CC1G_12014
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_12014 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | A8NF18 | Functional description | STE/STE11 protein kinase |
| Location | Chr_2:1320996..1324648 | Strand | - |
| Gene length (nt) | 3653 | Transcript length (nt) | 3183 |
| CDS length (nt) | 3183 | Protein length (aa) | 1060 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB21078 | 55 | 0 | 1211 |
| Agrocybe aegerita | Agrae_CAA7271666 | 55.8 | 0 | 1184 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1439689 | 54.8 | 0 | 1156 |
| Lentinula edodes NBRC 111202 | Lenedo1_1174260 | 52.3 | 0 | 1081 |
| Flammulina velutipes | Flave_chr10AA00313 | 51.3 | 0 | 1073 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_8316 | 51.7 | 0 | 1068 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_68456 | 51.8 | 0 | 1050 |
| Grifola frondosa | Grifr_OBZ75595 | 50.1 | 2.154E-304 | 996 |
| Schizophyllum commune H4-8 | Schco3_2605129 | 50.5 | 1.493E-304 | 988 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_153886 | 47.7 | 7.769E-292 | 974 |
| Auricularia subglabra | Aurde3_1_1233708 | 45.6 | 6.808E-272 | 867 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1060999 | 85 | 1.053E-147 | 500 |
| Pleurotus ostreatus PC9 | PleosPC9_1_44397 | 83.9 | 2.038E-134 | 460 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_64355 | 81.6 | 1.741E-132 | 454 |
| Lentinula edodes B17 | Lened_B_1_1_1365 | 79.7 | 1.197E-94 | 338 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 10114 |
| Description | STE/STE11 protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd09534 | SAM_Ste11_fungal | - | 35 | 96 |
| Pfam | PF00536 | SAM domain (Sterile alpha motif) | IPR001660 | 34 | 95 |
