CC1G_11102
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_11102 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8P7P2 | Functional description | Mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase (EC 3.2.1.96) |
| Location | Chr_5:435315..437890 | Strand | - |
| Gene length (nt) | 2576 | Transcript length (nt) | 2364 |
| CDS length (nt) | 2364 | Protein length (aa) | 787 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7269656 | 46.5 | 2.613E-231 | 730 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB20368 | 44.6 | 8.4E-217 | 688 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_11491 | 42.3 | 5.703E-198 | 633 |
| Lentinula edodes NBRC 111202 | Lenedo1_1235929 | 42.3 | 2.795E-197 | 631 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_80764 | 41.7 | 3.881E-191 | 613 |
| Pleurotus ostreatus PC9 | PleosPC9_1_115065 | 40.4 | 4.65E-187 | 601 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1092656 | 41.4 | 2.306E-186 | 599 |
| Schizophyllum commune H4-8 | Schco3_2681989 | 40.9 | 1.693E-183 | 591 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1386094 | 42.8 | 1.831E-180 | 582 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_181728 | 39.4 | 8.994E-175 | 565 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_109029 | 39.5 | 4.538E-174 | 563 |
| Lentinula edodes B17 | Lened_B_1_1_6561 | 54.7 | 9.521E-132 | 439 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 9435 |
| Description | Mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase (EC 3.2.1.96) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd06547 | GH85_ENGase | - | 61 | 436 |
| Pfam | PF03644 | Glycosyl hydrolase family 85 | IPR005201 | 75 | 416 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR005201 | Glycoside hydrolase, family 85 |
