CC1G_11507
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_11507 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NHA6 | Functional description | Cytoplasm protein |
| Location | Chr_2:2609552..2611927 | Strand | + |
| Gene length (nt) | 2376 | Transcript length (nt) | 1740 |
| CDS length (nt) | 1740 | Protein length (aa) | 579 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Schizosaccharomyces pombe | exg3 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB24049 | 48.1 | 2.029E-182 | 578 |
| Agrocybe aegerita | Agrae_CAA7265374 | 46.9 | 5.023E-169 | 539 |
| Schizophyllum commune H4-8 | Schco3_2613657 | 43 | 4.565E-161 | 516 |
| Grifola frondosa | Grifr_OBZ75975 | 43.6 | 1.6E-151 | 488 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_200333 | 45.6 | 3.069E-150 | 484 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1381013 | 44.5 | 2.192E-148 | 479 |
| Lentinula edodes NBRC 111202 | Lenedo1_1094061 | 43.3 | 1.384E-132 | 433 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_8028 | 42 | 3.465E-130 | 426 |
| Pleurotus ostreatus PC9 | PleosPC9_1_82312 | 42.9 | 1.975E-124 | 409 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1033087 | 50.4 | 2.152E-123 | 406 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_53834 | 48.2 | 2.044E-94 | 321 |
| Lentinula edodes B17 | Lened_B_1_1_297 | 35.9 | 5.69E-89 | 305 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 9757 |
| Description | Cytoplasm protein |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00150 | Cellulase (glycosyl hydrolase family 5) | IPR001547 | 151 | 426 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| SP(Sec/SPI) | 1 | 19 | 0.9039 |
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017853 | Glycoside hydrolase superfamily |
| IPR001547 | Glycoside hydrolase, family 5 |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004553 | hydrolase activity, hydrolyzing O-glycosyl compounds | MF |