| Pfam | PF14847 | Ras-binding domain of Byr2 | IPR029458 | 310 | 408 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 767 | 1028 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR017441 | Protein kinase, ATP binding site |
| IPR029458 | Ras-binding domain of Byr2 |
| IPR000719 | Protein kinase domain |
| IPR001660 | Sterile alpha motif domain |
| IPR013761 | Sterile alpha motif/pointed domain superfamily |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR008271 | Serine/threonine-protein kinase, active site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005524 | ATP binding | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005515 | protein binding | MF |
KEGG
| KEGG Orthology |
|---|
| K11228 |
EggNOG
| COG category | Description |
|---|---|
| T | Ras-binding domain of Byr2 |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
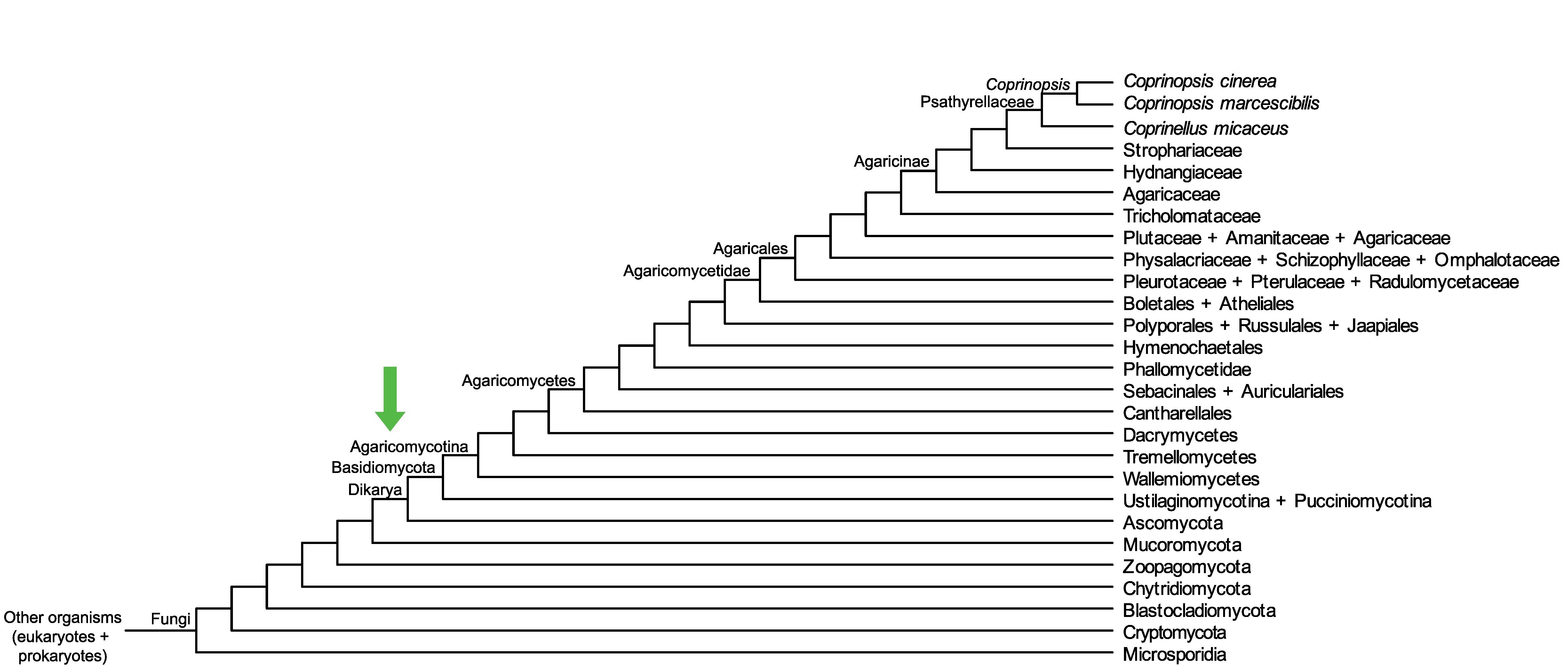
Conservation of CC1G_12014 across fungi.
Arrow shows the origin of gene family containing CC1G_12014.
Protein
| Sequence id | 10114 |
|---|---|
| Sequence |
>10114 MGSVDLRGQLPFPTGPTISLDPPPGTTFAESLKAWTDNHVARWLSDMKCGMHAEVFRINDIRGDVLLELDQDTLK EMNIVSIGDRIRILNAVKLLRQRAAARTPSPIHVTRPTASHTRTGSENLSLEQGVASGRGHSRKESTRPPPITIH PNANKGDLPDLIREPPPDSASGRSMMAPPPVRPLPVPQNATPTASQVSTPEPGITHALKRIYMGFTLQTLQINVS VAAASGPARRLGGHPYAMPSVQATLHPPTGLQNPNLSPIDEHFAAAGQNSSSTSTPSPPSQPYRSYTPANAYNTP SLDDIRKKIVKFVIPEEGTSYMIDVTNCSSGQEVIEKVLKKIGKGGFRGIDNDGHGDRDDGSLNVDGWAVYLASG EESPSEPLTETQLLNICNAPDHPARERGLAVRRLRRQEDRSGSPLARNLQPPTQPTSKATKRASSISILSGLGVR NPDKVLGDPPSPSNEAPSPPPPPLWQSGAGNAKRPSKLRNFFGQRPPSELITDHLPEFFPMAEKKVLRTARHSIL LRSGTLKRQSALSGGSIQLPPPPPLPSRFSTSTQGSGCRRSMSPGRASITSLPPPPLPEKDEGEPIPRMSLSTDD GHSIDLHSDDDDDDIPLSASVAPRLLPPIETGSFSQSMEEITGSRPASRATSIGSKRLSFMSELRSKRDRSDTAS MMTVDEITAEVESRRVSKMPDMSNANDLEGWTKVENAASFDTAPTVPADEVEVDDDEATLATEDDEDEDEDDSDD