CC1G_11009
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_11009 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P740 | Functional description | Protein kinase subdomain-containing protein PKL/ccin3 |
| Location | Chr_5:3385431..3386628 | Strand | + |
| Gene length (nt) | 1198 | Transcript length (nt) | 1080 |
| CDS length (nt) | 1080 | Protein length (aa) | 359 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB15498 | 36.6 | 8.437E-57 | 202 |
| Agrocybe aegerita | Agrae_CAA7263754 | 35.2 | 5.16E-49 | 179 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_6833 | 23.9 | 1.196E-7 | 53 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 9353 |
| Description | Protein kinase subdomain-containing protein PKL/ccin3 |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| No records | |||||
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| No records | ||
KEGG
| KEGG Orthology |
|---|
| No records |
EggNOG
| COG category | Description |
|---|---|
| No records | |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
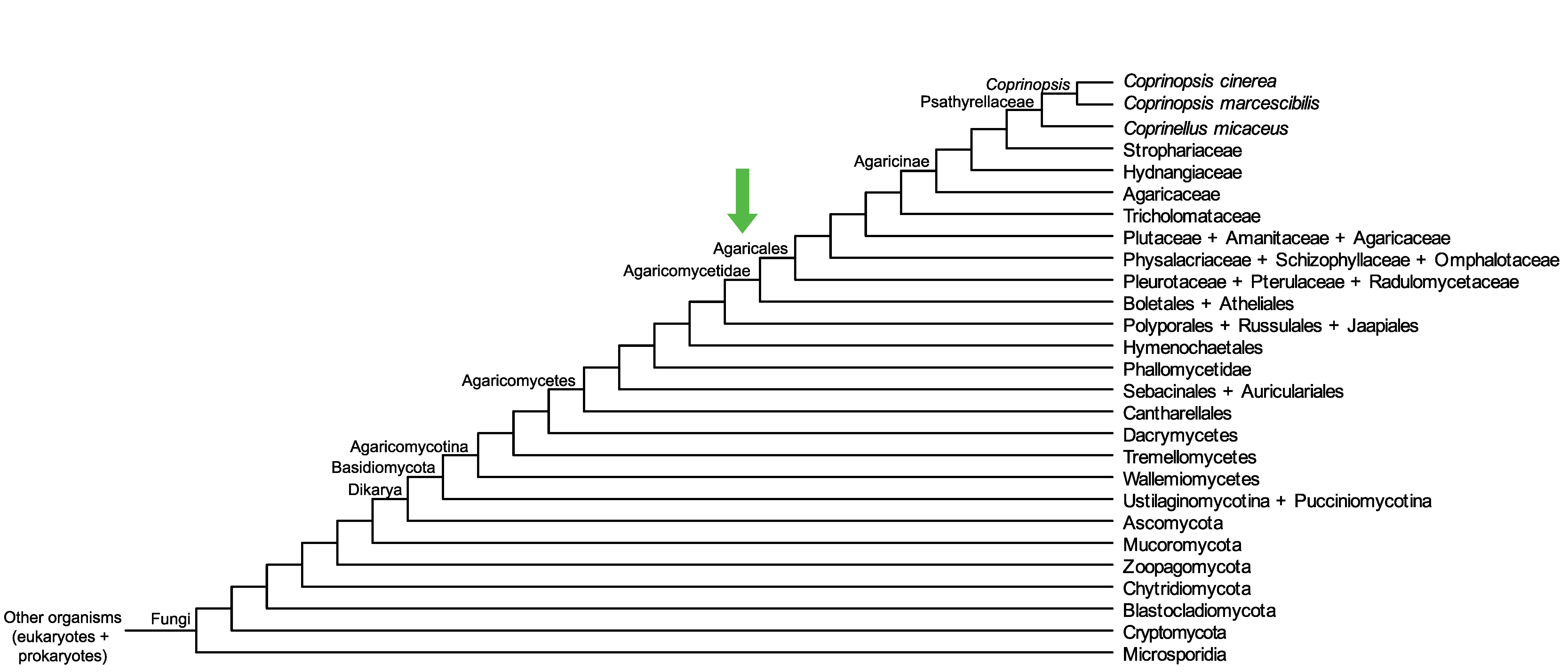
Conservation of CC1G_11009 across fungi.
Arrow shows the origin of gene family containing CC1G_11009.