| GO:0071704 | organic substance metabolic process | BP |
KEGG
| KEGG Orthology |
|---|
| K01210 |
EggNOG
| COG category | Description |
|---|---|
| G | Belongs to the glycosyl hydrolase 5 (cellulase A) family |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH5 | GH5_50 |
Transcription factor
| Group |
|---|
| No records |
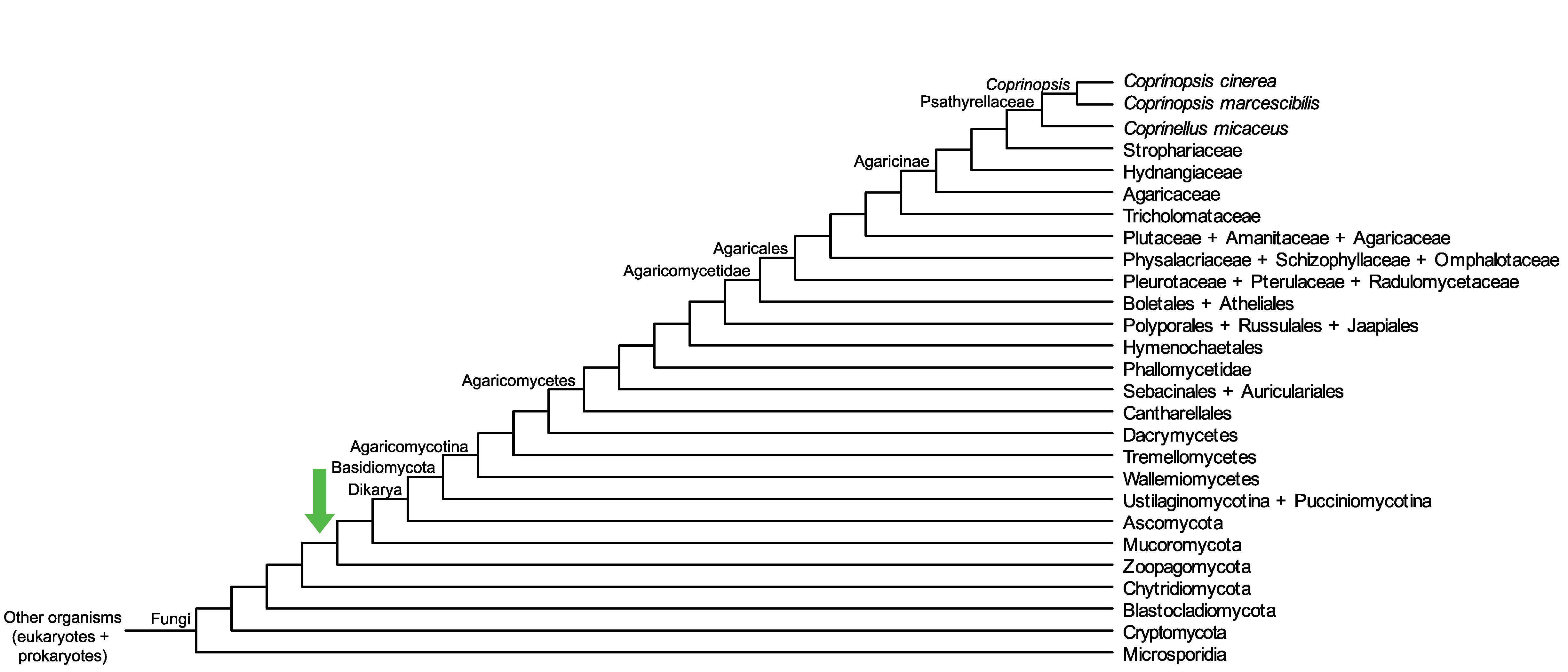
Conservation of CC1G_11507 across fungi.
Arrow shows the origin of gene family containing CC1G_11507.
Protein
| Sequence id | 9757 |
|---|---|
| Sequence |
>9757 MVSNATFVSALLALGVTQANYKPYPSVSNTSTSTTRTISTVDDTDVQPDGLVLPQNVRITAVMDASDPQCQVEPY DAPSVDHQEYPSYDEKLATVFRYRKQQSVNLGSWFVHENWMTPSLFRCAAGNAGSEIDIAYGWGNTTGARTVLER HWDTFINASDFKWLADVGINTVRLPIGYWNLGSDFVKGTDYESAAEVYQNSWARVKRAVNLAGEHGLGVLVDLHG VPGSQNGKDHSGVSNGASNLFGDSANMDKTIDILTFLTKEFVHVNNVVGIQVLNEPIFDDRLTDFYGRAMDAMRA ADPDASRLPLYAHNGFDLKRFGPFVTGRKDFVVQDHHSYFVFSPEDRDQTATDHANSISNDVASTLGNASQETRG ELIVGEWSCALPPESLASDSNQNQAHKDFCGGQVDTYGNNTAGWSFWSYTKEECDNDPGWCFKSAVGTVLPTKFF SYHHQQPESIQNSVAGSNHSFLLHDAELPLTRRDEFTRLSIPERFKTIARRRRRDGNTDADGKGYDDGRATAGIF AAHNMSRLGFVNQYISDTIANLGSNVIPQESEAPFILLWEYFARPTKMRFGGVL |
| Length | 579 |
Coding
| Sequence id | CC1G_11507T0 |
|---|---|
| Sequence |
>CC1G_11507T0 ATGGTCTCCAACGCTACTTTTGTTTCTGCTTTACTGGCGCTGGGCGTTACTCAAGCAAACTACAAACCATACCCC AGCGTTTCGAACACCTCGACATCAACAACAAGAACAATATCCACTGTCGACGACACCGACGTACAACCAGATGGC CTCGTTTTGCCTCAGAATGTCCGCATTACAGCCGTCATGGATGCGTCGGATCCCCAGTGTCAGGTCGAACCCTAT GATGCACCCTCAGTGGACCATCAAGAATACCCCTCATATGACGAGAAACTCGCTACAGTGTTTCGATATCGGAAA CAACAGTCTGTGAATCTAGGGTCTTGGTTTGTTCACGAGAATTGGATGACCCCATCGCTCTTCCGCTGTGCGGCA GGCAATGCTGGCTCAGAAATCGACATCGCCTATGGGTGGGGAAACACAACTGGCGCTCGTACTGTTTTGGAACGA CATTGGGATACCTTCATCAACGCTTCGGACTTCAAATGGTTGGCAGATGTGGGTATCAATACCGTTCGCCTGCCC ATCGGATATTGGAATCTAGGGTCAGATTTCGTCAAAGGGACGGATTACGAGAGTGCAGCCGAAGTGTATCAGAAC