DFGIAIPTRTNNKWIKGALIGAGSFGKVYLGMDASNGLLMAVKQVELPQGDGPSQERKKSMLSALEREIELLKVL QHENIVQYLYSSSDDEYLNIFLEYVPGGSVATLLSNYGAFEEPLVRNFVRQILQGLSYLHERDIIHRDIKGANIL VDNKGGVKISDFGISKKVDDNLLGGNRLHRPSLQGSVFWMAPEVVKQTGHTKKADIWSVGCLVVEMLTGEHPWAQ LTQMQAIFKIGSSARPTIPSDISAEAQDFLQKTFEINHELRPHAAELLQHPWLSKKGKKAAAAAAAAAAAASASA ASSTNDSPSS |
| Length | 1060 |
Coding
| Sequence id | CC1G_12014T0 |
|---|---|
| Sequence |
>CC1G_12014T0 ATGGGCAGTGTCGACCTCCGTGGCCAACTGCCTTTCCCAACTGGACCGACCATCTCACTTGATCCACCACCGGGC ACAACCTTCGCGGAATCCCTAAAAGCATGGACGGACAACCATGTTGCCCGCTGGTTATCCGATATGAAATGCGGA ATGCATGCAGAAGTATTTCGTATCAACGACATTCGCGGCGATGTTCTCCTCGAATTGGATCAAGATACACTCAAG GAAATGAATATCGTGAGCATTGGCGATCGCATTCGCATTTTGAACGCCGTCAAGCTCCTTCGCCAACGTGCAGCA GCGAGAACACCCTCTCCTATCCACGTTACCCGCCCCACGGCCTCCCATACCCGCACTGGCTCAGAGAACCTCAGC CTGGAACAAGGTGTCGCCTCTGGTCGCGGTCACTCGCGGAAAGAATCGACTCGACCACCTCCTATTACCATCCAC CCCAATGCGAACAAGGGGGATCTACCTGATCTTATTCGAGAGCCTCCACCAGACTCGGCATCTGGGCGGTCGATG ATGGCTCCACCACCTGTGCGACCTCTGCCAGTCCCTCAGAATGCAACCCCAACAGCATCTCAGGTCTCCACTCCA GAACCAGGGATTACTCACGCCCTCAAACGGATCTACATGGGATTCACGCTCCAAACCCTCCAGATCAACGTCTCC GTTGCCGCCGCCTCGGGCCCAGCCAGGAGACTGGGCGGACACCCTTACGCAATGCCTAGTGTACAGGCTACACTG CATCCACCGACAGGTCTACAGAACCCCAACCTTTCACCTATAGATGAACATTTCGCGGCAGCAGGCCAGAACAGT TCATCAACCAGCACACCATCACCGCCGTCTCAACCCTACAGATCCTACACACCCGCAAATGCCTACAACACTCCA AGCCTAGATGACATCCGGAAGAAGATTGTCAAGTTCGTTATTCCCGAGGAAGGAACATCATACATGATTGATGTC ACCAACTGCTCCAGCGGTCAAGAGGTCATCGAGAAAGTACTGAAGAAGATTGGAAAGGGAGGCTTTAGGGGGATT GATAACGACGGCCATGGTGACCGGGATGATGGTAGTCTGAACGTCGATGGCTGGGCCGTATACCTTGCATCCGGG GAAGAGTCACCTTCGGAACCGCTGACCGAAACCCAACTTCTAAATATCTGCAACGCTCCAGACCACCCTGCACGA GAACGGGGACTTGCTGTGCGCAGGCTACGCCGACAAGAGGACAGAAGCGGAAGCCCGCTTGCAAGGAATCTCCAA CCACCGACACAACCAACCAGCAAAGCAACTAAGCGCGCTAGCTCTATCAGTATTCTCAGTGGCCTCGGAGTTCGC AATCCAGACAAAGTCCTCGGCGACCCACCCTCACCCAGCAACGAAGCTCCAAGTCCTCCCCCTCCTCCCCTCTGG