| IPR032979 | Cytosolic endo-beta-N-acetylglucosaminidase |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005737 | cytoplasm | CC |
| GO:0033925 | mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K01227 |
EggNOG
| COG category | Description |
|---|---|
| G | Glycosyl hydrolase family 85 |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH85 |
Transcription factor
| Group |
|---|
| No records |
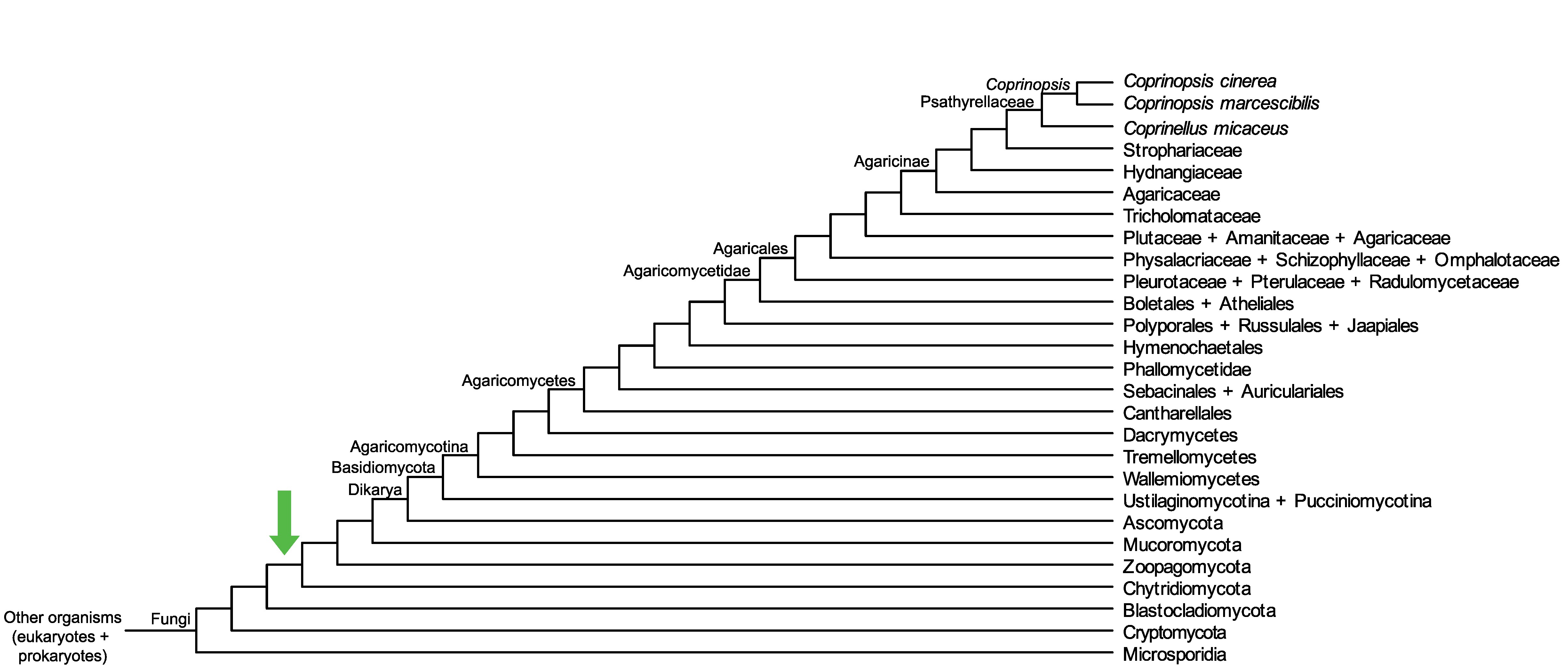
Conservation of CC1G_11102 across fungi.
Arrow shows the origin of gene family containing CC1G_11102.
Protein
| Sequence id | 9435 |
|---|---|
| Sequence |
>9435 MPIAGKKFHPRALPEFWRTFREMDEWRATQTGPQARPAEGILKYVPRKIRPADIAGKGRLLVSHDYKGGYVEDPF SKSYSFNWWFSTDSFNYFAHHRITIPPPEWINAAHRQGVPILGTIIFEGGSDEDILRMVIGKTPGSTSNFHAERN AEYTVPVSSYYAELFADLAVERGFDGWLLNVEIGLQGGSEQARGLAAWVALLQQEVLKKVGPHGLVIWYDSVTVR GDLWWQDRLNAFNLPFFLNSSGIFTNYWWYNDAPQKQIDFLSRVDPNLTGQTAEPHQYNLQKTIQDIYIGVDVWG RGSHGGGGFGAYKAIEHADPKGLGFSVALFAQGWTWETEEEKPGWNWAQFWDYDSKLWVGPPGVVEAPDHTVKPG EYPCVHGPFQPISSFFLTYPPPDPLDLPFYTNFCPGIGDAWFVEGKEVFRSETGWTDMDKQTTVGDLVWPRPKIY DLPSQNASQATLNAAFNFNDAWNGGNSLQINLTVPGGATTYGAYWVPIQTFTFSSRRQYEASIVYKPGLSGKTRF DAKYEVGIRTITGEDQGKIISNTTTEVGNGWRKVHILFEIETPVEGGSIIVPSSIGLVIAVSNVSTTEQFEFPFL VGQITIHPHLPDRYKEFKPALLWLLFTPSAGTNSLDGTLTWDVVAAIERPPPVEINNPDDAQIPWNLQPTKQEWF PDFLYFNVYVLELLDGGGQGPPQWIGTTGYDGEKKRFFIYDESLPPTSGLRRFTFQIEGVLETGESTHWYDAPAA PSATAGGEQKRTRRTSLKSVLSPLRRKKSKGDISVAK |
| Length | 787 |
Coding
| Sequence id | CC1G_11102T0 |
|---|---|
| Sequence |
>CC1G_11102T0 ATGCCTATCGCTGGGAAGAAGTTCCACCCCCGGGCTCTGCCTGAGTTCTGGAGGACGTTCCGGGAGATGGACGAA TGGCGGGCCACTCAGACTGGACCTCAGGCTCGTCCGGCTGAAGGCATTCTCAAGTACGTTCCACGGAAGATTCGG CCTGCTGATATCGCAGGGAAAGGTCGACTGTTGGTTTCTCATGACTACAAGGGAGGCTACGTCGAAGATCCCTTT TCCAAGTCGTATAGCTTCAATTGGTGGTTCTCGACGGATAGCTTCAACTACTTCGCTCACCACCGGATAACCATT CCCCCTCCGGAATGGATAAACGCTGCTCATCGCCAGGGTGTACCTATTCTCGGCACCATCATCTTCGAAGGTGGA