TCTTGGGCAAGGGTGAAGAGGGCGGTGAACCTGGCTGGAGAACATGGGCTTGGTGTCTTGGTCGACCTGCATGGC GTTCCCGGAAGCCAGAACGGAAAGGACCACTCGGGGGTCTCGAATGGTGCTTCCAACCTCTTCGGCGACTCCGCG AACATGGACAAGACCATCGATATCCTTACGTTCCTAACGAAGGAGTTTGTTCATGTGAACAATGTTGTCGGCATT CAAGTCCTTAACGAACCAATATTCGATGACCGTTTGACTGATTTCTATGGCAGAGCCATGGACGCTATGCGGGCG GCTGATCCTGACGCCTCTCGCCTTCCGTTATATGCCCATAATGGGTTCGACTTGAAACGTTTTGGCCCATTTGTT ACTGGACGGAAGGATTTTGTCGTGCAGGATCATCATTCGTACTTTGTCTTCAGCCCAGAGGACAGGGACCAAACC GCGACAGACCATGCGAACAGTATCTCCAATGATGTCGCGTCGACGTTGGGTAACGCTTCGCAAGAAACCAGGGGG GAGCTCATTGTCGGCGAATGGTCCTGCGCCCTTCCACCAGAAAGCCTTGCATCCGATTCGAATCAAAATCAAGCG CATAAAGATTTCTGCGGCGGGCAGGTTGATACCTATGGAAACAACACTGCTGGTTGGAGCTTCTGGTCTTACACG AAAGAAGAATGCGATAACGATCCCGGGTGGTGCTTCAAGTCAGCGGTCGGCACTGTTTTACCCACGAAGTTCTTC TCGTACCATCATCAACAACCAGAGTCCATCCAAAACAGCGTTGCTGGATCCAATCATTCCTTCCTGCTTCATGAC GCGGAGCTGCCGTTAACCAGGCGTGACGAGTTTACGAGGCTCTCTATTCCCGAGCGCTTCAAAACCATCGCTAGA AGACGCAGGCGAGATGGAAACACAGATGCAGATGGTAAAGGGTATGACGACGGCAGGGCGACGGCTGGCATATTT GCTGCGCATAACATGTCAAGGCTGGGATTCGTCAACCAATACATCTCGGATACCATCGCCAACCTTGGATCCAAT GTTATACCCCAGGAATCTGAAGCACCATTTATTTTACTCTGGGAGTACTTTGCTCGCCCGACCAAGATGAGGTTT GGCGGAGTTCTG |
| Length | 1740 |
Transcript
| Sequence id | CC1G_11507T0 |
|---|---|
| Sequence |
>CC1G_11507T0 ATGGTCTCCAACGCTACTTTTGTTTCTGCTTTACTGGCGCTGGGCGTTACTCAAGCAAACTACAAACCATACCCC AGCGTTTCGAACACCTCGACATCAACAACAAGAACAATATCCACTGTCGACGACACCGACGTACAACCAGATGGC CTCGTTTTGCCTCAGAATGTCCGCATTACAGCCGTCATGGATGCGTCGGATCCCCAGTGTCAGGTCGAACCCTAT GATGCACCCTCAGTGGACCATCAAGAATACCCCTCATATGACGAGAAACTCGCTACAGTGTTTCGATATCGGAAA CAACAGTCTGTGAATCTAGGGTCTTGGTTTGTTCACGAGAATTGGATGACCCCATCGCTCTTCCGCTGTGCGGCA GGCAATGCTGGCTCAGAAATCGACATCGCCTATGGGTGGGGAAACACAACTGGCGCTCGTACTGTTTTGGAACGA CATTGGGATACCTTCATCAACGCTTCGGACTTCAAATGGTTGGCAGATGTGGGTATCAATACCGTTCGCCTGCCC