGGATCGCGGGCTACAACGTCCTCAACGAGCCCGCGGACCCGCACCCCCAGCACGCGGG TTTGATCAAGATGTACGACAGGCTGCATCAGGCTATTCGCGAGATTGATGGGAACCATATCATCTTCCTCGATGG GAACACGTTTGCGACGGATTTTACAAAGTTTCCCGAGGATGCGGGGACGAGGTGGACGAATACGGCGTATGCGAT ACATGATTACGCTGTTTATGGGTTTCCGAGTGCGCCGGAGCCGTATGAGGGCTCCGAGGCCCAGAAGGAGAGGTT GCTAAAGACGTATAAGAGGAAGAGGGAGTGGATGGATCAGAGGGGTTTGTGTGTGTGGAATGGGGAGTGGGGGCC TGTGTATGCGAGGAGGGAGTATGATGGCGATGCGATGGAGGATATTAATGAGAGGAGATATAACGTGTTGAAGGA CCAATTGGAGATTTATGAAAAGGTAATTTACATGTACTTTGCGTTCGTTGTGCGAGGCTGACGGGTGTCGACTCT AGGATCGCCTCAGCTGGTCCATCTGGCTCTATAAAGACATTGGCTTCCAAGGGATGGTCTACGTCTCCCCAGACA CGCCCTACCGCCAACGCTTCAAAGACTTCCTCGCCAAGAAACACAGACTCGCAGCAGACGCCTGGGGTAAAGACG ACCAACACGTCAAGCAATTCTATAGCCCCATCATCTCCTTGATCGAGGACAACATCAAGGATAAATCCCACCTCA AGCTCTACCCGCCATTGTGGACCGTTCCGGAGAGGACGACAAGACTGGCGAGAACGATGTTGGTGGCAGAATACC TGGTGCAAGAGTGGGCAGACTTGTTCCTGGGATTGGACGAACAACAGCTGGAGGAACTAGCGAAGAGTTTTTCGT TCGATAACTGCTTGAAGCGGGATGGGTTGAACGAGGTTCTAACGGCTCATGCCGAAAGGGTCAGCAAGAAATAG |
| Length | 1724 |