Protein
| Sequence id | 9353 |
|---|---|
| Sequence |
>9353 MASSESLEALRDCNLLGRIRIAGLVKDDPALKVKLERSQSFPPCRANTGRDYRPPVPTWSPLPLPPNGDEIELSL HDEPISEGRVGVVYSADVTTRSNPDGLGPTSLPTILCVKVIKPRFSRRAAREAWMHEQLSLSGCSGTSTPRYFGF FTAPLSNTTTATQESRKALNPDDILPWVEARFHDSDHDPYVDSDSELPPDSLNDDSPEFHKYDVGRHRRNSPWYA YEHDEENALLSVLLFEVLGPRMFGEPDMKDREKEYHEEAAELVIDIGMTGVRHHDLRTANVLQVPSETLASPNSR VCPRHGRKHNWRIIDFDSAAKYSITPDDIANNSRDFRRVTTLPVQEIGKYYWWGIELSP |
| Length | 359 |
Coding
| Sequence id | CC1G_11009T0 |
|---|---|
| Sequence |
>CC1G_11009T0 ATGGCATCATCCGAATCTCTGGAGGCGTTGAGAGATTGTAACCTCCTCGGCAGGATCCGAATCGCAGGTCTTGTC AAAGACGATCCAGCGCTAAAAGTGAAGCTTGAACGATCCCAGTCGTTCCCCCCATGTCGCGCCAACACTGGACGA GACTATCGCCCCCCTGTTCCTACGTGGAGTCCCCTGCCTCTACCTCCCAACGGTGACGAGATTGAATTGAGCCTC CACGATGAGCCCATCTCTGAAGGACGCGTTGGTGTTGTATACTCGGCGGACGTGACTACACGTTCTAATCCGGAT GGTCTCGGGCCGACGTCCCTTCCTACGATTCTCTGTGTGAAGGTTATCAAACCTCGCTTCTCCAGGAGGGCGGCA CGCGAAGCATGGATGCACGAGCAGCTCTCCCTGAGCGGCTGCAGTGGCACCTCCACGCCGCGGTATTTTGGCTTT TTTACAGCGCCTTTGAGTAATACCACTACAGCTACTCAAGAGTCTAGAAAGGCGCTGAACCCCGACGACATCCTG CCCTGGGTCGAGGCACGTTTTCATGACTCTGACCACGACCCTTATGTCGACTCCGACTCGGAACTTCCTCCAGAC TCGCTCAACGACGACTCGCCCGAATTTCACAAATATGACGTCGGTCGTCATCGCAGGAACTCTCCCTGGTACGCC TATGAGCATGACGAAGAGAACGCGCTCCTCTCTGTCCTTCTCTTCGAGGTTTTAGGACCGCGCATGTTCGGTGAA CCGGACATGAAGGATCGCGAGAAGGAATACCACGAGGAGGCCGCCGAACTGGTGATTGACATTGGGATGACTGGA GTGCGACACCACGATCTCCGCACCGCGAATGTTCTGCAGGTCCCTTCAGAAACGTTGGCCTCTCCCAACTCACGG GTTTGTCCGCGCCATGGACGAAAACATAACTGGAGGATCATCGACTTTGACTCTGCAGCGAAGTACTCCATCACG CCTGACGACATCGCCAATAACAGCAGAGACTTTCGTAGGGTTACGACATTGCCGGTGCAGGAAATCGGAAAATAT TATTGGTGGGGAATTGAATTGTCGCCA |
| Length | 1080 |
Transcript
| Sequence id | CC1G_11009T0 |
|---|---|
| Sequence |
>CC1G_11009T0 ATGGCATCATCCGAATCTCTGGAGGCGTTGAGAGATTGTAACCTCCTCGGCAGGATCCGAATCGCAGGTCTTGTC AAAGACGATCCAGCGCTAAAAGTGAAGCTTGAACGATCCCAGTCGTTCCCCCCATGTCGCGCCAACACTGGACGA GACTATCGCCCCCCTGTTCCTACGTGGAGTCCCCTGCCTCTACCTCCCAACGGTGACGAGATTGAATTGAGCCTC CACGATGAGCCCATCTCTGAAGGACGCGTTGGTGTTGTATACTCGGCGGACGTGACTACACGTTCTAATCCGGAT GGTCTCGGGCCGACGTCCCTTCCTACGATTCTCTGTGTGAAGGTTATCAAACCTCGCTTCTCCAGGAGGGCGGCA