AGCGACGAAGACATCCTCCGGATGGTGATCGGGAAAACACCAGGAAGCACCAGCAACTTCCACGCCGAACGAAAC GCGGAGTACACCGTACCAGTTTCGTCGTACTACGCAGAACTCTTCGCAGACCTGGCTGTCGAGCGTGGATTCGAT GGTTGGCTGCTCAACGTTGAGATTGGTCTGCAGGGAGGATCAGAGCAAGCACGAGGTCTGGCTGCTTGGGTTGCG CTACTGCAGCAGGAGGTTTTGAAGAAGGTTGGCCCACATGGCTTGGTCATTTGGTACGACAGTGTCACTGTCCGT GGGGACCTGTGGTGGCAAGACAGGCTGAACGCTTTCAACTTGCCGTTCTTCTTGAATTCTTCGGGAATTTTCACA AACTATTGGTGGTACAACGATGCACCTCAGAAACAAATCGACTTCCTTTCGAGGGTTGACCCGAATCTCACCGGG CAAACCGCTGAGCCGCATCAATACAACCTGCAGAAGACGATTCAAGATATCTATATCGGTGTGGATGTCTGGGGA CGCGGTTCGCATGGTGGAGGAGGATTTGGTGCCTACAAAGCTATTGAGCACGCAGACCCGAAAGGACTCGGGTTT AGCGTTGCCCTCTTCGCTCAAGGATGGACCTGGGAAACCGAGGAGGAGAAACCAGGCTGGAACTGGGCACAGTTC TGGGACTACGACTCTAAACTCTGGGTTGGACCTCCCGGAGTTGTCGAGGCACCTGACCATACCGTCAAACCTGGC GAATACCCCTGCGTTCACGGACCCTTCCAACCCATCTCCAGCTTCTTCCTGACATATCCACCTCCCGACCCGCTA GACCTGCCATTCTACACCAACTTCTGCCCCGGTATCGGAGATGCGTGGTTCGTTGAGGGCAAGGAGGTCTTCCGC TCCGAGACGGGTTGGACAGACATGGACAAGCAGACCACGGTTGGCGACTTGGTCTGGCCCCGACCCAAGATTTAT GATCTTCCATCTCAAAATGCCAGTCAGGCTACGTTAAATGCGGCATTCAACTTTAACGATGCGTGGAATGGAGGA AACTCGCTTCAGATCAACCTCACCGTCCCTGGAGGAGCGACCACGTATGGAGCCTACTGGGTTCCCATCCAGACA TTCACATTCTCCAGTCGGCGCCAGTACGAAGCTTCGATCGTCTACAAGCCGGGGTTGAGTGGGAAGACCCGCTTC GATGCCAAGTACGAGGTGGGTATCCGAACCATCACAGGGGAAGACCAAGGCAAGATCATCTCCAACACGACGACG GAAGTTGGAAACGGTTGGCGCAAGGTGCACATTTTGTTCGAGATCGAGACGCCAGTTGAAGGAGGGTCCATCATC GTACCTTCATCCATCGGCCTGGTCATTGCAGTTTCGAACGTATCAACTACCGAGCAATTCGAGTTCCCCTTCCTG GTCGGCCAGATTACCATCCACCCCCACCTCCCCGATCGTTACAAGGAGTTCAAGCCGGCCCTCCTGTGGCTTTTG TTCACACCTTCCGCTGGAACTAATAGCCTCGATGGCACCCTCACTTGGGACGTCGTCGCAGCCATTGAACGCCCT CCACCAGTCGAAATTAACAACCCCGATGACGCACAAATCCCCTGGAACCTGCAGCCGACCAAACAAGAATGGTTC CCCGACTTCCTCTACTTCAATGTGTACGTGCTGGAGCTCTTGGATGGTGGTGGACAAGGTCCTCCACAGTGGATT GGCACGACTGGATACGATGGGGAGAAAAAGAGGTTCTTCATCTATGACGAAAGCTTGCCACCGACGTCCGGTTTA AGGAGGTTCACGTTCCAGATCGAGGGCGTCCTGGAGACGGGAGAGTCAACGCACTGGTACGATGCACCGGCTGCG CCGTCGGCAACGGCGGGAGGAGAGCAGAAGCGGACACGACGCACCTCTCTCAAGTCCGTGCTCAGTCCGTTGCGG AGGAAGAAGTCGAAGGGCGATATCTCCGTCGCCAAG |