CAAAGCGGTGCCGGCAATGCCAAGCGACCGTCAAAGCTGCGCAACTTCTTTGGTCAACGACCCCCCAGCGAGCTC ATCACCGACCATCTTCCCGAATTCTTTCCTATGGCGGAAAAGAAAGTGCTGCGTACAGCTCGACACAGTATTCTA TTGCGTTCTGGAACTCTGAAACGGCAGAGTGCCTTGTCAGGCGGTTCGATTCAACTTCCACCACCGCCACCGTTA CCCTCAAGGTTTAGCACCAGCACACAAGGCTCGGGTTGCAGACGCTCGATGTCCCCAGGCAGGGCGTCTATTACC TCACTGCCACCCCCTCCGCTTCCAGAAAAAGATGAAGGGGAACCAATACCTCGAATGTCACTCTCCACCGACGAT GGACATTCTATCGACCTTCATTCCGACGACGACGACGACGACATTCCTCTTTCCGCTTCCGTAGCCCCTCGGCTT CTGCCTCCCATCGAAACTGGTTCGTTCTCTCAATCCATGGAGGAAATCACAGGAAGTAGGCCCGCTTCGAGAGCC ACGTCCATAGGCTCCAAGCGACTTAGCTTCATGTCTGAACTCCGAAGCAAACGAGATCGATCTGACACTGCAAGT ATGATGACCGTGGATGAGATCACAGCGGAGGTGGAGAGTAGGAGGGTGAGCAAGATGCCAGATATGTCAAACGCG AATGATCTGGAGGGGTGGACGAAGGTAGAGAATGCGGCTAGCTTTGATACCGCTCCTACGGTCCCTGCTGATGAG GTCGAGGTTGATGATGATGAGGCTACCTTGGCCACAGAAGACGATGAGGATGAGGACGAGGATGATTCCGACGAT GACTTTGGTATTGCAATCCCAACACGGACGAACAACAAATGGATCAAGGGTGCATTGATTGGCGCTGGGTCATTT GGAAAAGTCTATTTGGGGATGGATGCGTCCAATGGTCTCCTCATGGCTGTCAAGCAAGTCGAACTTCCCCAGGGC GACGGTCCTAGCCAGGAACGCAAGAAGAGCATGCTAAGCGCCCTCGAAAGAGAGATTGAACTCTTGAAGGTCCTT CAACACGAAAACATTGTCCAATATCTCTACTCTTCTAGTGACGATGAGTACCTCAATATTTTCCTGGAATACGTC CCCGGTGGATCGGTCGCCACTCTCCTCTCGAATTACGGCGCTTTCGAAGAACCTTTGGTTCGGAACTTTGTTCGG CAAATCCTTCAGGGTCTCAGCTACCTTCACGAACGTGATATCATTCATCGAGACATCAAGGGTGCTAACATTCTG GTTGATAACAAAGGAGGAGTCAAGATTTCCGACTTTGGTATCTCCAAGAAGGTCGACGATAATCTACTGGGTGGA AATCGGCTACACAGACCGTCATTGCAAGGATCGGTCTTCTGGATGGCGCCTGAAGTCGTCAAGCAAACCGGGCAC ACGAAGAAGGCTGACATTTGGAGTGTCGGATGCCTTGTTGTCGAGATGTTGACCGGTGAACATCCTTGGGCGCAA CTGACTCAGATGCAAGCCATATTCAAGATCGGCTCTTCCGCAAGACCGACTATTCCTTCTGATATCTCTGCTGAG GCACAAGATTTCCTTCAGAAGACATTTGAAATCAACCACGAGCTTCGACCTCATGCTGCCGAACTTCTTCAGCAC CCCTGGCTGTCCAAGAAGGGTAAAAAAGCAGCAGCGGCAGCAGCTGCCGCCGCCGCCGCCGCCAGCGCCAGCGCA GCCTCCTCCACTAATGATTCGCCTTCATCG |