CGCGAAGCATGGATGCACGAGCAGCTCTCCCTGAGCGGCTGCAGTGGCACCTCCACGCCGCGGTATTTTGGCTTT TTTACAGCGCCTTTGAGTAATACCACTACAGCTACTCAAGAGTCTAGAAAGGCGCTGAACCCCGACGACATCCTG CCCTGGGTCGAGGCACGTTTTCATGACTCTGACCACGACCCTTATGTCGACTCCGACTCGGAACTTCCTCCAGAC TCGCTCAACGACGACTCGCCCGAATTTCACAAATATGACGTCGGTCGTCATCGCAGGAACTCTCCCTGGTACGCC TATGAGCATGACGAAGAGAACGCGCTCCTCTCTGTCCTTCTCTTCGAGGTTTTAGGACCGCGCATGTTCGGTGAA CCGGACATGAAGGATCGCGAGAAGGAATACCACGAGGAGGCCGCCGAACTGGTGATTGACATTGGGATGACTGGA GTGCGACACCACGATCTCCGCACCGCGAATGTTCTGCAGGTCCCTTCAGAAACGTTGGCCTCTCCCAACTCACGG GTTTGTCCGCGCCATGGACGAAAACATAACTGGAGGATCATCGACTTTGACTCTGCAGCGAAGTACTCCATCACG CCTGACGACATCGCCAATAACAGCAGAGACTTTCGTAGGGTTACGACATTGCCGGTGCAGGAAATCGGAAAATAT TATTGGTGGGGAATTGAATTGTCGCCATGA |
| Length | 1080 |
Gene
| Sequence id | CC1G_11009T0 |
|---|---|
| Sequence |
>CC1G_11009T0 ATGGCATCATCCGAATCTCTGGAGGCGGTATGTACCCTTATCATCTTGTTCAAACCCGACCGCTAACCCCTCAAT TATATTCCAGTTGAGAGATTGTAACCTCCTCGGCAGGATCCGAATCGCAGGTCTTGTCAAAGACGATCCAGCGCT AAAAGTGAAGCTTGAACGATCCCAGTCGTTCCCCCCATGTCGCGCCAACACTGGACGAGACTATCGCCCCCCTGT TCCTACGTGGAGTCCCCTGCCTCTACCTCCCAACGGTGACGAGATTGAATTGAGCCTCCACGATGAGCCCATCTC TGAAGGACGCGTTGGTGTTGTATACTCGGCGGACGTGACTACACGTTCTAATCCGGATGGTCTCGGGCCGACGTC CCTTCCTACGATTCTCTGTGTGAAGGTTATCAAACCTCGCTTCTCCAGGAGGGCGGCACGCGAAGCATGGATGCA CGAGCAGCTCTCCCTGAGCGGCTGCAGTGGCACCTCCACGCCGCGGTATTTTGGCTTTTTTACAGCGCCTTTGAG TAATACCACTACAGCTACTCAAGAGTCTAGAAAGGCGCTGAACCCCGACGACATCCTGCCCTGGGTCGAGGCACG TTTTCATGACTCTGACCACGACCCTTATGTCGACTCCGACTCGGAACTTCCTCCAGACTCGCTCAACGACGACTC GCCCGAATTTCACAAATATGACGTCGGTCGTCATCGCAGGAACTCTCCCTGGTACGCCTATGAGCATGACGAAGA GAACGCGCTCCTCTCTGTCCTTCTCTTCGAGGTTTTAGGACCGCGCATGTTCGGTGAACCGGACATGAAGGATCG CGAGAAGGAATACCACGAGTGAGTGCACGATCCTCTTTGTGTTATTAAACCTCATCTTCTAACATTTTGCTCCAA CAGGGAGGCCGCCGAACTGGTGATTGACATTGGGATGACTGGAGTGCGACACCACGATCTCCGCACCGCGAATGT TCTGCAGGTCCCTTCAGAAACGTTGGCCTCTCCCAACTCACGGGTTTGTCCGCGCCATGGACGAAAACATAACTG GAGGATCATCGACTTTGACTCTGCAGCGAAGTACTCCATCACGCCTGACGACATCGCCAATAACAGCAGAGACTT TCGTAGGGTTACGACATTGCCGGTGCAGGAAATCGGAAAATATTATTGGTGGGGAATTGAATTGTCGCCATGA |
| Length | 1198 |