| Length | 2364 |
Transcript
| Sequence id | CC1G_11102T0 |
|---|---|
| Sequence |
>CC1G_11102T0 ATGCCTATCGCTGGGAAGAAGTTCCACCCCCGGGCTCTGCCTGAGTTCTGGAGGACGTTCCGGGAGATGGACGAA TGGCGGGCCACTCAGACTGGACCTCAGGCTCGTCCGGCTGAAGGCATTCTCAAGTACGTTCCACGGAAGATTCGG CCTGCTGATATCGCAGGGAAAGGTCGACTGTTGGTTTCTCATGACTACAAGGGAGGCTACGTCGAAGATCCCTTT TCCAAGTCGTATAGCTTCAATTGGTGGTTCTCGACGGATAGCTTCAACTACTTCGCTCACCACCGGATAACCATT CCCCCTCCGGAATGGATAAACGCTGCTCATCGCCAGGGTGTACCTATTCTCGGCACCATCATCTTCGAAGGTGGA AGCGACGAAGACATCCTCCGGATGGTGATCGGGAAAACACCAGGAAGCACCAGCAACTTCCACGCCGAACGAAAC GCGGAGTACACCGTACCAGTTTCGTCGTACTACGCAGAACTCTTCGCAGACCTGGCTGTCGAGCGTGGATTCGAT GGTTGGCTGCTCAACGTTGAGATTGGTCTGCAGGGAGGATCAGAGCAAGCACGAGGTCTGGCTGCTTGGGTTGCG CTACTGCAGCAGGAGGTTTTGAAGAAGGTTGGCCCACATGGCTTGGTCATTTGGTACGACAGTGTCACTGTCCGT GGGGACCTGTGGTGGCAAGACAGGCTGAACGCTTTCAACTTGCCGTTCTTCTTGAATTCTTCGGGAATTTTCACA AACTATTGGTGGTACAACGATGCACCTCAGAAACAAATCGACTTCCTTTCGAGGGTTGACCCGAATCTCACCGGG CAAACCGCTGAGCCGCATCAATACAACCTGCAGAAGACGATTCAAGATATCTATATCGGTGTGGATGTCTGGGGA CGCGGTTCGCATGGTGGAGGAGGATTTGGTGCCTACAAAGCTATTGAGCACGCAGACCCGAAAGGACTCGGGTTT AGCGTTGCCCTCTTCGCTCAAGGATGGACCTGGGAAACCGAGGAGGAGAAACCAGGCTGGAACTGGGCACAGTTC TGGGACTACGACTCTAAACTCTGGGTTGGACCTCCCGGAGTTGTCGAGGCACCTGACCATACCGTCAAACCTGGC GAATACCCCTGCGTTCACGGACCCTTCCAACCCATCTCCAGCTTCTTCCTGACATATCCACCTCCCGACCCGCTA GACCTGCCATTCTACACCAACTTCTGCCCCGGTATCGGAGATGCGTGGTTCGTTGAGGGCAAGGAGGTCTTCCGC TCCGAGACGGGTTGGACAGACATGGACAAGCAGACCACGGTTGGCGACTTGGTCTGGCCCCGACCCAAGATTTAT GATCTTCCATCTCAAAATGCCAGTCAGGCTACGTTAAATGCGGCATTCAACTTTAACGATGCGTGGAATGGAGGA AACTCGCTTCAGATCAACCTCACCGTCCCTGGAGGAGCGACCACGTATGGAGCCTACTGGGTTCCCATCCAGACA