ATCGGATATTGGAATCTAGGGTCAGATTTCGTCAAAGGGACGGATTACGAGAGTGCAGCCGAAGTGTATCAGAAC TCTTGGGCAAGGGTGAAGAGGGCGGTGAACCTGGCTGGAGAACATGGGCTTGGTGTCTTGGTCGACCTGCATGGC GTTCCCGGAAGCCAGAACGGAAAGGACCACTCGGGGGTCTCGAATGGTGCTTCCAACCTCTTCGGCGACTCCGCG AACATGGACAAGACCATCGATATCCTTACGTTCCTAACGAAGGAGTTTGTTCATGTGAACAATGTTGTCGGCATT CAAGTCCTTAACGAACCAATATTCGATGACCGTTTGACTGATTTCTATGGCAGAGCCATGGACGCTATGCGGGCG GCTGATCCTGACGCCTCTCGCCTTCCGTTATATGCCCATAATGGGTTCGACTTGAAACGTTTTGGCCCATTTGTT ACTGGACGGAAGGATTTTGTCGTGCAGGATCATCATTCGTACTTTGTCTTCAGCCCAGAGGACAGGGACCAAACC GCGACAGACCATGCGAACAGTATCTCCAATGATGTCGCGTCGACGTTGGGTAACGCTTCGCAAGAAACCAGGGGG GAGCTCATTGTCGGCGAATGGTCCTGCGCCCTTCCACCAGAAAGCCTTGCATCCGATTCGAATCAAAATCAAGCG CATAAAGATTTCTGCGGCGGGCAGGTTGATACCTATGGAAACAACACTGCTGGTTGGAGCTTCTGGTCTTACACG AAAGAAGAATGCGATAACGATCCCGGGTGGTGCTTCAAGTCAGCGGTCGGCACTGTTTTACCCACGAAGTTCTTC TCGTACCATCATCAACAACCAGAGTCCATCCAAAACAGCGTTGCTGGATCCAATCATTCCTTCCTGCTTCATGAC GCGGAGCTGCCGTTAACCAGGCGTGACGAGTTTACGAGGCTCTCTATTCCCGAGCGCTTCAAAACCATCGCTAGA AGACGCAGGCGAGATGGAAACACAGATGCAGATGGTAAAGGGTATGACGACGGCAGGGCGACGGCTGGCATATTT GCTGCGCATAACATGTCAAGGCTGGGATTCGTCAACCAATACATCTCGGATACCATCGCCAACCTTGGATCCAAT GTTATACCCCAGGAATCTGAAGCACCATTTATTTTACTCTGGGAGTACTTTGCTCGCCCGACCAAGATGAGGTTT GGCGGAGTTCTGTAA |
| Length | 1740 |
Gene
| Sequence id | CC1G_11507T0 |
|---|---|
| Sequence |
>CC1G_11507T0 ATGGTCTCCAACGCTACTTTTGTTTCTGCTTTACTGGCGCTGGGCGTTACTCAAGCAAACTACAAACCATACCCC AGCGTTTCGAACACCTCGACATCAACAACAAGAACAATATCCACTGTCGACGACACCGACGTACAACCAGATGGC CTCGTTTTGCCTCAGAATGTCCGCATTACAGCCGTCATGGATGCGTCGGATCCCCAGTGTCAGGTCGAACCCTAT GATGCACCCTCAGTGGACCATCAAGAATACCCCTCATATGACGAGAAACTCGCTACAGTGTTTCGATATCGGAAA CAACAGTCTGTGAATCTAGGGTCTTGGTACGTGGTCAATTTGCCTATCCGCCGTGACGTCTCTTTAGAACCCTTT CCTAACCCTTGCCCCGCAATAGGTTTGTTCACGAGAATTGGATGACCCCATCGCTCTTCCGCTGTGCGGCAGGCA ATGCTGGCTCAGAAATCGACATCGCCTATGGGTGGGGAAACACAACTGGCGCTCGTACTGTTTTGGAACGACATT