| Length | 3183 |
Transcript
| Sequence id | CC1G_12014T0 |
|---|---|
| Sequence |
>CC1G_12014T0 ATGGGCAGTGTCGACCTCCGTGGCCAACTGCCTTTCCCAACTGGACCGACCATCTCACTTGATCCACCACCGGGC ACAACCTTCGCGGAATCCCTAAAAGCATGGACGGACAACCATGTTGCCCGCTGGTTATCCGATATGAAATGCGGA ATGCATGCAGAAGTATTTCGTATCAACGACATTCGCGGCGATGTTCTCCTCGAATTGGATCAAGATACACTCAAG GAAATGAATATCGTGAGCATTGGCGATCGCATTCGCATTTTGAACGCCGTCAAGCTCCTTCGCCAACGTGCAGCA GCGAGAACACCCTCTCCTATCCACGTTACCCGCCCCACGGCCTCCCATACCCGCACTGGCTCAGAGAACCTCAGC CTGGAACAAGGTGTCGCCTCTGGTCGCGGTCACTCGCGGAAAGAATCGACTCGACCACCTCCTATTACCATCCAC CCCAATGCGAACAAGGGGGATCTACCTGATCTTATTCGAGAGCCTCCACCAGACTCGGCATCTGGGCGGTCGATG ATGGCTCCACCACCTGTGCGACCTCTGCCAGTCCCTCAGAATGCAACCCCAACAGCATCTCAGGTCTCCACTCCA GAACCAGGGATTACTCACGCCCTCAAACGGATCTACATGGGATTCACGCTCCAAACCCTCCAGATCAACGTCTCC GTTGCCGCCGCCTCGGGCCCAGCCAGGAGACTGGGCGGACACCCTTACGCAATGCCTAGTGTACAGGCTACACTG CATCCACCGACAGGTCTACAGAACCCCAACCTTTCACCTATAGATGAACATTTCGCGGCAGCAGGCCAGAACAGT TCATCAACCAGCACACCATCACCGCCGTCTCAACCCTACAGATCCTACACACCCGCAAATGCCTACAACACTCCA AGCCTAGATGACATCCGGAAGAAGATTGTCAAGTTCGTTATTCCCGAGGAAGGAACATCATACATGATTGATGTC ACCAACTGCTCCAGCGGTCAAGAGGTCATCGAGAAAGTACTGAAGAAGATTGGAAAGGGAGGCTTTAGGGGGATT GATAACGACGGCCATGGTGACCGGGATGATGGTAGTCTGAACGTCGATGGCTGGGCCGTATACCTTGCATCCGGG GAAGAGTCACCTTCGGAACCGCTGACCGAAACCCAACTTCTAAATATCTGCAACGCTCCAGACCACCCTGCACGA GAACGGGGACTTGCTGTGCGCAGGCTACGCCGACAAGAGGACAGAAGCGGAAGCCCGCTTGCAAGGAATCTCCAA CCACCGACACAACCAACCAGCAAAGCAACTAAGCGCGCTAGCTCTATCAGTATTCTCAGTGGCCTCGGAGTTCGC AATCCAGACAAAGTCCTCGGCGACCCACCCTCACCCAGCAACGAAGCTCCAAGTCCTCCCCCTCCTCCCCTCTGG CAAAGCGGTGCCGGCAATGCCAAGCGACCGTCAAAGCTGCGCAACTTCTTTGGTCAACGACCCCCCAGCGAGCTC ATCACCGACCATCTTCCCGAATTCTTTCCTATGGCGGAAAAGAAAGTGCTGCGTACAGCTCGACACAGTATTCTA TTGCGTTCTGGAACTCTGAAACGGCAGAGTGCCTTGTCAGGCGGTTCGATTCAACTTCCACCACCGCCACCGTTA