TTCACATTCTCCAGTCGGCGCCAGTACGAAGCTTCGATCGTCTACAAGCCGGGGTTGAGTGGGAAGACCCGCTTC GATGCCAAGTACGAGGTGGGTATCCGAACCATCACAGGGGAAGACCAAGGCAAGATCATCTCCAACACGACGACG GAAGTTGGAAACGGTTGGCGCAAGGTGCACATTTTGTTCGAGATCGAGACGCCAGTTGAAGGAGGGTCCATCATC GTACCTTCATCCATCGGCCTGGTCATTGCAGTTTCGAACGTATCAACTACCGAGCAATTCGAGTTCCCCTTCCTG GTCGGCCAGATTACCATCCACCCCCACCTCCCCGATCGTTACAAGGAGTTCAAGCCGGCCCTCCTGTGGCTTTTG TTCACACCTTCCGCTGGAACTAATAGCCTCGATGGCACCCTCACTTGGGACGTCGTCGCAGCCATTGAACGCCCT CCACCAGTCGAAATTAACAACCCCGATGACGCACAAATCCCCTGGAACCTGCAGCCGACCAAACAAGAATGGTTC CCCGACTTCCTCTACTTCAATGTGTACGTGCTGGAGCTCTTGGATGGTGGTGGACAAGGTCCTCCACAGTGGATT GGCACGACTGGATACGATGGGGAGAAAAAGAGGTTCTTCATCTATGACGAAAGCTTGCCACCGACGTCCGGTTTA AGGAGGTTCACGTTCCAGATCGAGGGCGTCCTGGAGACGGGAGAGTCAACGCACTGGTACGATGCACCGGCTGCG CCGTCGGCAACGGCGGGAGGAGAGCAGAAGCGGACACGACGCACCTCTCTCAAGTCCGTGCTCAGTCCGTTGCGG AGGAAGAAGTCGAAGGGCGATATCTCCGTCGCCAAGTGA |
| Length | 2364 |
Gene
| Sequence id | CC1G_11102T0 |
|---|---|
| Sequence |
>CC1G_11102T0 ATGCCTATCGCTGGGAAGAAGTTCCACCCCCGGGCTCTGCCTGAGTTCTGGAGGACGTTCCGGGAGATGGACGAA TGGCGGGCCACTCAGACTGGACCTCAGGCTCGTCCGGCTGAAGGCATTCTCAAGTACGTTCCACGGAAGATTCGG CCTGCTGATATCGCAGGGAAAGGTCGACTGTTGGTAAGCGCCCACTGCTTCAGGTACTCTTCCGACTCTGGGCTC ATTGGAAGCATTTCAGGTTTCTCATGACTACAAGGGAGGCTACGTCGAAGATCCCTTTTCCAAGTCGTATAGCTT CAATTGGTGGTTCTCGACGGATAGCTTCAACTAGTGAGCCGTACAATTACCTGTGTCCCTGGAGGTTGACGAACA ATCCCAAAGCTTCGCTCACCACCGGATAACCATTCCCCCTCCGGAATGGATAAACGCTGCTCATCGCCAGGGTGT ACCTATTCTCGGCACCATGTACGTGATACTCGATCCAGAAACCTTTCTTCACACTGACCATGCACAAGCATCTTC GAAGGTGGAAGCGACGAAGACATCCTCCGGATGGTGATCGGGAAAACACCAGGAAGCACCAGCAACTTCCACGCC GAACGAAACGCGGAGTACACCGTACCAGTTTCGTCGTACTACGCAGAACTCTTCGCAGACCTGGCTGTCGAGCGT GGATTCGATGGTTGGCTGCTCAACGTTGAGATTGGTCTGCAGGGAGGATCAGAGCAAGCACGAGGTCTGGCTGCT TGGGTTGCGCTACTGCAGCAGGAGGTTTTGAAGAAGGTTGGCCCACATGGCTTGGTCATTTGGTACGACAGTGTC