GGGATACCTTCATCAACGCTTCGGACTTCAAATGGTTGGCAGATGTGGGTATCAATACCGTTCGCCTGCCCATCG GATATTGGAATCTAGGGTCAGATTTCGTCAAAGGGACGGATTACGAGAGTGCAGCCGAAGTGTATCAGAACTCTT GGGCAAGGGTGAAGAGGGCGGTGAACCTGGCTGGAGAACATGGGCTTGGTGTCTTGGTCGACCTGCATGGCGTTC CCGGAAGCCAGAACGGAAAGGACCACTCGGGGGTCTCGAATGGTGCTTCCAACCTCTTCGGCGACTCCGCGAACA TGGACAAGACCATCGATATCCTTACGTTCCTAACGAAGGAGTTTGTTCATGTGAACAATGTTGTCGGCATTCAAG TCCTTAACGAACCAATATTCGATGACCGTTTGACTGATTTCTGTGAGTATTTCTTCCTTGAGACGTTGACATCAA CTTATAGACATCTTGTAGATGGCAGAGCCATGGACGCTATGCGGGCGGCTGATCCTGACGCCTCTCGCCTTCCGT TATATGCCCATAATGGGTTCGACTTGAAACGTTTTGGCCCATTTGTTACTGGACGGAAGGATTTTGTCGTGCAGG ATCATCATTCGTACTTTGTCTTCAGCCCAGAGGACAGGGACCAAACCGCGACAGACCATGCGAACAGTATCTCCA ATGATGTCGCGTCGACGTTGGGTAACGCTTCGCAAGAAACCAGGGGGGAGCTCATTGTCGGCGAATGGTCCTGCG CCCTTCCACCAGAAAGCCTTGCATCCGATTCGAATCAAAATCAAGCGCATAAAGATTTCTGCGGCGGGCAGGTTG ATACCTATGGAAACAACACTGCTGGTTGGAGCTTCTGGTGTAAGTCTTGTTTTCCTCTCGTAACTCGAAACTGAA ACCAACTGAGCTGAATCTTGCCTTTACAGCTTACACGAAAGAAGAATGCGATAACGATCCCGGGTGGTGCTTCAA GTCAGCGGTCGGCACTGTTTTACCCACGAAGTTCTTCTCGTACCATCATCAACAACCAGAGTCCATCCAAAACAG CGTTGCTGGATCCAATCATTCCTTCCTGCTTCATGACGCGGAGCTGCCGTTAACCAGGCGTGACGAGTTTACGAG GCTCTCTATTCCCGAGCGCTTCAAAACCATCGCTAGAAGACGCAGGCGAGATGGAAACACAGATGCAGATGGTAA AGGGTATGACGACGGCAGGGCGACGGCTGGCATATTTGCTGCGCATAACATGTCAAGGCTGGGATTCGTCAACCA ATACATCTCGGATACCATCGCCAACCTTGGATCCAATGTTATACCCCAGGAATCTGAAGGTGCTTATACAGAGGG ATTCCTTCGTGGTCTTCGGGAGGCAGAGTCGAATTTCTCGACACAAGCTTTCACATCGTAGTGCTTTACCAACCT TGCATTCGCTATTCGATTTTCACCGTTGTATTGCTAGCACCATTTATTTTACTCTGGGAGTACTTTGCTCGCCCG GTGTTCACAACCAGACATTTCAGTATTGACTACGAGTGAAATTCACCGTATAAAACCCCCTCAGAGCTTTGCATC ATAATGCCGGACGGCTTCCGCTTCTATACCCCCTCCTGGTACCTAGGTGCCCATGTTTCATCACAGCGCTGGGGG ATACGGATTGCGGCCACAAGTTAAAAGTGACGTTTGCCGTACCCAGTGCCGAGAACTAACTGTAAATAGACCAAG ATGAGGTTTGGCGGAGGTGCGACAAGCATTTACAGGCAAGCCACCATCATGATGGGGCACCACAACCGTCCGACA CTCGGTCTGCCAGTCCAATCATATACCGTCTAACCTTTTCCAGTTCTGTAA |
| Length | 2376 |