CCCTCAAGGTTTAGCACCAGCACACAAGGCTCGGGTTGCAGACGCTCGATGTCCCCAGGCAGGGCGTCTATTACC TCACTGCCACCCCCTCCGCTTCCAGAAAAAGATGAAGGGGAACCAATACCTCGAATGTCACTCTCCACCGACGAT GGACATTCTATCGACCTTCATTCCGACGACGACGACGACGACATTCCTCTTTCCGCTTCCGTAGCCCCTCGGCTT CTGCCTCCCATCGAAACTGGTTCGTTCTCTCAATCCATGGAGGAAATCACAGGAAGTAGGCCCGCTTCGAGAGCC ACGTCCATAGGCTCCAAGCGACTTAGCTTCATGTCTGAACTCCGAAGCAAACGAGATCGATCTGACACTGCAAGT ATGATGACCGTGGATGAGATCACAGCGGAGGTGGAGAGTAGGAGGGTGAGCAAGATGCCAGATATGTCAAACGCG AATGATCTGGAGGGGTGGACGAAGGTAGAGAATGCGGCTAGCTTTGATACCGCTCCTACGGTCCCTGCTGATGAG GTCGAGGTTGATGATGATGAGGCTACCTTGGCCACAGAAGACGATGAGGATGAGGACGAGGATGATTCCGACGAT GACTTTGGTATTGCAATCCCAACACGGACGAACAACAAATGGATCAAGGGTGCATTGATTGGCGCTGGGTCATTT GGAAAAGTCTATTTGGGGATGGATGCGTCCAATGGTCTCCTCATGGCTGTCAAGCAAGTCGAACTTCCCCAGGGC GACGGTCCTAGCCAGGAACGCAAGAAGAGCATGCTAAGCGCCCTCGAAAGAGAGATTGAACTCTTGAAGGTCCTT CAACACGAAAACATTGTCCAATATCTCTACTCTTCTAGTGACGATGAGTACCTCAATATTTTCCTGGAATACGTC CCCGGTGGATCGGTCGCCACTCTCCTCTCGAATTACGGCGCTTTCGAAGAACCTTTGGTTCGGAACTTTGTTCGG CAAATCCTTCAGGGTCTCAGCTACCTTCACGAACGTGATATCATTCATCGAGACATCAAGGGTGCTAACATTCTG GTTGATAACAAAGGAGGAGTCAAGATTTCCGACTTTGGTATCTCCAAGAAGGTCGACGATAATCTACTGGGTGGA AATCGGCTACACAGACCGTCATTGCAAGGATCGGTCTTCTGGATGGCGCCTGAAGTCGTCAAGCAAACCGGGCAC ACGAAGAAGGCTGACATTTGGAGTGTCGGATGCCTTGTTGTCGAGATGTTGACCGGTGAACATCCTTGGGCGCAA CTGACTCAGATGCAAGCCATATTCAAGATCGGCTCTTCCGCAAGACCGACTATTCCTTCTGATATCTCTGCTGAG GCACAAGATTTCCTTCAGAAGACATTTGAAATCAACCACGAGCTTCGACCTCATGCTGCCGAACTTCTTCAGCAC CCCTGGCTGTCCAAGAAGGGTAAAAAAGCAGCAGCGGCAGCAGCTGCCGCCGCCGCCGCCGCCAGCGCCAGCGCA GCCTCCTCCACTAATGATTCGCCTTCATCGTGA |
| Length | 3183 |
Gene
| Sequence id | CC1G_12014T0 |
|---|---|
| Sequence |