ACTGTCCGTGGGGACCTGTGGTGGCAAGACAGGCTGAACGCTTTCAACTTGCCGTTCTTCTTGAATTCTTCGGGA ATTTTCACAAACTATTGGGTATGTGGCTGATTTGTTGTTCCTTTGACTCCAACTGACTGGCACTTTCCCAGTGGT ACAACGATGCACCTCAGAAACAAATCGACTTCCTTTCGAGGGTTGACCCGAATCTCACCGGGCAAACCGCTGAGC CGCATCAATACAACCTGCAGAAGACGATTCAAGATATCTATATCGGTGTGGATGTCTGGGGACGCGGTTCGCATG GTGGAGGAGGATTTGGTGCCTACAAAGCTATTGAGCACGCAGACCCGAAAGGACTCGGGTTTAGCGTTGCCCTCT TCGCTCAAGGATGGACCTGGGAAACCGAGGAGGAGAAACCAGGCTGGAACTGGGCACAGTTCTGGGACTACGACT CTAAACTCTGGGTTGGACCTCCCGGAGTTGTCGAGGCACCTGACCATACCGTCAAACCTGGCGAATACCCCTGCG TTCACGGACCCTTCCAACCCATCTCCAGCTTCTTCCTGACATATCCACCTCCCGACCCGCTAGACCTGCCATTCT ACACCAACTTCTGCCCCGGTATCGGAGATGCGTGGTTCGTTGAGGGCAAGGAGGTCTTCCGCTCCGAGACGGGTT GGACAGACATGGACAAGCAGACCACGGTTGGCGACTTGGTCTGGCCCCGACCCAAGATTTATGATCTTCCATCTC AAAATGCCAGTCAGGCTACGTTAAATGCGGCATTCAACTTTAACGATGCGTGGAATGGAGGAAACTCGCTTCAGA TCAACCTCACCGTCCCTGGAGGAGCGACCACGTATGGAGCCTACTGGGTTCCCATCCAGACATTCACATTCTCCA GTCGGCGCCAGTACGAAGCTTCGATCGTCTACAAGCCGGGGTTGAGTGGGAAGACCCGCTTCGATGCCAAGTACG AGGTGGGTATCCGAACCATCACAGGGGAAGACCAAGGCAAGATCATCTCCAACACGACGACGGAAGTTGGAAACG GTTGGCGCAAGGTGCACATTTTGTTCGAGATCGAGACGCCAGTTGAAGGAGGGTCCATCATCGTACCTTCATCCA TCGGCCTGGTCATTGCAGTTTCGAACGTATCAACTACCGAGCAATTCGAGTTCCCCTTCCTGGTCGGCCAGATTA CCATCCACCCCCACCTCCCCGATCGTTACAAGGAGTTCAAGCCGGCCCTCCTGTGGCTTTTGTTCACACCTTCCG CTGGAACTAATAGCCTCGATGGCACCCTCACTTGGGACGTCGTCGCAGCCATTGAACGCCCTCCACCAGTCGAAA TTAACAACCCCGATGACGCACAAATCCCCTGGAACCTGCAGCCGACCAAACAAGAATGGTTCCCCGACTTCCTCT ACTTCAATGTGTACGTGCTGGAGCTCTTGGATGGTGGTGGACAAGGTCCTCCACAGTGGATTGGCACGACTGGAT ACGATGGGGAGAAAAAGAGGTTCTTCATCTATGACGAAAGCTTGCCACCGACGTCCGGTTTAAGGAGGTTCACGT TCCAGATCGAGGGCGTCCTGGAGACGGGAGAGTCAACGCACTGGTACGATGCACCGGCTGCGCCGTCGGCAACGG CGGGAGGAGAGCAGAAGCGGACACGACGCACCTCTCTCAAGTCCGTGCTCAGTCCGTTGCGGAGGAAGAAGTCGA AGGGCGATATCTCCGTCGCCAAGTGA |
| Length | 2576 |