>CC1G_12014T0 ATGGGCAGTGTCGACCTCCGTGGCCAACTGCCTTTCCCAACTGGACCGACCATCTCACTTGATCCACCACCGGGC ACAACCTTCGCGGAATCCCTAAAAGCATGGACGGACAACCATGTTGCCCGCTGGTTATCCGATATGAAATGCGGA ATGCATGCAGAAGTATTTCGTATCAACGACATTCGCGGCGATGTTCTCCTCGAATTGGATCAAGATACACTCAAG GAAATGAATATCGTGAGCATTGGCGATCGCATTCGCATTTTGAACGCCGTCAAGCTCCTTCGCCAACGTGCAGCA GCGAGAACACCCTCTCCTATCCACGTTACCCGCCCCACGGCCTCCCATACCCGCACTGGCTCAGAGAACCTCAGC CTGGAACAAGGTGTCGCCTCTGGTCGCGGTCACTCGCGGAAAGAATCGACTCGACCACCTCCTATTACCATCCAC CCCAATGCGAACAAGGGGGATCTACCTGATCTTATTCGAGAGCCTCCACCAGACTCGGCATCTGGGCGGTCGATG ATGGCTCCACCACCTGTGCGACCTCTGCCAGTCCCTCAGAATGCAACCCCAACAGCATCTCAGGTCTCCACTCCA GGTGGGAGTCATCGTCCCAATCTCCCACCACTTCCTCCTCCCCCACGCGGCCAACCACCCCCACCCCCGACCACA AACCGCACTCCCAATCGCTGGAACTCCTCCGCTTCCGAAGCACCATCCCAACCTTTGCCTCCTACCCCTCAGAAC CAGGGATTACTCACGCCCTCAAACGGATCTACATGGGATTCACGCTCCAAACCCTCCAGATCAACGTCTCCGTTG CCGCCGCCTCGGGGTGTGCGAGGACCTGTTGCCAAAGCCTCTGGAGCAGGAGTTGCATCCCCGAACAACAGCCCA GCCAGGAGACTGGGCGGACACCCTTACGCAATGCCTAGTGTACAGGCTACACTGCATCCACCGACAGGTCTACAG AACCCCAACCTTTCACCTATAGATGAACATTTCGCGGCAGCAGGCCAGAACAGTTCATCAACCAGCACACCATCA CCGCCGTCTCAACCCTACAGATCCTACACACCCGCAAATGCCTACAACACTCCAAGCCTAGATGACATCCGGAAG AAGATTGTCAAGTTCGTTATTCCCGAGGAAGGAACATCATACATGATTGATGTCACCAACTGCTCCAGCGGTCAA GAGGTCATCGAGAAAGTACTGAAGAAGATTGGAAAGGGAGGCTTTAGGGGGATTGATAACGACGGCCATGGTGAC CGGGATGATGGTAGTCTGAACGTCGATGGCTGGGCCGTATACCTTGCATCCGGGGAAGAGTCACCTTGTAAGTCG GTCTAGATGCTATATGCCAATCTCAACTAACTCTTTCCCAGCGGAACCGCTGACCGAAACCCAACTTCTAAATAT CTGCAACGCTCCAGACCACCCTGCACGAGAACGGGGACTTGCTGTGCGCAGGCTACGCCGACAAGAGGACAGAAG CGGAAGCCCGCTTGCAAGGAATCTCCAACCACCGACACAACCAACCAGCAAAGCAACTAAGCGCGCTAGCTCTAT CAGTATTCTCAGTGGCCTCGGAGTTCGCAATCCAGACAAAGTCCTCGGCGACCCACCCTCACCCAGCAACGAAGC TCCAAGTCCTCCCCCTCCTCCCCTCTGGCAAAGCGGTGCCGGCAATGCCAAGCGACCGTCAAAGCTGCGCAACTT CTTTGGTCAACGACCCCCCAGCGAGCTCATCACCGACCATCTTCCCGAATTCTTTCCTATGGCGGAAAAGAAAGT GCTGCGTACAGCTCGACACAGTATTCTATTGCGTTCTGGAACTCTGAAACGGCAGAGTGCCTTGTCAGGCGGTTC GATTCAACTTCCACCACCGCCACCGTTACCCTCAAGGTTTAGCACCAGCACACAAGGCTCGGGTTGCAGACGCTC GATGTCCCCAGGCAGGGCGTCTATTACCTCACTGCCACCCCCTCCGCTTCCAGAAAAAGATGAAGGGGAACCAAT ACCTCGAATGTCACTCTCCACCGACGATGGACATTCTATCGACCTTCATTCCGACGACGACGACGACGACATTCC TCTTTCCGCTTCCGTAGCCCCTCGGCTTCTGCCTCCCATCGAAACTGGTTCGTTCTCTCAATCCATGGAGGAAAT CACAGGAAGTAGGCCCGCTTCGAGAGCCACGTCCATAGGCTCCAAGCGACTTAGCTTCATGTCTGAACTCCGAAG CAAACGAGATCGATCTGACACTGCAAGTATGATGACCGTGGATGAGATCACAGCGGAGGTGGAGAGTAGGAGGGT GAGCAAGATGCCAGATATGTCAAACGCGAATGATCTGGAGGGGTGGACGAAGGTAGAGAATGCGGCTAGCTTTGA TACCGCTCCTACGGTCCCTGCTGATGAGGTCGAGGTTGATGATGATGAGGCTACCTTGGCCACAGAAGACGATGA GGATGAGGACGAGGATGATTCCGACGATGACTTTGGTATTGCAATCCCAACACGGACGAGTAAGCATTATTACTG CCAAGTGCCAATCTTCGCTCGGTACTAACTGCTTTTCTAGACAACAAATGGATCAAGGGTGCATTGATTGGCGCT GGGTCATTTGGAAAAGTCTATTTGGGGATGGATGCGTCCAATGGTCTCCTCATGGCTGTCAAGCAAGTCGAACTT CCCCAGGGCGACGGTCCTAGCCAGGAACGCAAGAAGAGCATGCTAAGCGCCCTCGAAAGAGAGATTGAACTCTTG AAGGTCCTTCAACACGAAAACATTGTCCAATATCTCTGTAAGTCGCTTCAATTCGGGAATGCCATCCATGCTAAC GCAGTTTGTAGACTCTTCTAGTGACGATGAGTACCTCAATATTTTCCTGGAATACGTCCCCGGTGGATCGGTCGC CACTCTCCTCTCGAATTACGGCGCTTTCGAAGAACCTTTGGTTCGGAACTTTGTTCGGCAAATCCTTCAGGGTCT CAGCTACCTTCACGAACGTGATATCATTCATCGAGACATCAAGGGTGCTAACATTCTGGTTGATAACAAAGGAGG AGTCAAGATTTCCGACTTTGGTATCTCCAAGAAGGTCGACGATAGTGAGTTACCCTGGTTGTGATGGTCTGTAAC GTGGTAAACTGATGATCTCTACGTAGATCTACTGGGTGGAAATCGGCTACACAGACCGTCATTGCAAGGATCGGT CTTCTGGATGGCGCCTGAAGTCGTCAAGCAAACCGGGCACACGAAGAAGGCTGACATTTGGAGTGTCGGATGCCT TGTTGTCGAGATGTTGACCGGTGAACATCCTTGGGCGCAACTGACTCAGATGCAAGCCATATTCAAGGTAACTAT GGATTAAGCAGCTGTCGGGATTAGATGCTTACCGTTGCTATTCTTAGATCGGCTCTTCCGCAAGACCGACTATTC CTTCTGATATCTCTGCTGAGGCACAAGATTTCCTTCAGAAGACATTTGAAATCAACCACGAGCTTCGACCTCATG CTGCCGAACTTCTTCAGCACCCCTGGCTGTCCAAGAAGGGTAAAAAAGCAGCAGCGGCAGCAGCTGCCGCCGCCG CCGCCGCCAGCGCCAGCGCAGCCTCCTCCACTAATGATTCGCCTTCATCGTGA |
| Length | 3653 |